at Large Scale) 2. InstructPix2Pix。画像編集の指示に従うことを学ぶ (原文: InstructPix2Pix: Learning to Follow Image Editing Instructions) 3. トランス推論の効率的なスケーリング (原文: Efficiently Scaling Transformer Inference) 4. BLOOM:176Bパラメータオープンアクセス多言語言語モデル (原文: BLOOM: A 176B-Parameter Open-Access Multilingual Language Model) 5.敵対的な政策がプロフェッショナルレベルの囲碁AIを打ち負かす (原文: Adversarial Policies Beat Professional-Level Go AIs) 6.インコンテキストラーニングによるアルゴリズム推論の教育 (原文: Teaching Algorithmic Reasoning via In-context Learning) 7.大規模言語モデルは人間レベルのプロンプトエンジニアである (原文: Large Language Models Are Human-Level Prompt Engineers) 8. ERNIE-ViLG 2.0:テキストから画像への拡散モデルの改良と知識拡張型Mixture-of-Denoising-Expertsの利用 (原文: ERNIE-ViLG 2.0: Improving Text-to-Image Diffusion Model with Knowledge-Enhanced Mixture-of-Denoising-Experts) 9.一つの会場、二つの会議。中国とアメリカの引用ネットワークの分離 (原文: One Venue, Two Conferences: The Separation of Chinese and American Citation Networks) 10.対照的な復号化。最適化としての自由形式テキスト生成 (原文: Contrastive Decoding: Open-ended Text Generation as Optimization) PaperWithCodeの10本を紹介 【pickup】 https://ml-ocu.s3-ap-northeast-1.amazonaws.com/arxiv-translation/sanity/2022-11-25-top-social.txt
Large Scale) https://arxiv.org/abs/2211.03759v1 機械学習モデルによって、ユーザーが書いたテキスト説明を自然な画像に変換できるようになった。これらのモデル はオンラインで誰でも利用でき、1日に数百万枚の画像を生成するために利用されている。我々はこれらのモデルを 調査し、危険で複雑な固定観念を増幅することを発見した。さらに、増幅されたステレオタイプは予測が難しく、 ユーザやモデルの所有者によって容易に緩和されないことがわかった。これらの画像生成モデルが、どの程度、ステ レオタイプを永続させ、増幅させるのか、また、その大量展開は、深刻な懸念材料である 目的:画像生成モデルが利用される際における固定概念への影響を調査する 成果:画像生成モデルが利用される際に固定概念を増幅され、またその固定概念の予測が困難であることを確認した 方法:生成された画像に固定概念が増幅されることを確認した 固有名: - 著者所属:Stanford University, Columbia University, Bocconi University, University of Washington
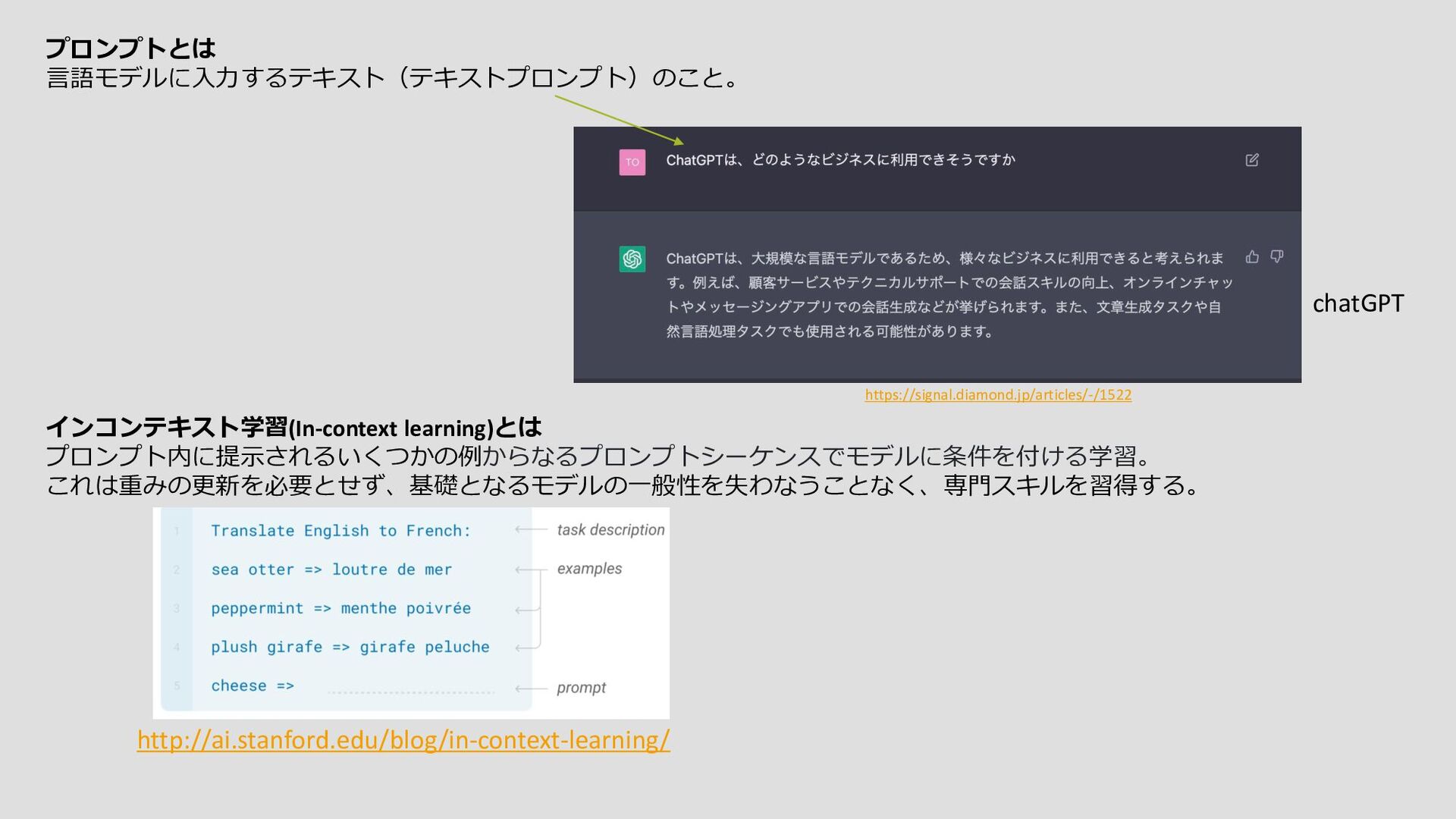
beautiful painting of a mountain next to a waterfall.”と入力したときより以下のようにveryを多く付けたほうが綺麗。 “A very very very very very very very very very very very very beautiful painting of a mountain next to a waterfall. https://www.arinteli.com/what-is-prompt-engineering-and-why-is-it-important/ このようにユーザ(人)は特定のモデルとプロンプト(入力テキスト)の相性をほとんど知らないため、望ましい結果 を得るためには様々なプロンプトでの試行錯誤が必要となる(これをプロンプトエンジニアリングという。LLMが高い品質を返すように質問の仕方を工夫すること)。 →本研究では、LLMを用いて効果的な命令を自動で生成し、選択する新しいアルゴリズムを提案する。
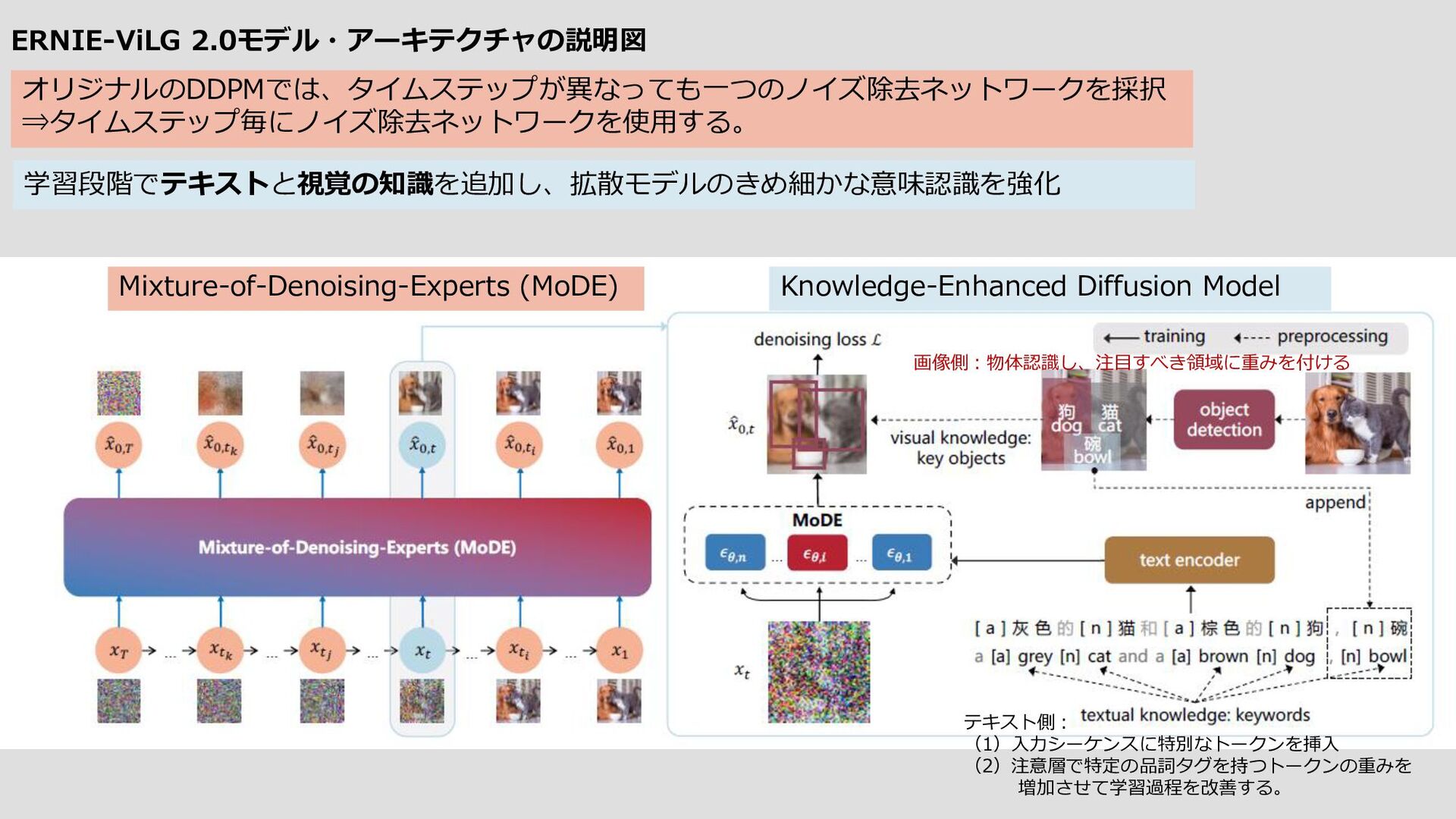
(提案手法) DALL-E 2 Stable Diffusion A wine glass on top of a dog 犬の上に ワイングラスが乗っている 緑のコップと 青い携帯電話 ERNIE-ViLG 2.0 と DALL-E 2/Stable Diffusion の ViLG-300 における定性的な比較例 ViLG-300は、DrawBench (Saharia et al, 2022) (英語)とERNIE-ViLG (Zhang et al, 2021b) (中国語)で使用したプロンプトセットからなる 16カテゴリー300のプロンプトを含んでいる。これらのプロンプトを手翻訳・校正して、最終的に中英並列セットを実現しました
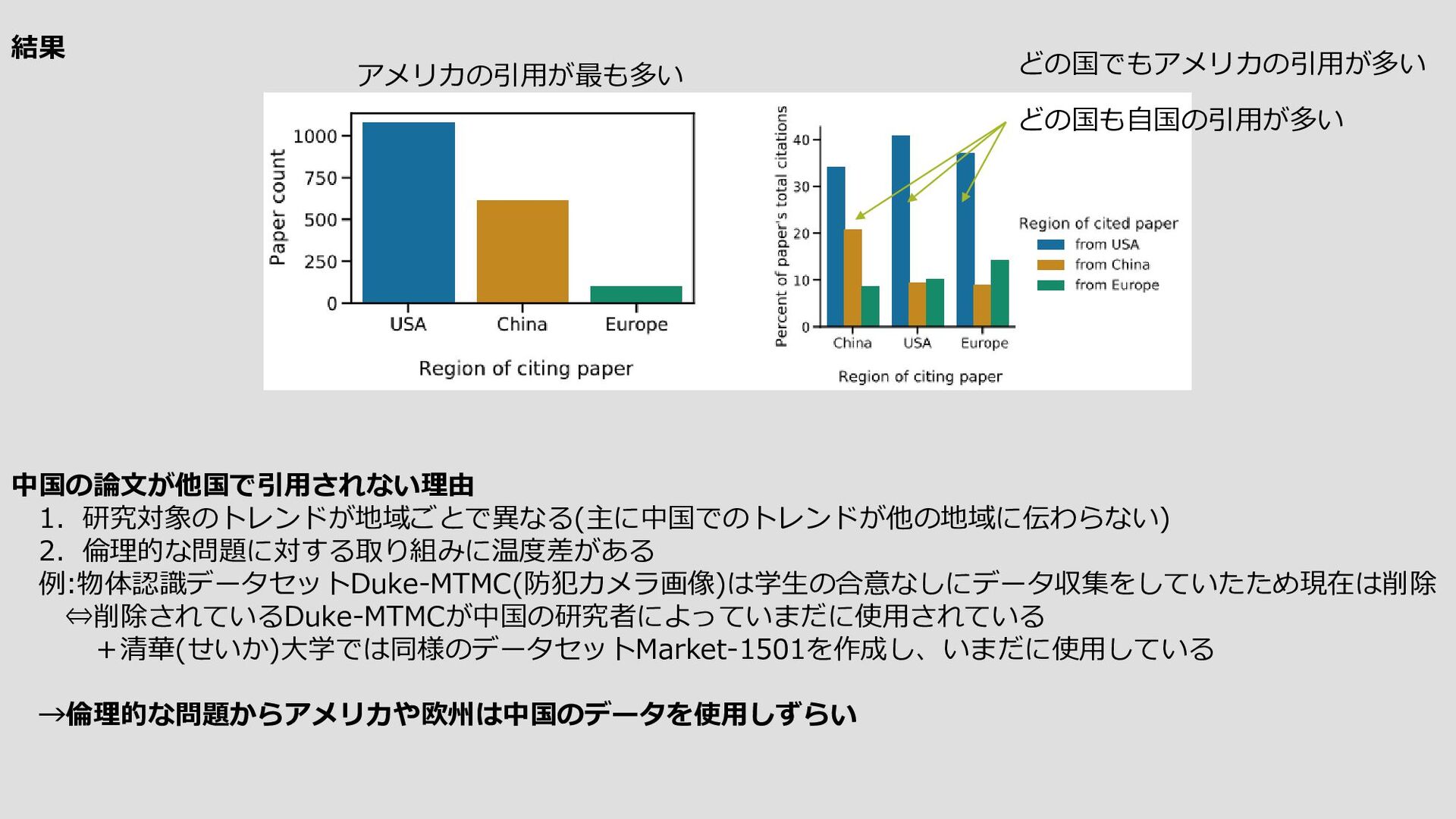
and American Citation Networks) https://arxiv.org/abs/2211.12424v1 NeurIPSでは、アメリカと中国の研究機関が互いの地域の論文を引用する割合は、内輪で引用する割合よりも大幅に 少ない。私たちは、この格差を定量化するために引用グラフを作成し、ヨーロッパの連結性と比較し、その原因と結 果について議論しています。 目的:米中の研究機関のそれぞれの論文引用数とその出典元の格差の原因と結果を議論する。 成果:米欧中それぞれの論文出典元の格差の原因について議論した 方法:米欧中での論文引用数とその出典元の格差のグラフを作成する 固有名:ー 著者所属:University of Edinburgh, Allen Institute of A.I., Brown University, New York University
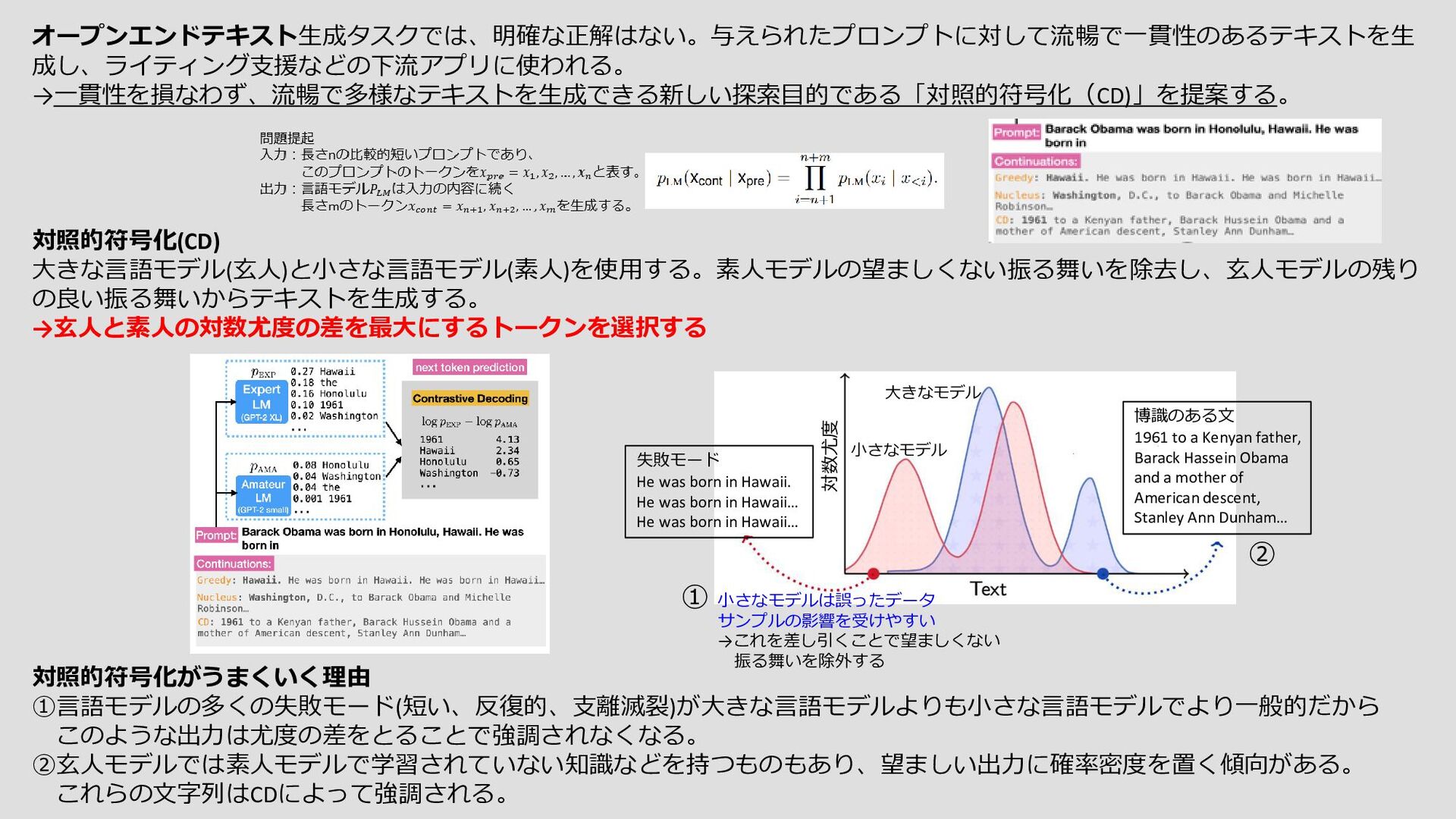
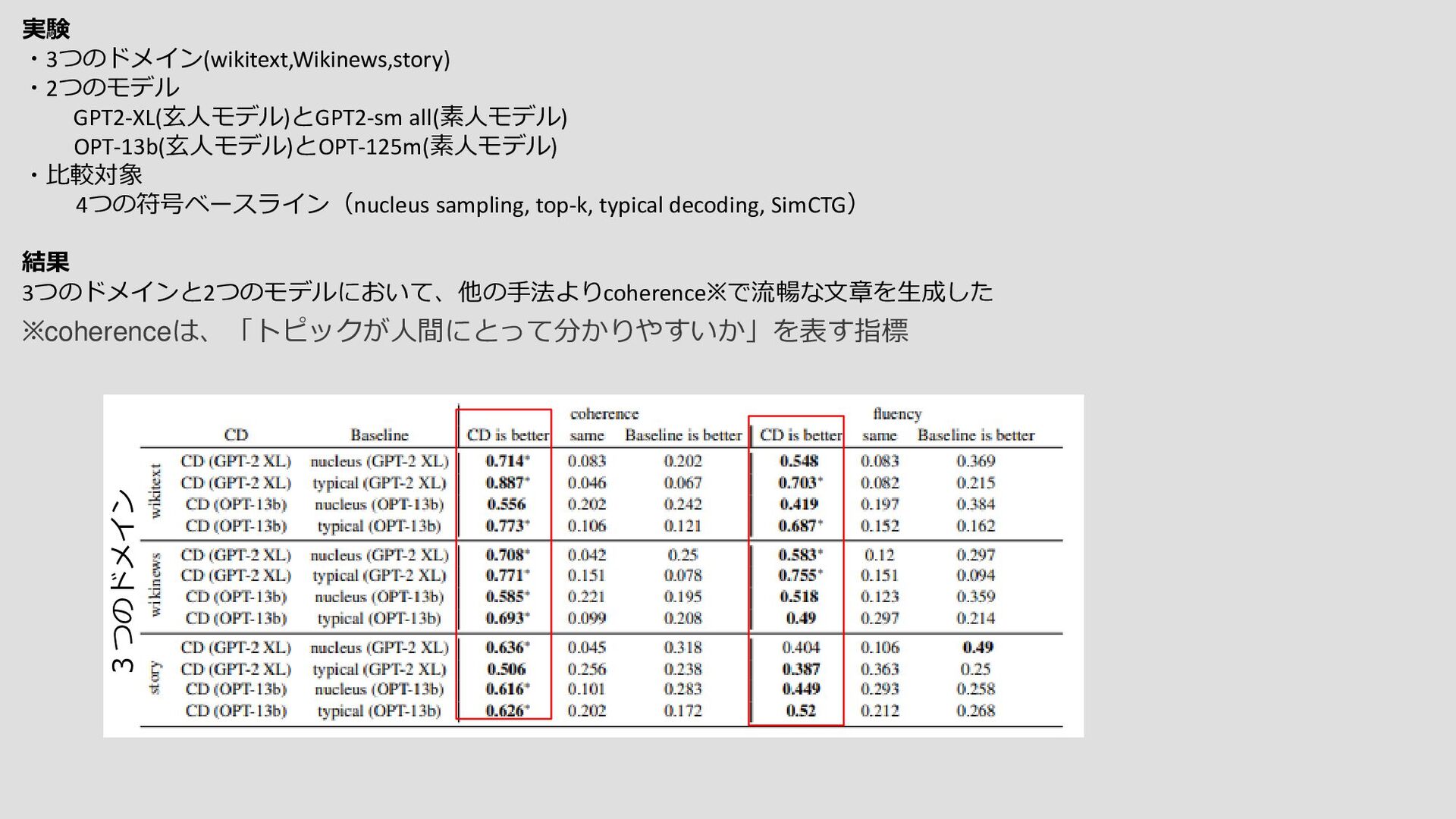
②玄人モデルでは素人モデルで学習されていない知識などを持つものもあり、望ましい出力に確率密度を置く傾向がある。 これらの文字列はCDによって強調される。 対数尤度 小さなモデル 大きなモデル 失敗モード He was born in Hawaii. He was born in Hawaii… He was born in Hawaii… 博識のある文 1961 to a Kenyan father, Barack Hassein Obama and a mother of American descent, Stanley Ann Dunham… 小さなモデルは誤ったデータ サンプルの影響を受けやすい →これを差し引くことで望ましくない 振る舞いを除外する ① ②
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
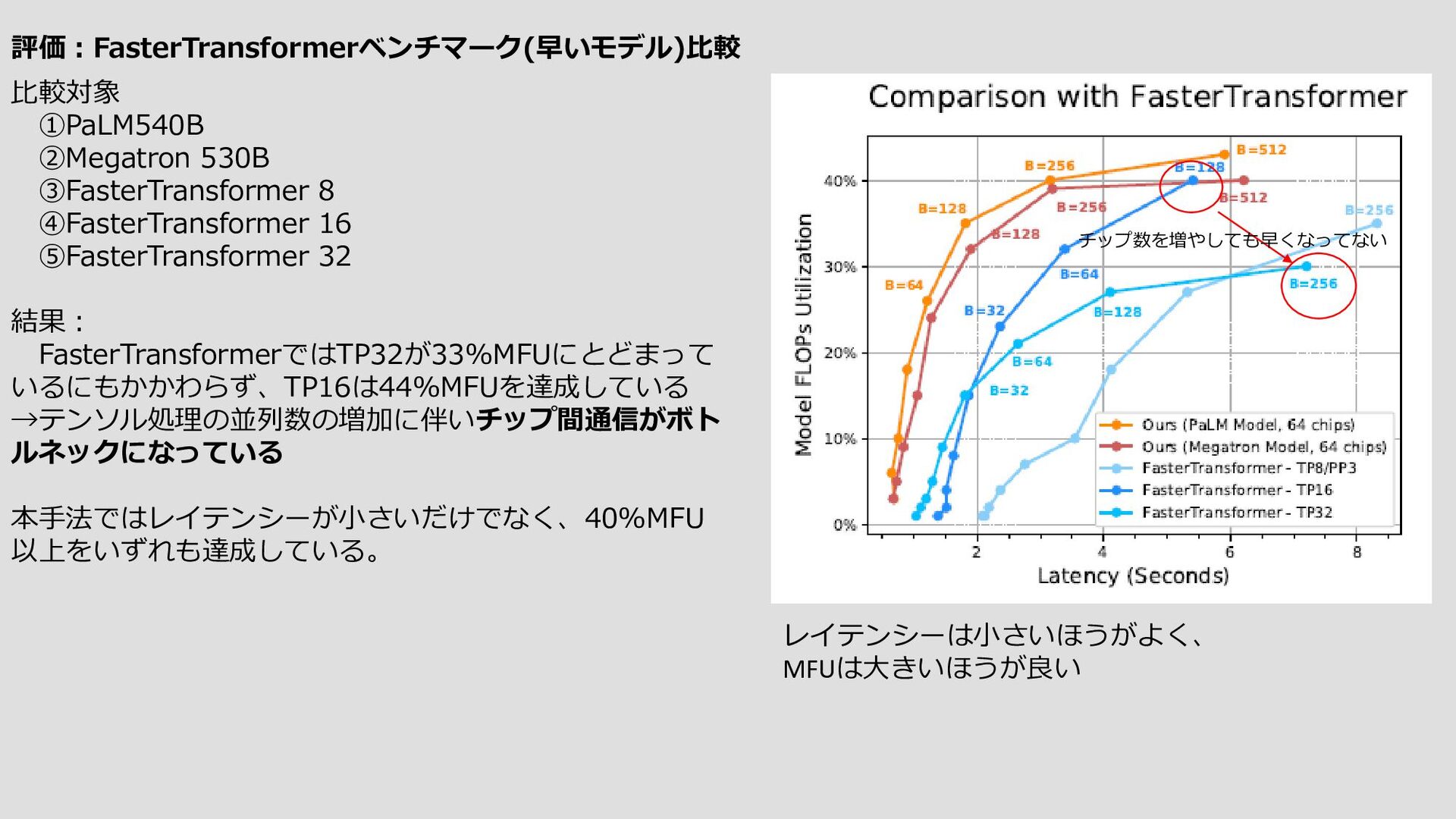{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
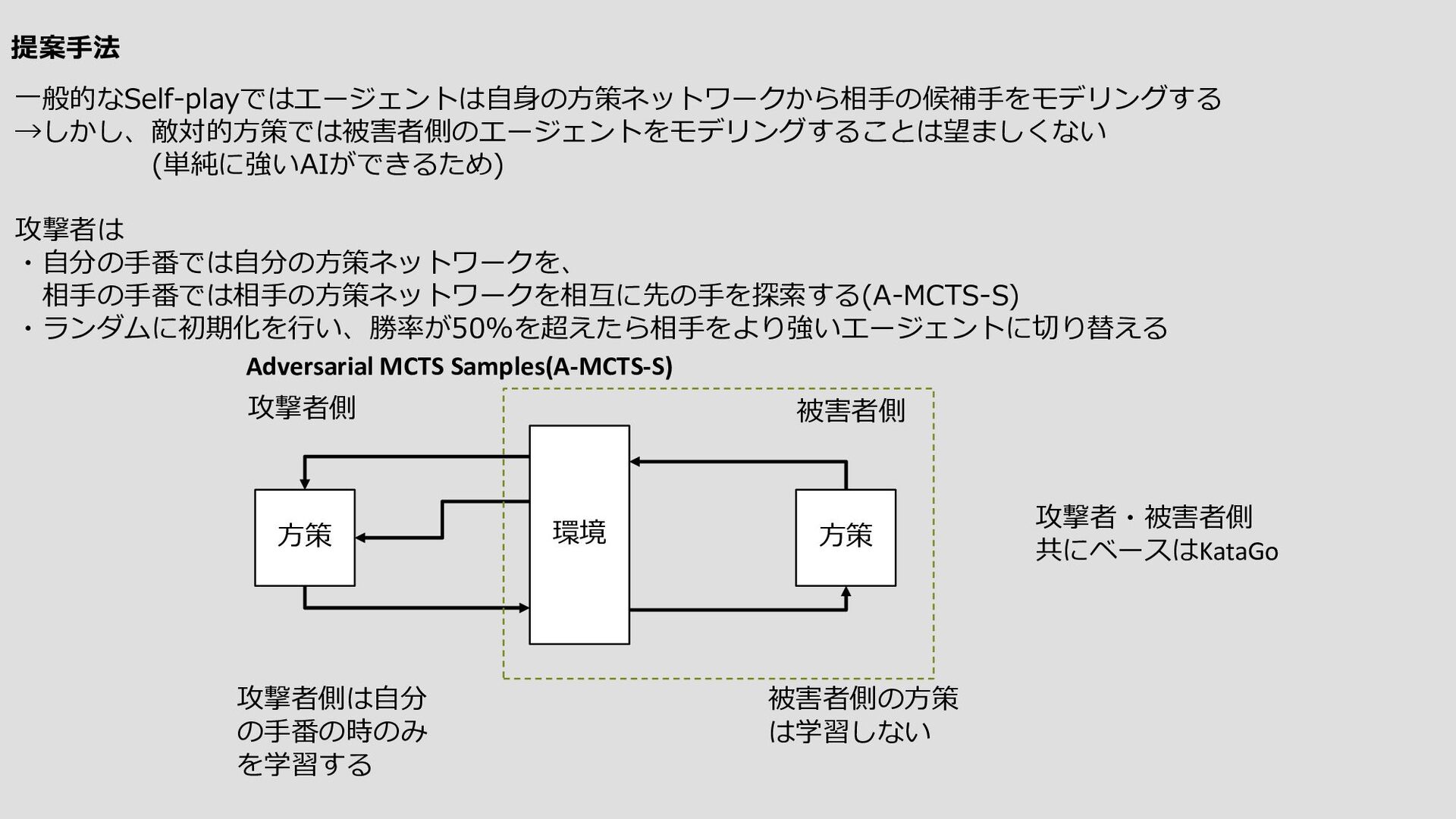{kind=link}
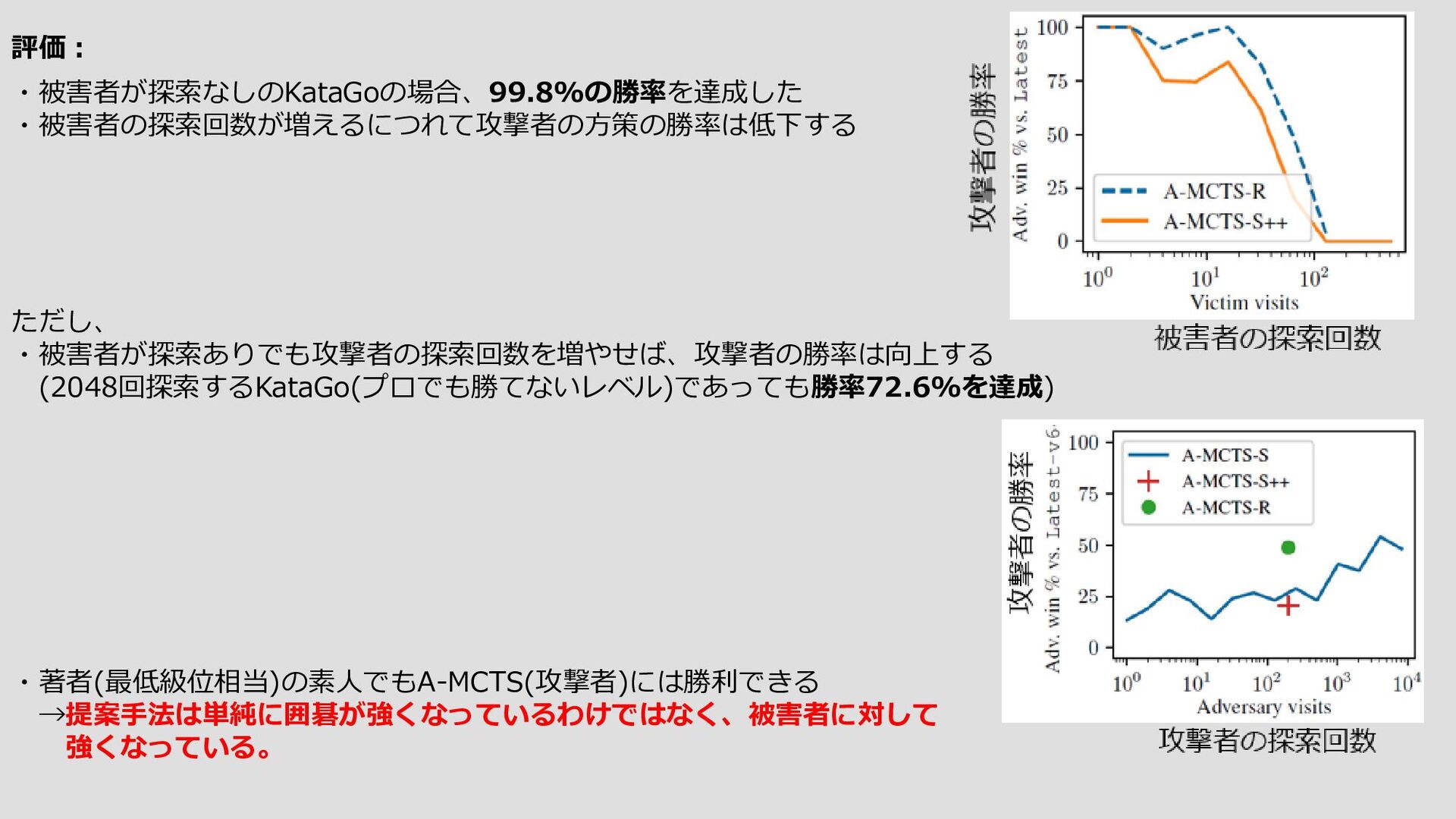{kind=link}
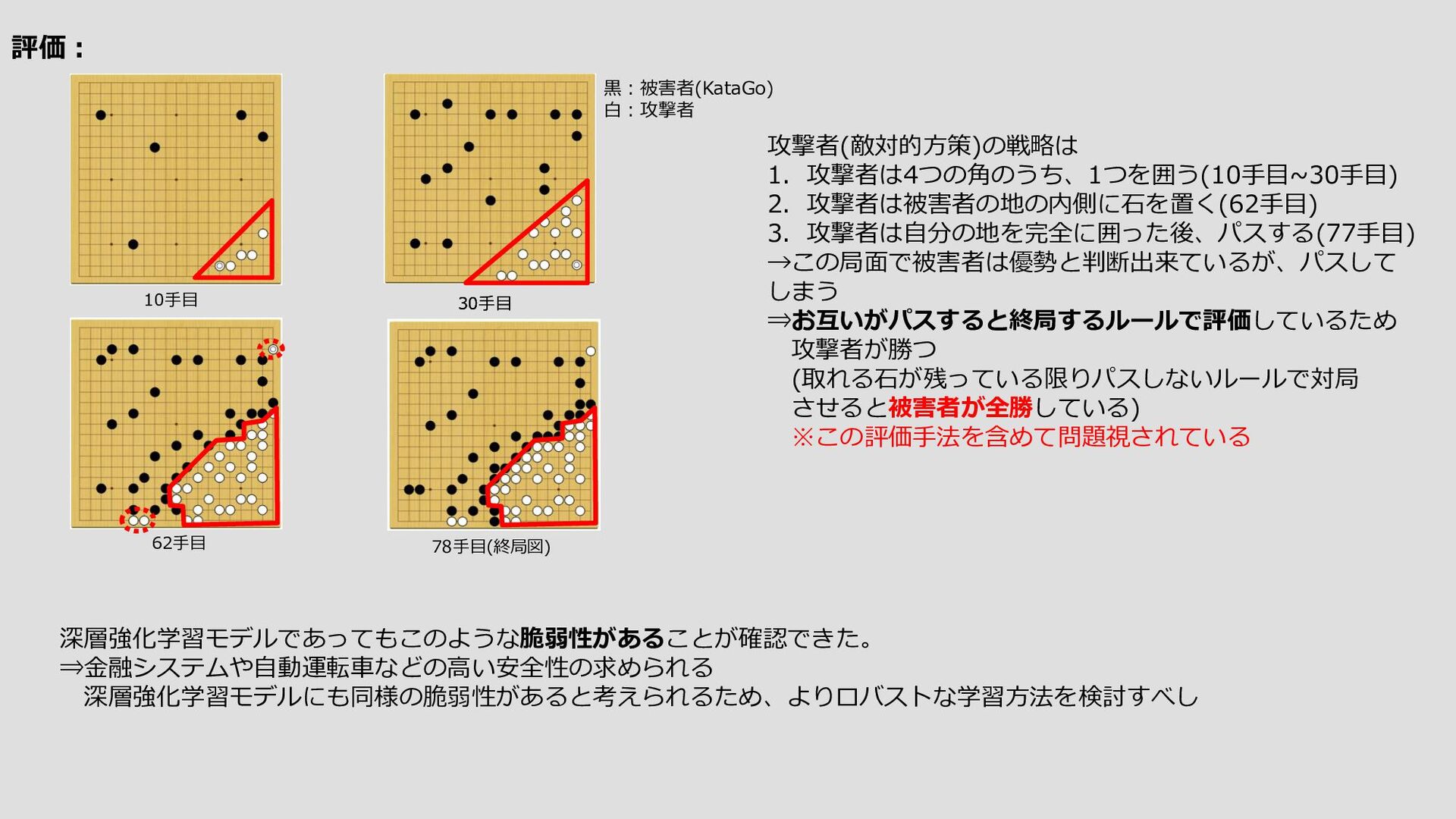{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![問題定義 訓練データセット𝐷𝑡𝑟𝑎𝑖𝑛 = (𝑄(入力), 𝐴(出力) 𝑛 とプロンプトモデル(M)を使用する。 Mにプロンプト𝜌と𝑄(入力),を連結した[𝜌, 𝑄]を入力し、 𝐴(出力)を出力させたい。](https://files.speakerdeck.com/presentations/fef772435e0b47b0a01d4b53932af472/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}