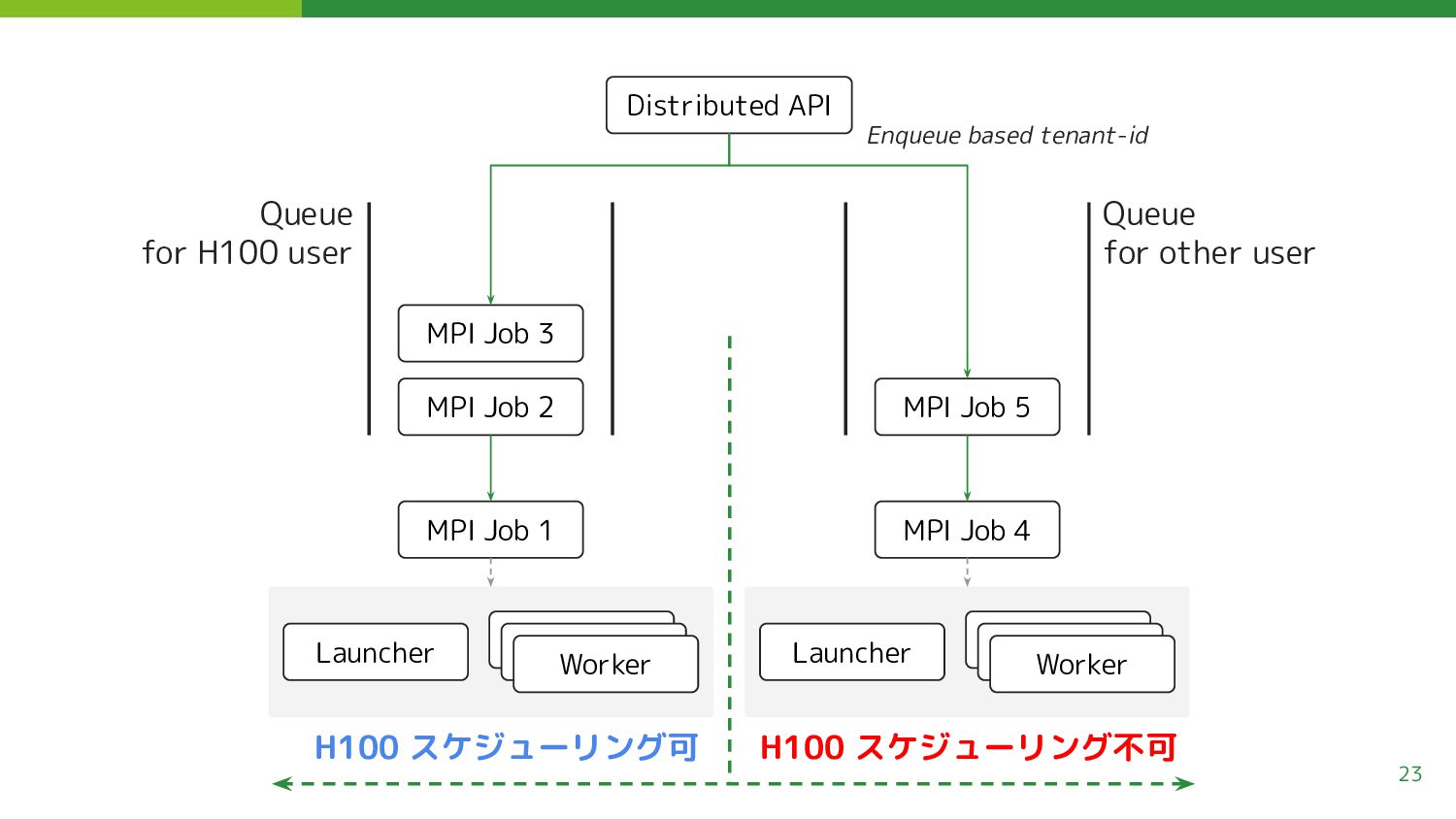
Job 1 Launcher Worker Queue for H100 user Queue for other user MPI Job 5 MPI Job 4 Launcher Worker H100 スケジューリング可 H100 スケジューリング不可 Enqueue based tenant-id
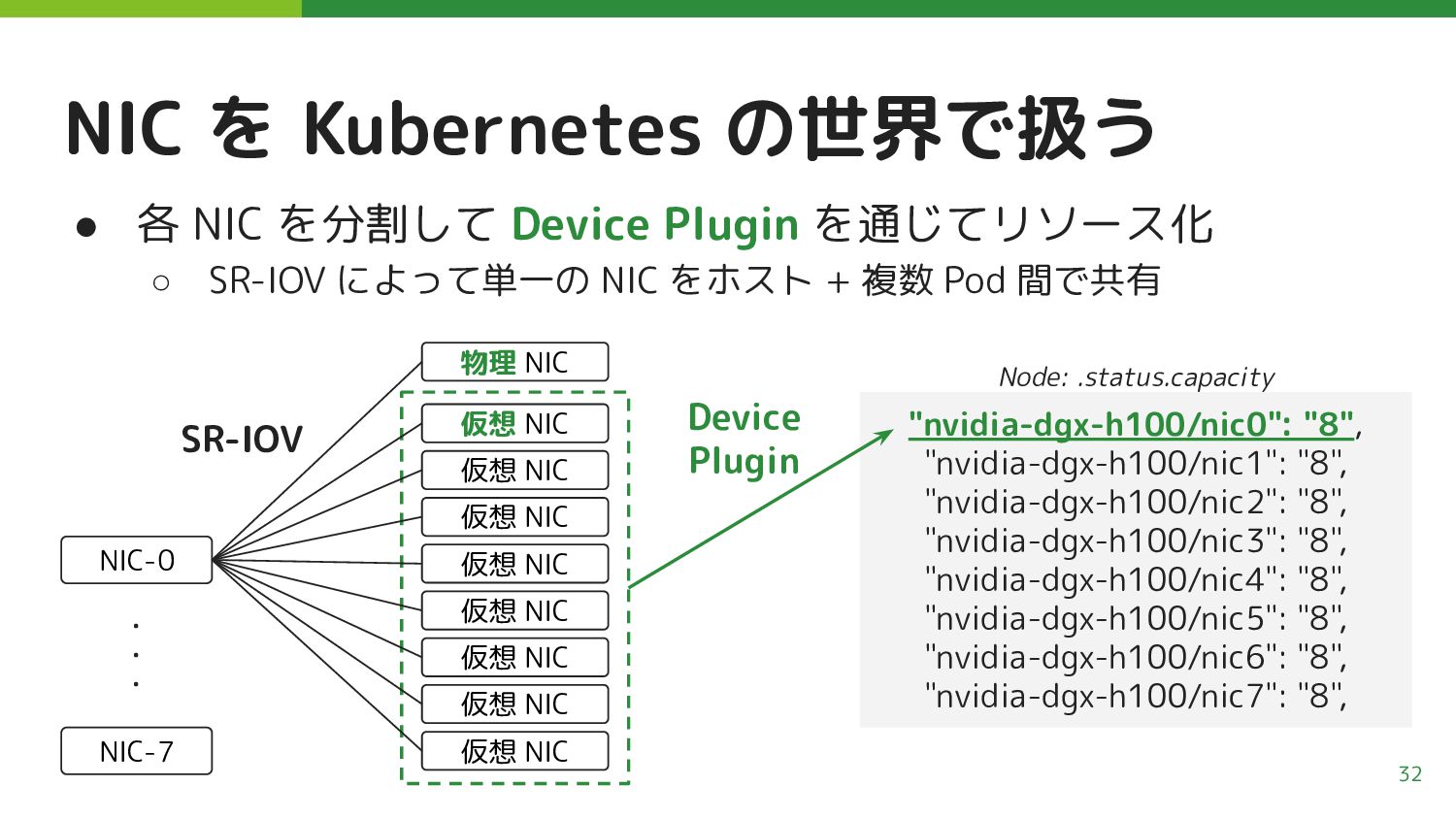
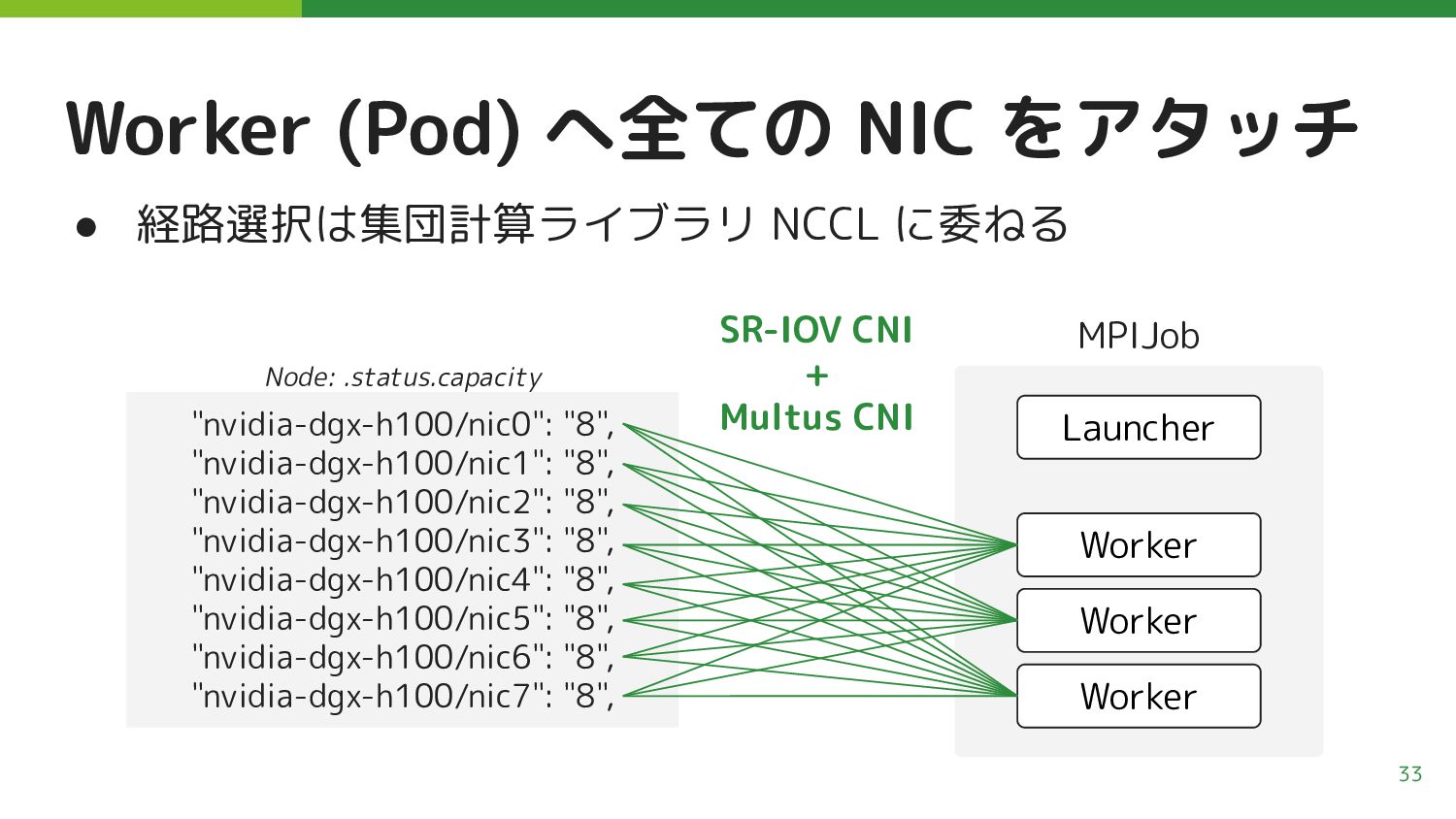
を通じてリソース化 ◦ SR-IOV によって単一の NIC をホスト + 複数 Pod 間で共有 32 "nvidia-dgx-h100/nic0": "8", "nvidia-dgx-h100/nic1": "8", "nvidia-dgx-h100/nic2": "8", "nvidia-dgx-h100/nic3": "8", "nvidia-dgx-h100/nic4": "8", "nvidia-dgx-h100/nic5": "8", "nvidia-dgx-h100/nic6": "8", "nvidia-dgx-h100/nic7": "8", Node: .status.capacity NIC-0 物理 NIC 仮想 NIC 仮想 NIC 仮想 NIC 仮想 NIC 仮想 NIC 仮想 NIC 仮想 NIC 仮想 NIC SR-IOV Device Plugin NIC-7 ・ ・ ・
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}