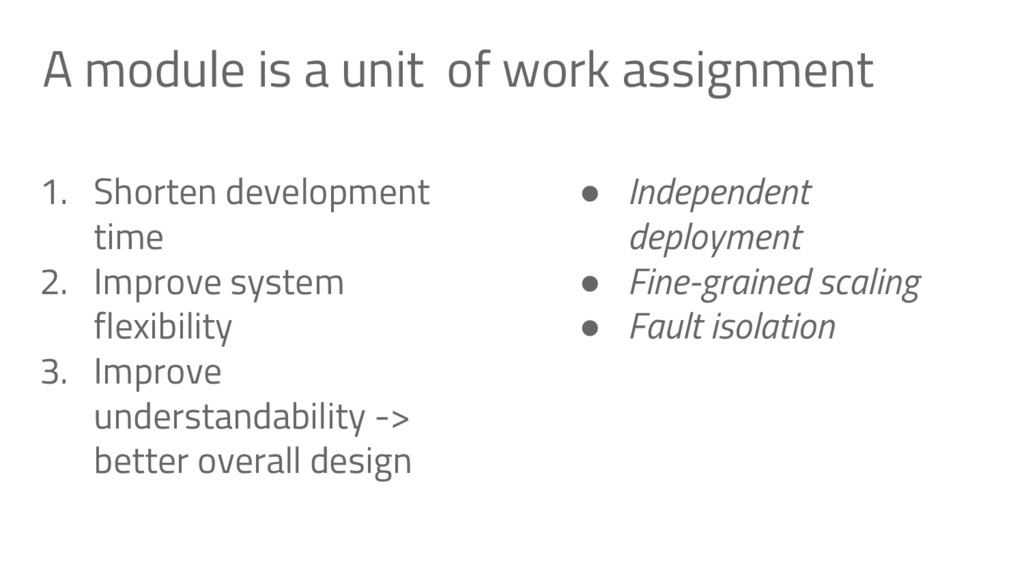
schedule and wanted to deliver an early release, but found that we couldn’t subset the system 2. We wanted to add a simple feature, but found it would have required rewriting all or most of the current code. 3. We wanted to simplify the system by removing some feature, but taking advantage of it meant rewriting large sections of the code 4. We wanted a custom deployment (e.g. in dev, or test environments) but the system wasn’t flexible enough.
iff: • A is essentially simpler because it uses B • B is not substantially more complex because it is not allowed to use A • There is a useful subset containing B and not A • There is no conceivable useful subset containing A but not B And of course, it does not introduce any cycles into the dependency graph
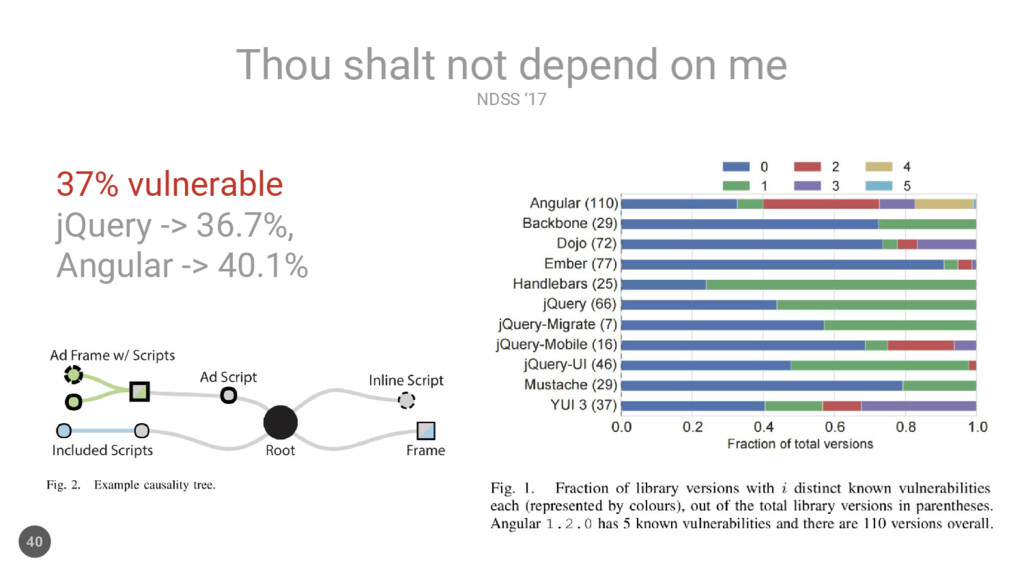
source and commercial projects, we have observed that there are just a few distinct types of architecture issues, and these occur over and over again…”
attention to are • the interfaces of the modules and how well they hide information so that changes can be made without cascades, and • the uses structure of the system
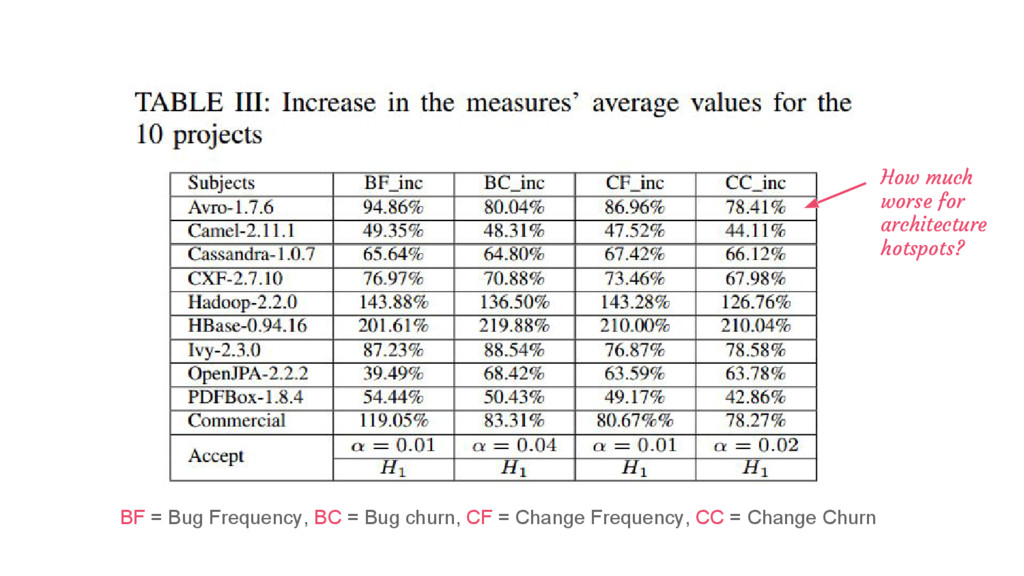
of the total project maintenance effort in projects studied • The top five modularity debts alone consume 61% of the total effort • Modularity violation is the most common and expensive debt overall - it accounts for 82% of the total effort in HBase! • Top debts only involve a small number of files/modules, but consume a large amount of the total project effort • About half of all architectural debts accumulate interest at a constant rate.
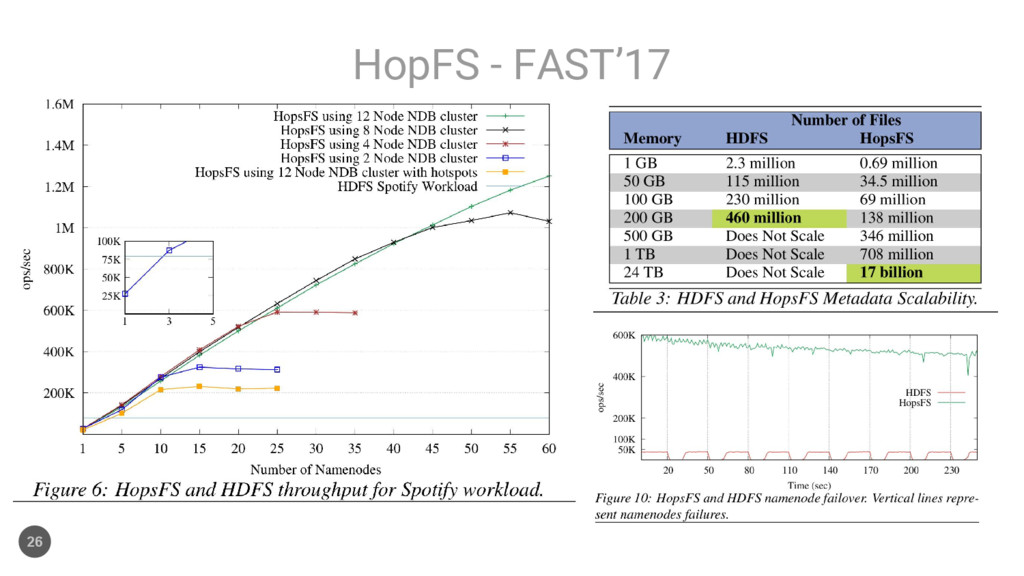
single file-system fault can induce catastrophic outcomes in most modern distributed storage systems...data loss, corruption, unavailability, and, in some cases, the spread of corruption to other intact replicas.”
Research Center Photo Collection http://www.dfrc.nasa.gov/Gallery/Photo/Places/HT ML/E49-54.html. Licensed under Public Domain via Commons - https://commons.wikimedia.org/wiki/File:Human_co mputers_-_Dryden.jpg#/media/File:Human_comput ers_-_Dryden.jpg
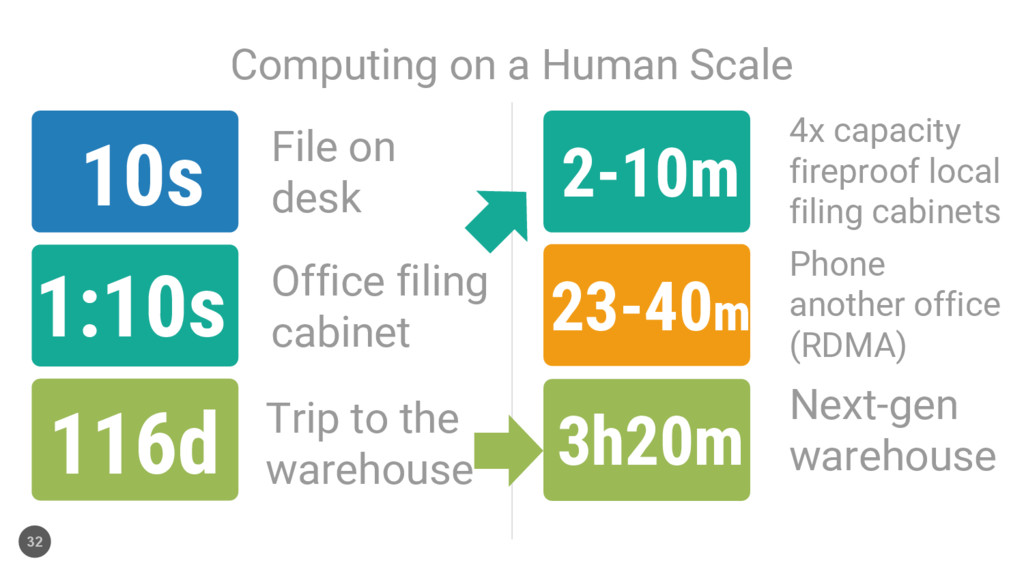
File on desk Office filing cabinet Trip to the warehouse 4x capacity fireproof local filing cabinets 23-40m Phone another office (RDMA) 3h20m Next-gen warehouse
modern data centers can eliminate the need to compromise. It describes the transaction, replication, and recovery protocols in FaRM, a main memory distributed computing platform. FaRM provides distributed ACID transactions with strict serializability, high availability, high throughput and low latency. These protocols were designed from first principles to leverage two hardware trends appearing in data centers: fast commodity networks with RDMA and an inexpensive approach to providing non-volatile DRAM.”
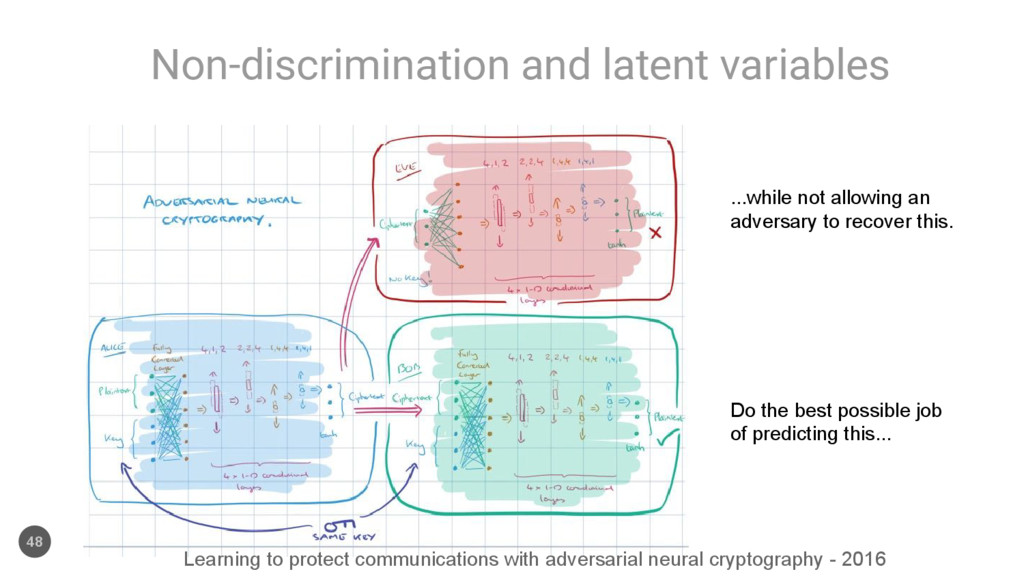
of predicting this... ...while not allowing an adversary to recover this. Learning to protect communications with adversarial neural cryptography - 2016
talk to researchers, when I talk to people wanting to engage in entrepreneurship, I tell them that if you read research papers consistently, if you seriously study half a dozen papers a week and you do that for two years, after those two years you will have learned a lot. This is a fantastic investment in your own long term development. Andrew Ng “Inside the mind that built Google Brain” http://www.huffingtonpost.com.au/2015/05/ 13/andrew-ng_n_7267682.html
know how the human brain works, but it’s almost magical - when you read enough or talk to enough experts, when you have enough inputs, new ideas start appearing. Andrew Ng “Inside the mind that built Google Brain” : http://www.huffingtonpost.com.au/2015/05/13/andrew-ng_n_7267682.html
Straight to your inbox If you prefer email-based subscription to read at your leisure. 02 Announced on Twitter I’m @adriancolyer. 03 Go to a Papers We Love Meetup A repository of academic computer science papers and a community who loves reading them. 04 Share what you learn Anyone can take part in the great conversation. 05
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
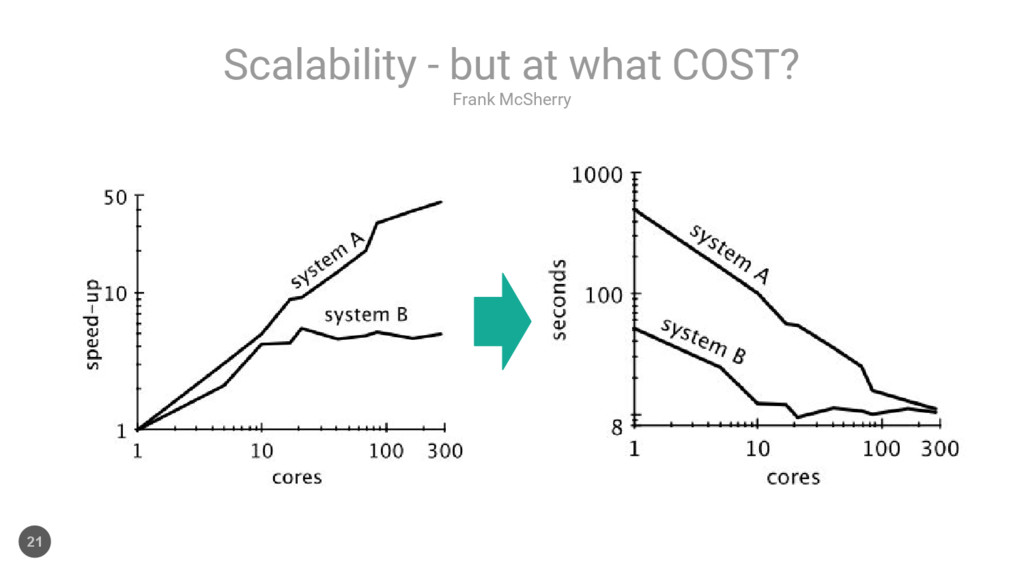{kind=link}
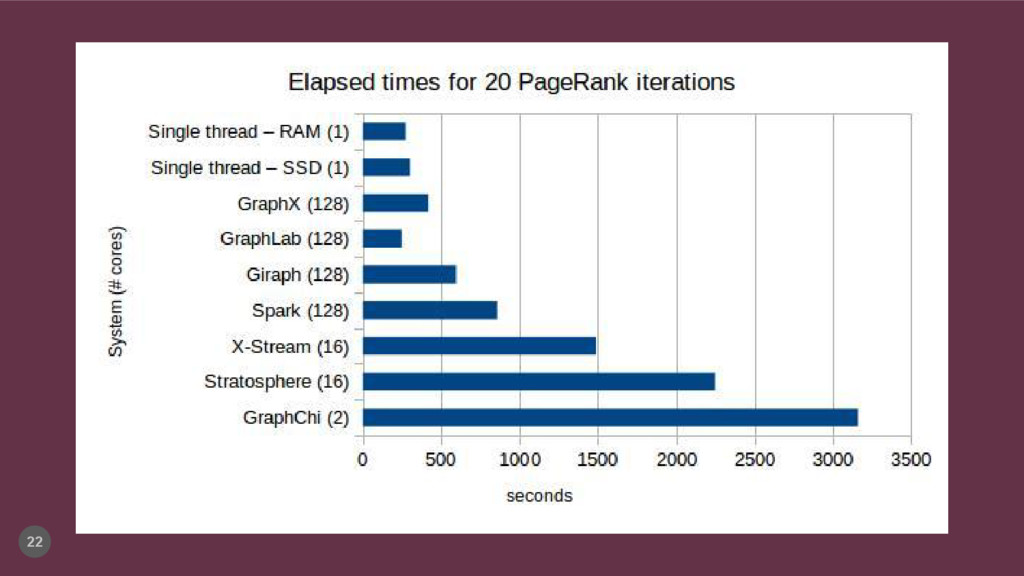{kind=link}
{kind=link}
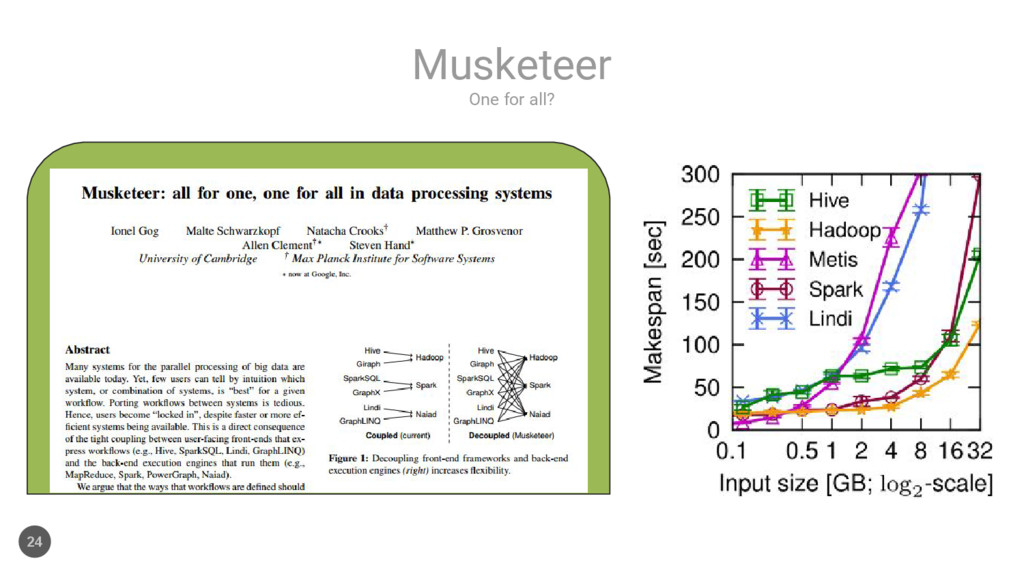{kind=link}
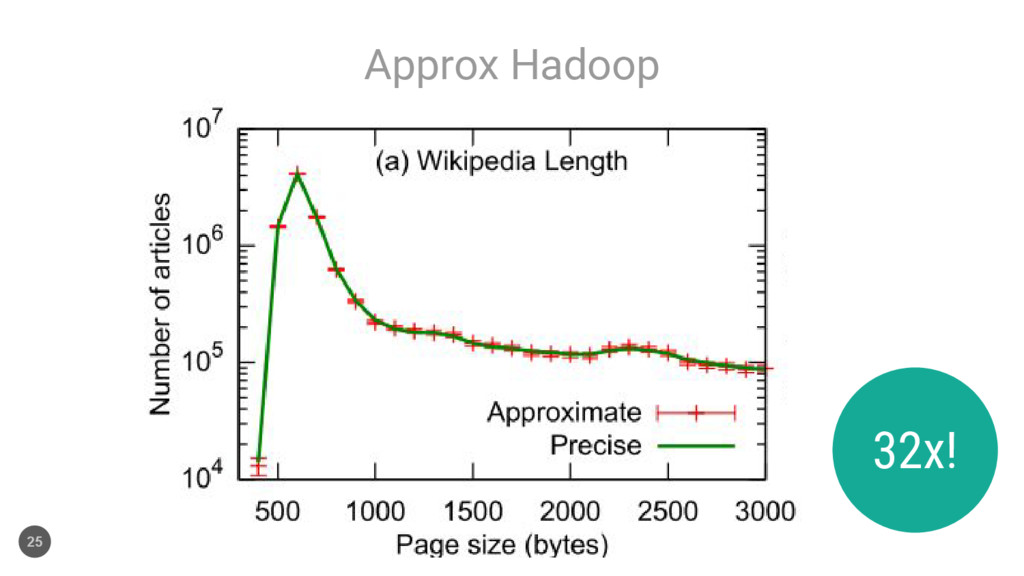{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}