Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
汎用推薦システム Embedding基盤と BigQuery Vector Search で実...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
ZOZO Developers
PRO
June 19, 2026
Technology
43
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
汎用推薦システム Embedding基盤と BigQuery Vector Search で実現する高速システム構築
株式会社ZOZO
データ・AIシステム本部 データシステム部 MA推薦ブロック
伊藤 瑠海
ZOZO Developers
PRO
June 19, 2026
More Decks by ZOZO Developers
See All by ZOZO Developers
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
0
140
After the Prompt. -プロンプトの先にある、デザイナーの価値とは。
zozotech
PRO
0
31
現地で盛り上がった WWDC26 Keynote
zozotech
PRO
1
310
Google I/O 2026 現地参加レポート
zozotech
PRO
0
120
AIエージェントとUIをつなぐ技術 - Google Cloud Next '26 の Generative UI セッションレポート -
zozotech
PRO
0
290
AlloyDBの新機能と活用事例を紹介
zozotech
PRO
0
250
Agentに最適化されたインフラへ
zozotech
PRO
0
260
Gemini Enterprise app & Google Workspaceのアップデート
zozotech
PRO
0
270
Cloud Runはどこまで広がるのか
zozotech
PRO
0
230
Other Decks in Technology
See All in Technology
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
0
2.6k
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
150
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
3.5k
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
1
2.5k
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
150
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
1.8k
AI Driven AI Governance
pict3
0
250
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
120
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
2.5k
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
8.1k
Featured
See All Featured
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
670
エンジニアに許された特別な時間の終わり
watany
107
250k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
The SEO Collaboration Effect
kristinabergwall1
1
500
The Pragmatic Product Professional
lauravandoore
37
7.4k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
220
Abbi's Birthday
coloredviolet
3
8.5k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Transcript
汎用推薦システム Embedding基盤と BigQuery Vector Search で実現する高速システム構築 株式会社ZOZO データ・AIシステム本部 データシステム部 MA推薦ブロック
伊藤 瑠海 Copyright © ZOZO, Inc. 1
© ZOZO, Inc. 株式会社ZOZO データ・AIシステム本部 データシステム部 MA推薦ブロック 伊藤 瑠海 出身地
北海道 札幌市 趣味 / 特技 筋トレ / ボクシング 最近気になるもの Enhanced Games 2
© ZOZO, Inc. 3 AGENDA 本日の流れ 01 MA推薦ブロックの取り組み 02 従来の課題
03 解決策:汎用推薦システム 04 アーキテクチャ:6ステップのパイプライン 05 ぶつかった課題と対処 06 運用事例 07 今後の展望
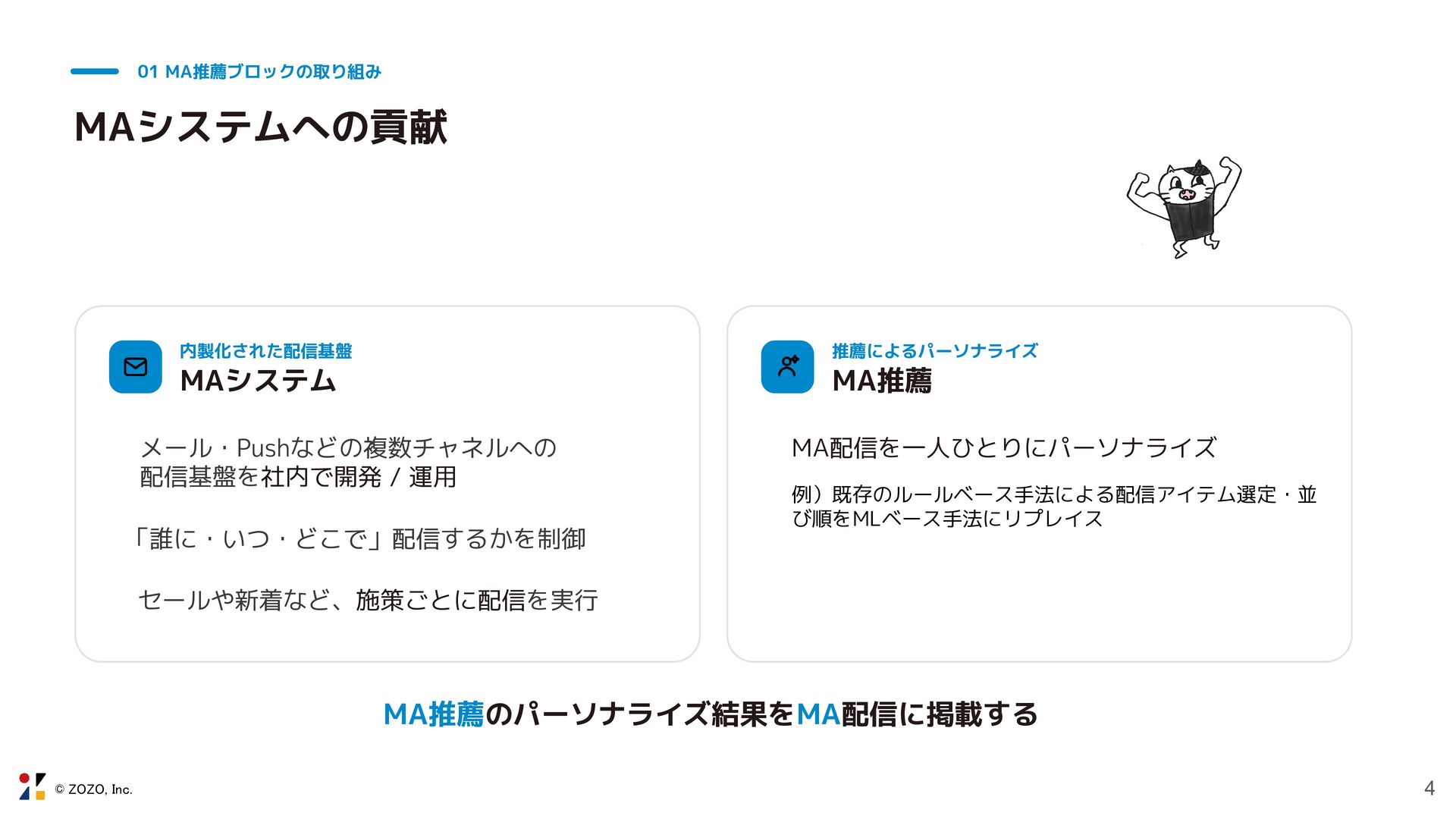
© ZOZO, Inc. 4 01 MA推薦ブロックの取り組み MAシステムへの貢献 内製化された配信基盤 MAシステム メール・Pushなどの複数チャネルへの
配信基盤を社内で開発 / 運用 「誰に・いつ・どこで」配信するかを制御 セールや新着など、施策ごとに配信を実行 推薦によるパーソナライズ MA推薦 MA配信を一人ひとりにパーソナライズ 例)既存のルールベース手法による配信アイテム選定・並 び順をMLベース手法にリプレイス MA推薦のパーソナライズ結果をMA配信に掲載する
© ZOZO, Inc. 5 02 従来の課題 「速さ」と「精度」のトレードオフ 速さ 機械学習ベース :
施策ごとにモデルを実装 開発リードタイムが長い 工程 所要期間 EDA 約2週間 モデルの設計・実装 約3週間 パイプラインの設計・実装 約2週間 実験・評価・チューニング 約3週間 1施策あたりの開発リードタイム 約2.5か月 ※ 開発工数はプロジェクトによって増減します 精度 ルールベース : 行動ログに基づくルール 潜在的な嗜好を捉えられない 閲覧履歴やお気に入りブランドなど、顕在的な嗜好に基づく 推薦が中心ルールの設計は比較的容易 ルールの例 「ブランドAを閲覧したユーザーに、ブランドAの値下げ商品 を 推薦する」 「閲覧回数の多い人気商品を、多くのユーザーに推薦する」 潜在的な嗜好を反映できない どちらか一方しか満たせず、速さと精度の両立ができていなかった
© ZOZO, Inc. 6 02 従来の課題 求めていたのは「高速な構築 × 高い精度」の両立 高い
低い 速い 遅い 機械学習ベース 精度◎/構築は遅い ルールベース 速い/精度に限界 求めていたもの 両立 要求 01 ── 高速な推薦システム構築 短期間で構築できる 施策ごとにモデルを作り直さず推薦システムを短期間 で立ち上げられること 要求 02 ── 高い推薦精度 潜在的な嗜好を捉える ユーザーの潜在的な嗜好を反映した推薦ができること 速度 精度
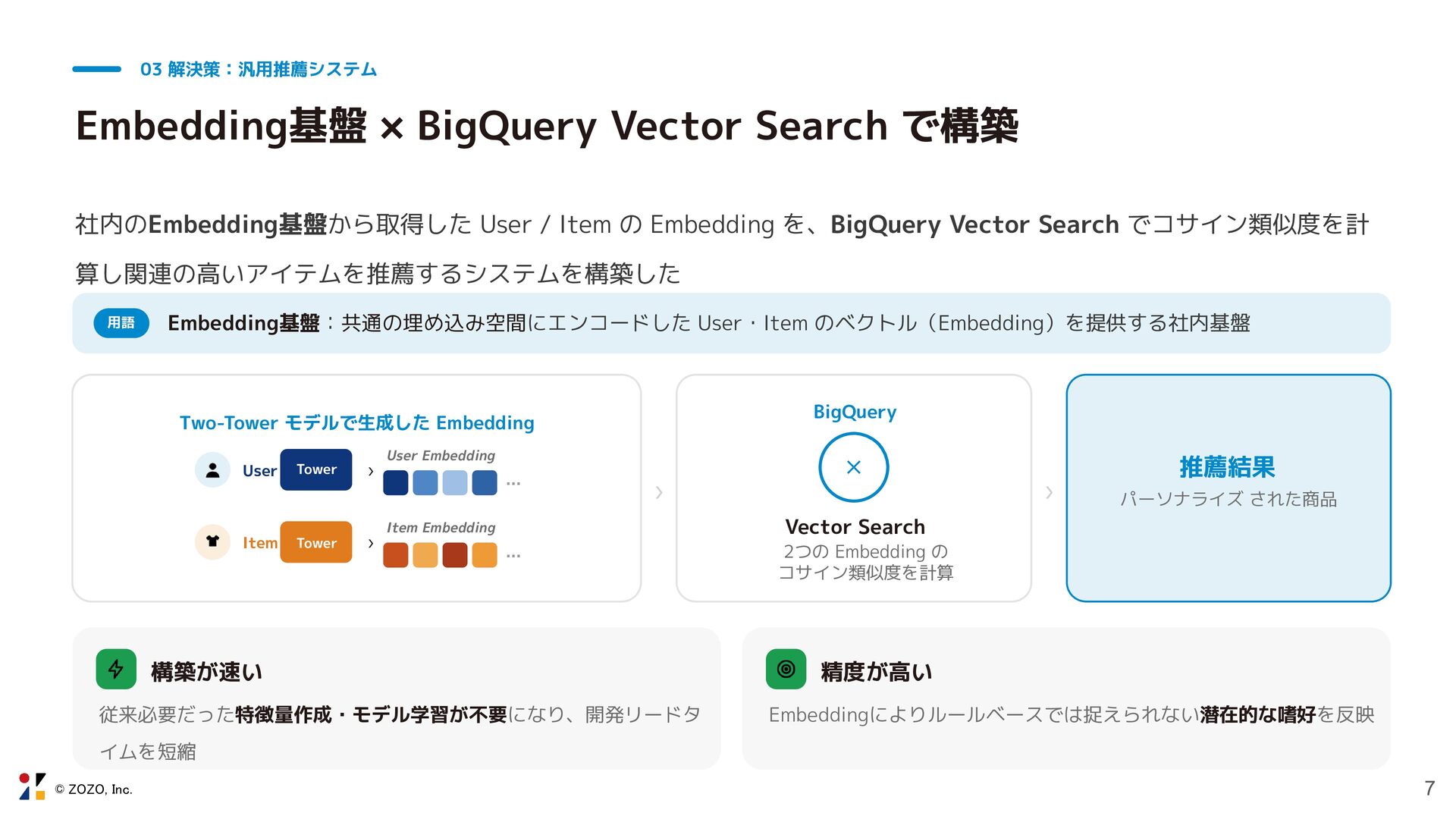
© ZOZO, Inc. 7 03 解決策:汎用推薦システム Embedding基盤 × BigQuery Vector
Search で構築 社内のEmbedding基盤から取得した User / Item の Embedding を、BigQuery Vector Search でコサイン類似度を計 算し関連の高いアイテムを推薦するシステムを構築した 用語 Embedding基盤:共通の埋め込み空間にエンコードした User・Item のベクトル(Embedding)を提供する社内基盤 Two-Tower モデルで生成した Embedding User Tower › User Embedding … Item Tower › Item Embedding … › BigQuery × Vector Search 2つの Embedding の コサイン類似度を計算 › 推薦結果 パーソナライズ された商品 構築が速い 従来必要だった特徴量作成・モデル学習が不要になり、開発リードタ イムを短縮 精度が高い Embeddingによりルールベースでは捉えられない潜在的な嗜好を反映
© ZOZO, Inc. 8 04 アーキテクチャ 6ステップのパイプライン(Vertex AI Pipelines) 1
セグメント抽出 施策の対象となる User・Item(= セグメン ト)を抽出 › 2 Embedding抽出 対象セグメントの Embedding を社内基盤 から取得 › 3 Vector Index作成 計算量削減のため candidate に Index を 貼る › 4 Vector Search User と Item の類似度 計算を実行 › 5 後処理 施策ごとのスコアブースト フィルタリング › 6 評価・ポリシー 定量評価・事前定義ポ リシーで検証 汎用たる所以 2つを差し替えるだけで、複数施策に利用可能 ① セグメント抽出:対象の User・Item を抽出する SQL を差し替え ⑤ 後処理:施策に合わせてスコアブースト・フィルタの条件を変更 実行・連携 パイプラインはBigQuery のジョブでバッチ実行 配信連携:推薦結果を BigQuery に保存しMAシステムが読み込む
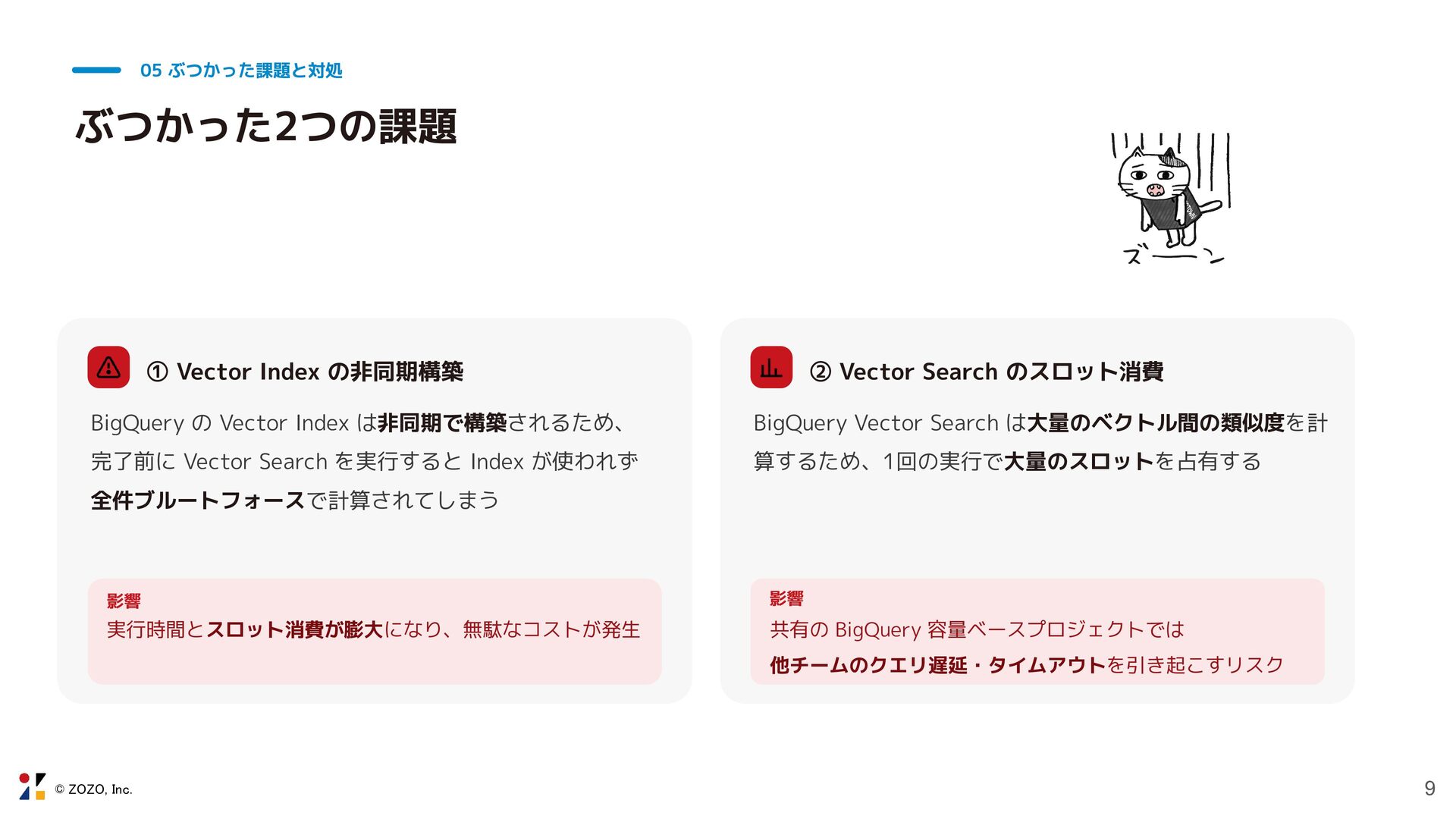
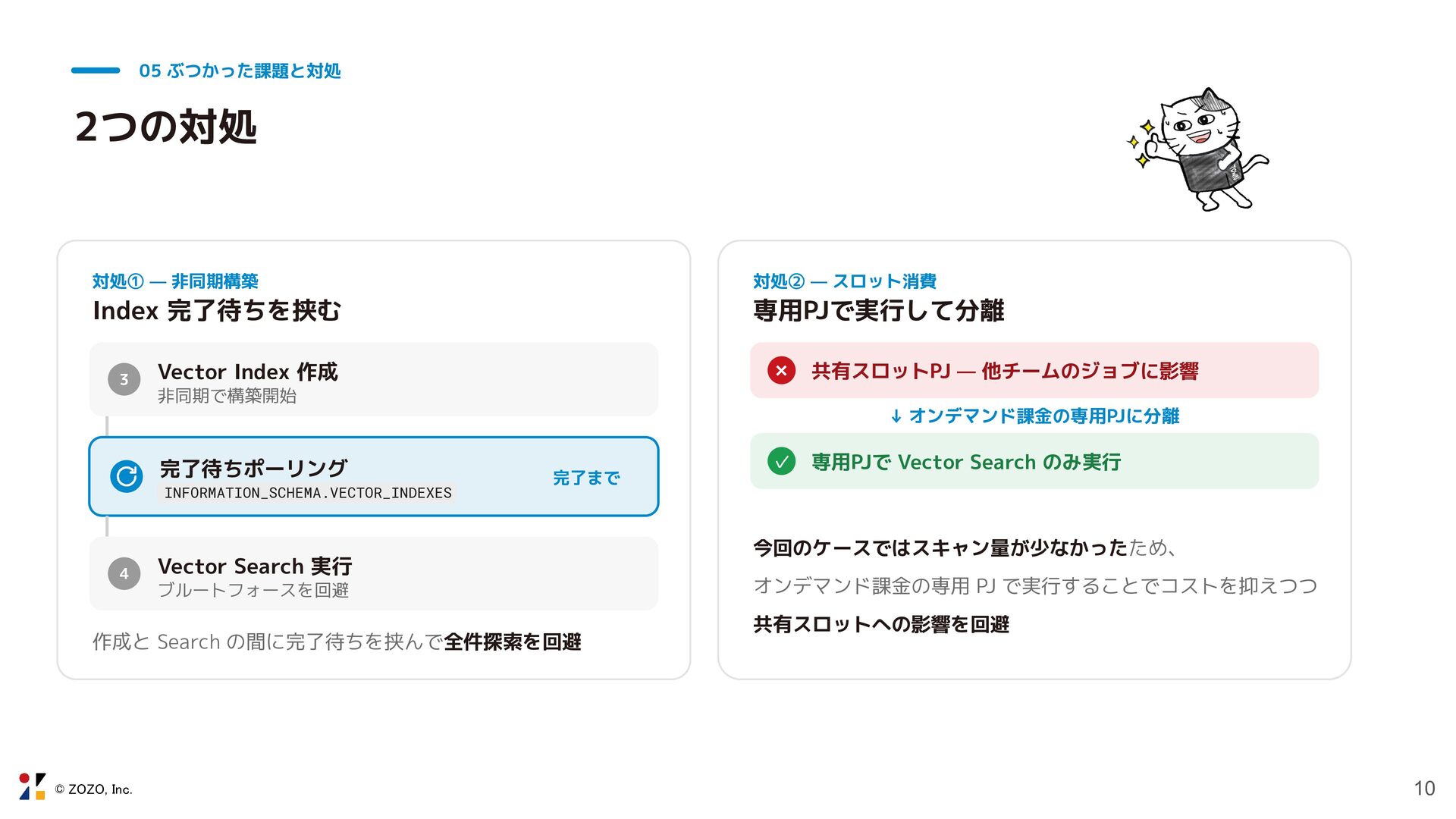
© ZOZO, Inc. 9 05 ぶつかった課題と対処 ぶつかった2つの課題 ① Vector Index
の非同期構築 BigQuery の Vector Index は非同期で構築されるため、 完了前に Vector Search を実行すると Index が使われず 全件ブルートフォースで計算されてしまう 影響 実行時間とスロット消費が膨大になり、無駄なコストが発生 ② Vector Search のスロット消費 BigQuery Vector Search は大量のベクトル間の類似度を計 算するため、1回の実行で大量のスロットを占有する 影響 共有の BigQuery 容量ベースプロジェクトでは 他チームのクエリ遅延・タイムアウトを引き起こすリスク
© ZOZO, Inc. 05 ぶつかった課題と対処 2つの対処 対処① — 非同期構築 Index
完了待ちを挟む 3 Vector Index 作成 非同期で構築開始 完了待ちポーリング INFORMATION_SCHEMA.VECTOR_INDEXES 完了まで 4 Vector Search 実行 ブルートフォースを回避 作成と Search の間に完了待ちを挟んで全件探索を回避 対処② — スロット消費 専用PJで実行して分離 × 共有スロットPJ — 他チームのジョブに影響 ↓ オンデマンド課金の専用PJに分離 ✓ 専用PJで Vector Search のみ実行 今回のケースではスキャン量が少なかったため、 オンデマンド課金の専用 PJ で実行することでコストを抑えつつ 共有スロットへの影響を回避 10
© ZOZO, Inc. 11 06 運用事例 開発リードタイムの短縮 ある施策に汎用推薦システムを適用した際の開発リードタイム比較 工程 従来
汎用推薦システム EDA 約2週間 不要(Embedding基盤を利用) モデルの設計・実装 約3週間 不要(Embedding基盤を利用) パイプラインの設計・実装 約2週間 約1週間(セグメント設定 + 既存基盤) 実験・評価・チューニング 約3週間 約2週間(後処理によるチューニング) EDAとモデル開発が不要になった パイプライン再利用で各工程の工数も削減 約2.5か月 ▶ 約3週間
© ZOZO, Inc. 12 06 運用事例 A/Bテストで主要KPIが向上 Control:ルールベース手法 / Treatment:汎用推薦システム
配信あたり MA経由 流入数 向上 ↑ 配信あたり MA経由 購入数 向上 ↑ 両指標とも Treatment が Control を統計的に有意に上回り、本番導入へ移行
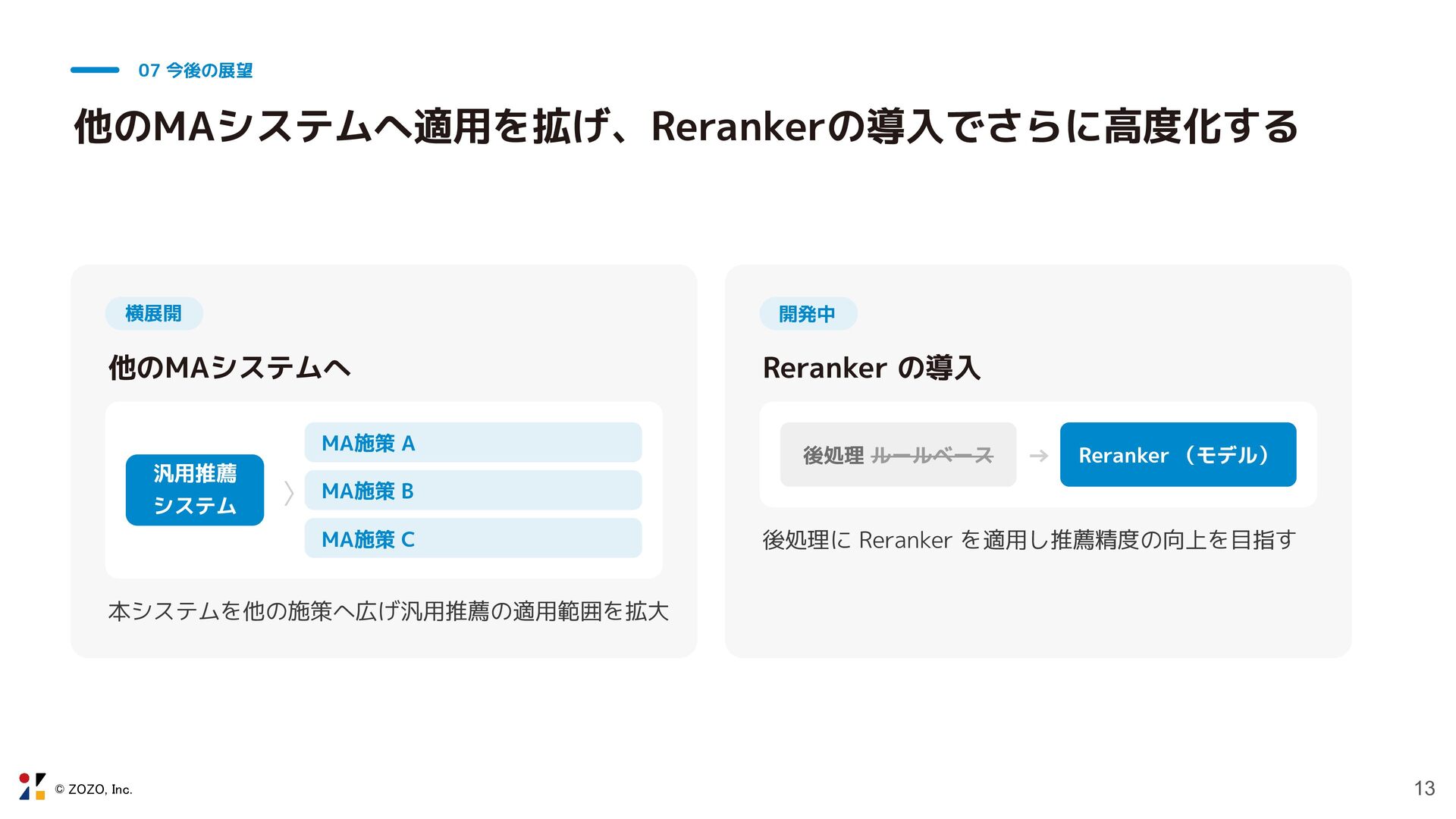
© ZOZO, Inc. 13 07 今後の展望 他のMAシステムへ適用を拡げ、Rerankerの導入でさらに高度化する 横展開 他のMAシステムへ 汎用推薦
システム ⟩ MA施策 A MA施策 B MA施策 C 本システムを他の施策へ広げ汎用推薦の適用範囲を拡大 開発中 Reranker の導入 後処理 ルールベース → Reranker (モデル) 後処理に Reranker を適用し推薦精度の向上を目指す
14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}