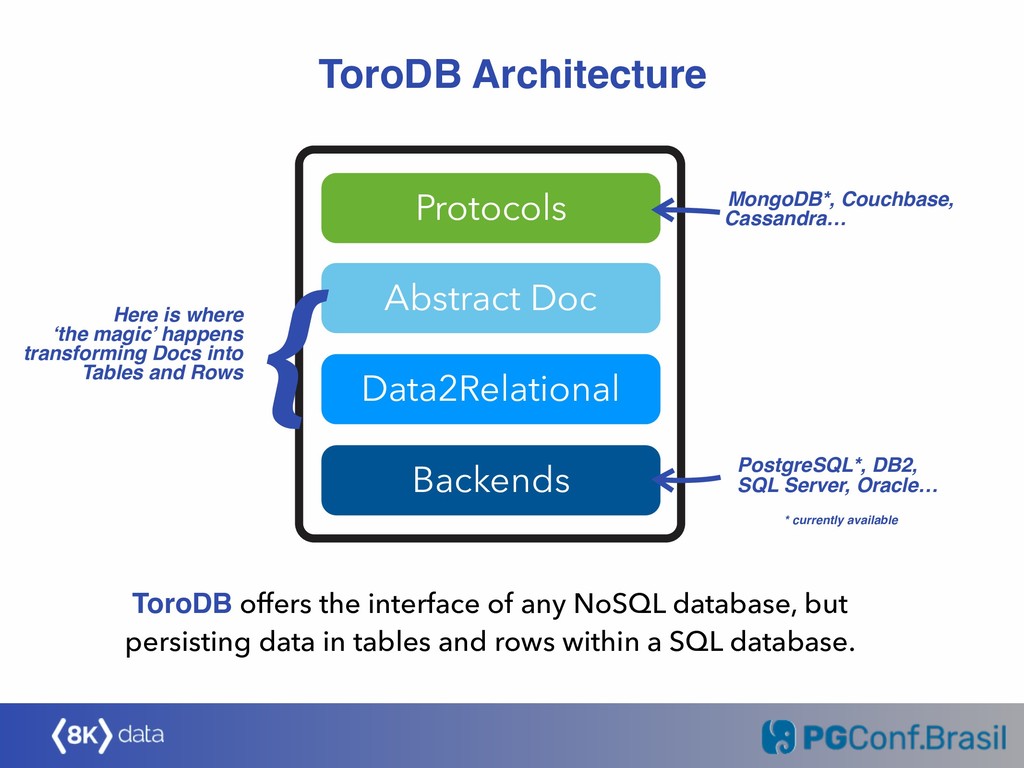
MongoDB is a successful database in the NoSQL space, mostly used for OLTP-type workloads. However, due to the lack of ACID (transactions in particular) and significant performance issues with OLAP/DW workloads, more and more MongoDB users are considering migrating off of MongoDB to a RDBMS, where PostgreSQL is the usual choice. This represents a significant opportunity for the PostgreSQL ecosystem, to "bring NoSQL to SQL". This talk presents the challenges that MongoDB users are facing and the state of the art of the available tools and open source solutions available to perform ETL and live migrations to PostgreSQL. In particular, ToroDB Stampede (https://www.torodb.com/stampede) will be discussed, an open source solution that replicates live from MongoDB, transform JSON documents into relational tables, and stores the data in PostgreSQL.
![Migrating off of MongoDB to PostgreSQL Álvaro Hernández Tortosa <[email protected]>](https://files.speakerdeck.com/presentations/c5b921f1c0be46a7a08d2b0c703fcd54/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
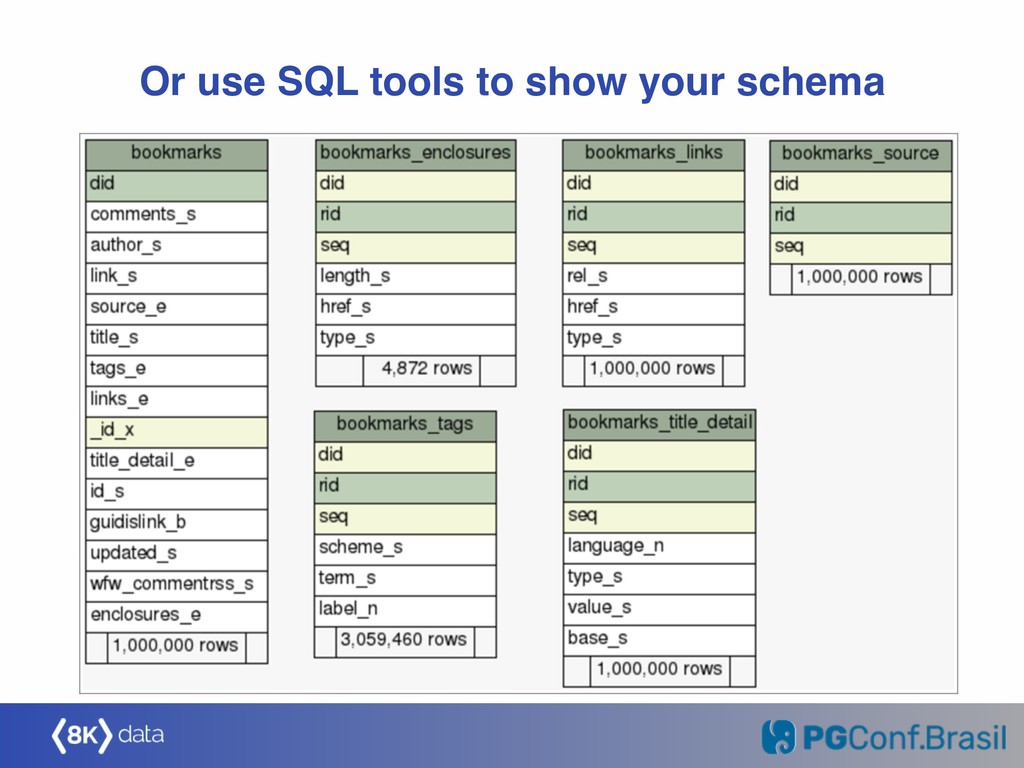{kind=link}
![Migrating off of MongoDB to PostgreSQL Let’s Talk! www.8kdata.com [email protected]](https://files.speakerdeck.com/presentations/c5b921f1c0be46a7a08d2b0c703fcd54/slide_46.jpg){kind=link}