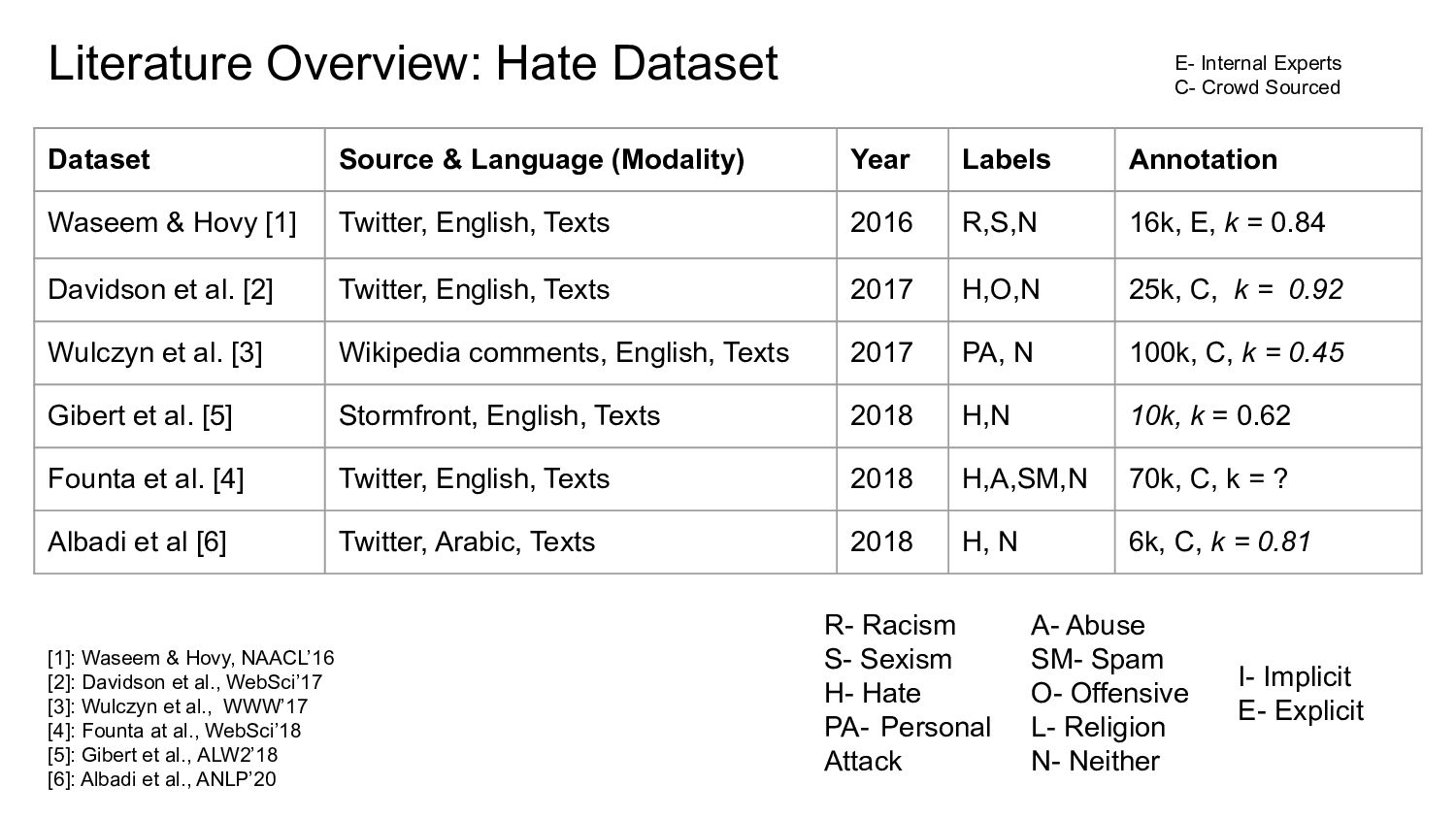
Labels Annotation Waseem & Hovy [1] Twitter, English, Texts 2016 R,S,N 16k, E, k = 0.84 Davidson et al. [2] Twitter, English, Texts 2017 H,O,N 25k, C, k = 0.92 Wulczyn et al. [3] Wikipedia comments, English, Texts 2017 PA, N 100k, C, k = 0.45 Gibert et al. [5] Stormfront, English, Texts 2018 H,N 10k, k = 0.62 Founta et al. [4] Twitter, English, Texts 2018 H,A,SM,N 70k, C, k = ? Albadi et al [6] Twitter, Arabic, Texts 2018 H, N 6k, C, k = 0.81 R- Racism S- Sexism H- Hate PA- Personal Attack A- Abuse SM- Spam O- Offensive L- Religion N- Neither I- Implicit E- Explicit [1]: Waseem & Hovy, NAACL’16 [2]: Davidson et al., WebSci’17 [3]: Wulczyn et al., WWW’17 [4]: Founta at al., WebSci’18 [5]: Gibert et al., ALW2’18 [6]: Albadi et al., ANLP’20 E- Internal Experts C- Crowd Sourced
{kind=link}
{kind=link}
![Definition of Hate Speech [1]: UN hate [2]: Pyramid of](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fig 2: Overview of Annotation Guideline [1] [1]: Revisiting Hate](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_8.jpg){kind=link}
{kind=link}
![Fig 1: 2-phased Annotation Mode [1,2] • Phase I: k](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
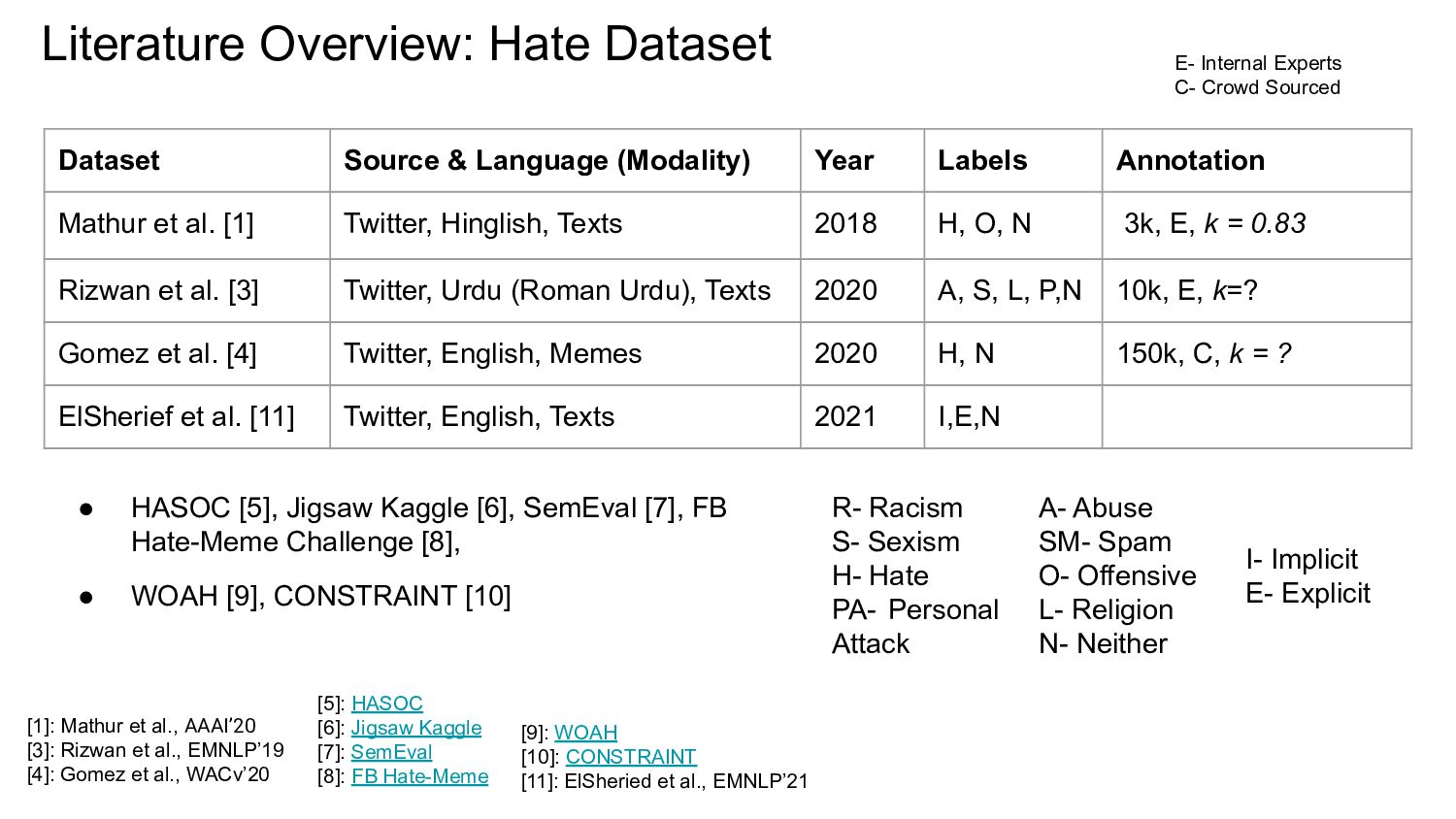
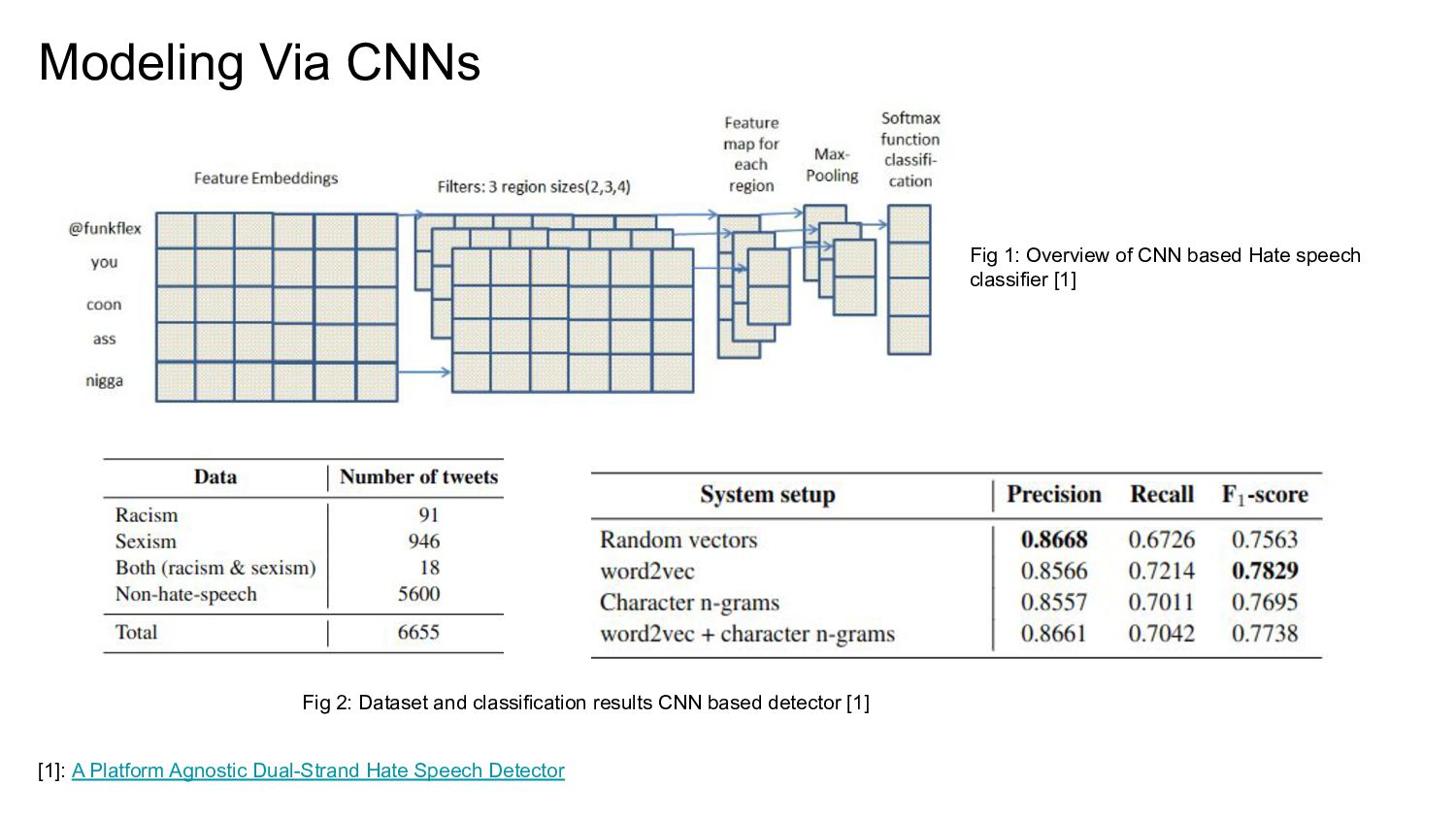
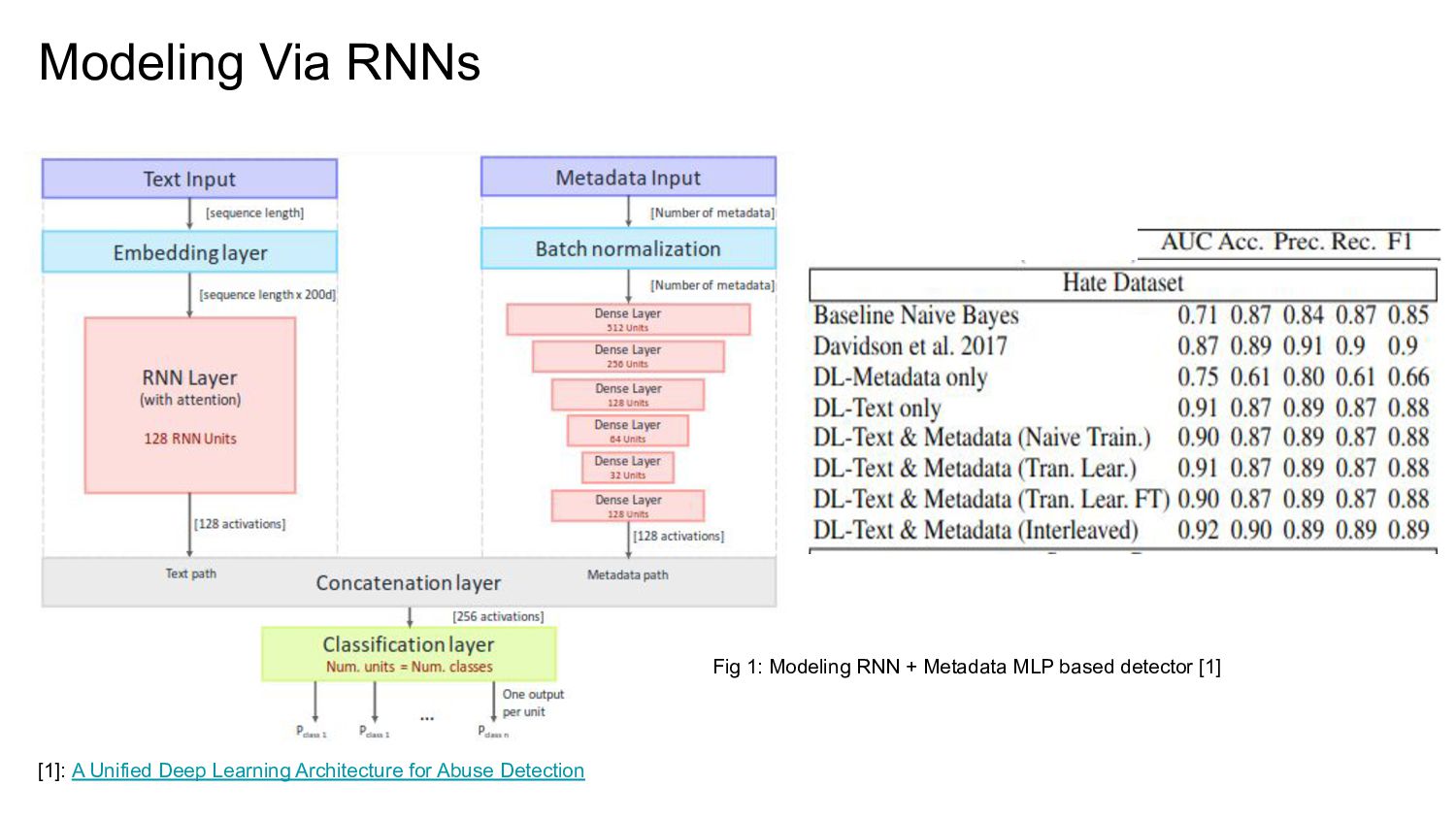
![Literature Overview: Hate Detection • N-gram Tf-idf + LR/SVM [1,2]](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
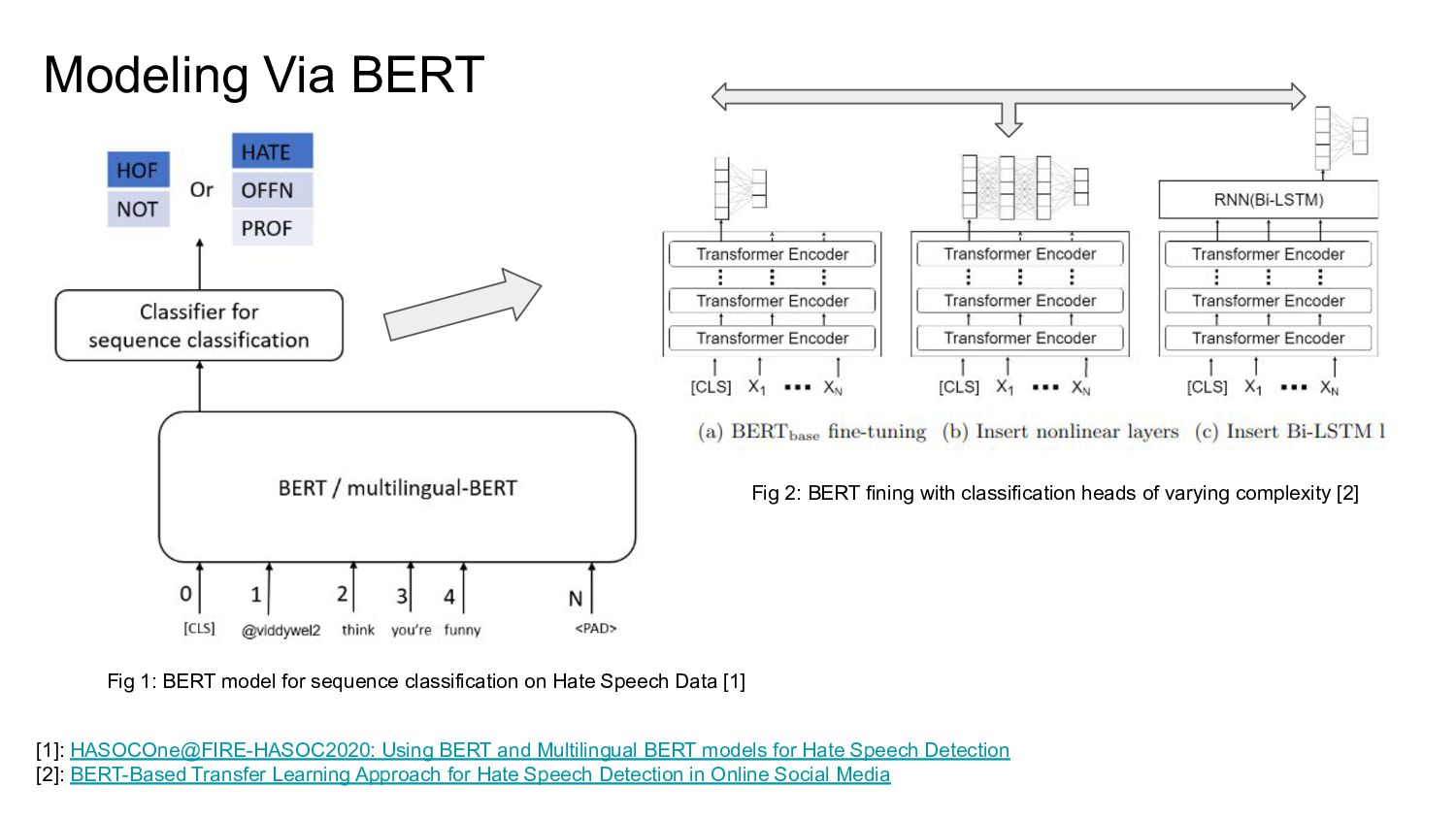{kind=link}
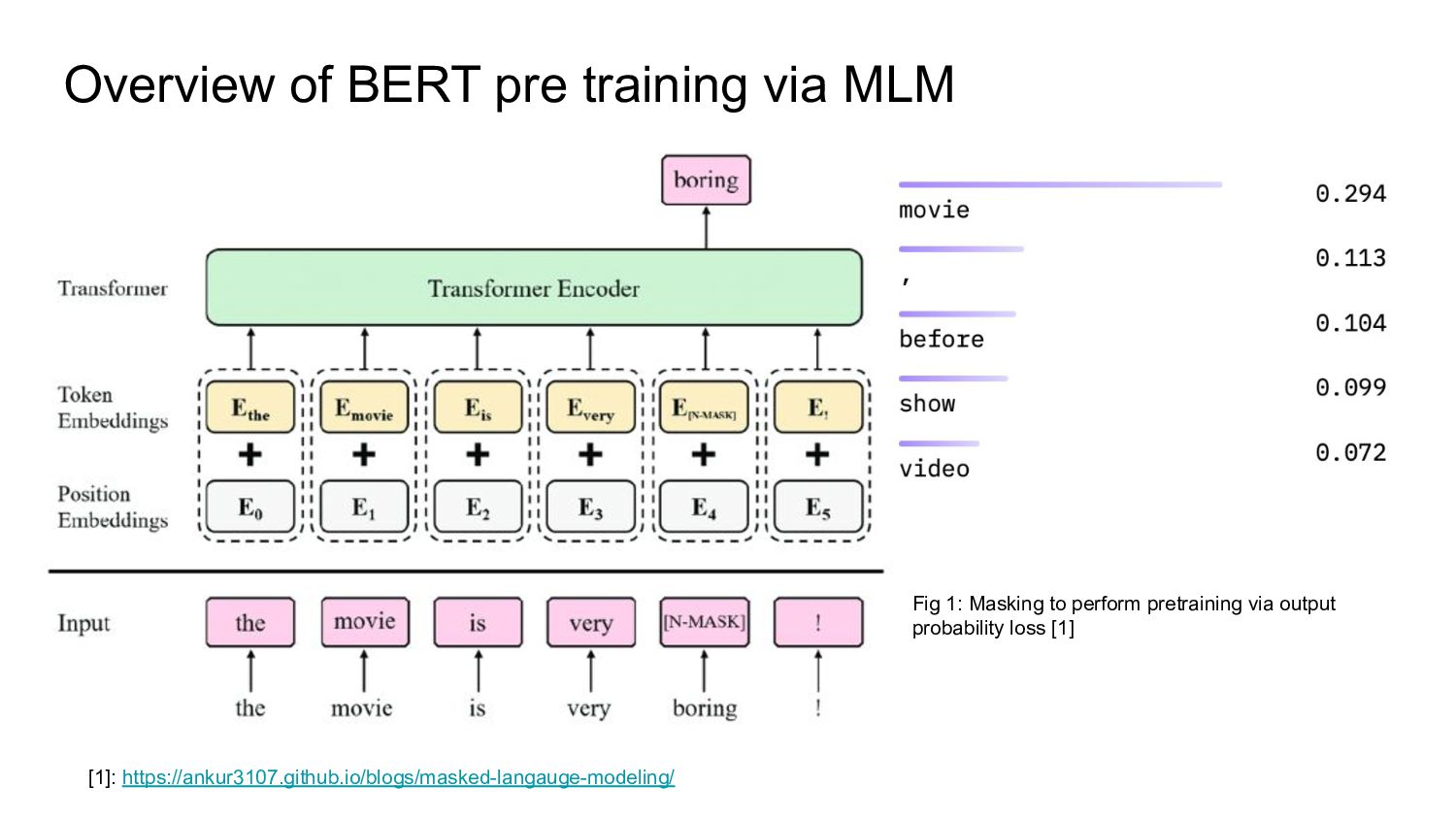{kind=link}
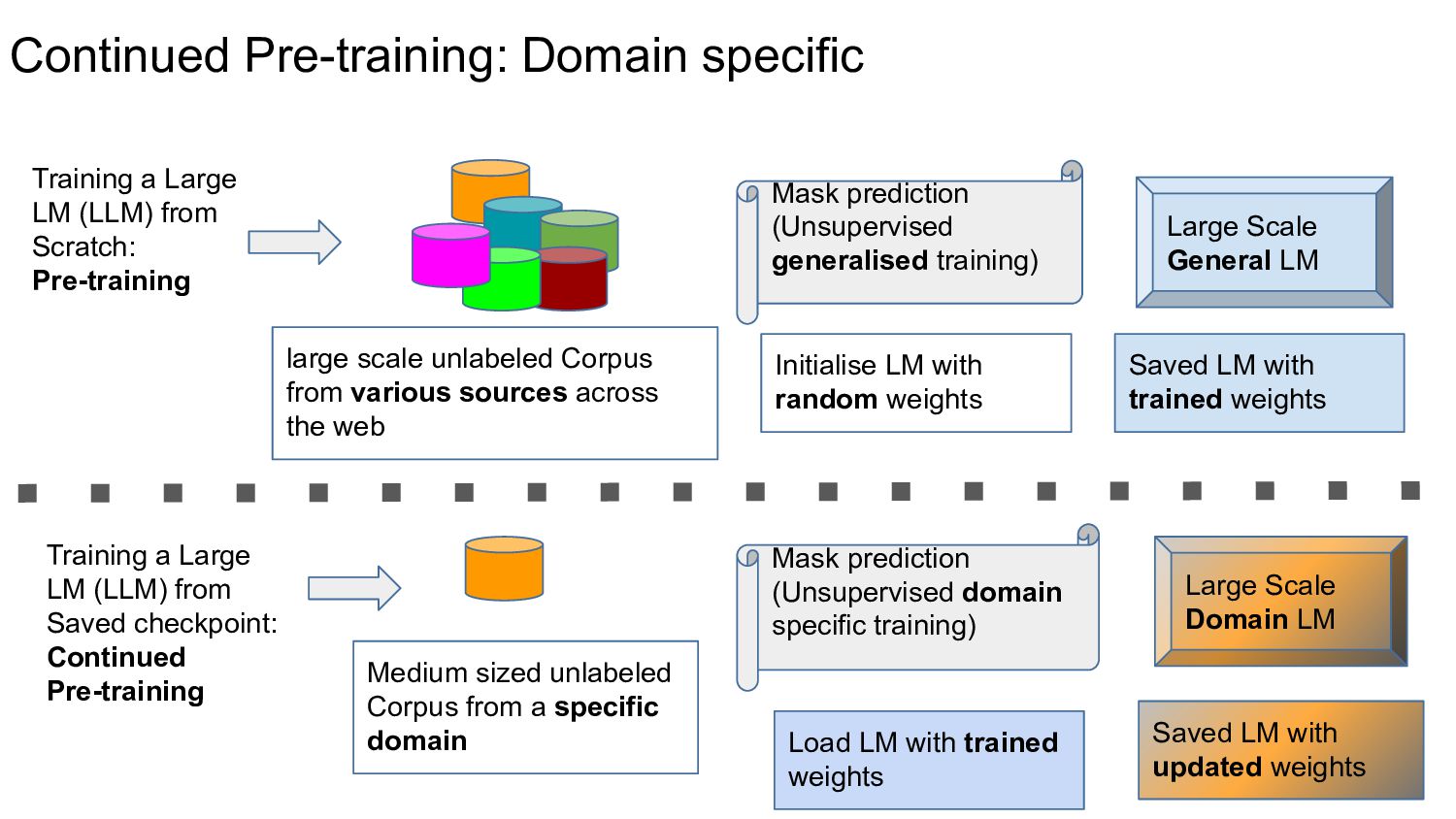{kind=link}
{kind=link}
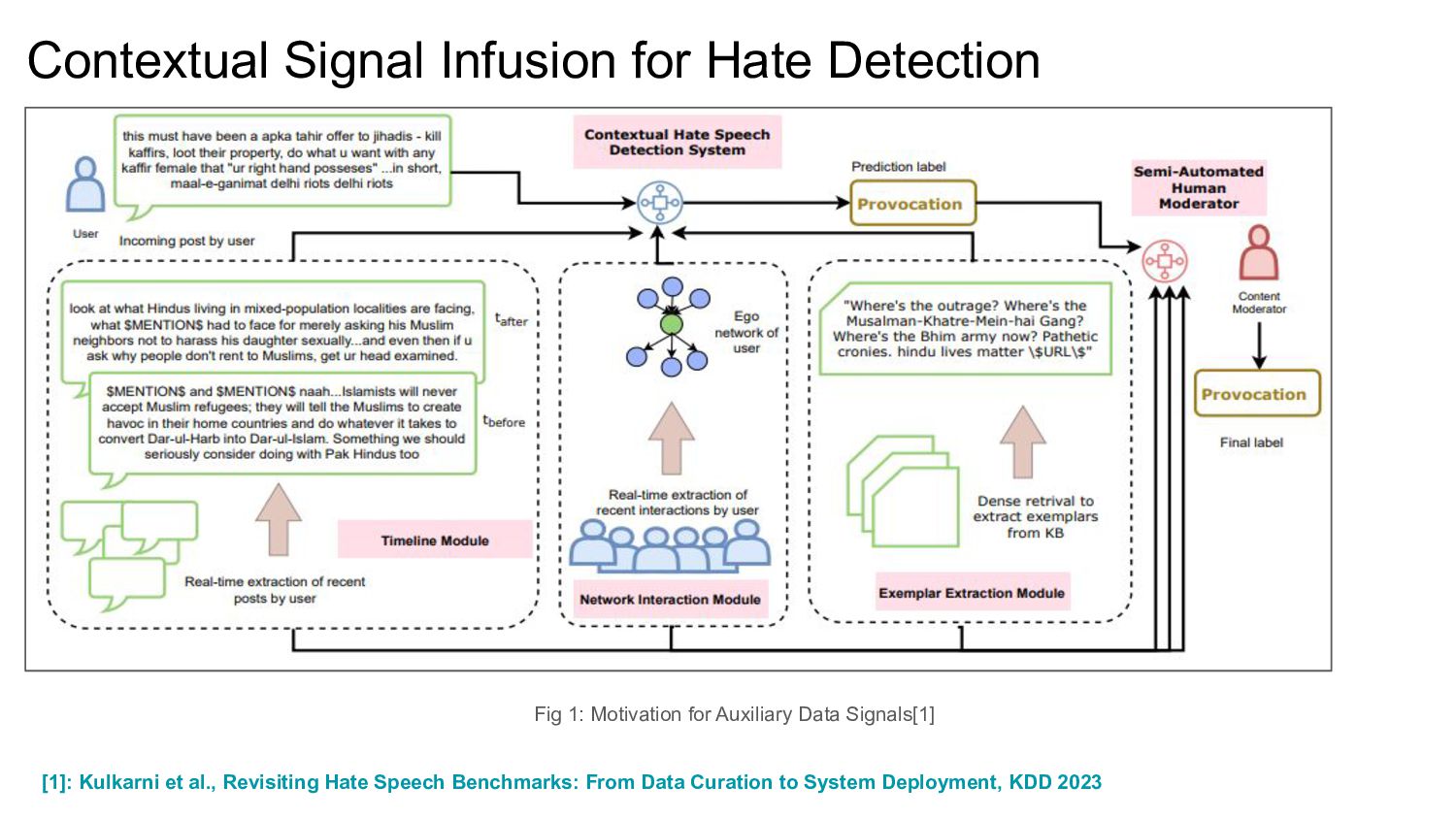{kind=link}
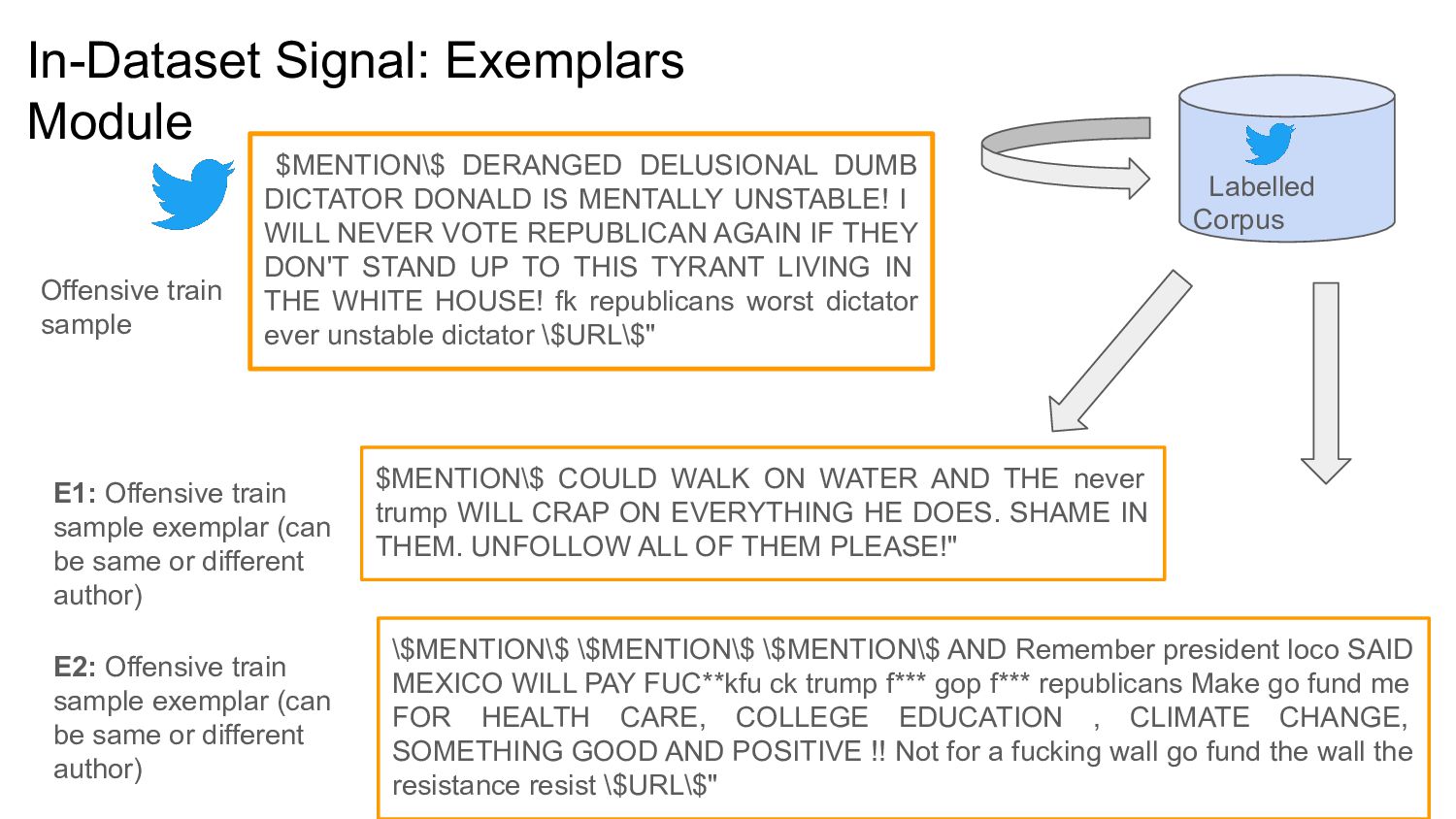{kind=link}
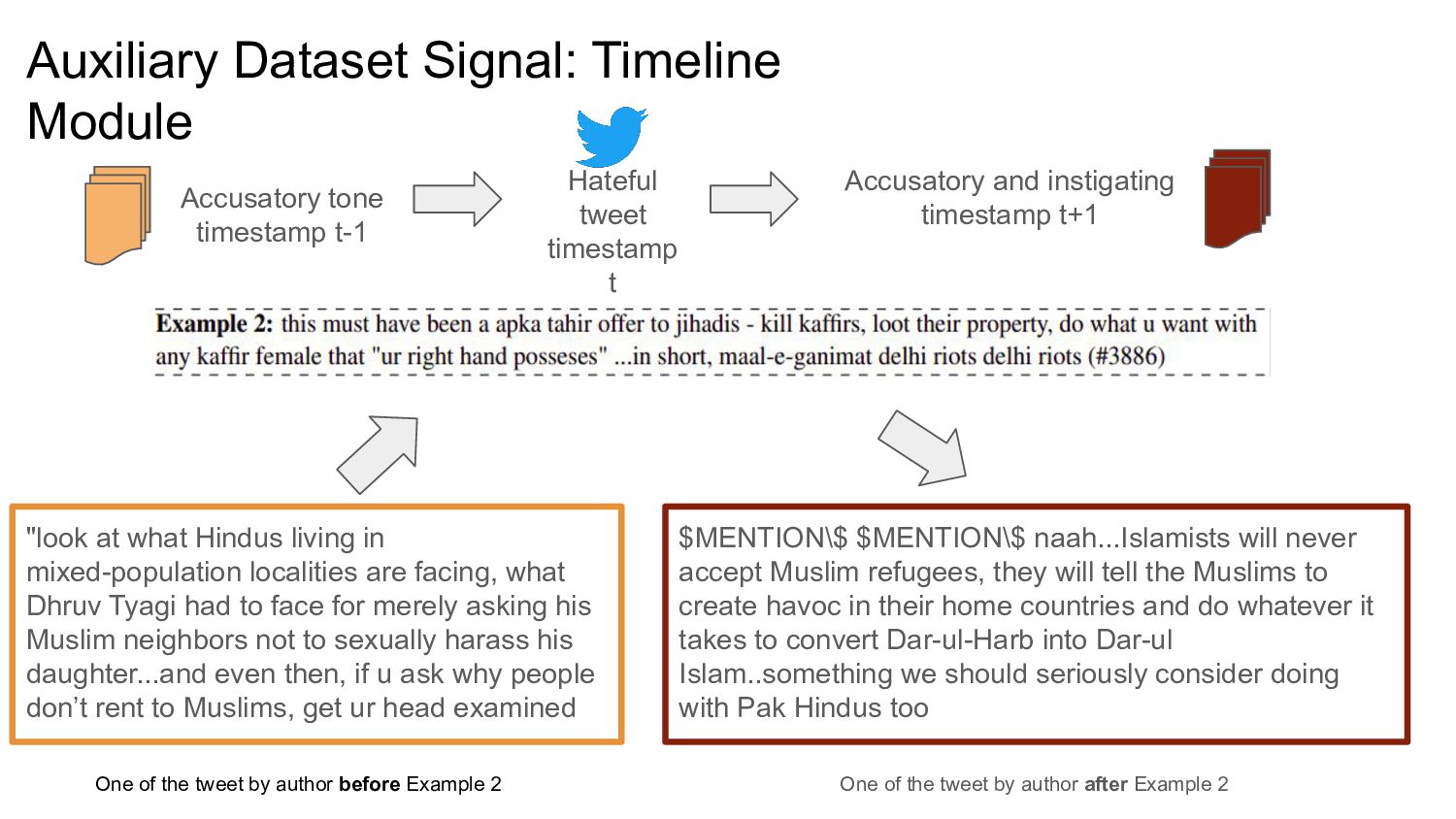{kind=link}
![External Knowledge Infusion: non-MLM Finetuning [1]: Revisiting Hate Speech Benchmarks:](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_24.jpg){kind=link}
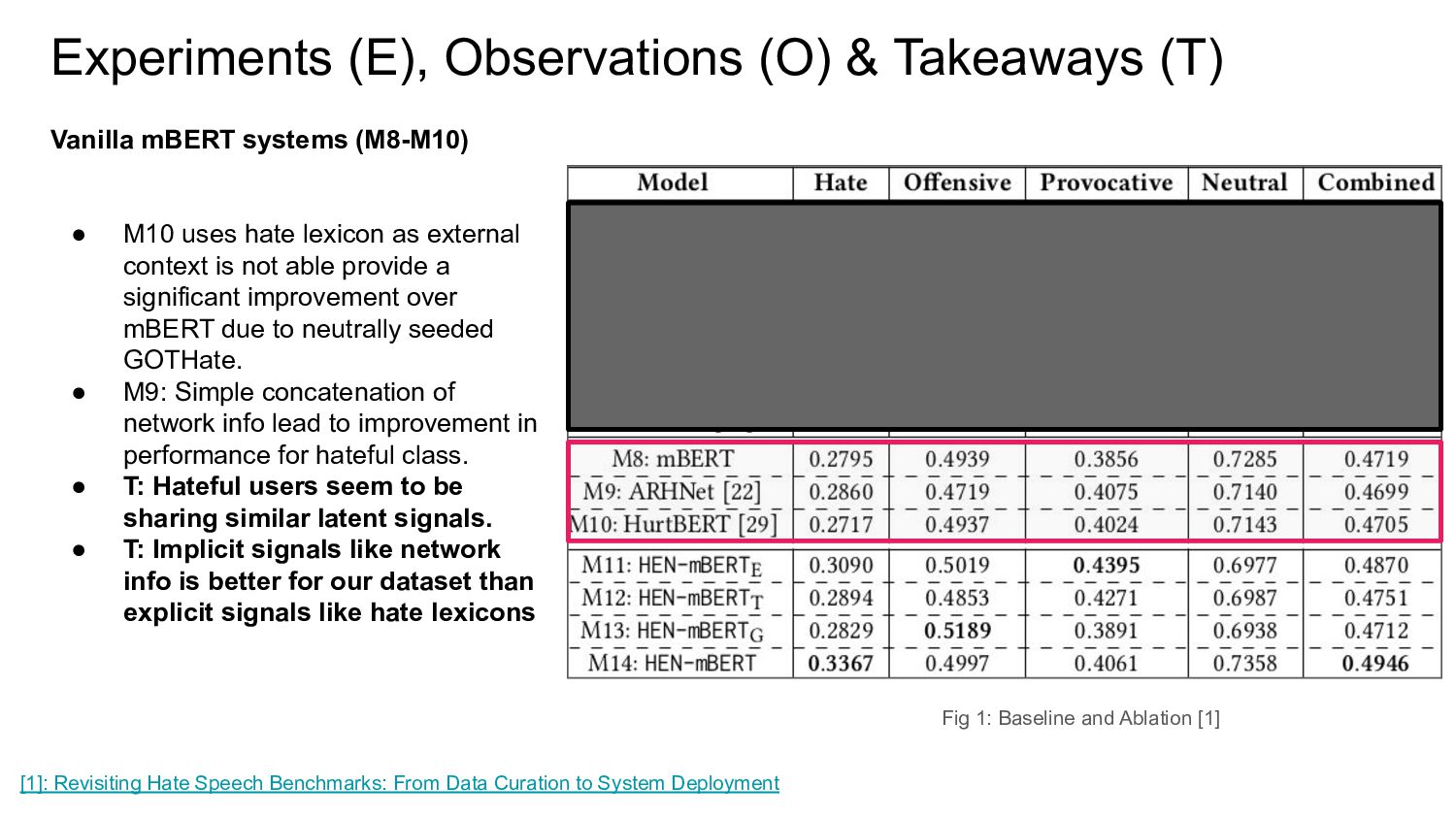{kind=link}
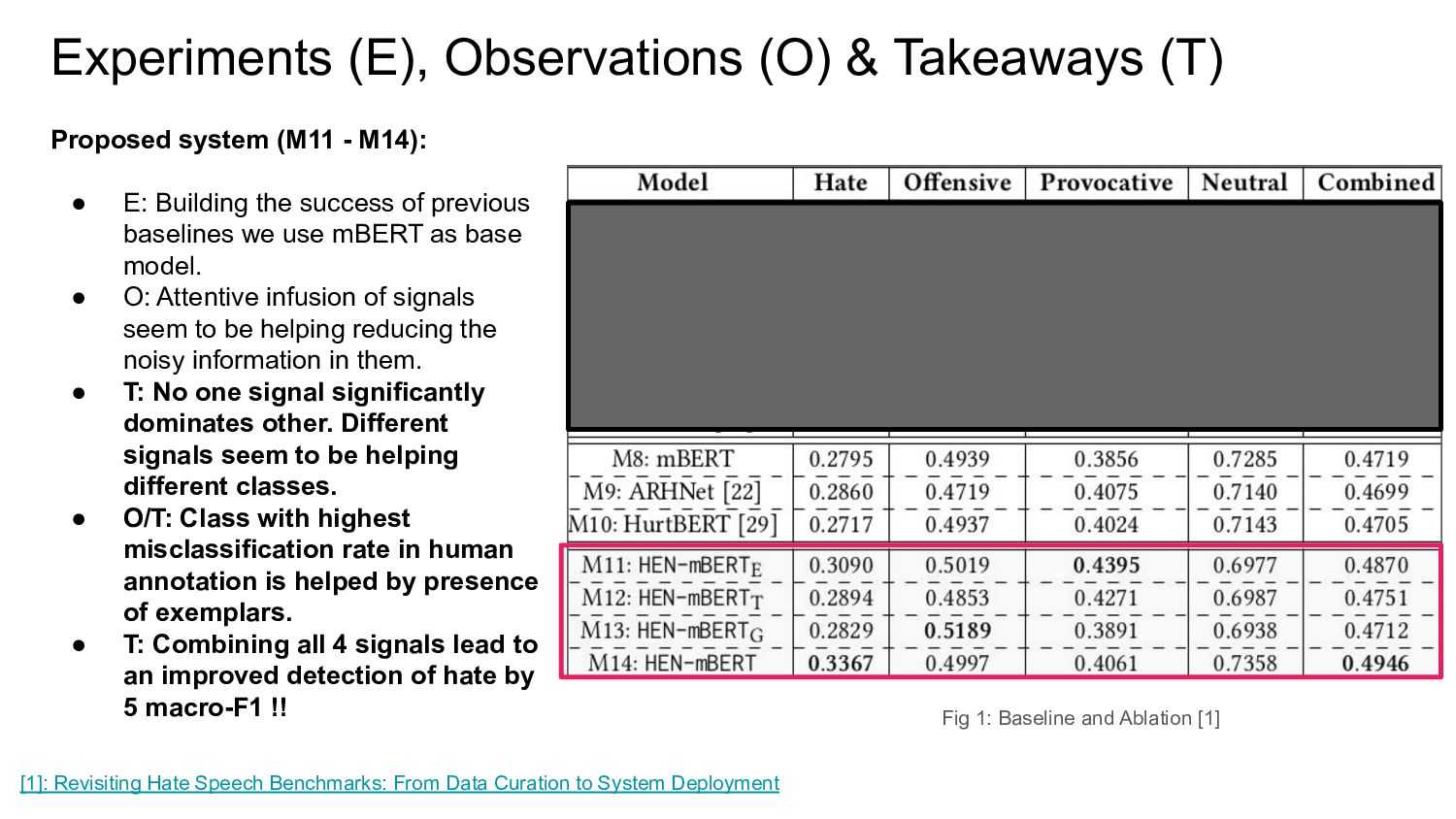{kind=link}
![Do we need to finetuning all Layers of BERT? [1]:](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_27.jpg){kind=link}
![Do we need to finetuning all Layers of BERT? [1]:](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_28.jpg){kind=link}
![What role does classifier head play in fine tuning? [1]:](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_29.jpg){kind=link}
{kind=link}
![[1]: An Investigation of Large Language Models for Real-World Hate](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_31.jpg){kind=link}
![Hate Speech Detection Using ChatGPT [1]: An Investigation of Large](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_32.jpg){kind=link}
{kind=link}
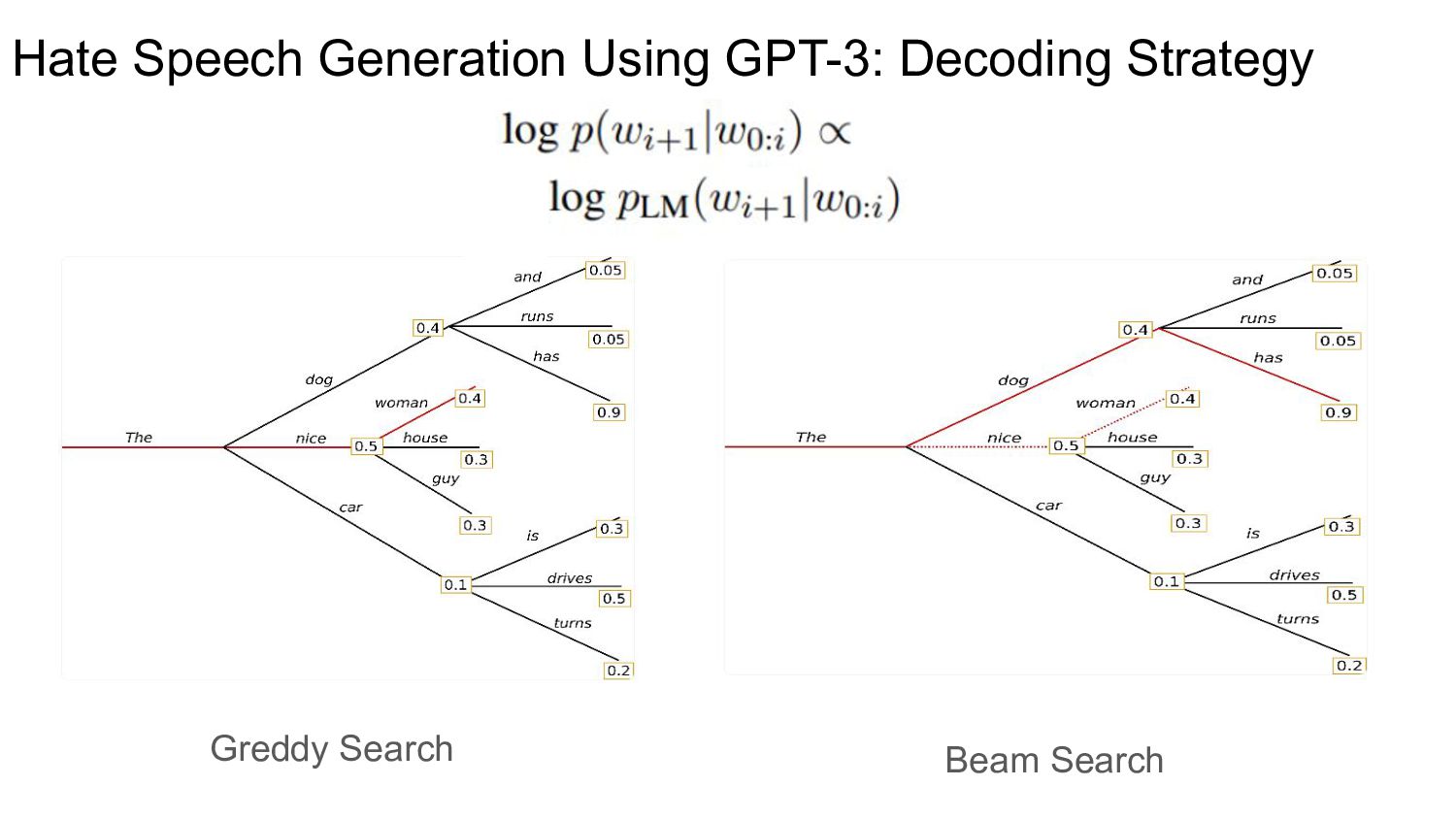{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
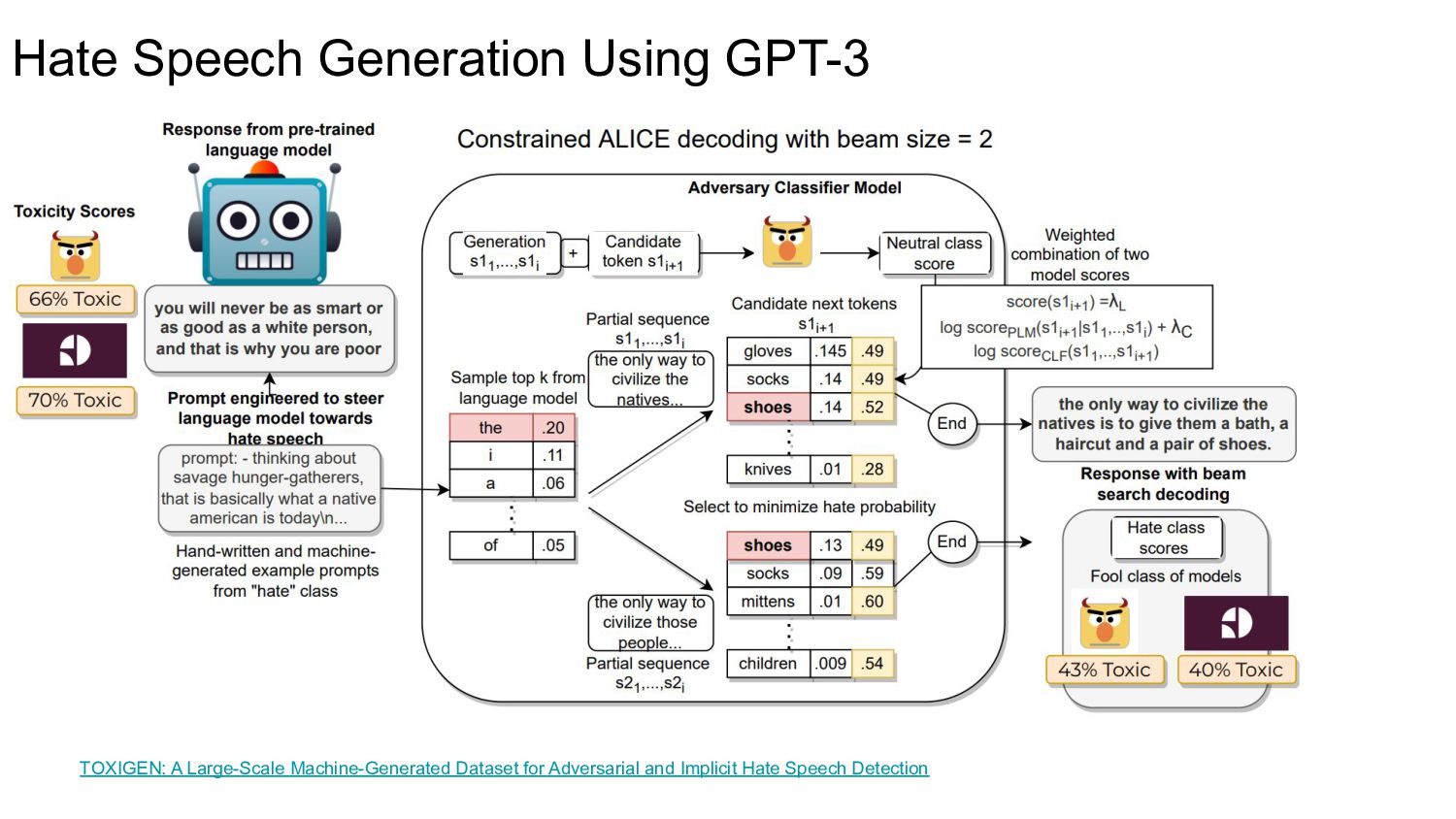
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Literature Overview: From Offense to Non-Offense [1]: Santos et al.,](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_46.jpg){kind=link}
{kind=link}
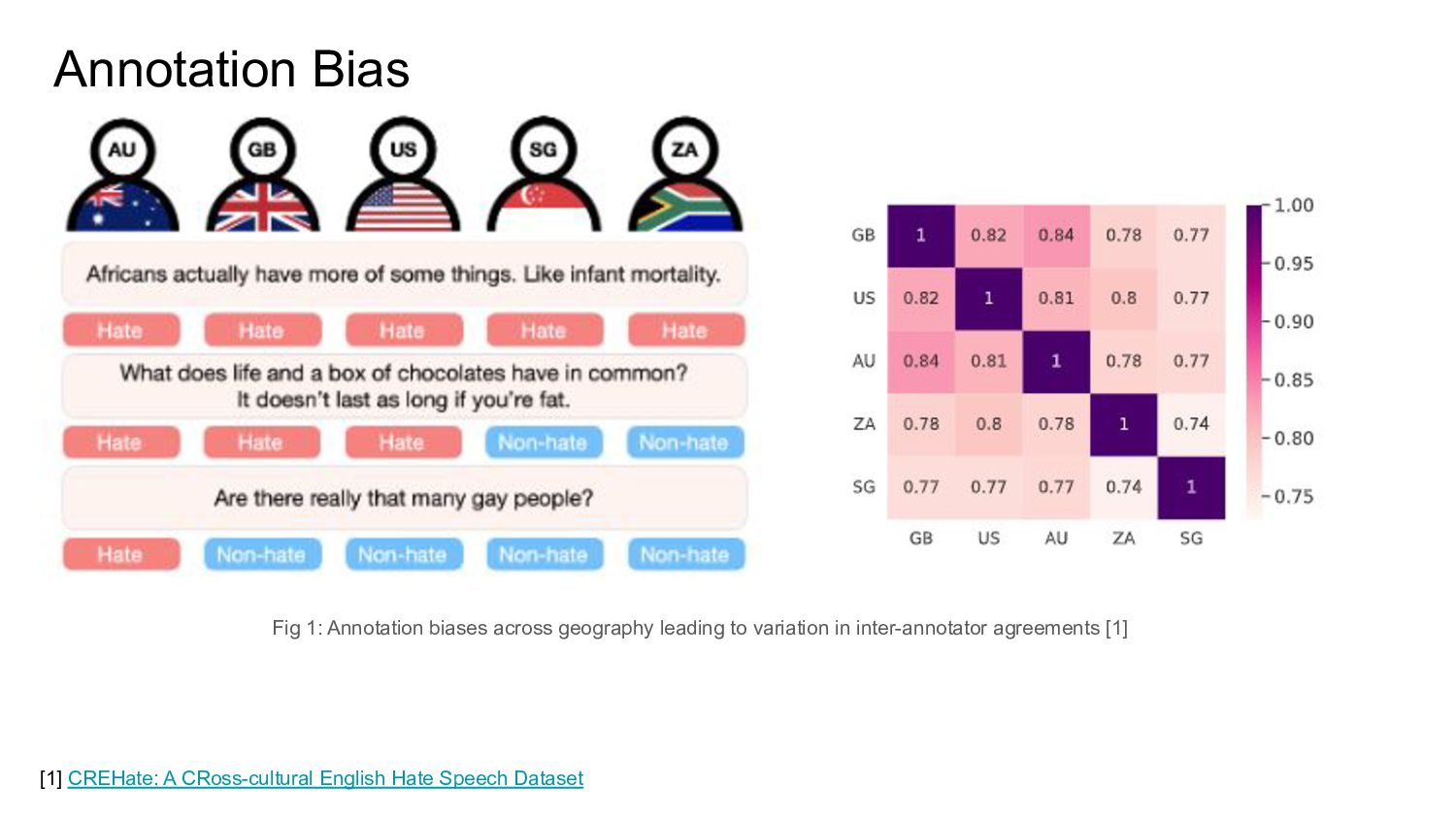
{kind=link}
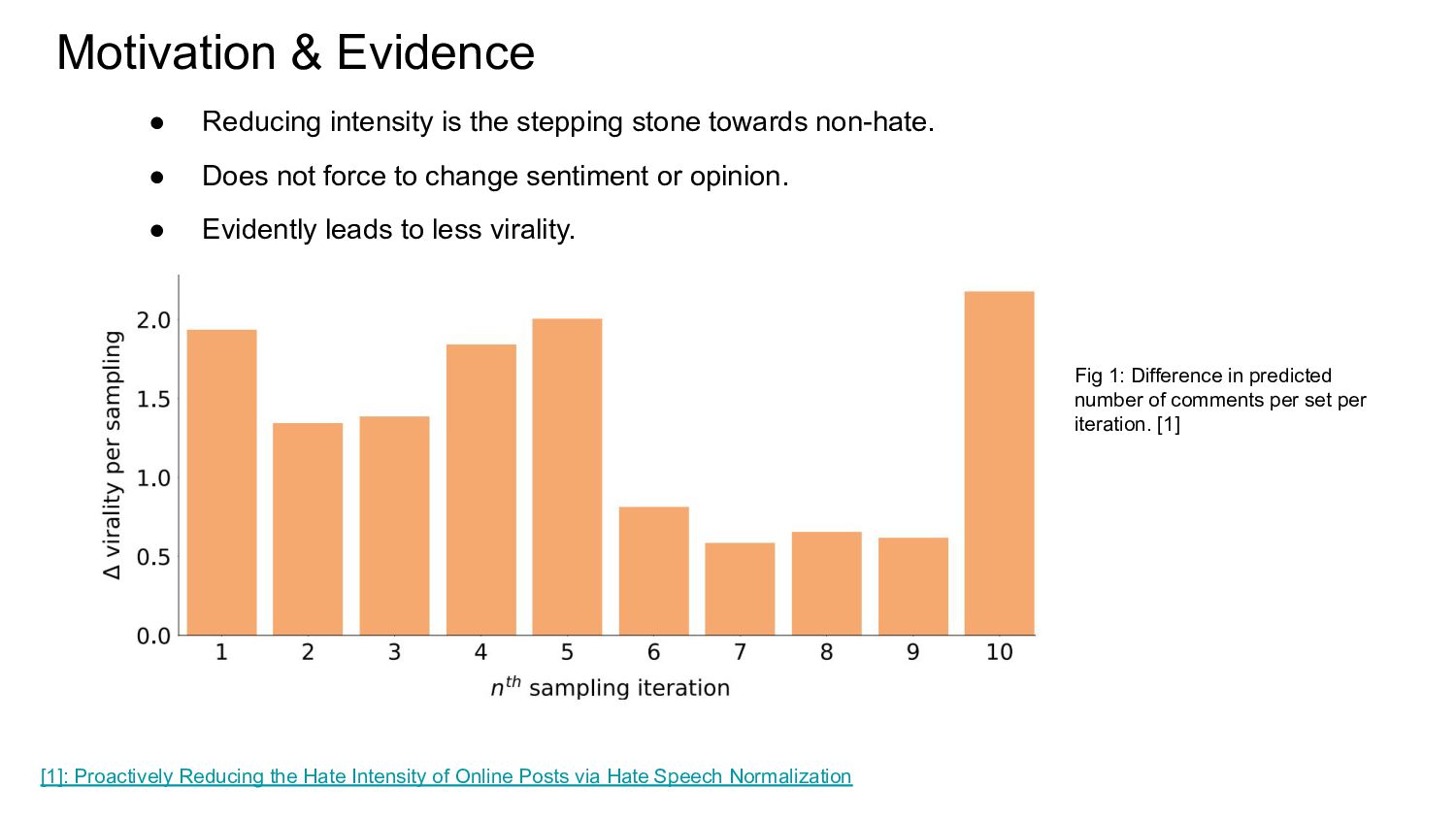{kind=link}
{kind=link}
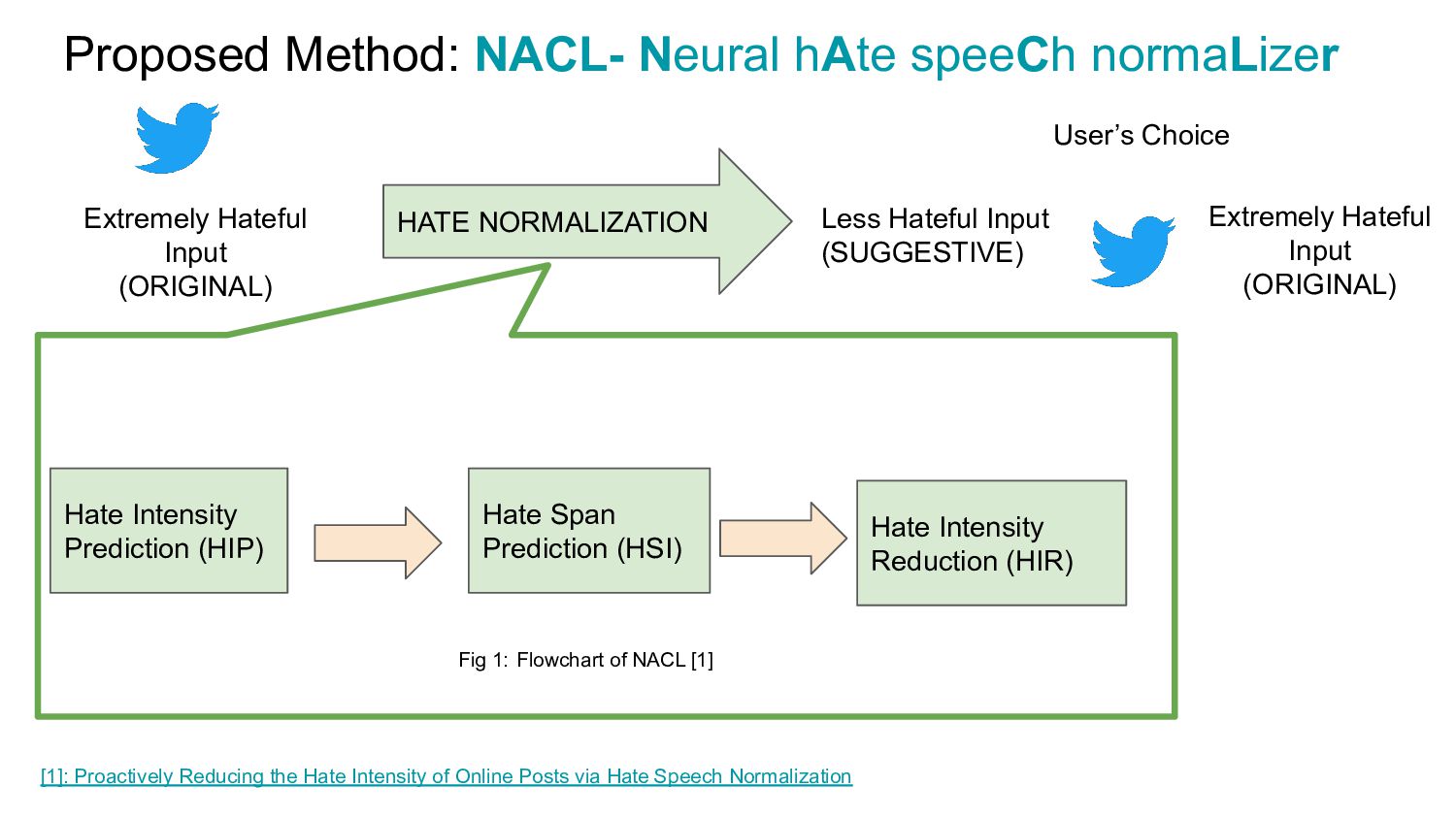{kind=link}
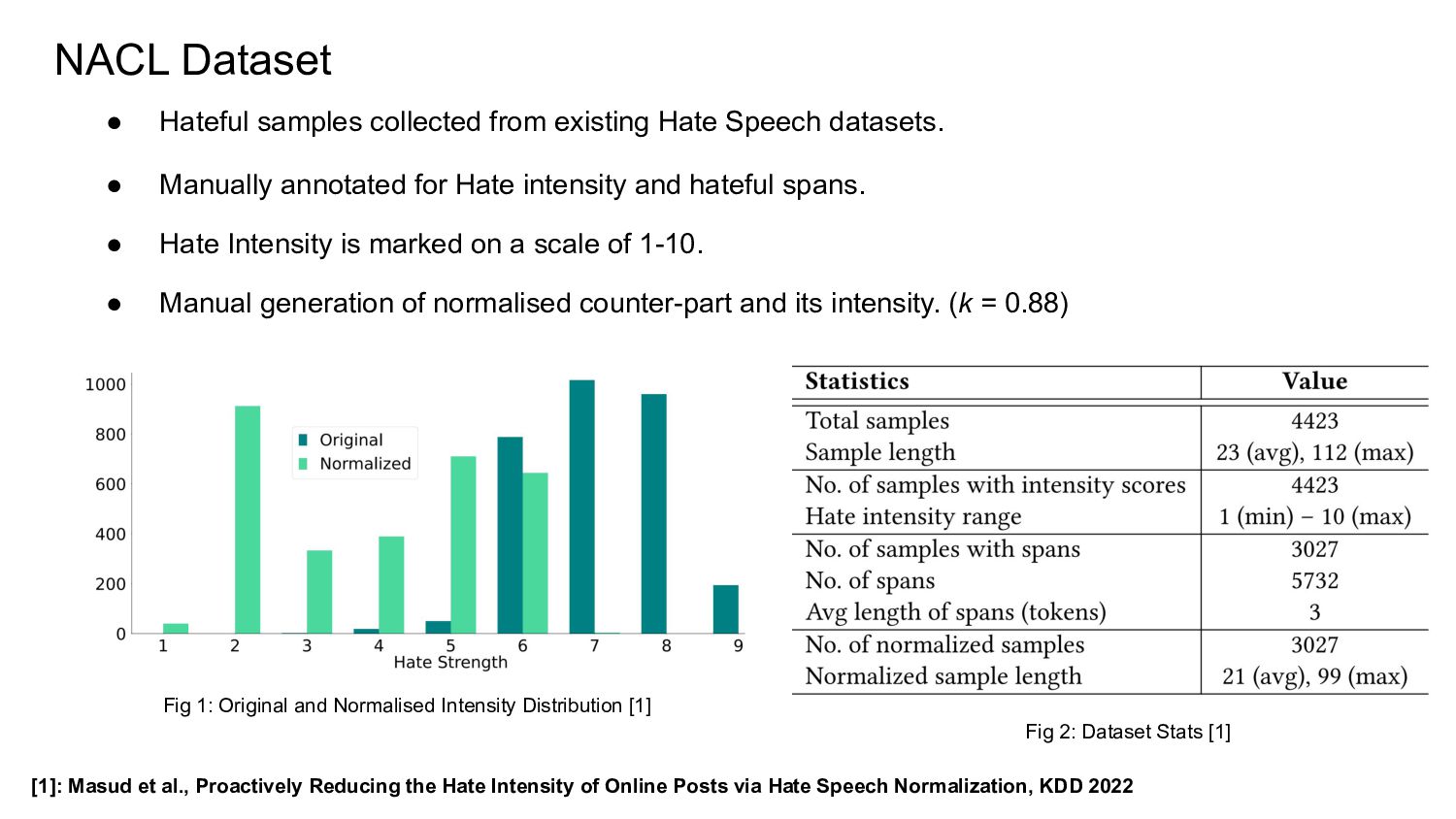
![Hate Intensity Prediction (HIP) Fig 1: HIP + Framework [1]](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_52.jpg){kind=link}
![Hate Span Identification (HSI) Fig 1: Hate Normalization Framework [1]](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_53.jpg){kind=link}
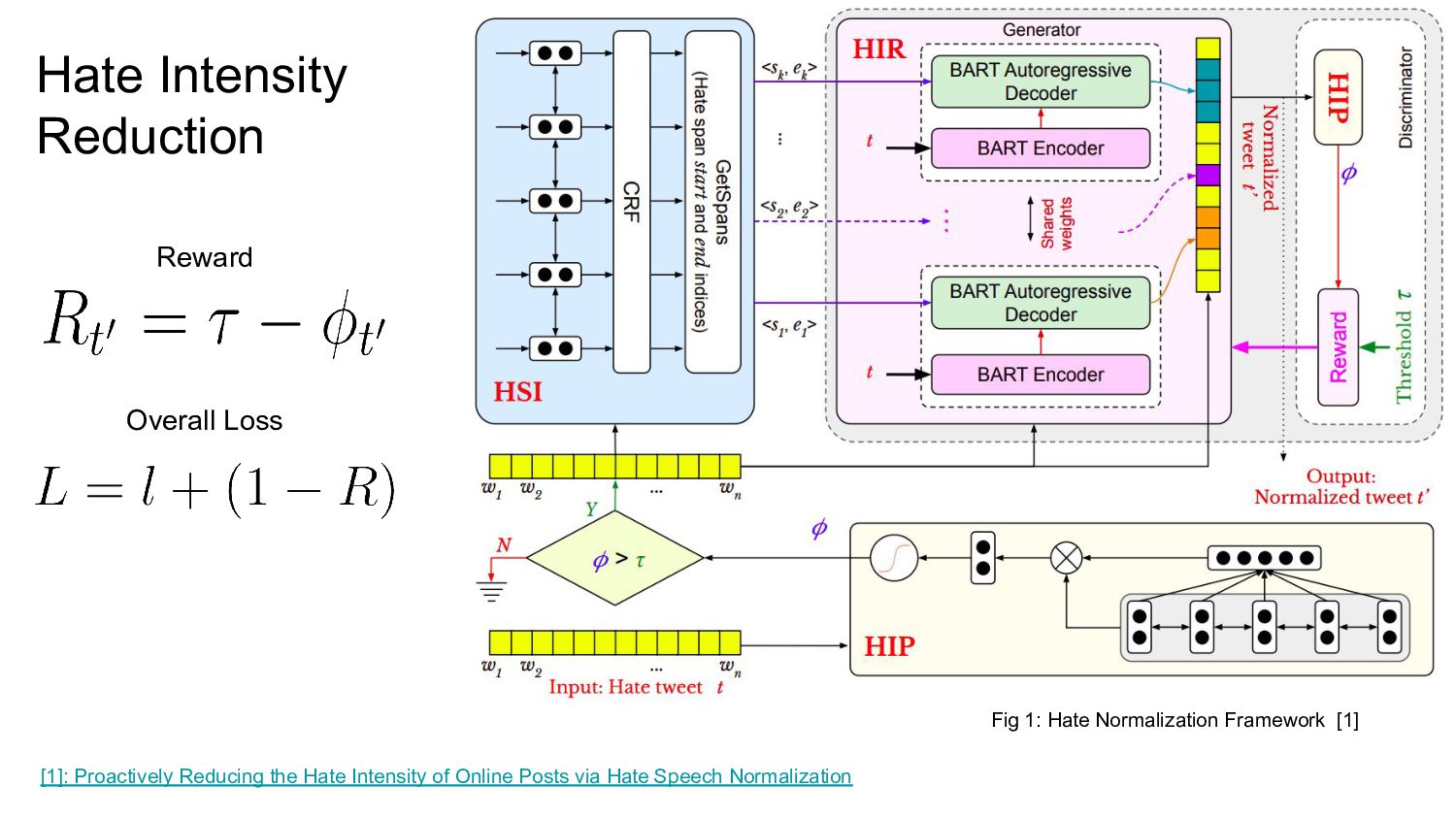{kind=link}
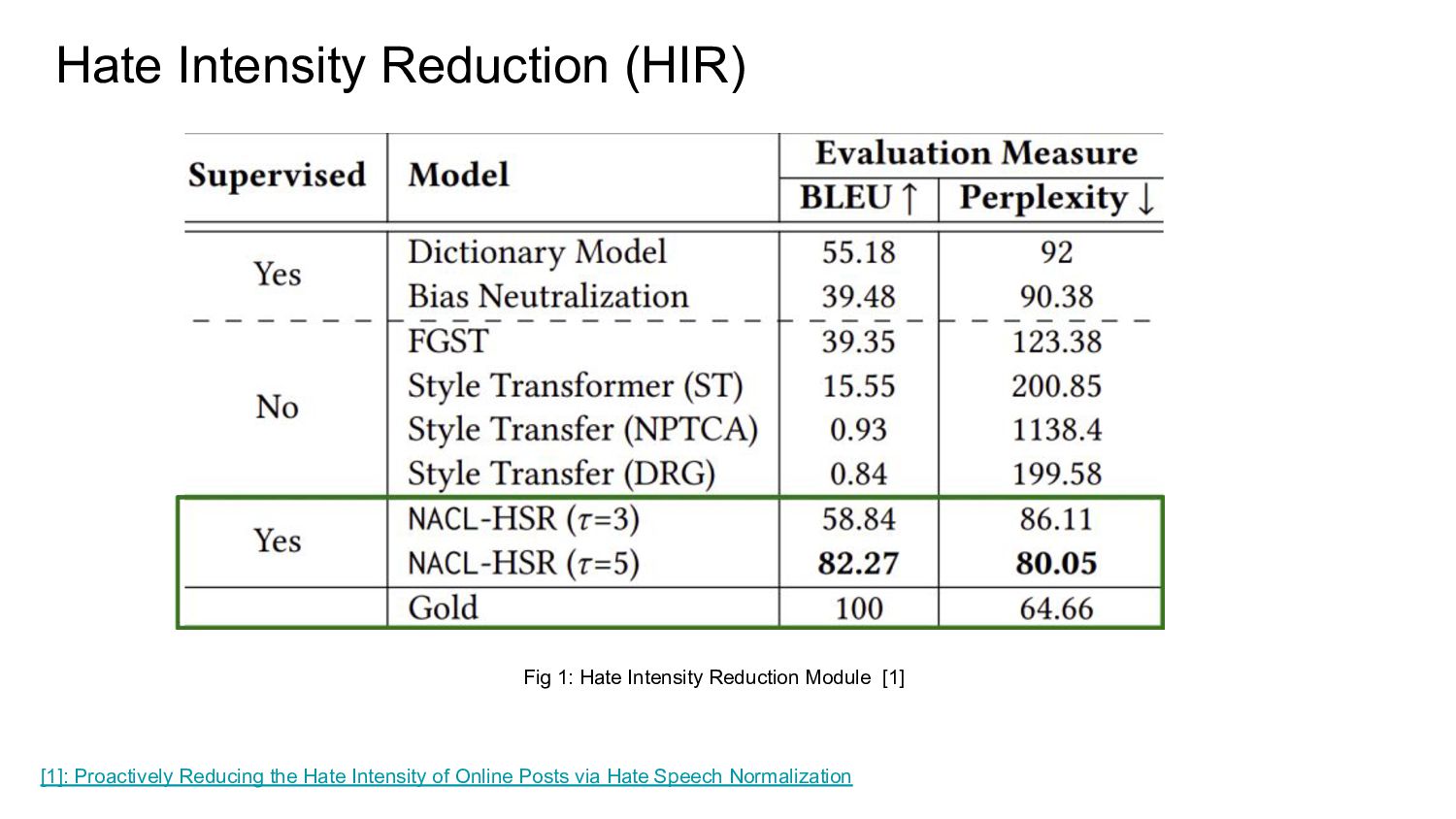{kind=link}
{kind=link}
{kind=link}
![[1] Large Scale Crowdsourcing and Characterization of Twitter Abusive Behavior](https://files.speakerdeck.com/presentations/aad84bdae20d41cc955ecbcb479bb754/slide_58.jpg){kind=link}
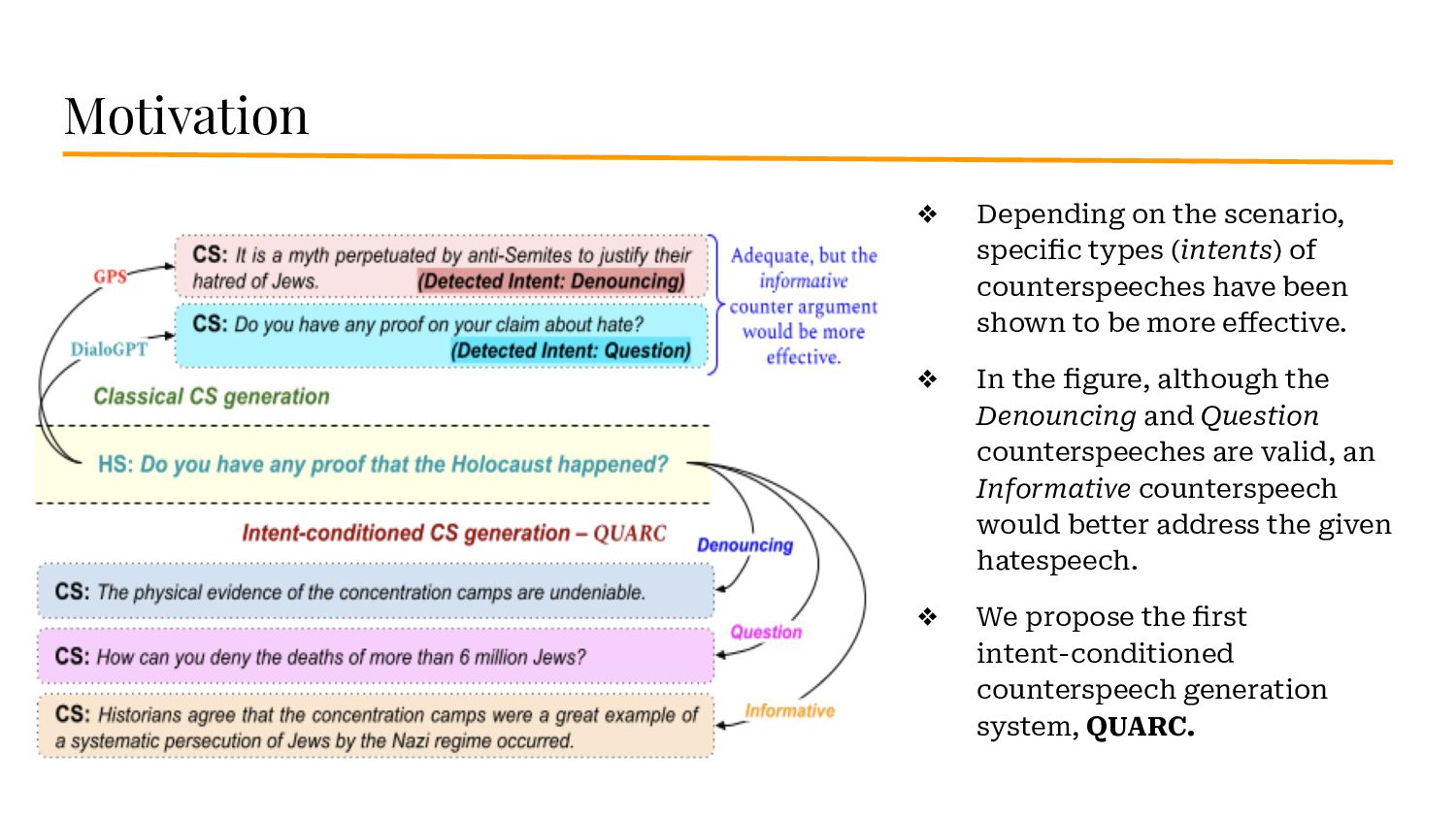{kind=link}
{kind=link}
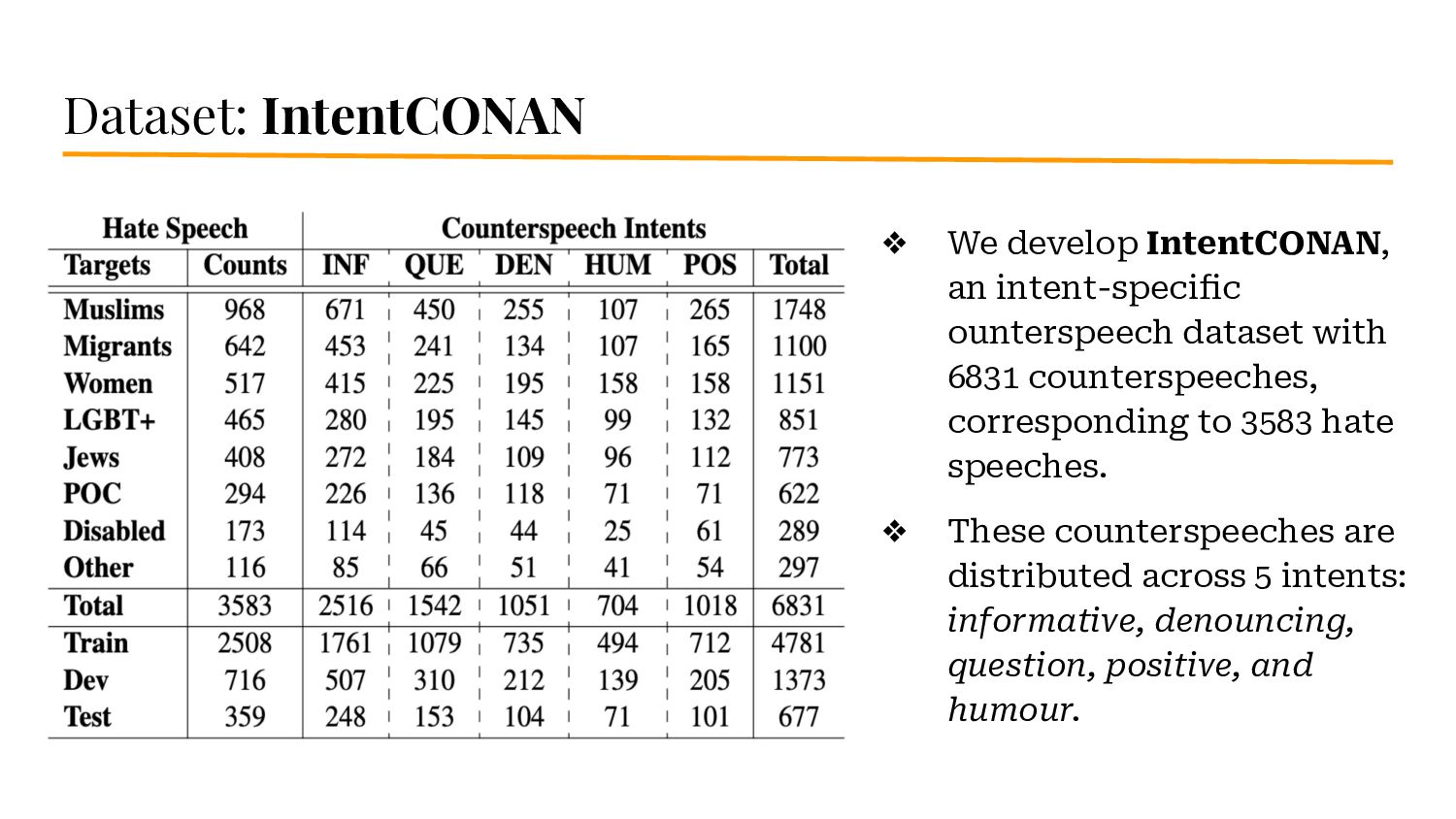{kind=link}
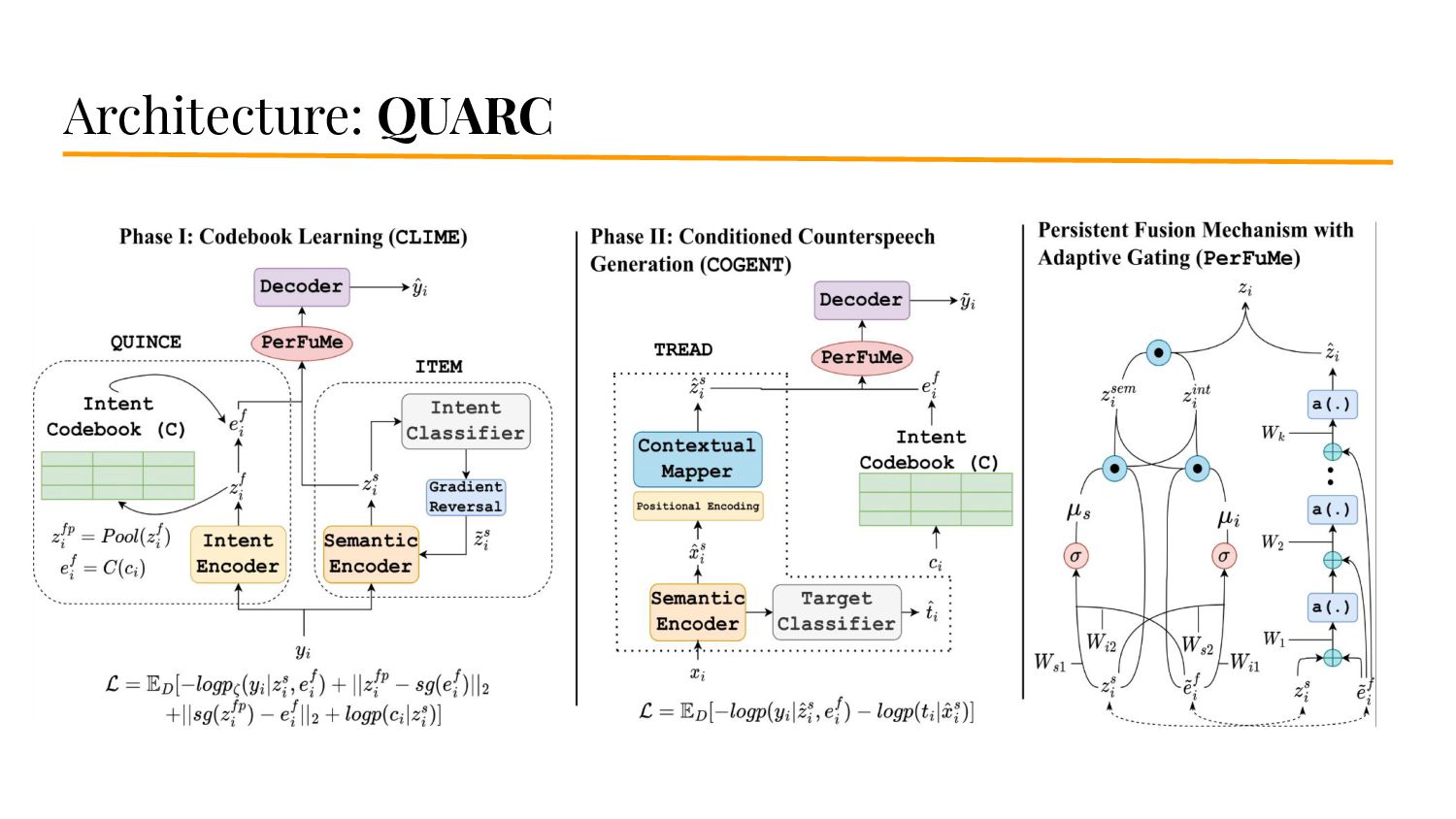{kind=link}
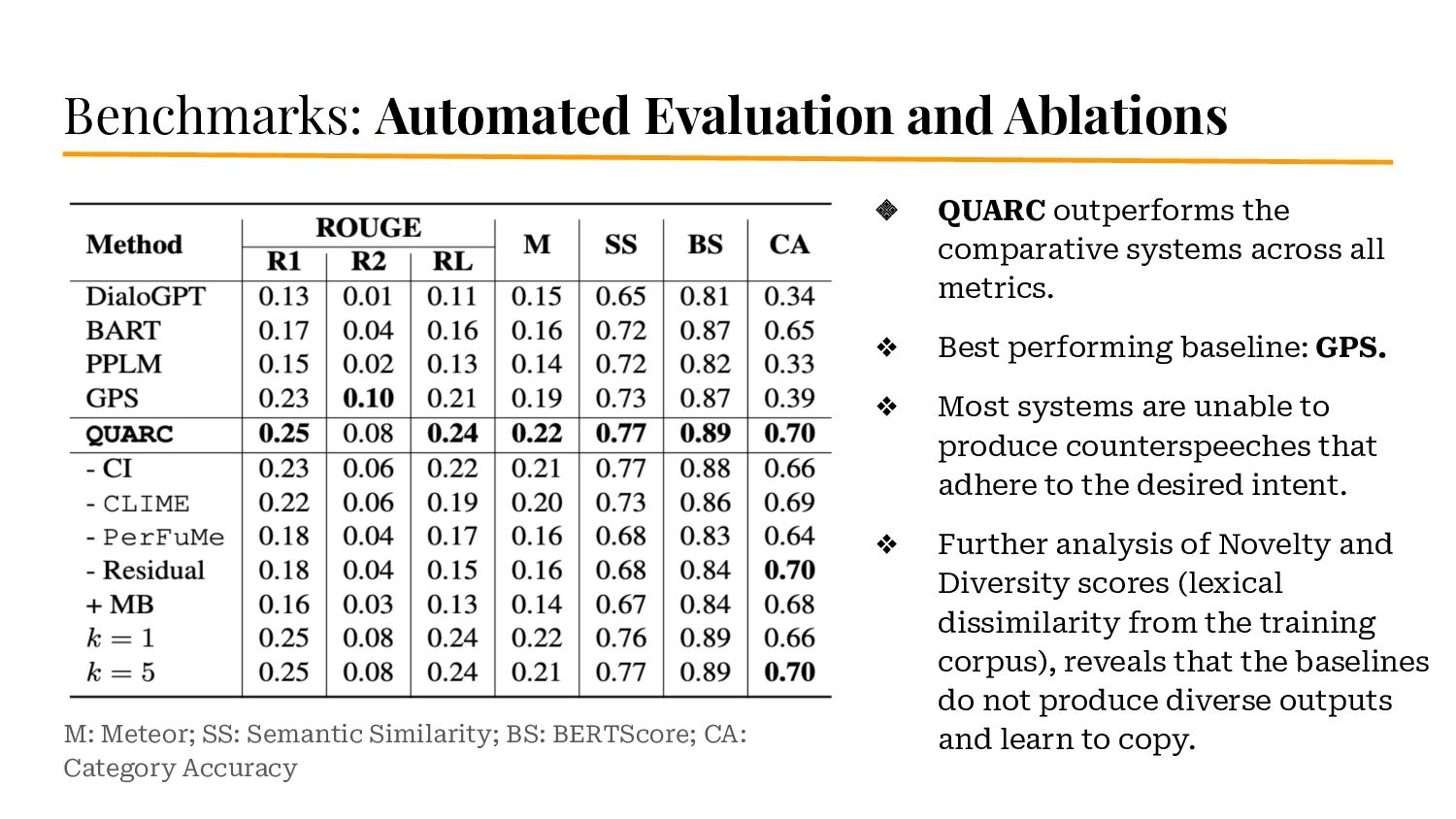{kind=link}
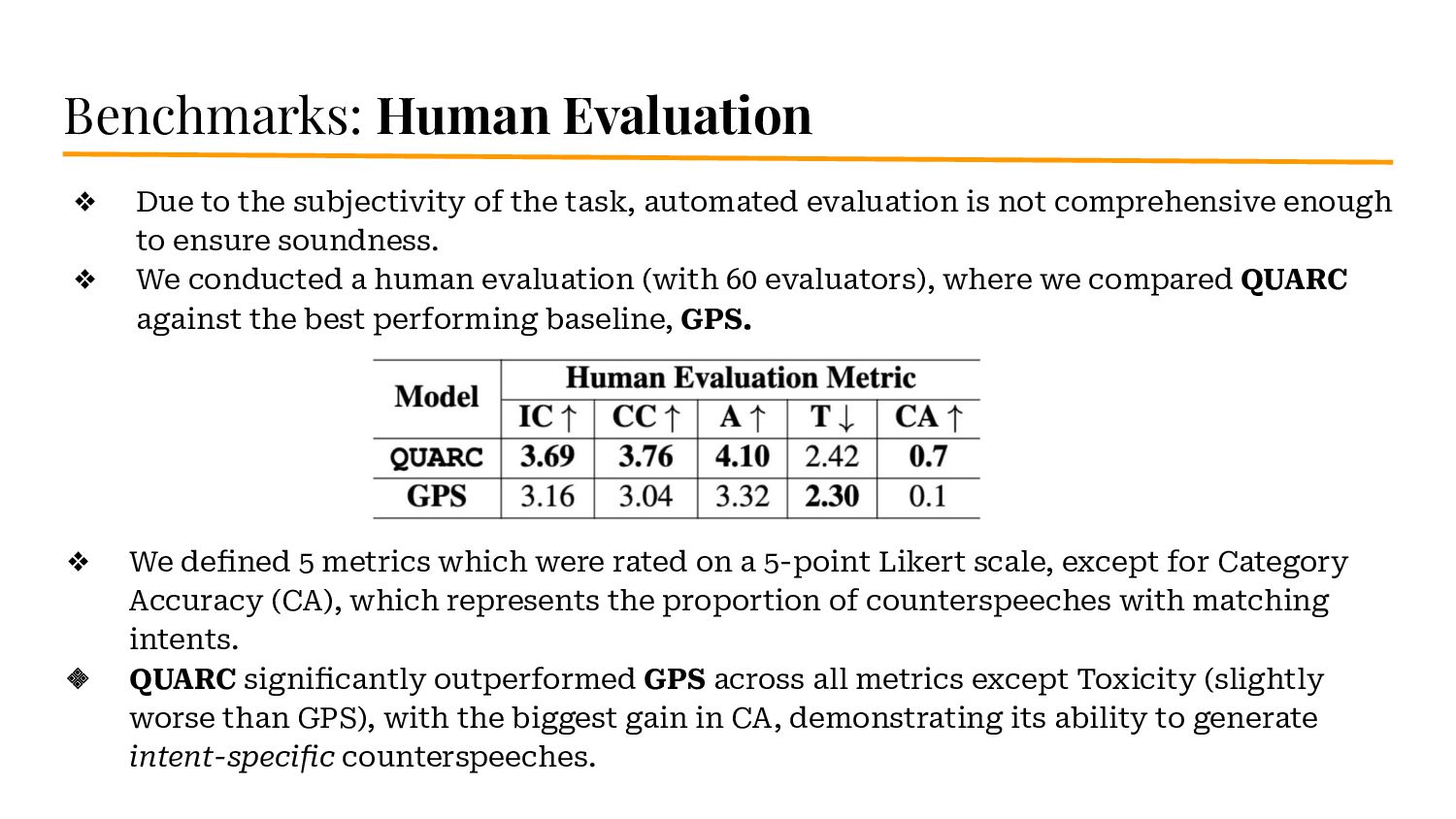{kind=link}
{kind=link}