ML 4 | • We’ve talk about decision trees do decisions based on… • Bagging / Boosting • ML in Finance / Trading (Portfolio construction & Factor investment) Recall of Interpretable ML (I)
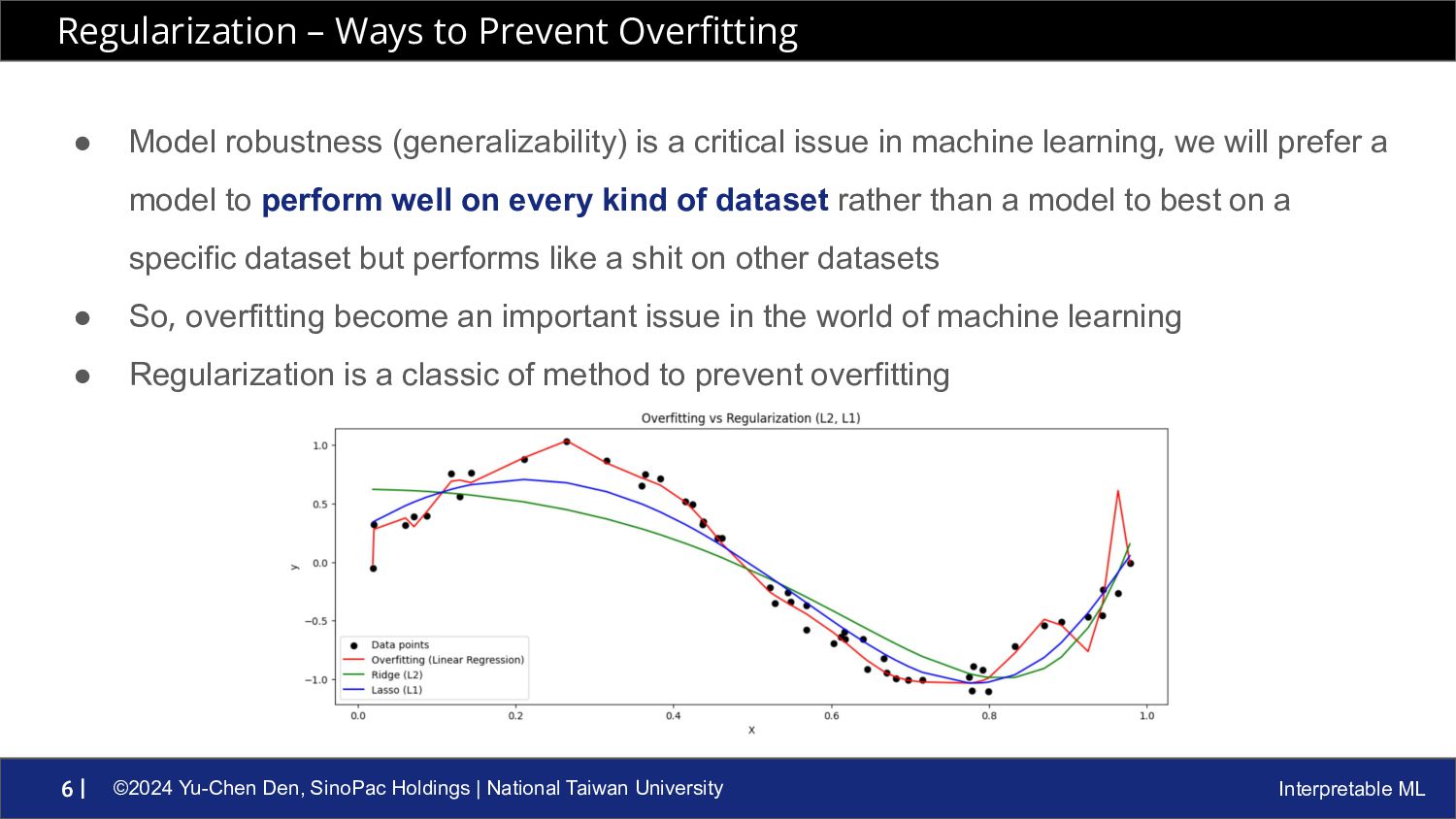
ML 6 | • Model robustness (generalizability) is a critical issue in machine learning, we will prefer a model to perform well on every kind of dataset rather than a model to best on a specific dataset but performs like a shit on other datasets • So, overfitting become an important issue in the world of machine learning • Regularization is a classic of method to prevent overfitting Regularization – Ways to Prevent Overfitting
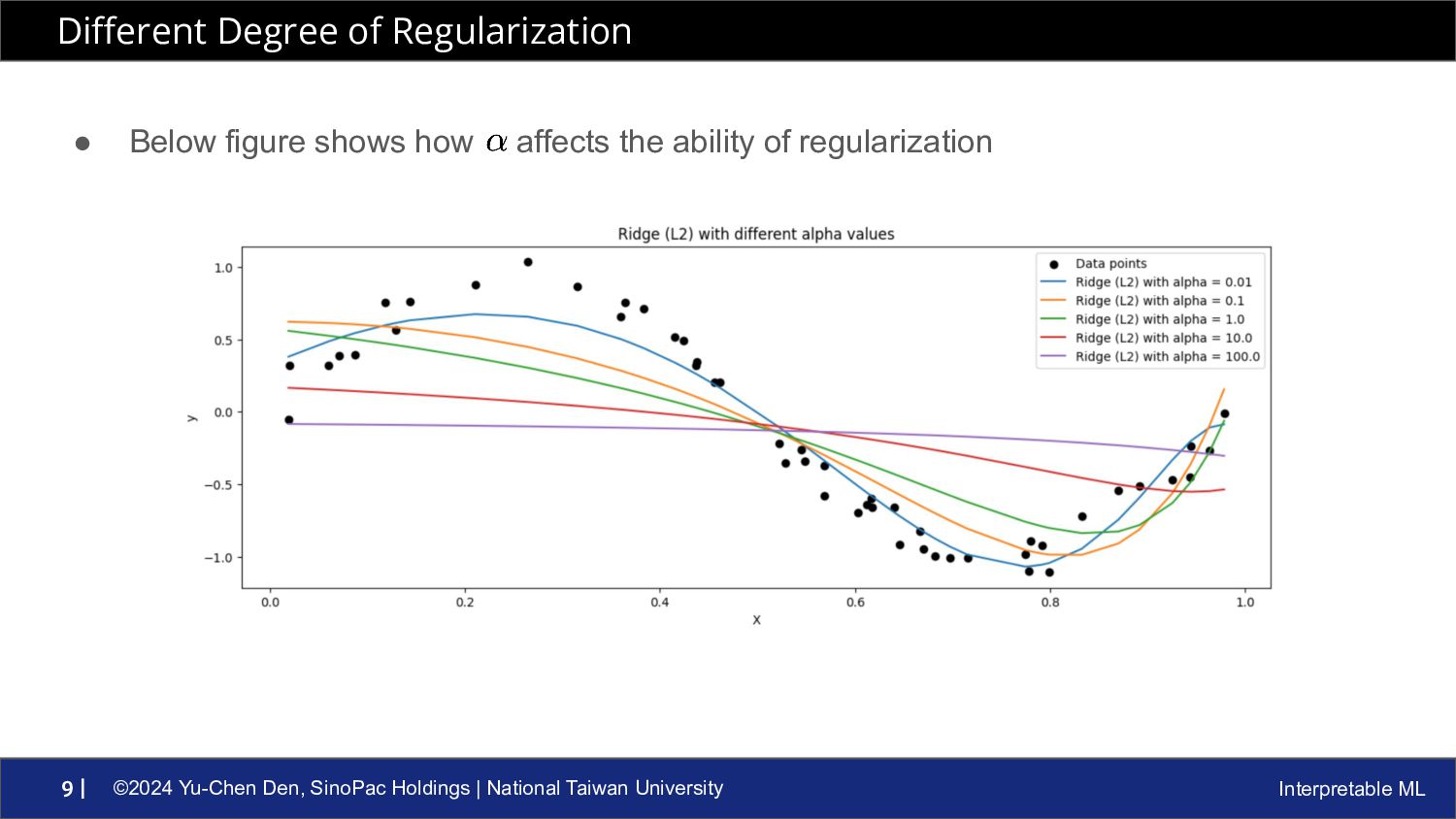
ML 8 | • As we minimize the loss function with penalty terms, L1 & L2 regularization seems to shrinks the coefficients ◦ L1 regularization tends to make some coefficients exactly to 0 ◦ L2 regularization shrink some coefficients towards to 0 • Since unnecessary parameters are eliminated, or large coefficients are penalized, regularization methods force the model to be less complex • But, be aware of the hyperparameter , if it’s too high, the model will be too simple to capture information from data, leading to underfitting Penalty Terms
ML 10 | • Since financial data has more features and less observations (N >> M), regularization seems to be an important part to prevent overfitting problems in finance issues ◦ Classical machine learning dataset ◦ Financial machine learning dataset • Moreover, since financial data (especially stock prices) has high volatility and the pattern will change due to investors’ sentiment & what they have learned from the market, prevent overfitting on training dataset is so important • If you want to know how regularization affects R-square, see Appendix I (lot of math!) Why Regularization is Important in Finance?
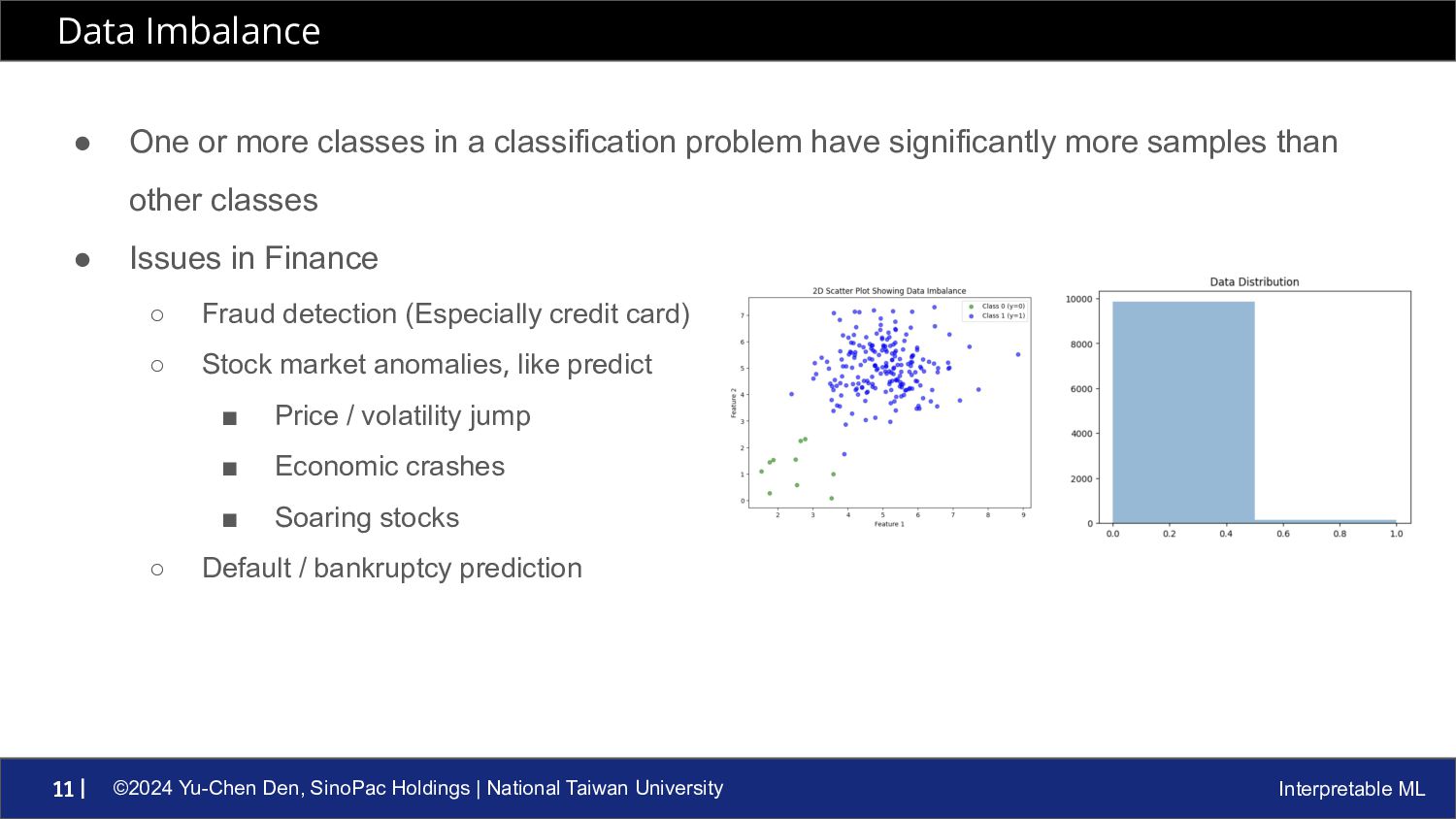
ML 11 | • One or more classes in a classification problem have significantly more samples than other classes • Issues in Finance ◦ Fraud detection (Especially credit card) ◦ Stock market anomalies, like predict ▪ Price / volatility jump ▪ Economic crashes ▪ Soaring stocks ◦ Default / bankruptcy prediction Data Imbalance
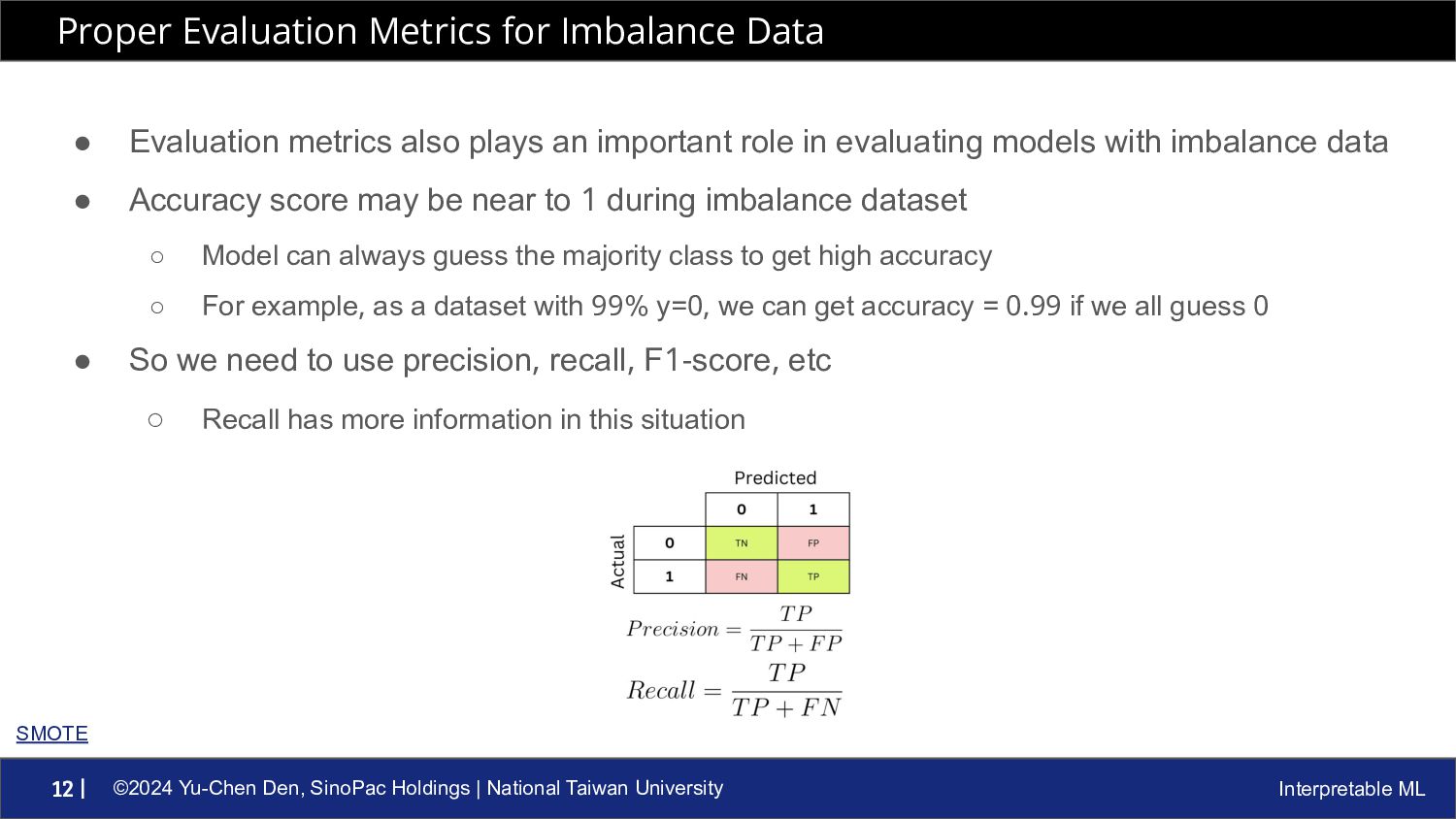
ML 12 | • Evaluation metrics also plays an important role in evaluating models with imbalance data • Accuracy score may be near to 1 during imbalance dataset ◦ Model can always guess the majority class to get high accuracy ◦ For example, as a dataset with 99% y=0, we can get accuracy = 0.99 if we all guess 0 • So we need to use precision, recall, F1-score, etc ◦ Recall has more information in this situation Proper Evaluation Metrics for Imbalance Data SMOTE
ML 13 | • Oversampling ◦ Generate new samples of classes which is under-represented ◦ SMOTE ◦ ADASYN • Undersampling ◦ Remove samples from the class which is over-represented ◦ Be aware that remove data points is usually not an ideal method in machine learning tasks, since data is very expensive & rare ◦ But It’s still worth a try, sometimes undersampling provides exciting performance • Popular package dealing with imbalance data ◦ imblearn Methods to Deal with Data Imbalance Tasks
ML 14 | • What makes SMOTE a better method dealing with imbalance data is that it doesn’t use random over sampling ◦ Instead, SMOTE finds one of the nearest samples of a minority class sample and calculate the difference between the selected data point to get the synthetic data ◦ Example (Consider a 2-dim dataset) SMOTE (Synthetic Minority Oversampling TEchnique) SMOTE
ML 15 | • It’s really important to write a good CV for applying internships & full-time works • In most cases, a formal CV / Resume is one-page and with only black words with white background • Some must-sections in a CV ◦ Education (especially for students / juniors) ◦ Work / Internship Experience ◦ Projects • Use LaTeX to write your CV if you have the ability to learn that thing, it’s also useful for your master thesis (or research) Supplementary – How to Write Good CV & Prepare Your Portfolio
ML 16 | • How to demonstrate things you’ve done? • Most of all, we use STAR principle ◦ Situation, Task, Action, and Result • Adding some quantitative examples of your outcome with what you’ve learned from it is usually a good idea ◦ Example ▪ Pioneered the development of convex optimization algorithm recommendation system, contributing to a 90% accuracy in recommending high-value KOLs for advertorial, which not only beats ML algorithms but also be more interpretable, and took the lead in a highly quantitative project. ◦ If you’re not sure about the number? Just make a reasonable estimate of your outcome Supplementary – How to Write Good CV & Prepare Your Portfolio (Cont’d) Resume Guide
ML 17 | • How about portfolio? Everyone who code may need to show their portfolio • Strongly Recommended: GitHub ◦ Every Quant / DS / MLE uses GitHub or GitLab for work or for personal if they’re not shit / companies are not shit ◦ We all loves GitHub, so that we don’t need to see the stupid screenshots of codes, .zip file for python modules, and unexecutable .ipynb from interviewers ▪ Seeing those files make us very angry!!! • If you have time & you have a little interest in software engineering: Personal Website ◦ Start with the user-friendly framework: bootstrap / html5up + GitHub pages Supplementary – How to Write Good CV & Prepare Your Portfolio (Cont’d)
ML 19 | • In practical, models & strategies are just a small part of the whole trading system • Signal generator ◦ Generate signals and notice traders ▪ Slack ▪ Discord ▪ Line Bot • Automatic trading system ◦ Need to use broker’s API to trade automatically ◦ Usually contains the signal generator, but change the notify part to trade with broker’s api ◦ TW brokers usually use C# as their main programming language ◦ Binance uses Python Not Only Models & Strategies
ML 20 | • Although algorithms & strategies are the main part of signal generator, the system itself is also a key point to make signals • Why we need a system? ◦ Automatically update data to generate new signals to trade ◦ If you don’t build an automation pipeline, you’ll need to execute the Python script every time you want to trade ▪ Isn’t it sounds too annoying? ▪ Or maybe you’ll just miss the best trade point when you’re executing the scripts ▪ Once you’ve run the script, do you want to open Excel to see the generated signals? Or they just send the action to you? Deep Dive Into Signal Generator
ML 21 | • For updating data, we’ll need an orchestration data pipeline / ETL pipeline ◦ Apache Airflow ◦ Dagster • For notification & getting actions, we’ll need backend API to connect with apps like Discord, Line, Slack, etc. ◦ Python ▪ FlaskAPI ▪ FastAPI ◦ Golang Tools to Build Trading System
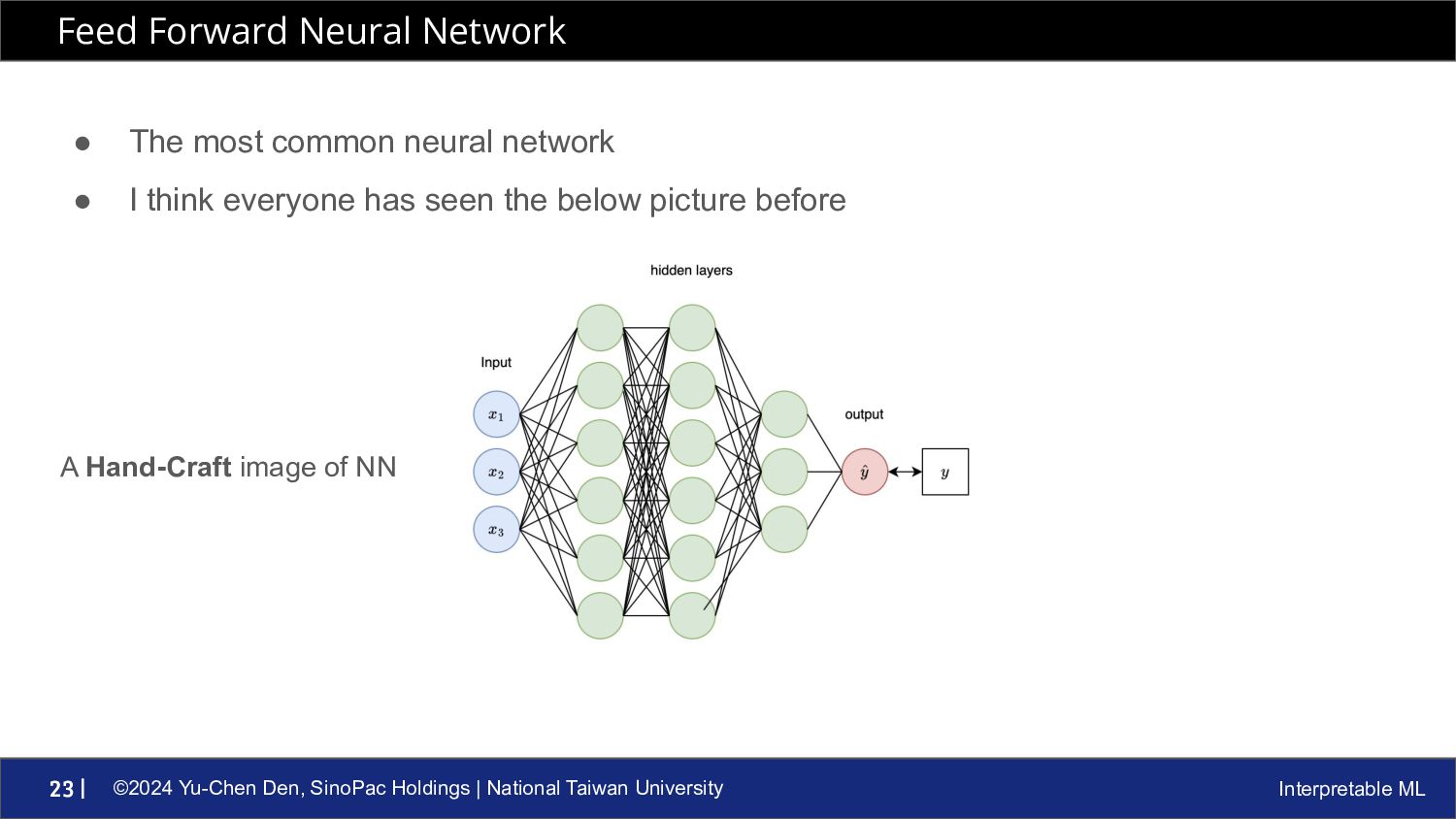
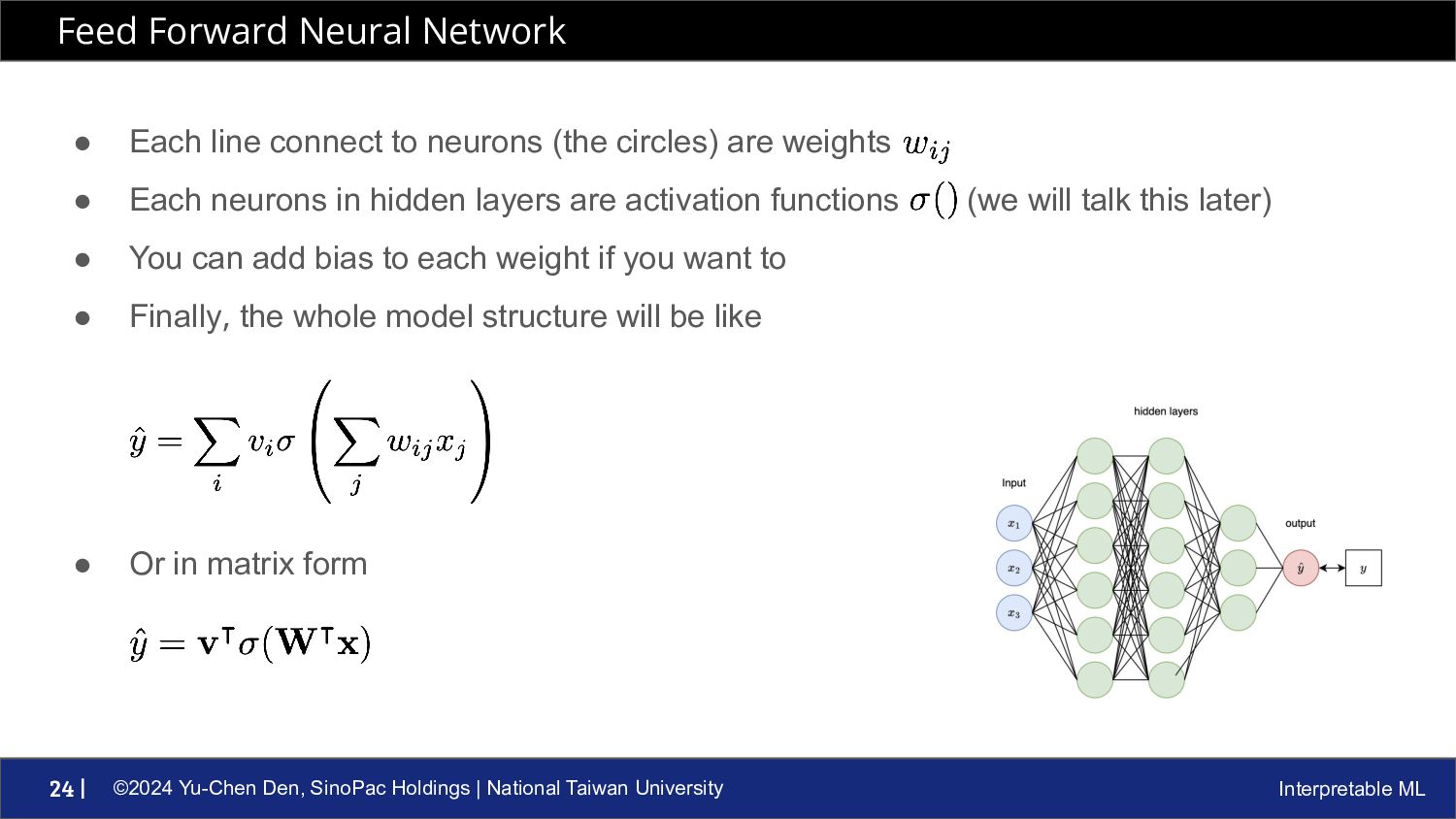
ML 24 | • Each line connect to neurons (the circles) are weights • Each neurons in hidden layers are activation functions (we will talk this later) • You can add bias to each weight if you want to • Finally, the whole model structure will be like • Or in matrix form Feed Forward Neural Network
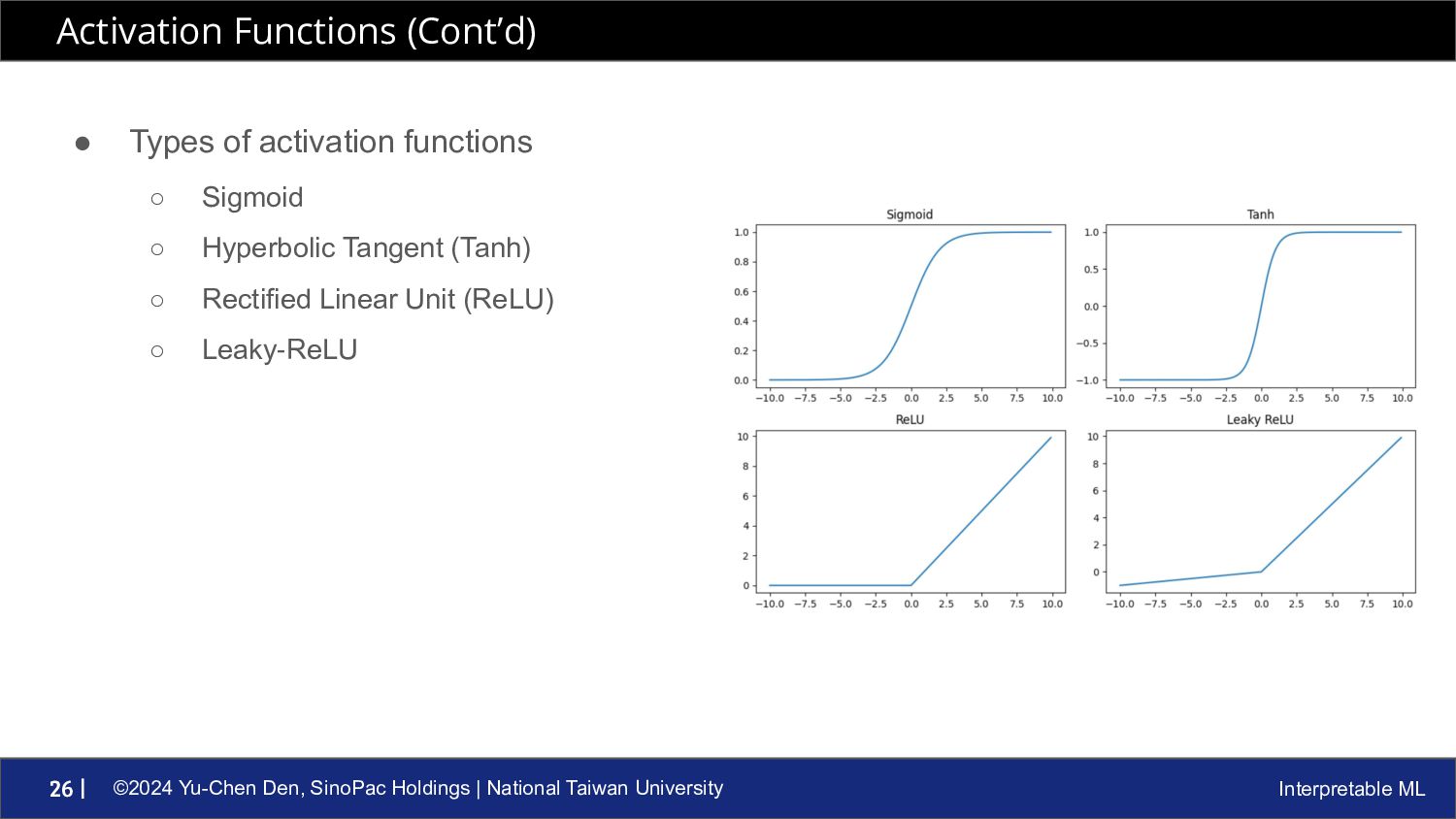
ML 25 | • Activation functions are the green circles in the above neural network image • Why we need activation functions? Isn’t it simpler to just time up weights and inputs? ◦ The model with a lot of linear transformations is still linear model (less complex) ◦ So, with non-linear activation functions, we can prevent inputs go through only linear functions Activation Functions
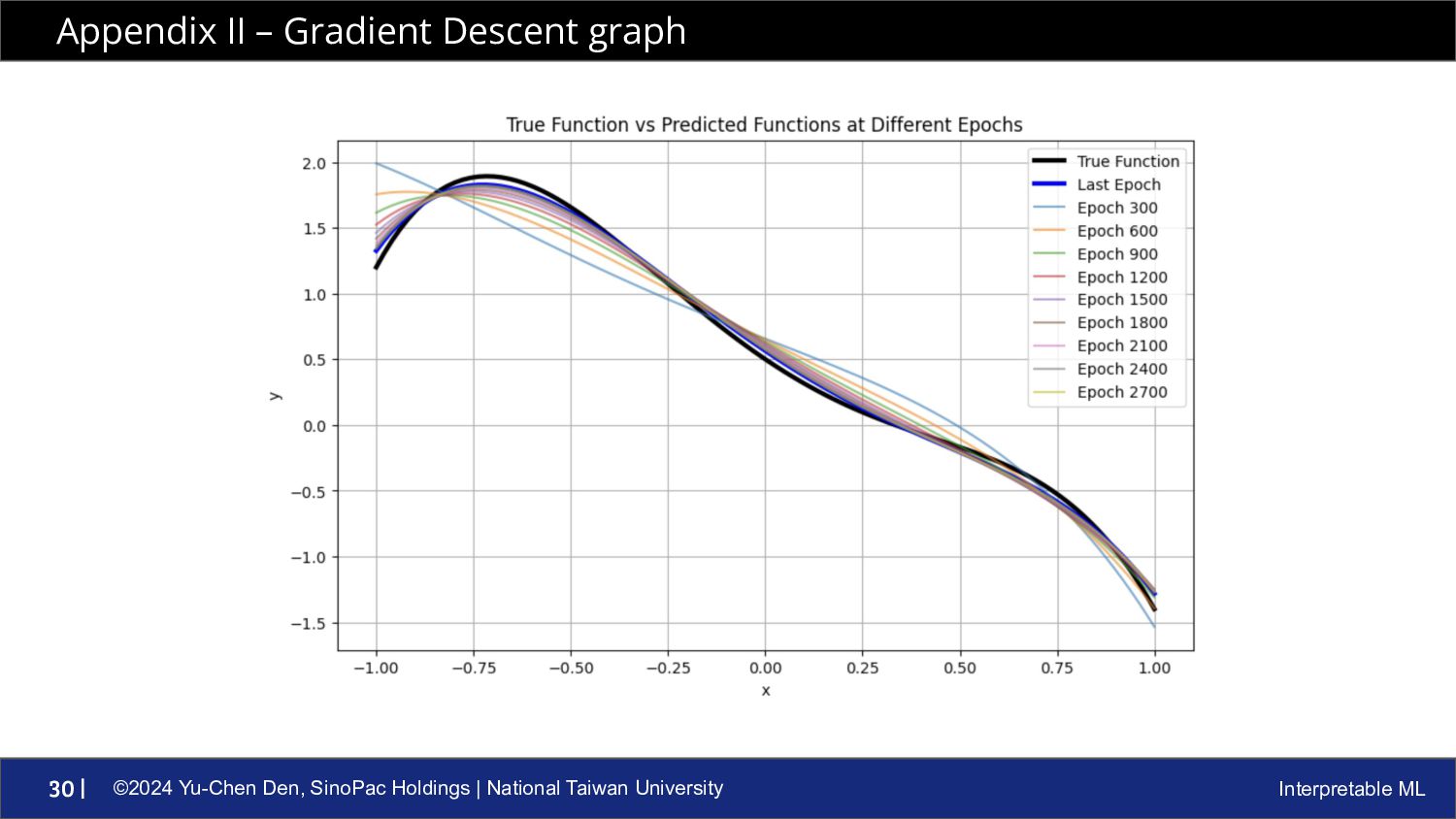
ML 27 | • After the input data goes through the network, we’ll get a prediction • We all know that we need to calculate the difference between prediction and answer ◦ • Optimization step ◦ Use partial derivatives to get the minimal value of Loss given parameters Gradient Descent
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}