2. 計算最適化された大規模言語モデルの学習 Training Compute-Optimal Large Language Models 3. ソクラテスモデル。ゼロショット多言語推論を言語で構成する Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language 4. STaR: 推論によるブートストラップ推論 STaR: Bootstrapping Reasoning With Reasoning 5. Make-A-Scene: 人間のプライヤーを用いた情景ベースのテキストから画像への生成 Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors 6. 映像拡散モデル Video Diffusion Models 7. 努力する価値はあるのか?サッカーにおける身体的指標の理解と文脈化 Is it worth the effort? Understanding and contextualizing physical metrics in soccer 8. ビッグモデルへの道しるべ A Roadmap for Big Model 9. 正則化とデータ補強の効果はクラスに依存する The Effects of Regularization and Data Augmentation are Class Dependent 10.物体検出のためのプレインビジョントランスフォーマーバックボーンの探索 Exploring Plain Vision Transformer Backbones for Object Detection https://megalodon.jp/2022-0423-1158-49/https://paperswithcode.com:443/top-social?num_days=30
of literary prose developed in Greece at the turn of the fourth century BC. The earliest ones are preserved in the works of Plato and Xenophon and all involve Socrates as the protagonist. These dialogues and subsequent ones in the genre present a discussion of moral and philosophical problems between two or more individuals illustrating the application of the Socratic method. The dialogues may be either dramatic or narrative. While Socrates is often the main participant, his presence in the dialogue is not essential to the genre. ソクラテス対話(古代ギリシャ語:Σωκρατικὸς λόγος) は、紀元前4世紀頃にギリシャで発展した文学散文 のジャンルである。最古のものはプラトンやクセノ フォンの著作に残されており、いずれもソクラテスを 主人公としたものである。これらの対話篇とそれに続 く対話篇は、ソクラテスの方法を応用した2人以上の 個人による道徳的・哲学的な問題の議論を提示する ものである。対話は劇形式と物語形式がある。ソクラ テスはしばしば主要な参加者であるが、対話におけ る彼の存在は、このジャンルにとって不可欠なもので はない。 https://en.wikipedia.org/wiki/Socratic_dialogue deeplによる翻訳
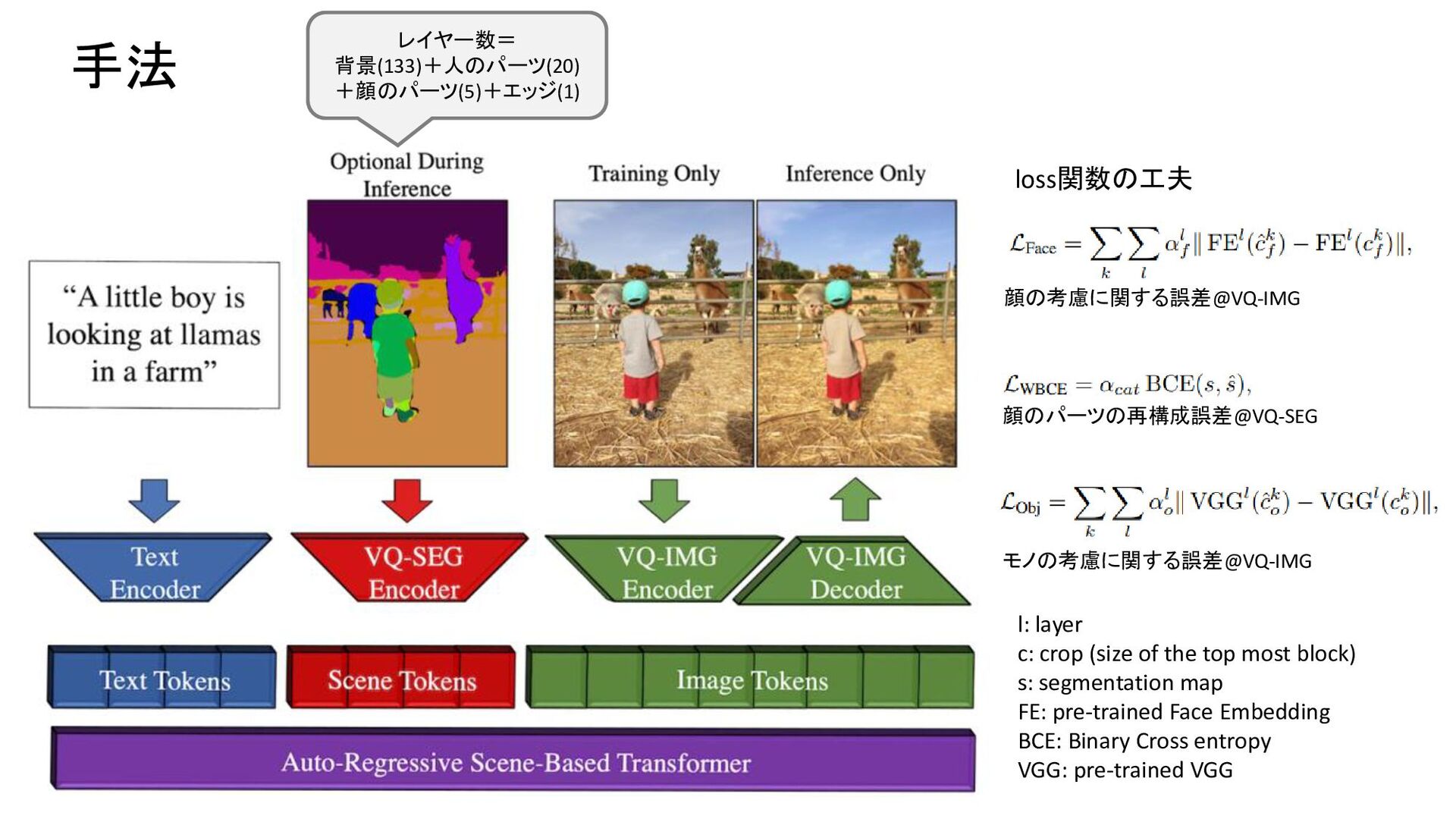
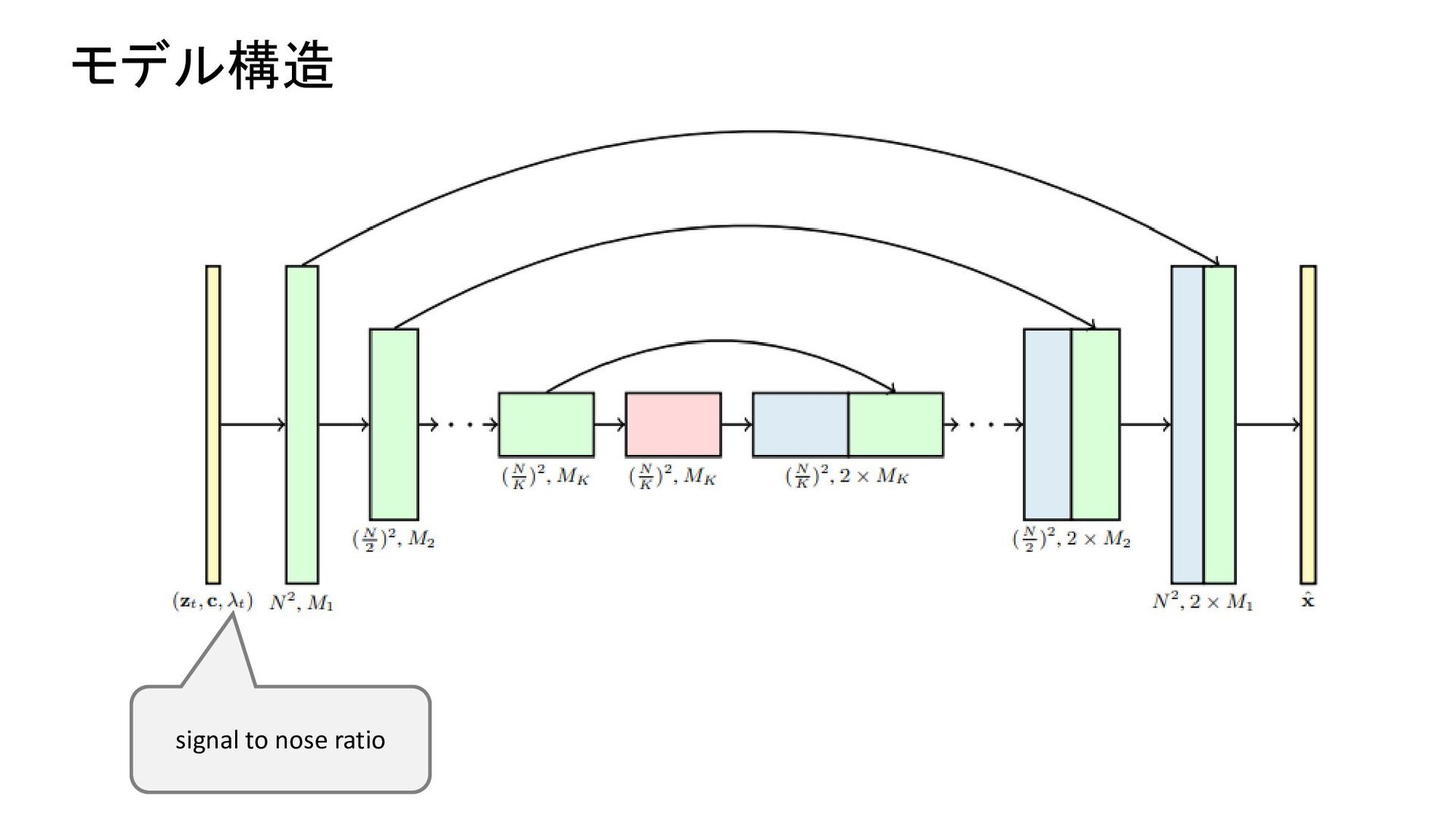
of the top most block) s: segmentation map FE: pre-trained Face Embedding BCE: Binary Cross entropy VGG: pre-trained VGG レイヤー数= 背景(133)+人のパーツ(20) +顔のパーツ(5)+エッジ(1)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
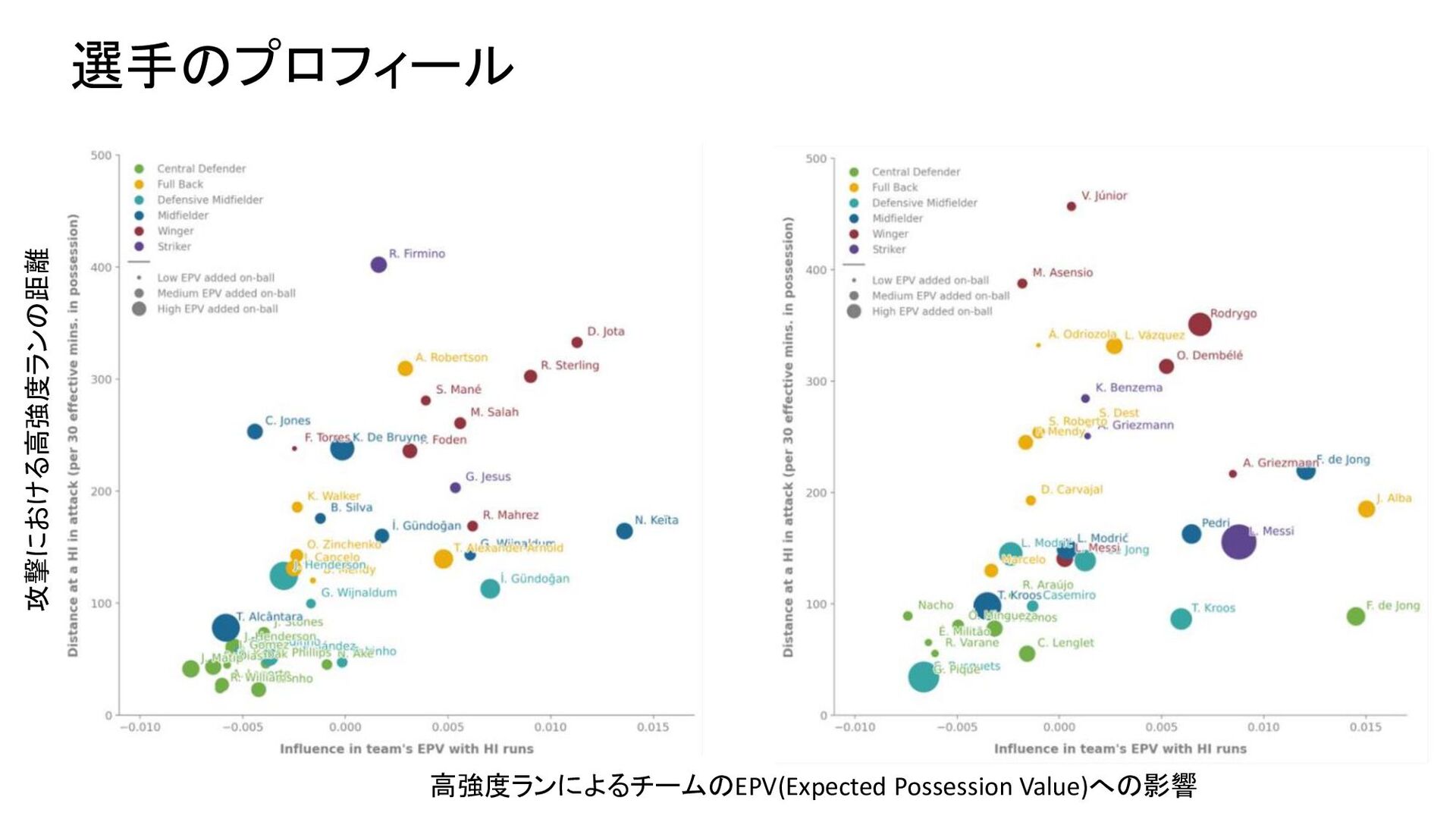
{kind=link}
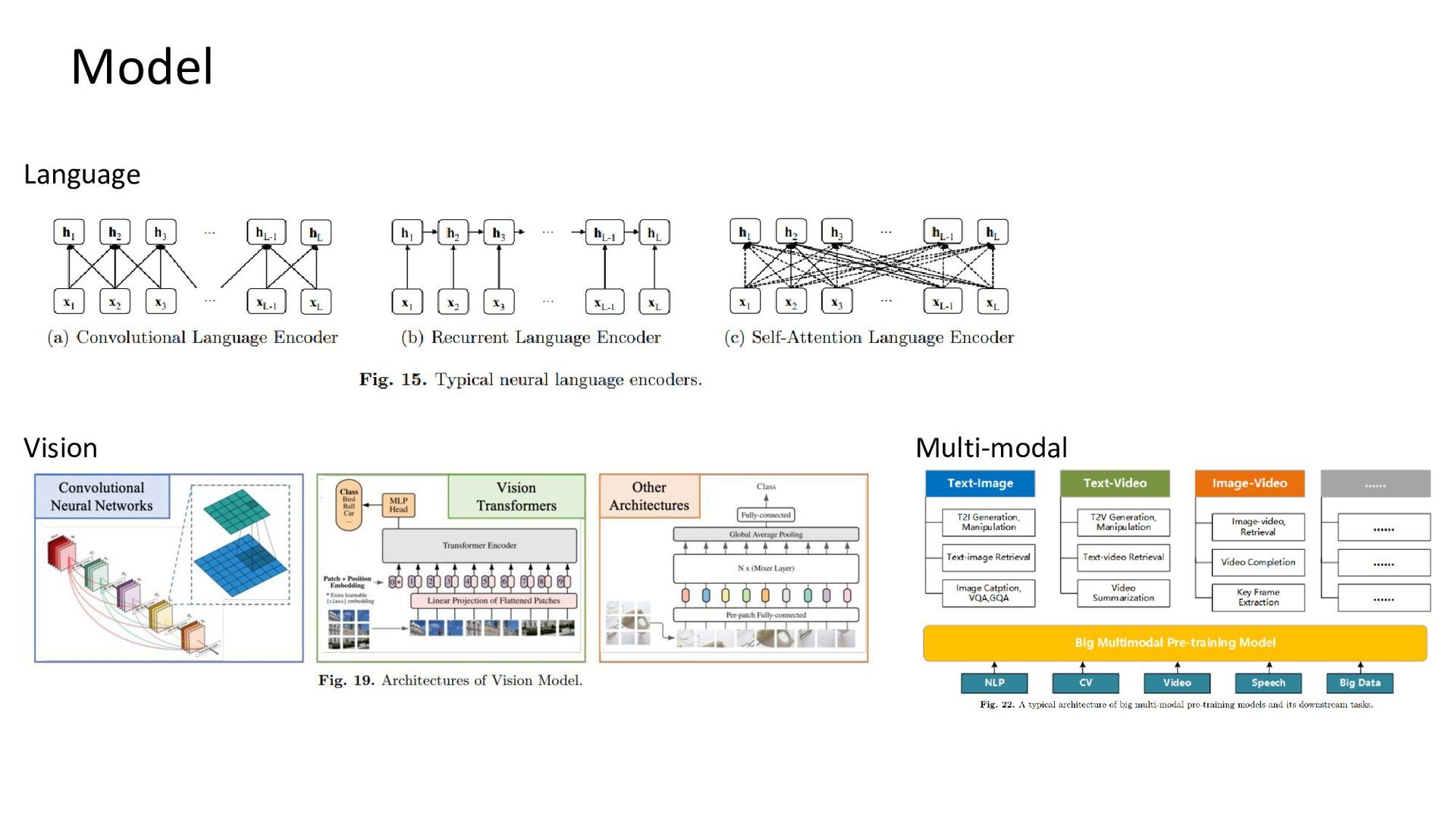
{kind=link}
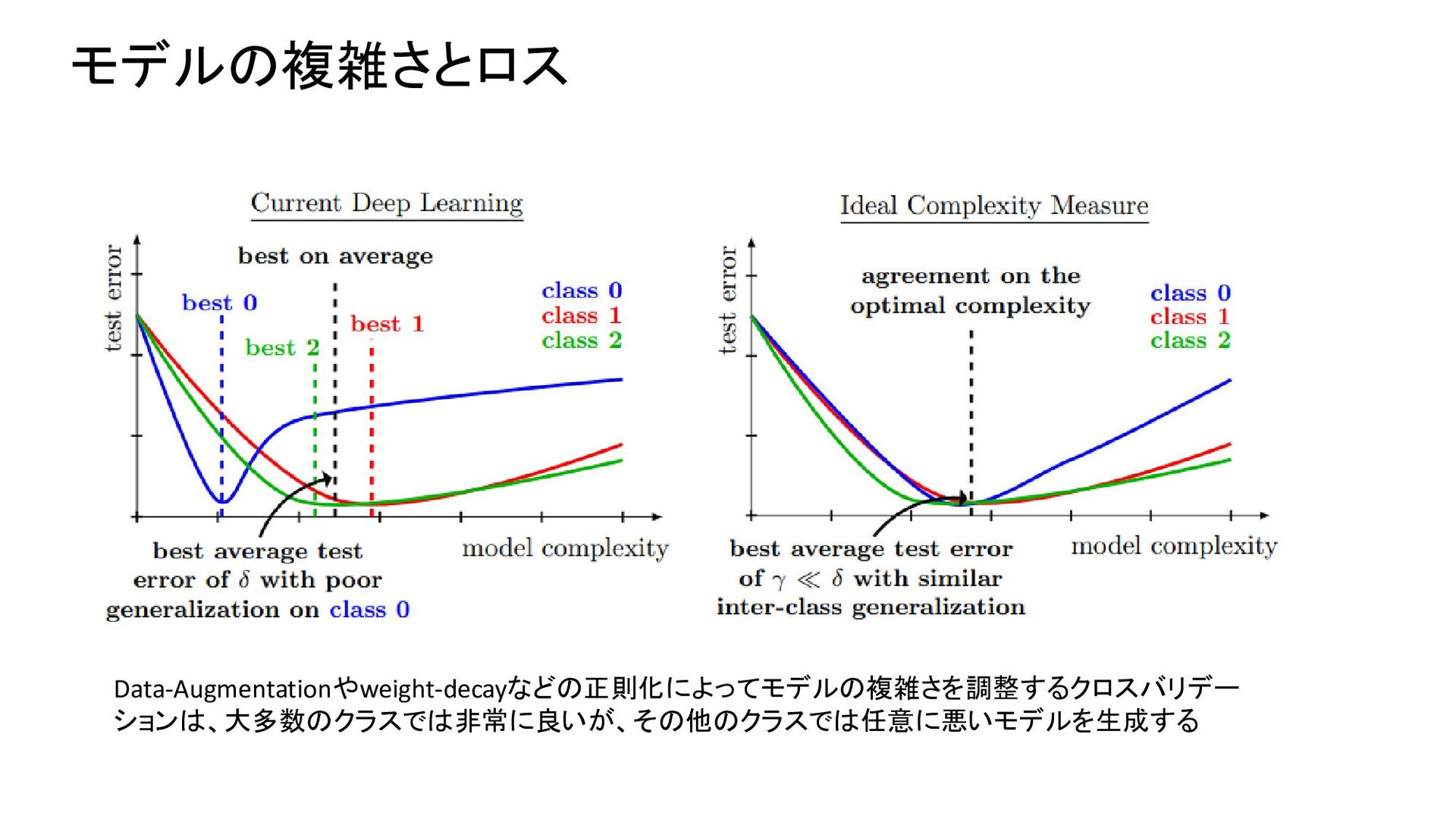
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
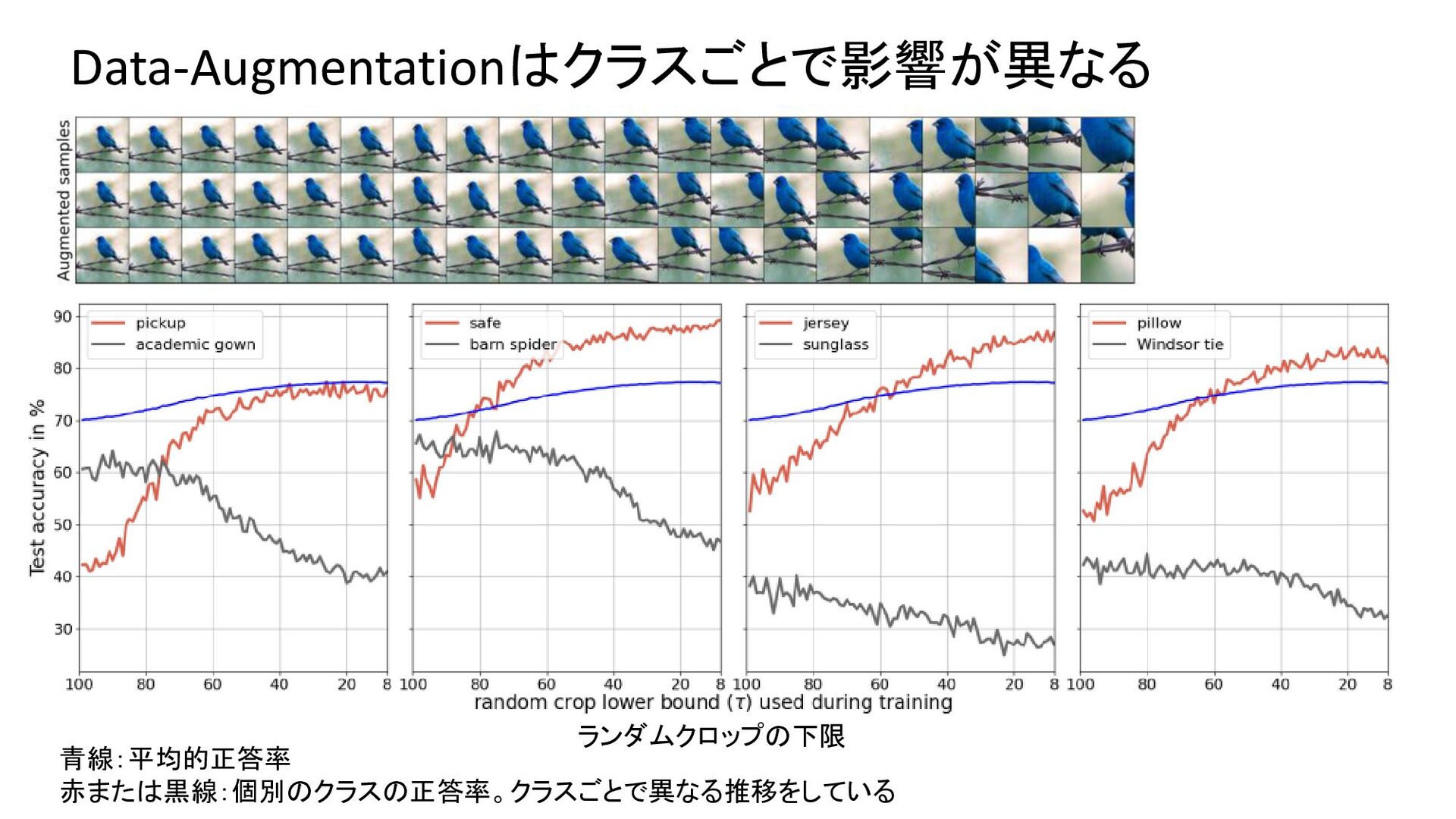{kind=link}
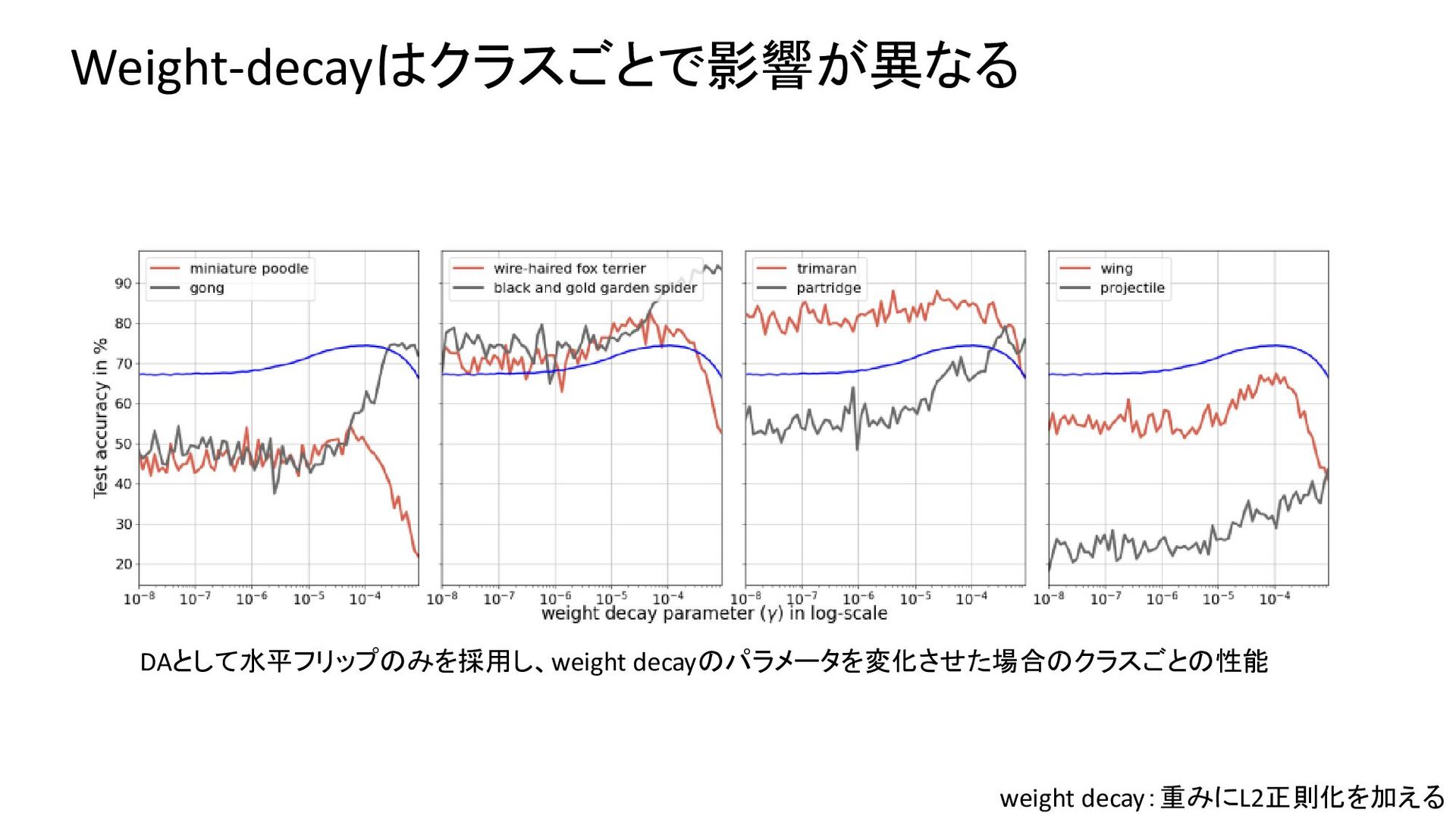{kind=link}
{kind=link}
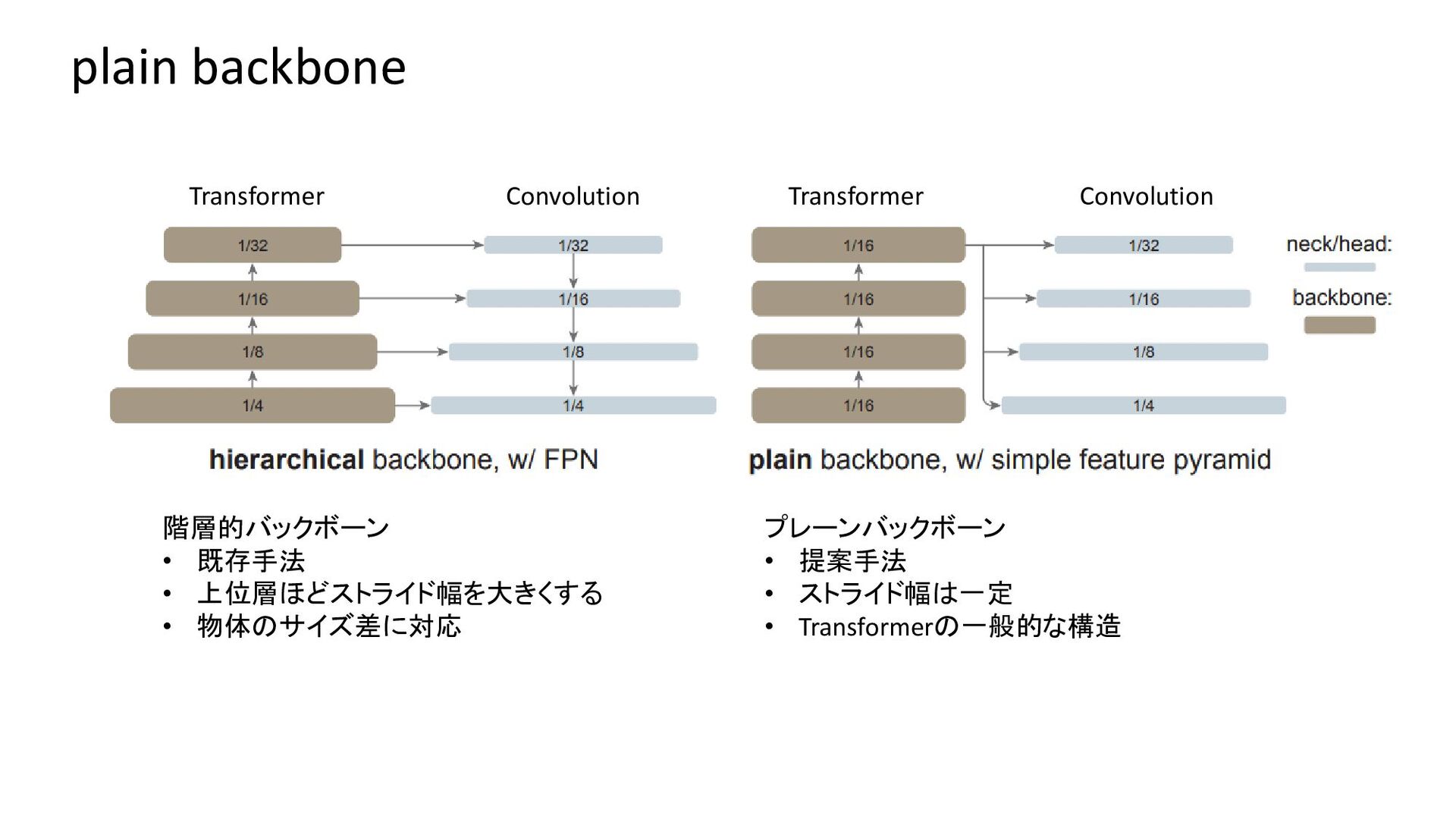{kind=link}
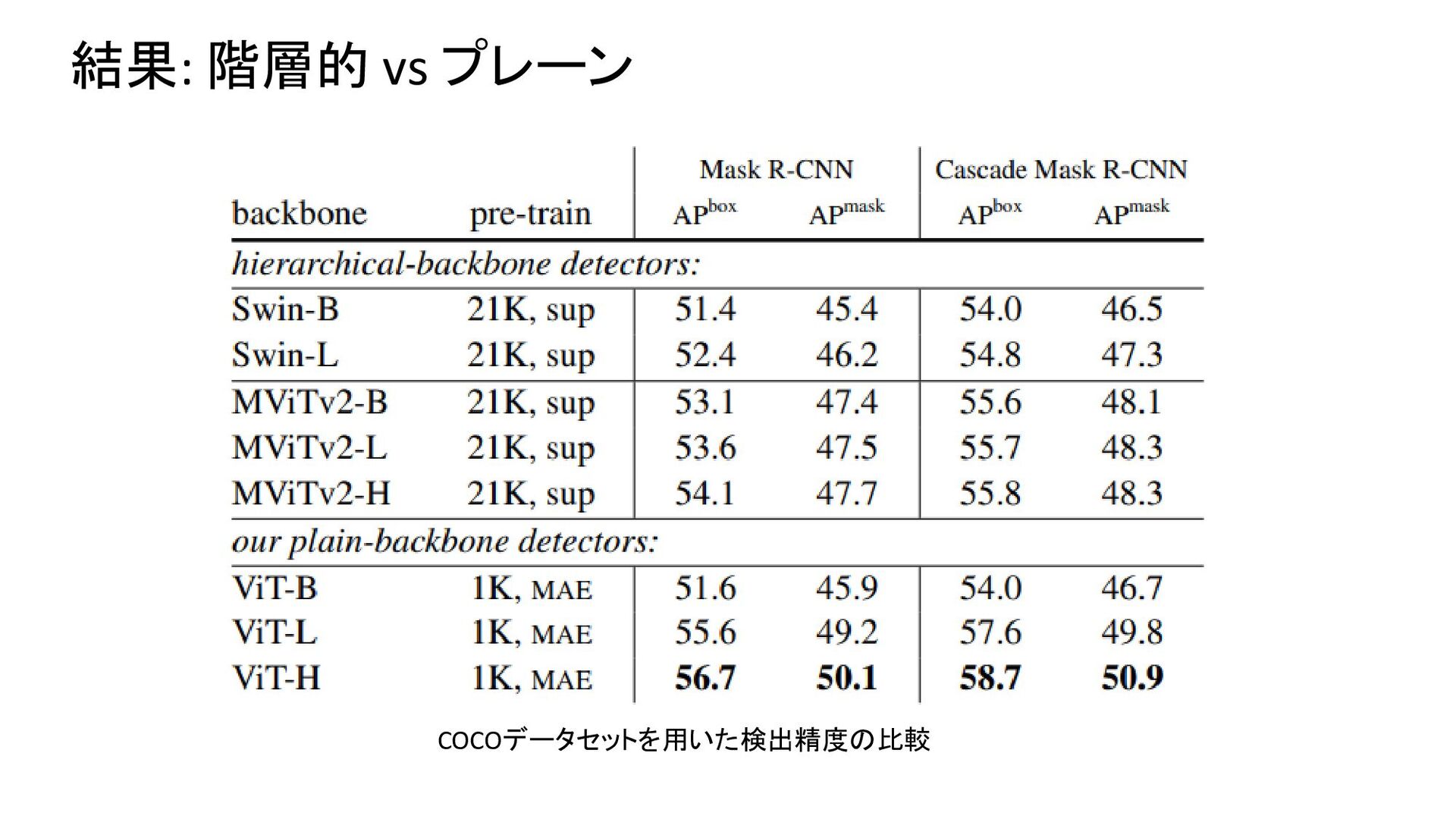{kind=link}
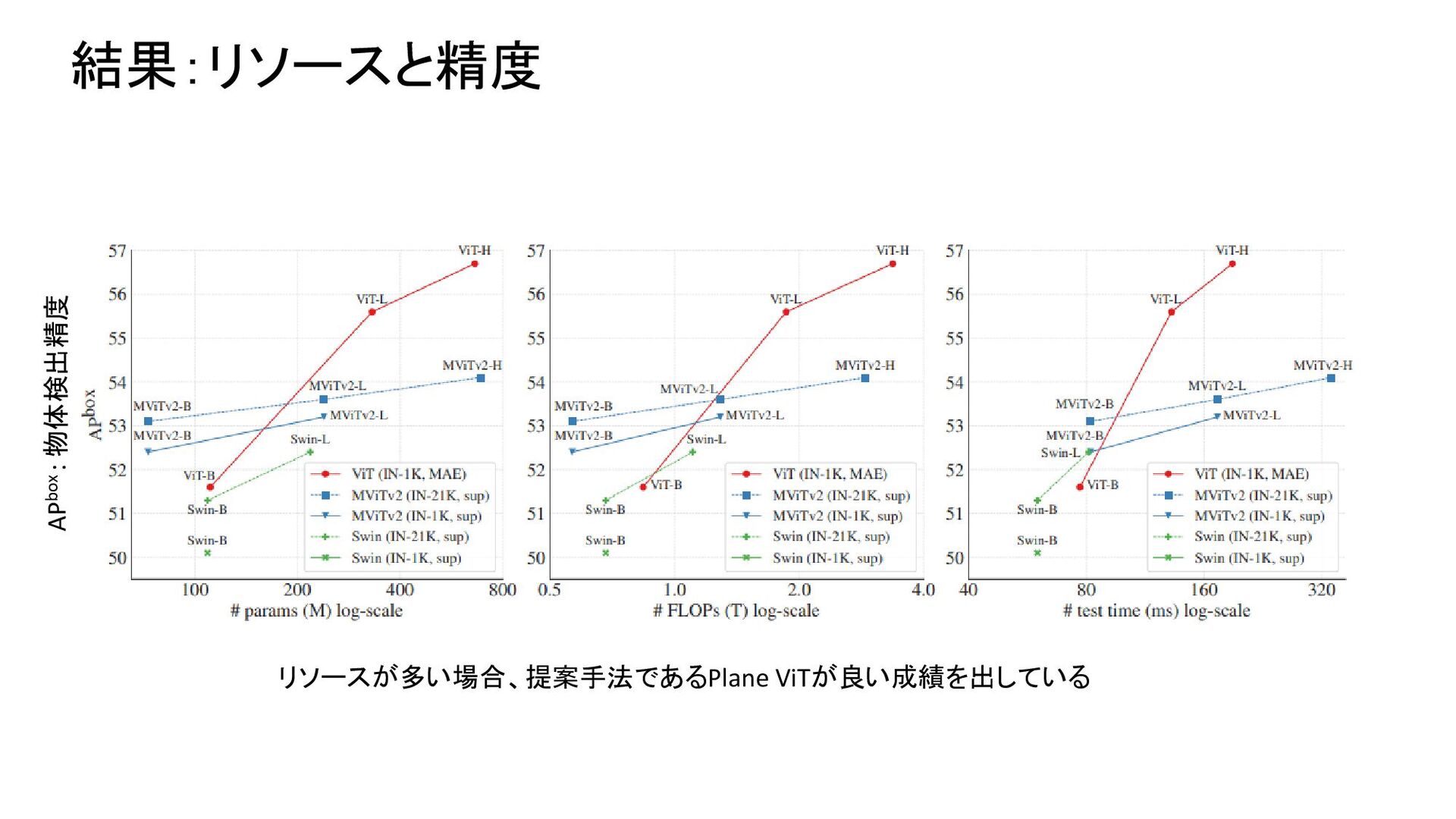{kind=link}
{kind=link}