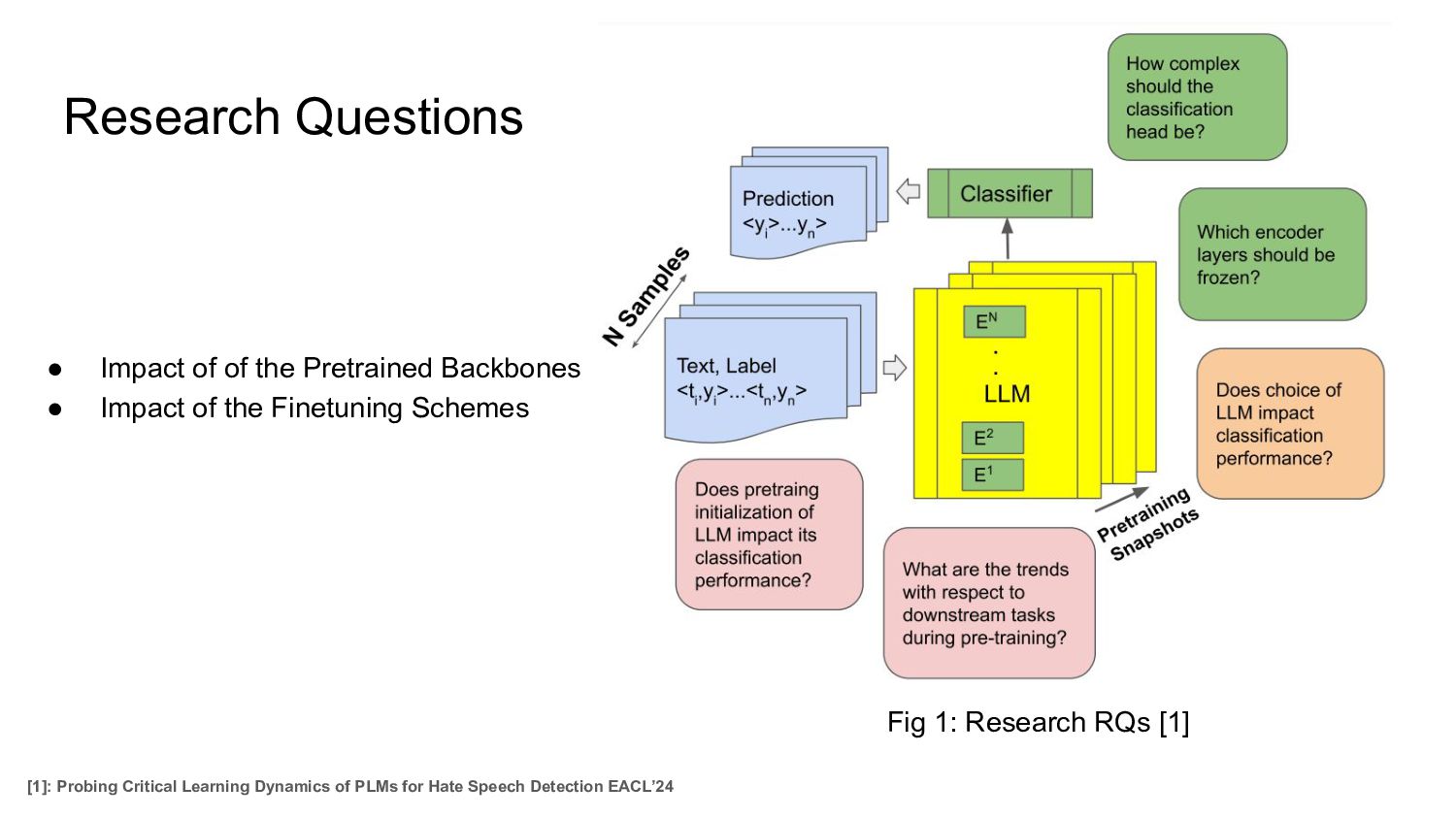
[1]. • There is a surge in LM based systems, finetuned for detecting hate. • Most often these systems either adopt the default parameters, or finetune the parameters for a specific dataset + LM combination. Are there any common trends across datasets and LM combinations when performing hate speech detection as measured by macro F1 performance Fig 1: Online Hate Speech [1]
into hate vs non-hate • 5 BERT based PLMs • 3 Classification Heads ◦ Simple CH: A linear layer followed by Softmax. ◦ Medium CH: Two linear layers followed by Softmax. ◦ Complex CH: Two linear layers and an intermediate dropout layer with a dropout probability ◦ of 0.1, followed by Softmax. • Classification Head seed aka MLP seed: ms = {12, 127, 451}
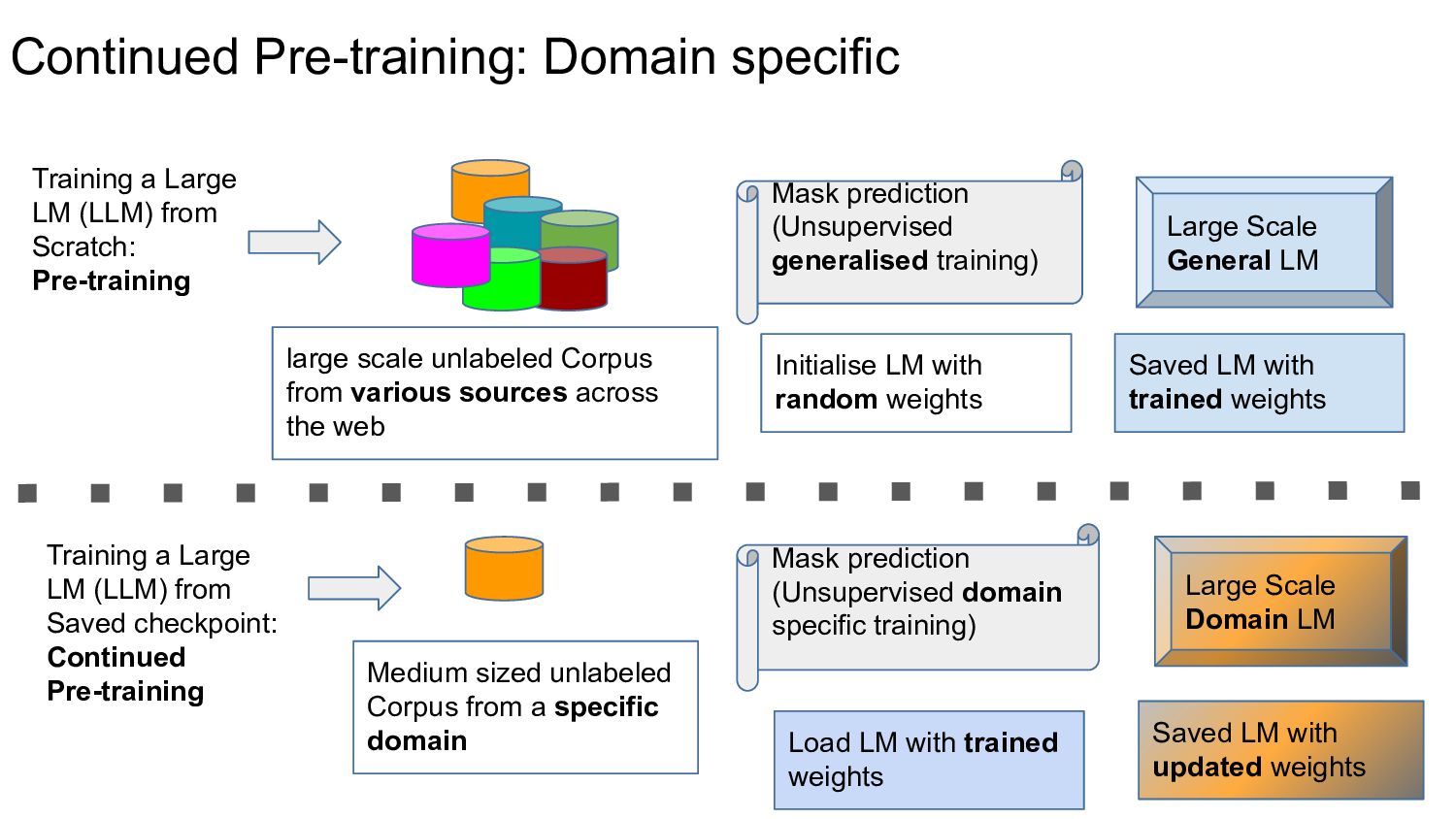
unlabeled Corpus from various sources across the web Mask prediction (Unsupervised generalised training) Training a Large LM (LLM) from Scratch: Pre-training Initialise LM with random weights Saved LM with trained weights Medium sized unlabeled Corpus from a specific domain Mask prediction (Unsupervised domain specific training) Training a Large LM (LLM) from Saved checkpoint: Continued Pre-training Load LM with trained weights Large Scale Domain LM Saved LM with updated weights
to perform MLM. [1] 2. BertTweet -> Over 845M tweets used to perform MLM. [2] 3. HateBERT -> Over 1M offensive reddit posts to perform MLM. [3] BERT variants for different context via MLM Fig 1: MLM top 3 candidates for the templates “Women are [MASK.]” [3] Fig 2: Performance gain of HateBERT over BERT for hate classification [3] [1]: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [2]: BERTweet: A pre-trained language model for English Tweets [3]: HateBERT: Retraining BERT for Abusive Language Detection in English
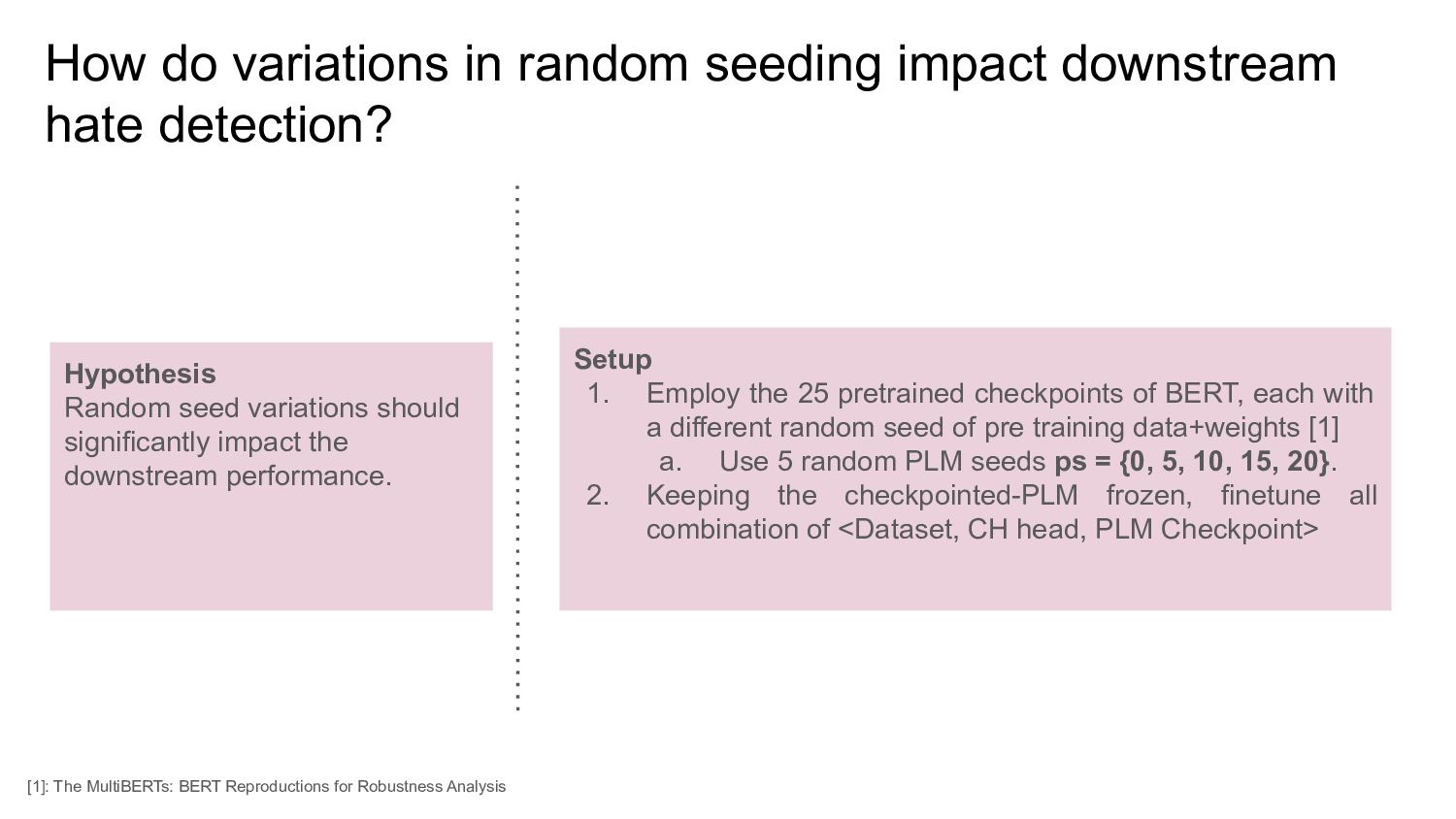
Hypothesis Random seed variations should significantly impact the downstream performance. Setup 1. Employ the 25 pretrained checkpoints of BERT, each with a different random seed of pre training data+weights [1] a. Use 5 random PLM seeds ps = {0, 5, 10, 15, 20}. 2. Keeping the checkpointed-PLM frozen, finetune all combination of <Dataset, CH head, PLM Checkpoint> [1]: The MultiBERTs: BERT Reproductions for Robustness Analysis
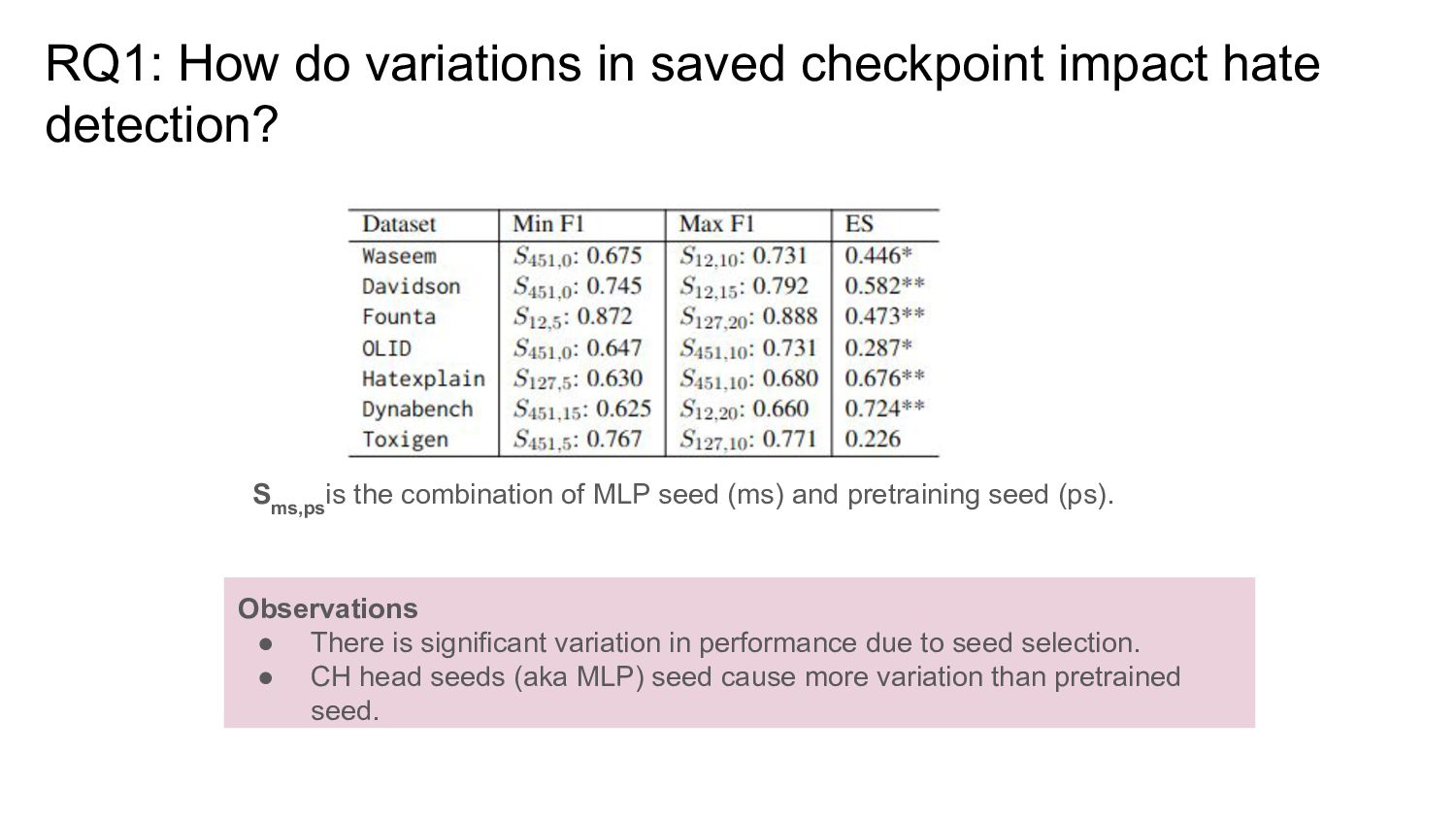
seed selection. • CH head seeds (aka MLP) seed cause more variation than pretrained seed. S ms,ps is the combination of MLP seed (ms) and pretraining seed (ps). RQ1: How do variations in saved checkpoint impact hate detection?
Hypothesis Does default assumption that best/last pre trained checkpoint leads to highest downstream task hold when compared against intermediate checkpoints? Setup 1. Employ the 84 intermediate pretrained checkpoints, one for each training epoch of the RoBERTa English [1] 2. Employ the Simple and Complex CH. 3. Keeping the checkpointed-PLM frozen, finetune all combination of <Dataset, CH head, PLM Checkpoint> [1]: Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions
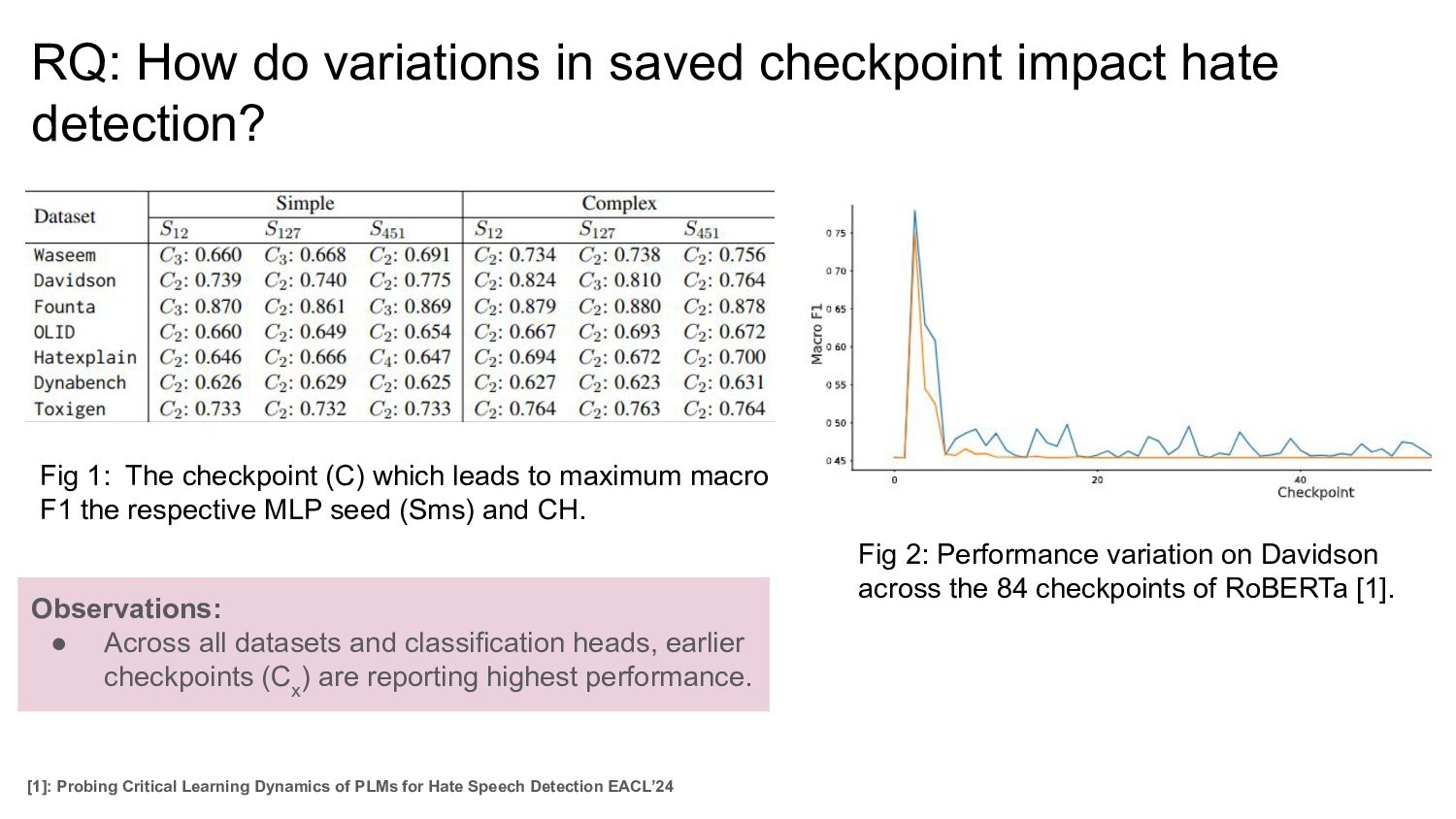
Fig 1: The checkpoint (C) which leads to maximum macro F1 the respective MLP seed (Sms) and CH. Observations: • Across all datasets and classification heads, earlier checkpoints (C x ) are reporting highest performance. [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24 Fig 2: Performance variation on Davidson across the 84 checkpoints of RoBERTa [1].
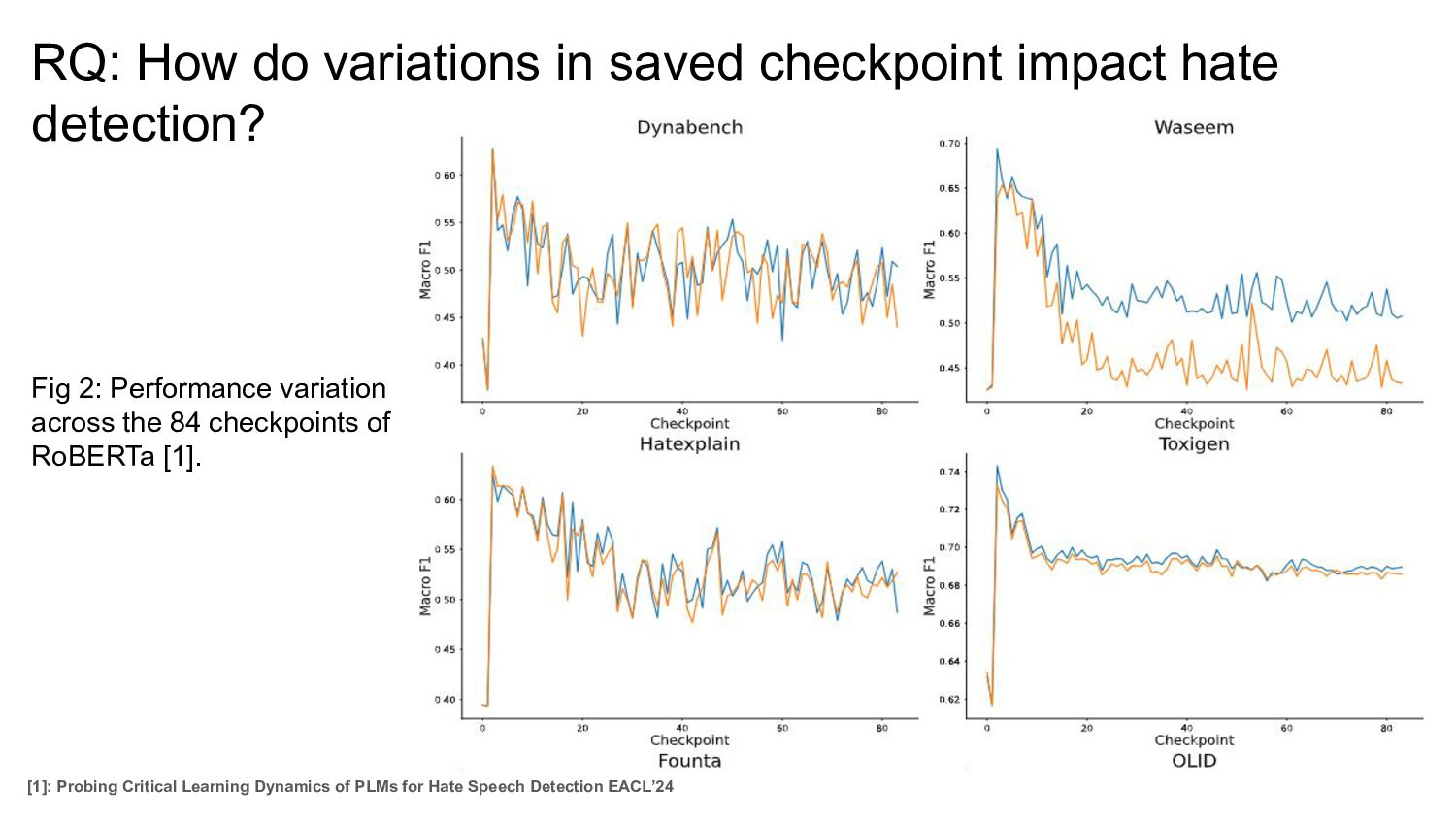
Fig 2: Performance variation across the 84 checkpoints of RoBERTa [1]. [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24
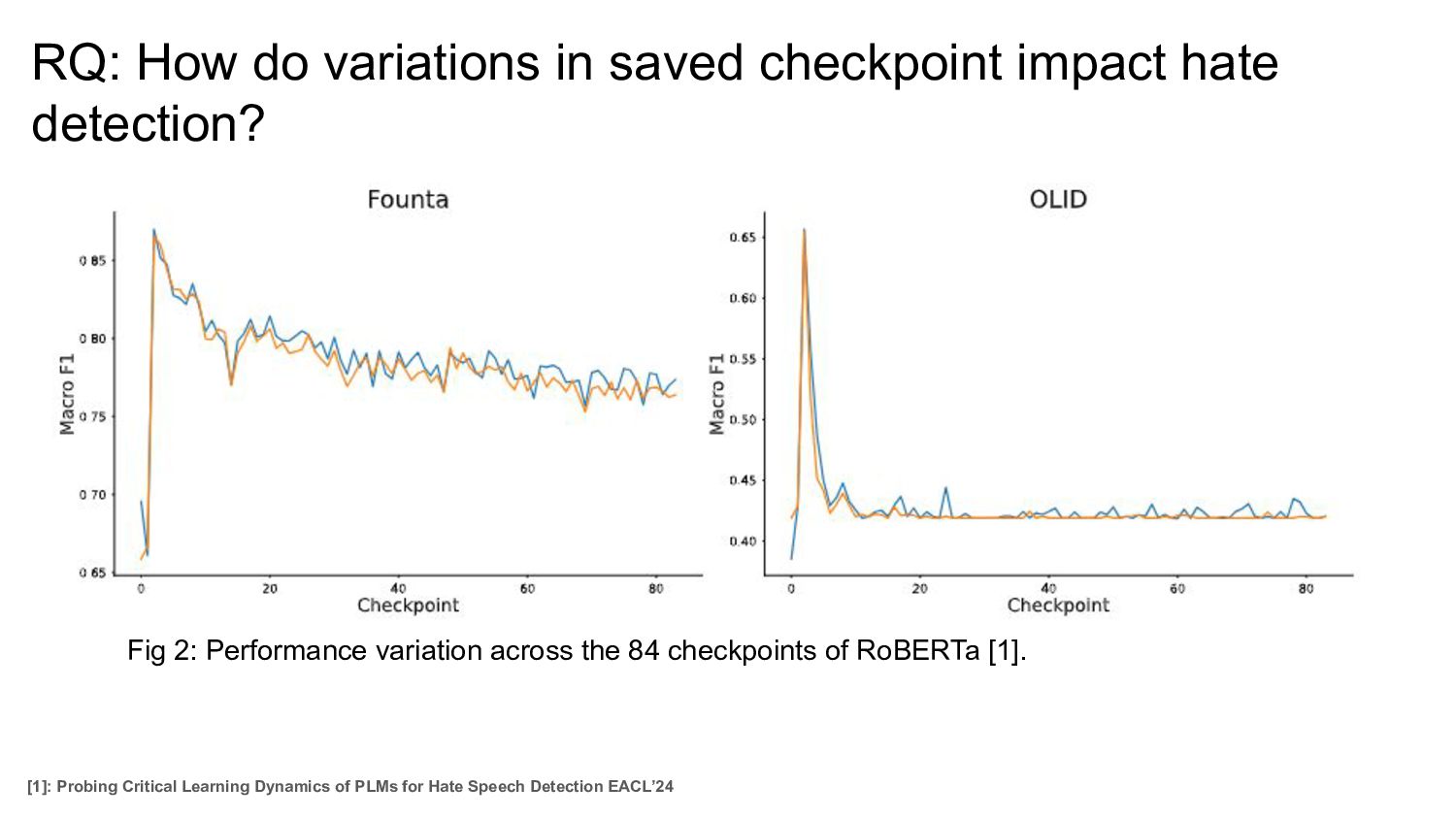
Fig 2: Performance variation across the 84 checkpoints of RoBERTa [1]. [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24
Takeaway • Not all downstream tasks require a full fledged pretraining. • Can intermediate validation test on these task can produce more cost effective PLMs?
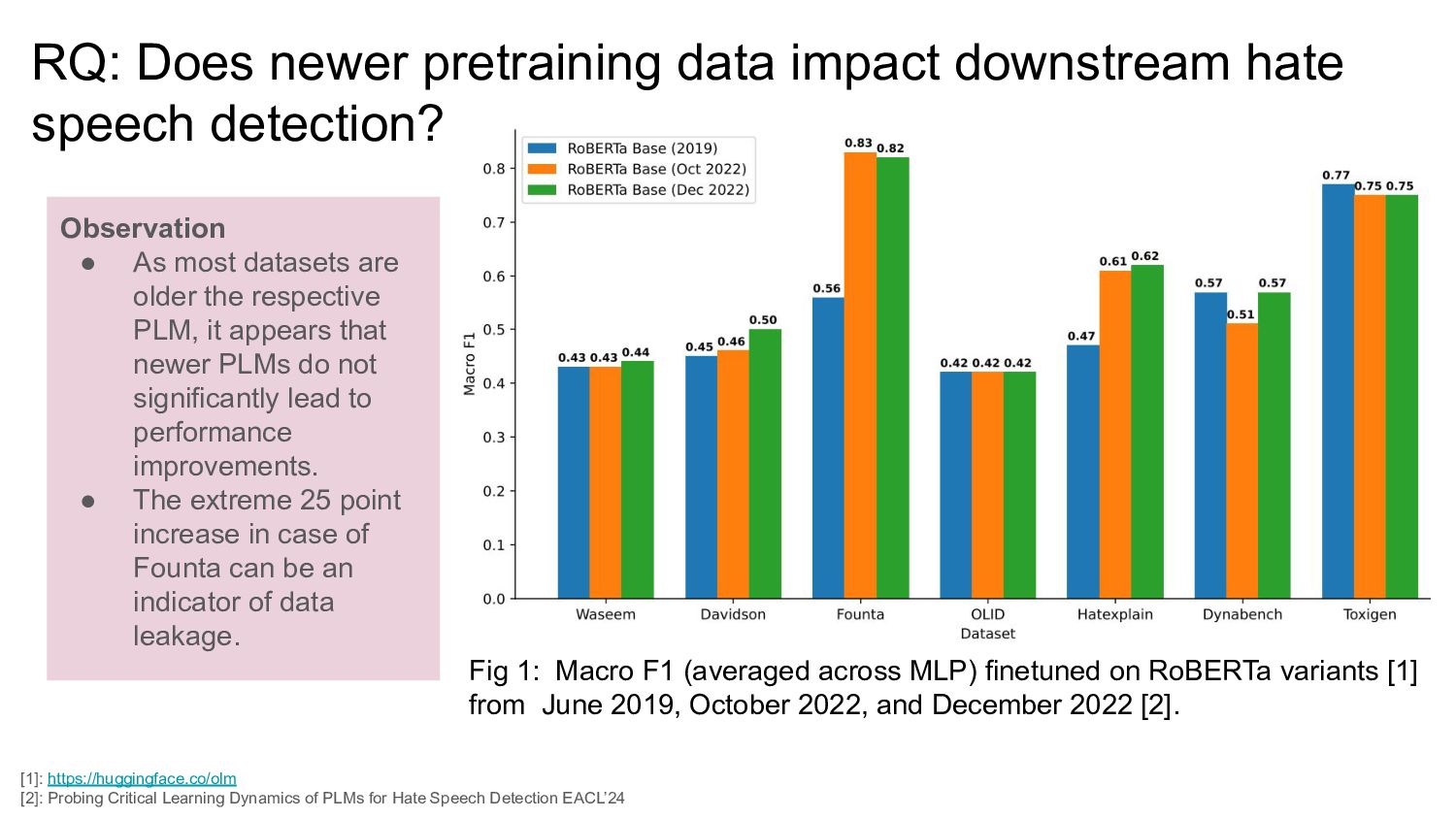
Hypothesis PLMs trained on more recent data should capture the emerging hateful world knowledge and enhance the detection of hate. Setup 1. Employ incrementally updated checkpoints from Hugginface OLM on RoBERTa English [1] 2. Keeping the checkpointed-PLM frozen, finetune all combination of <Dataset, Simple CH head> [1]: https://huggingface.co/olm
Observation • As most datasets are older the respective PLM, it appears that newer PLMs do not significantly lead to performance improvements. • The extreme 25 point increase in case of Founta can be an indicator of data leakage. [1]: https://huggingface.co/olm [2]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24 Fig 1: Macro F1 (averaged across MLP) finetuned on RoBERTa variants [1] from June 2019, October 2022, and December 2022 [2].
Takeaways • Community also needs to develop upon the likes of HateCheck [1] test sets to standardise testing of newer LLMs against hate speech. • How do we scale this dynamically and continually, across languages, topics and cultural sensitivities? • How do we check for data leakage of existing hate speech datasets (which are curated from web), in the pretraining datasets of newer LMs? [1]: HateCheck: Functional Tests for Hate Speech Detection Models
Hypothesis Different layers or groups of layers in the PLM will be of varying importance for hate detection. Setup 1. Freeze all layer(s) expect the one(s) being probed. 2. Finetune all combination of <Dataset, Simple CH head, PLM>
https://iq.opengenus.org/bert-base-vs-bert-large/ Fig 1: BERT Encoders [1] Fig 1: BERT Base vs Large in terms of encoding layers [1] Different layers encode the semantics to a different extend
Fig 1: The best and worst perming layer for different BERT variants. [1] [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24 Observations: • Excluding mBERT, trainable higher layers (closer to the classification head) lead to higher macro-F1 for most BERT-variants (except Davidson and Founta!), the trend is significant for 5 dataset.
Fig 1: The best and worst perming layer for different BERT variants. [1] [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24 Observations: • mBERT’s highest performance for a dataset lags behind other BERT variants. • Further for mBERT middle layers seem to be consistently performing better.
Observations: • The impact of region (consecutive group of layers) wise Freezing (F) i.e trainable=False or non-freezing (NF) i.e trainable=True depends more on the dataset rather than the underlying BERT variant.
[1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24 Takeaways: • Layer grouping is a easier strategy to validate than single layer. • Employ mBERT only when the dataset is multilingual, otherwise you will suffer a loss of performance on English datasets.
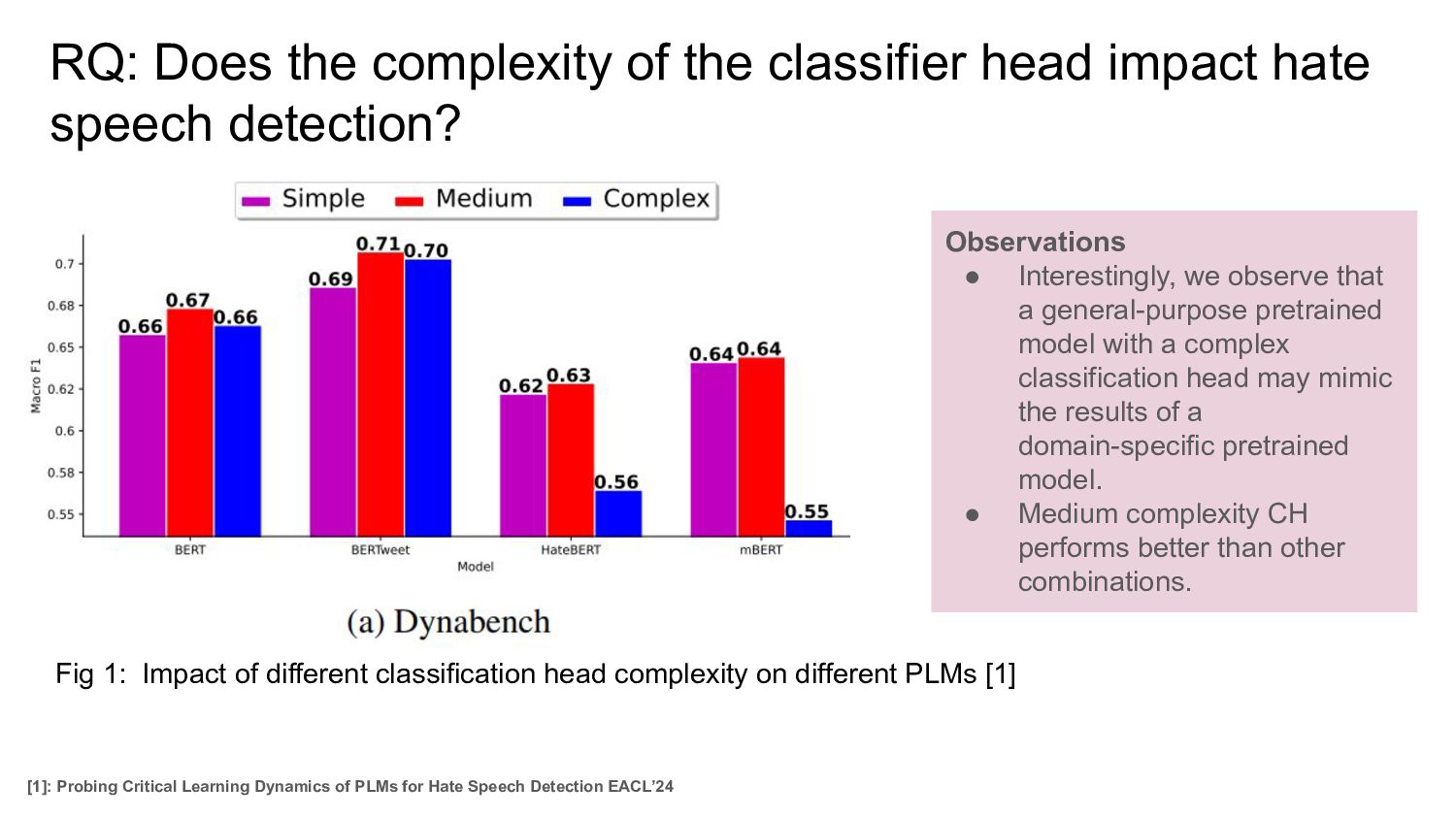
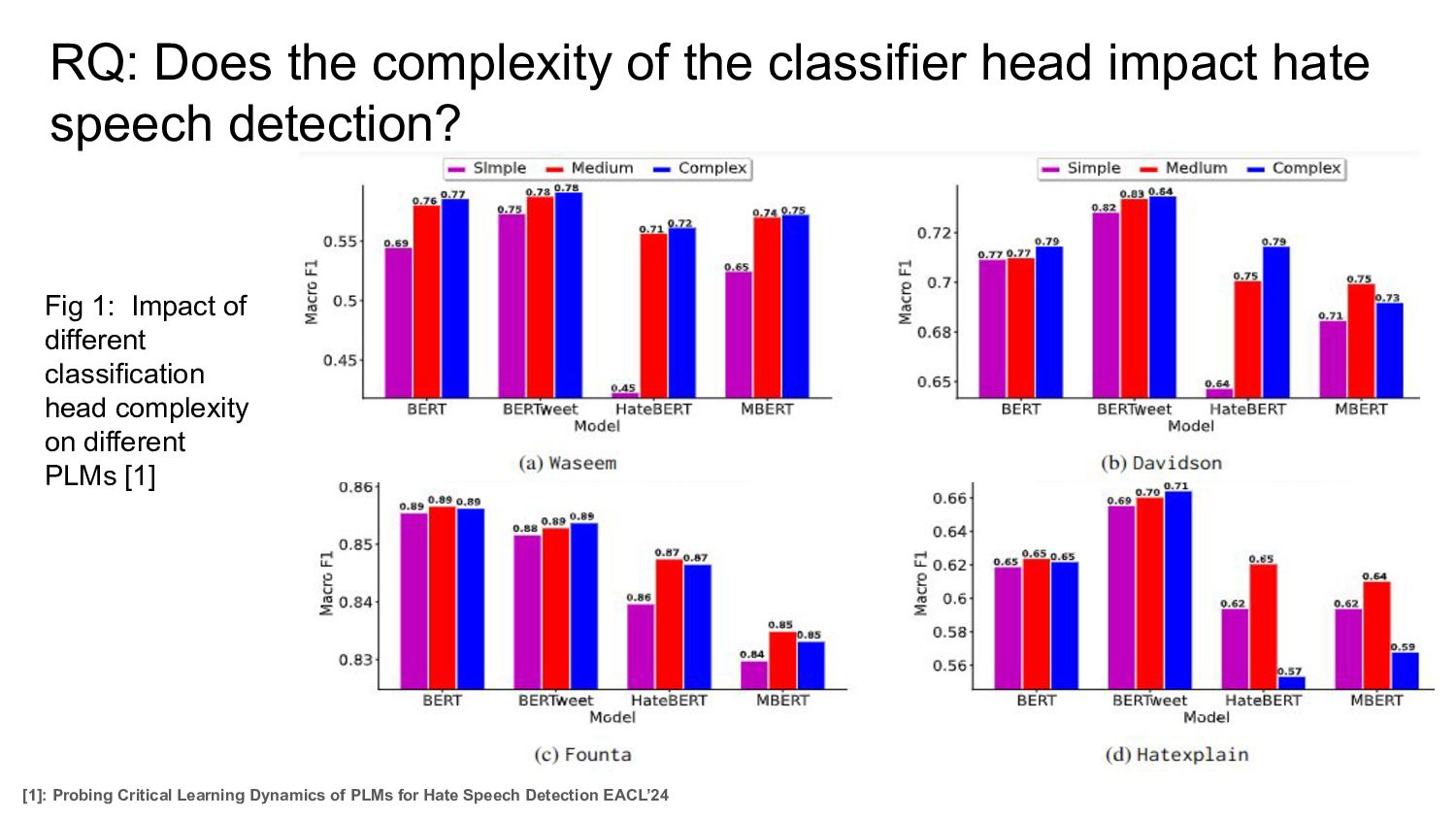
speech detection? Hypothesis Increasing the complexity of classification head should lead to an increase in performance. Setup 1. Keeping the base-PLM frozen run for all combination of <dataset, PLM, and classification head>, where the CH complexity is among: Simple < Medium < Complex
speech detection? Observations • Interestingly, we observe that a general-purpose pretrained model with a complex classification head may mimic the results of a domain-specific pretrained model. • Medium complexity CH performs better than other combinations. Fig 1: Impact of different classification head complexity on different PLMs [1] [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24
PLMs [1] RQ: Does the complexity of the classifier head impact hate speech detection? [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24
speech detection? Takeaways: • There is a saturation in performance of classifier head complexity, does not help beyond a point. • BERTweet seems to be performing better than HateBERT. We suggest that authors employing HateBERT also test their experiments on BERTweet. • To what extent are domain specific models like HateBERT useful? [1]: Probing Critical Learning Dynamics of PLMs for Hate Speech Detection EACL’24
better release and maintain intermediate checkpoints? 2. Should we not use mBERT when monolingual PLM is available for monolingual dataset? 3. Role of domain specific models? Is domain specific MLM enough?
seed for the hate detection tasks. 2. Hate speech corpus needs to be continually augmented with newer samples to keep up with updated training corpus of the PLMs. 3. Datasets that report result on HateBERT should consider BERTTweet as well, given the closeness in performance of BERTweet and BERT. 4. We recommend reporting results on varying complexity of classification heads to establish the efficacy of domain-specific models. Recommendations for Hate Speech Community
{kind=link}
{kind=link}
![Motivation [1]: https://www.un.org/en/hate-speech/understanding-hate-speech/what-is-hate-speech • No universal definition of hate speech](https://files.speakerdeck.com/presentations/603499279fa1413e933a37d984abb00e/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![Experimental Setup Fig 1: Datasets [1] Fig 2: PLMs [1]](https://files.speakerdeck.com/presentations/603499279fa1413e933a37d984abb00e/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Do we need to finetuning all Layers of BERT? [1]:](https://files.speakerdeck.com/presentations/603499279fa1413e933a37d984abb00e/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}