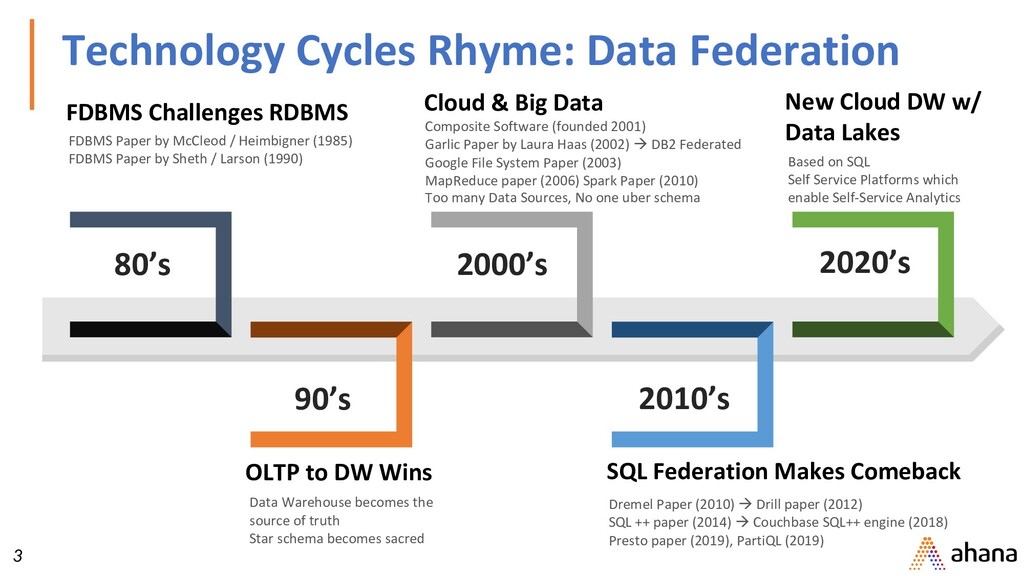
Paper by McCleod / Heimbigner (1985) FDBMS Paper by Sheth / Larson (1990) OLTP to DW Wins Data Warehouse becomes the source of truth Star schema becomes sacred Cloud & Big Data Composite Software (founded 2001) Garlic Paper by Laura Haas (2002) à DB2 Federated Google File System Paper (2003) MapReduce paper (2006) Spark Paper (2010) Too many Data Sources, No one uber schema New Cloud DW w/ Data Lakes Based on SQL Self Service Platforms which enable Self-Service Analytics SQL Federation Makes Comeback Dremel Paper (2010) à Drill paper (2012) SQL ++ paper (2014) à Couchbase SQL++ engine (2018) Presto paper (2019), PartiQL (2019) 80’s 90’s 2000’s 2010’s 2020’s
in Data Analytics Business Needs Data-driven decision making Businesses need more data to iterate over Technology Trends Disaggregation of Storage and Compute The rise of data lakes
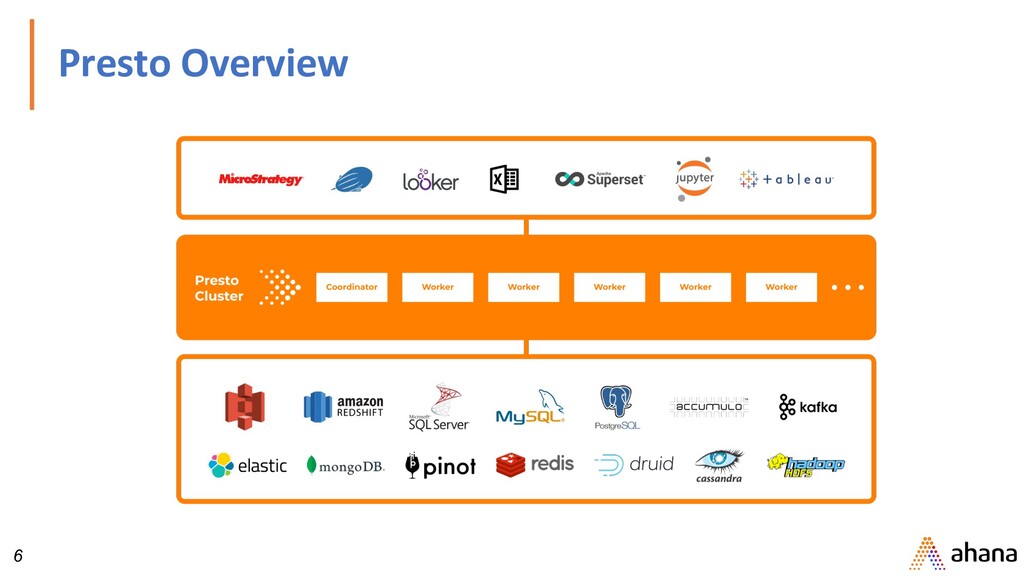
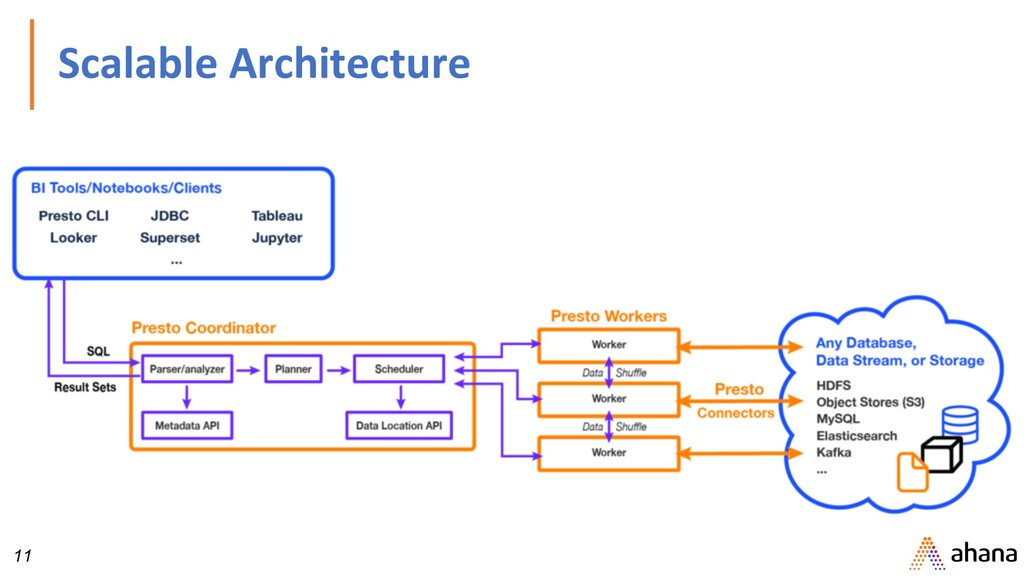
ANSI SQL on Databases, Data lakes • Designed to be interactive • Access to petabytes of data • Opensource, hosted on github • https://github.com/prestodb
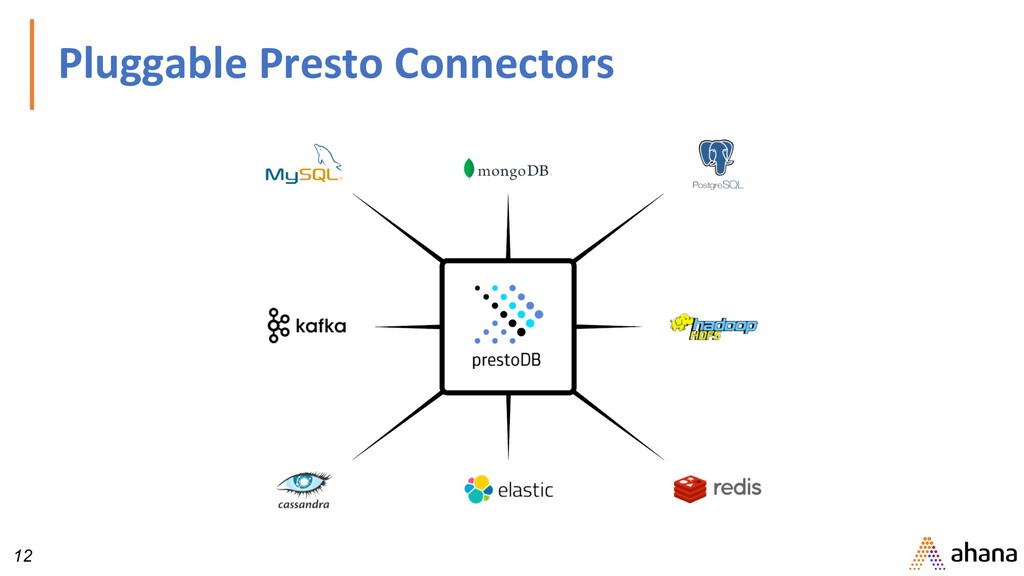
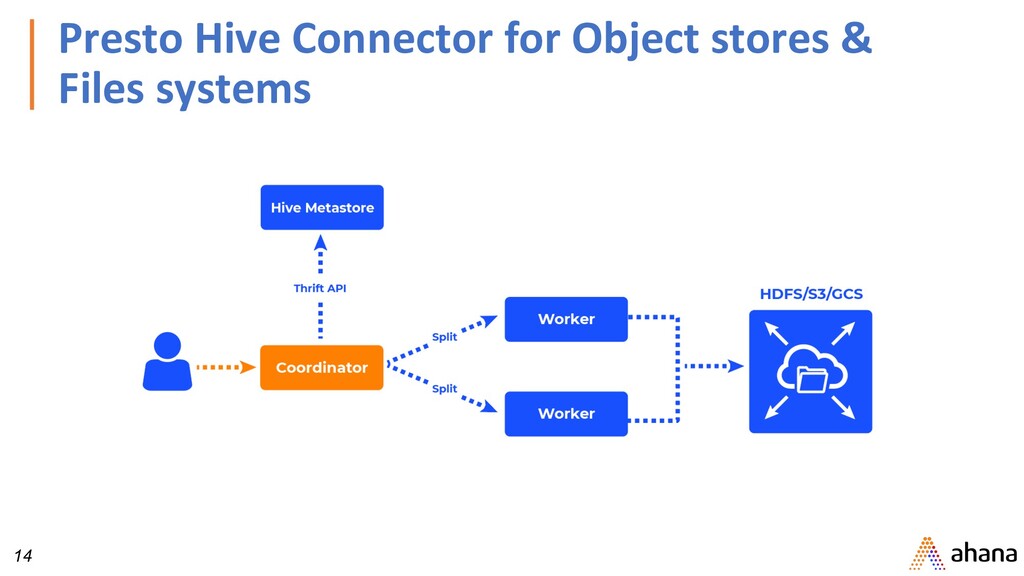
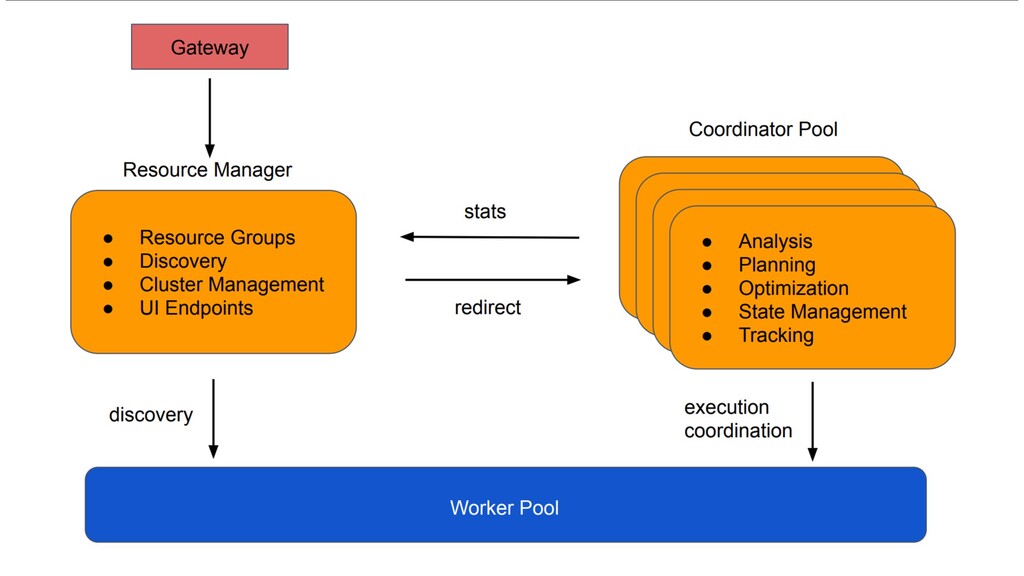
data source. • Example: HDFS, AWS S3, Cassandra, MySQL, SQL Server, Kafka • Catalog: Contains schemas from a data source specified by the connector • Schemas: Namespace to organize tables. • Tables: Set of unordered rows organized into columns with types.
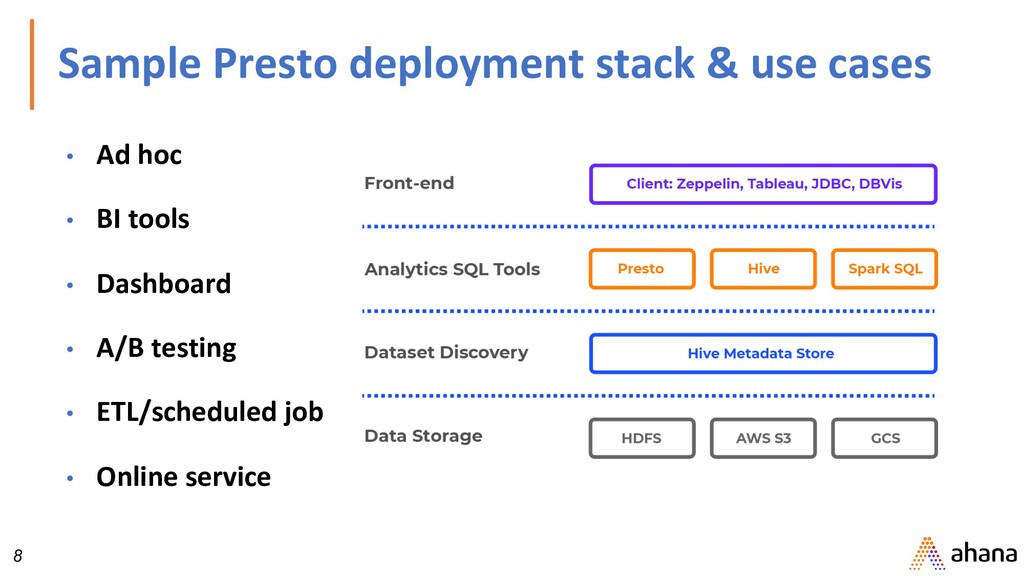
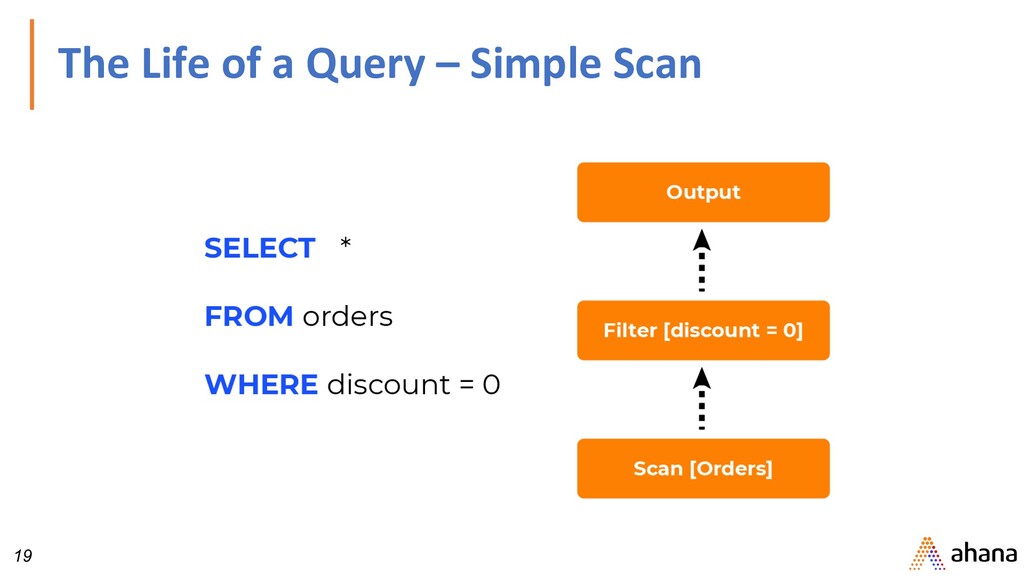
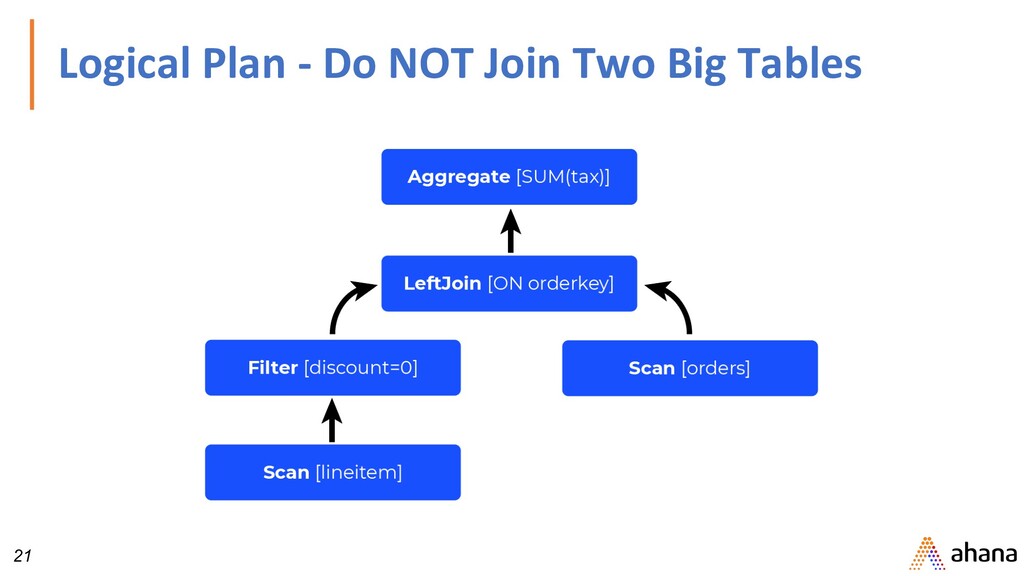
SELECT orders.orderkey, SUM(tax) FROM orders LEFT JOIN lineitem ON orders.orderkey = lineitem.orderkey WHERE discount = 0 GROUP BY orders.orderkey This example is from Presto: SQL on Everything https://research.fb.com/publications/ presto-sql-on-everything/
Named Best Big Data Startup of 2020 by Datanami • Named CRN Top 10 Big Data Startup of 2020 • Investment from Google Ventures, Lux Ventures, Leslie Ventures • Team of experts in cloud, database, and Presto • Premier member of
/etc/presto/node.properties ▪ /etc/presto/jvm.config Many hidden parameters – difficult to tune Just the query engine ▪ No built-in catalog – users need to manage Hive metastore or AWS Glue ▪ No datalake S3 integration Poor out-of-box perf ▪ No tuning ▪ No high-performance indexing ▪ Basic optimizations for even for common queries
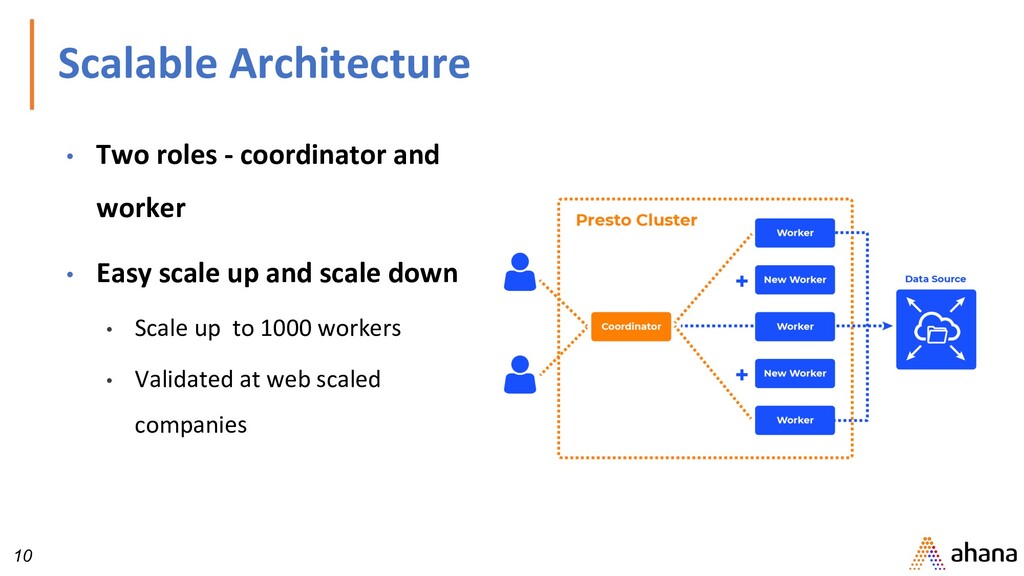
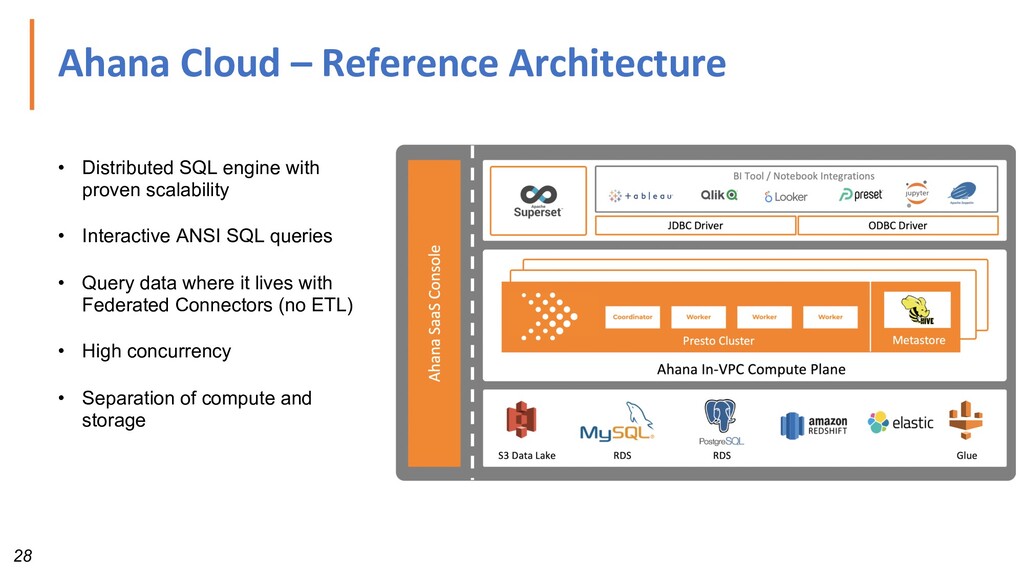
with proven scalability • Interactive ANSI SQL queries • Query data where it lives with Federated Connectors (no ETL) • High concurrency • Separation of compute and storage
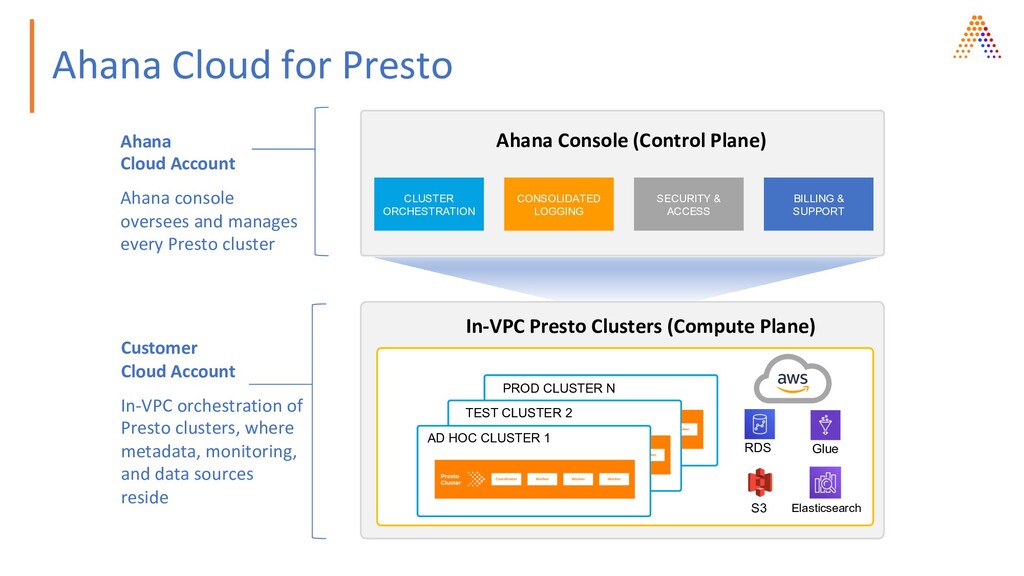
ORCHESTRATION CONSOLIDATED LOGGING SECURITY & ACCESS BILLING & SUPPORT In-VPC Presto Clusters (Compute Plane) AD HOC CLUSTER 1 TEST CLUSTER 2 PROD CLUSTER N Glue S3 RDS Elasticsearch Ahana Cloud Account Ahana console oversees and manages every Presto cluster Customer Cloud Account In-VPC orchestration of Presto clusters, where metadata, monitoring, and data sources reside
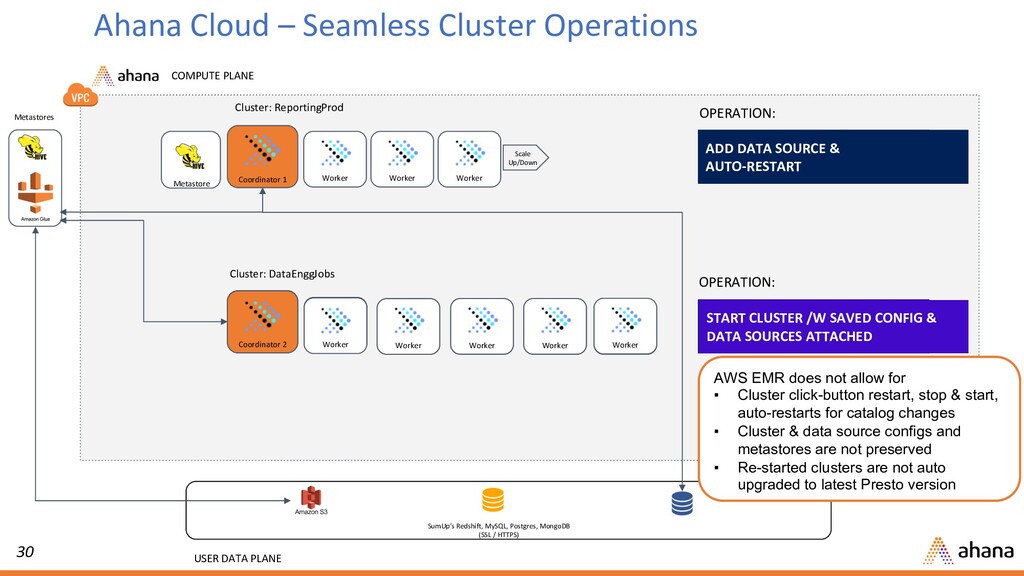
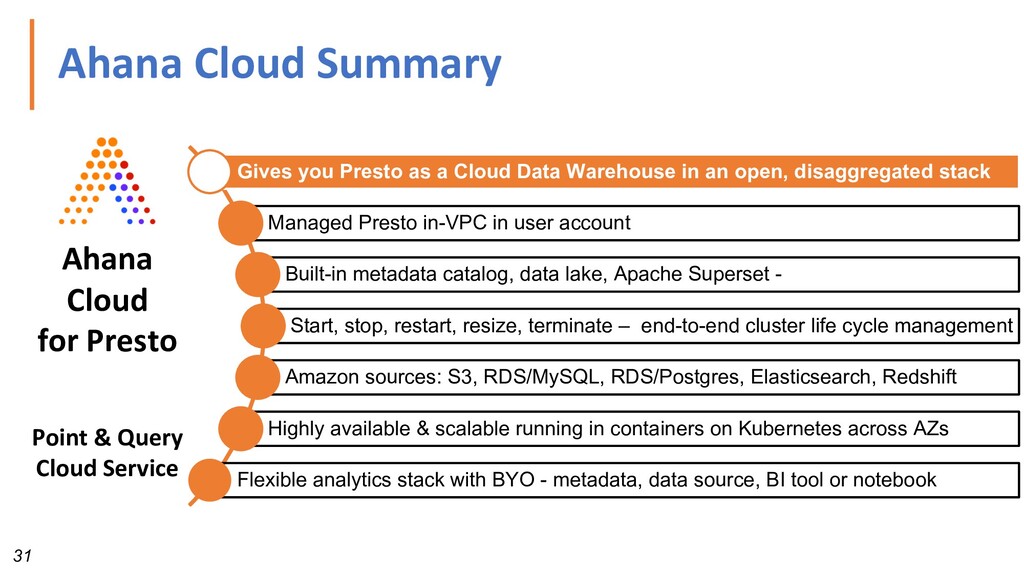
Data Warehouse in an open, disaggregated stack Managed Presto in-VPC in user account Built-in metadata catalog, data lake, Apache Superset - Start, stop, restart, resize, terminate – end-to-end cluster life cycle management Amazon sources: S3, RDS/MySQL, RDS/Postgres, Elasticsearch, Redshift Highly available & scalable running in containers on Kubernetes across AZs Flexible analytics stack with BYO - metadata, data source, BI tool or notebook Ahana Cloud for Presto Point & Query Cloud Service
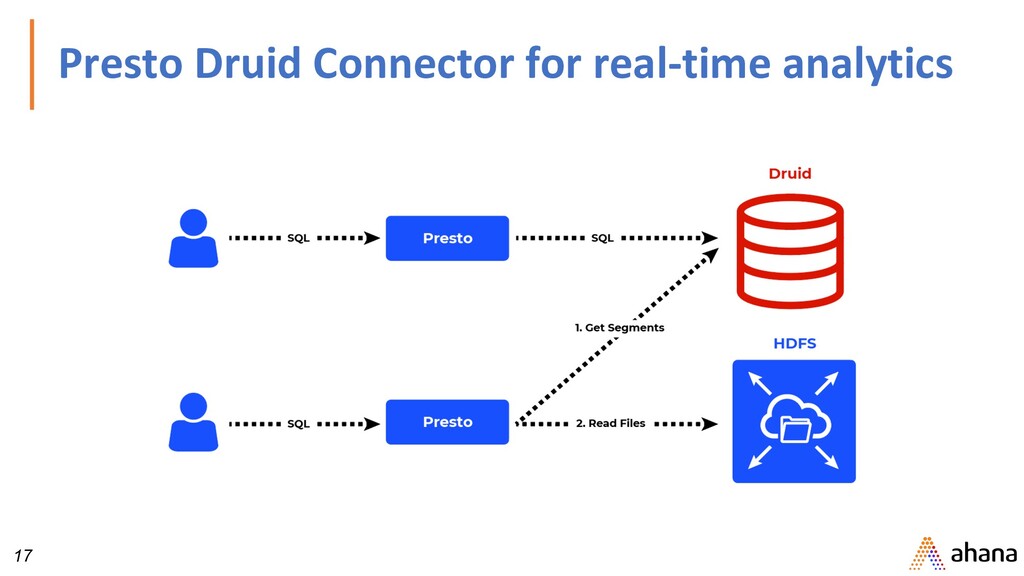
Project Aria - prestodb can now push down entire expression to the data source for some file formats like ORC. https://prestodb.io/blog/2019/12/23/improve-presto-planner https://engineering.fb.com/data-infrastructure/aria-presto/ 2. Grouped execution of non-partitioned tables via Project Presto Unlimited https://prestodb.io/blog/2019/08/05/presto-unlimited-mpp-database-at-scale https://github.com/prestodb/presto/issues/12124 3. UDFs - Dynamic SQL functions support https://prestodb.io/docs/current/admin/function-namespace-managers.html 4. Connectors - Pinot and Druid https://prestodb.io/docs/current/connector.html https://prestosql.io/docs/current/connector.html
Project Aria - prestodb can now push down entire expression to the data source for some file formats like ORC. https://prestodb.io/blog/2019/12/23/improve-presto-planner https://engineering.fb.com/data-infrastructure/aria-presto/ 2. Grouped execution of non-partitioned tables via Project Presto Unlimited https://prestodb.io/blog/2019/08/05/presto-unlimited-mpp-database-at-scale https://github.com/prestodb/presto/issues/12124 3. UDFs - Dynamic SQL functions support https://prestodb.io/docs/current/admin/function-namespace-managers.html 4. Connectors - Pinot and Druid https://prestodb.io/docs/current/connector.html https://prestosql.io/docs/current/connector.html
Project Aria - prestodb can now push down entire expression to the data source for some file formats like ORC. https://prestodb.io/blog/2019/12/23/improve-presto-planner https://engineering.fb.com/data-infrastructure/aria-presto/ 2. Grouped execution of non-partitioned tables via Project Presto Unlimited https://prestodb.io/blog/2019/08/05/presto-unlimited-mpp-database-at-scale https://github.com/prestodb/presto/issues/12124 3. UDFs - Dynamic SQL functions support https://prestodb.io/docs/current/admin/function-namespace-managers.html 4. Connectors - Pinot and Druid https://prestodb.io/docs/current/connector.html https://prestosql.io/docs/current/connector.html
Project Aria - prestodb can now push down entire expression to the data source for some file formats like ORC. https://prestodb.io/blog/2019/12/23/improve-presto-planner https://engineering.fb.com/data-infrastructure/aria-presto/ 2. Grouped execution of non-partitioned tables via Project Presto Unlimited https://prestodb.io/blog/2019/08/05/presto-unlimited-mpp-database-at-scale https://github.com/prestodb/presto/issues/12124 3. UDFs - Dynamic SQL functions support https://prestodb.io/docs/current/admin/function-namespace-managers.html 4. Connectors - Pinot and Druid https://prestodb.io/docs/current/connector.html https://prestosql.io/docs/current/connector.html
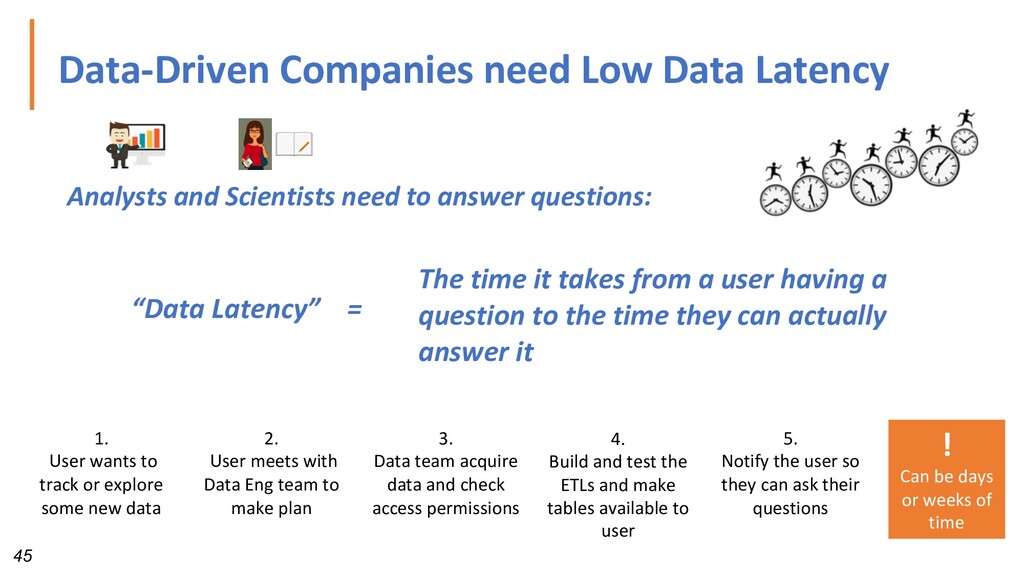
need to answer questions: The time it takes from a user having a question to the time they can actually answer it “Data Latency” = 1. User wants to track or explore some new data 2. User meets with Data Eng team to make plan 3. Data team acquire data and check access permissions 4. Build and test the ETLs and make tables available to user 5. Notify the user so they can ask their questions ! Can be days or weeks of time
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}