Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Mar_05_2020.pdf
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
医療AI研究所@大阪公立大学
March 05, 2020
230
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Mar_05_2020.pdf
医療AI研究所@大阪公立大学
March 05, 2020
More Decks by 医療AI研究所@大阪公立大学
See All by 医療AI研究所@大阪公立大学
GPTの解説:ミートアップ用
ailaboocu
0
510
AI最新論文読み会2022年まとめ
ailaboocu
0
610
AI最新論文読み会2022年12月
ailaboocu
0
640
AI最新論文読み会2022年11月
ailaboocu
0
630
AI最新論文読み会2022年8月
ailaboocu
0
690
AI最新論文読み会2022年7月
ailaboocu
0
710
AI最新論文読み会2022年6月
ailaboocu
0
740
AI最新論文読み会2022年5月11日
ailaboocu
0
770
AI最新論文読み会2022年4月
ailaboocu
1
800
Featured
See All Featured
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Practical Orchestrator
shlominoach
191
11k
YesSQL, Process and Tooling at Scale
rocio
174
15k
How STYLIGHT went responsive
nonsquared
100
6.2k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Being A Developer After 40
akosma
91
590k
Building Adaptive Systems
keathley
44
3.1k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Deep Space Network (abreviated)
tonyrice
0
230
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
Transcript
勉強会⽤ ⼤阪市⽴⼤学⼤学院医学系研究科 放射線診断学・IVR学 ⼈⼯知能研究室 植⽥⼤樹
1. Arxiv top recent articles last month 2. Arxiv top
hype articles last month 3. My favorite Time line
1. Arxiv top recent articles last month 2. Arxiv top
hype articles last month 3. My favorite Time line
①A Simple Framework for Contrastive Learning of Visual Representations 本論⽂は、SimCLR:視覚表現の対照的学習のための単純なフレームワークを提示す
る。筆者らは、特殊化アーキテクチャやメモリバンクを必要とせずに、最近提案され た対照的⾃⼰管理学習アルゴリズムを単純化した。対照的予測タスクが有⽤な表現を 学習することを可能にするものを理解するために、筆者らは筆者らのフレームワーク の主要コンポーネントを系統的に研究した。著者らは、 (1) データ増強の構成が、効 果的な予測タスクを定義する際に重要な役割を果たし、 (2) 表現と対照的損失の間に 学習可能な⾮線形変換を導⼊することが、学習された表現の品質を実質的に改善 し、 (3) 教師付き学習と⽐較して、より⼤きなバッチサイズとより多くの訓練ステッ プからの対照的学習の利点を示す。これらの発⾒を組み合わせることにより、 ImageNet上での⾃⼰管理および半管理学習のための従来の⽅法をかなり上回ること ができる。SimCLRにより学習された⾃⼰管理表現上で訓練された線形分類器は、 76.5%のトップ1精度を達成した。これは、以前の最新技術と⽐較して7%の相対的改 善であり、管理されたResNet‐50の性能に⼀致した。わずか1%のラベル上で微調整 したとき、85.8%のトップ5精度を達成し、100倍少ないラベルでAlexNetを凌駕し た。
②How Good is the Bayes Posterior in Deep Neural Networks
Really? 過去5年間、ベイジアン深層学習コミュニティは、深層ニューラルネットワークでの ベイジアン推論を可能にする、ますます正確かつ効率的な近似推論⼿順を開発してき ました。ただし、このアルゴリズムの進歩と不確実性の定量化とサンプル効率の改善 の⾒込みにもかかわらず、2020年初頭の時点では、産業実践におけるベイジアン ニューラルネットワークの公開された展開はありません。この作業では、⼈気のある ディープニューラルネットワークにおけるベイズの後継者の現在の理解に疑問を投げ かけます。注意深いMCMCサンプリングを通じて、ベイズの事後によって誘導され た事後予測が、SGDから得られたポイント推定を含む単純な⽅法と⽐較して体系的 に悪い予測をもたらすことを示します。さらに、証拠を過⼤評価する「cold posterior」を使⽤することにより、予測パフォーマンスが⼤幅に改善されることを 実証します。このようなcold posteriorは、ベイジアンのパラダイムから⼤きく逸脱 しますが、ベイジアンの深層学習論⽂でヒューリスティックとして⼀般的に使⽤され ます。私たちは、寒い後継者を説明し、実験を通じて仮説を評価できるいくつかの仮 説を提唱しました。私たちの仕事は、ベイジアン深層学習における正確な事後近似の ⽬標に疑問を投げかけます。真のベイズ事後が貧弱な場合、より正確な近似の使⽤は 何ですか?代わりに、cold posteriorのパフォーマンスの向上の起源を理解すること に焦点を合わせるのがタイムリーであると主張します。
③fastai: A Layered API for Deep Learning fastaiはディープラーニングライブラリで、標準的なディープラーニングドメインで 最先端の結果を迅速かつ容易に提供できる⾼度なコンポーネントを実践者に提供し、 新しいアプローチを構築するために組み合わせ可能な低レベルのコンポーネントを研
究者に提供する。使いやすさ、柔軟性、パフォーマンスの⾯で実質的な妥協をするこ となく、両⽅を実現することを⽬指しています。これは、多くのディープラーニング やデータ処理技術の共通基盤パターンを、分離された抽象化の観点から表現する、注 意深く階層化されたアーキテクチャのおかげで可能になった。これらの抽象化は、基 礎となるPython⾔語の動的性とPyTorchライブラリーの柔軟性を活⽤することに よって、簡潔かつ明確に表現することができます。fastaiに含まれるもの:Python⽤ の新しい型ディスパッチシステムと、テンソル⽤のセマンティック型階層;純粋な Pythonで拡張できるGPU最適化コンピュータビジョンライブラリ;現代のオプティマ イザの共通機能を2つの基本部分にリファクタリングし、最適化アルゴリズムを4~5 ⾏のコードで実装できるようにするオプティマイザ;データ、モデル、またはオプ ティマイザの任意の部分にアクセスし、トレーニング中の任意の時点で変更できる新 しい2ウェイコールバックシステム;新しいデータ・ブロックAPI;他にもたくさんあり ます。私たちはこのライブラリを使って完全なディープラーニングコースを作成する ことに成功し、以前のアプローチよりも素早く書くことができ、コードもより明確に なりました。図書館はすでに研究、産業、教育の分野で広く利⽤されている。注:こ の⽂書では、現在http://dev.fast.ai/でプレリリースされているfastai v2について説明 します。
④The Next Decade in AI: Four Steps Towards Robust Artificial
Intelligence ⼈⼯知能と機械学習の最近の研究は、汎⽤学習とますます⼤きなトレーニングセット とますます多くの計算を主に強調しています。 対照的に、私は、認知モデルを中⼼ とした、ハイブリッドで知識主導の推論ベースのアプローチを提案します。これは、 現在可能なものよりも豊富で堅牢なAIの基盤を提供できます。
⑤Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early
Stopping 教師付き下流タスクへの事前訓練⽂脈語埋込みモデルの微調整は、⾃然⾔語処理にお いて⼀般的になった。しかしながら、このプロセスは、しばしば脆く、同じハイパー パラメータ値であっても、異なるランダムシードは、実質的に異なる結果をもたらし 得る。この現象をより良く理解するために、筆者らはGLUEベンチマークからの4つ のデータセットを⽤いて実験し、ランダムシードのみを変化させながら、各々につい て数百回BERTを微調整した。著者らは、以前に報告された結果と⽐較して、かなり の性能増加を発⾒し、最良に発⾒されたモデルの性能が、微調整試⾏の数の関数とし てどのように変化するかを定量化した。さらに、ランダムシードの選択により影響さ れる2つの因⼦、重み初期化と訓練データ順序を検討した。両⽅とも、標本外性能の 分散に⽐較的寄与し、いくつかの重み初期化が調査した全てのタスクで良好に動作す ることを⾒出した。⼩規模データセットでは、多くの微調整試⾏が訓練の途中で分岐 することを観察し、あまり有望でない訓練を早期に中⽌するための実践者のためのベ ストプラクティスを提供する。微調整中のトレーニング動態のさらなる分析を促進す るため、2,100試験のトレーニングおよび検証スコアを含むすべての実験データを公 開しています。
⑥Self-Distillation Amplifies Regularization in Hilbert Space ディープラーニングの⽂脈で導⼊される知識蒸留は、あるアーキテクチャから別の アーキテクチャに知識を伝達する⽅法である。特に、アーキテクチャが同⼀である場 合、これは⾃⼰蒸留と呼ばれる。このアイデアは、再訓練のための新しい⽬標値とし て訓練されたモデルの予測を供給することである(このループを数回繰り返すこと
で)。経験的に、⾃⼰蒸留モデルはしばしば保持データに関してより⾼い精度を達成 することが観察されている。しかし、なぜこのようなことが起こるのかは謎である。 すなわち、⾃⼰蒸留の⼒学は、その仕事についての新しい情報を何も受け取らず、た だ訓練を繰り返すことによって進化するのである。私たちの知る限り、なぜこのよう なことが起こるのかについての厳密な理解はない。本研究は⾃⼰蒸留の最初の理論的 解析を提供する。モデル空間がHilbert空間であり、フィッティングがこの関数空間 におけるL2正則化に従う、⾮線形関数を訓練データにフィッティングすることに焦 点を当てた。⾃⼰蒸留反復は解を表現するために使⽤できる基底関数の数を漸次制限 することにより正則化を修正することを示した。これは、(我々が経験的に証明する ように)ことを意味し、⾃⼰蒸留の数回のラウンドはオーバーフィッティングを減少 させ得るが、さらなるラウンドはアンダーフィッティングをもたらし、したがって、 より悪い性能をもたらし得る。
⑦Bayesian Deep Learning and a Probabilistic Perspective of Generalization ベイジアンアプローチの重要な特徴は、単⼀の重み設定を使⽤するのではなく、周辺
化です。ベイジアン周辺化は、通常、データでは指定不⾜である現代のディープ ニューラルネットワークの精度とキャリブレーションを特に改善でき、多くの説得⼒ のある異なるソリューションを表すことができます。深いアンサンブルが近似ベイジ アン周辺化のための効果的なメカニズムを提供することを示し、⼤きなオーバーヘッ ドなしで、引⼒域内で周辺化することにより予測分布をさらに改善する関連アプロー チを提案します。また、確率論的な観点からそのようなモデルの⼀般化特性を説明す る、ニューラルネットワークの重みのあいまいな分布によって暗示される関数に対す る事前優先順位を調べます。この観点から、ランダムラベル付きの画像を適合させる 能⼒など、ニューラルネットワークの⼀般化に不可解で明確なものとして提示された 結果を説明し、これらの結果がガウス過程で再現できることを示します。最後に、予 測分布を調整するための焼き戻しに関するベイズの視点を提供します。
⑧Torch-Struct: Deep Structured Prediction Library NLPの構造化予測に関する⽂献には、シーケンス、セグメンテーション、アラインメ ント、ツリーに関する分布とアルゴリズムの豊富なコレクションが記載されていま す。ただし、これらのアルゴリズムはディープラーニングフレームワークで利⽤する のが困難です。 Torch-Structを導⼊します。これは、ベクトル化された⾃動分化
ベースのフレームワークを活⽤して統合するように設計された構造化予測のライブラ リです。 Torch-Structには、ディープラーニングモデルに接続するシンプルで柔軟 なディストリビューションベースのAPIを介してアクセスされる確率構造の幅広いコ レクションが含まれています。このライブラリは、バッチ化されたベクトル化された 操作を利⽤し、⾃動微分を活⽤して、読み取り可能で⾼速でテスト可能なコードを⽣ 成します。内部的に、クロスアルゴリズム効率を提供するための多くの汎⽤最適化も 含まれています。実験では、⾼速ベースラインを超える⼤幅なパフォーマンスの向上 が示され、ケーススタディはライブラリの利点を示しています。 Torch-Structは https://github.com/harvardnlp/pytorch-structで⼊⼿できます。
⑨Gradient Boosting Neural Networks: GrowNet 浅いニューラルネットワークを「学習能⼒の低いネットワーク」として⽤いる新しい 勾配ブースティングフレームワークを提案した。この統⼀フレームワークの下で⼀般 損失関数を考察し、分類、回帰およびランク付け学習のための具体例を示した。古典 的勾配ブースティング決定⽊の欲張り関数近似の落とし⽳を改善するために、完全な 修正ステップを組み込んだ。提案したモデルは、複数のデータセット上の3つのタス
クすべてにおいて最先端の結果を示した。アブレーション研究を⾏い、各モデル成分 とモデル超パラメータの効果を明らかにした。
⑩Cross-Iteration Batch Normalization バッチ正規化のよく知られた問題は、⼩さなミニバッチサイズの場合にその有効性が 著しく低下することである。ミニバッチが少数の例を含む場合、正規化が定義される 統計は、訓練反復の間、それから信頼できる推定ができない。この問題に取り組むた めに、筆者らはCross‐Iteration Batch Normalization(CBN)を提示した。そこでは、 複数の最近の反復からの例を、推定品質を強化するために共同で利⽤した。複数反復
にわたる統計計算の課題は、異なる反復からのネットワーク活性化がネットワーク重 みの変化のために互いに⽐較できないことである。従って、Taylor多項式に基づく提 案⼿法によりネットワーク重み変化を補償し、統計量を正確に推定でき、バッチ正規 化を効果的に適⽤できる。⼩さいミニバッチサイズを持つ物体検出と画像分類に関し て、CBNは元のバッチ正規化と提案した補償技術なしでの以前の反復にわたる統計 量の直接計算より優れていることが分かった。
1. Arxiv top recent articles last month 2. Arxiv top
hype articles last month 3. My favorite Time line
①A Primer in BERTology: What we know about how BERT
works 変換器ベースのモデルは現在NLPで広く使⽤されているが、我々はまだそれらの内部 構造について多くを理解していない。有名なBERTモデル(Devlinら、2019年)につい てこれまでに知られていることを述べ、40以上の解析研究を統合した。また、提案し たモデルの修正とその訓練体制の概要を示した。その後、さらなる研究の⽅向性を概 説する。
②GANILLA: Generative Adversarial Networks for Image to Illustration Translation この論⽂では、対になっていない画像から画像への翻訳の新しい領域として、児童書
のイラストを探求します。現在の最先端の画像から画像への変換モデルは、スタイル またはコンテンツのいずれかを正常に転送しますが、両⽅を同時に転送することはで きません。この問題に対処するための新しいジェネレーターネットワークを提案し、 結果のネットワークがスタイルとコンテンツのバランスを改善することを示します。 ペアになっていない画像から画像への変換のための明確に定義された、または合意さ れた評価指標はありません。これまで、画像変換モデルの成功は、限られた数の画像 での主観的、定性的な視覚的⽐較に基づいていました。この問題に対処するために、 個別の分類⼦を使⽤してコンテンツとスタイルの両⽅が考慮される、イメージからイ ラストへのモデルの定量的評価のための新しいフレームワークを提案します。この新 しい評価フレームワークでは、提案されたモデルは、イラストデータセットの現在の 最新モデルよりも優れたパフォーマンスを発揮します。コードと事前学習済みのモデ ルは、https://github.com/giddyyupp/ganillaにあります。
③Bayesian Deep Learning and a Probabilistic Perspective of Generalization ベイジアンアプローチの重要な特徴は、単⼀の重み設定を使⽤するのではなく、周辺
化です。ベイジアン周辺化は、通常、データでは指定不⾜である現代のディープ ニューラルネットワークの精度とキャリブレーションを特に改善でき、多くの説得⼒ のある異なるソリューションを表すことができます。深いアンサンブルが近似ベイジ アン周辺化のための効果的なメカニズムを提供することを示し、⼤きなオーバーヘッ ドなしで、引⼒域内で周辺化することにより予測分布をさらに改善する関連アプロー チを提案します。また、確率論的な観点からそのようなモデルの⼀般化特性を説明す る、ニューラルネットワークの重みのあいまいな分布によって暗示される関数に対す る事前優先順位を調べます。この観点から、ランダムラベル付きの画像を適合させる 能⼒など、ニューラルネットワークの⼀般化に不可解で明確なものとして提示された 結果を説明し、これらの結果がガウス過程で再現できることを示します。最後に、予 測分布を調整するための焼き戻しに関するベイズの視点を提供します。
④MLIR: A Compiler Infrastructure for the End of Moore's Law
本研究は、再利⽤可能で拡張可能なコンパイラ基盤を構築するための新しいアプロー チであるMLIRを提示する。MLIRは、ソフトウェアの断⽚化に対処し、異種ハード ウェアのコンパイルを改善し、ドメイン固有のコンパイラの構築コストを⼤幅に削減 し、既存のコンパイラを相互に接続するのを⽀援することを⽬的としている。MLIR は、さまざまな抽象化レベルで、またアプリケーションドメイン、ハードウェアター ゲット、および実⾏環境全体で、コードジェネレータ、トランスレータ、およびオプ ティマイザの設計と実装を容易にします。本研究の貢献には、 (1) 拡張と進化のため に構築された研究成果物としてのMLIRの議論、および設計、意味論、最適化仕様、 システム、⼯学におけるこの新しい設計点によってもたらされる課題と機会の特定が 含まれる。(2) 将来のプログラミング⾔語、コンパイラ、実⾏環境、コンピュータ アーキテクチャの研究と教育の機会を示すための多様なユースケースを記述するコン パイラの構築コストを低減する⼀般化インフラとしてのMLIRの評価。本論⽂はま た、MLIRの理論的根拠、そのオリジナルの設計原理、構造および意味論を提示す る。
⑤fastai: A Layered API for Deep Learning fastaiはディープラーニングライブラリで、標準的なディープラーニングドメインで 最先端の結果を迅速かつ容易に提供できる⾼度なコンポーネントを実践者に提供し、 新しいアプローチを構築するために組み合わせ可能な低レベルのコンポーネントを研
究者に提供する。使いやすさ、柔軟性、パフォーマンスの⾯で実質的な妥協をするこ となく、両⽅を実現することを⽬指しています。これは、多くのディープラーニング やデータ処理技術の共通基盤パターンを、分離された抽象化の観点から表現する、注 意深く階層化されたアーキテクチャのおかげで可能になった。これらの抽象化は、基 礎となるPython⾔語の動的性とPyTorchライブラリーの柔軟性を活⽤することに よって、簡潔かつ明確に表現することができます。fastaiに含まれるもの:Python⽤ の新しい型ディスパッチシステムと、テンソル⽤のセマンティック型階層;純粋な Pythonで拡張できるGPU最適化コンピュータビジョンライブラリ;現代のオプティマ イザの共通機能を2つの基本部分にリファクタリングし、最適化アルゴリズムを4~5 ⾏のコードで実装できるようにするオプティマイザ;データ、モデル、またはオプ ティマイザの任意の部分にアクセスし、トレーニング中の任意の時点で変更できる新 しい2ウェイコールバックシステム;新しいデータ・ブロックAPI;他にもたくさんあり ます。私たちはこのライブラリを使って完全なディープラーニングコースを作成する ことに成功し、以前のアプローチよりも素早く書くことができ、コードもより明確に なりました。図書館はすでに研究、産業、教育の分野で広く利⽤されている。注:こ の⽂書では、現在http://dev.fast.ai/でプレリリースされているfastai v2について説明 します。
⑥How Good is the Bayes Posterior in Deep Neural Networks
Really? 過去5年間、ベイジアン深層学習コミュニティは、深層ニューラルネットワークでの ベイジアン推論を可能にする、ますます正確かつ効率的な近似推論⼿順を開発してき ました。ただし、このアルゴリズムの進歩と不確実性の定量化とサンプル効率の改善 の⾒込みにもかかわらず、2020年初頭の時点では、産業実践におけるベイジアン ニューラルネットワークの公開された展開はありません。この作業では、⼈気のある ディープニューラルネットワークにおけるベイズの後継者の現在の理解に疑問を投げ かけます。注意深いMCMCサンプリングを通じて、ベイズの事後によって誘導され た事後予測が、SGDから得られたポイント推定を含む単純な⽅法と⽐較して体系的 に悪い予測をもたらすことを示します。さらに、証拠を過⼤評価する「cold posterior」を使⽤することにより、予測パフォーマンスが⼤幅に改善されることを 実証します。このようなcold posteriorは、ベイジアンのパラダイムから⼤きく逸脱 しますが、ベイジアンの深層学習論⽂でヒューリスティックとして⼀般的に使⽤され ます。私たちは、寒い後継者を説明し、実験を通じて仮説を評価できるいくつかの仮 説を提唱しました。私たちの仕事は、ベイジアン深層学習における正確な事後近似の ⽬標に疑問を投げかけます。真のベイズ事後が貧弱な場合、より正確な近似の使⽤は 何ですか?代わりに、cold posteriorのパフォーマンスの向上の起源を理解すること に焦点を合わせるのがタイムリーであると主張します。
⑦Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early
Stopping 教師付き下流タスクへの事前訓練⽂脈語埋込みモデルの微調整は、⾃然⾔語処理にお いて⼀般的になった。しかしながら、このプロセスは、しばしば脆く、同じハイパー パラメータ値であっても、異なるランダムシードは、実質的に異なる結果をもたらし 得る。この現象をより良く理解するために、筆者らはGLUEベンチマークからの4つ のデータセットを⽤いて実験し、ランダムシードのみを変化させながら、各々につい て数百回BERTを微調整した。著者らは、以前に報告された結果と⽐較して、かなり の性能増加を発⾒し、最良に発⾒されたモデルの性能が、微調整試⾏の数の関数とし てどのように変化するかを定量化した。さらに、ランダムシードの選択により影響さ れる2つの因⼦、重み初期化と訓練データ順序を検討した。両⽅とも、標本外性能の 分散に⽐較的寄与し、いくつかの重み初期化が調査した全てのタスクで良好に動作す ることを⾒出した。⼩規模データセットでは、多くの微調整試⾏が訓練の途中で分岐 することを観察し、あまり有望でない訓練を早期に中⽌するための実践者のためのベ ストプラクティスを提供する。微調整中のトレーニング動態のさらなる分析を促進す るため、2,100試験のトレーニングおよび検証スコアを含むすべての実験データを公 開しています。
⑧Towards a Human-like Open-Domain Chatbot 筆者らは、パブリックドメインのソーシャルメディア会話からマイニングされフィル タリングされたデータ上でエンドツーエンドに訓練されたマルチターンのオープンド メインチャットボット、Meenaを提示した。この2.6 Bパラメータニューラルネット ワークは、次のトークンのパープレキシティを最⼩化するように単純に訓練される。
また、⼈間のようなマルチターン会話の鍵となる要素を捕捉する、Sensibleness and Specificity Average(SSA)と呼ばれる⼈間評価尺度を提案する。著者らの実験 は、パープレキシティとSSAの間の強い相関を示した。エンドツーエンド訓練した最 良のパープレキシティは、SSAで⾼いスコアを示した(マルチターン評価で72%)とい う事実は、パープレキシティをより良く最適化できれば、86%の⼈間レベルのSSAが 潜在的に到達可能であることを示唆する。加えて、Meenaの完全版(フィルタリング 機構とチューニングされたデコード)は79%のSSAをスコア化し、著者らが評価した 既存チャットボットよりも絶対SSAが23%⾼かった。
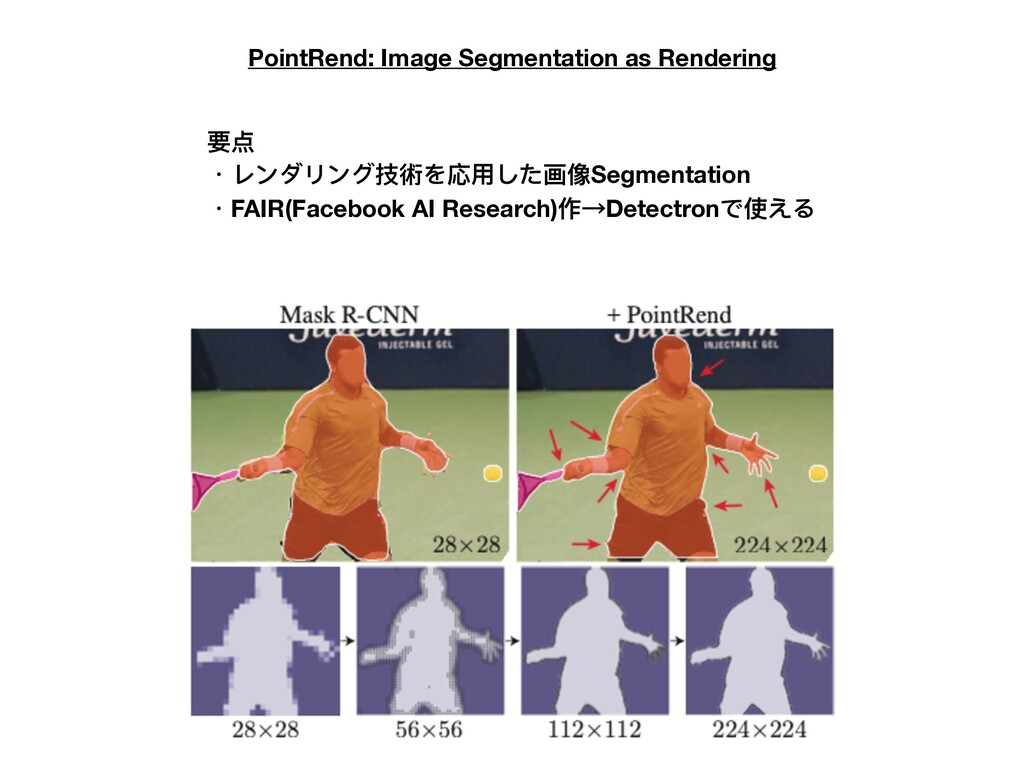
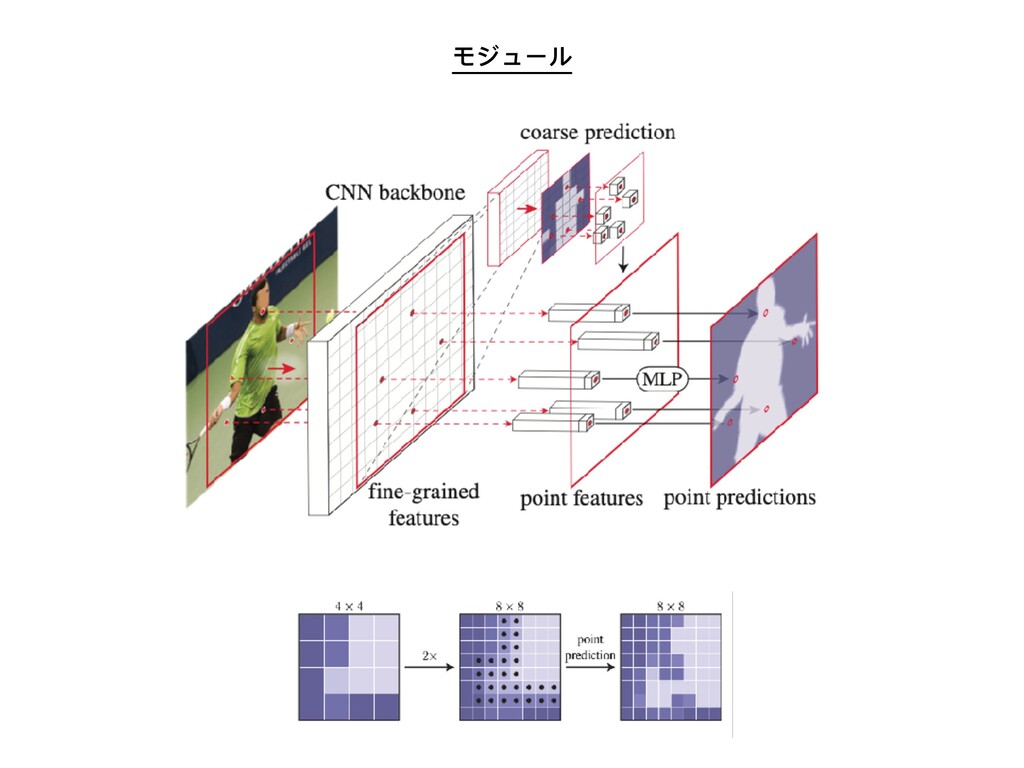
⑨PointRend: Image Segmentation as Rendering オブジェクトとシーンの効率的な⾼品質画像セグメンテーションのための新しい⽅法 を示す。画素ラベリングタスクで直⾯するオーバーサンプリングとアンダーサンプリ ングの課題を伴う効率的なレンダリングのための古典的コンピュータグラフィックス 法を類推することにより、レンダリング問題としての画像セグメンテーションのユ ニークな視点を開発した。この観点から、反復分割アルゴリズムに基づいて適応的に
選択した位置で点ベースのセグメンテーション予測を実⾏するモジュールである PointRend(ポイントベースのレンダリング)ニューラルネットワークモジュールを示 す。PointRendは、既存の最先端のモデルの上に構築することで、インスタンスとセ マンティックの両⽅のセグメンテーション・タスクに柔軟に適⽤することができま す。⼀般概念の多くの具体的な実装が可能であるが、単純な設計が既に優れた結果を 達成していることを示した。定性的には、PointRendは、以前のメソッドによって過 度にスムージングされた領域に鮮明なオブジェクト境界を出⼒します。数量的には、 PointRendは、COCOおよび都市景観において、インスタンスおよびセマンティック セグメンテーションの両⽅において、⼤幅な改善をもたらします。PointRendの効率 性により、既存の⽅法に⽐べてメモリや計算の⾯で実⽤的でない出⼒解像度を実現で きます。コードはhttps://github.com/facebookresearch/detectron2/tree/master/ projects/PointRendから⼊⼿できます。
⑩Wavesplit: End-to-End Speech Separation by Speaker Clustering エンドツーエンド⾳声分離システムWavesplitを紹介する。混合⾳声の単⼀記録か ら、モデルは各話者の表現を推論し、クラスタ化し、推論した表現に条件付けた各 ソース信号を推定する。モデルは⽣波形で訓練され、2つのタスクを同時に実⾏す
る。このモデルはクラスタリングを通して話者表現の集合を推論し、これは⾳声分離 の基本的な順列問題に対処する。さらに、シーケンス全体の話者表現は、以前のアプ ローチと⽐較して、⻑く、挑戦的なシーケンスのよりロバストな分離を提供する。著 者らは、Wavesplitが、雑⾳の多い(バッ!)および反響する(うわっ!)条件と同様に、2ま たは3スピーカのクリーンな混合物(WSJ0-2mix、WSJ0-3mix)において、以前の最新 技術を凌駕することを示した。さらなる貢献として、分離のためのオンラインデータ 増強を導⼊することにより、モデルをさらに改善した。
1. Arxiv top recent articles last month 2. Arxiv top
hype articles last month 3. My favorite Time line
PointRend: Image Segmentation as Rendering 要点 ・レンダリング技術を応⽤した画像Segmentation ・FAIR(Facebook AI Research)作→Detectronで使える
モジュール
Segmentationサンプル
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}