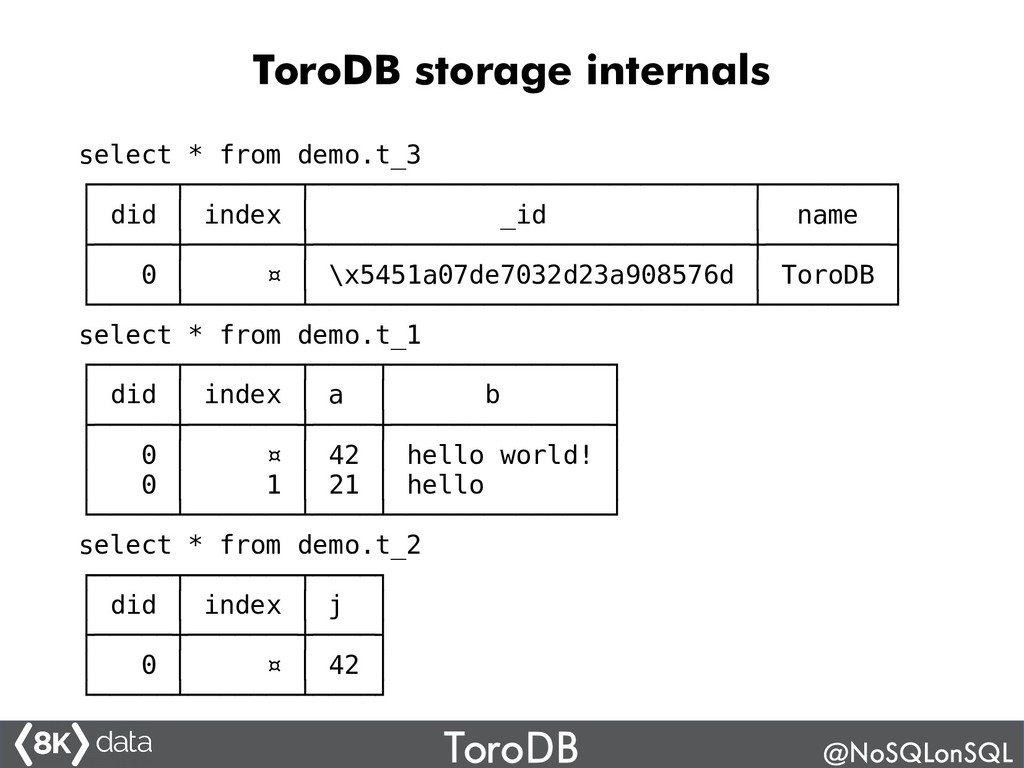
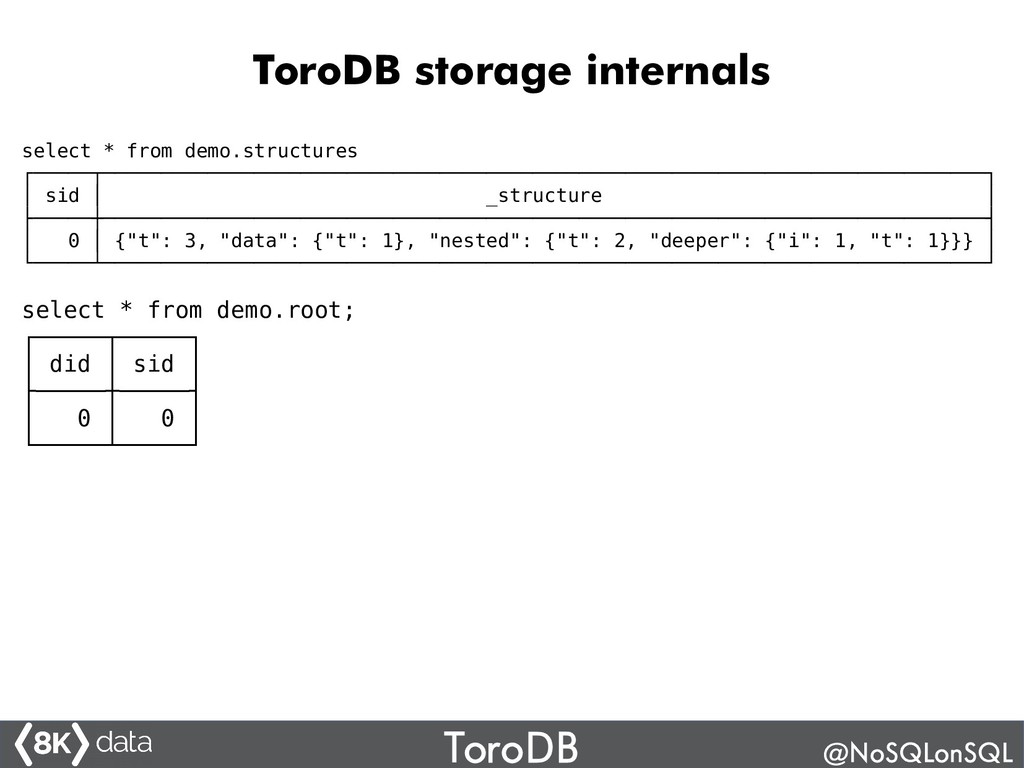
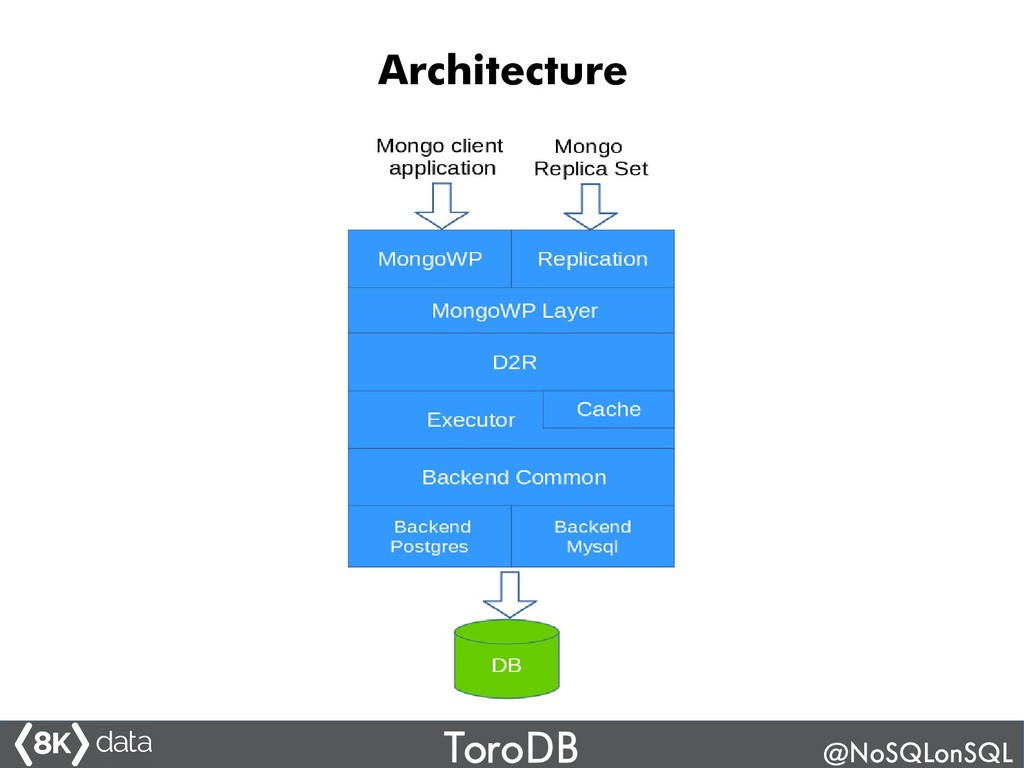
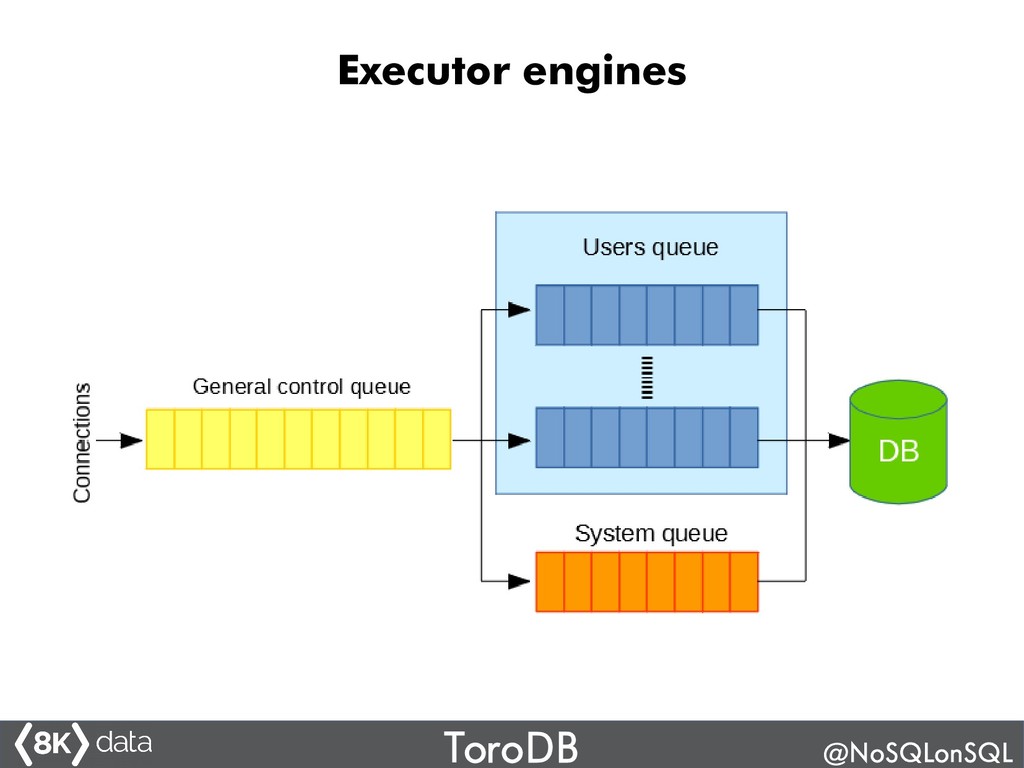
ToroDB is an exciting, new 100% open-source Java database system based on PostgreSQL that is 100% compatible with the MongoDB protocol (API and tools) and provides orders of magnitude higher analytics performance (up to 100x). It has a novel architecture that allows it to work with PostgreSQL, DB2, Oracle, Greenplum another back-ends. You can replicate data from a (noSQL) MongoDB cluster and perform analytics using SQL. Join this talk to understand how ToroDB works, what advantages it may bring to your Big Data architecture, and how to hack ToroDB's Java open source code.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}