a system into modules on the basis of a flowchart.” “ We propose instead that one begins with a list of difficult design decisions or design decisions which are likely to change. Each module is then designed to hide such a decision from the others.” “ Since, in most cases, design decisions transcend time of execution, modules will not correspond to steps in the processing…”
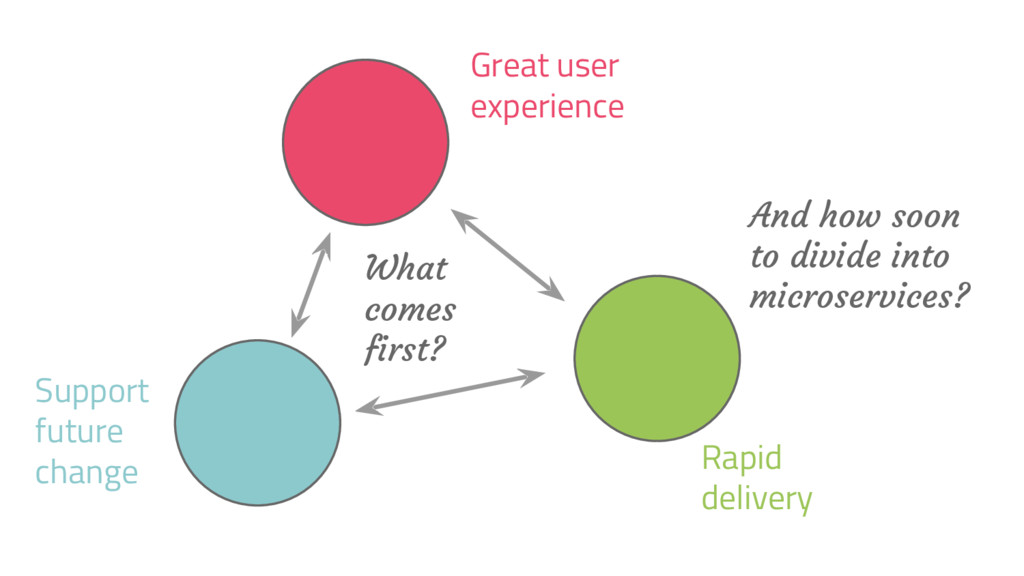
schedule and wanted to deliver an early release, but found that we couldn’t subset the system 2. We wanted to add a simple feature, but found it would have required rewriting all or most of the current code. 3. We wanted to simplify the system by removing some feature, but taking advantage of it meant rewriting large sections of the code 4. We wanted a custom deployment (e.g. in dev, or test environments) but the system wasn’t flexible enough.
‘chain of data transforming components’ it is necessary to stop thinking of the system in terms of components that correspond to steps in the processing. This way of thinking dies hard...”
component programs to use are left to individual systems programmers… Unless some restraint is exercised, one may end up with a system in which nothing works until everything works.”
iff: • A is essentially simpler because it uses B • B is not substantially more complex because it is allowed to use A • There is a useful subset containing B and not A • There is no conceivable useful subset containing A but not B And of course, it does not introduce any cycles into the dependency graph
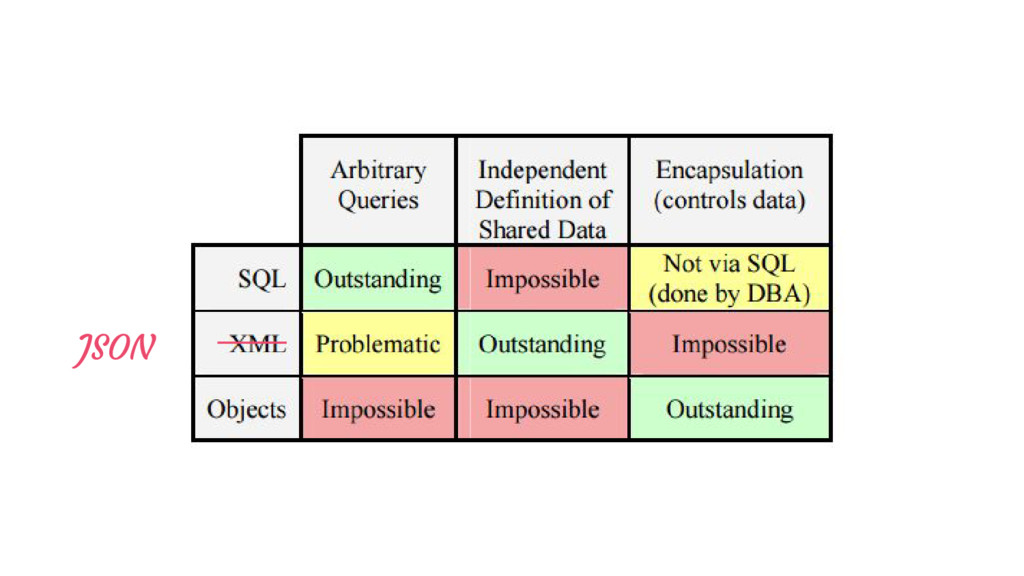
uses B Broken when A calls B, for B’s benefit! There’s no better information hiding than not knowing a service is there at all. Making an RPC call leaks: • There is a service • It’s here • It’s currently available Events are very powerful in this situation.
source and commercial projects, we have observed that there are just a few distinct types of architecture issues, and these occur over and over again…”
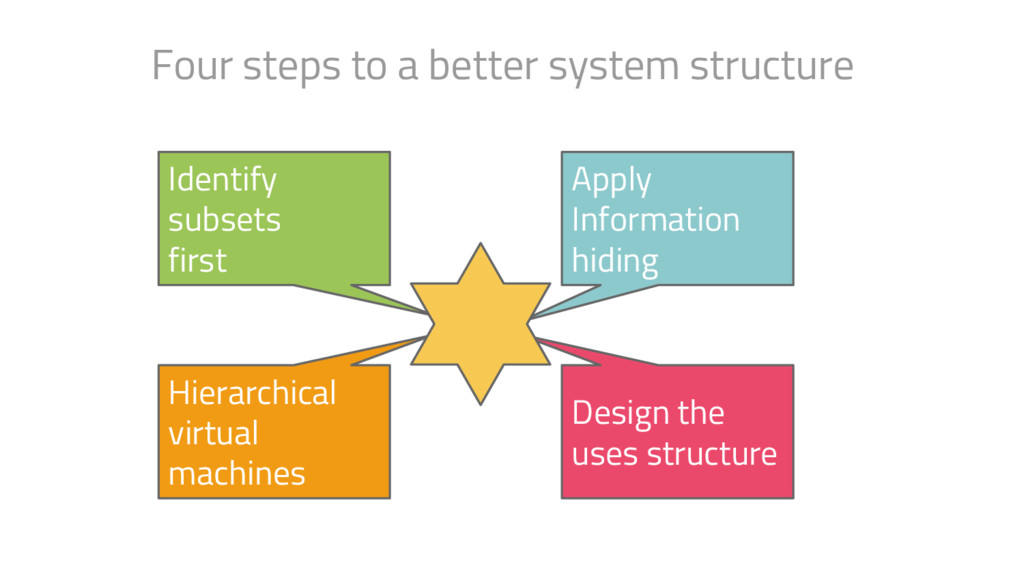
attention to are • the interfaces of the modules and how well they hide information so that changes can be made without cascades, and • the uses structure of the system
of the total project maintenance effort in projects studied • The top five modularity debts alone consume 61% of the total effort • Modularity violation is the most common and expensive debt overall - it accounts for 82% of the total effort in HBase! • Top debts only involve a small number of files/modules, but consume a large amount of the total project effort • About half of all architectural debts accumulate interest at a constant rate.
Usually it is also the most difficult, since the interface design must satisfy three conflicting requirements: an interface should be simple, it should be complete, and it should admit a sufficiently small and fast implementation.”
don’t rush to generalize 2. Don’t promise more than you know how to deliver. Especially don’t add features for the few that penalise the many 3. Make it fast, rather than general or powerful 4. Sometimes, it’s worth a lot of work to make a fast implementation of a clean and powerful interface. But only when you already know the importance of the interface.
way that scales.” How to design a commutative interface: 1. Decompose compound operations(*) 2. Embrace specification non-determinism 3. Permit weak ordering 4. Release resources asynchronously
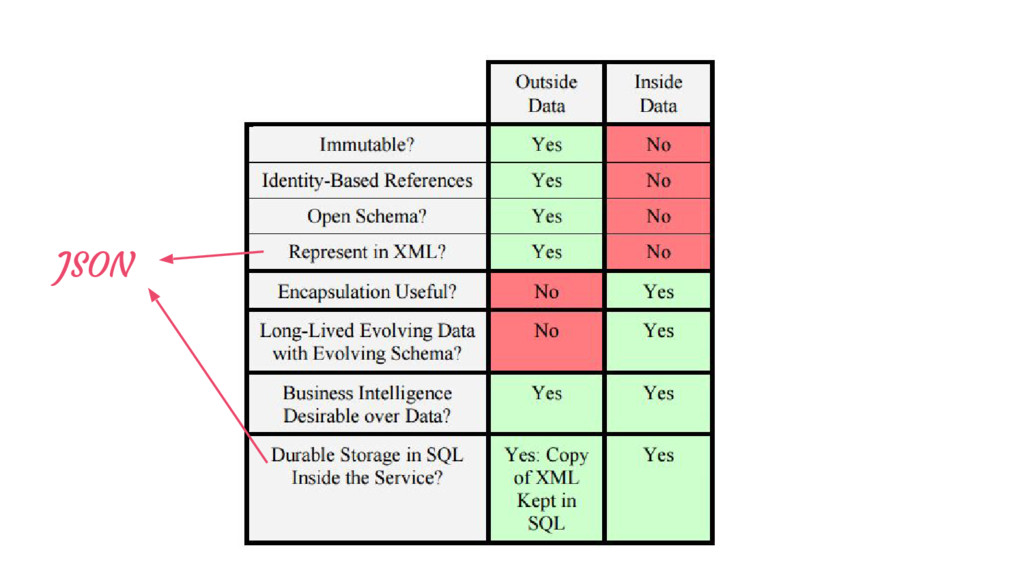
In these systems, there are multiple services each with its own code and data, and ability to operate independently of its partners… This paper proposes there are a number of seminal differences between data inside a service and data sent into the space outside of the service boundary.”
transactions commit, each new transaction perceives the output of the transactions that preceded it. The executing logic of the service lives with a clear and crisp sense of “now” Copyright: Maxim Popov, 123RF Stock Photo
Einstein’s physics. Newton’s time marched forward uniformly with instant knowledge at a distance. Before microservices, distributed computing strove to make many systems look like one with RPC, 2PC etc.. In Einstein’s universe, everything is relative to one’s perspective. Microservices has “now” inside (a service) and the “past” arriving in messages.”
depending on their usage pattern. They live in the past if they have copies of unlocked information from a distant service. They live in the future if they contain proposed values that hopefully will be used if the operator is successfully completed. Between the services, life is in the world of “then”… This means that data on the outside lives in the world of “then”. It is past or future but it is not now.” -> It is up to the microservices themselves to reconcile now and then.
New York Times” ? • Stable • Any referenced data is also immutable • Messages themselves are also immutable (think retries) “Stable data has an unambiguous and unchanging interpretation across space and time… One excellent technique for the creation of stable data is the use of time-stamping and/or versioning.”
attention to are • the interfaces of the modules and how well they hide information so that changes can be made without cascades, and • the uses structure of the system Pay attention to data on the inside vs data on the outside Don’t forget the power of events / messages Some takeaways
Straight to your inbox If you prefer email-based subscription to read at your leisure. 02 Announced on Twitter I’m @adriancolyer. 03 Go to a Papers We Love Meetup A repository of academic computer science papers and a community who loves reading them. 04 Share what you learn Anyone can take part in the great conversation. 05
to be used in decomposing systems into modules https://blog.acolyer.org/2016/09/05/on-the-criteria-to-be-used-in-decomposing-systems-into-modules/ • Information distribution aspects of design methodology: https://blog.acolyer.org/2016/10/17/information-distribution-aspects-of-design-methodology/ • Designing software for ease of extension and contraction: https://blog.acolyer.org/2016/10/31/designing-software-for-ease-of-extension-and-contraction/ • Hotspot patterns: The formal definition and automatic detection of architecture smells https://blog.acolyer.org/2016/06/10/hotspot-patterns-the-formal-definition-and-automatic-detection-of-architecture-smells/ • Identifying and quantifying architectural debt https://blog.acolyer.org/2016/06/13/identifying-and-quantifying-architectural-debt/ • Exploring complex networks https://blog.acolyer.org/2015/05/25/exploring-complex-networks/ • Hints for computer system design https://blog.acolyer.org/2016/09/16/hints-for-computer-system-design/ • The scalable commutativity rule: designing scalable software for multicore processors https://blog.acolyer.org/2015/04/24/the-scalable-commutativity-rule-designing-scalable-software-for-multicore-processors/ • Data on the outside vs data on the inside https://blog.acolyer.org/2016/09/13/data-on-the-outside-versus-data-on-the-inside/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}