cultural in nature. • UN defines hate speech as “any kind of communication that attacks or uses pejorative or discriminatory language with reference to a person or a group on the basis of who they are.” [1] • Need sensitisation of social media users. Fig 1: Pyramid of Hate [2] [1]: UN hate [2]: Pyramid of Hate
own social issues like: • India is a home to multiple languages and dialects. • Users show varying degrees of hateful inclination towards different topics. Fig 1: Hatefulness of different users towards different hashtags in RETINA [1] [1]: Masud et al., Hate is the New Infodemic: A Topic-aware Modeling of Hate Speech Diffusion on Twitter, ICDE 2021
speech datasets using hate lexicons/slur terms. • Limited Study in English-Hindi code-mixed (Hinglish) context. • Limited context means systems default to non-hate. Motivation ❖ Can we curate a large scale Indic Dataset? ❖ Can we model contextual information into detection of hate? The need of Indic datasets?
topics in India and USA and UK. • Not filtered for language. • Source: Twitter (from Jan 2020-Jan 2021) ◦ Primary dataset: Tweets on these (Fig. 1) topics. ◦ Secondary dataset: User metadata, timeline and 1-hop network information. ◦ RIP Free Twitter API :( Fig 1: Socio-political topics covered in GOTHate [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023
multiple keys in round robin fashion b. Add appropriate halting between API calls 2. Hateful content is effervescent and limited in quantity compared to non-hateful counterparts a. Parallely curating primary and secondary dataset 3. Reproducibility in research is limited by Twitter’s data sharing policy a. Apart from publicly releasing tweet ids, make the textual content available to researchers on demand 4. Twitter access in India is privileged compared to other platforms like Whatsapp and Telegram a. No direct way of curating datasets from these platforms b. Some platforms like Tik Tok get banned due to geo-political or legal reasons.
researchers will access to research API free of cost! 2. Provide research access to content flagged/removed by human/AI moderators. a. Provide appropriate copyright access 3. Access to such dataset should be available to researchers across geographies. What about users? Can they opt-out of public research irrespective of their data being public?
what is hateful • Varying labels hate, offense, toxic, profane, abusive. ◦ Some go into finer details of offense being sexist, racist, islamophobic etc. • NO STANDARD DEFINITION of hate speech in NLP ◦ AKA no benchmark dataset or leaderboard for hate speech. Current approaches • Expert annotations • Crowdsourced annotations • Mixtures of both
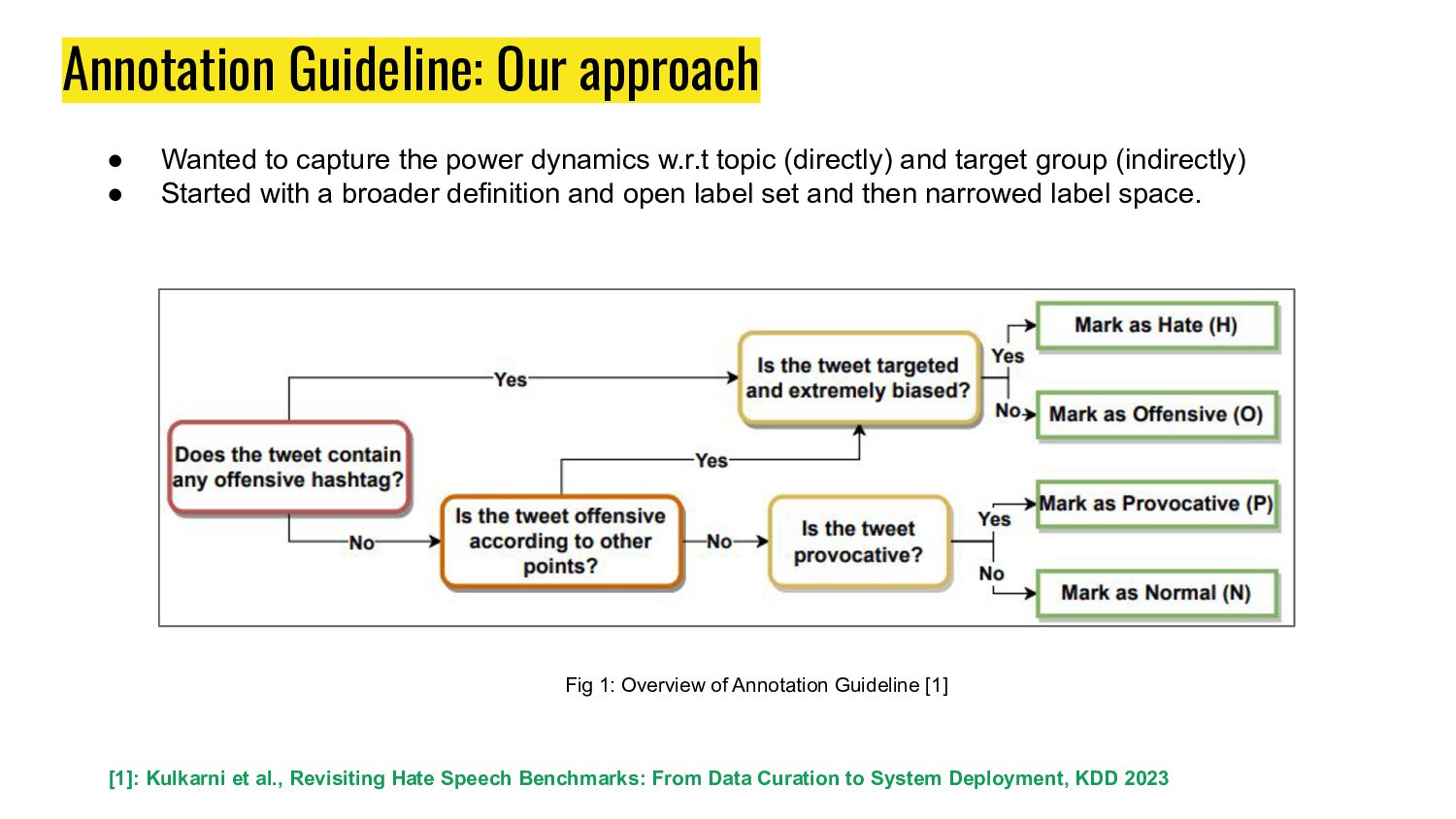
dynamics w.r.t topic (directly) and target group (indirectly) • Started with a broader definition and open label set and then narrowed label space. Fig 1: Overview of Annotation Guideline [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023
terms of topic the tweet belongs to helps the annotator get a sense of the vulnerable group under consideration. a. No prior list of vulnerable group b. Subjective in nature. Eg: Asian population 2. Annotation bias is real!! 3. Neutral seeding makes the annotations even harder.
continuous validation is better than 1-phase for large scale annotations. a. Tradeoff in time/effort vs quality of annotation from expert to crowdsourced. 2. Involve local/socially aware annotators rather than generic platforms. a. Xsaras vs Crowdflower 3. Finalise the guideline iteratively, keep an open mind. a. Use social media guidelines as seed b. Add/remove labels based on already existing labels in literature
bias a. Communicate with the annotators to understand their point-of-view and share the aim of hate speech detection. b. Avoid working with annotators who have strong political affiliations and are directly involved in political work. c. Work with diverse annotators w.r.t age, gender, lingusitc capabilities 2. There will still be mislabelling! a. It will mimic the chaotic real-world more closely :P b. Dataset even with mislabelled annotators represents some annotation bias and annotator’s point-of-view. It is not ideal but still representative of the society. [1,2] Jury is still out on if these biases and issues can be overcome by genAI [1]: Novak et al., Handling Disagreement in Hate Speech Modelling [2]: Davani et al., Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations
loco SAID MEXICO WILL PAY FUC**kfu ck trump f*** gop f*** republicans Make go fund me FOR HEALTH CARE, COLLEGE EDUCATION , CLIMATE CHANGE, SOMETHING GOOD AND POSITIVE !! Not for a fucking wall go fund the wall the resistance resist \$URL\$" $MENTION\$ DERANGED DELUSIONAL DUMB DICTATOR DONALD IS MENTALLY UNSTABLE! I WILL NEVER VOTE REPUBLICAN AGAIN IF THEY DON'T STAND UP TO THIS TYRANT LIVING IN THE WHITE HOUSE! fk republicans worst dictator ever unstable dictator \$URL\$" $MENTION\$ COULD WALK ON WATER AND THE never trump WILL CRAP ON EVERYTHING HE DOES. SHAME IN THEM. UNFOLLOW ALL OF THEM PLEASE!" Offensive train sample Labelled Corpus E1: Offensive train sample exemplar (can be same or different author) E2: Offensive train sample exemplar (can be same or different author)
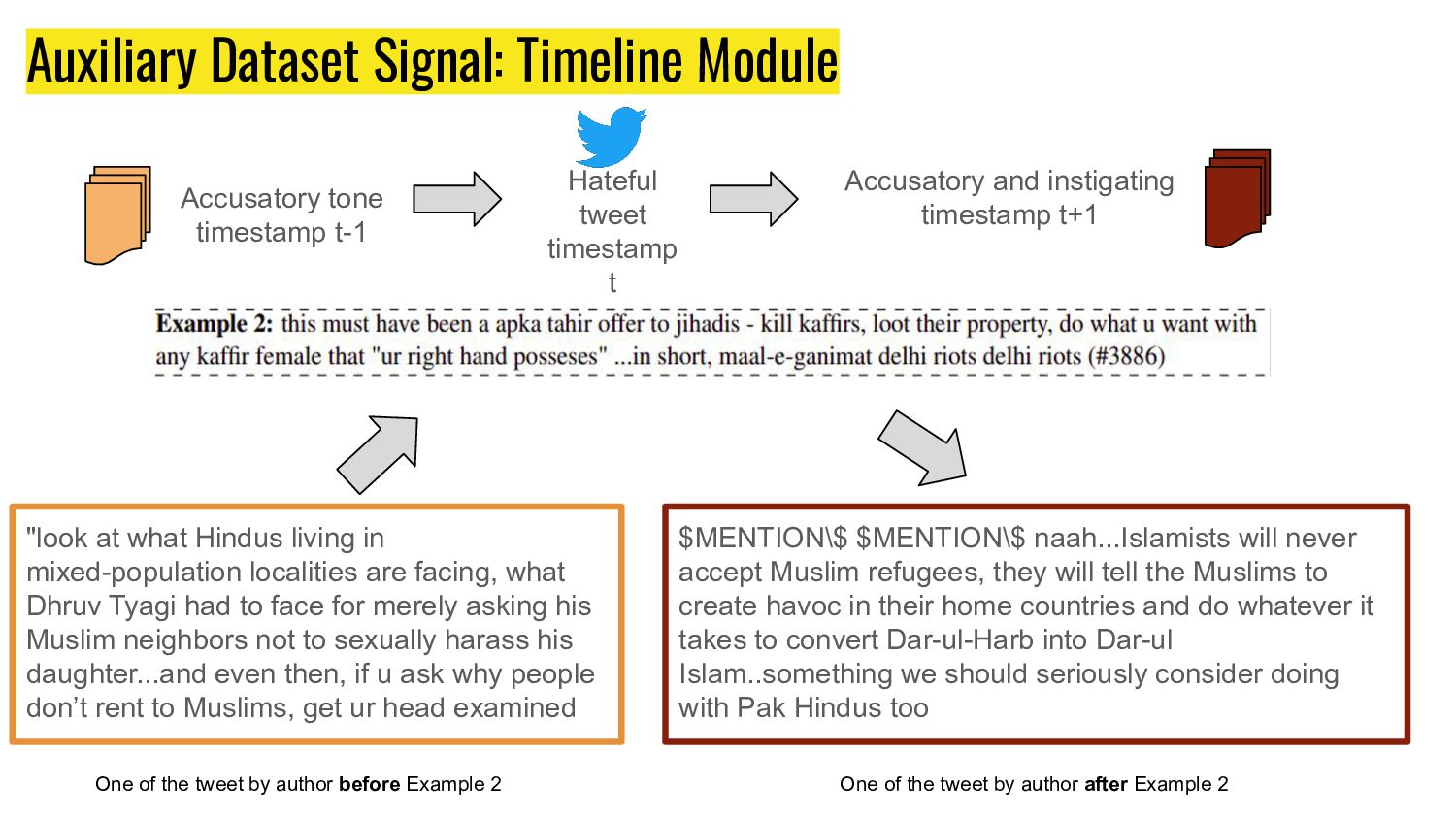
in mixed-population localities are facing, what Dhruv Tyagi had to face for merely asking his Muslim neighbors not to sexually harass his daughter...and even then, if u ask why people don’t rent to Muslims, get ur head examined $MENTION\$ $MENTION\$ naah...Islamists will never accept Muslim refugees, they will tell the Muslims to create havoc in their home countries and do whatever it takes to convert Dar-ul-Harb into Dar-ul Islam..something we should seriously consider doing with Pak Hindus too One of the tweet by author before Example 2 One of the tweet by author after Example 2 Accusatory tone timestamp t-1 Hateful tweet timestamp t Accusatory and instigating timestamp t+1
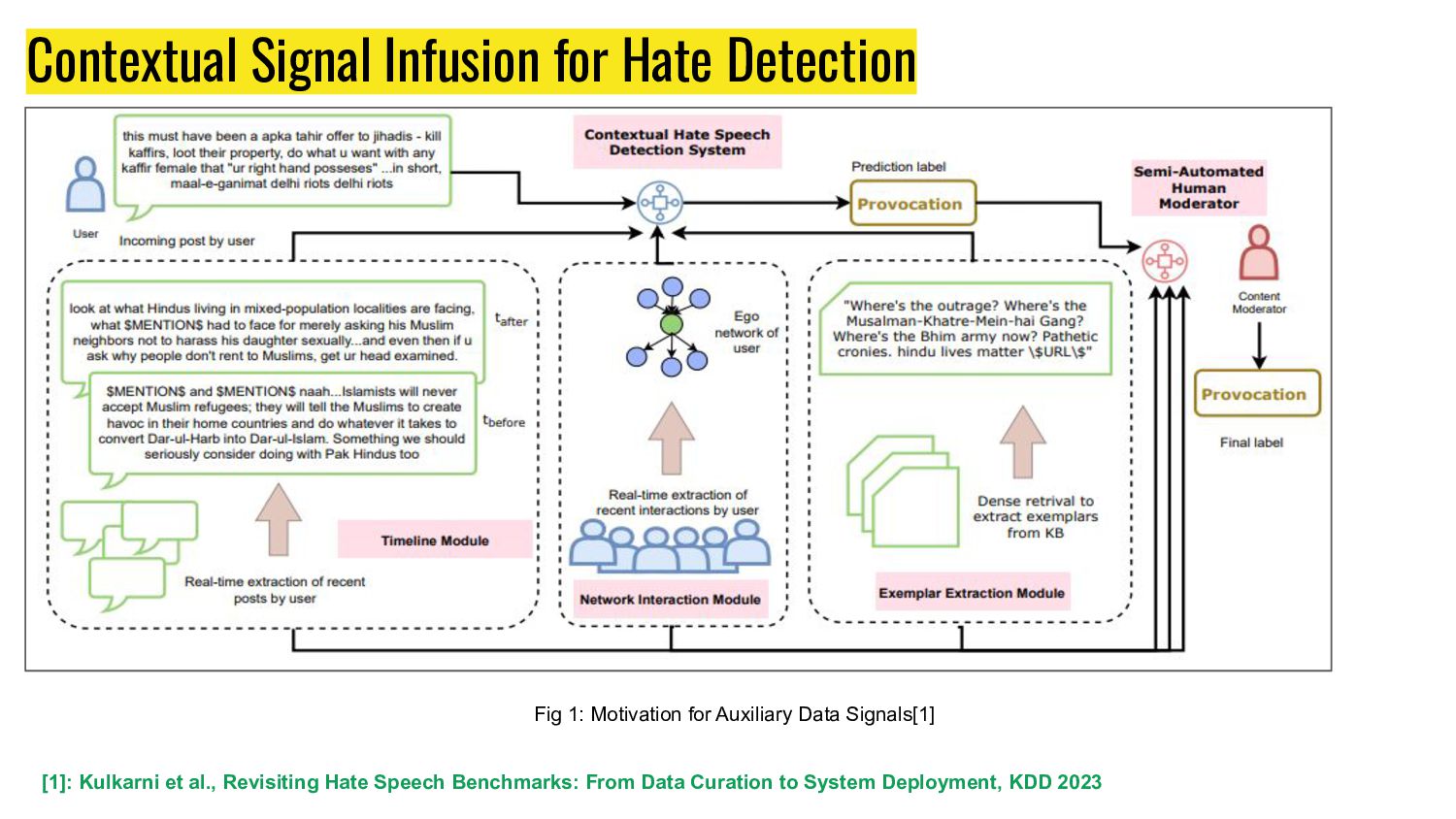
Benchmarks: From Data Curation to System Deployment, KDD 2023 HEN-mBERT: History, Exemplar and Network infused mBERT model. Fig 1: Proposed model HEN-mBERT [1]
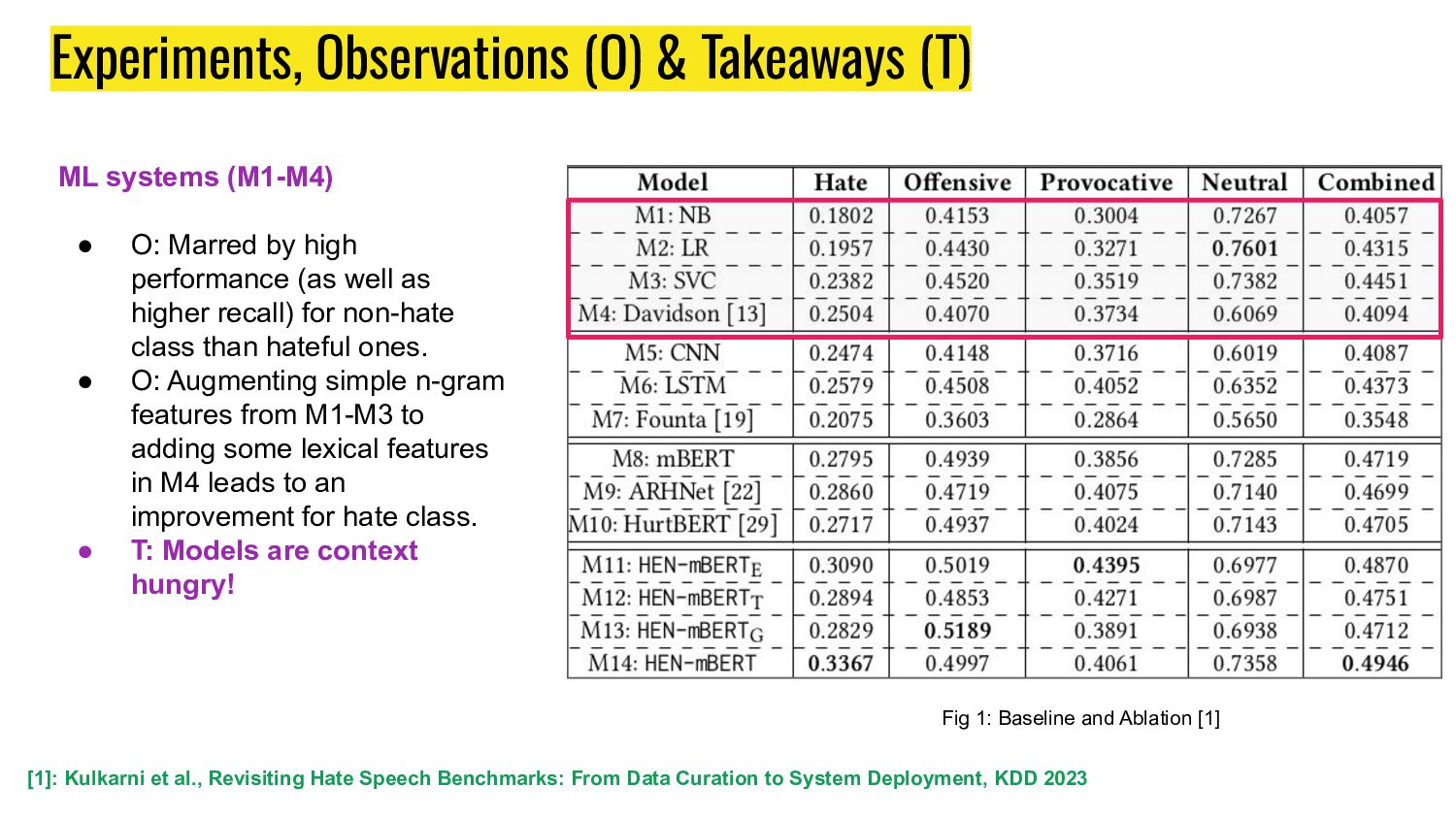
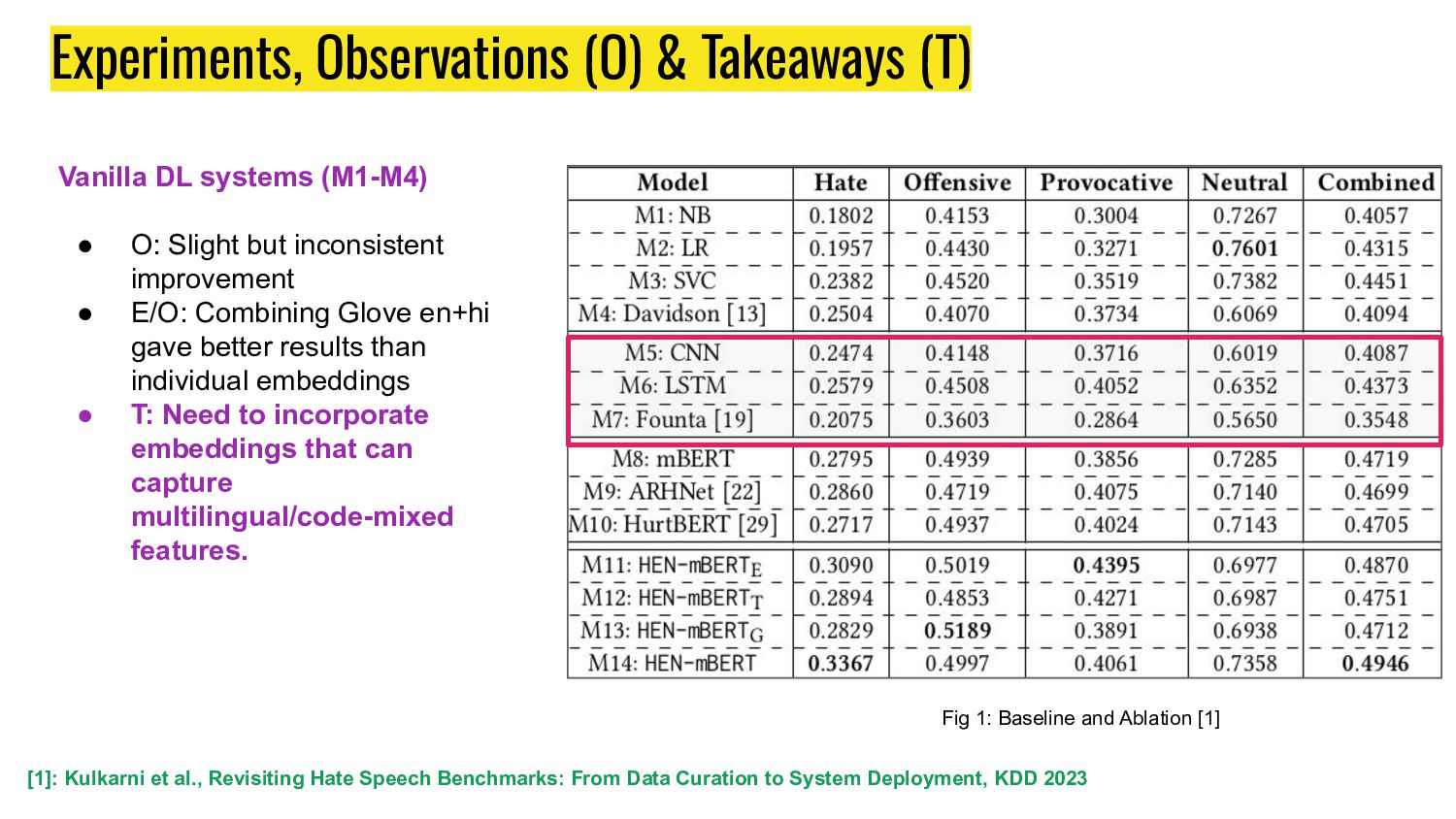
Ablation [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023 ML systems (M1-M4) • O: Marred by high performance (as well as higher recall) for non-hate class than hateful ones. • O: Augmenting simple n-gram features from M1-M3 to adding some lexical features in M4 leads to an improvement for hate class. • T: Models are context hungry!
Ablation [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023 Vanilla DL systems (M1-M4) • O: Slight but inconsistent improvement • E/O: Combining Glove en+hi gave better results than individual embeddings • T: Need to incorporate embeddings that can capture multilingual/code-mixed features.
and Ablation [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023 Vanilla mBERT systems (M8-M10) • O: As expected major jump in performance when fine-tuning mBERT based systems • M10 uses hate lexicon as external context is not able provide a significant improvement over mBERT due to neutrally seeded GOTHate. • M9: Simple concatenation of network info lead to improvement in performance for hateful class. • T: Hateful users seem to be sharing similar latent signals. • T: Implicit signals like network info is better for our dataset than explicit signals like hate lexicons
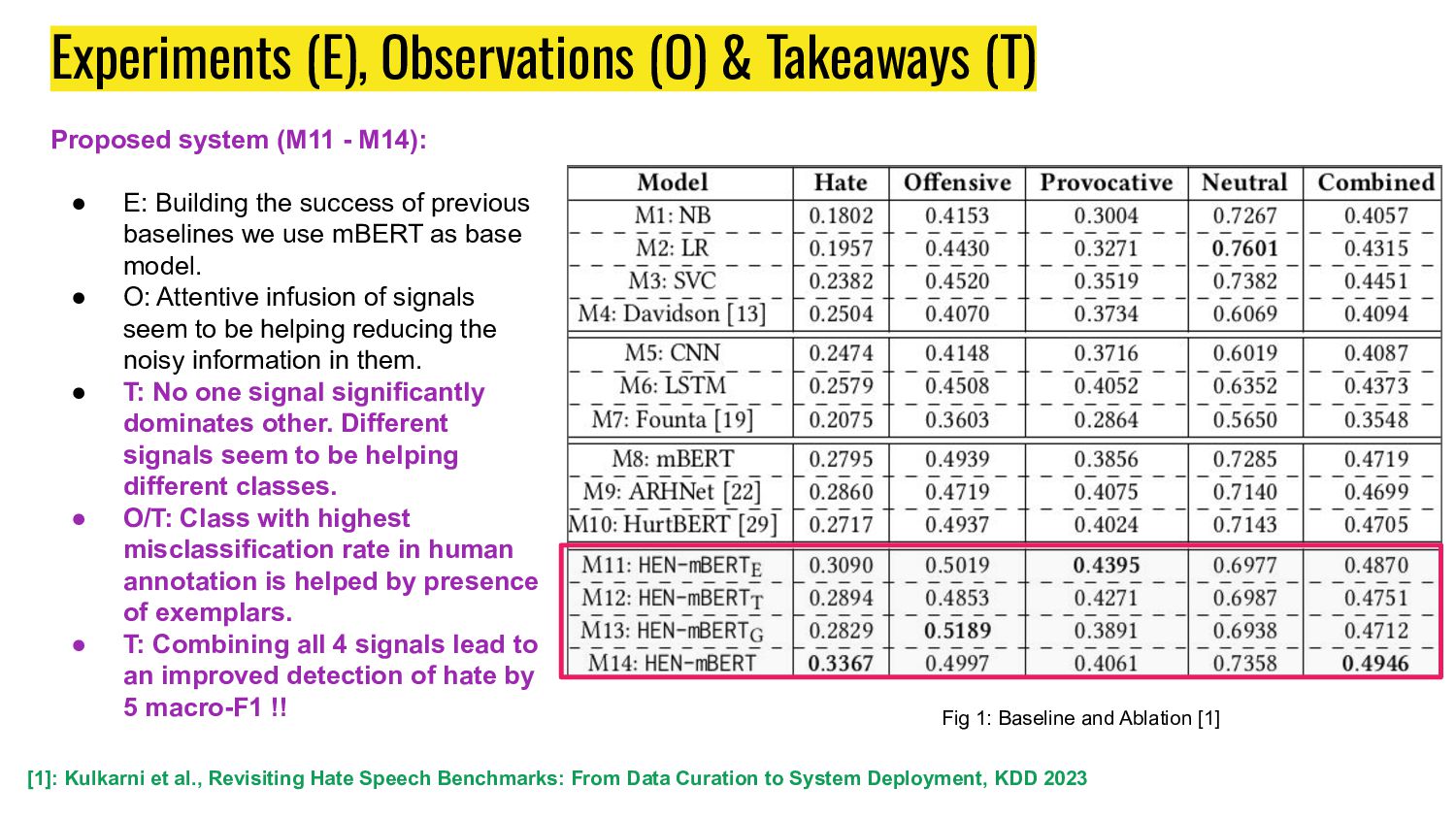
and Ablation [1] [1]: Kulkarni et al., Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment, KDD 2023 Proposed system (M11 - M14): • E: Building the success of previous baselines we use mBERT as base model. • O: Attentive infusion of signals seem to be helping reducing the noisy information in them. • T: No one signal significantly dominates other. Different signals seem to be helping different classes. • O/T: Class with highest misclassification rate in human annotation is helped by presence of exemplars. • T: Combining all 4 signals lead to an improved detection of hate by 5 macro-F1 !!
of crowd 2. Contextual signals and how to align them matters for hate speech detection 3. Increasing complexity of the system did not help, we need better signals not more complex models Pros: • Exemplar: Easily available • Timeline & network: Helps capture repeated behaviour and interaction patterns • Timeline & network: Can latter be used for justification of content flagging. Cons: • Examplar: Difficult to capture topical drifts • Timeline & network: Not available if the user is deleted or private • Timeline & Network:Platform specific
correlation of words/phrases in a class. • Terms contributing to lexical bias can be enlisted under as bias sensitive words (BSW) • BSW differ for different datasets and target group under consideration. For example if our datasets has a lot of hate speech against African Americans then mere presence of their identity terms like Black or slur terms like n** can trigger the model to classify such statements as hateful irrespective of the context.
identified replaced their occurrence in Hate class via [1]: ◦ POS tags to reduce dependency on explicit terms (Black -> <NOUN>) ◦ Parent in the hypernym-tree (Black -> Color) ◦ k-Nearest neighbour in a word embedding [1]: Badjatiya et al., Stereotypical Bias Removal for Hate Speech Detection Task using Knowledge-based Generalizations [2]: Waseem & hovy, Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter [3]: Garg et al., Handling Bias in Toxic Speech Detection: A Survey, ACM CSUR Drawback of the study: Post substitution of BSW, the the original BSW is employed to evaluate reduction in bias with no discussion on evaluating the bias on the newly replaced terms. [1] Fig 1: Reproduced results [3] on WordNet replacement [1] for Waseem& Hovy dataset [2]
∈ 𝐵𝑆𝑊 with its Wordnet ancestor 𝑎 ∈ 𝐴 will shift the lexical bias from 𝑤 to 𝑎 [1]: Badjatiya et al., Stereotypical Bias Removal for Hate Speech Detection Task using Knowledge-based Generalizations [2]: Garg et al., Handling Bias in Toxic Speech Detection: A Survey, ACM CSUR M-bias is the dataset before debiasing/substitution M-gen is the dataset after debiasing Fig 1: Knowledge-drift results. [2] Fig 1: Formula for pinned bias metric. [1]
bias seems to be capable of transferring from one source to the other. • Like a system at rest, a model/dataset with bias will remain biased unless external force of mitigation/regularization terms are added to the training. • Like interactive systems tend to become more chaotic overtime, hence bias mitigation in toxicity systems and NLP in general needs to be incorporated in the pipeline in a continuous fashion. Our survey enlists the issues and takeaways on other type of biases and mitigation for hate speech.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Annotation Guideline: Our approach Fig 1: 2-phased Annotation Mode [1]](https://files.speakerdeck.com/presentations/07c1e8ad14cd416983b6e36a1c85f05d/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Proposed model: HEN-mBERT [1]: Kulkarni et al., Revisiting Hate Speech](https://files.speakerdeck.com/presentations/07c1e8ad14cd416983b6e36a1c85f05d/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Taxonomy w.r.t Toxicity Detection [1]: Garg et al., Handling Bias](https://files.speakerdeck.com/presentations/07c1e8ad14cd416983b6e36a1c85f05d/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You Sarah, 4th year PhD@ LCS2, IIIT-Delhi [email protected] _themessier](https://files.speakerdeck.com/presentations/07c1e8ad14cd416983b6e36a1c85f05d/slide_36.jpg){kind=link}