. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Background Recent advances in tabular neural network Transformer-based models, which utilize self-attention mechanism to capture dependencies between features TabTransformer (Xie et al., 2020) FT-Transformer (Gorishniey et al., 2021) Trompt (Chen et al., 2023) Tree-based models, which dedicates to make the decision process differentiable. TabNet (Arik et al., 2020) GRANDE (Marton et al., 2024) DOFEN (Chen et al., 2024) Your name Short title September 7, 2024 2 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Motivation Retrieval-Augmented tabular neural network Retrieves additional objects (information) from the training set and use them to improve performance While multiple retrieval-augmented models for tabular data exists, authors show that they provide only minor benefits over the properly-tuned multi linear perceptron (MLP), while being significantly more complex and costly. Your name Short title September 7, 2024 3 / 23
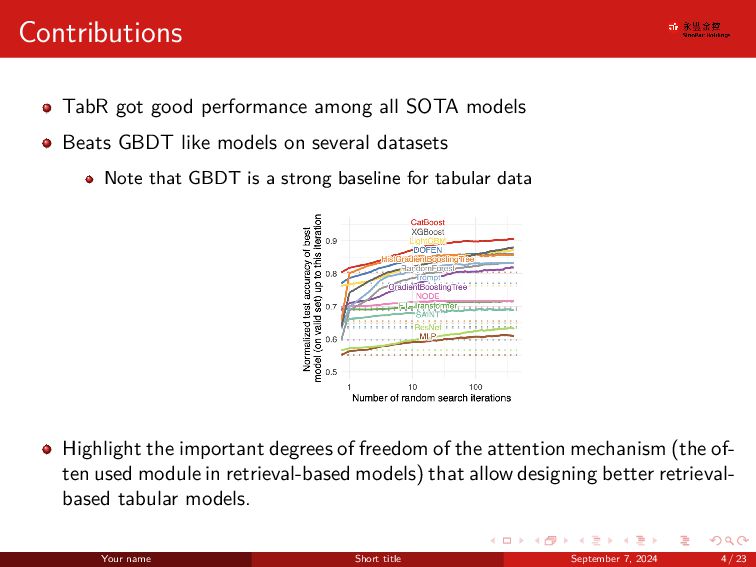
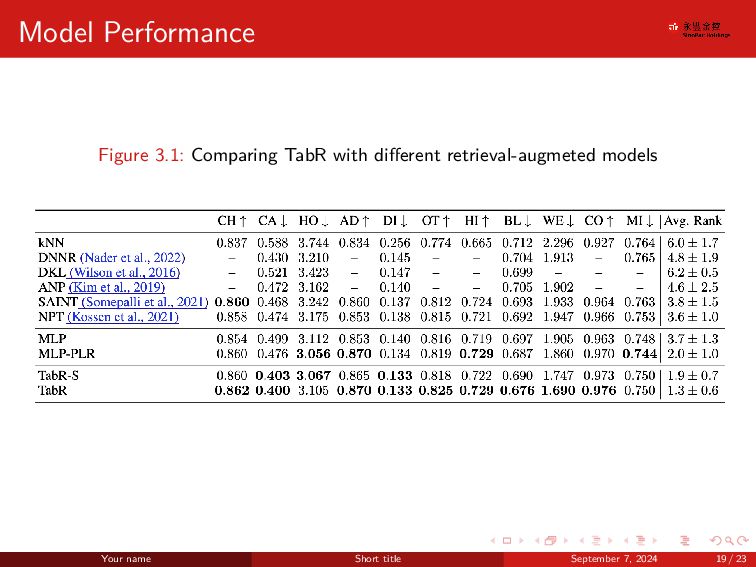
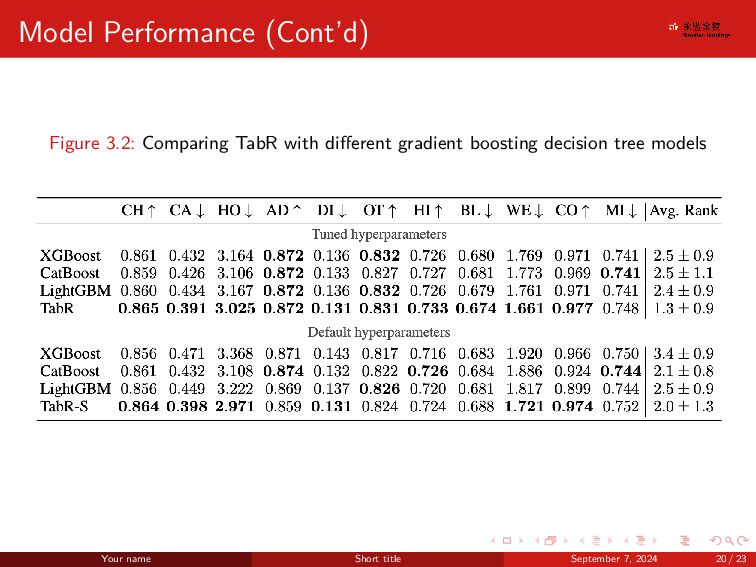
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Contributions TabR got good performance among all SOTA models Beats GBDT like models on several datasets Note that GBDT is a strong baseline for tabular data Highlight the important degrees of freedom of the attention mechanism (the of- ten used module in retrieval-based models) that allow designing better retrieval- based tabular models. Your name Short title September 7, 2024 4 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Preliminaries Dataset: {(xi, yi)}n i=1 , where xi ∈ X represents the i-th object’s feature and yi ∈ Y represents the i-th object’s label. Consider three types of tasks: Binary Classification: Y = {0, 1} Multi-class Classification: Y = {1, 2, . . . , C} Regression: Y ∈ R In most cases, feature xi is numerical features (a.k.a no categorical features) Dataset is split into three disjoint parts: 1, n = Itrain ∪ Ival ∪ Itest Your name Short title September 7, 2024 7 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Prelimiaries (Cont’d) When the retrieval technique is used for a given target object, the retrieval is performed within the set of “context candidates” or simply “candidates”: Icand ⊆ Itrain . The retrieved objects, in turn, are called “context objects” or simply “object”. Optionally, the target object can be included in its own context. In this work, unless otherwise noted, we use the same set of candidates for all input objects and set Icand = Itrain (which means retrieving from all training objects). Your name Short title September 7, 2024 8 / 23
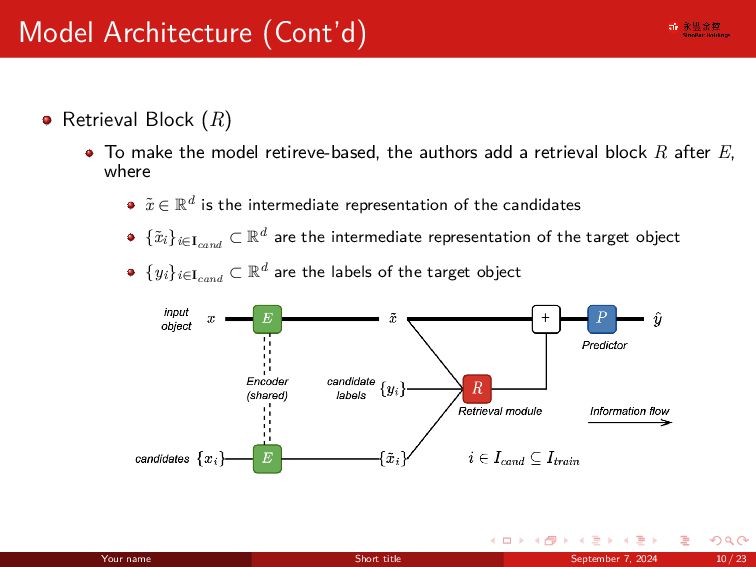
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Model Architecture (Cont’d) Retrieval Block (R) To make the model retireve-based, the authors add a retrieval block R after E, where ˜ x ∈ Rd is the intermediate representation of the candidates {˜ xi}i∈Icand ⊂ Rd are the intermediate representation of the target object {yi}i∈Icand ⊂ Rd are the labels of the target object Your name Short title September 7, 2024 10 / 23
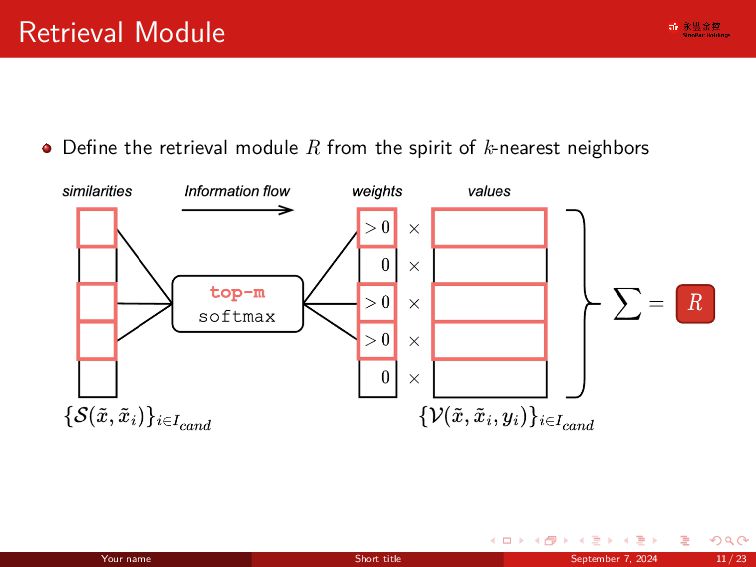
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Revolution of Retrieval Block Vanilla attention-like Similarity Module S : (Rd, Rd) → R S(˜ x,˜ xi) = WQ(˜ x)⊺WK(˜ xi) · d−1/2 (1) A self-attention like baseline: To model the interaction between a target object and candidate objects To make it simpler, we can said that we calculate the attention score between ˜ x and every ˜ xi∈Icand Vanilla attention-like Similarity Value V : (Rd, Rd, Y) → Rd V(˜ x,˜ xi, yi) = WV(˜ xi) (2) Self-Attention Introduction Your name Short title September 7, 2024 12 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Revolution of Retrieval Block (Cont’d) Improving Similarity Module S : (Rd, Rd) → R S(˜ x,˜ xi) = −||WK(˜ x) − WK(˜ xi)||2 · d−1/2 (3) Authors found that instead of the original dot-product mechanism in self-attention, removing the notion of queries and using the L2 regularization improves the per- formance Adding context labels V : (Rd, Rd, Y) → Rd V(˜ x,˜ xi, yi) = WV(˜ xi) + WY(yi) (4) Utilize labels of the context objects, which is an embedding table for classifica- tion tasks and a linear layer for regression tasks Your name Short title September 7, 2024 13 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Finally: TabR Authors find out that omitting the scaling term d−1/2 in the similarity module and not including the object to it’s own context leads to better results on average. So the final retrieval module R is like: S(˜ x,˜ xi) = −||WK(˜ x)−WK(˜ xi)||2 V(˜ x,˜ xi, yi) = WY(yi)+T(WK(˜ x)−WK(˜ xi)) (8) Your name Short title September 7, 2024 15 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Discussion Why can L2 regularization be better than self-attention? Aligning two representations (Two different trainable matrix) of targets and candidate objects is an additional challenge for the optimization process → Too many trainable parameters The similarity module S operates over linear transformations of the input. Then, a reasonable similarity measure in the original feature space may remain reasonable in the transformed feature space, and L2 is usually a good measure than the dot product in the original feature space We found that the L2 is a better measure for dataset with distance-related features, maybe useful for spatio-temporal data Your name Short title September 7, 2024 16 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Discussion (Cont’d) How retrieval model enhances the model performance? Access to contextually relevant information By retrieving the most similar instances from the training data, the retrieval module provides context that the original input might lack Original Neural Network model can only learn from each instance in the training data, each instance is treated independently In tabular data with categorical or time-series features, there may be patterns that are not immediately apparent in the input but become more evident when considering similar instances Improved generalization The model benefits from additional examples (neighbors) that are similar but not identical to input, which can help avoid overfitting to specific patterns in the training data (act as a form of data augmentation) Your name Short title September 7, 2024 17 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Conclusion Authors have designed TabR - a retrieval-augmented tabular DL architecture that provides strong average performance and achieve state-of-the-art (SOTA) on several datasets Authors have highlighted similarity and value modules as the important details of the attention mechanism which have significant impact on the performance for attention-based retrieval components Your name Short title September 7, 2024 22 / 23
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Appendix: Self-Attention Self-attention is a mechanism that helps the model to focus on the relevant parts of the input sequence It computes the attention score between each pair of elements in a sequence AttentionQ, K, V = softmax ( Q⊺K √ dk ) V (9) Where Q, K and V are the query, key and value matrices, respectively, and they are all derived from the input sequence Q = XWQ K = XWK V = XWV (10) Where WQ , WK and WV are the learnable weight matrics, and X is the input sequence Go Back Your name Short title September 7, 2024 23 / 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}