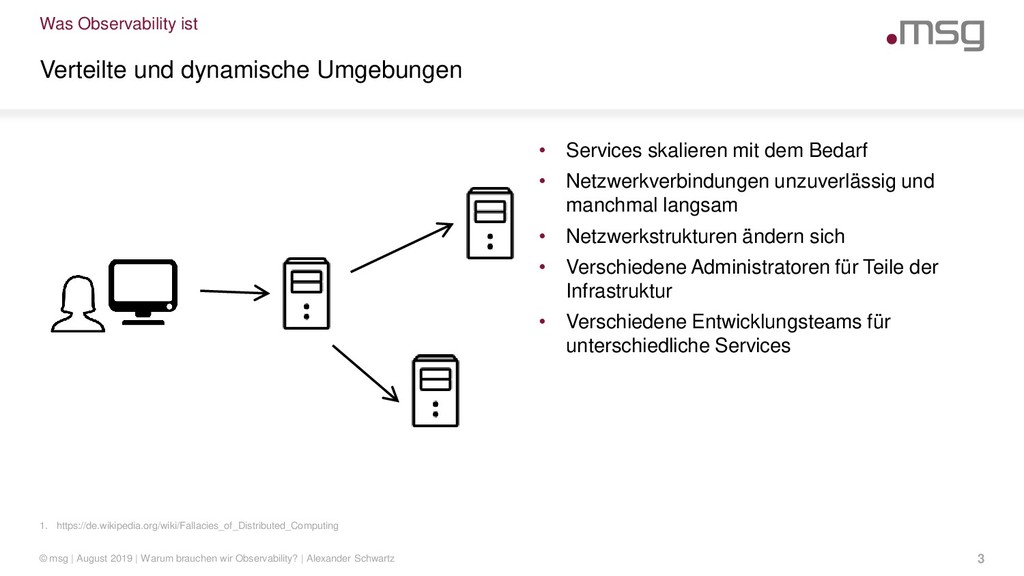
Anwendungen müssen Status- und Laufzeitinformationen bereitstellen, damit Fehler erkannt und analysiert werden können. Verteilte und dynamische Microservice Umgebungen müssen dies standardisiert umsetzen, damit ein effizienter Betrieb möglich ist.
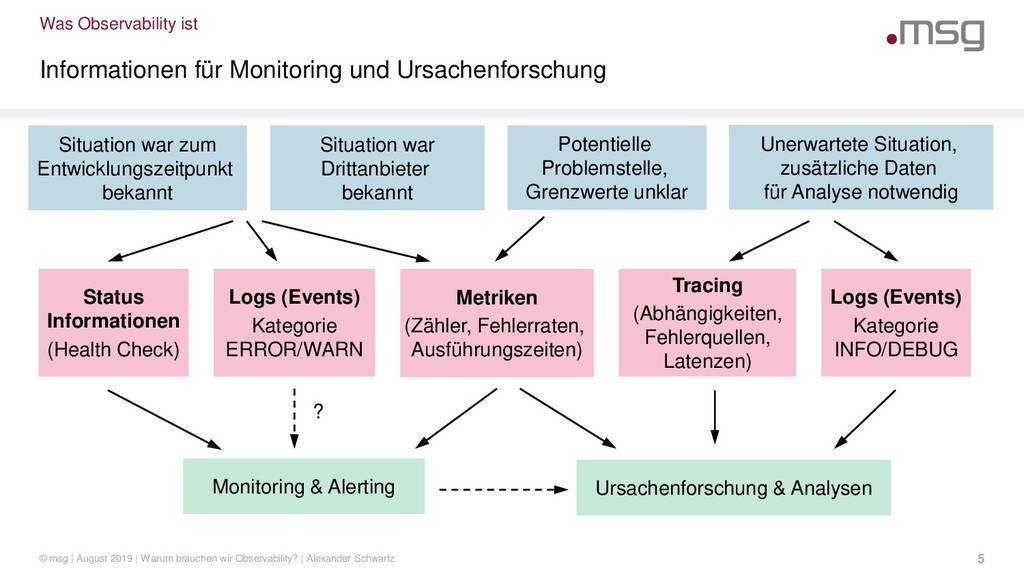
Dieser Vortrag stellt die vier Bereiche vor, die zur Beobachtbarkeit (engl. Observability) dazugehören: Status-Informationen, Logs, Metriken und Traces. Technologie-Beispiele zu Spring Boot Actuator, Log4j, Micrometer und Prometheus zeigen, wie die Konzepte praktisch umgesetzt werden können.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
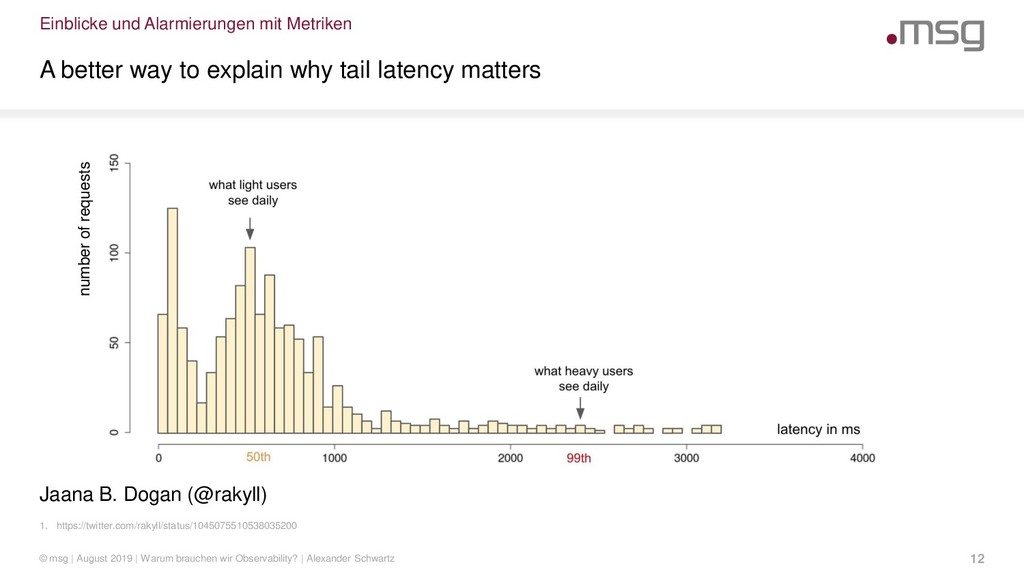{kind=link}
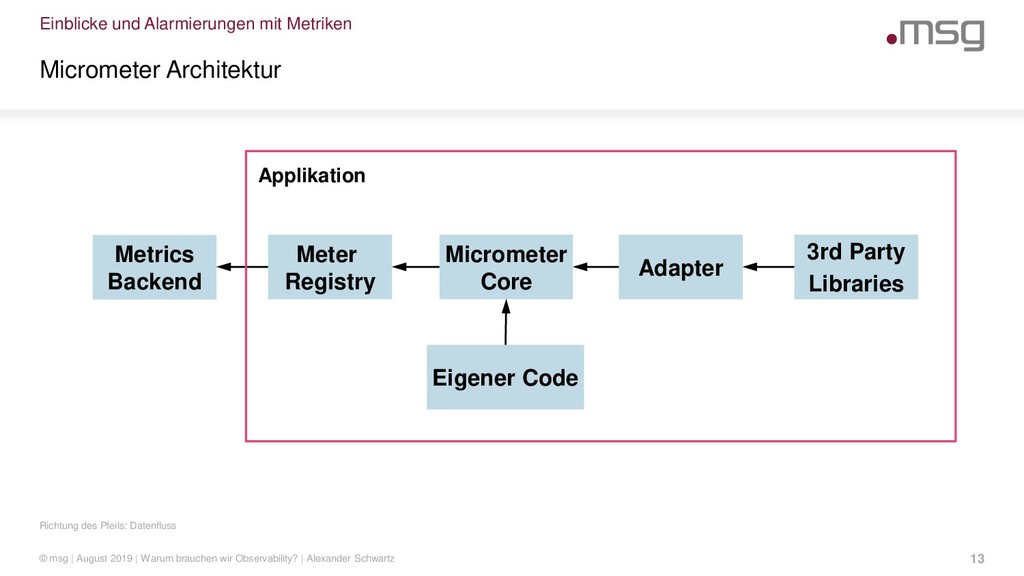{kind=link}
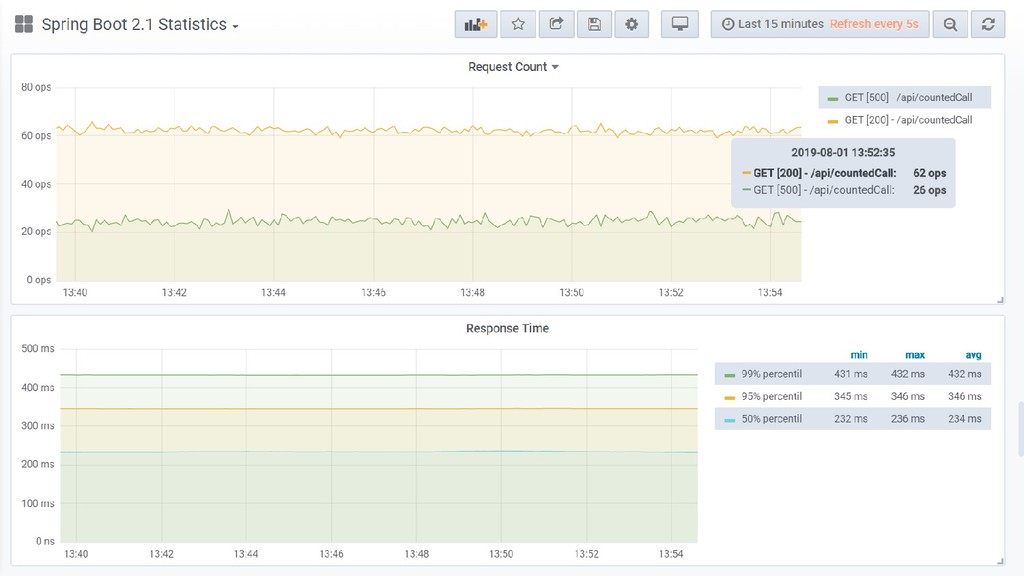{kind=link}
{kind=link}
{kind=link}
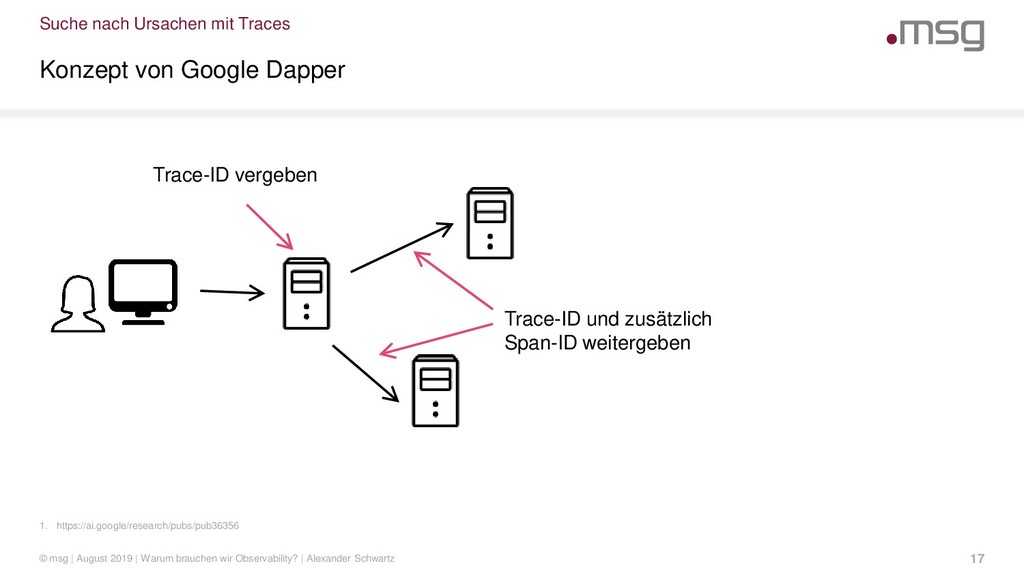{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
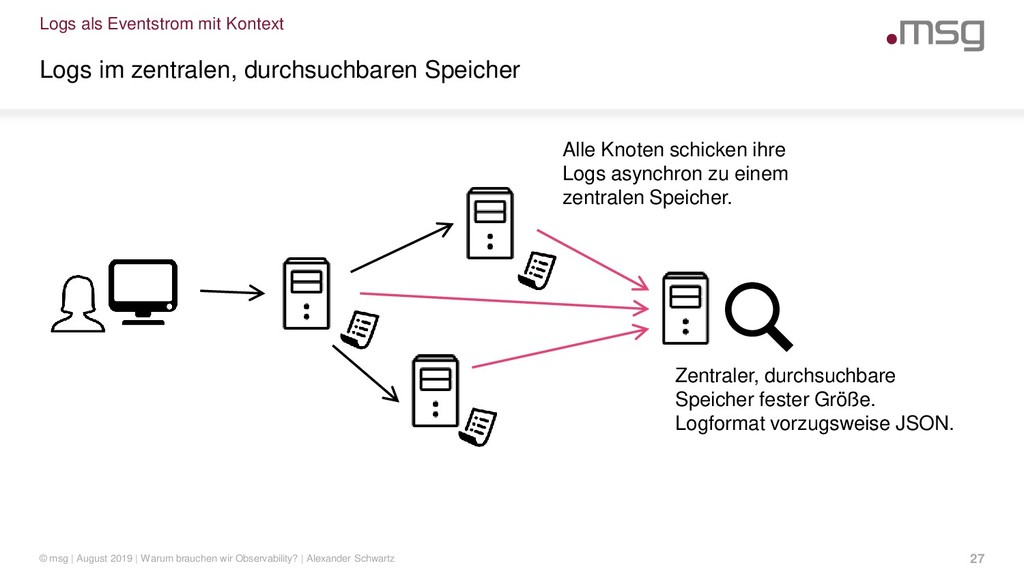{kind=link}
{kind=link}
{kind=link}
{kind=link}
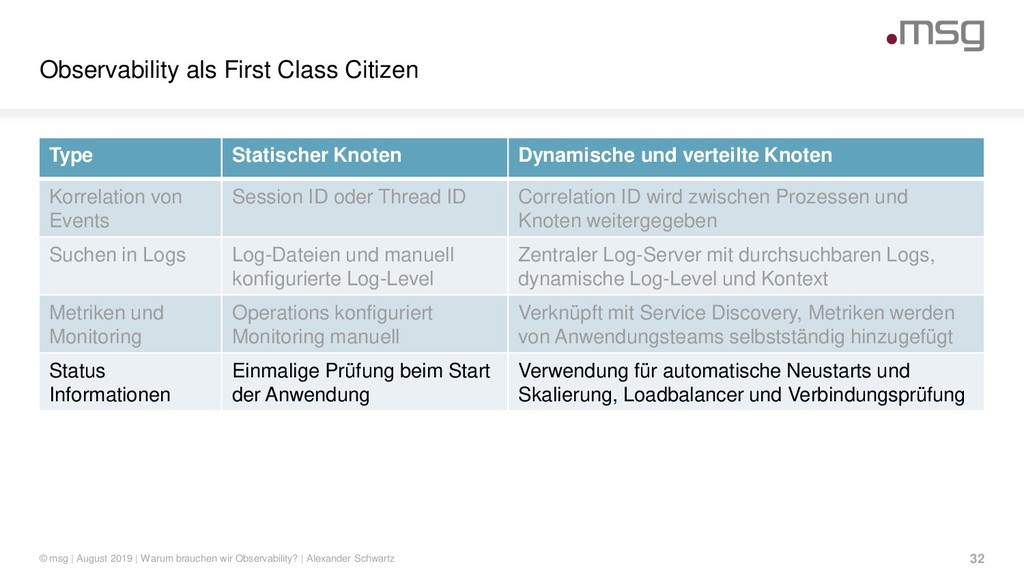
{kind=link}
{kind=link}
{kind=link}
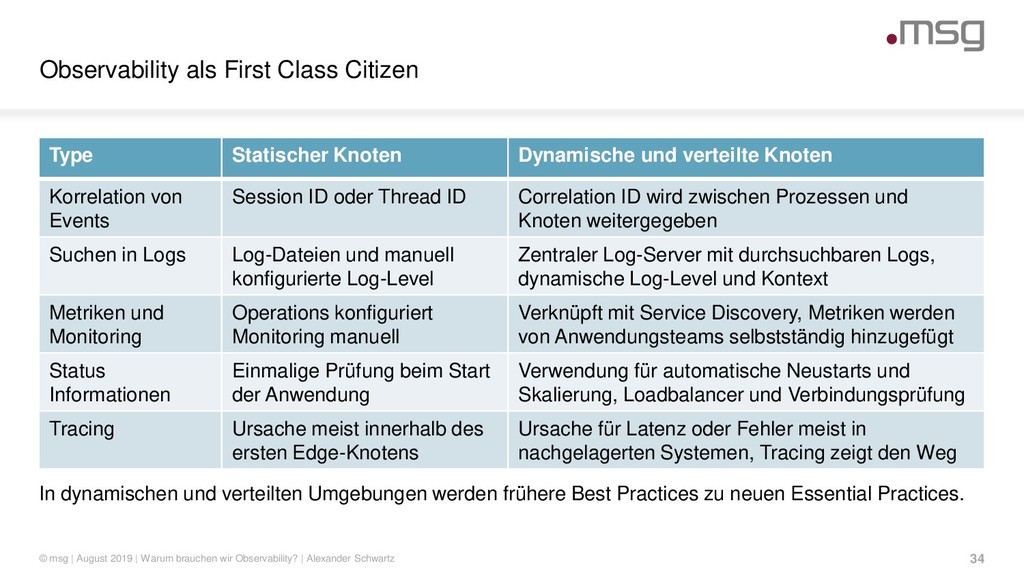{kind=link}
{kind=link}
{kind=link}