Das Lucene-Projekt gibt es schon seit 1999. Mit dem lange erwarteten Release 4 Ende 2012 gab es unter anderem eine bis zu 100x schnellere unscharfe Suche, eine effiziente Indexierung neuer Daten (near realtime search), und eine verbesserte Replikation im Solr Cluster. Seitdem gibt es regelmäßige Minor-Releases.
Grund genug einmal unter die Haube zu schauen: Der Vortrag gibt einen Einstieg wie man Lucene in eine Java-Anwendung einbettet, als Standalone Suchserver betreibt, oder als hochverfügbaren Cluster.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
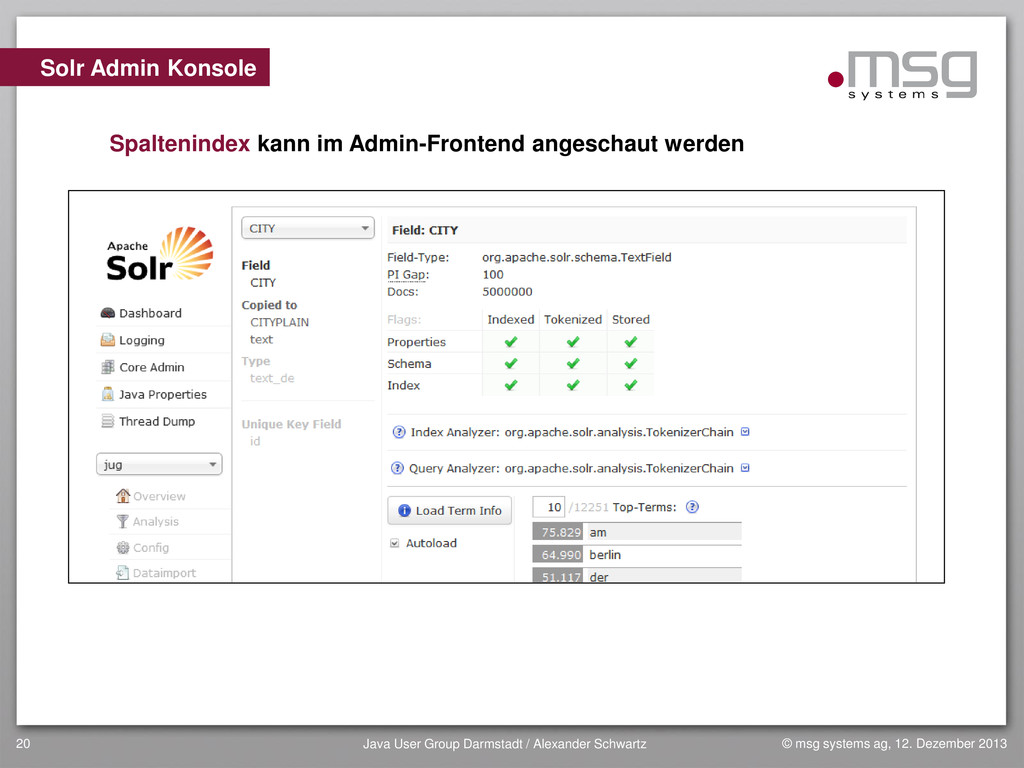{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
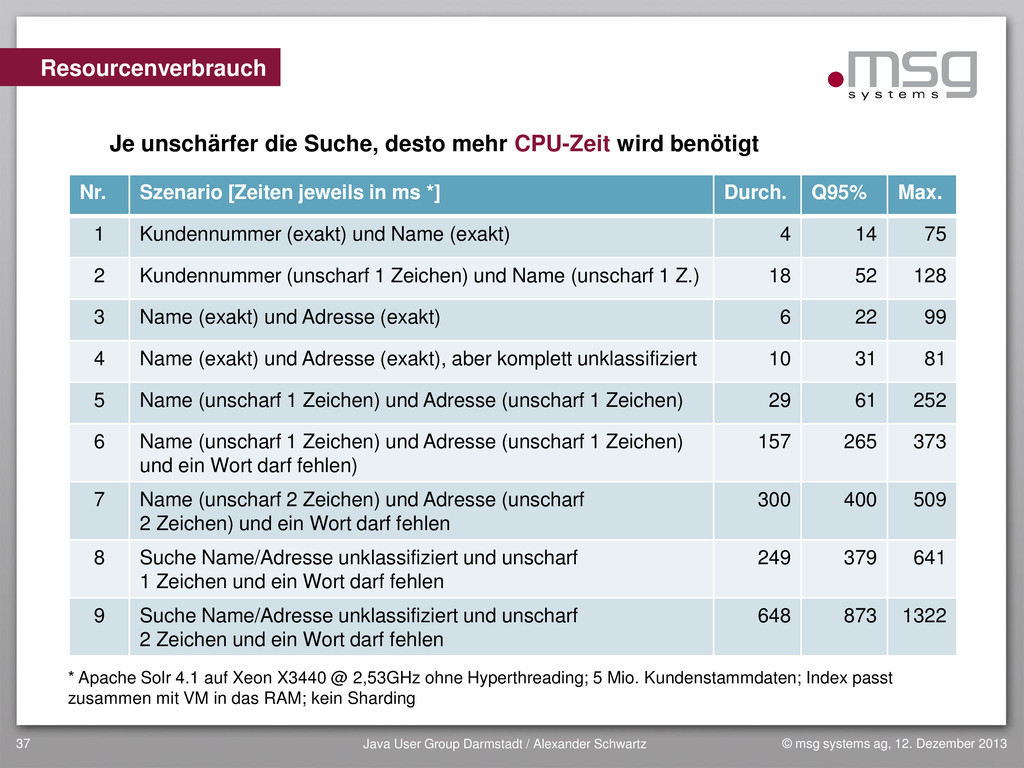{kind=link}
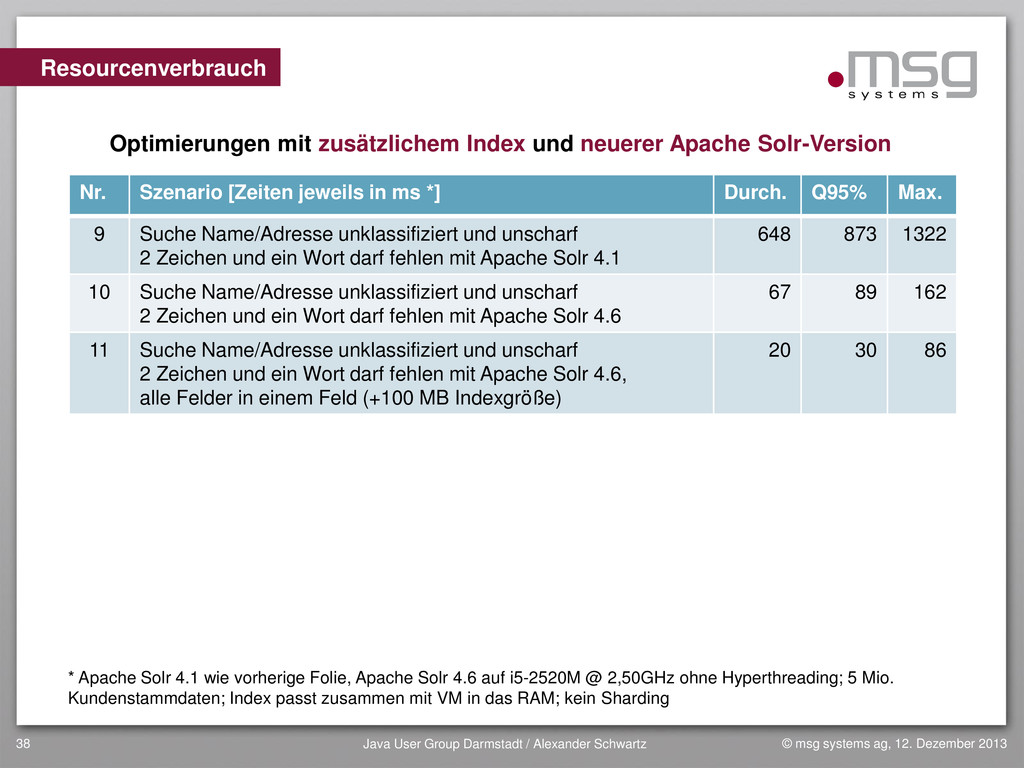{kind=link}
{kind=link}
{kind=link}
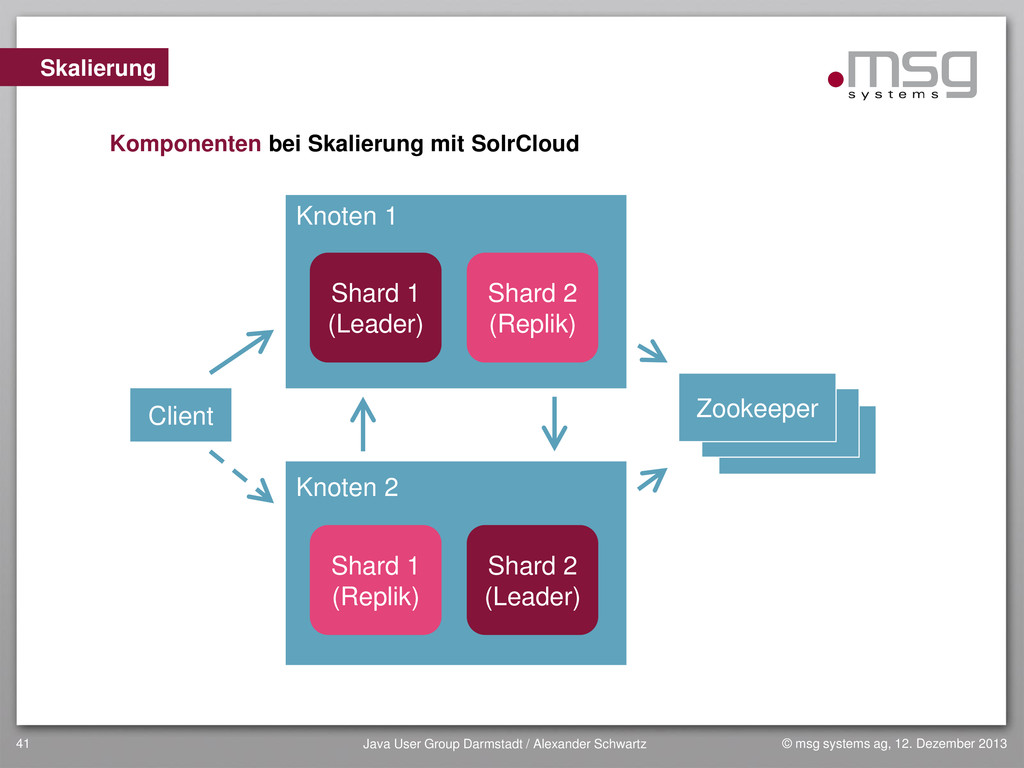{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}