Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Optimizing for GPUs
Search
Arnaud Bergeron
April 25, 2017
Programming
680
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Optimizing for GPUs
A bag of tricks to improve performance on the GPU and avoid the most common pitfalls.
Arnaud Bergeron
April 25, 2017
Other Decks in Programming
See All in Programming
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.6k
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
4
1.4k
Claude Team Plan導入・ガイド
tk3fftk
0
220
symfony/aiとlaravel/boost
77web
0
140
ITヒヤリハットを整理してみた ~ライフサイクルと原因から考える再発防止策~
koukimiura
1
110
AWS CDK を「作」ってみた 〜フルスクラッチで見えた CDK の裏側〜 / aws-cdk-from-scratch
gotok365
3
460
【やさしく解説 設計編 #0】DDDのコード、読めるのに分からない人へ
panda728
PRO
2
270
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
140
AIエージェントで 変わるAndroid開発環境
takahirom
2
680
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
150
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
260
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
810
Featured
See All Featured
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Visualization
eitanlees
152
17k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
KATA
mclloyd
PRO
35
15k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
The Cult of Friendly URLs
andyhume
79
7k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Transcript
Optimizing for GPUs Arnaud Bergeron
Kernels __kernel void add(__global float *a, __global float *b, __global
float *c, size_t n) { size_t i = get_global_id(0); if (i < n) c[i] = a[i] + b[i]; } __global__ void add(float *a, float *b, float *c, size_t n) { size_t i = (blockIdx.x * blockDim.x) + threadIdx.x; if (i < n) c[i] = a[i] + b[i]; } OpenCL CUDA
Unified Kernel KERNEL void add(GLOBAL_MEM ga_float *a, GLOBAL_MEM ga_float *b,
GLOBAL_MEM ga_float *c, ga_size n) { ga_size i = GID_0 * LDIM_0 + LID_0; if (i < n) c[i] = a[i] + b[i]; }
Grid, Blocks, Threads Grid Block
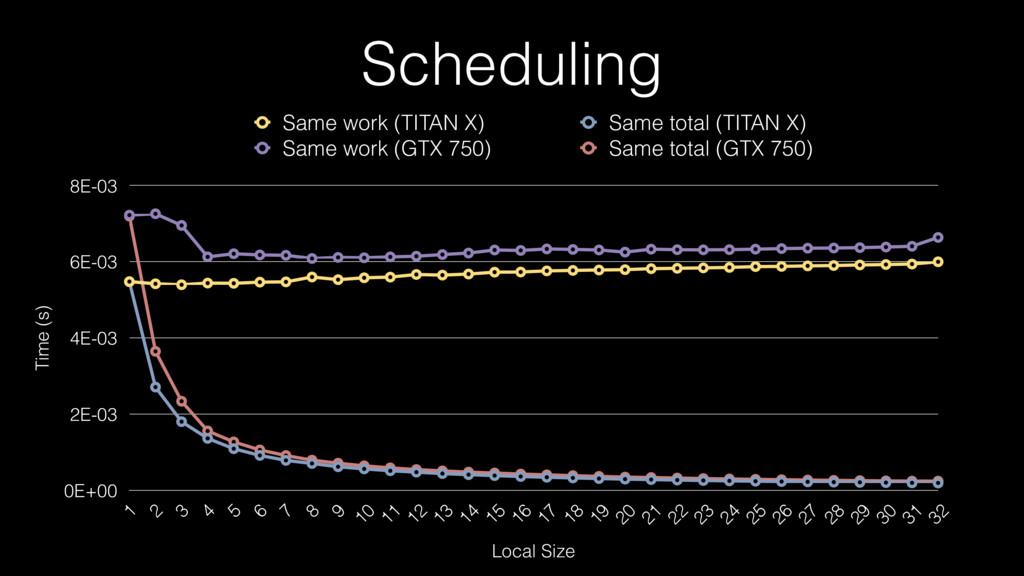
Scheduling Time (s) 0E+00 2E-03 4E-03 6E-03 8E-03 Local Size
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 Same work (TITAN X) Same total (TITAN X) Same work (GTX 750) Same total (GTX 750)
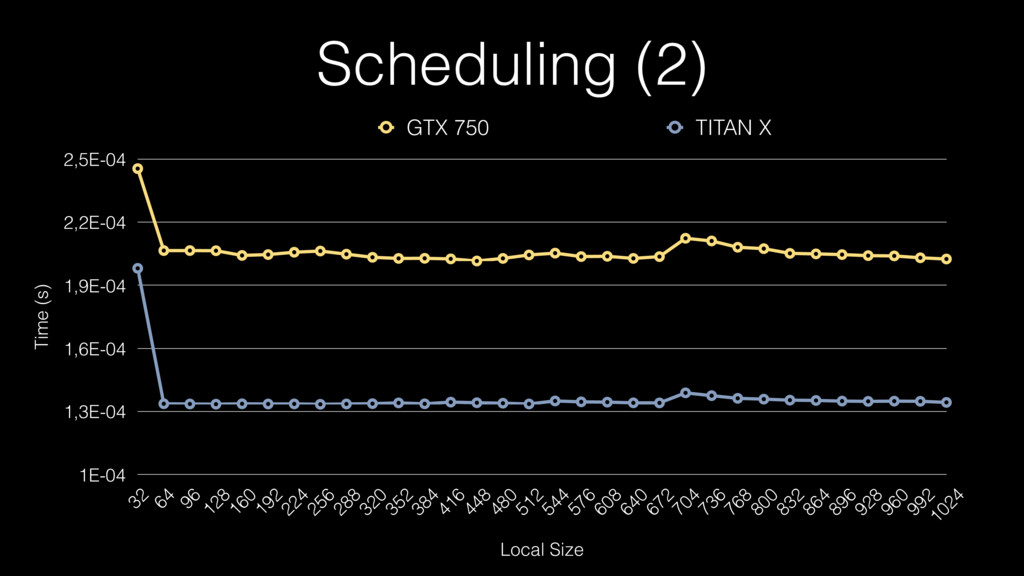
Scheduling (2) Time (s) 1E-04 1,3E-04 1,6E-04 1,9E-04 2,2E-04 2,5E-04
Local Size 32 64 96 128 160 192 224 256 288 320 352 384 416 448 480 512 544 576 608 640 672 704 736 768 800 832 864 896 928 960 992 1024 GTX 750 TITAN X
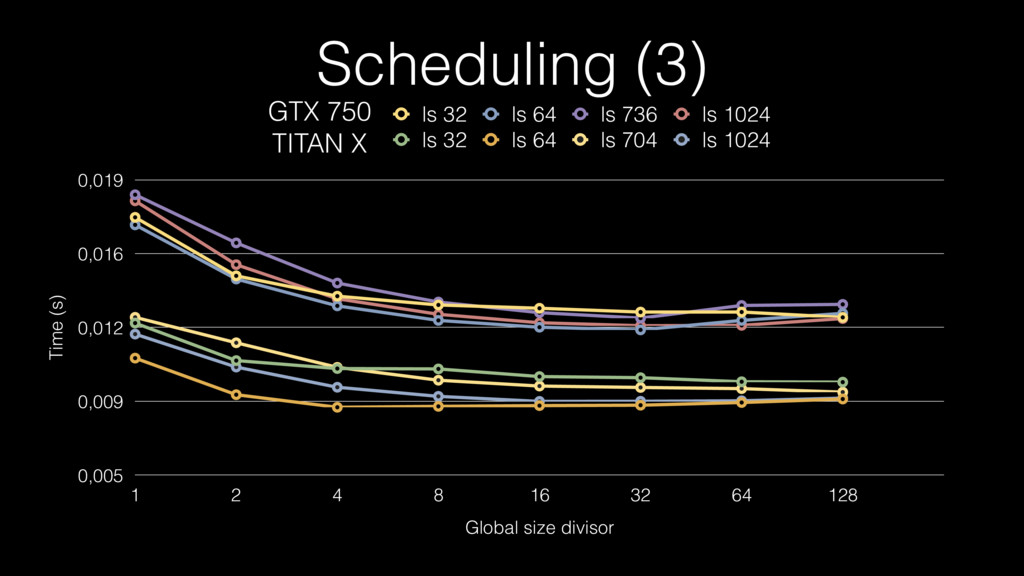
Scheduling (3) Time (s) 0,005 0,009 0,012 0,016 0,019 Global
size divisor 1 2 4 8 16 32 64 128 ls 32 ls 64 ls 736 ls 1024 ls 32 ls 64 ls 704 ls 1024 GTX 750 TITAN X
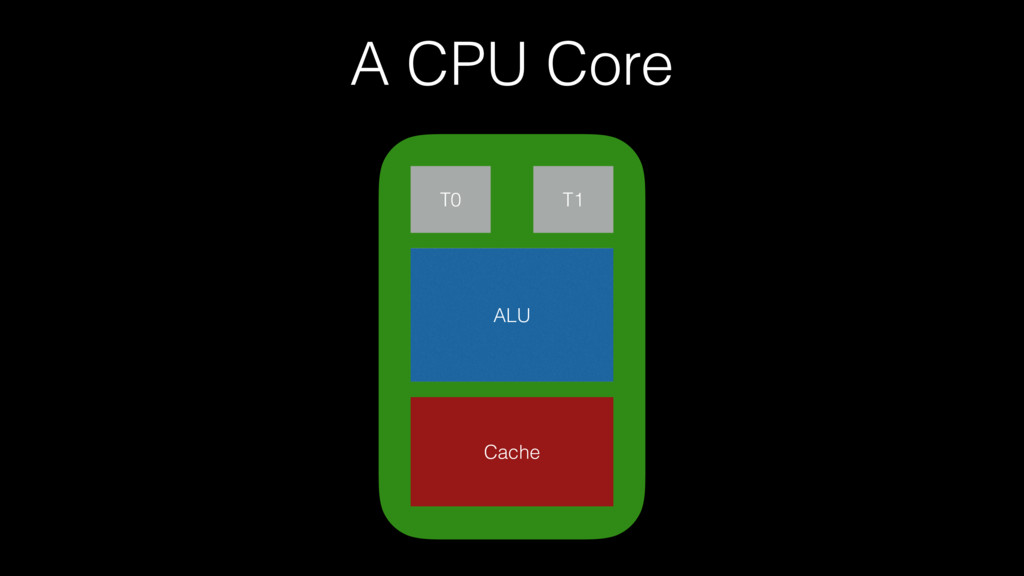
A CPU Core T0 T1 ALU Cache
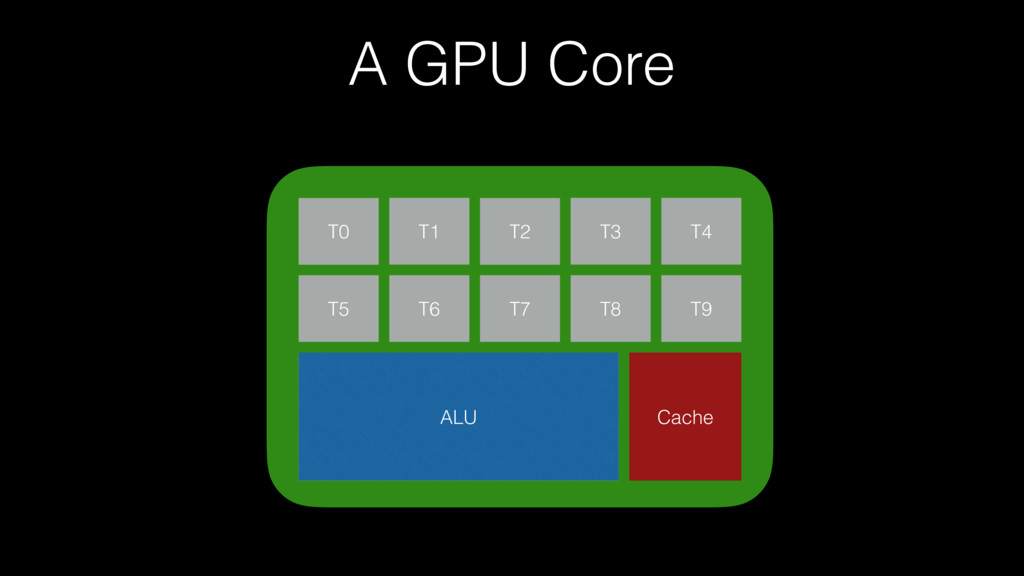
A GPU Core T0 T2 ALU T1 T5 T6 T3
T4 T9 T8 T7 Cache
Blocking Operations CPU Sync Sync Sync GPU Add kernel Add
kernel CPU Sync Sync GPU Add kernel Add kernel
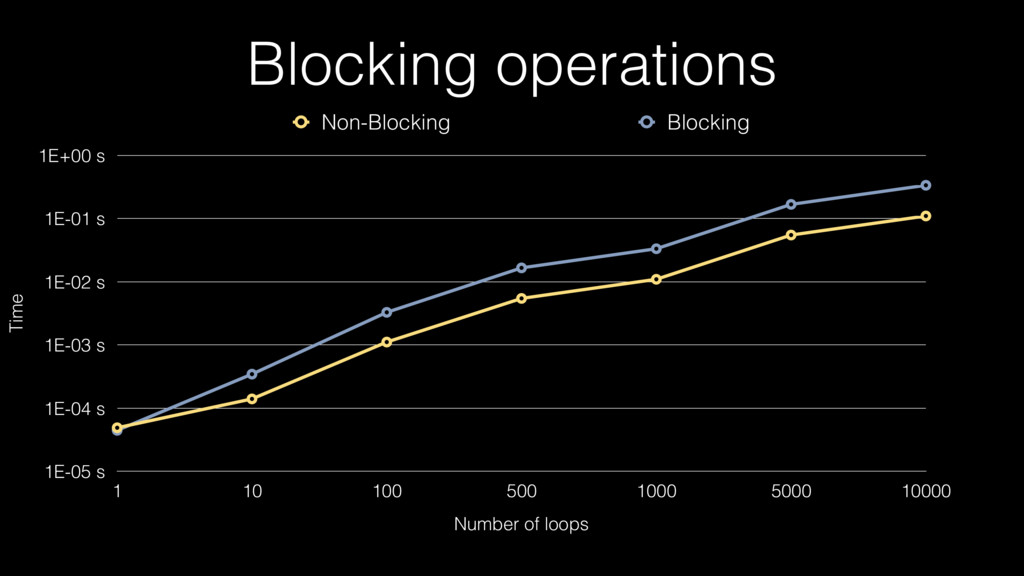
Blocking operations Time 1E-05 s 1E-04 s 1E-03 s 1E-02
s 1E-01 s 1E+00 s Number of loops 1 10 100 500 1000 5000 10000 Non-Blocking Blocking
Warp Divergence if (x < 0.0) z = x -
2.0; else z = sqrt(x); Divergent code Straight-line code @p = (x < 0.0); p: z = x - 2.0; !p: z = sqrt(x);
Divergent Kernel KERNEL void add(GLOBAL_MEM ga_float *a, GLOBAL_MEM ga_float *b,
GLOBAL_MEM ga_float *c, ga_size n) { ga_size i = GID_0 * LDIM_0 + LID_0; if (i < n) { if (i % 2) c[i] = a[i] + b[i]; else c[i] = asinhf(a[i]) + erfinvf(b[i]); } }
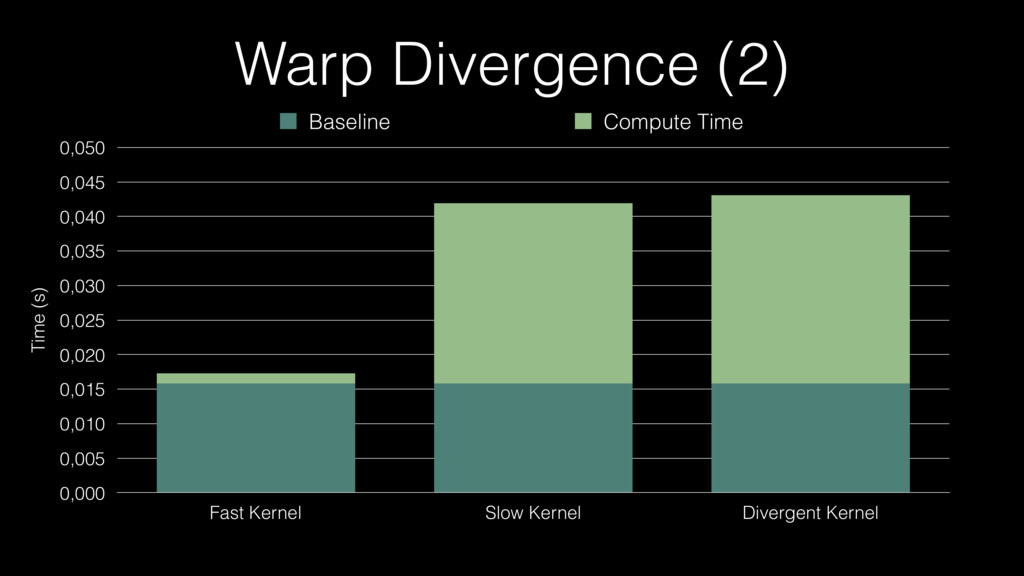
Warp Divergence (2) Time (s) 0,000 0,005 0,010 0,015 0,020
0,025 0,030 0,035 0,040 0,045 0,050 Fast Kernel Slow Kernel Divergent Kernel Baseline Compute Time
Last Kernel (simple) KERNEL void add(GLOBAL_MEM ga_float *a, ga_ssize lda,
GLOBAL_MEM ga_float *b, ga_ssize ldb, GLOBAL_MEM ga_float *c, ga_ssize ldc, ga_size M, ga_size N) { for (ga_size row = GID_1 * LDIM_1 + LID_1; row < M; row += GDIM_1 * LDIM_1) { for (ga_size col = GID_0 * LDIM_0 + LID_0; col < N; col += GDIM_0 * LDIM_0) { c[row * ldc + col] = rdA(row, col) * rdB(row, col); } } }
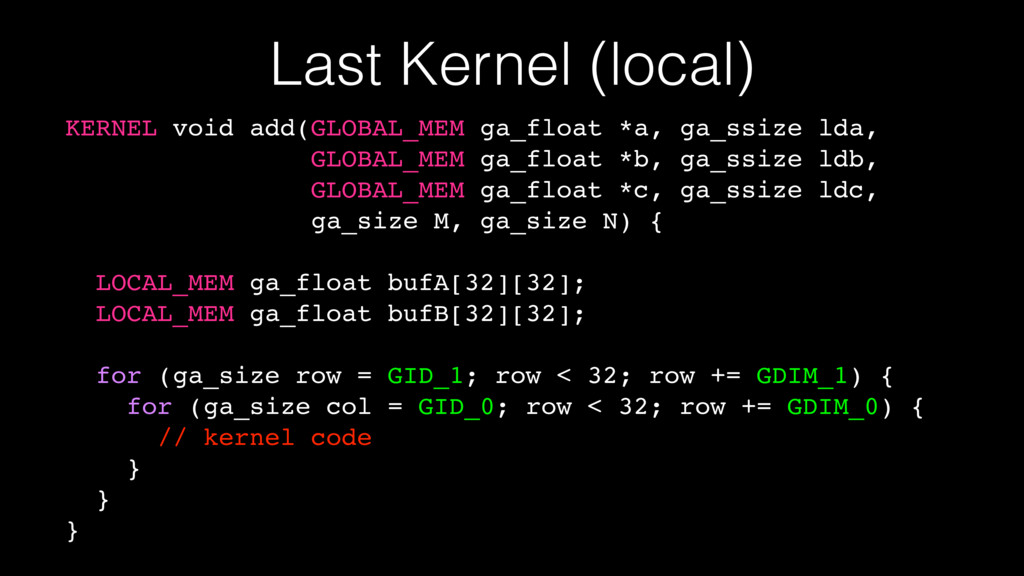
Last Kernel (local) KERNEL void add(GLOBAL_MEM ga_float *a, ga_ssize lda,
GLOBAL_MEM ga_float *b, ga_ssize ldb, GLOBAL_MEM ga_float *c, ga_ssize ldc, ga_size M, ga_size N) { LOCAL_MEM ga_float bufA[32][32]; LOCAL_MEM ga_float bufB[32][32]; for (ga_size row = GID_1; row < 32; row += GDIM_1) { for (ga_size col = GID_0; row < 32; row += GDIM_0) { // kernel code } } }
Inner Code (local) for (int i = 0; i <
32; i++) bufA[i][LID_0] = rdA(row*32 + i, col*32 + LID_0); for (int i = 0; i < 32; i++) bufB[i][LID_0] = rdB(row*32 + i, col*32 + LID_0); local_barrier(); for (int i = 0; i < 32; i++) { for (int j = 0; j < 32; j++) { c[(row*32 + i)*ldc + (col*32 + j)] = bufA[i][j] * bufB[i][j]; } }
Final example Time (s) 0 0,001 0,002 0,003 0,004 0,005
0,006 C order F order F order (with scheduling) C order (shared memory) F order (shared memory)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}