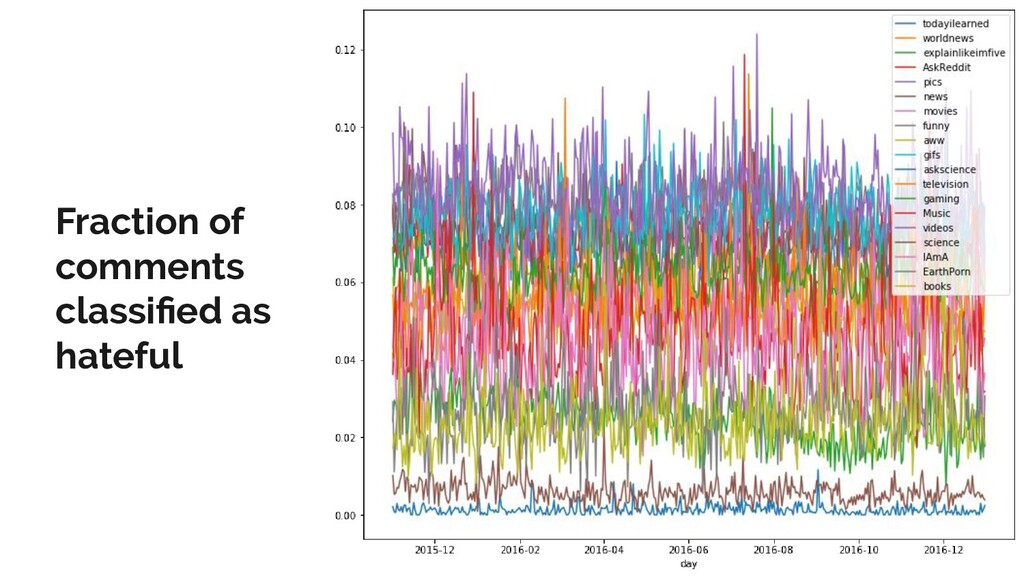
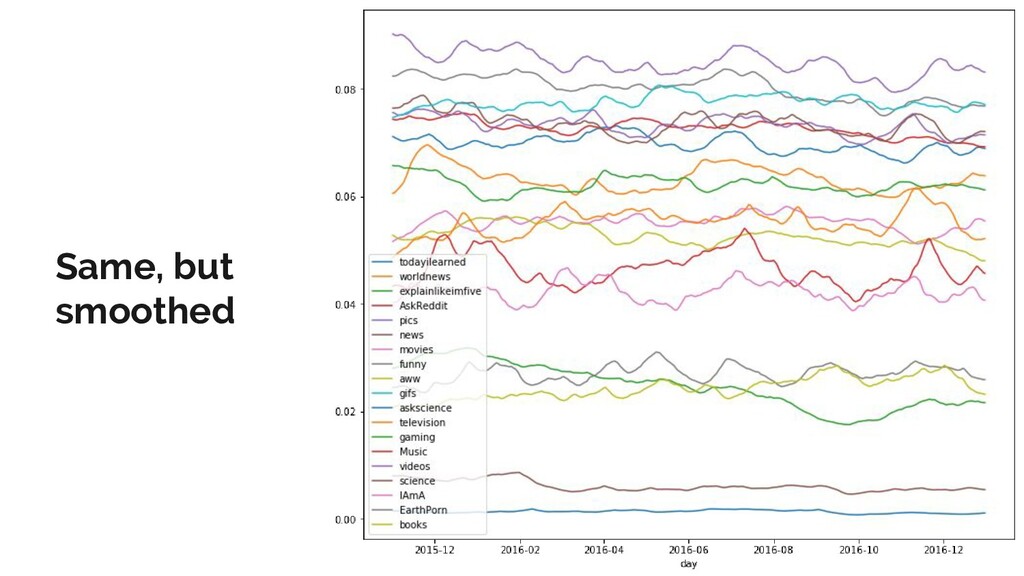
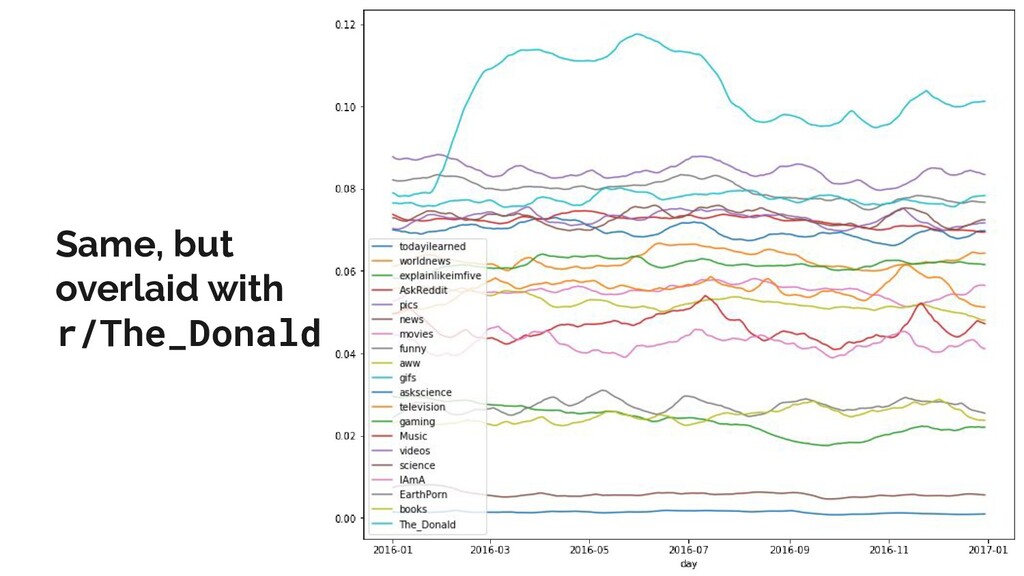
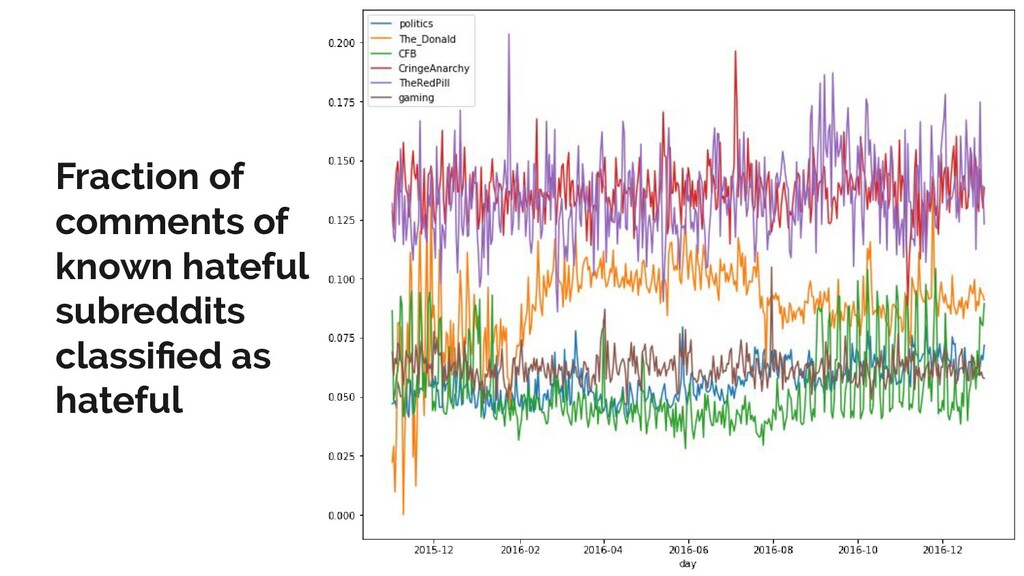
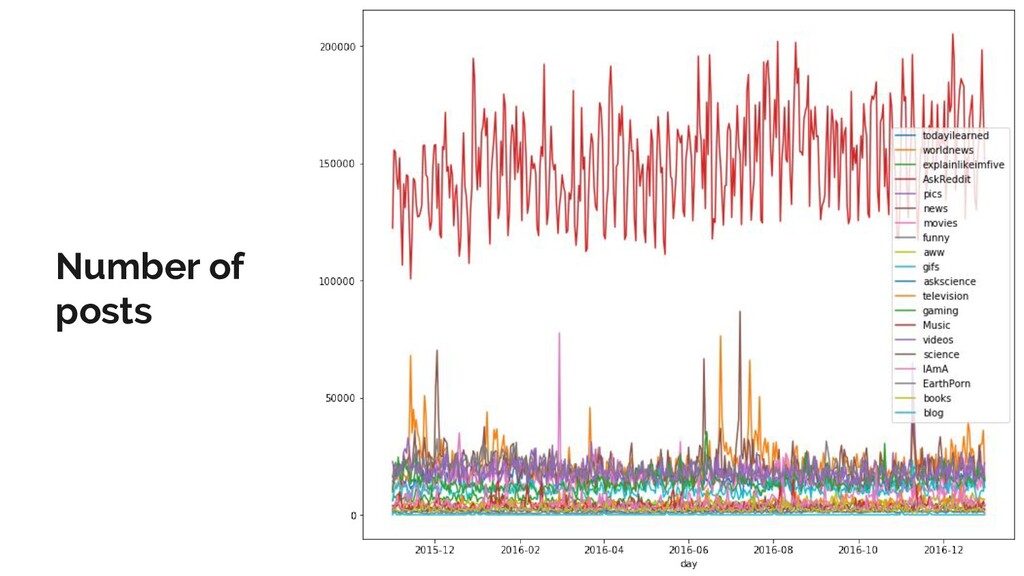
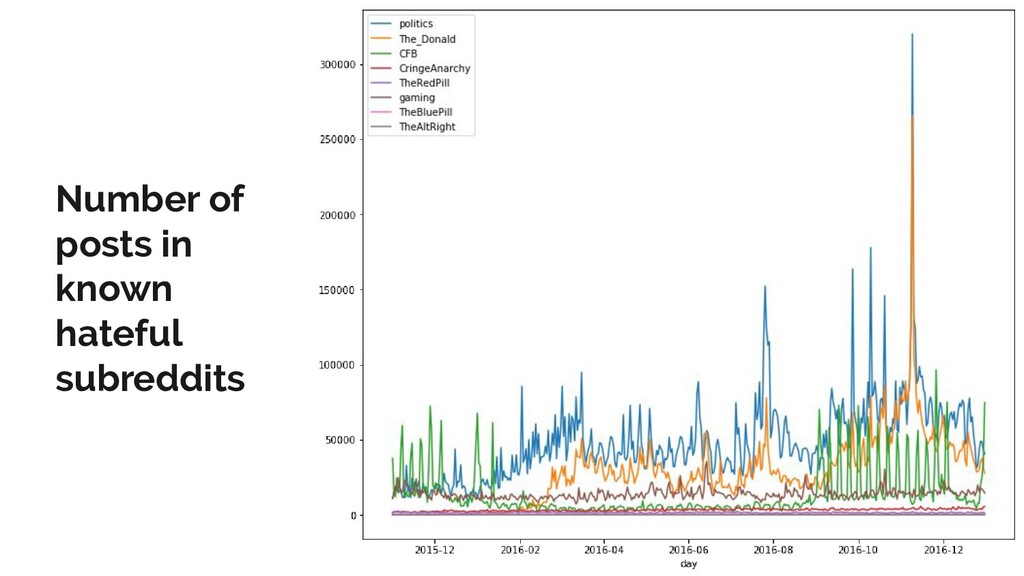
Reddit is the one of the most popular discussion websites today, and is famously broad-minded in what it allows to be said on its forums: however, where there is free speech, there are invariably pockets of hate speech.
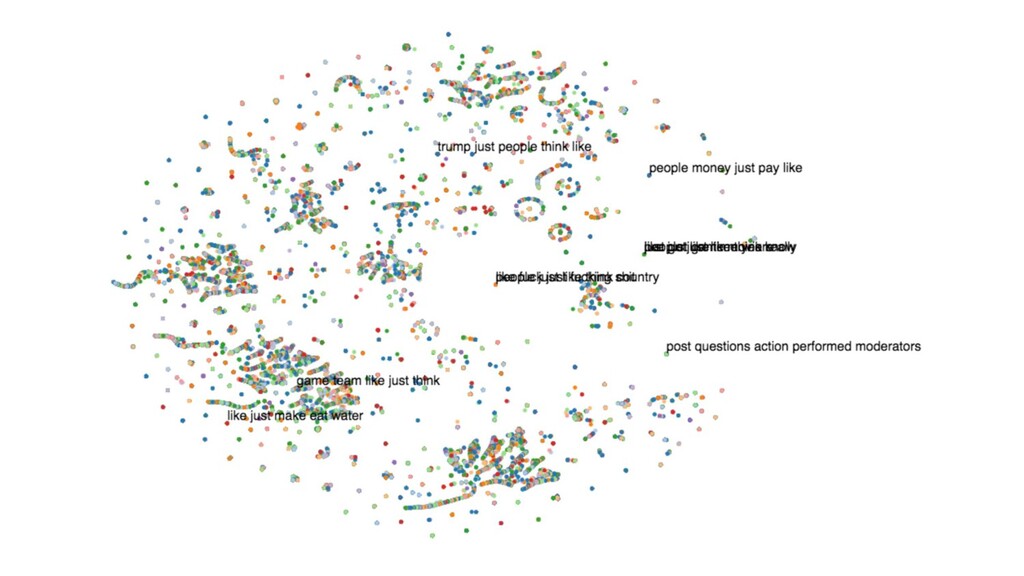
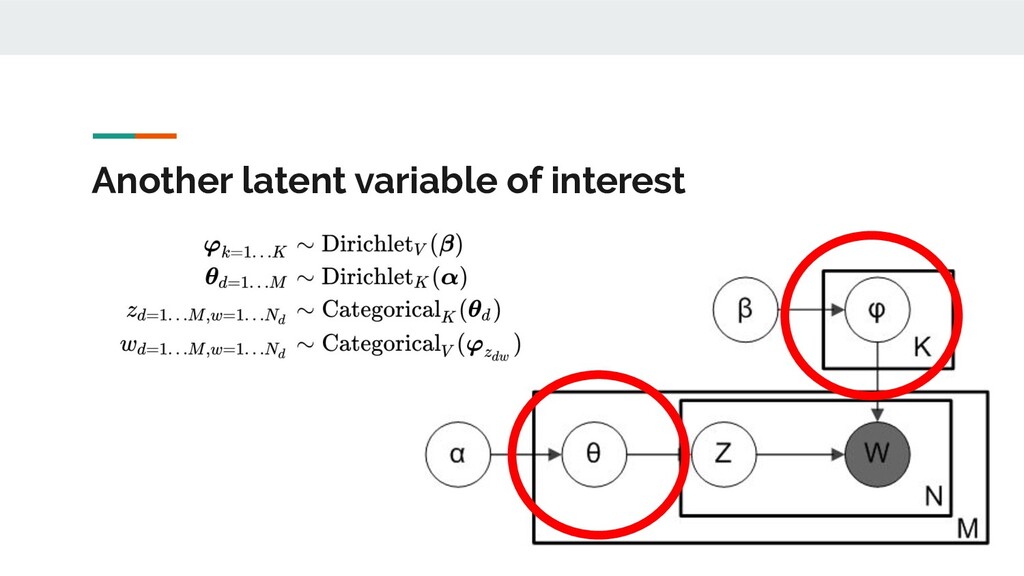
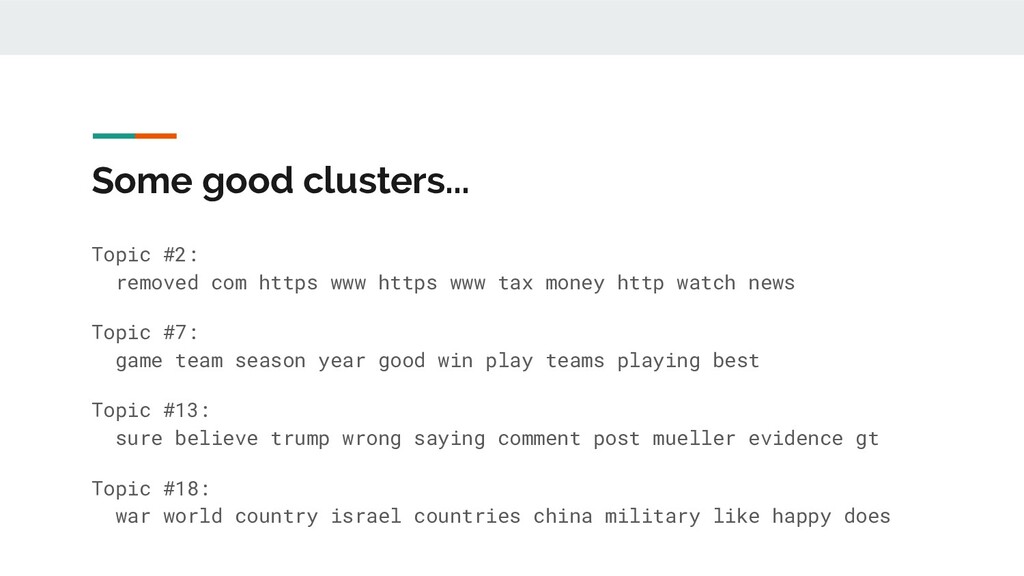
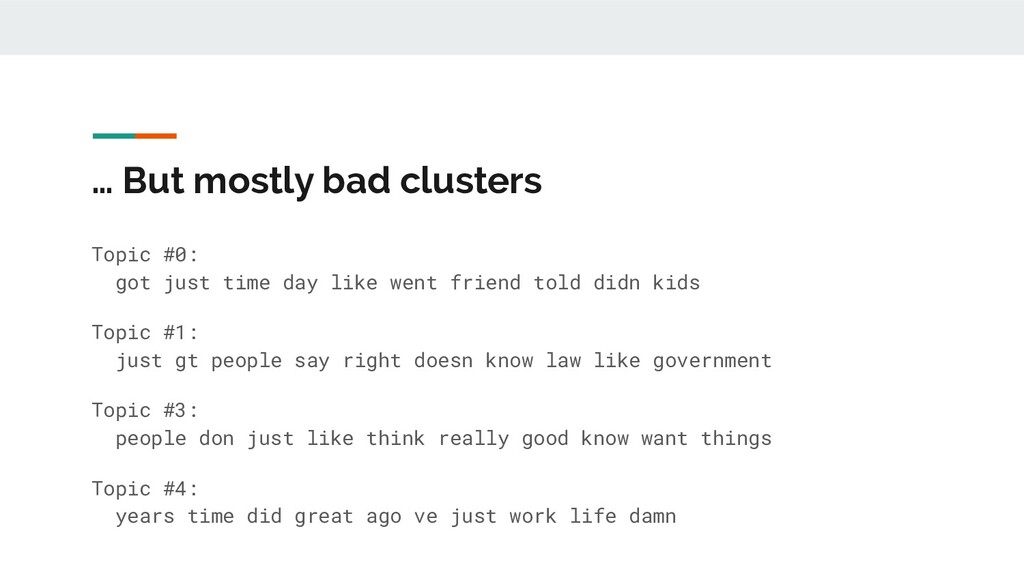
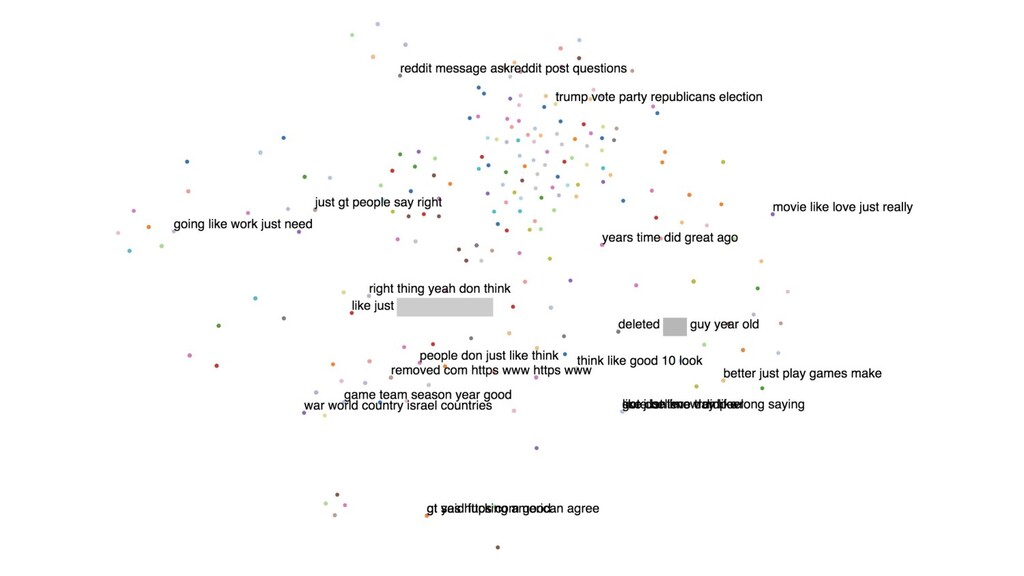
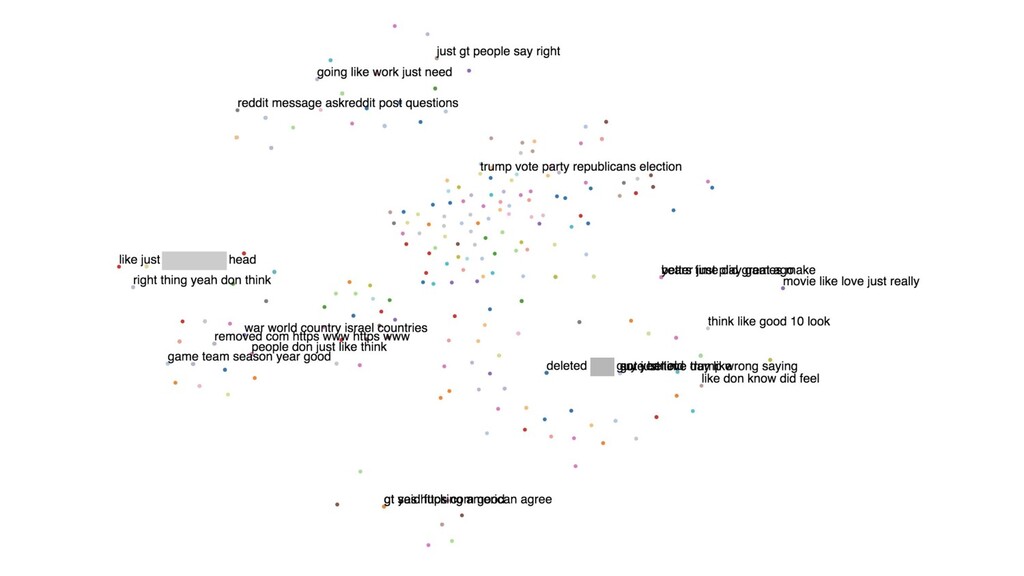
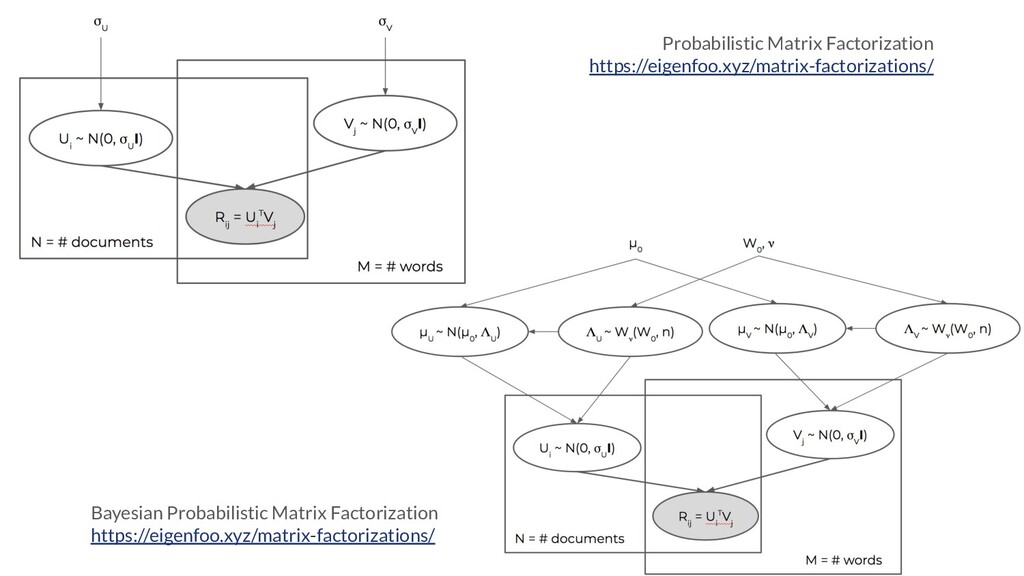
In this talk, I present a recent project to model hate speech on Reddit. In three acts, I chronicle the thought processes and stumbling blocks of the project, with each act applying a different form of machine learning: supervised learning, topic modelling and text clustering. I conclude with the current state of the project: a system that allows the modelling and summarization of entire subreddits, and possible future directions. Rest assured that both the talk and the slides have been scrubbed to be safe for work!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}