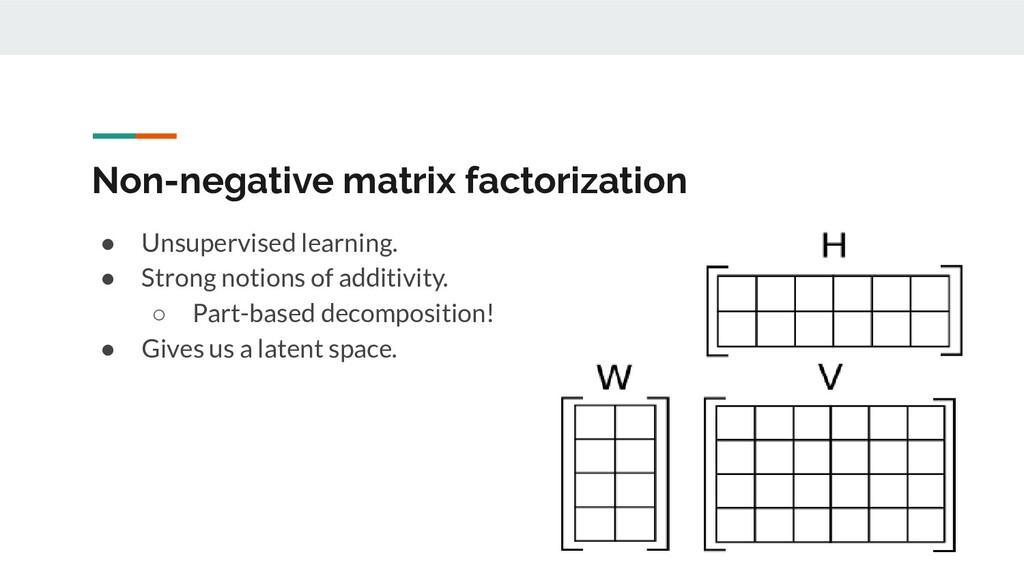
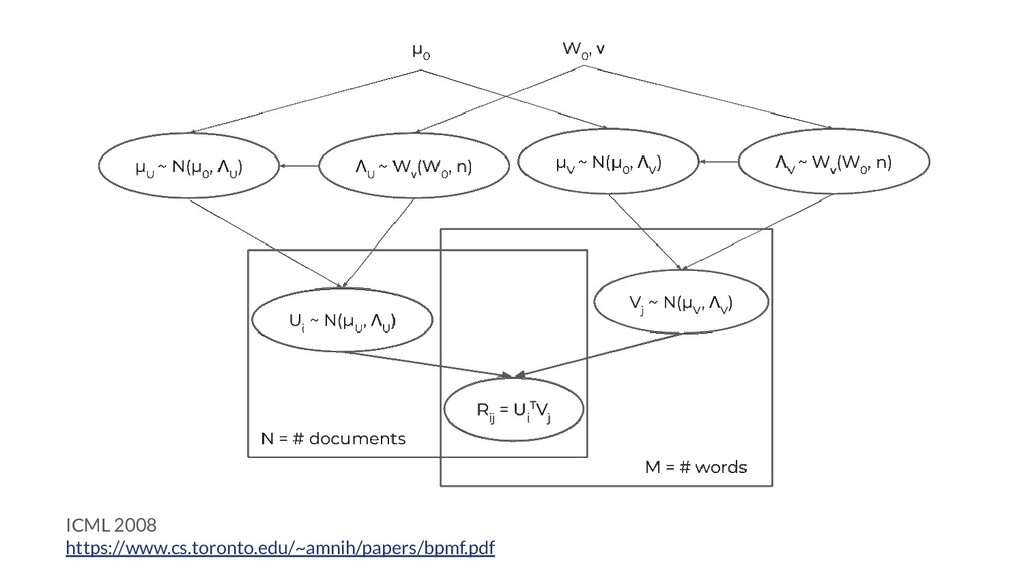
Most of the work in matrix factorization techniques focus on dimensionality reduction: that is, the problem of finding two factor matrices that faithfully reconstruct the original matrix when multiplied together. However, I was interested in applying the exact same techniques to a separate task: text clustering.
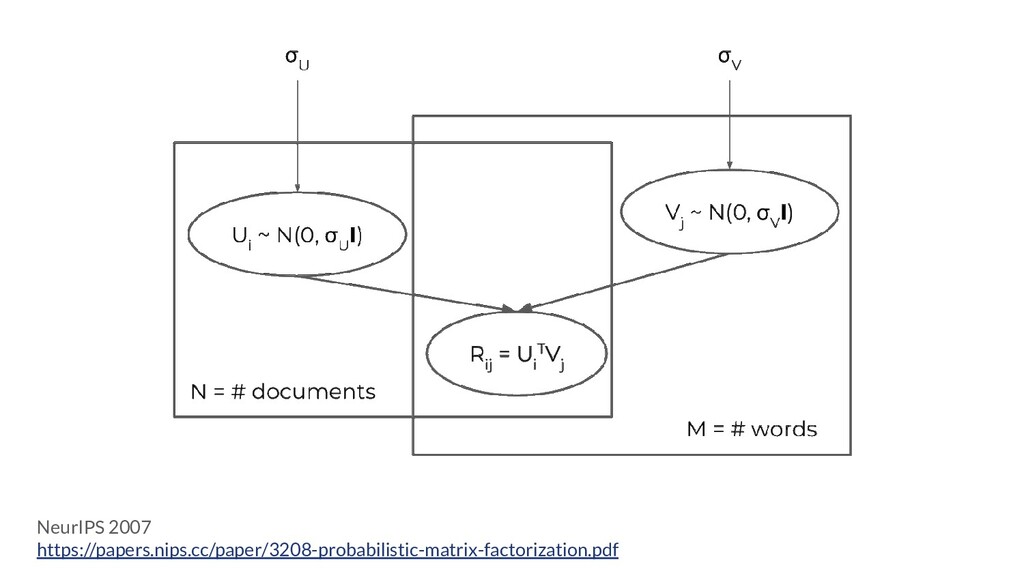
A natural question is: why is matrix factorization a good technique to use for text clustering? Because it is simultaneously a clustering and a feature engineering technique: not only does it offer us a latent representation of the original data, but it also gives us a way to easily reconstruct the original data from the latent variables! This is something that latent Dirichlet allocation, for instance, cannot do.
I experimented with using these techniques to cluster subreddits. In a nutshell, nothing seemed to work out very well, and I opine on why I think that’s the case in this slide deck. This talk was delivered to a graduate-level course in frequentist machine learning.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}