A High-Performance Packet Processing Framework for Heterogeneous Processors. Received the best student paper award.
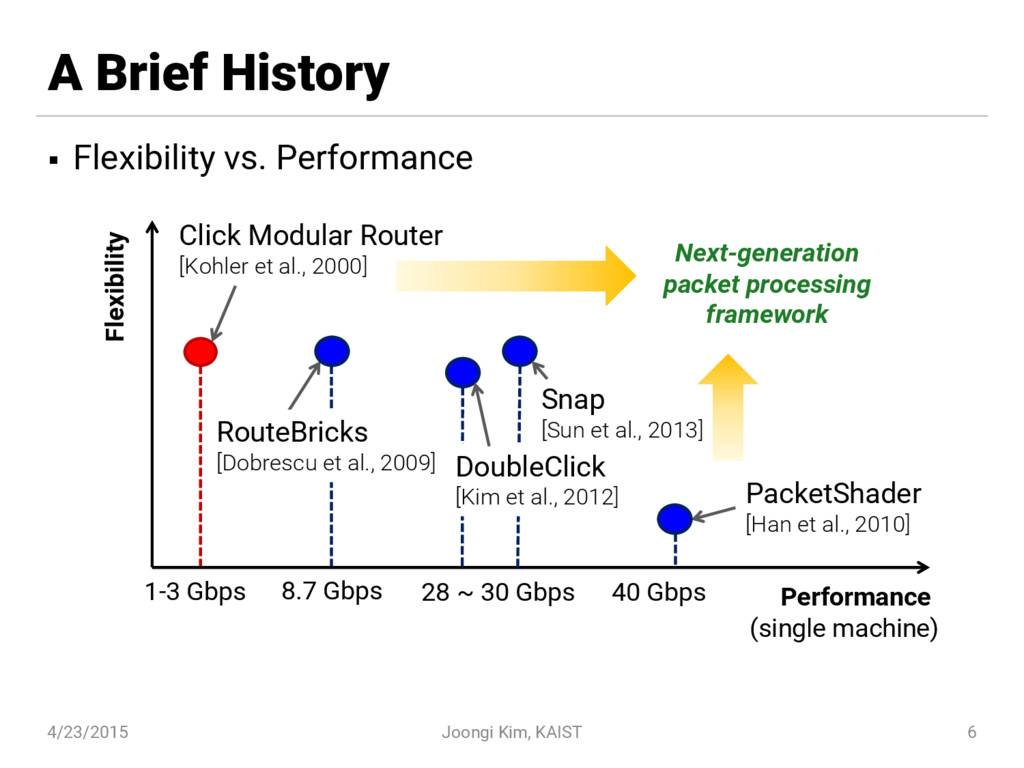
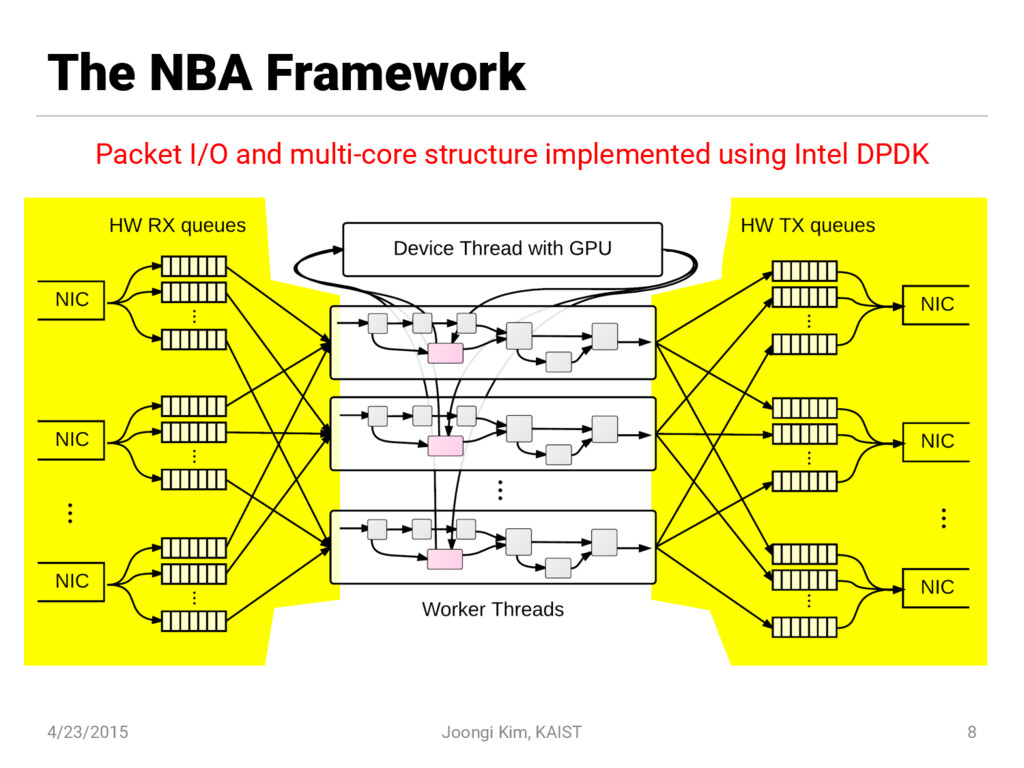
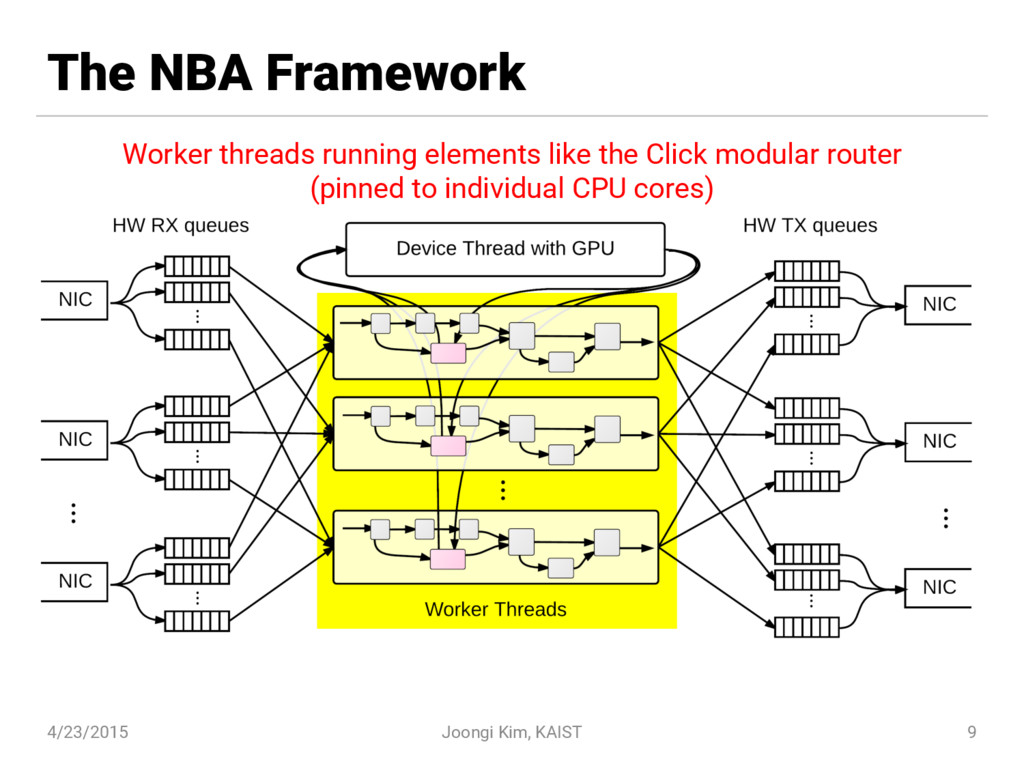
The NBA framework is the world-first 80 Gbps-grade generic packet processing framework, though there had existed application-specific prototypes reaching that performance. The framework's API resembles the Click modular router while it transparently supports composition of offloadable elements (e.g., GPU-accelerated) with an adaptive load balancer.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
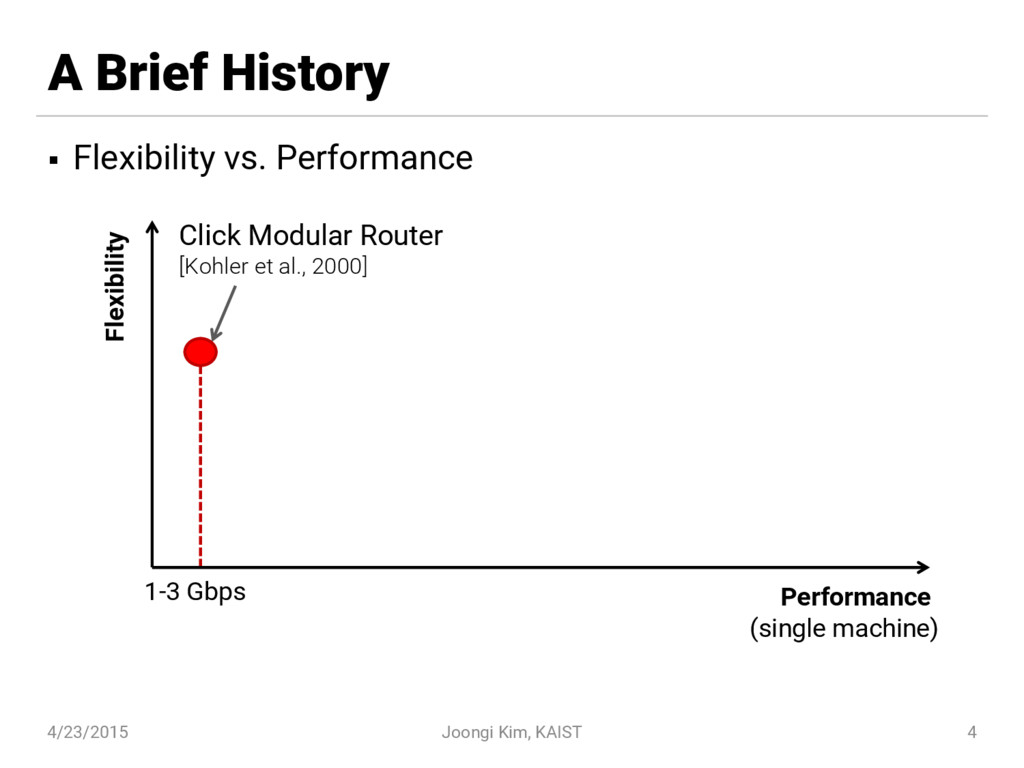
![The Click modular router [Kohler et al., 2000] § Fine-grained](https://files.speakerdeck.com/presentations/de0082175cdc41c782c9e40a5b99d6e4/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
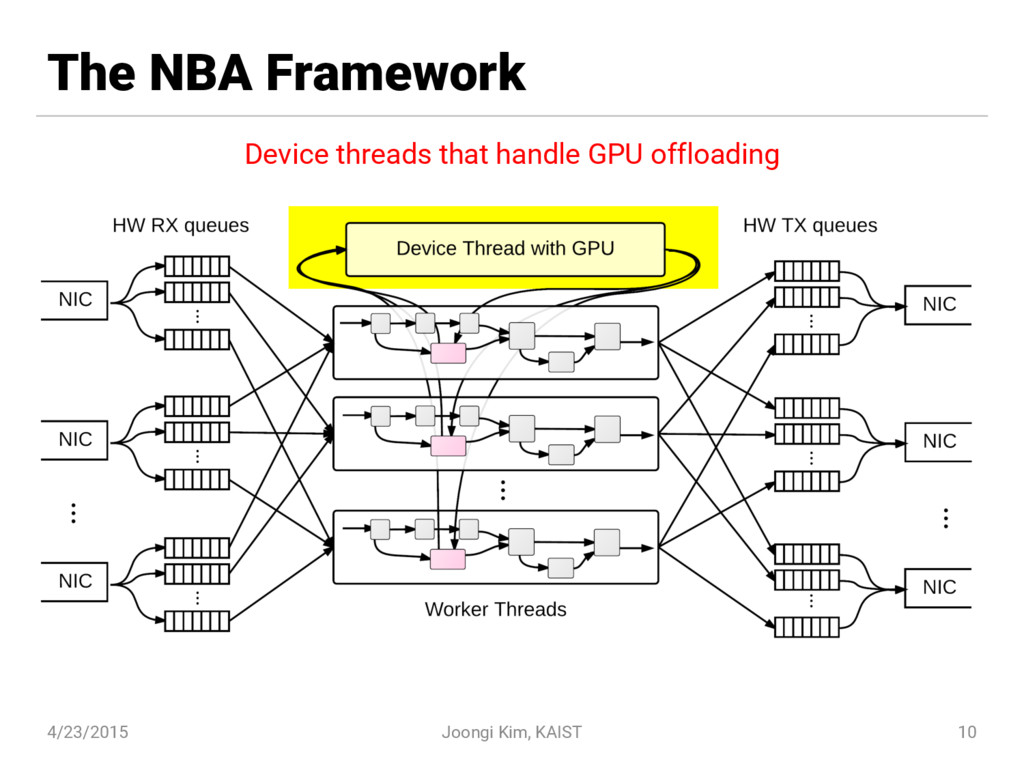{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
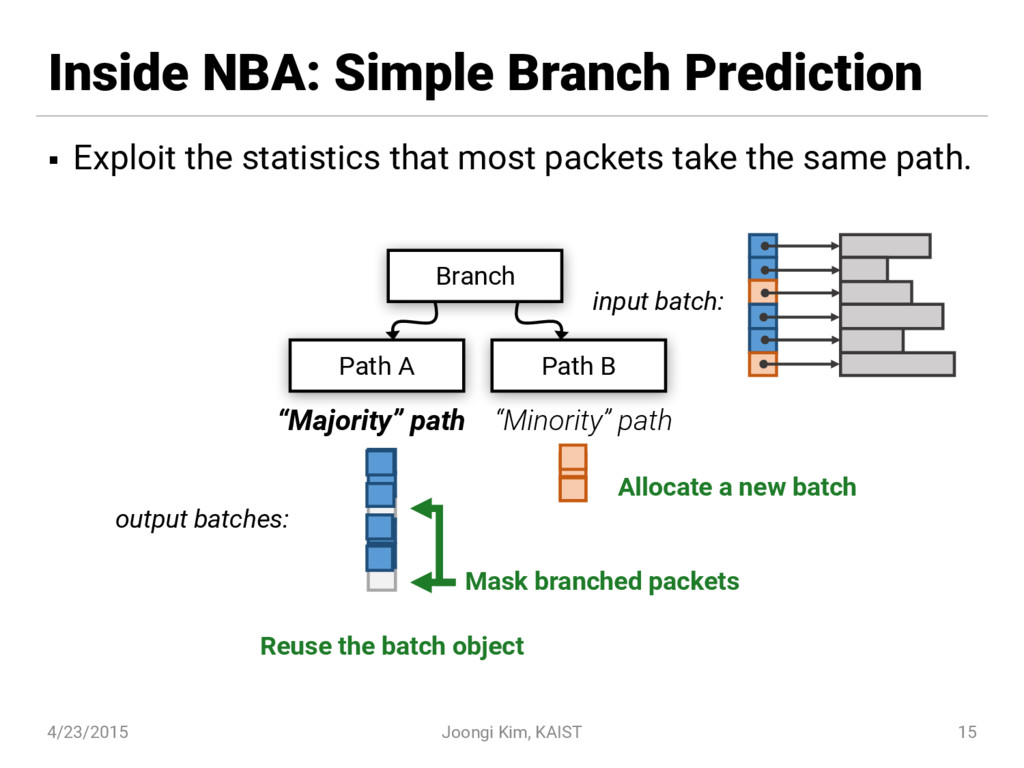{kind=link}
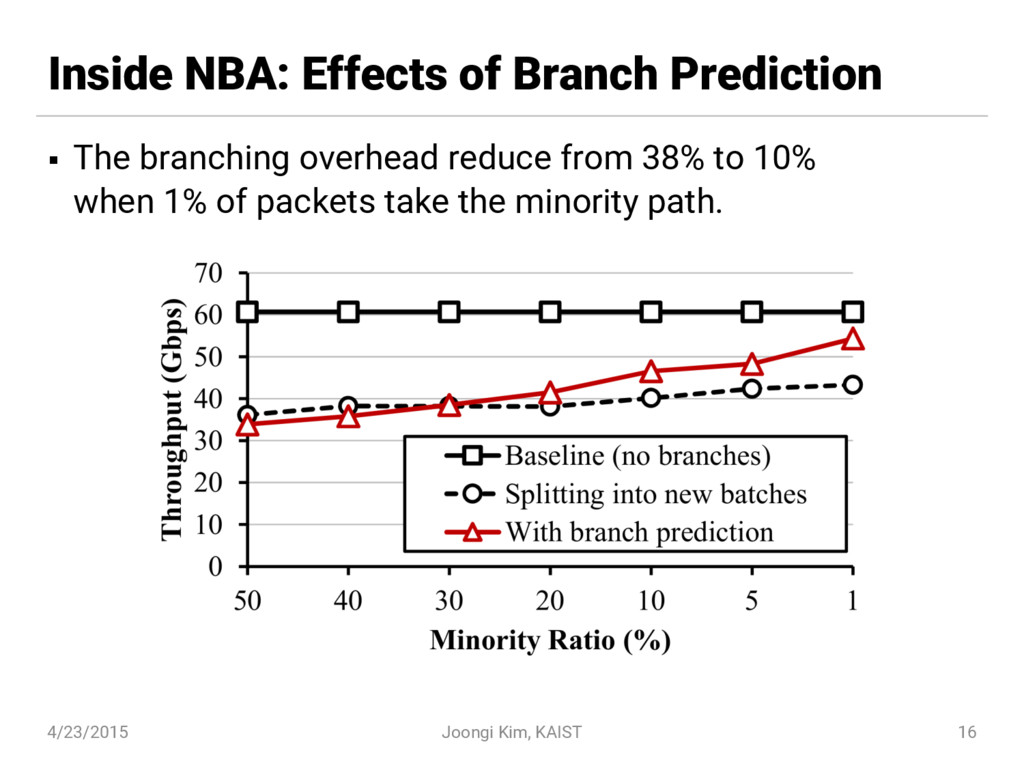{kind=link}
{kind=link}
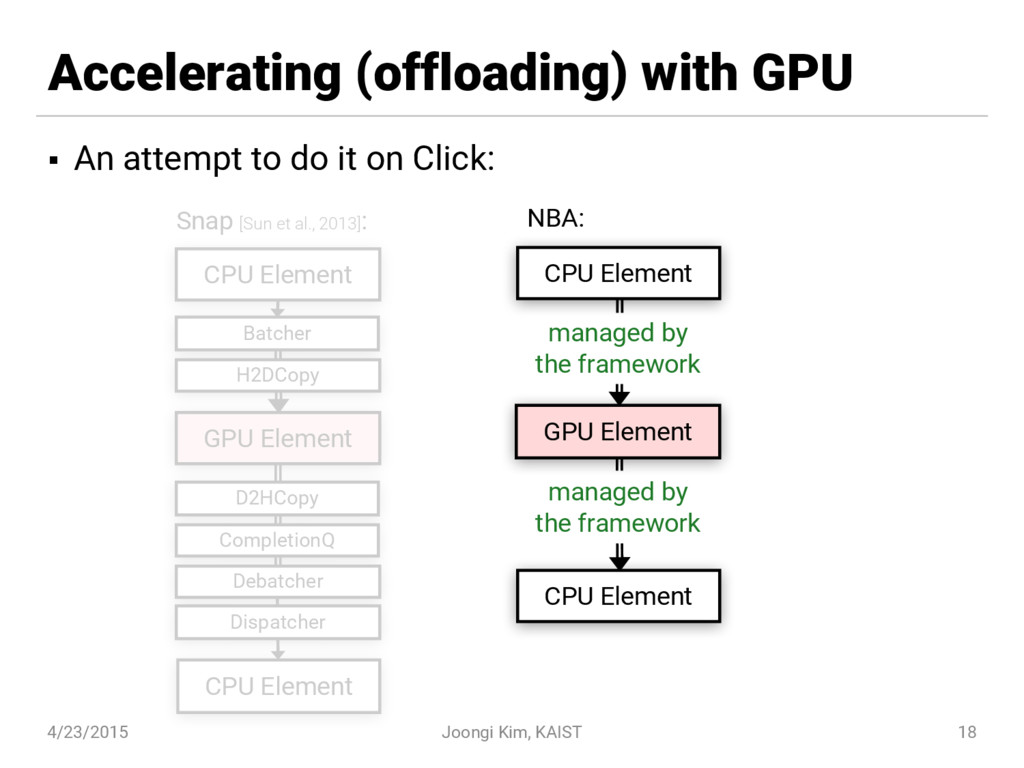{kind=link}
{kind=link}
{kind=link}
{kind=link}
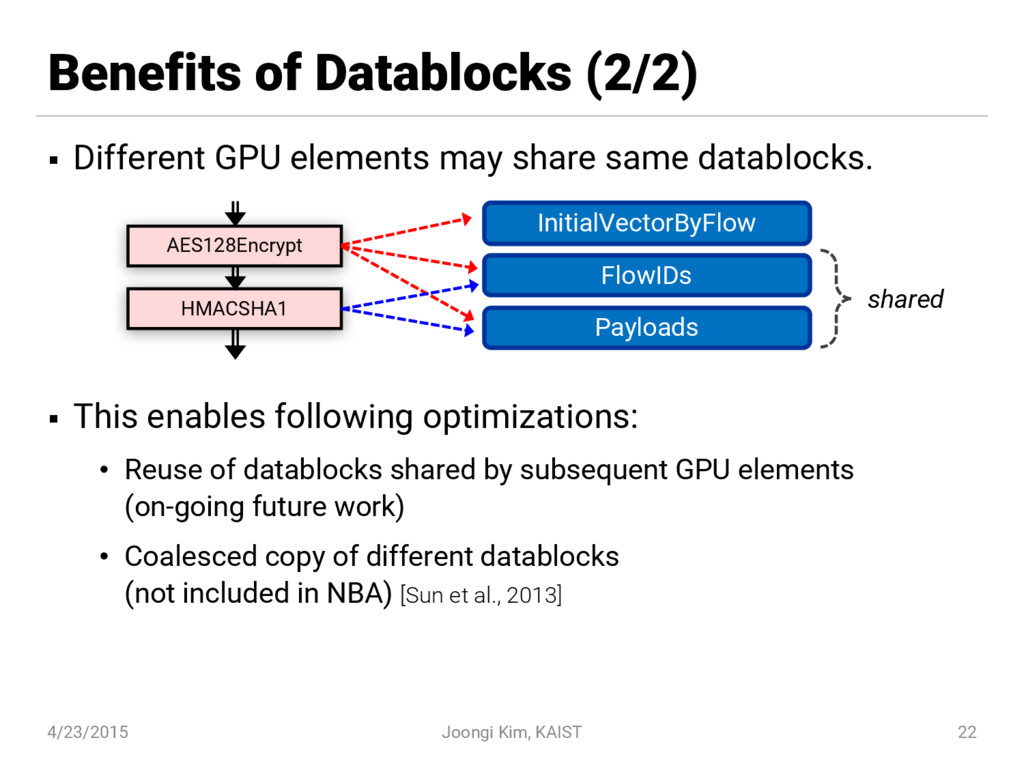{kind=link}
{kind=link}
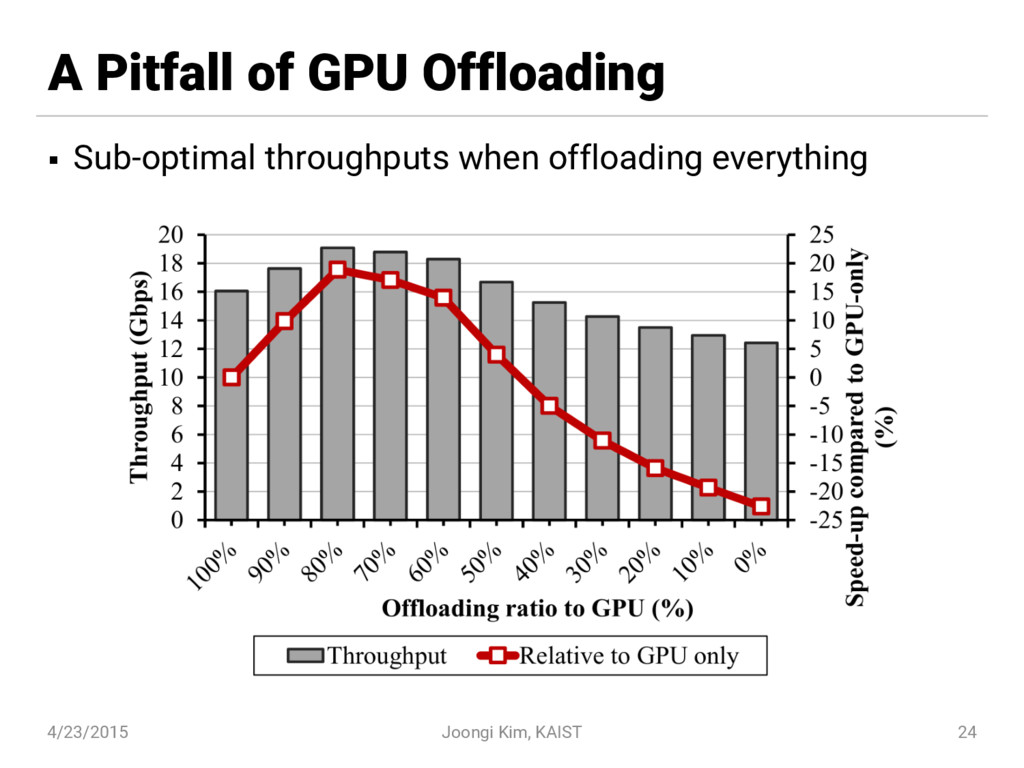{kind=link}
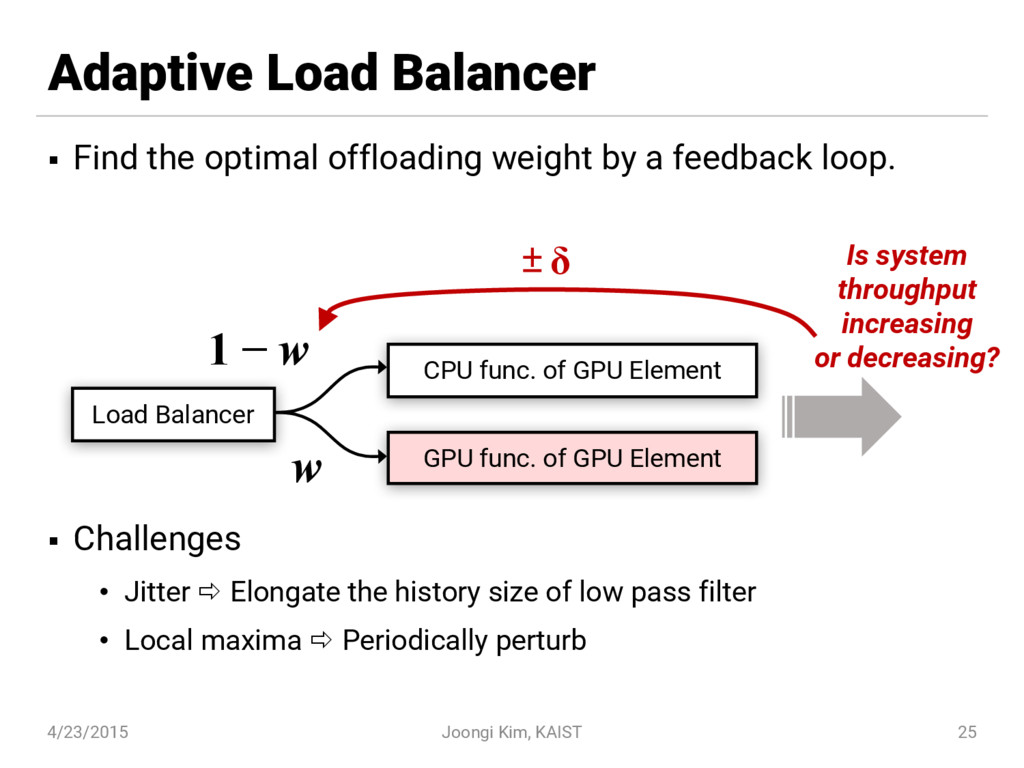{kind=link}
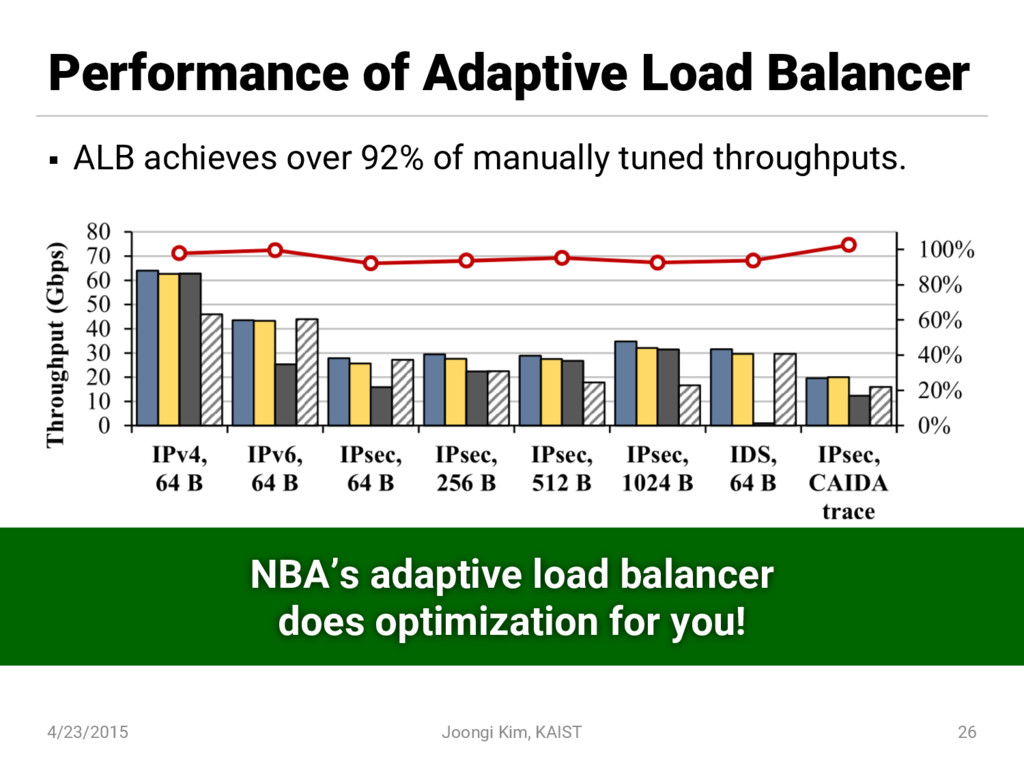{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
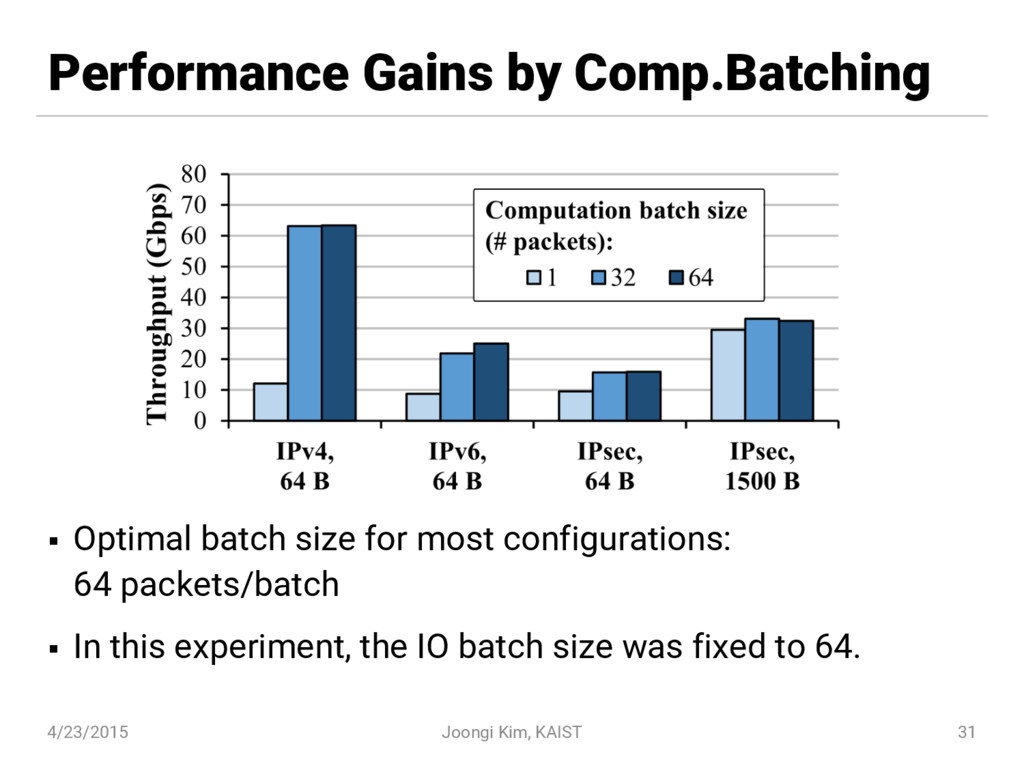{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
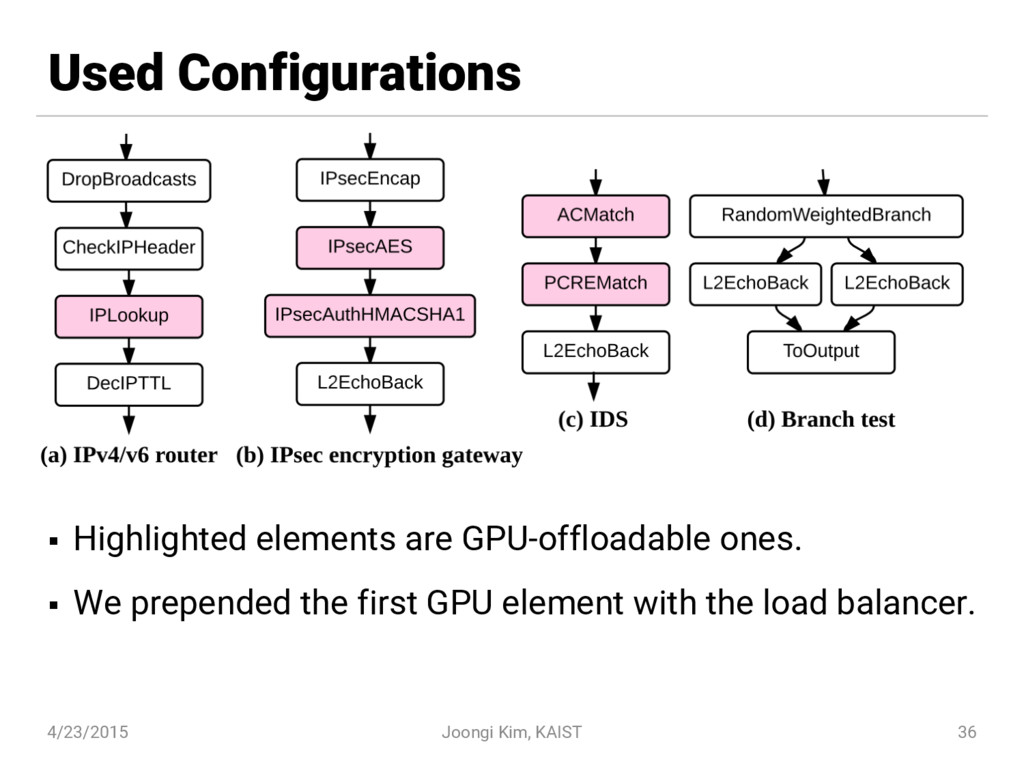{kind=link}
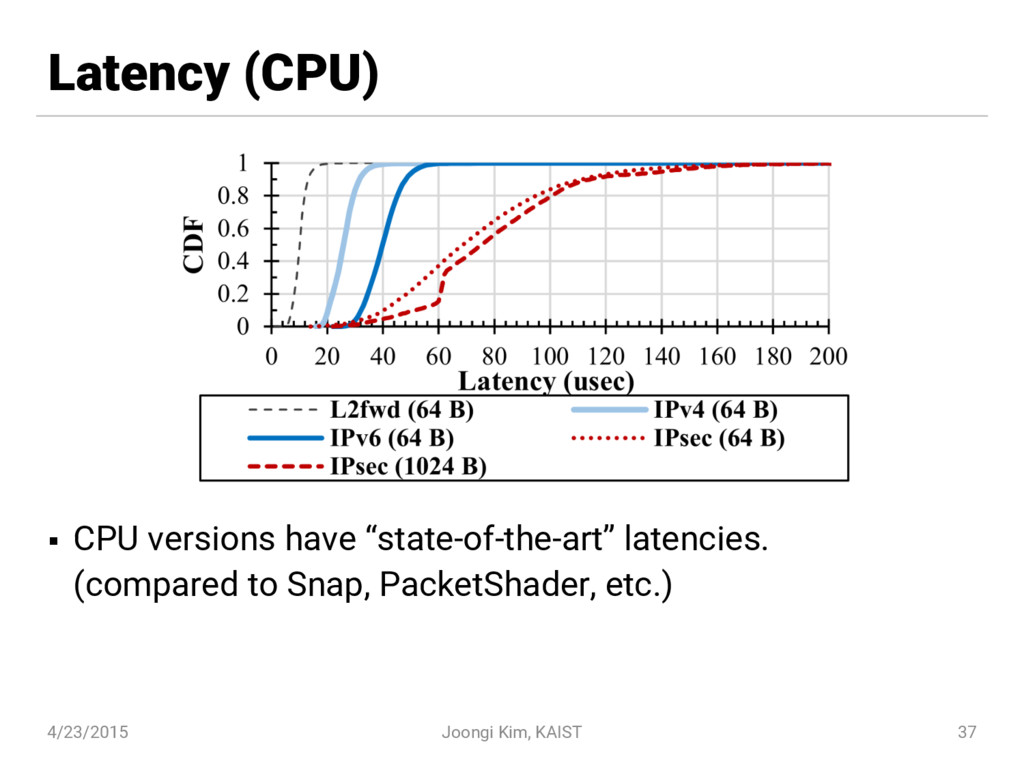{kind=link}
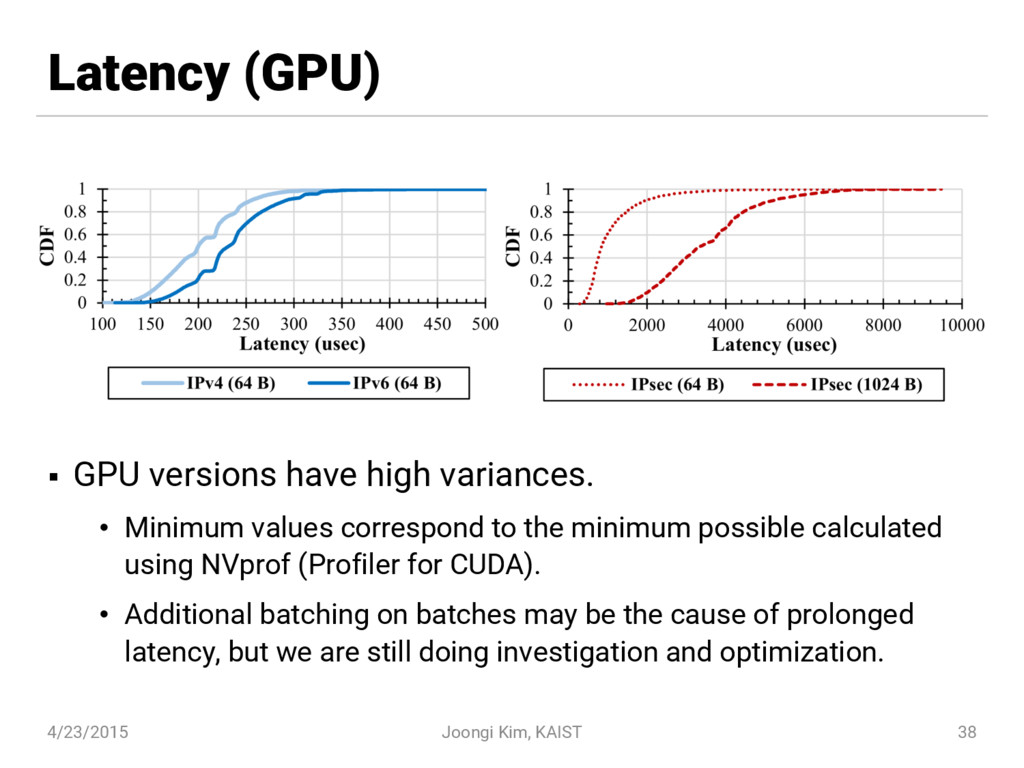{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}