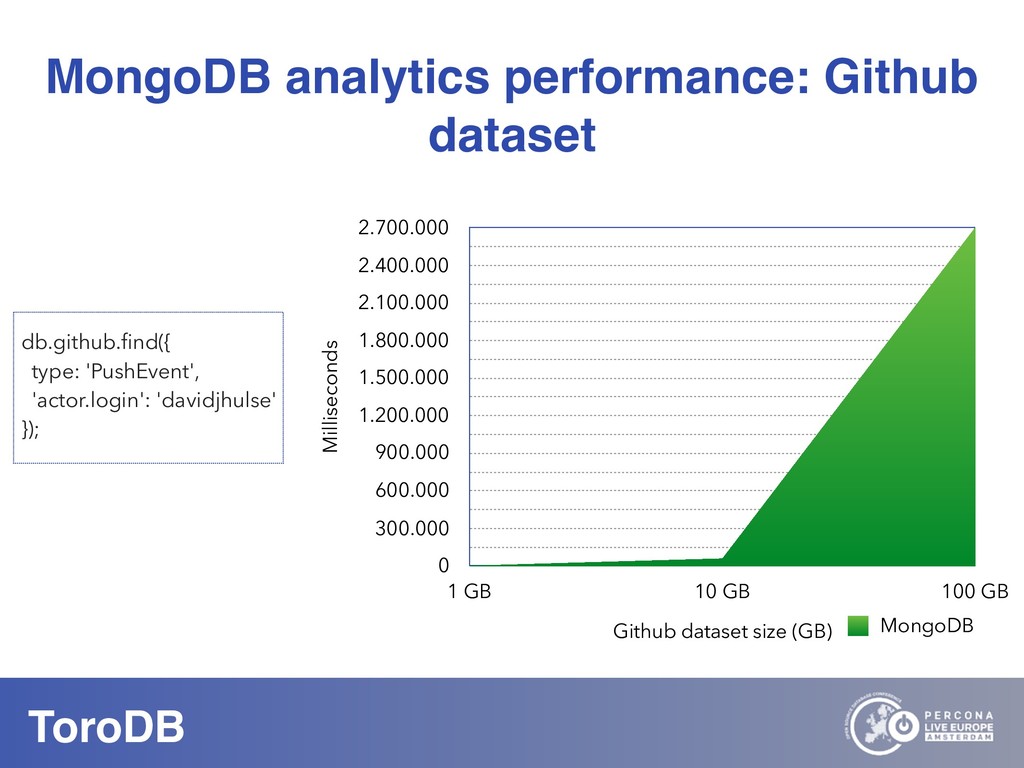
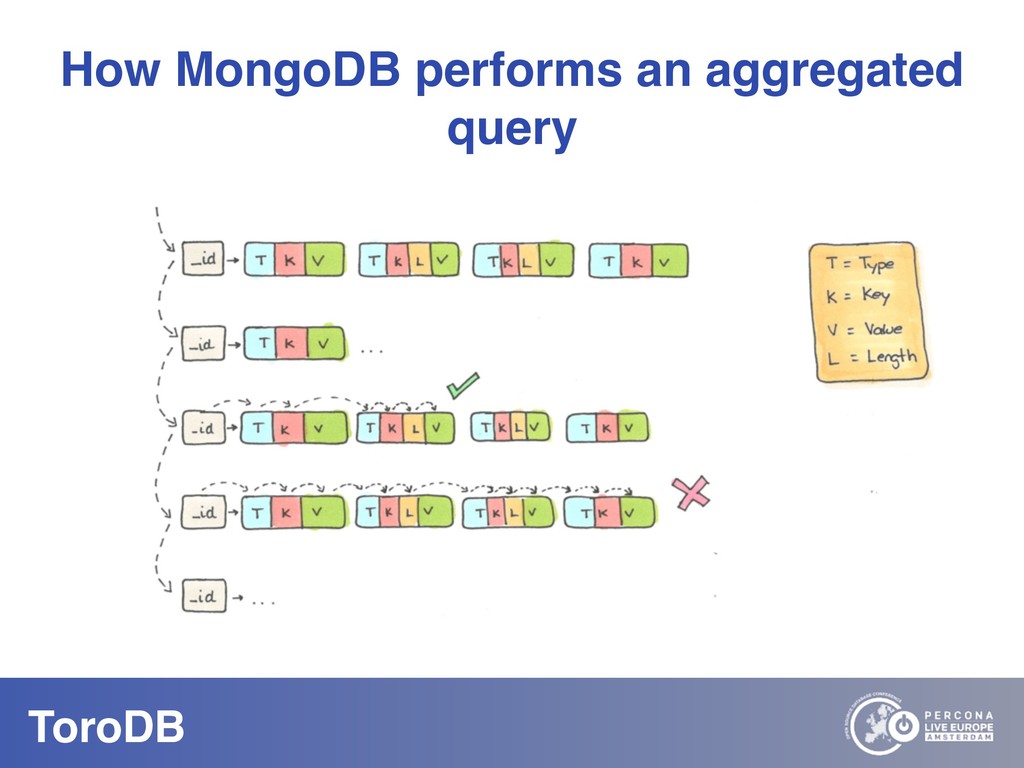
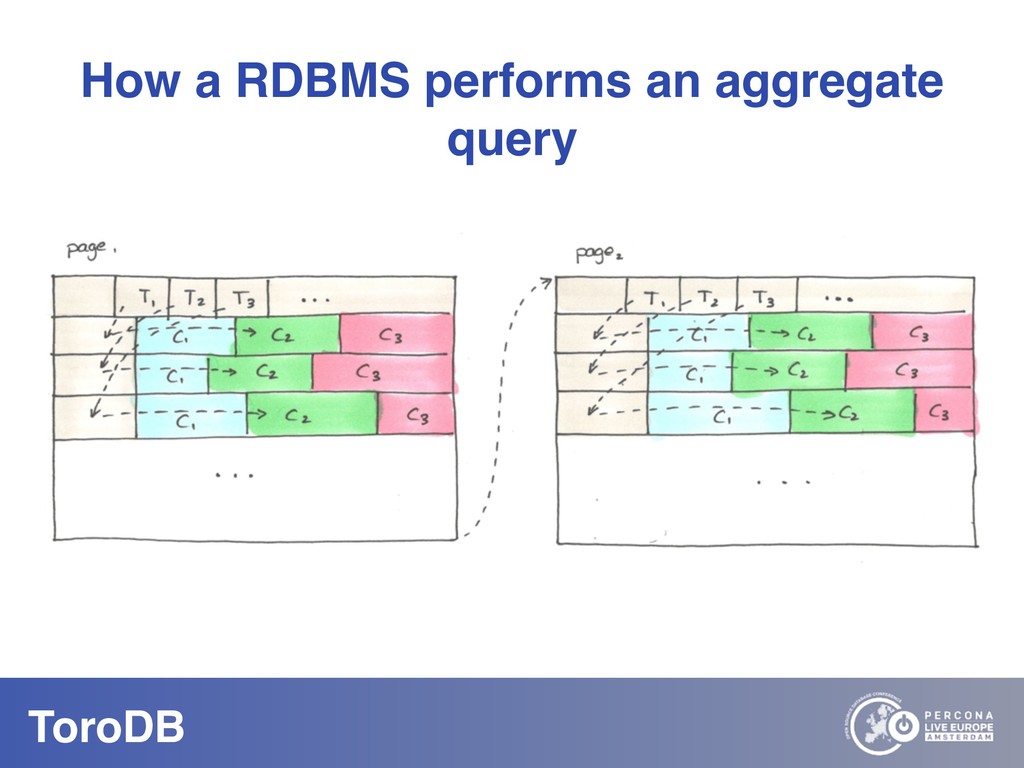
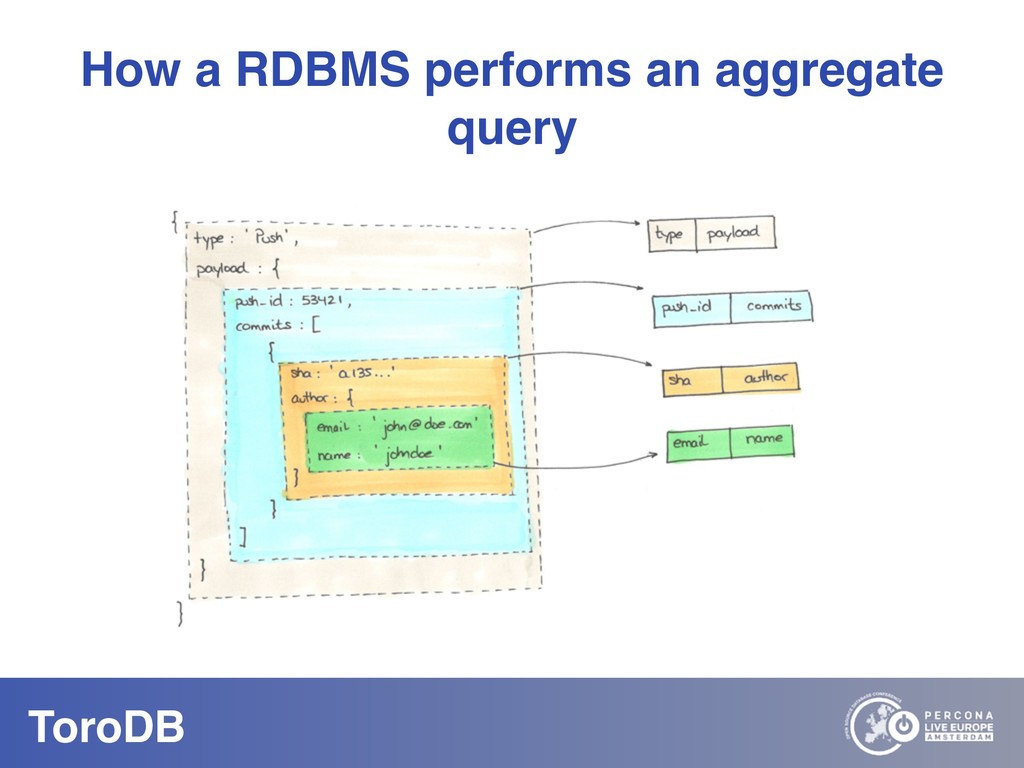
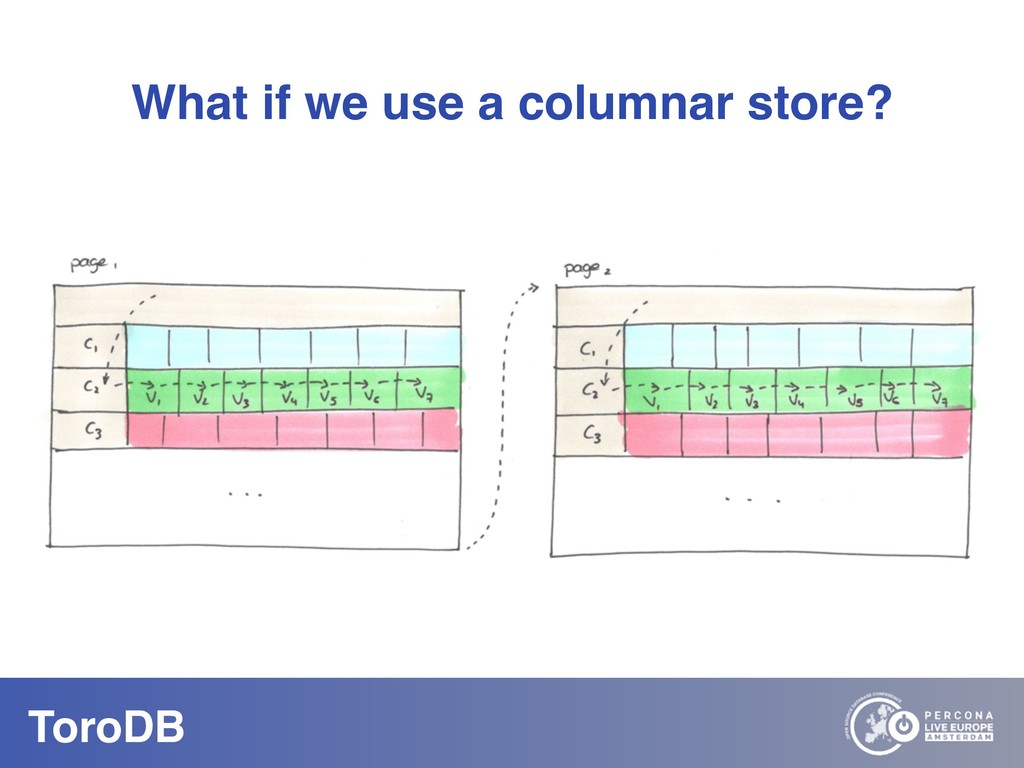
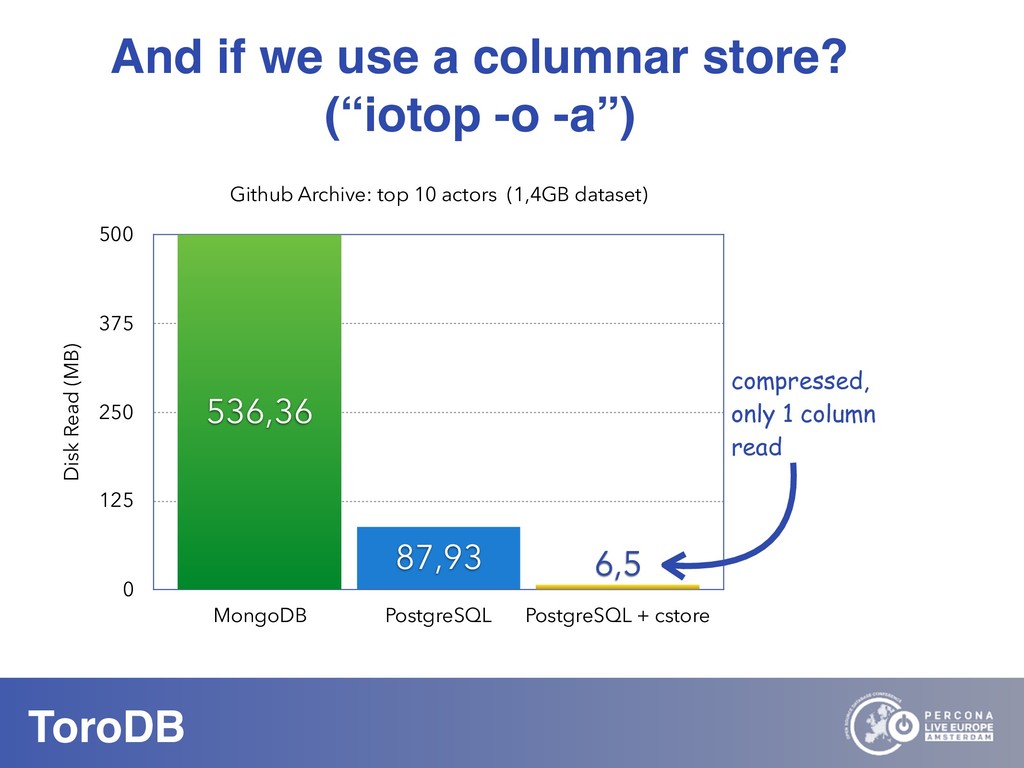
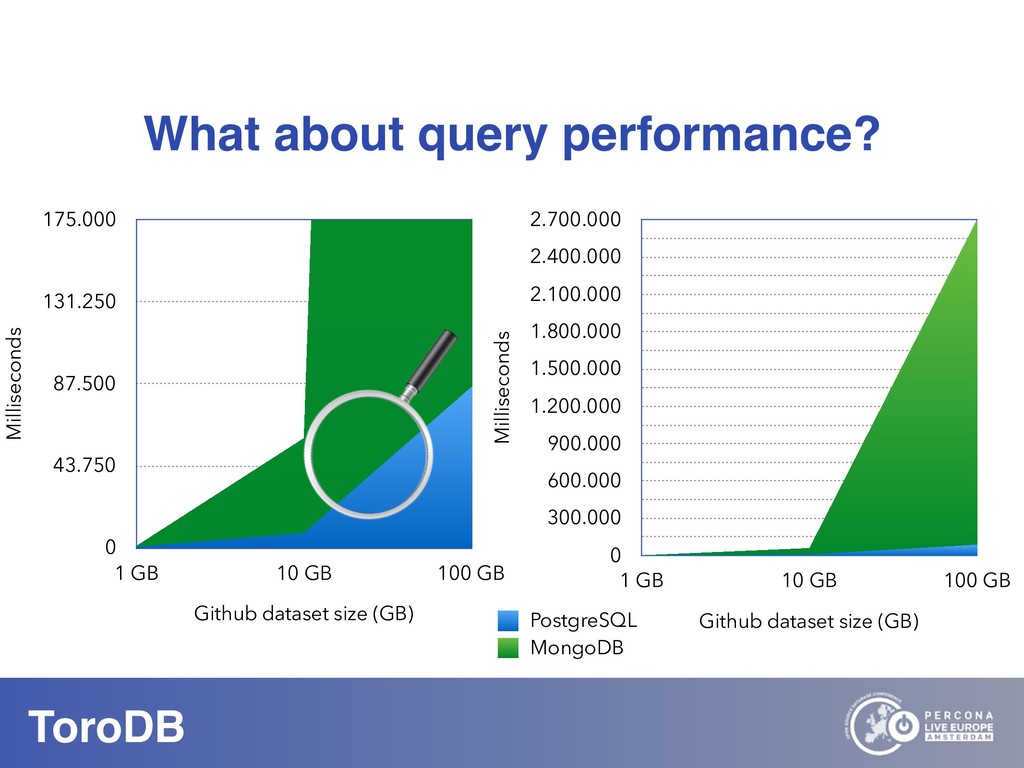
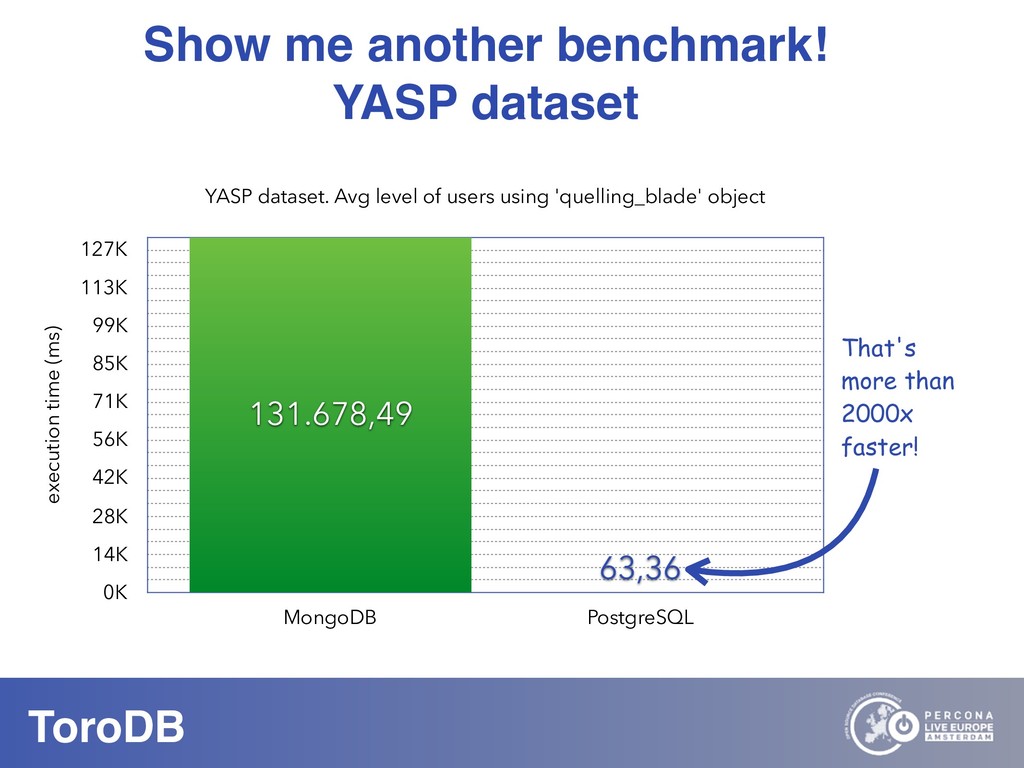
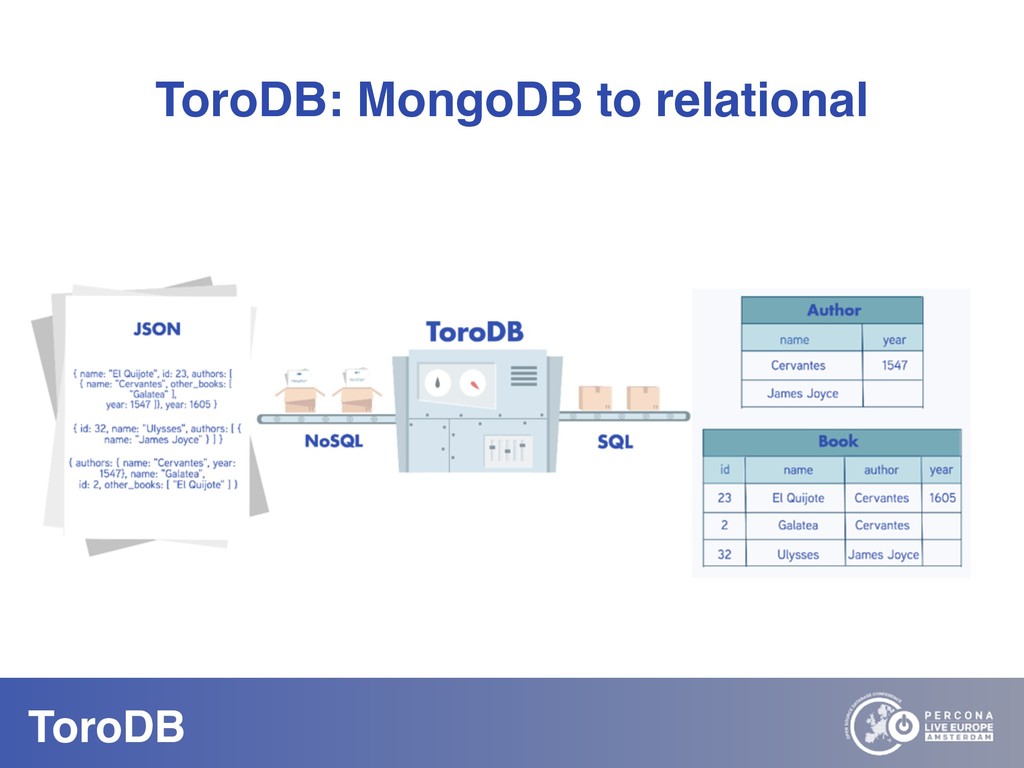
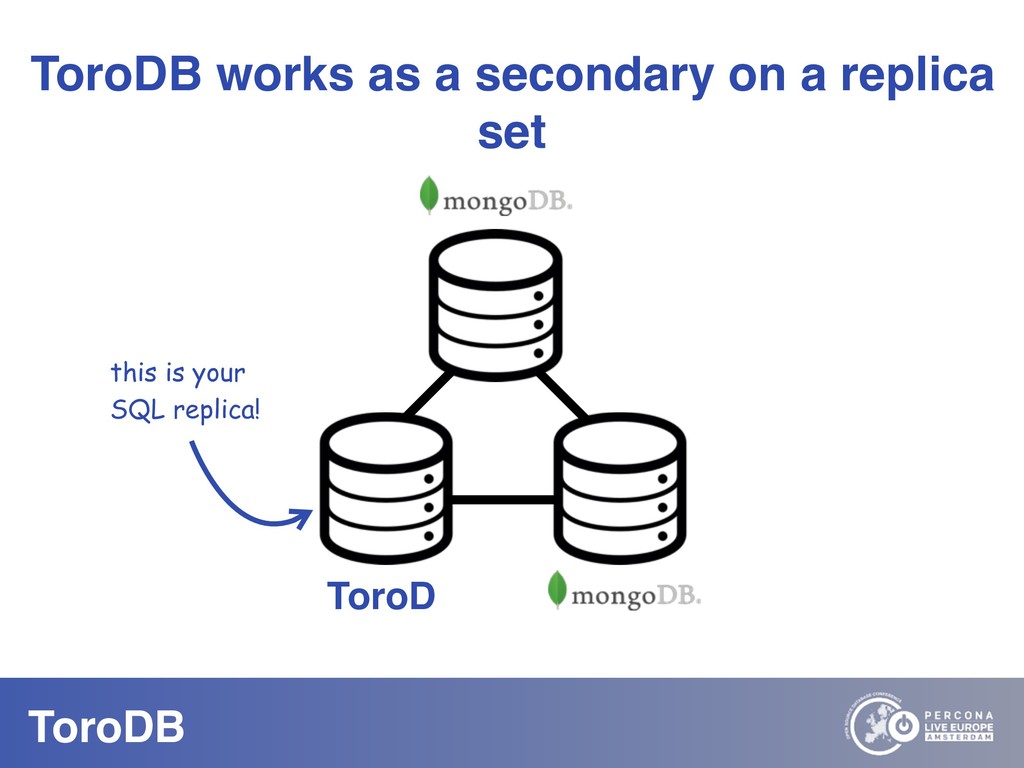
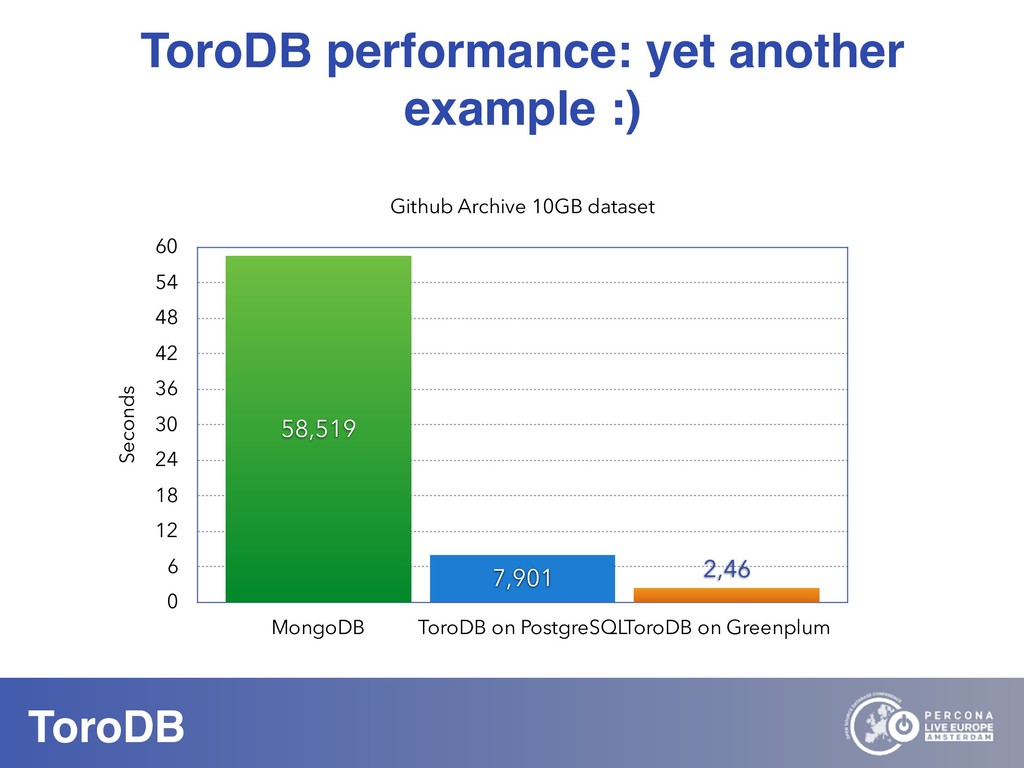
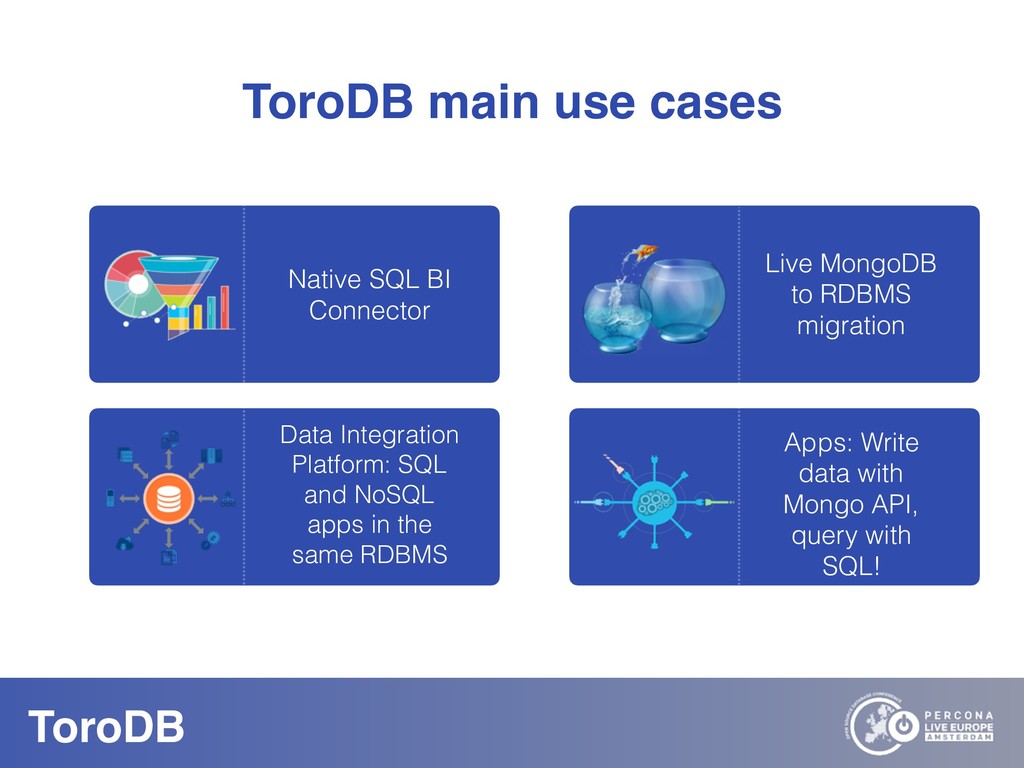
What if you could seamlessly replicate all your MongoDB data to a native SQL database? With NoSQL you can scale out, you don’t need to pre-define your schema, and it maps naturally to the OO world. But how do you perform data discovery? How do you interact with the vast SQL ecosystem, specially the BI tools? How do your SQL-savvy users do without SQL? The answer to most of these questions is usually not a very convincing one. But there are good news: you can bring all your MongoDB data to the SQL world. With ToroDB, an open-source database that participates in a MongoDB cluster. ToroDB acts as a hidden secondary node and replicates in real-time your MongoDB data to a native, SQL database such as PostgreSQL. The process does not involve defining any schema or creating any definition files: ToroDB creates everything needed to represent your MongoDB data as relational tables. Now you can leverage all the SQL ecosystem with your MongoDB data, be it for data migration, connecting to BI connectors, using native SQL tools or simply querying with the powerful SQL language.And using native SQL sharded databases like Greenplum and columnar storage, your aggregate queries, compared to MongoDB’s sharding and aggregation, run up to 100x faster!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}