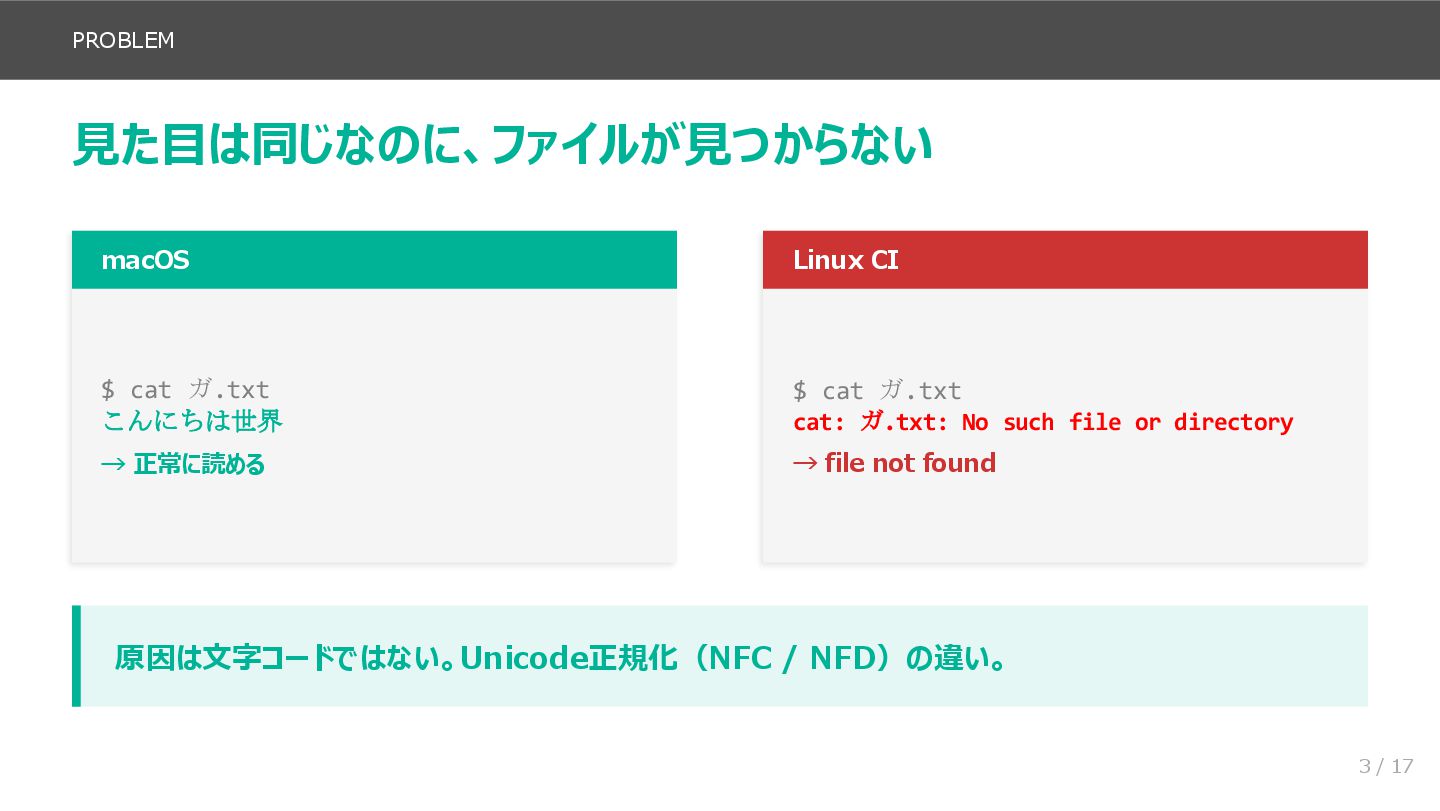
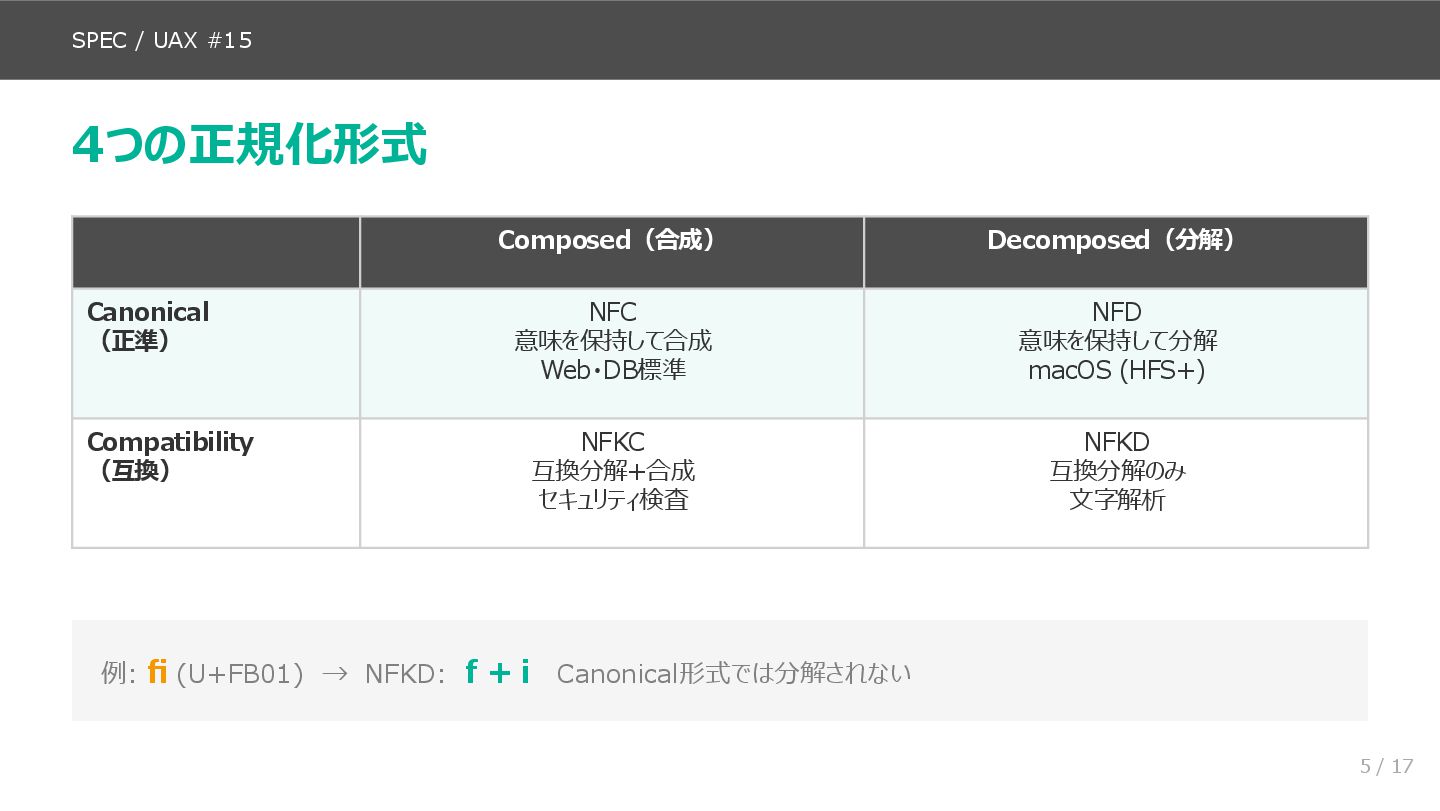
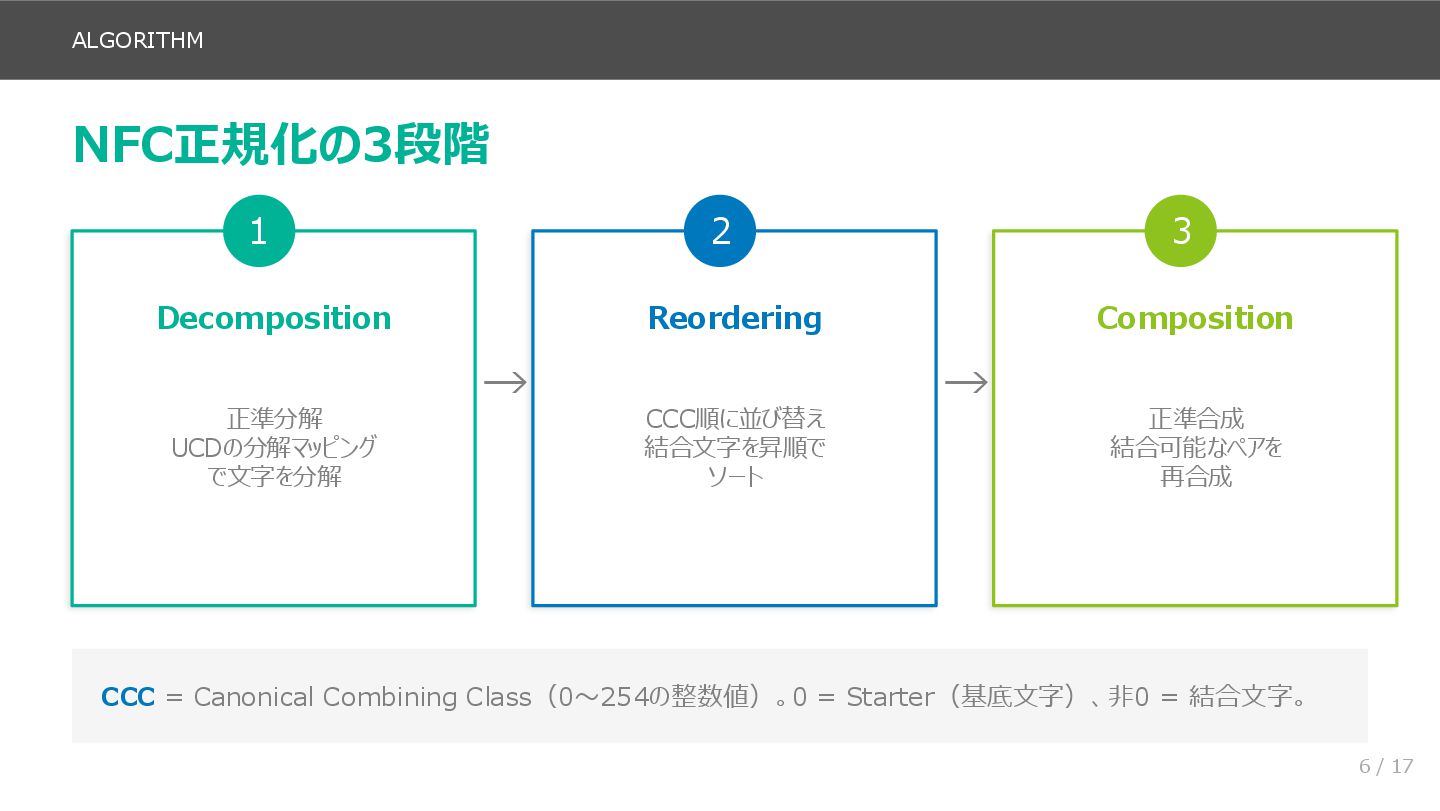
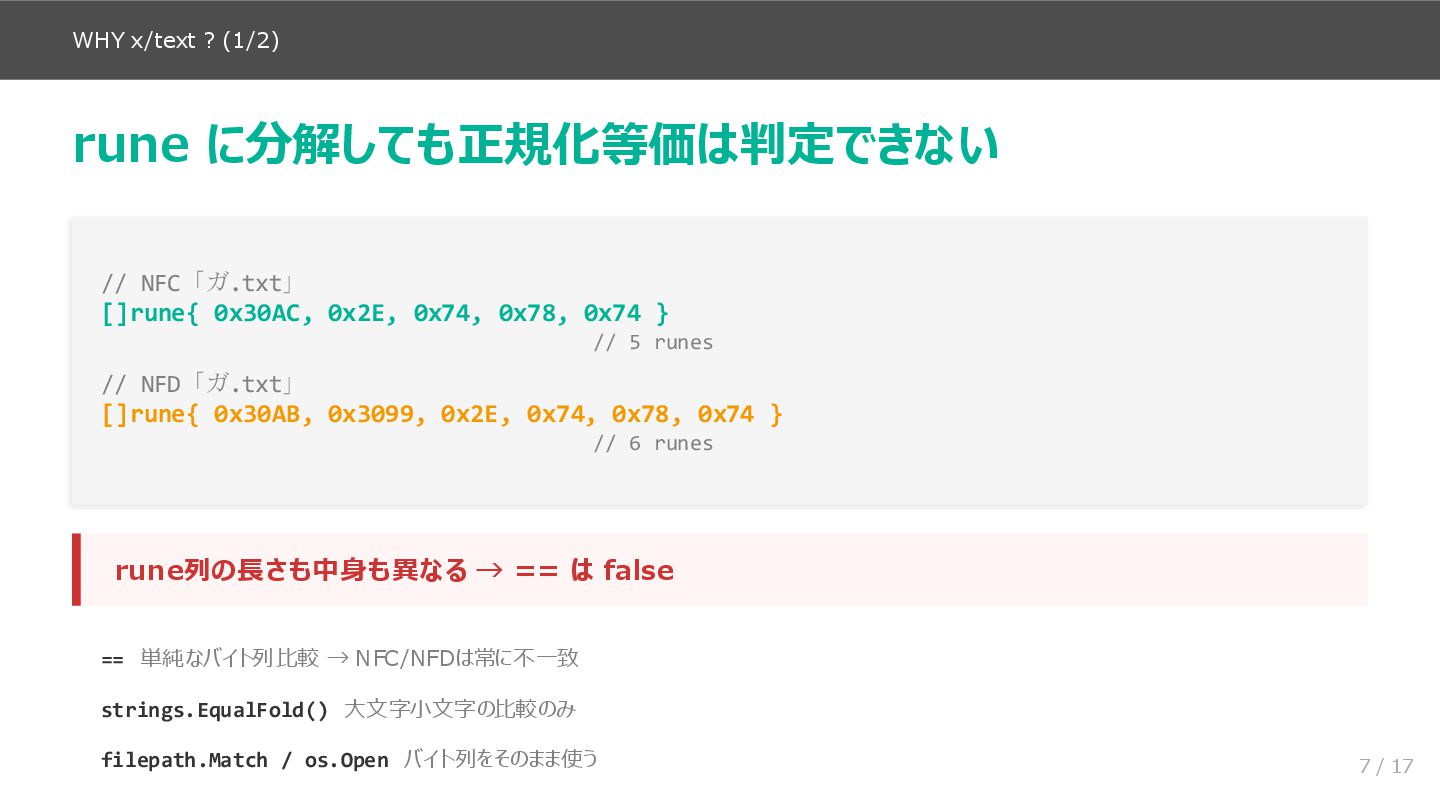
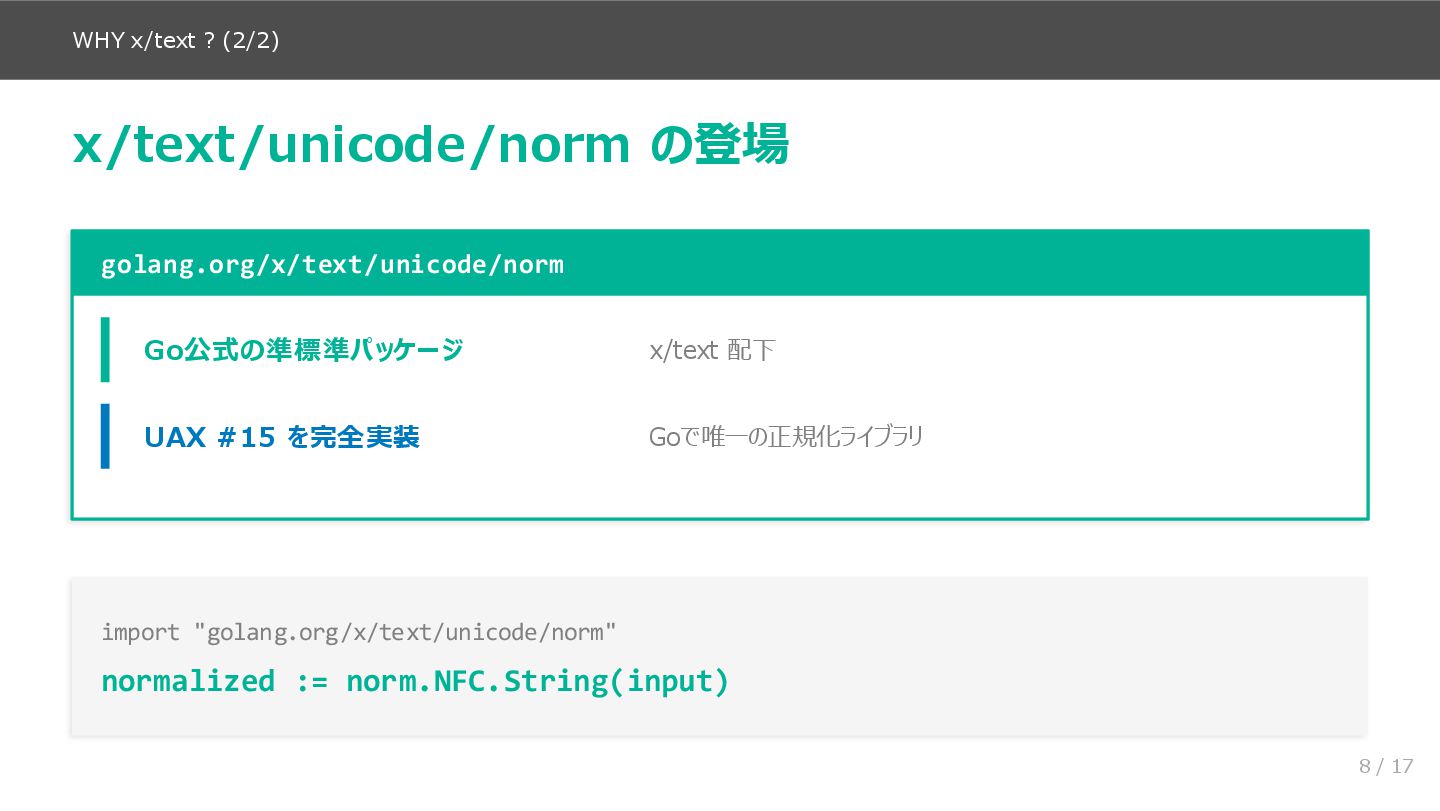
前半(スライド3〜8)では、問題の再現から原因の特定までを扱います。macOS と Linux で同じ cat ガ.txt を実行したときの挙動の違いから始まり、NFC/NFD の基本、UAX #15 の4つの正規化形式、NFC アルゴリズムの3段階を説明します。そのうえで、Go の標準ライブラリでは rune に分解しても正規化等価を判定できないことを具体例で示し、golang.org/x/text/unicode/norm パッケージの必要性につなげます。
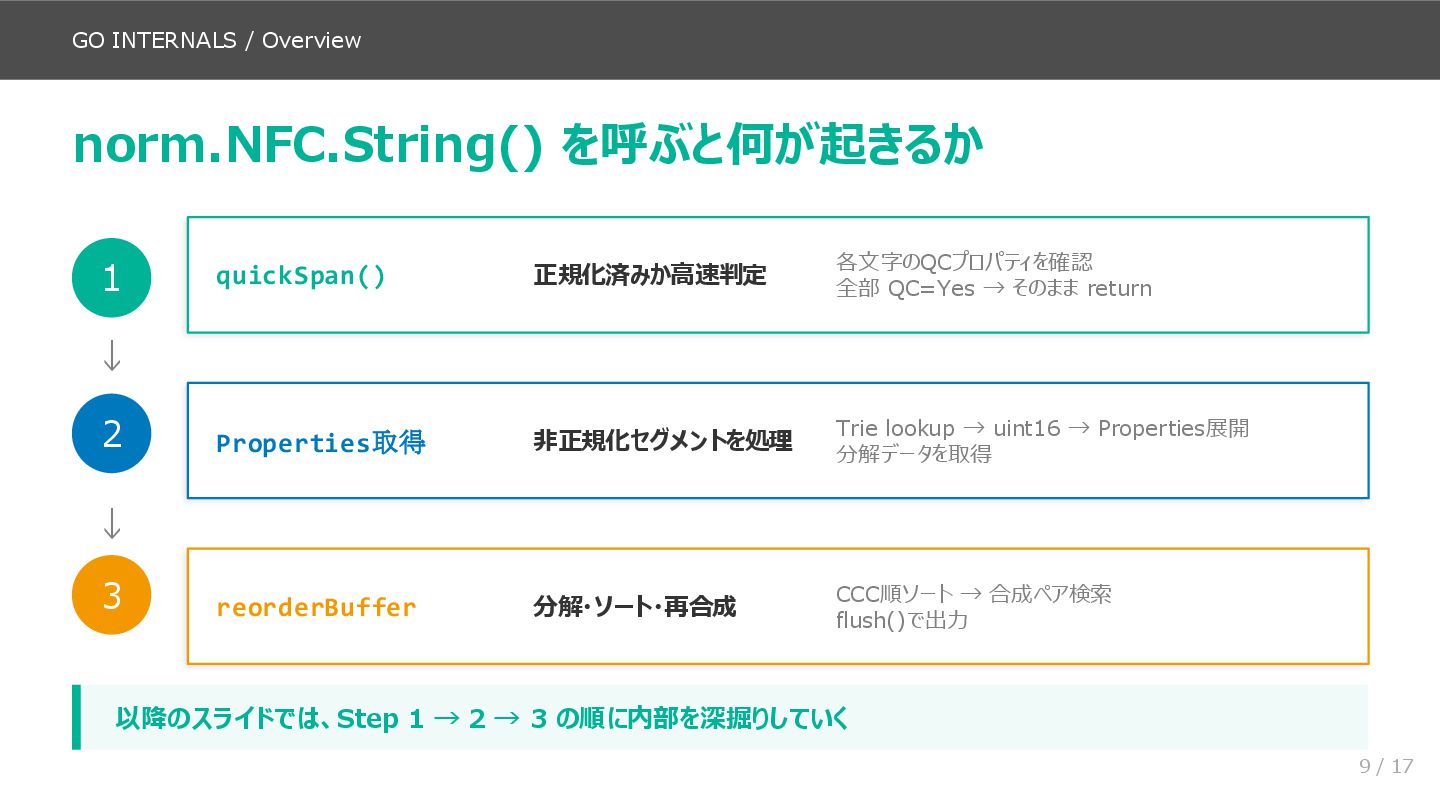
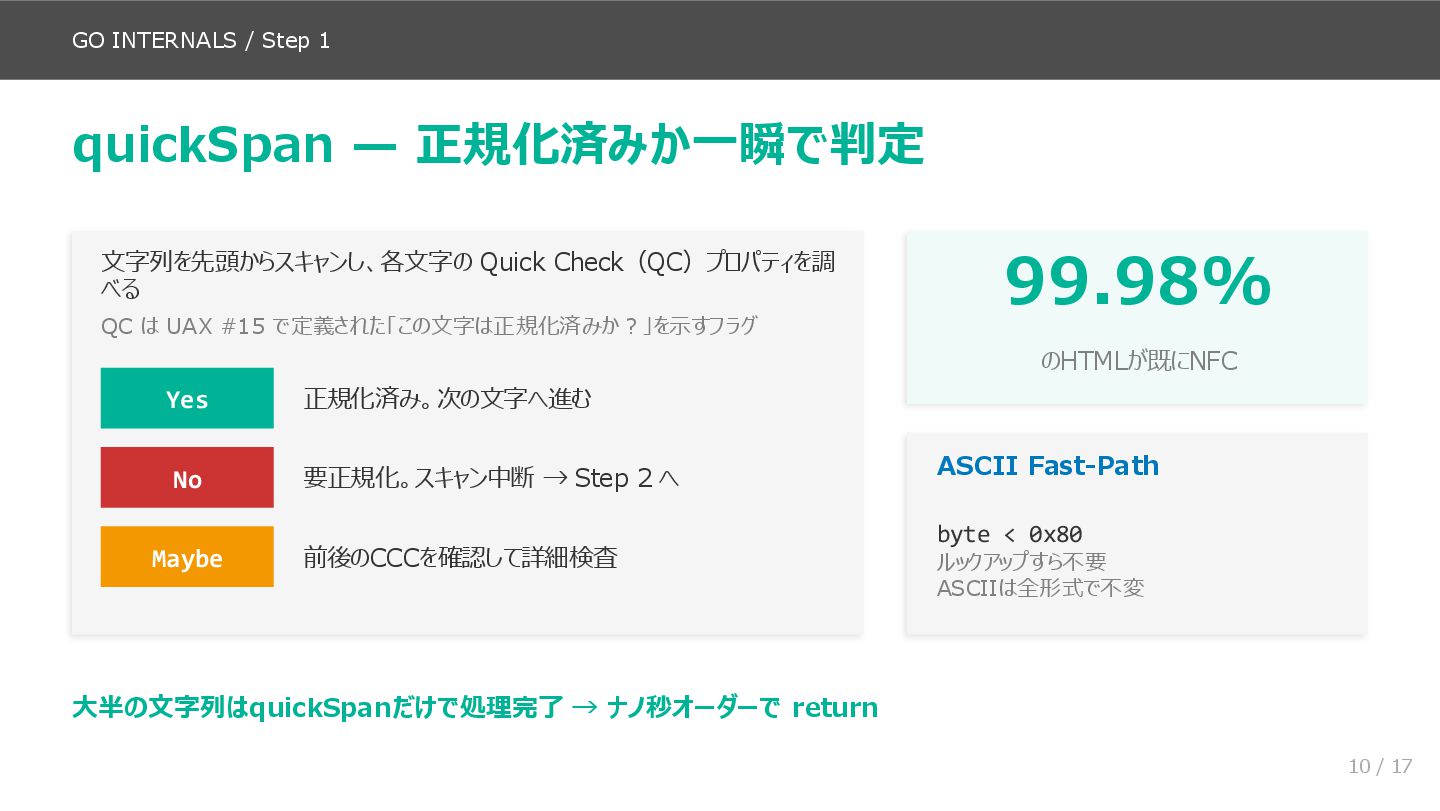
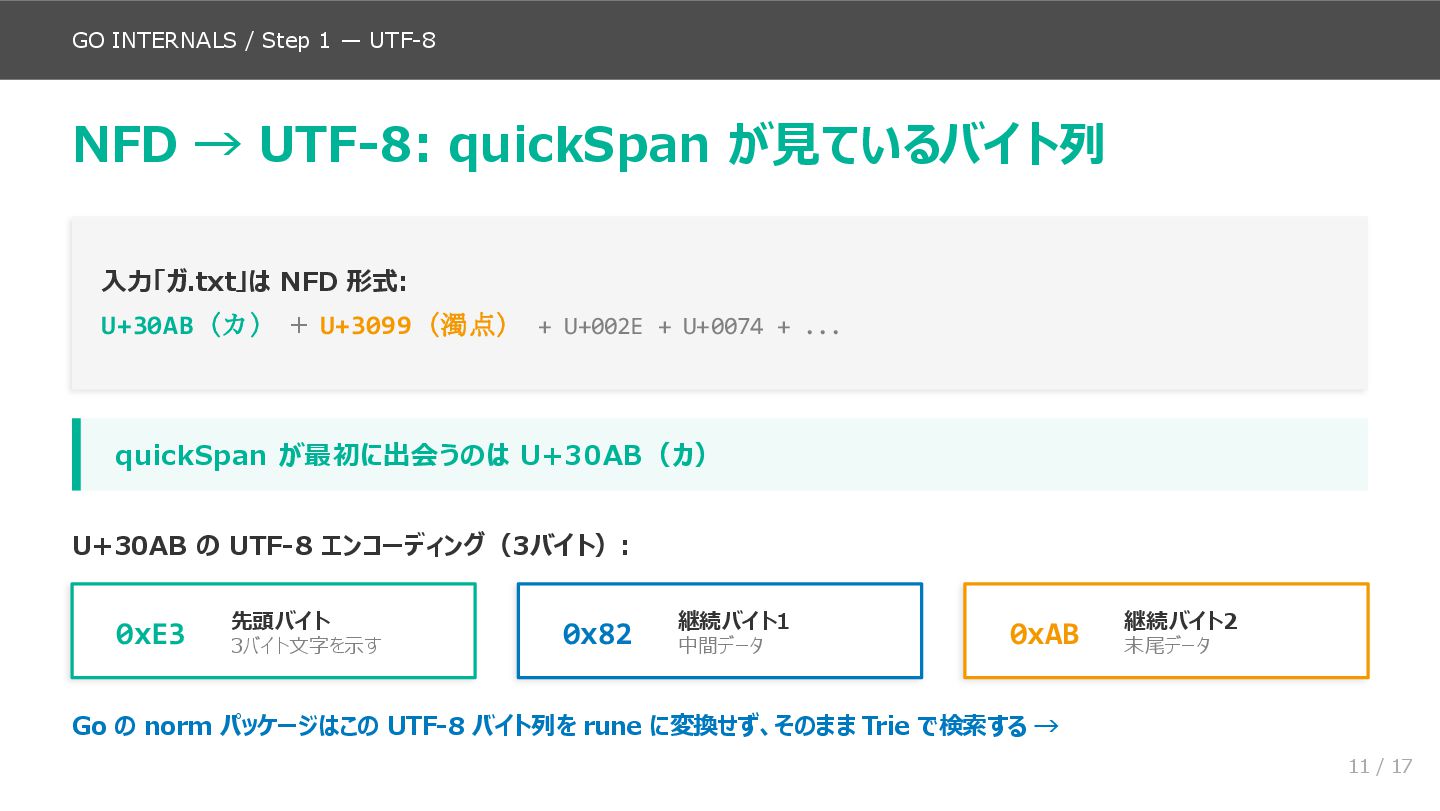
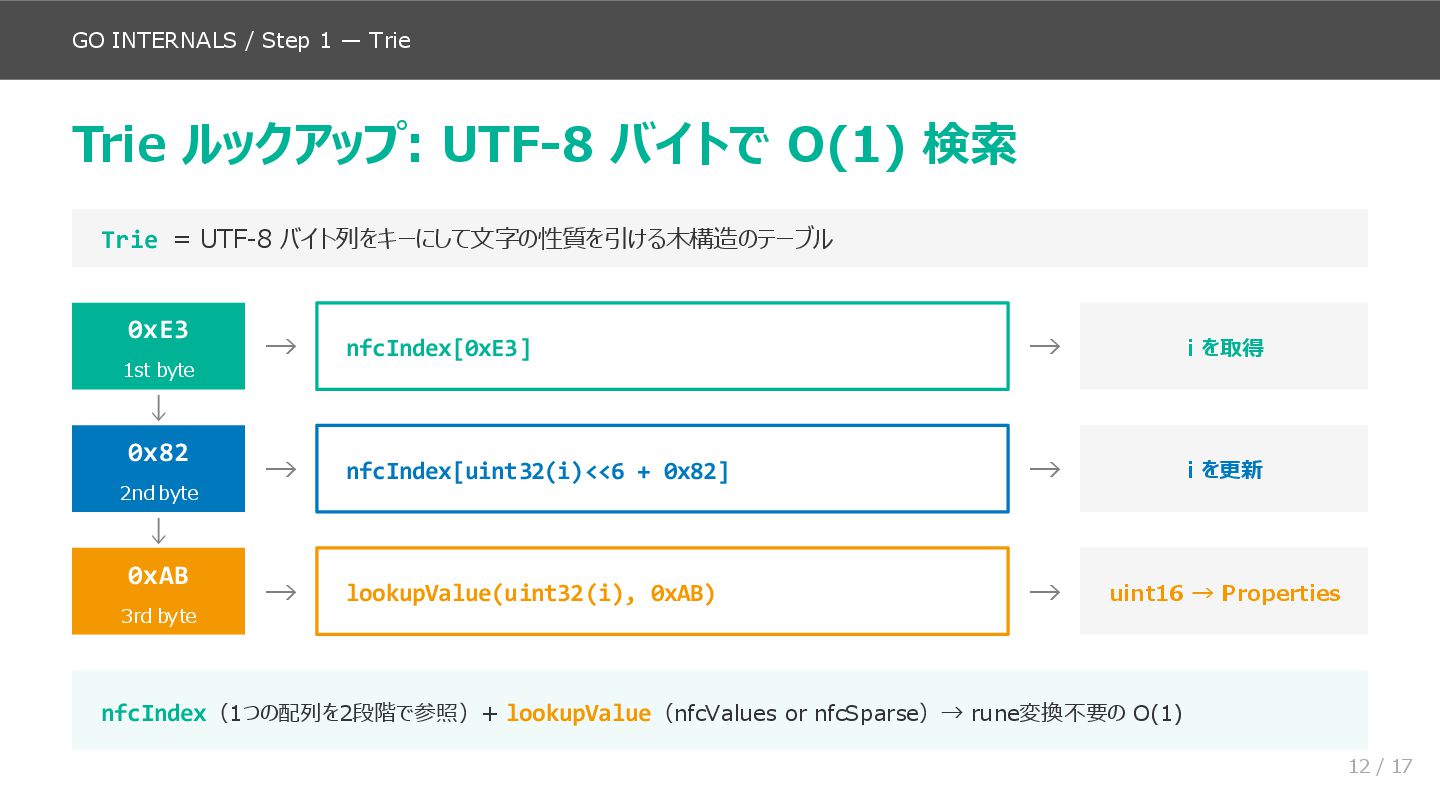
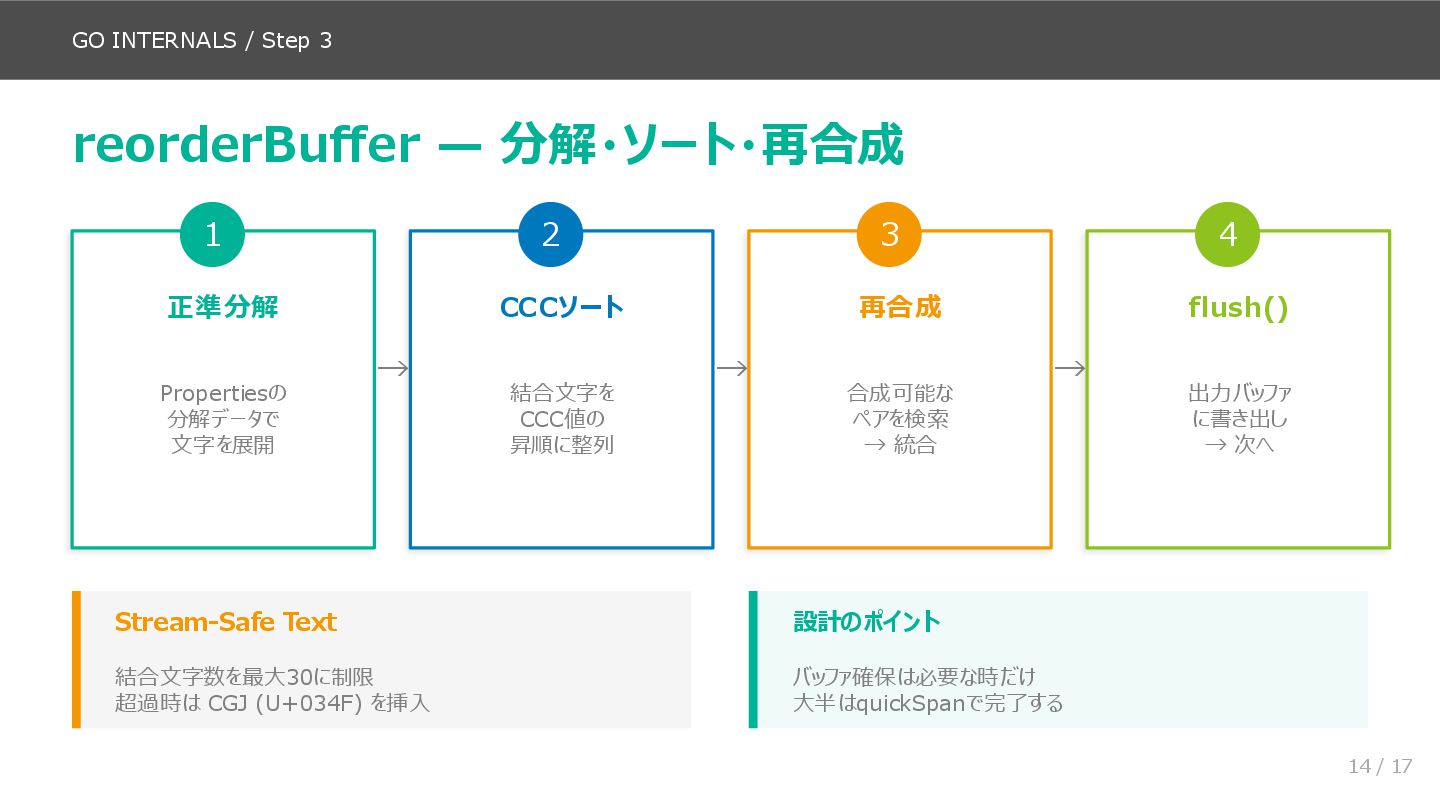
後半(スライド9〜14)が本資料の核心で、norm.NFC.String() の内部実装を処理フローに沿って追いかけます。quickSpan による Quick Check 判定、NFD 入力の UTF-8 バイト列構造、Trie ルックアップの仕組み(実際のコード名 nfcIndex / lookupValue を使用)、Properties 構造体への展開、reorderBuffer による分解・ソート・再合成という流れです。
終盤(スライド15〜17)では、macOS のファイルシステム(HFS+ / APFS)の正規化戦略、実務で遭遇する具体的な壊れパターンと対策をまとめ、「境界で NFC に統一する」という原則で締めくくります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}