Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWSで始めるサーバーレスなデータ分析基盤
Search
afooooil
October 22, 2025
800
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWSで始めるサーバーレスなデータ分析基盤
JAWS-UG東京 ランチタイムLT会 #28(
https://jawsug.connpass.com/event/367465/
) で発表させていただいた資料です。
afooooil
October 22, 2025
More Decks by afooooil
See All by afooooil
workmuxで始めるClaude Codeの並列開発
afooooil
0
36
DynamoDBからS3(Icebergテーブル)へのZeroETLを行う
afooooil
1
110
退屈なことはAI_Agentにやらせよう
afooooil
0
230
Amazon Qとのより良い付き合い方を考える
afooooil
0
270
ZeroETLで始めるDynamoDBとS3の連携
afooooil
0
310
Featured
See All Featured
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
660
Deep Space Network (abreviated)
tonyrice
0
230
My Coaching Mixtape
mlcsv
0
170
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
620
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Transcript
AWSではじめるサーバーレスな データ分析基盤 株式会社モリサワ 岡田 晃 JAWS-UG東京 ランチタイムLT会 #28
自己紹介 岡田 晃 / @afooooil 所属: 株式会社モリサワ ポジション: データエンジニア /
データサイエンティスト 最近興味のある技術: Apache Iceberg, DuckDB
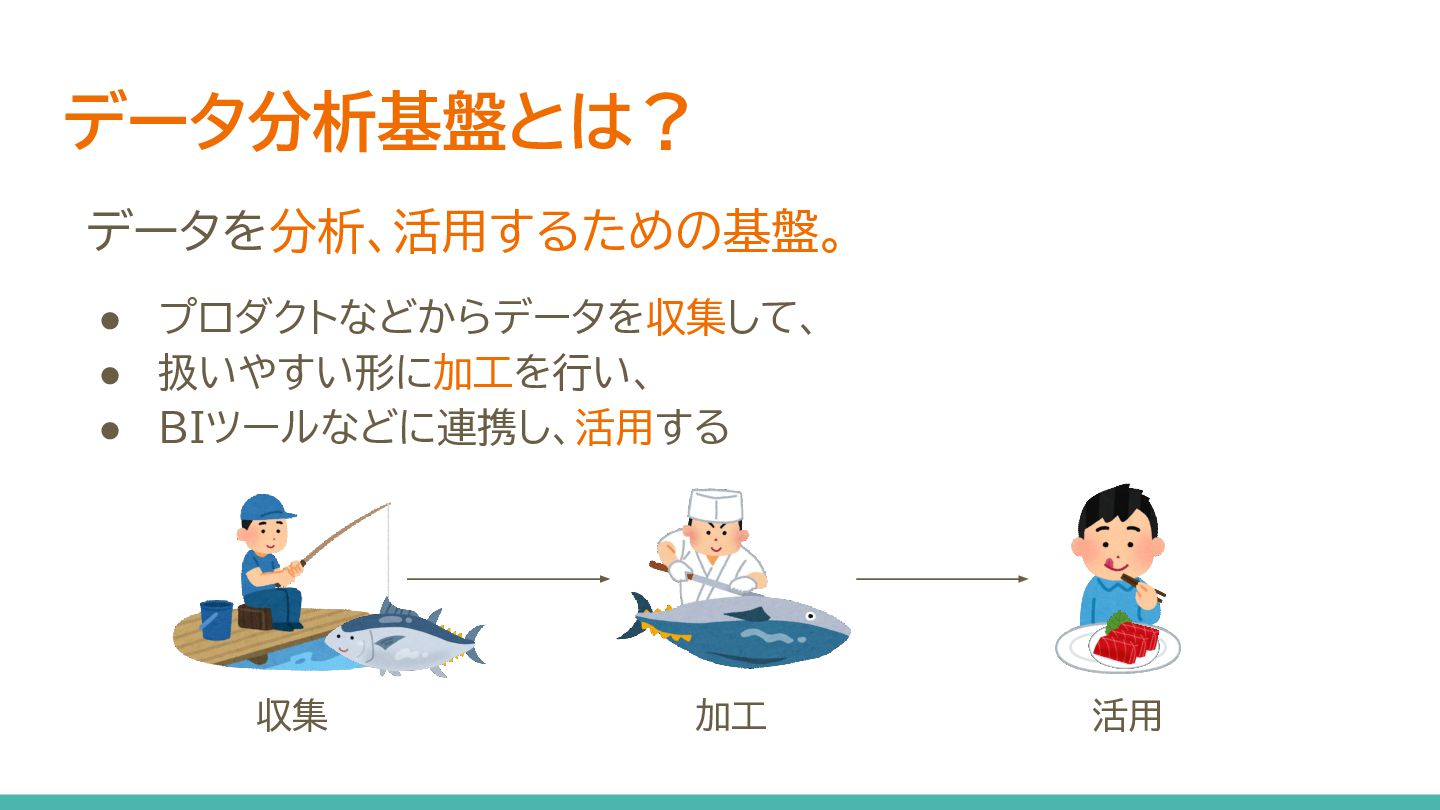
データを分析、活用するための基盤。 • プロダクトなどからデータを収集して、 • 扱いやすい形に加工を行い、 • BIツールなどに連携し、活用する データ分析基盤とは? 収集 加工
活用
構築、運用にかかるコストを下げたかった。 • 自分のロールはデータ分析、活用 + 基盤の整備。 ◦ サーバーレスにすることで浮くリソースを分析業務に配分できる。 サーバーレスに絶対のこだわりがあるわけではなく、要件で必要になることがあれ ば、ECSやRedshiftを利用する。 •
コスト軽減が目的でありサーバーレス化はあくまで手段である。 なぜサーバーレス?
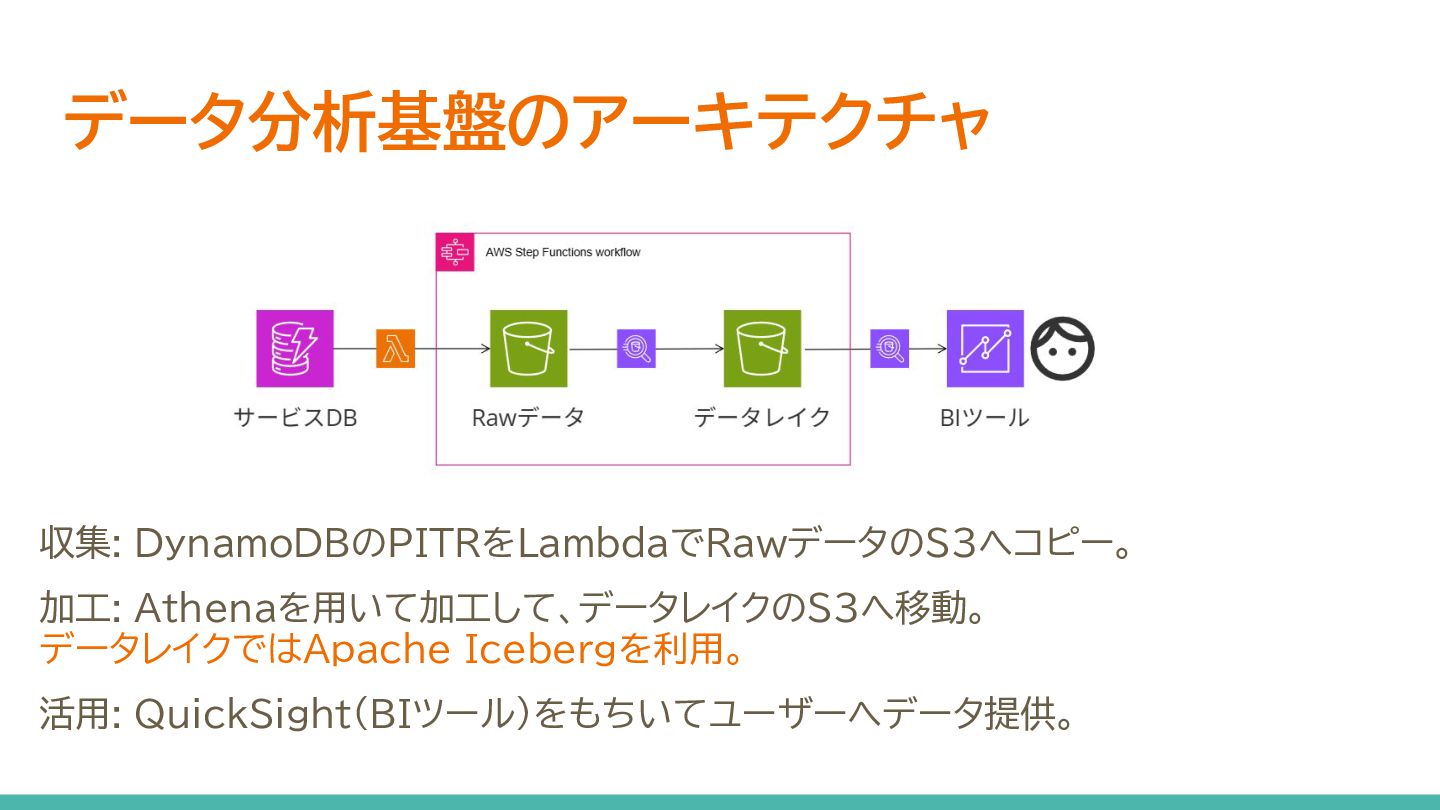
データ分析基盤のアーキテクチャ 収集: DynamoDBのPITRをLambdaでRawデータのS3へコピー。 加工: Athenaを用いて加工して、データレイクのS3へ移動。 データレイクではApache Icebergを利用。 活用: QuickSight(BIツール)をもちいてユーザーへデータ提供。
Apache Icebergとは? Apache IcebergとはOpen Table Formatのひとつ。 - 個々のファイルの集合をあたかも一つのテーブルのように扱える。 - 従来のデータレイクにある課題を解決する次世代のフォーマットとして注目され
ている。 嬉しい特徴の一つとして、レコードの追加、更新、削除を容易に効率的に行う ことがあげられる。 ここでは紹介しませんが、Icebergには他にも様々な魅力的な機能があり ます。
Icebergは何が嬉しいか? SQLを用いてS3上のデータの追加、更新、削除が行える • INSERT, MERGE, DELETEが使える • データソースの変更の差分を継続的にデータレイクに取り込むことも可能 • 一方でS3にあるファイルを直接触らなくて良い
そのためStepFunctionsでAthenaのクエリを定期的に実行するだけで データ変換が可能になる。 Redshiftの導入も視野に入れていたが、Icebergをデータレイクに導入した。 DynamoDBからSageMaker Lakehouse(Icebergテーブル)へのZeroETL も可能になっており導入に向けて検証中
まとめ • Lambda, Athena, QuickSightなどを使うことで、AWS上でサーバレスな データ分析基盤を構築することが可能。 • Apache Icebergではデータの追加、更新、削除が効率的、容易に行うことが できる。
• Apache Icebergをデータレイクに採用することでデータレイクの構築、運用 にかかるコストを低減できる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}