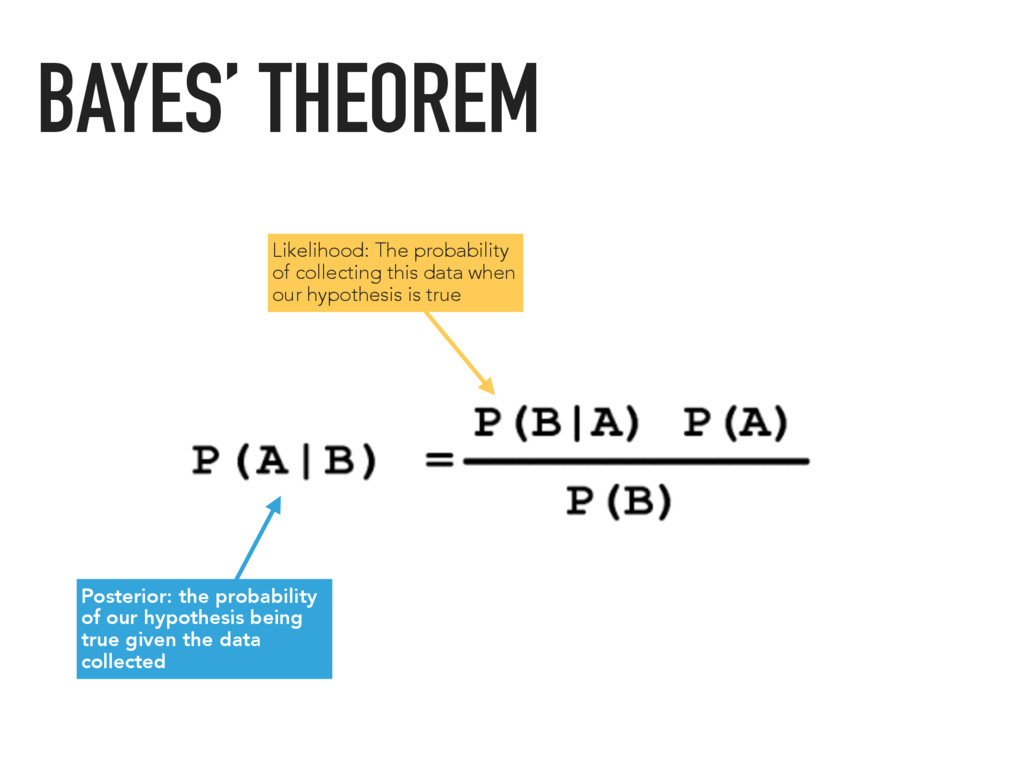
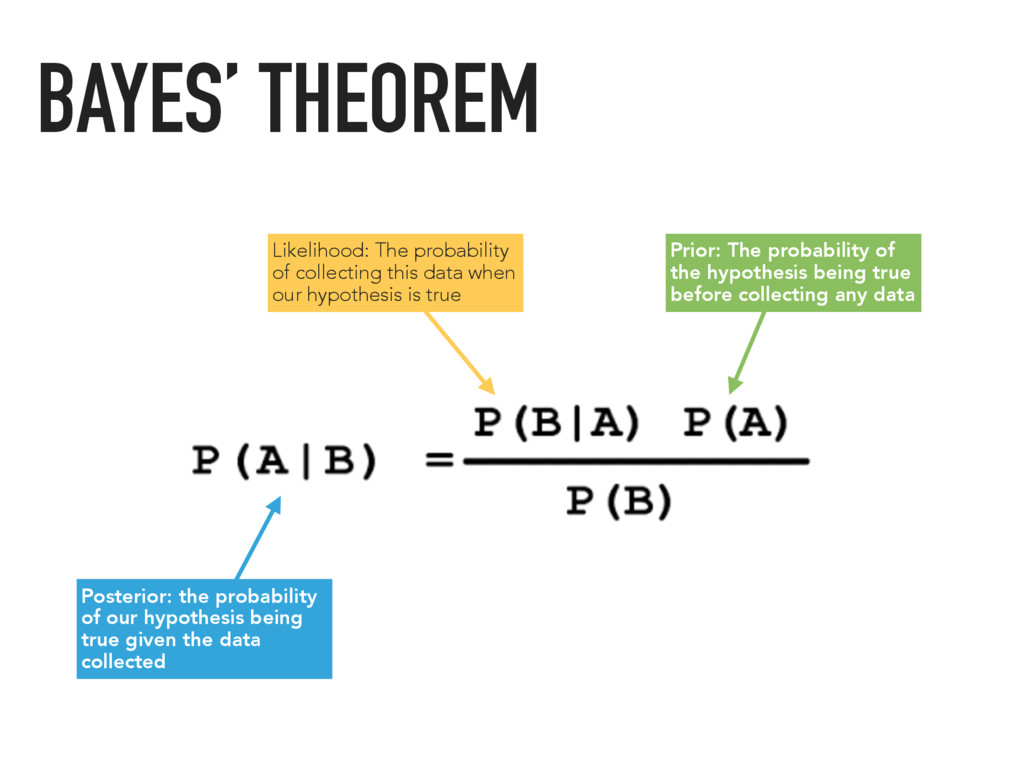
data collected Likelihood: The probability of collecting this data when our hypothesis is true Prior: The probability of the hypothesis being true before collecting any data BAYES’ THEOREM
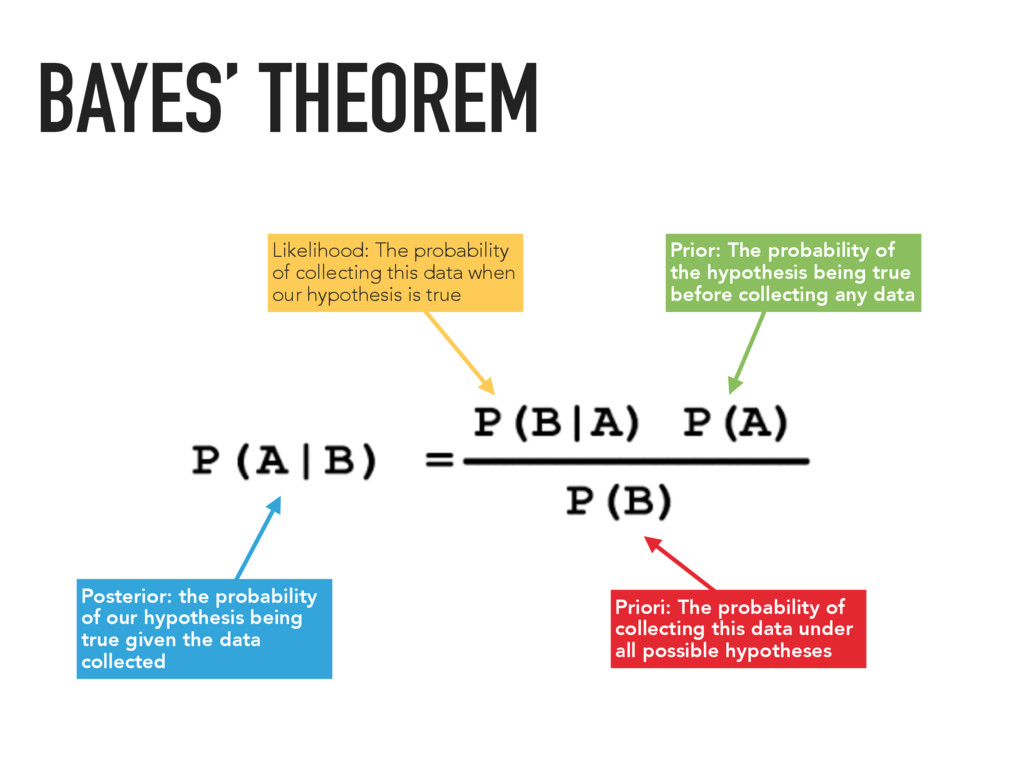
data collected Priori: The probability of collecting this data under all possible hypotheses Likelihood: The probability of collecting this data when our hypothesis is true Prior: The probability of the hypothesis being true before collecting any data BAYES’ THEOREM
P(tweet) tweet = “I really liked this movie” P(tweet) = This is a constant so we’ll disregard it for now. P(x) = Probability of x occurring P(positive) = 0.5 Since we only have 2 classes (negative and positive) there is a 50% chance that something is positive. P(tweet | positive) = number of times the words in the tweet were in a tweet marked as positive in the training set divided by the total number of words marked as positive in the training set. HOW DO WE GET THIS?
words in the tweet were in a tweet marked as positive in the training set divided by the total number of words marked as positive in the training set. tweet = “I really liked this movie” Number of times ‘liked’ occurs in positive tweets = 1623 Number of words in all positive tweets = 2342 1623 / 2342 = 0.692 probability that a tweet that says ‘liked’ will be a positive tweet 69.2%
P(tweet) tweet = “I really liked this movie” P(tweet) = This is a constant so we’ll disregard it for now. P(x) = Probability of x occurring P(positive) = 0.5 Since we only have 2 classes (negative and positive) there is a 50% chance that something is positive. P(tweet | positive) = 0.692 The Number of times the words in the tweet were in a tweet marked as positive in the the training set divided by the total number of words marked as positive in the training set. P(positive | tweet) = 0.692 x 0.5
P(tweet) tweet = “I really liked this movie” P(tweet) = This is a constant so we’ll disregard it for now. P(x) = Probability of x occurring P(positive) = 0.5 Since we only have 2 classes (negative and positive) there is a 50% chance that something is positive. P(tweet | positive) = 0.692 The Number of times the words in the tweet were in a tweet marked as positive in the the training set divided by the total number of words marked as positive in the training set. 0.346 = 0.692 x 0.5 34.6% Probability that the tweet is positive
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
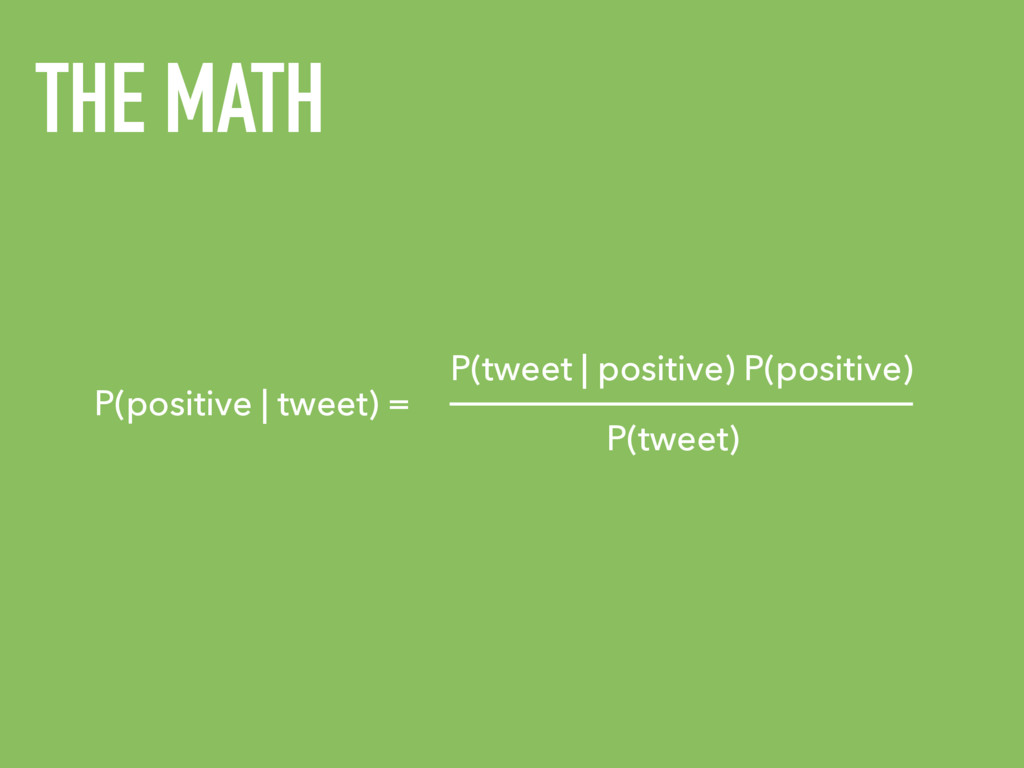{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}