which does not reflect the opinions of myself or my collaborators. They are employed solely for the purpose of explaining the work. Viewer’s discretion is advised.
cultural in nature. • UN defines hate speech as “any kind of communication that attacks or uses pejorative or discriminatory language with reference to a person or a group on the basis of who they are.” [1] Fig 1: Pyramid of Hate [2] [1]: UN hate [2]: Pyramid of Hate
speech datasets using hate lexicons/slur terms. • Limited Study in English-Hindi code-mixed (Hinglish) context. • Limited context means systems default to non-hate. Motivation • Can we curate a large scale Indic Dataset? • Can we model contextual information into detection of hate?
• Neutrally seeded from socio-political topics in India and USA and UK. • Source: Twitter (from Jan 2020-Jan 2021) Fig 1: Dataset Sample of GOTHate [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023 Fig 2: Dataset Sample of GOTHate [1]
we have 25k unique root users. • For each root tweet we collect the list of first 100 retweeters. • For each root user we collect the +/-25 tweets from the time of posting the tweet. Thus timeline is not only user but also tweet specific. • For each root user we collect their 1-hop ego-network (followers and followee).
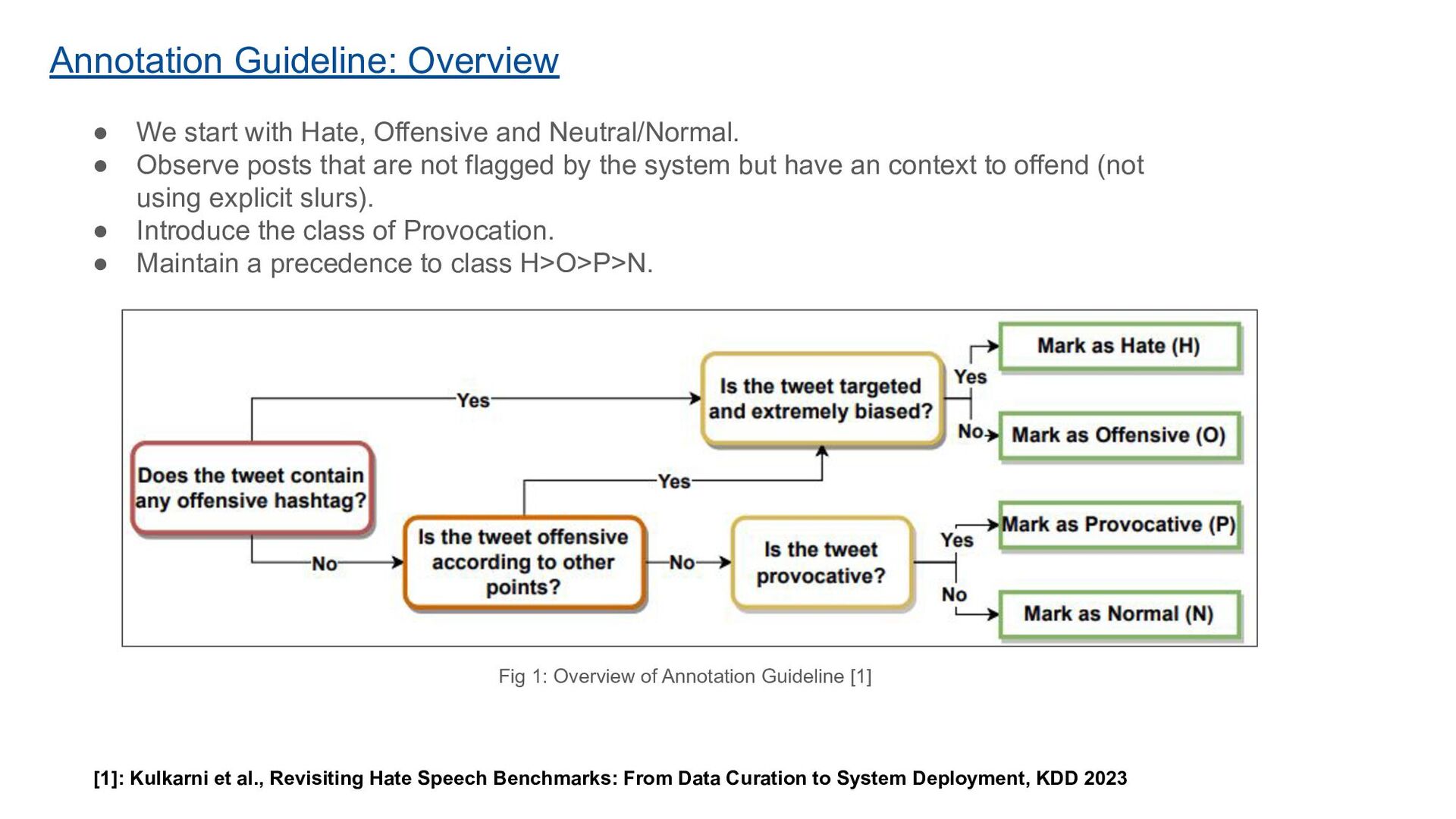
Neutral/Normal. • Observe posts that are not flagged by the system but have an context to offend (not using explicit slurs). • Introduce the class of Provocation. • Maintain a precedence to class H>O>P>N. Fig 1: Overview of Annotation Guideline [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023
hateful and 10k provocative. [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023 GOTHate Annotations
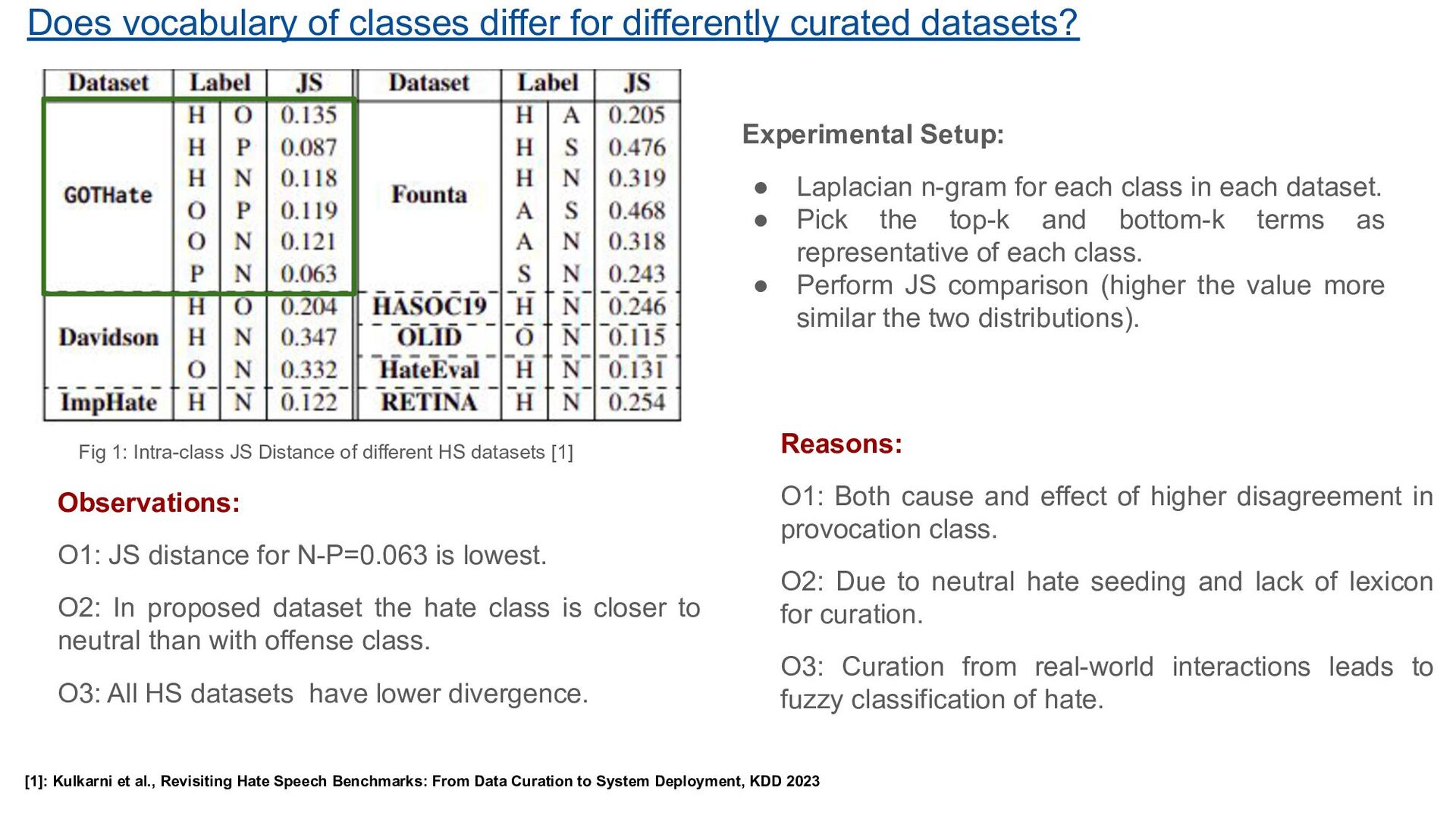
1: Intra-class JS Distance of different HS datasets [1] Observations: O1: JS distance for N-P=0.063 is lowest. O2: In proposed dataset the hate class is closer to neutral than with offense class. O3: All HS datasets have lower divergence. Reasons: O1: Both cause and effect of higher disagreement in provocation class. O2: Due to neutral hate seeding and lack of lexicon for curation. O3: Curation from real-world interactions leads to fuzzy classification of hate. Experimental Setup: • Laplacian n-gram for each class in each dataset. • Pick the top-k and bottom-k terms as representative of each class. • Perform JS comparison (higher the value more similar the two distributions). [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023
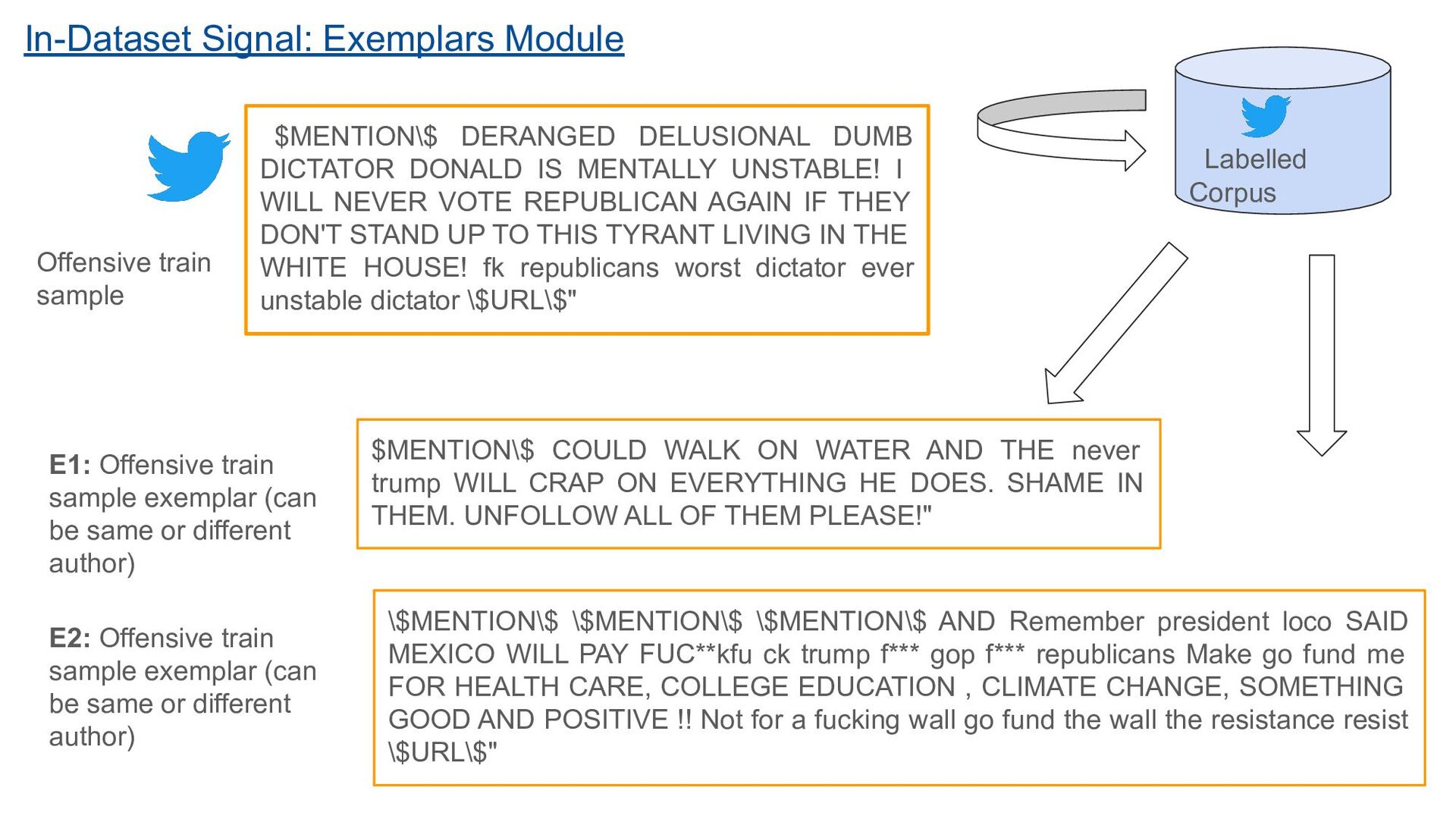
PAY FUC**kfu ck trump f*** gop f*** republicans Make go fund me FOR HEALTH CARE, COLLEGE EDUCATION , CLIMATE CHANGE, SOMETHING GOOD AND POSITIVE !! Not for a fucking wall go fund the wall the resistance resist \$URL\$" $MENTION\$ DERANGED DELUSIONAL DUMB DICTATOR DONALD IS MENTALLY UNSTABLE! I WILL NEVER VOTE REPUBLICAN AGAIN IF THEY DON'T STAND UP TO THIS TYRANT LIVING IN THE WHITE HOUSE! fk republicans worst dictator ever unstable dictator \$URL\$" $MENTION\$ COULD WALK ON WATER AND THE never trump WILL CRAP ON EVERYTHING HE DOES. SHAME IN THEM. UNFOLLOW ALL OF THEM PLEASE!" Offensive train sample Labelled Corpus E1: Offensive train sample exemplar (can be same or different author) E2: Offensive train sample exemplar (can be same or different author) In-Dataset Signal: Exemplars Module
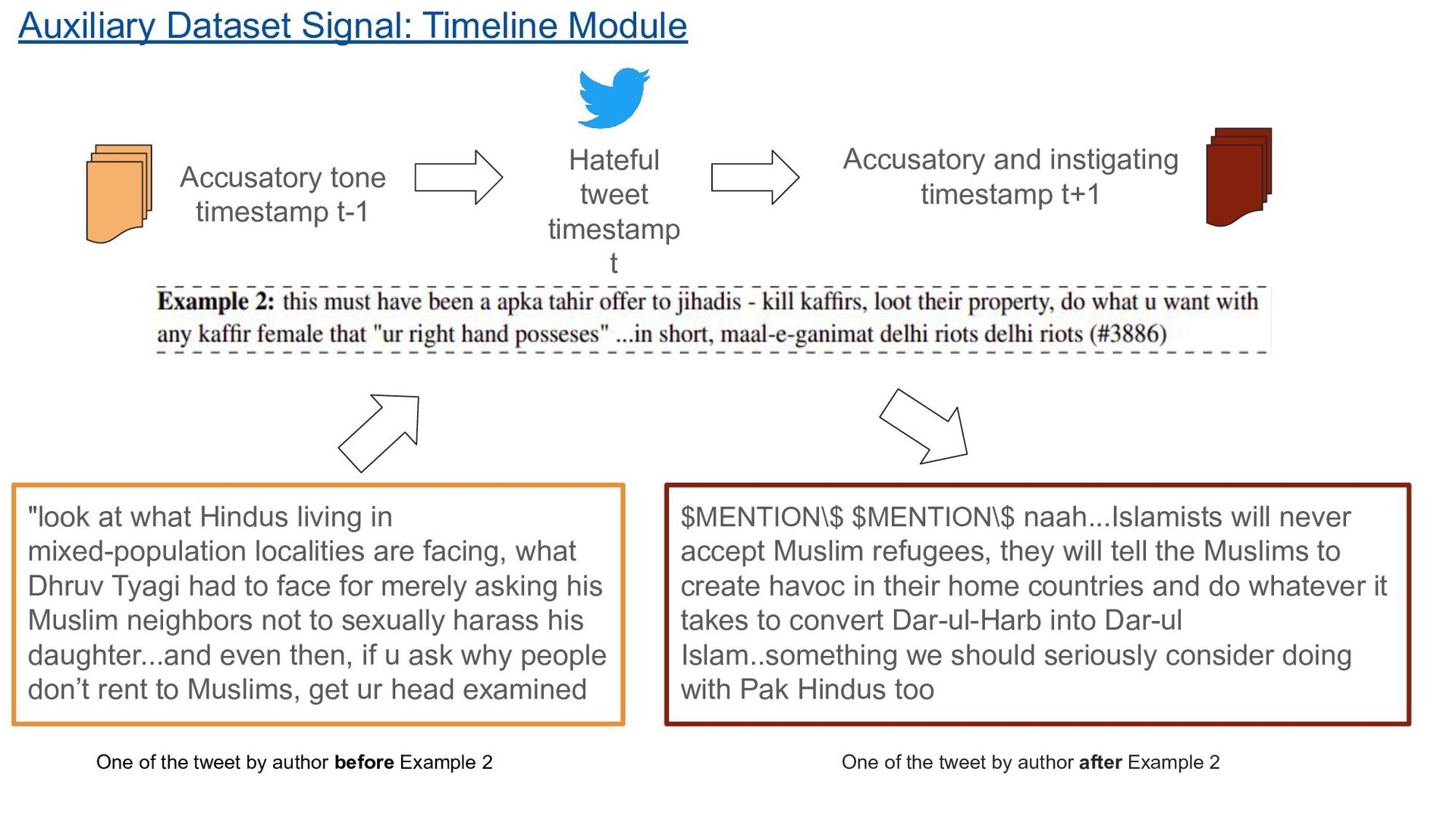
what Dhruv Tyagi had to face for merely asking his Muslim neighbors not to sexually harass his daughter...and even then, if u ask why people don’t rent to Muslims, get ur head examined $MENTION\$ $MENTION\$ naah...Islamists will never accept Muslim refugees, they will tell the Muslims to create havoc in their home countries and do whatever it takes to convert Dar-ul-Harb into Dar-ul Islam..something we should seriously consider doing with Pak Hindus too One of the tweet by author before Example 2 One of the tweet by author after Example 2 Accusatory tone timestamp t-1 Hateful tweet timestamp t Accusatory and instigating timestamp t+1 Auxiliary Dataset Signal: Timeline Module
Benchmarks: From Data Curation to System Deployment, KDD 2023 HEN-mBERT: History, Exemplar and Network infused mBERT model. Fig 1: Proposed model HEN-mBERT [1]
hate speech dataset with Indic topics. • Perform extensive experiments on analysing the quality of dataset and its similarity to existing datasets. • Propose a signal rich attention module to fine-tune mBERT for detection of hateful content. Takeaways: • Tradeoff in time/effort vs quality of annotation from expert to crowdsourced. • Contextual signals infused in an attentive manner reduce the signal/noise and improves detection of hate.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Annotation Phases: Overview Fig 1: 2-phased Annotation Mode [1] •](https://files.speakerdeck.com/presentations/4d6fad5ff84442a3b12a5e383ce73411/slide_9.jpg){kind=link}
![Fig 1: Dataset Stats [1] • 50k tweets. • 3k](https://files.speakerdeck.com/presentations/4d6fad5ff84442a3b12a5e383ce73411/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fig 1: Motivation for Auxiliary Data Signals[1] Contextual Signal Infusion](https://files.speakerdeck.com/presentations/4d6fad5ff84442a3b12a5e383ce73411/slide_15.jpg){kind=link}
![Proposed model: HEN-mBERT [1]: Kulkarni et al., Revisiting Hate Speech](https://files.speakerdeck.com/presentations/4d6fad5ff84442a3b12a5e383ce73411/slide_16.jpg){kind=link}
![Fig 1: Baseline and Ablation [1] [1]: Kulkarni et al.,](https://files.speakerdeck.com/presentations/4d6fad5ff84442a3b12a5e383ce73411/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
![THANK YOU Sarah, 4th year PhD@ LCS2, IIIT-Delhi [email protected] _themessier](https://files.speakerdeck.com/presentations/4d6fad5ff84442a3b12a5e383ce73411/slide_20.jpg){kind=link}