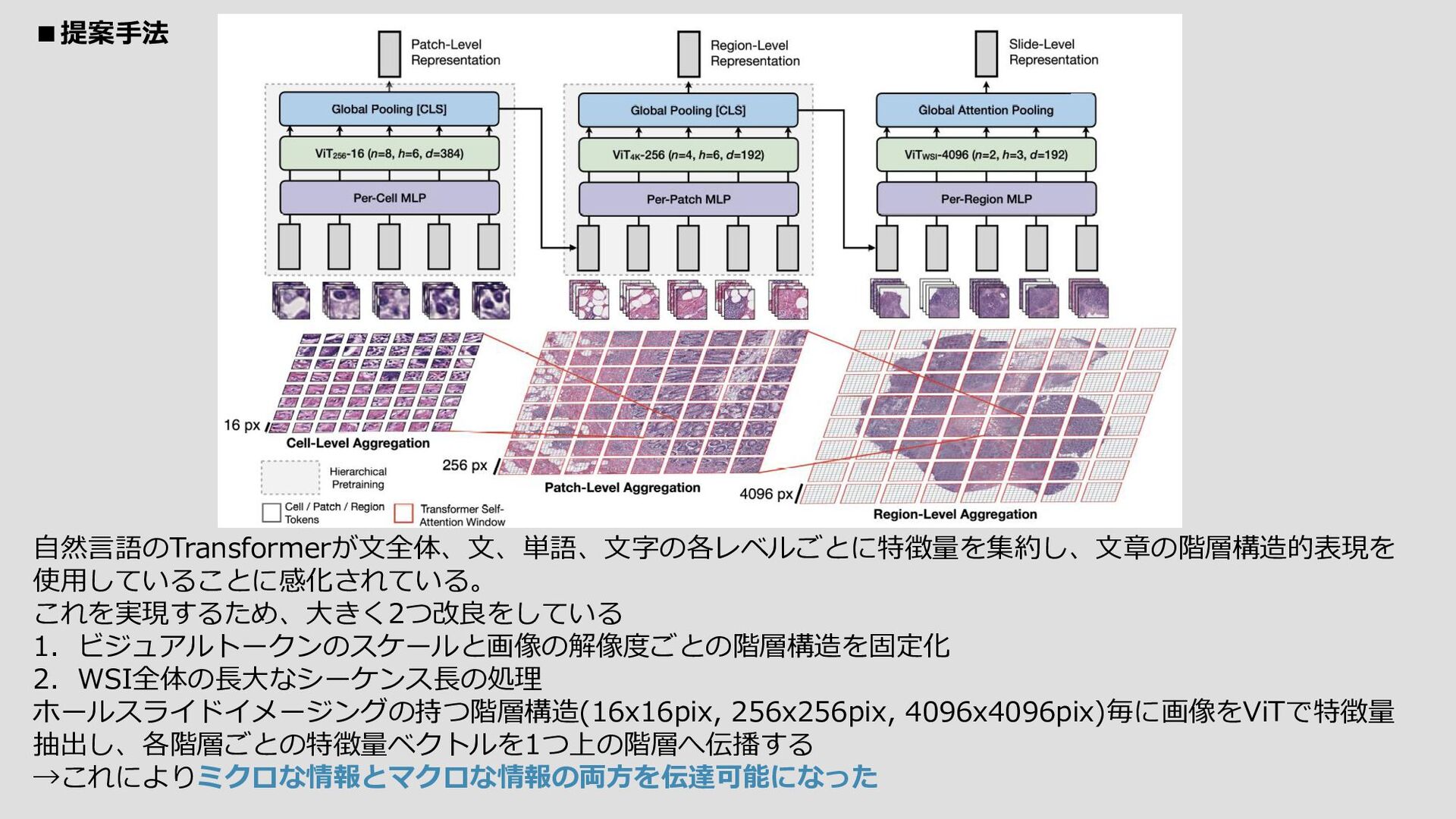
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models) 3. 自己教師付き学習による脳内音声処理の現実的なモデル化に向けて (原文: Toward a realistic model of speech processing in the brain with self-supervised learning) 4. 大規模言語モデルの創発的能力 (原文: Emergent Abilities of Large Language Models) 5. Diffusion-LMによる制御可能なテキスト生成の改善 (原文: Diffusion-LM Improves Controllable Text Generation) 6. アルゴリズム・インプリント (原文: The Algorithmic Imprint) 7. Pythae:Pythonによる生成オートエンコーダの統一 -- ベンチマーキングユースケース (原文: Pythae: Unifying Generative Autoencoders in Python -- A Benchmarking Use Case) 8. 学習可能な点、学習価値のある点、未学習の点を優先的にトレーニングする。 (原文: Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt) 9. アメリカの博士号取得者の給与は、生活費の格差の拡大を考慮していない (原文: American postdoctoral salaries do not account for growing disparities in cost of living) 10. 階層的自己教師付き学習によるギガピクセル画像への視覚変換器のスケーリング (原文: Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning) PaperWithCodeの10本を紹介 【pickup】 https://ml-ocu.s3-ap-northeast-1.amazonaws.com/arxiv-translation/sanity/2022-06-24-top-social.txt
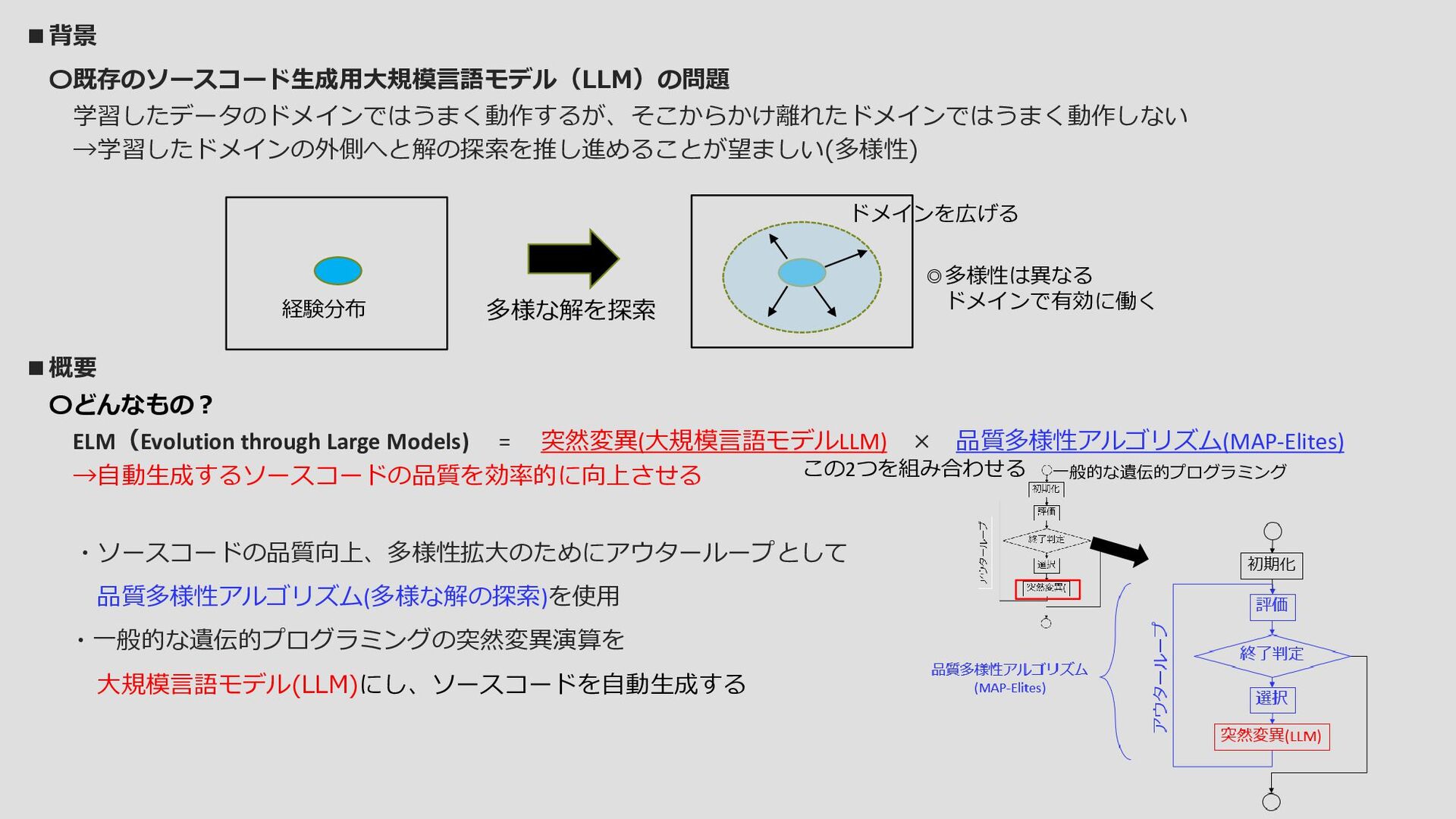
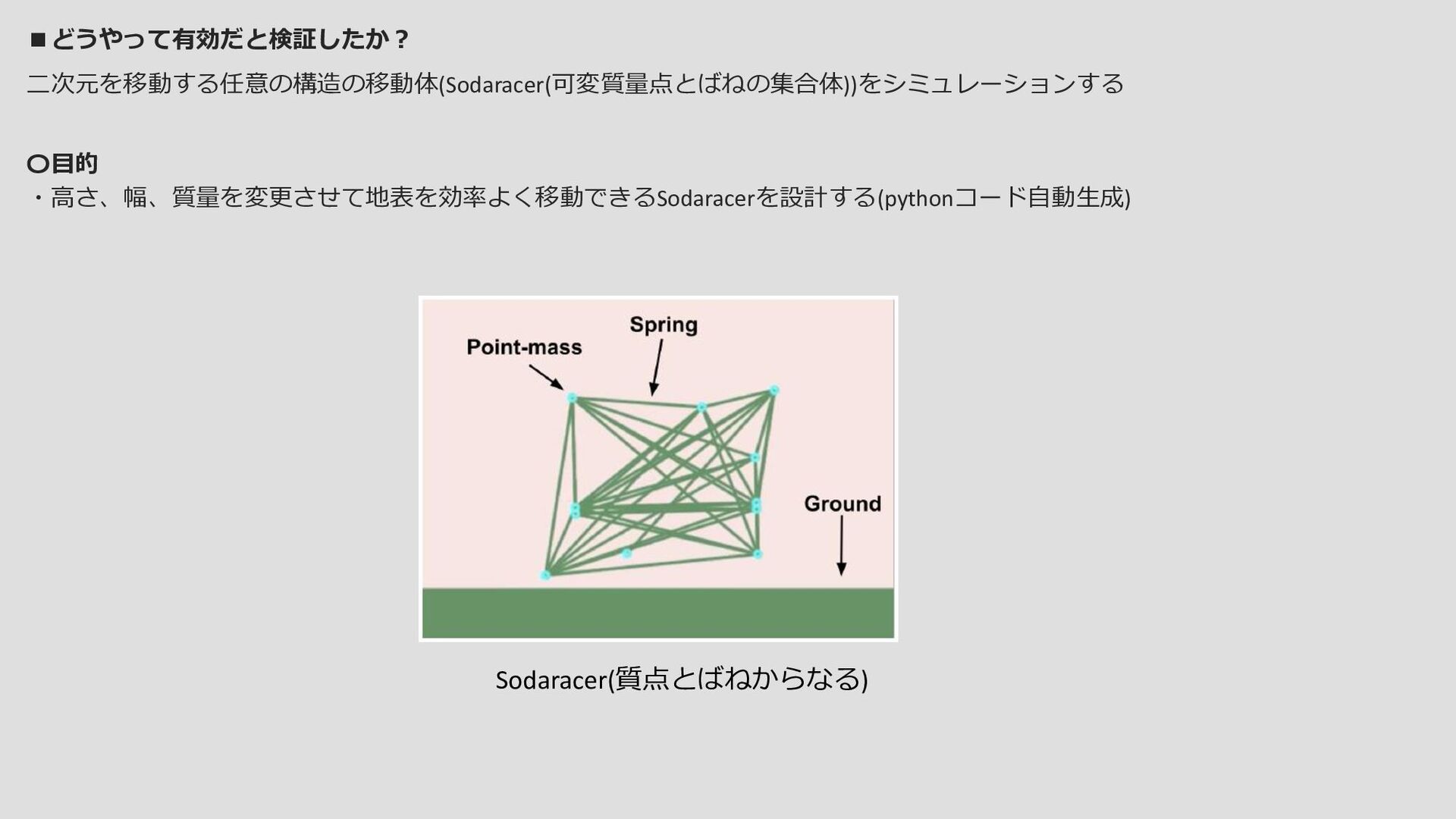
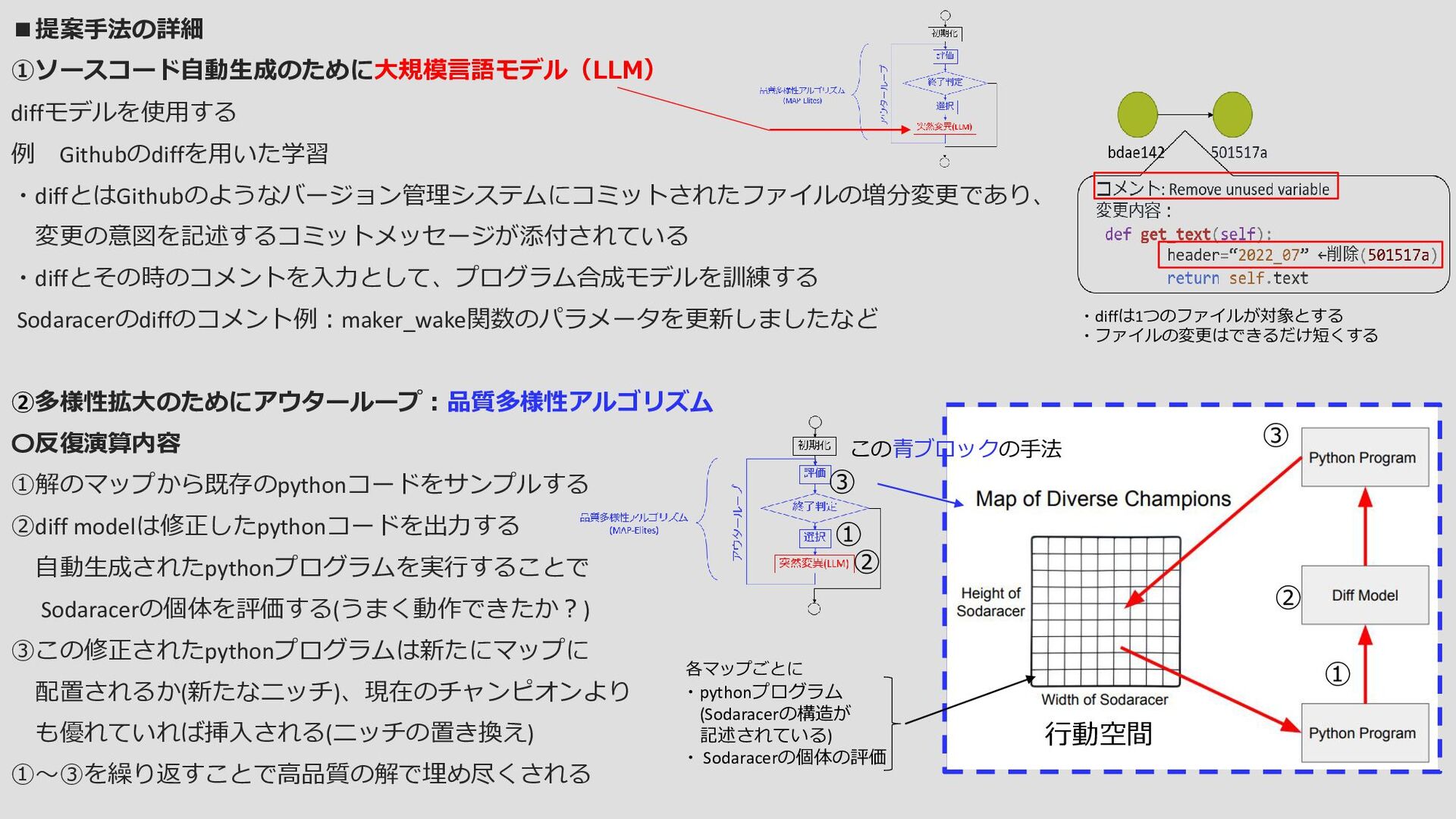
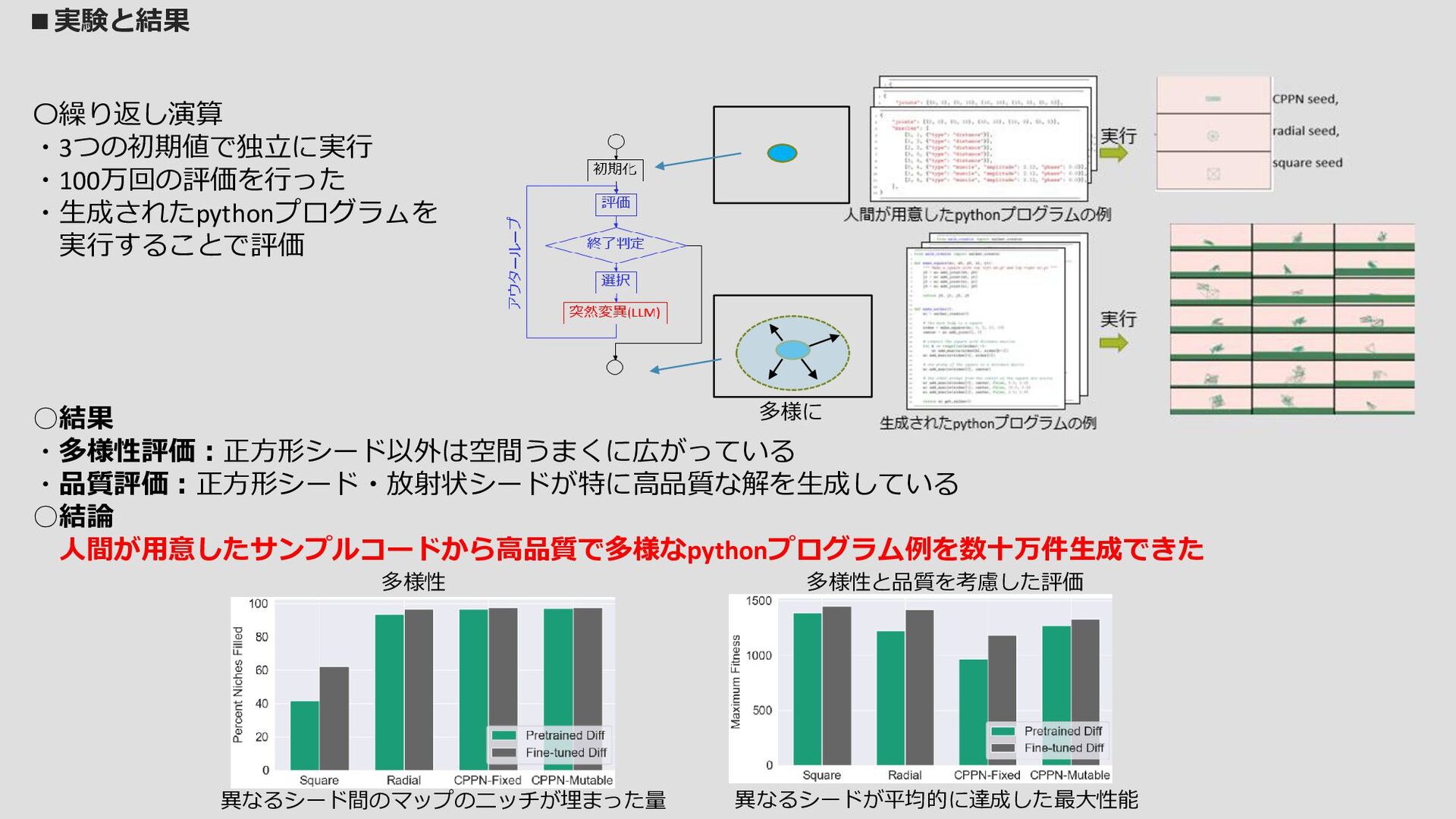
〇反復演算内容 ①解のマップから既存のpythonコードをサンプルする ②diff modelは修正したpythonコードを出力する 自動生成されたpythonプログラムを実行することで Sodaracerの個体を評価する(うまく動作できたか?) ③この修正されたpythonプログラムは新たにマップに 配置されるか(新たなニッチ)、現在のチャンピオンより も優れていれば挿入される(ニッチの置き換え) ①~③を繰り返すことで高品質の解で埋め尽くされる ・diffは1つのファイルが対象とする ・ファイルの変更はできるだけ短くする この青ブロックの手法 ・pythonプログラム (Sodaracerの構造が 記述されている) ・ Sodaracerの個体の評価 各マップごとに ① ① ② ② ③ ③ 行動空間
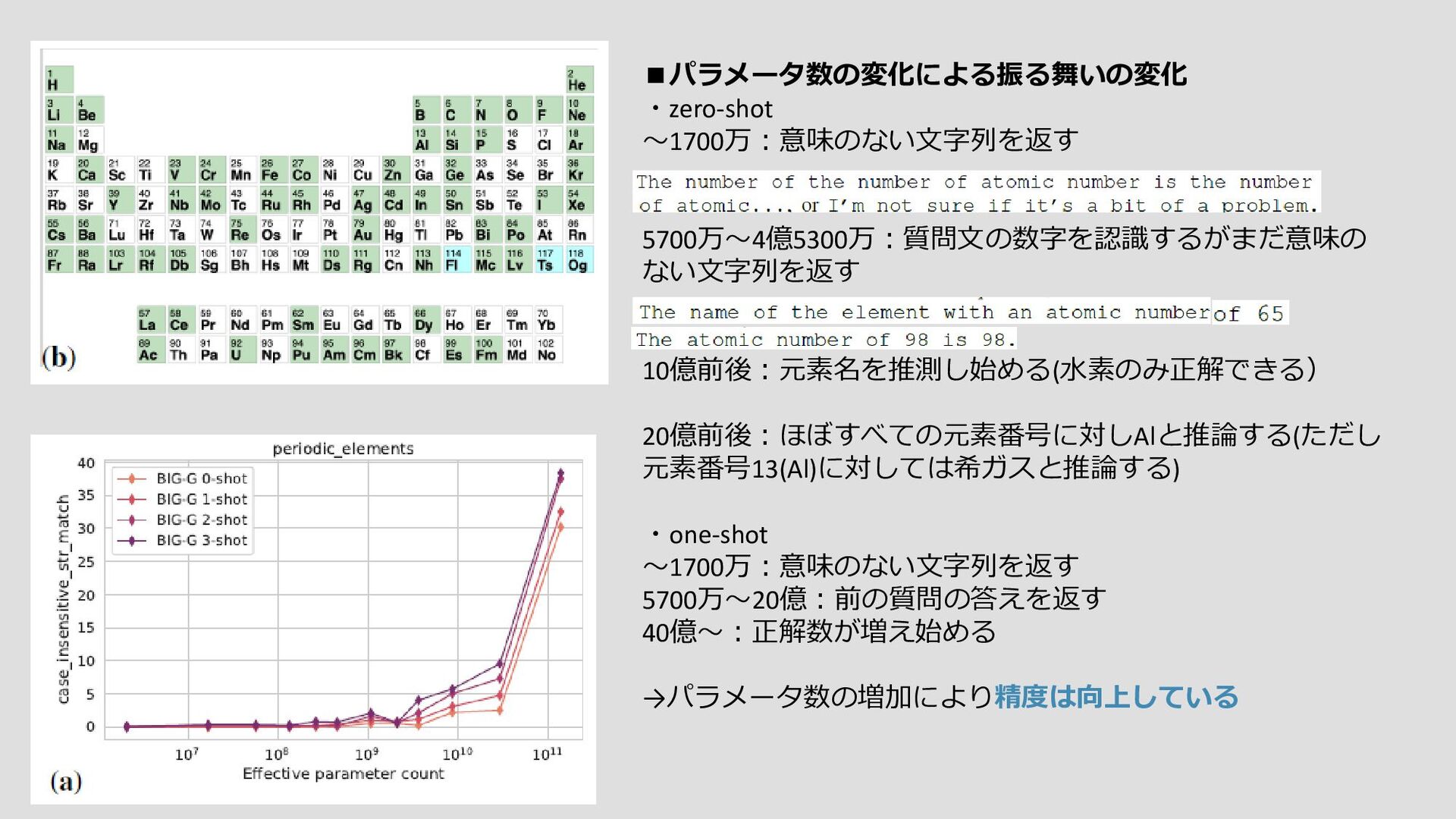
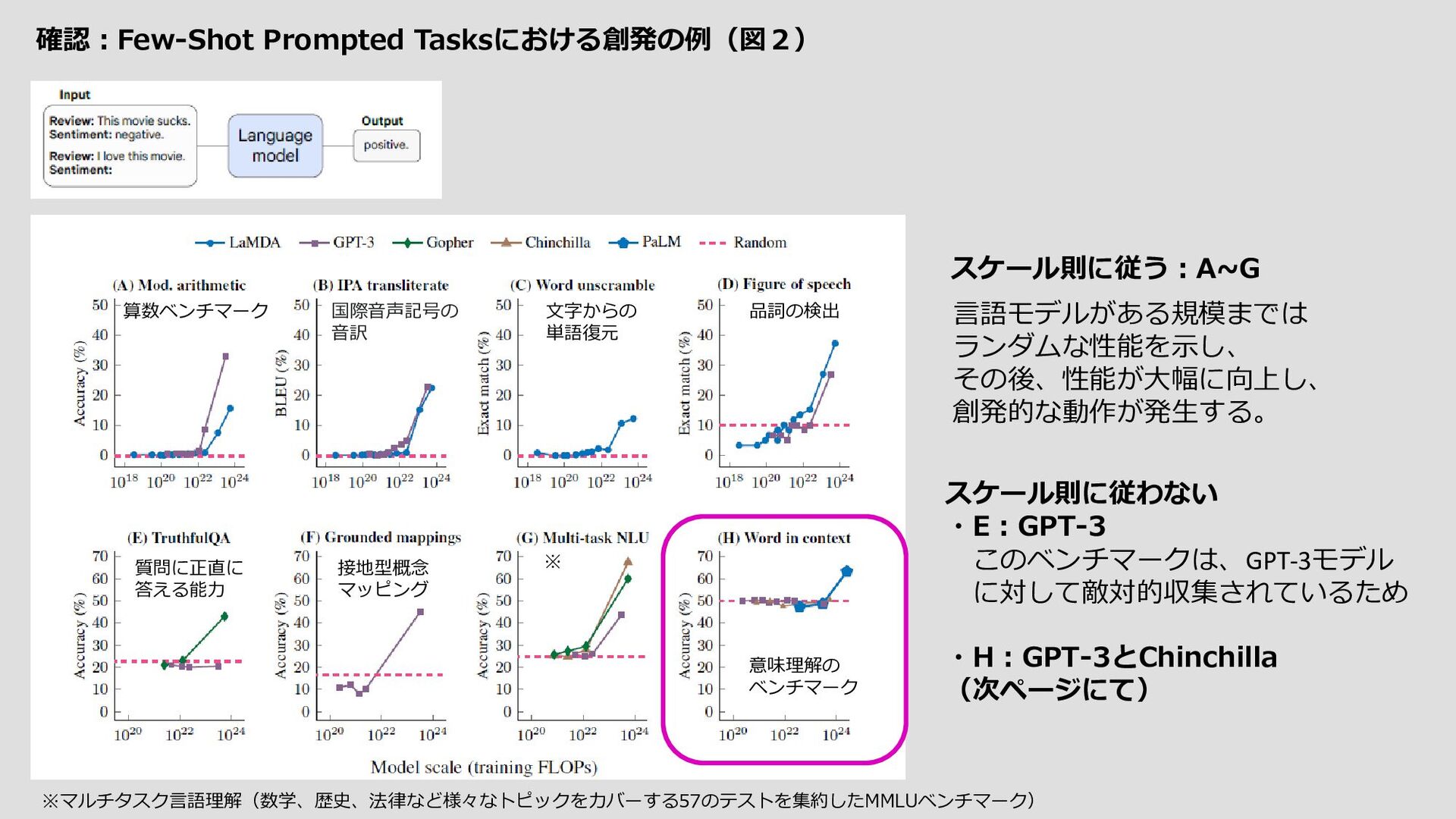
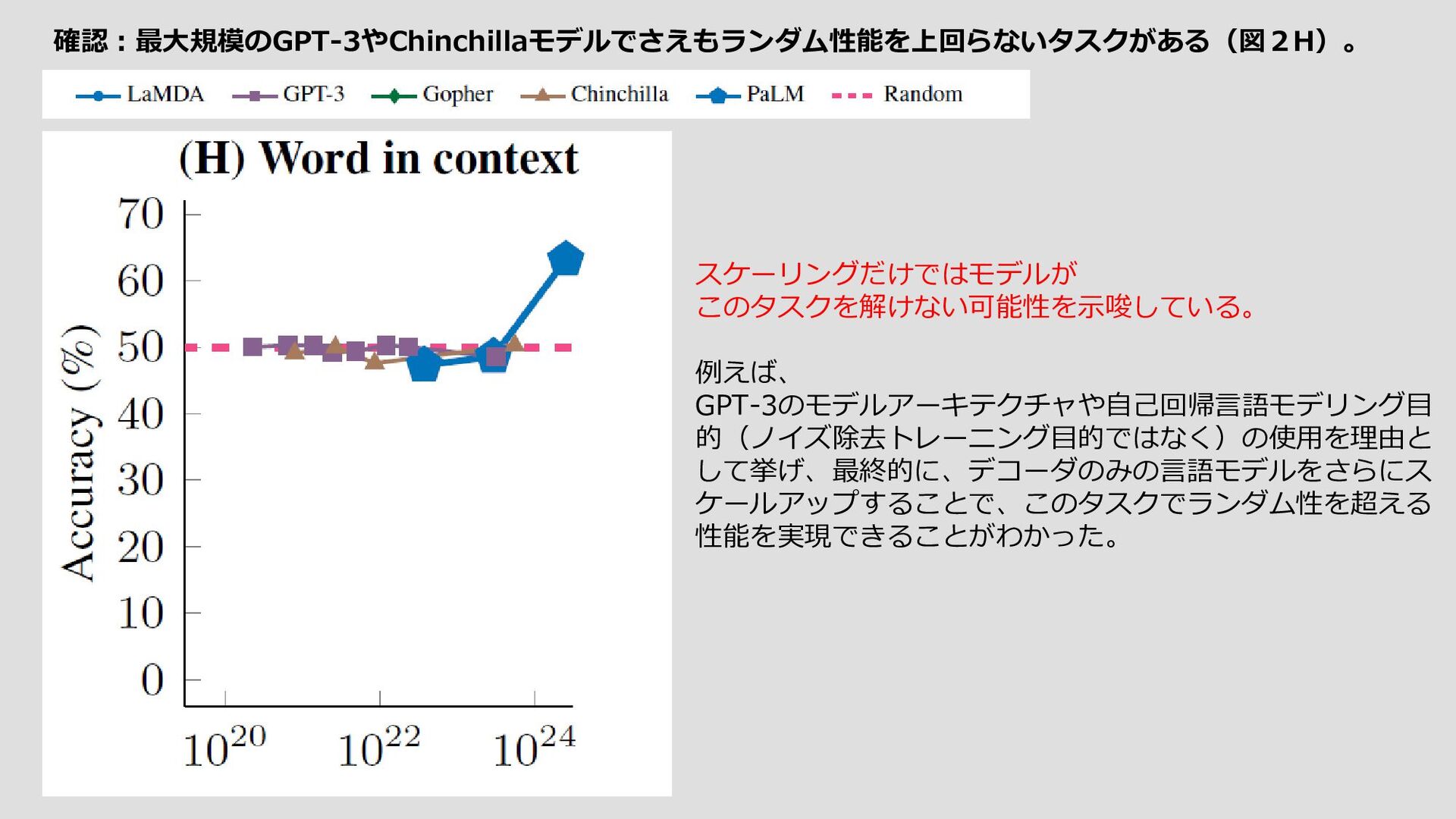
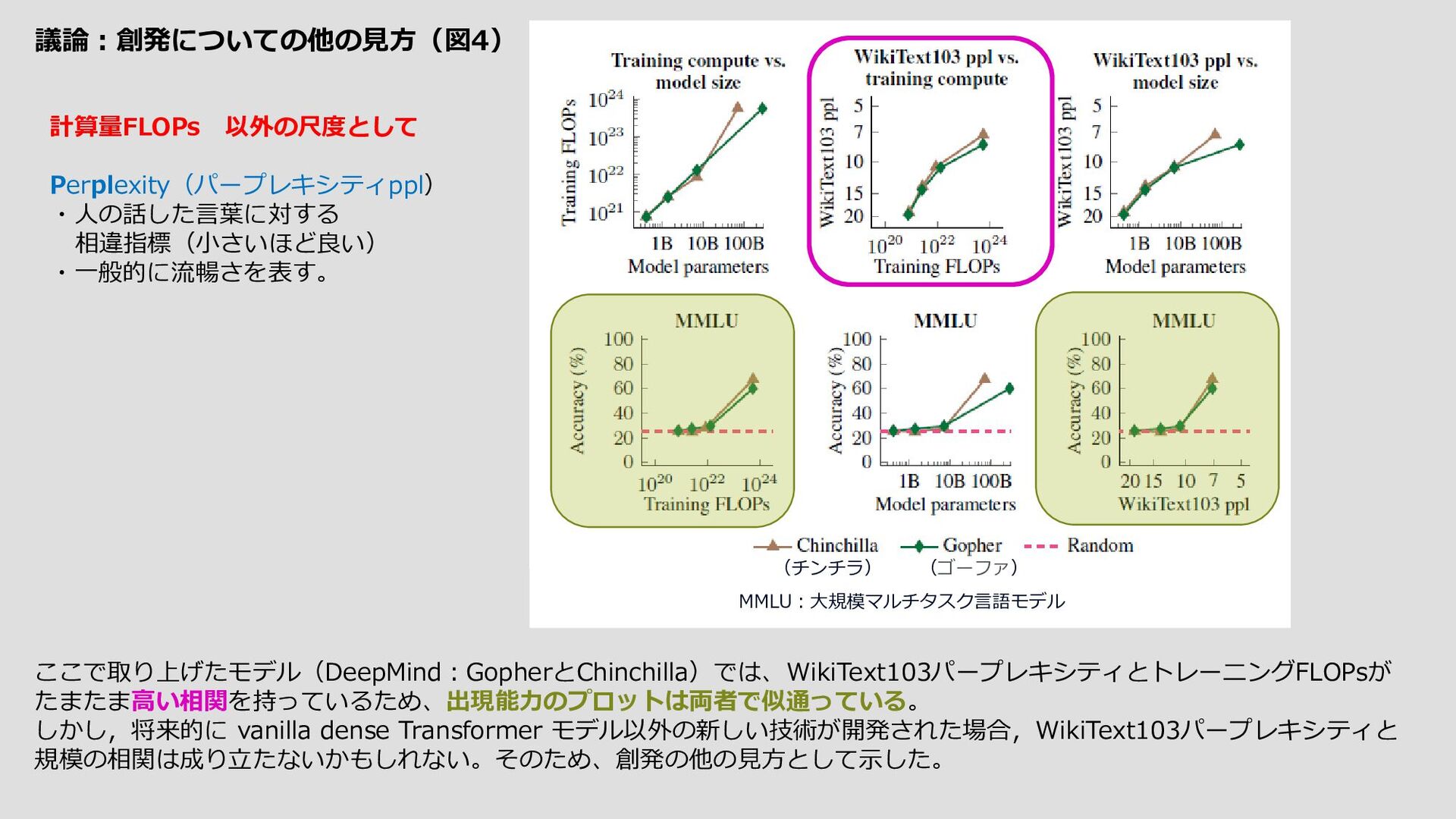
大規模言語モデルの創発能力という予測不可能な現象に関する議論をすること。 ノーベル賞を受賞した物理学者Philip Anderson(アンダーソン、1972)の1972年の論文「More Is Different」 に根ざした、以下の創発の一般定義より 『創発とは、システムの量的な変化によって、振る舞いが質的に変化することです』 創発の例 参照先)Emergence – How Stupid Things Become Smart Together – YouTube ・個体としては取るに足らないものが集団となることで、単なる「個体の集合」を超えた別次元の性質を 備えることができる現象を「創発」と呼ぶ。 ・個体が起こすアクションとそれに対するリアクションはランダムで、予測することはできません。 ・相互作用の結果として
・自然言語の指示をロボットが実行可能な動作に変換したり(Ahn et al., 2022; Huang et al., 2022)、 ・ユーザーと対話したり(Coenen et al., 2021; Wu et al., 2021, 2022; Lee et al., 2022b)、 ・マルチモーダル推論(Zeng et al.) 創発的な能力の例は数多くあるが、なぜそのような能力が創発されるのかについて、説得力のある説明は 今のところほとんどない。直観的には、例えば、 ・多段階推論タスクが、Lステップの逐次計算を必要とする場合、少なくともO(L)層の深さを持つモデルが 必要となるかもしれない。 ・世界知識を必要とするタスクの場合、圧縮された知識ベース自体を捉えるのに十分なパラメータを持つモデルが 必要かもしれない。 事前訓練に明示的に含まれることなく、 Few-Shot Promptedで出現能力が観察されているため、リスクも出現しうる ということである。
ズムの刻印」という概念を導入します.この概念とその意味を,160カ国以上で実施されている国際的に認められた英国ベースの高校卒業資格試験で あるGeneral Certificate of Education (GCE) Advanced (A) Level試験のアルゴリズムによる採点を巡る2020年の出来事を通じて運用する.アルゴ リズムによる標準化は、最終的に世界的な抗議運動によって撤廃されたが、この撤廃が、学生、教師、保護者の生活を形成する社会技術的インフラへ のアルゴリズムによる刷り込みを元に戻すことがいかにできなかったかを示す。これらの出来事は、アルゴリズムによる仲介がある場合とない場合の 両方の世界の状態を分析する貴重な機会となっている。我々はバングラデシュをケーススタディとして、北半球で作られたアルゴリズムが南半球のス テークホルダーにいかに不釣り合いな影響を与えるかを説明する。47のインタビューからなる1年以上にわたるコミュニティとの関わりを記録し、バ ングラデシュで「何が」起こったかを初めて一貫した年表として提示し、「なぜ」「どのように」起こったかをアルゴリズムの刻印とアルゴリズムに よる公平性の位置づけというレンズを通して文脈付けしている。これらの出来事を分析することで、アルゴリズムによる刷り込みの輪郭をインフラ、 社会、個人の各レベルでどのように推測することができるかを明らかにする。また、インプリントを意識することで、(a)アルゴリズムの影響につ いて考える際の境界を広げ、(b)アルゴリズムの設計方法を伝え、(c)AIガバナンスの指針とすることができるのかについて、概念的・実際的な示 唆を与えている。 目的:アルゴリズムによる害が発生した場合の対策として、アルゴリズムの使用停止がよく行われるが、停止(削除)したからと 言って公平性、説明責任、透明性、倫理の問題がなくなるわけではない。この有害なアルゴリズムは存在した期間以降も はるかに長く残り続ける(アルゴリズムの痕跡)ことを説明する 成果:例を通して「アルゴリズムの痕跡」について説明し、それを踏まえた上で、アルゴリズムをどう考慮するか説明する 方法:英国ベースの高校卒業資格試験(GCE)の2020年の問題を例に挙げて「アルゴリズムの痕跡」について説明する 固有名: ー 著者所属: Data & Society Research Institute, Georgia Institute of Technology
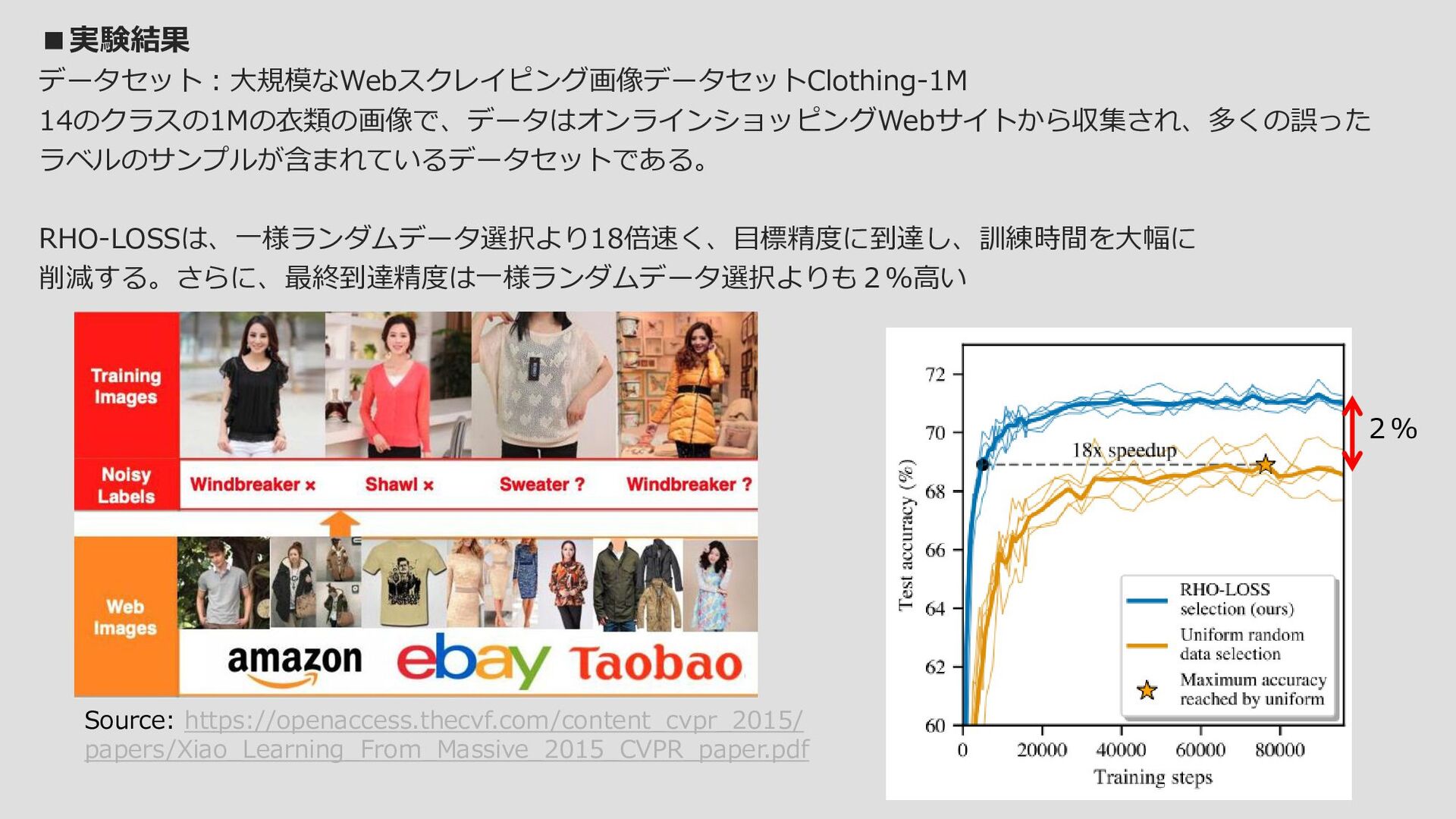
Worth Learning, and Not Yet Learnt) https://arxiv.org/abs/2206.07137v2 ウェブスケールデータでの学習は数ヶ月かかることもある。しかし、ほとんどの計算と時間は、既に学習済みの冗長 でノイズの多いポイントや、学習不可能なポイントに浪費されている。学習を高速化するために、我々はRHO-LOSS (Reducible Holdout Loss Selection)を導入する。これは、モデルの汎化損失を最も低減する学習用のポイントを ほぼ選択する、シンプルだが原理的な手法である。その結果、RHO-LOSSは既存のデータ選択手法の弱点を緩和する。 最適化文献の技術は一般的に「難しい」(例えば高損失)点を選択するが、そのような点はしばしばノイズが多い (学習可能ではない)かタスクとの関連性が低いのである。逆に、カリキュラム学習は「簡単な」点を優先するが、 そのような点は一度学習すれば学習する必要はない。これに対し、RHO-LOSSは学習可能で、学習に値する、そして まだ学習していないポイントを選択する。RHO-LOSSは先行技術よりはるかに少ないステップで学習し、精度を向上 させ、幅広いデータセット、ハイパーパラメータ、アーキテクチャ(MLP、CNN、BERT)において学習を高速化す ることが可能です。大規模なウェブスクレイピング画像データセットClothing-1Mにおいて、RHO-LOSSは18倍少な いステップで学習し、均一なデータシャッフリングよりも2%高い最終精度に到達しました。 目的:従来手法より高速に汎用誤差を低減させることができるRHO-LOSSを紹介する 成果:クリーンなデータと、ノイズの多いWebスクレイピングデータの大幅な高速化が可能 方法:冗長データ(学習済みデータ)、ノイズの多いデータ、外れ値をスキップし、学ぶ価値があるデータを 選択的して学習する 固有名:ー 著者所属:OATML、 University of Oxford、Cohere、University of Toronto
{kind=link}
{kind=link}
{kind=link}
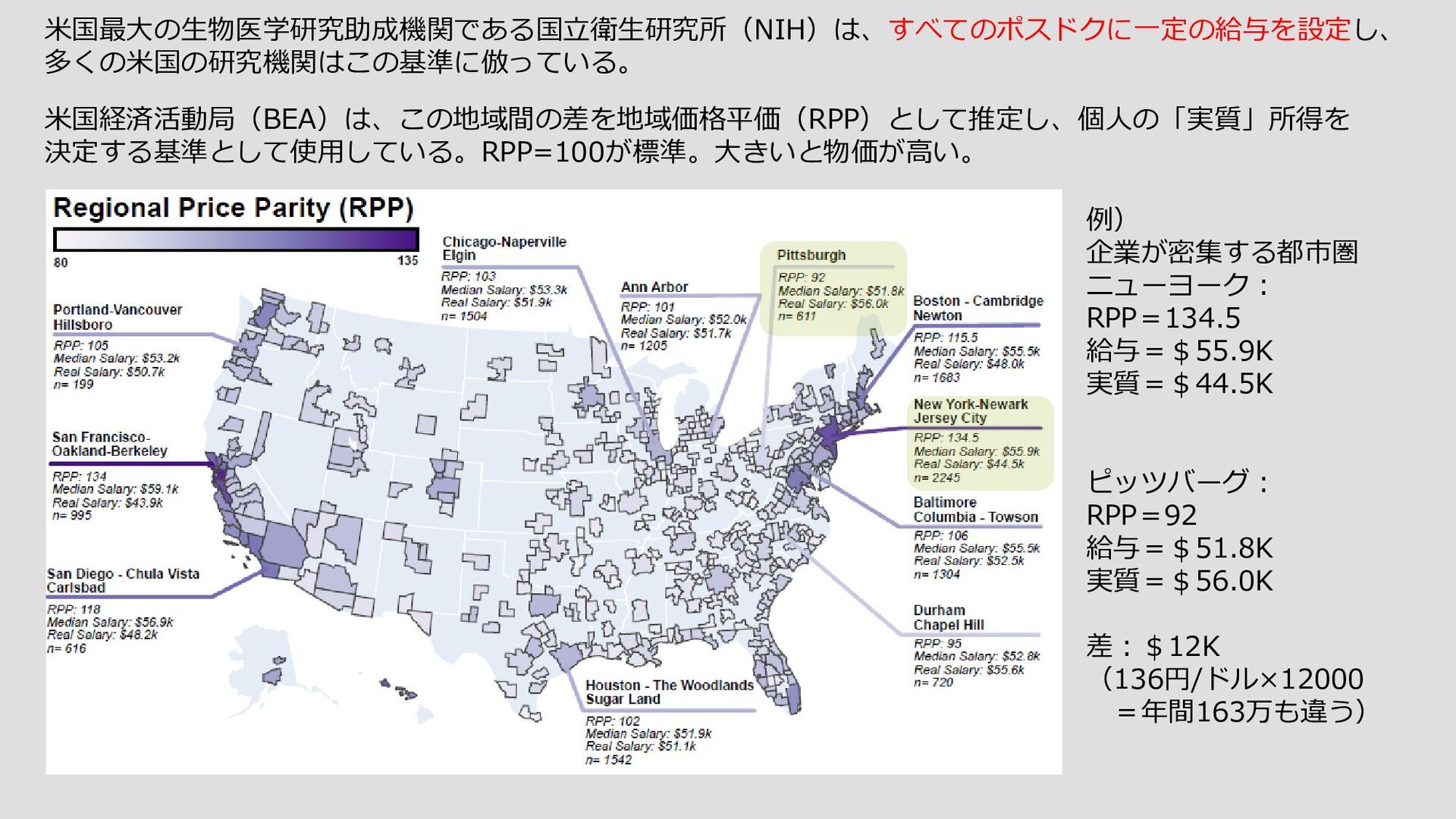
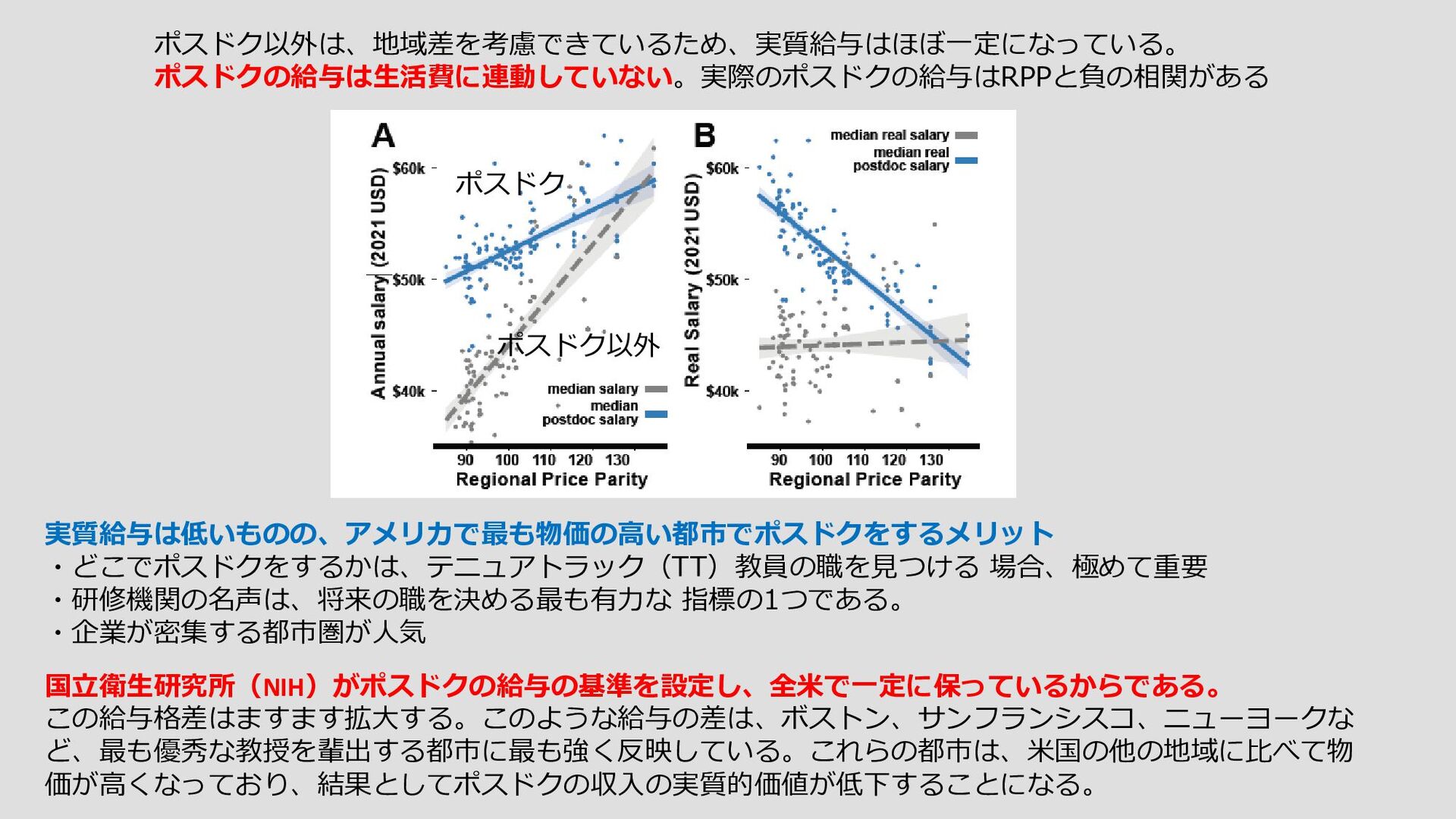
{kind=link}
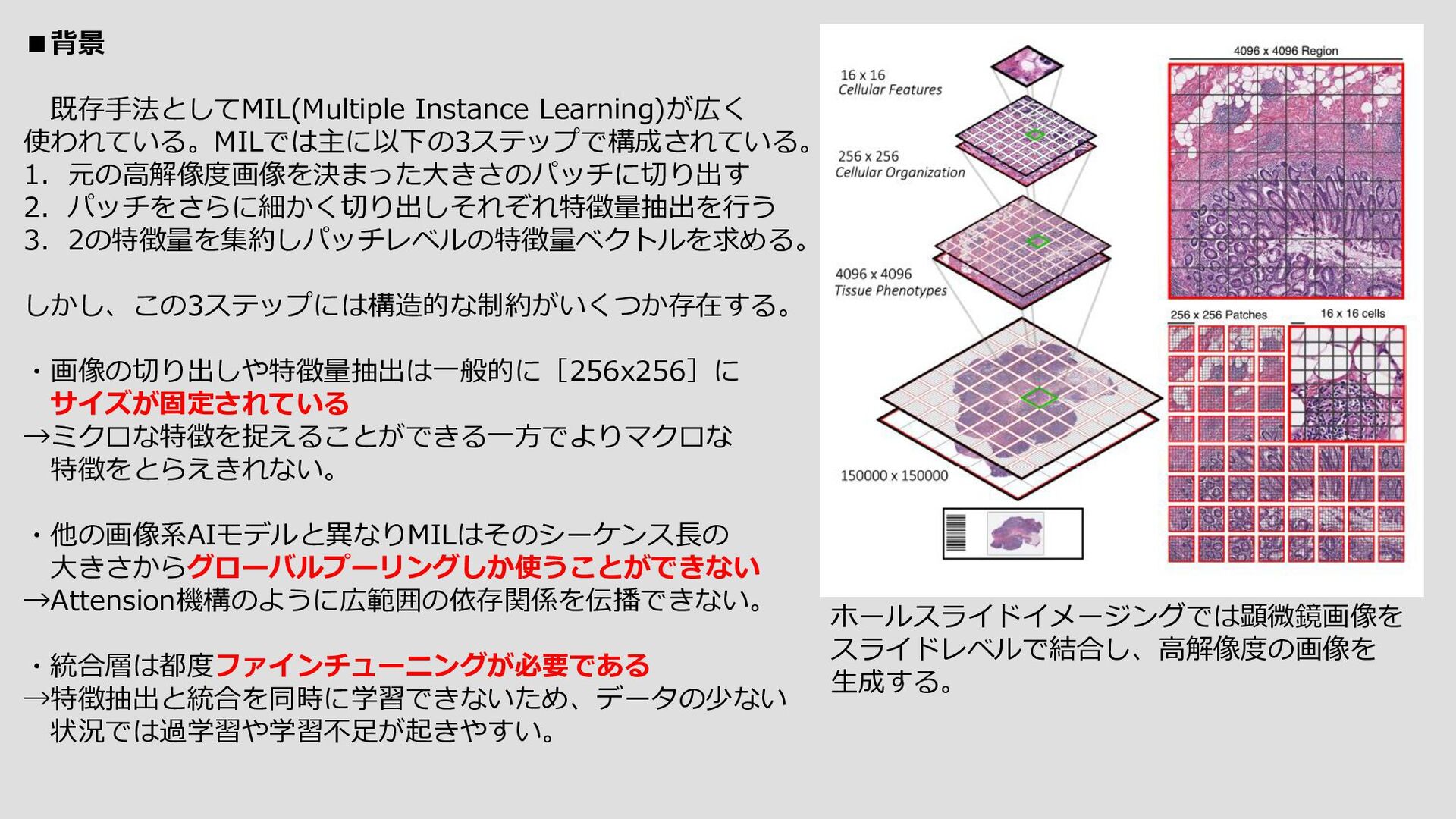
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}