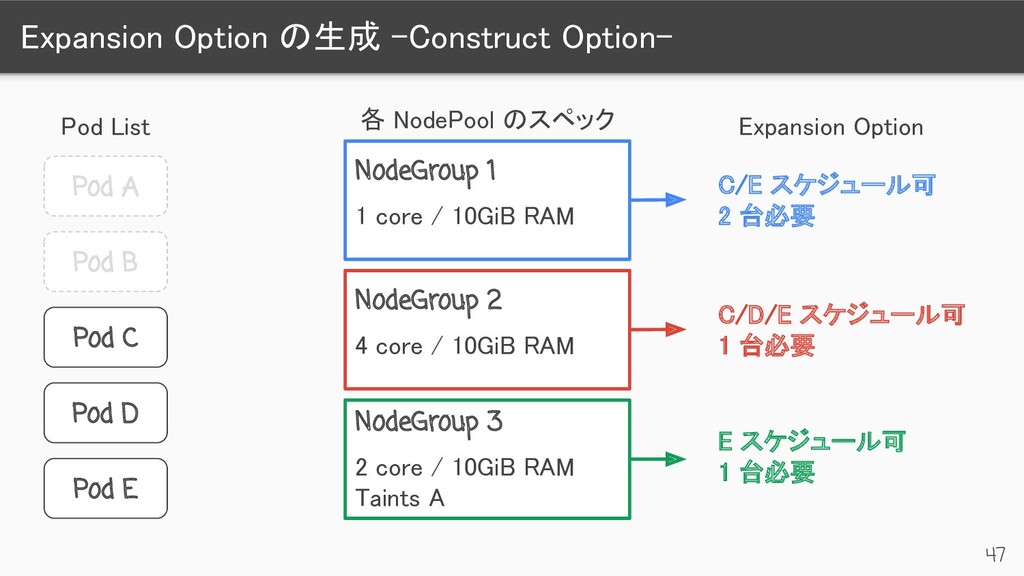
Pod List Pod C Pod D Pod E NodeGroup 1 1 core / 10GiB RAM Expansion Option NodeGroup 2 4 core / 10GiB RAM NodeGroup 3 2 core / 10GiB RAM Taints A C/E スケジュール可 2 台必要 C/D/E スケジュール可 1 台必要 E スケジュール可 1 台必要 各 NodePool のスペック
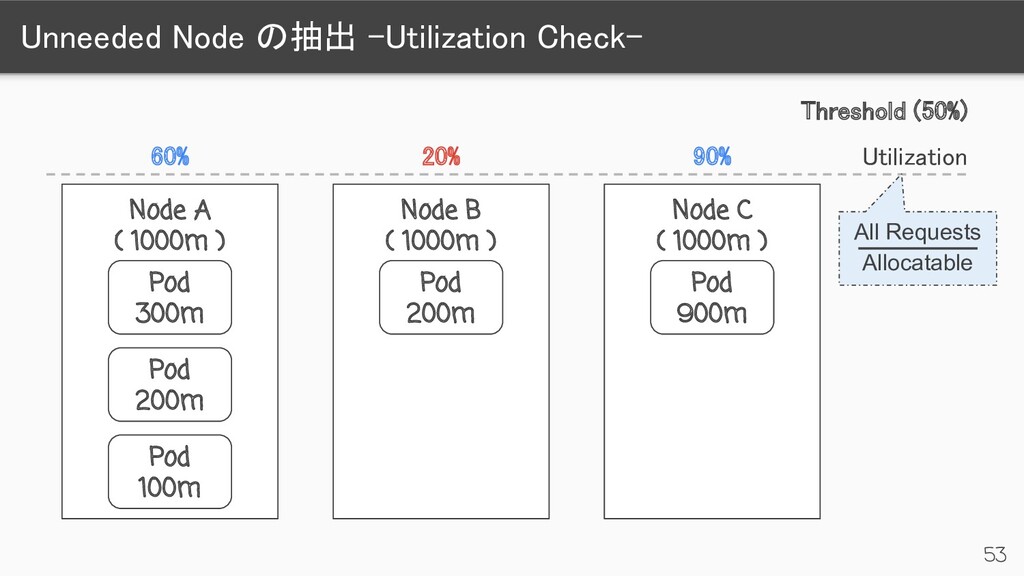
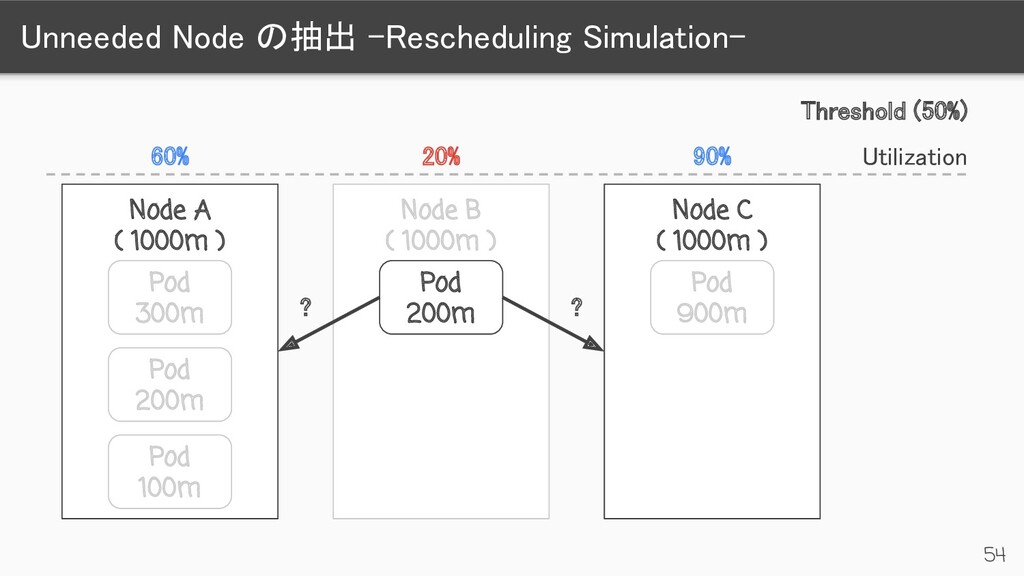
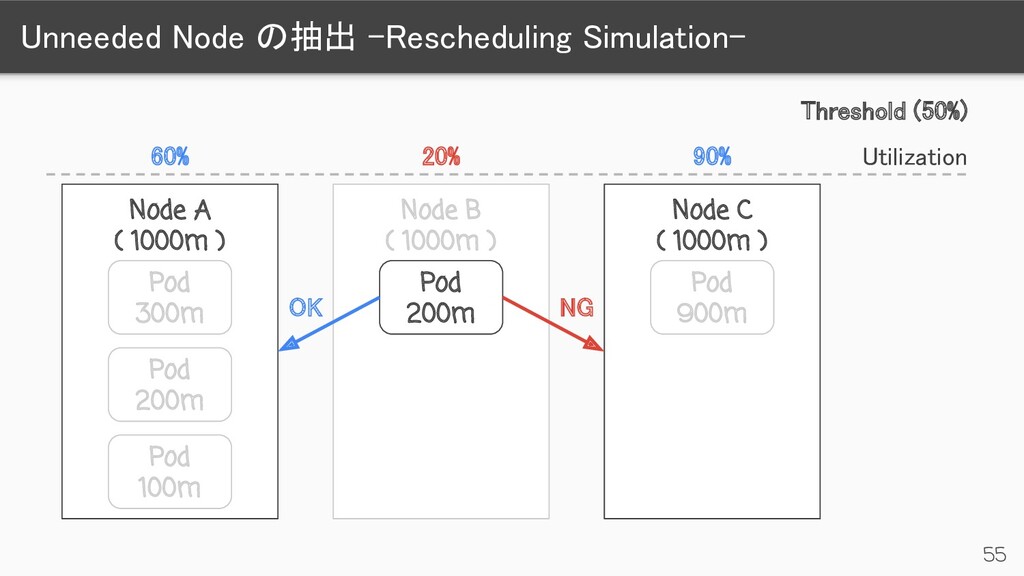
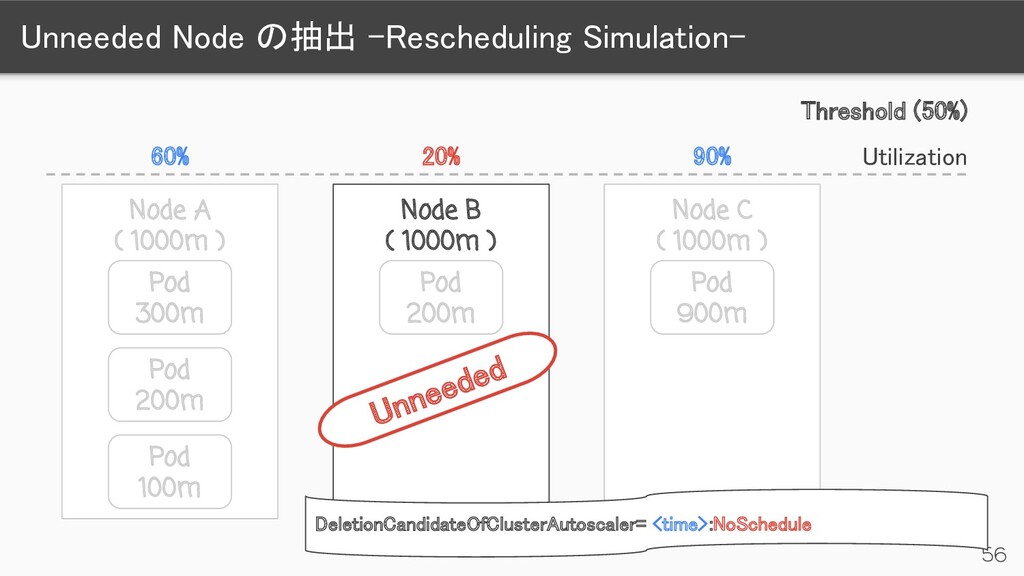
) Pod 300m Pod 200m Pod 100m Node B ( 1000m ) Pod 200m Node C ( 1000m ) Pod 900m 90% 20% 60% Threshold (50%) Utilization Unneeded DeletionCandidateOfClusterAutoscaler= <time>:NoSchedule
{kind=link}
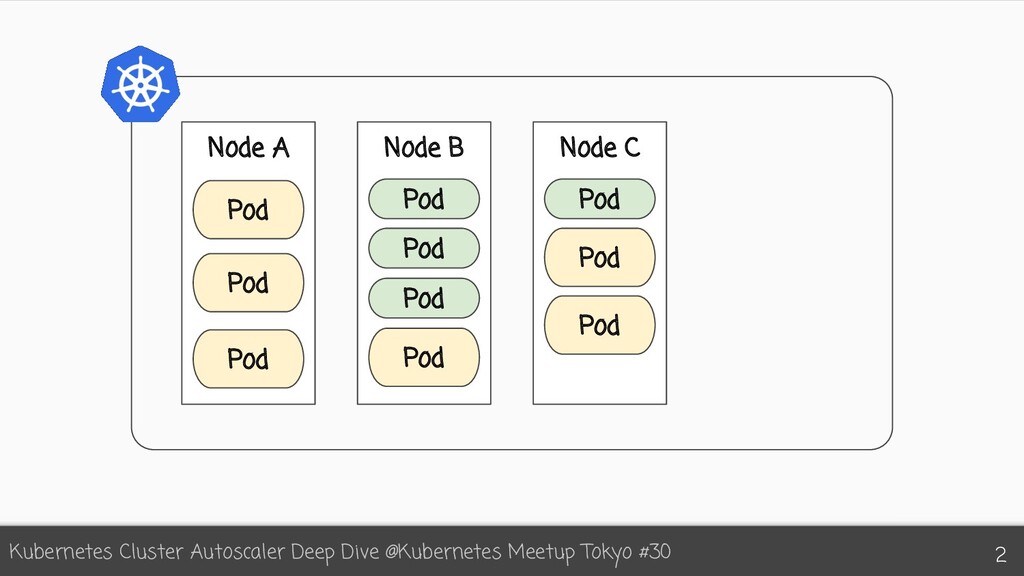{kind=link}
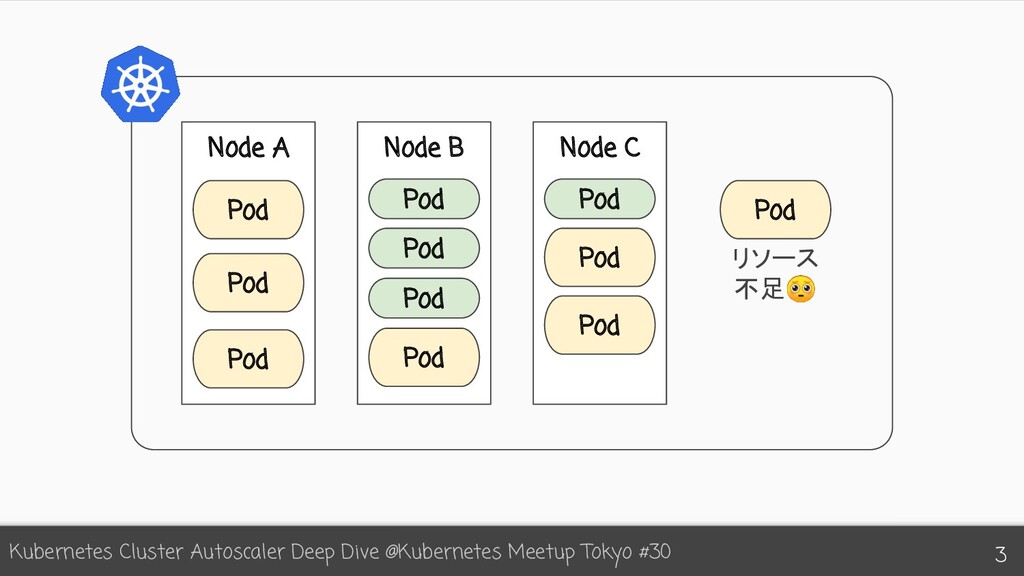{kind=link}
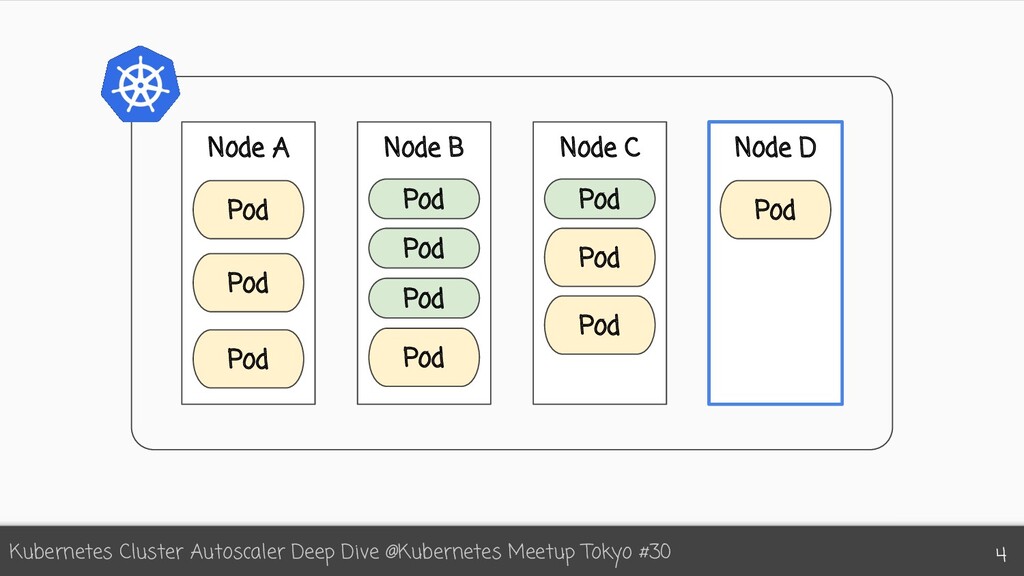{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
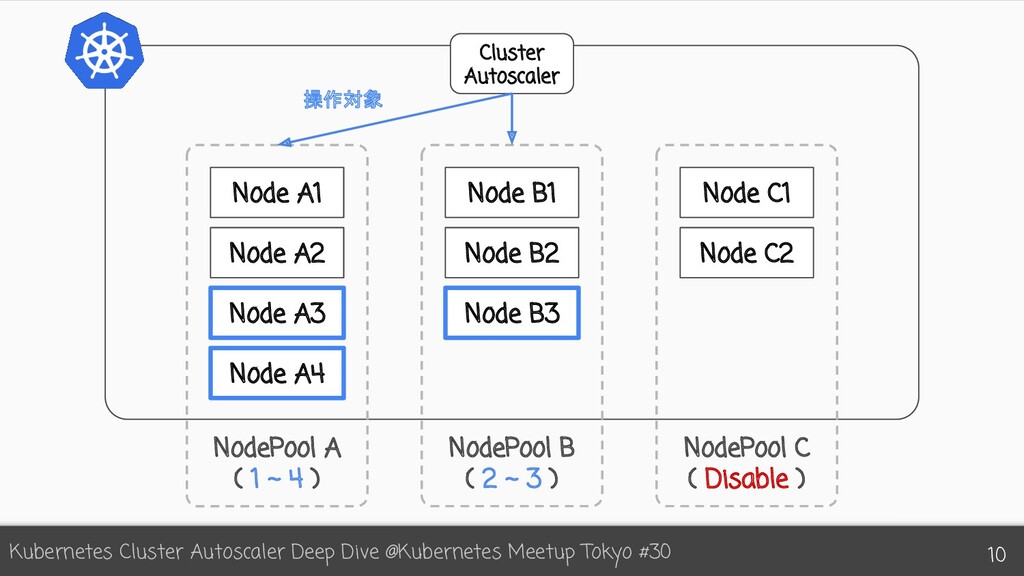{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
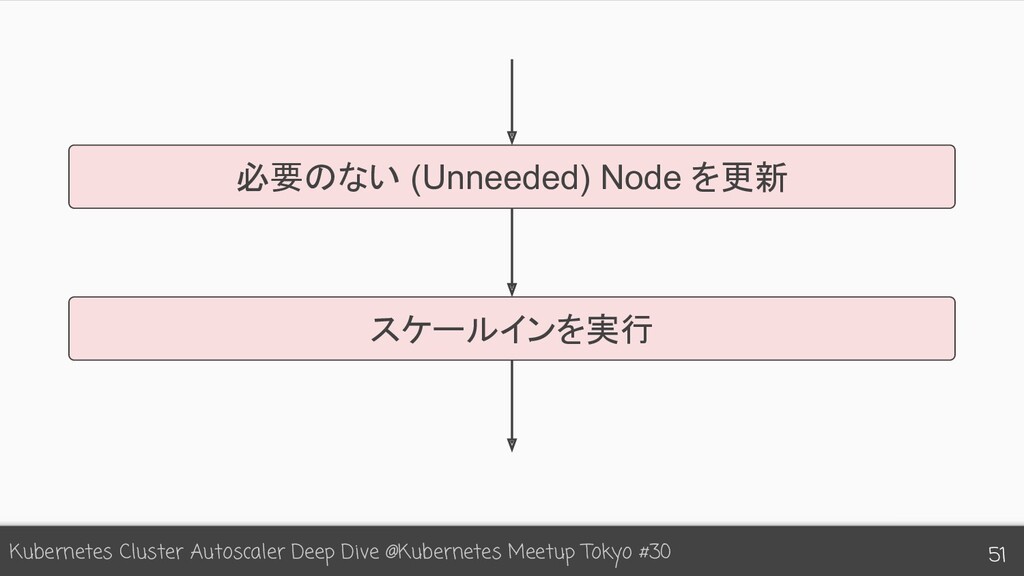
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}