Vasilis Gavrielatos*, A. Joshi, N. Oswald, B. Grot, V. Nagarajan The University of Edinburgh This work was supported by EPSRC, ARM and Microsoft through their PhD Fellowship Programs *The first two authors equally contribute to this work
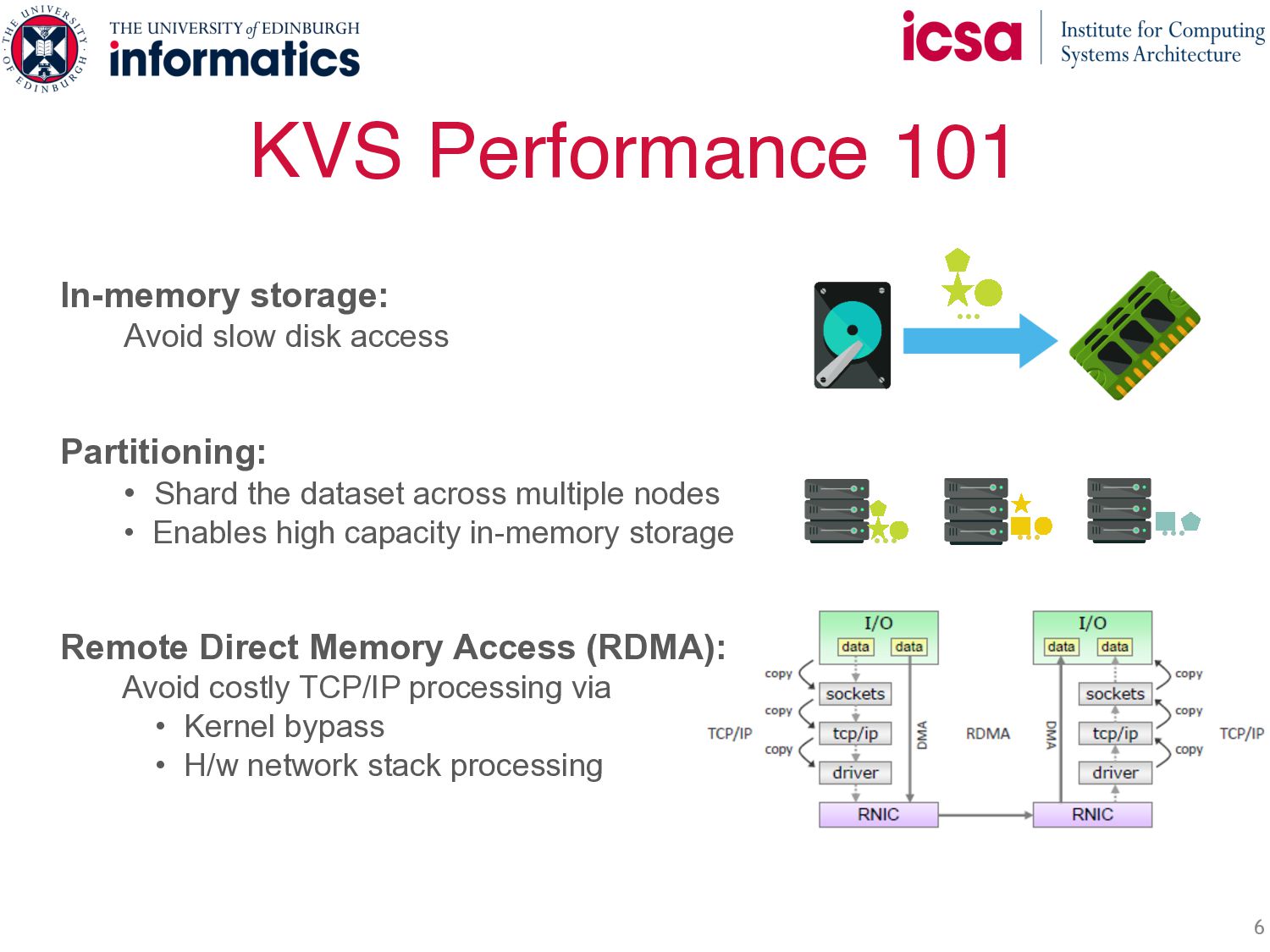
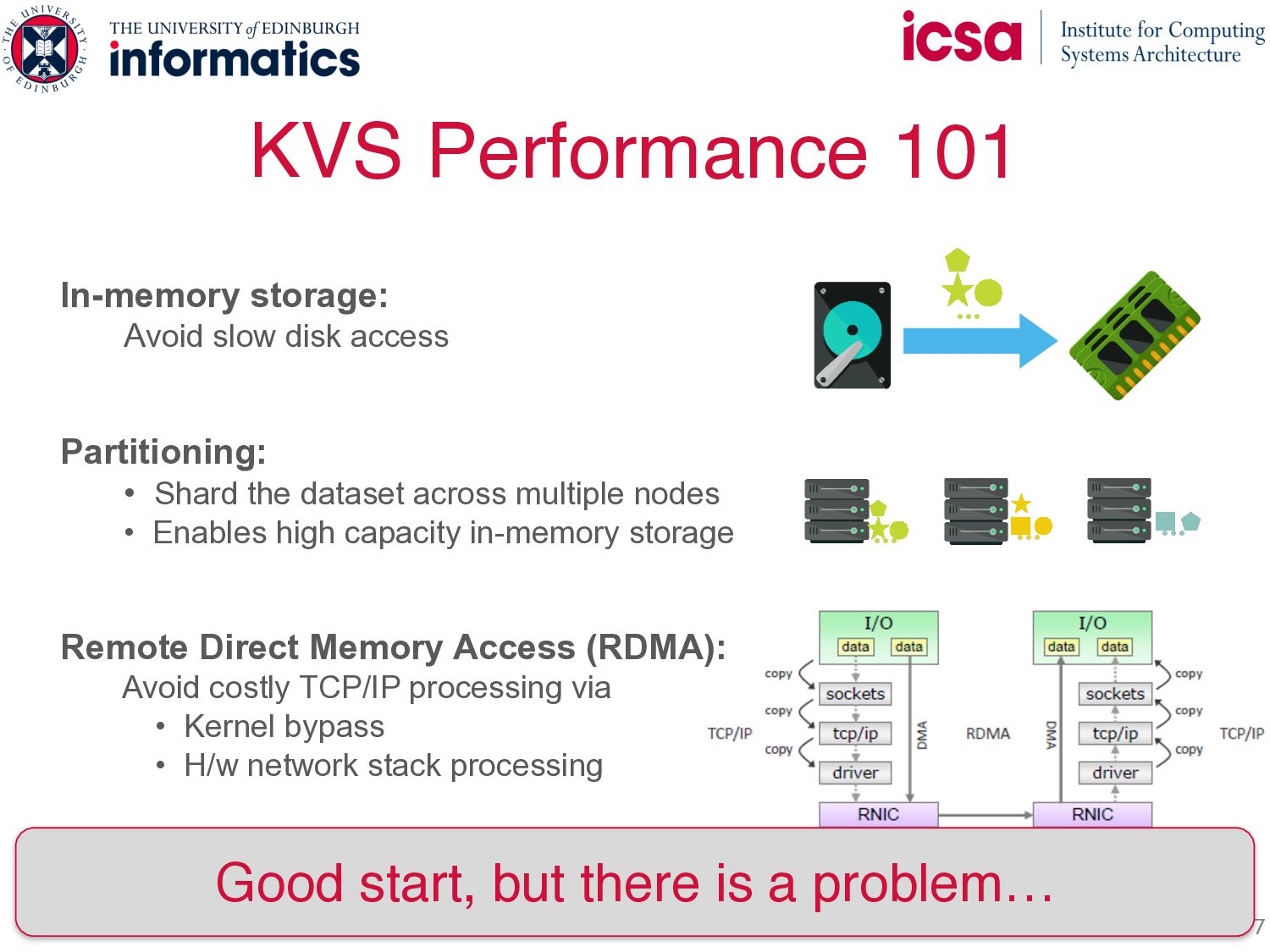
Avoid slow disk access Partitioning: • Shard the dataset across multiple nodes • Enables high capacity in-memory storage Remote Direct Memory Access (RDMA): Avoid costly TCP/IP processing via • Kernel bypass • H/w network stack processing Good start, but there is a problem…
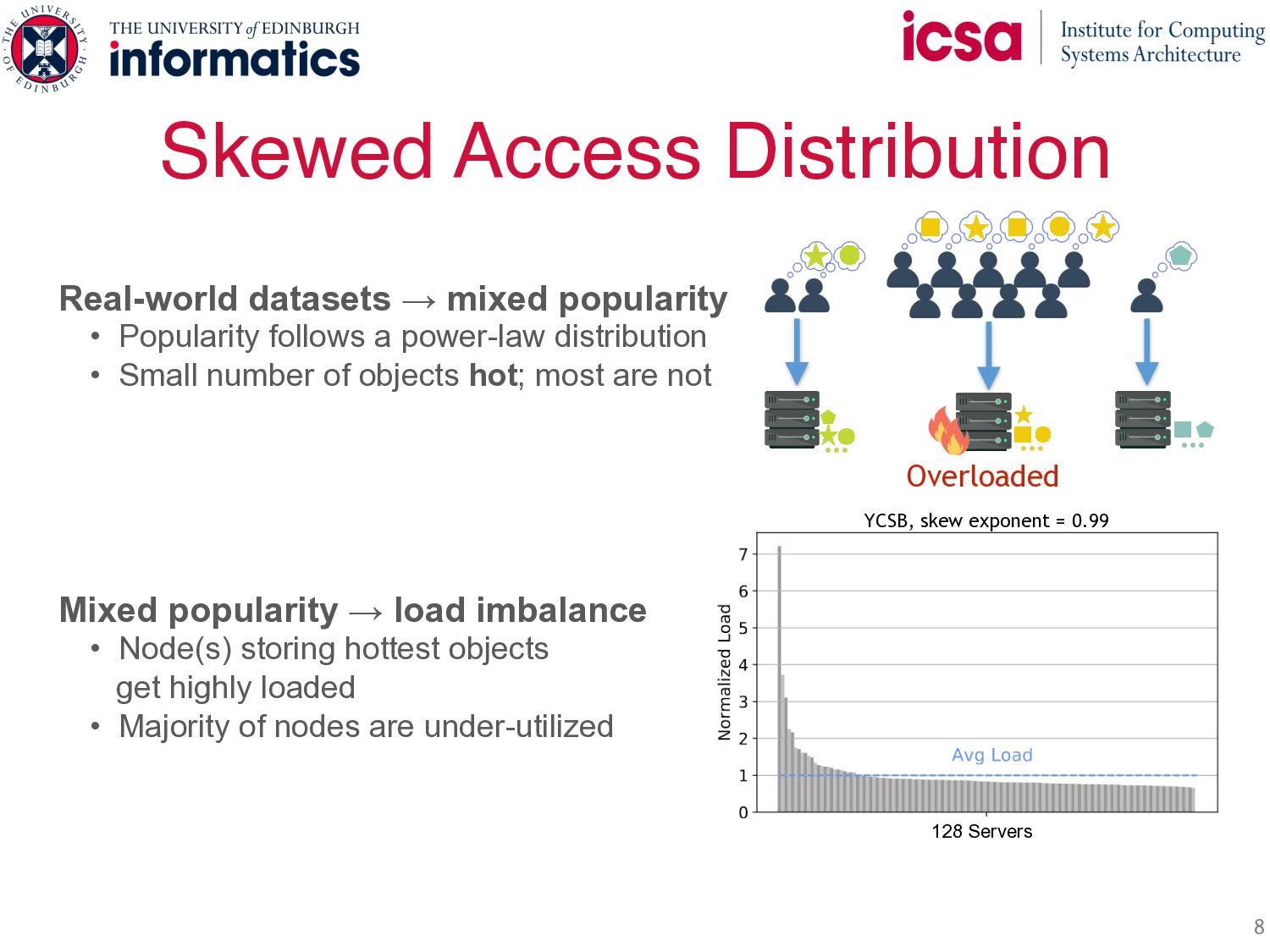
Popularity follows a power-law distribution • Small number of objects hot; most are not Mixed popularity → load imbalance • Node(s) storing hottest objects get highly loaded • Majority of nodes are under-utilized 128 Servers … … … Overloaded YCSB, skew exponent = 0.99
Popularity follows a power-law distribution • Small number of objects hot; most are not Mixed popularity → load imbalance • Node(s) storing hottest objects get highly loaded • Majority of nodes are under-utilized 128 Servers … … … Overloaded YCSB, skew exponent = 0.99 Skew-induced load imbalance limits system throughput
of the KVS caching hot objects. ◦ Filters the skew with a small cache ◦ Throughput is limited by the single cache Existing Skew Mitigation Techniques 10 … … … ← Cache
of the KVS caching hot objects. ◦ Filters the skew with a small cache ◦ Throughput is limited by the single cache NUMA abstraction [NSDI’14, SOCC’16] • Uniformly distribute requests to all servers • Remote objects RDMA’ed from home node ◦ Load balance the client requests ◦ No locality → excessive network b/w Most requests require remote access Existing Skew Mitigation Techniques 11 … … … … … … ← Cache
of the KVS caching hot objects. ◦ Filters the skew with a small cache ◦ Throughput is limited by the single cache NUMA abstraction [NSDI’14, SOCC’16] • Uniformly distribute requests to all servers • Remote objects RDMA’ed from home node ◦ Load balance the client requests ◦ No locality → excessive network b/w Most requests require remote access Existing Skew Mitigation Techniques 12 … … … … … … Can we get the best of both worlds? ← Cache
• Which items to cache and where? • How to steer traffic for maximum load balance & hit rate? Challenge 2: Keeping the caches consistent (i.e. what happens on a write) • How to locate replicas? • How to execute writes efficiently?
• Which items to cache and where? • How to steer traffic for maximum load balance & hit rate? Challenge 2: Keeping the caches consistent (i.e. what happens on a write) • How to locate replicas? • How to execute writes efficiently? Solving Challenge 1 with Symmetric Caching
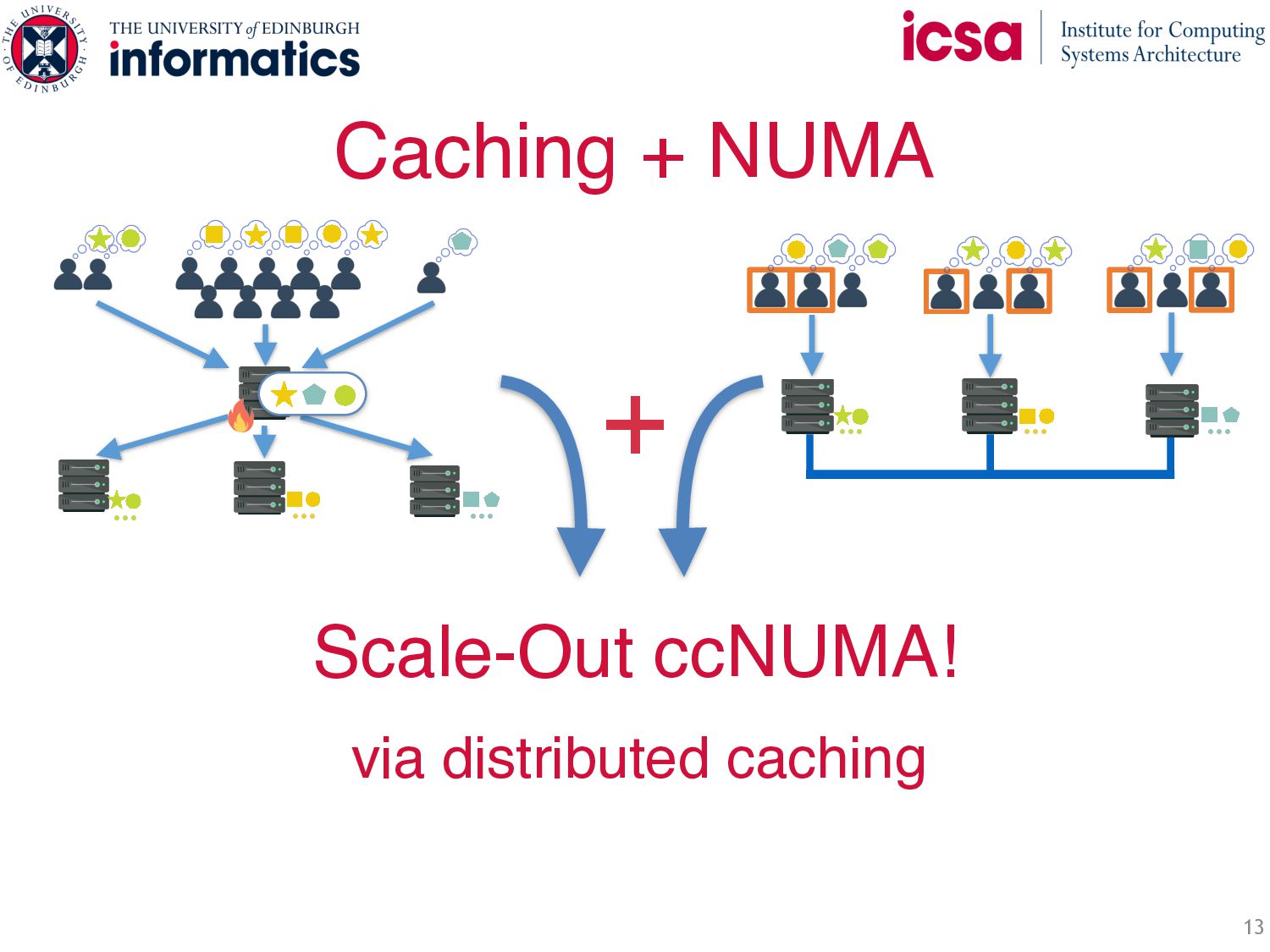
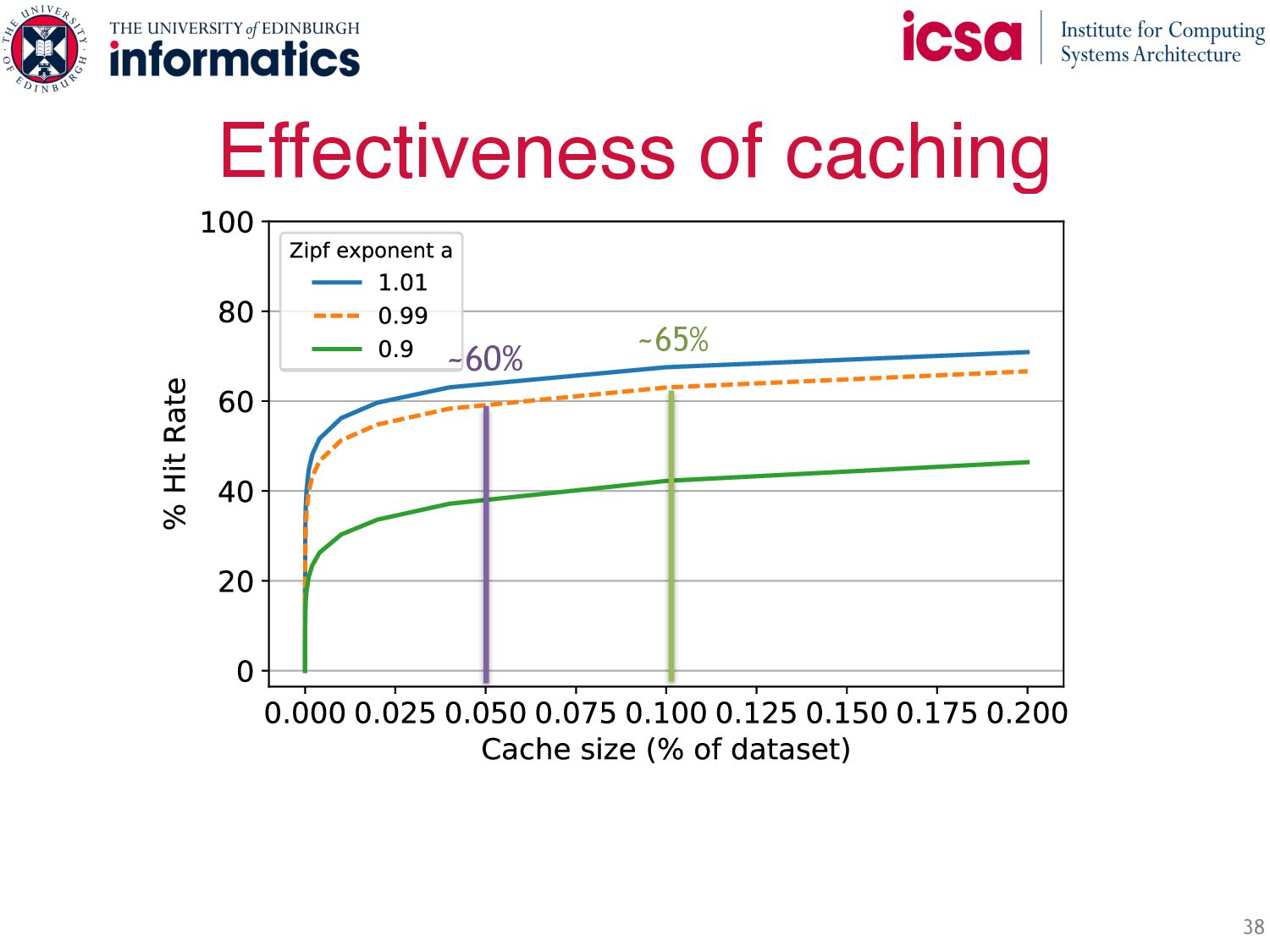
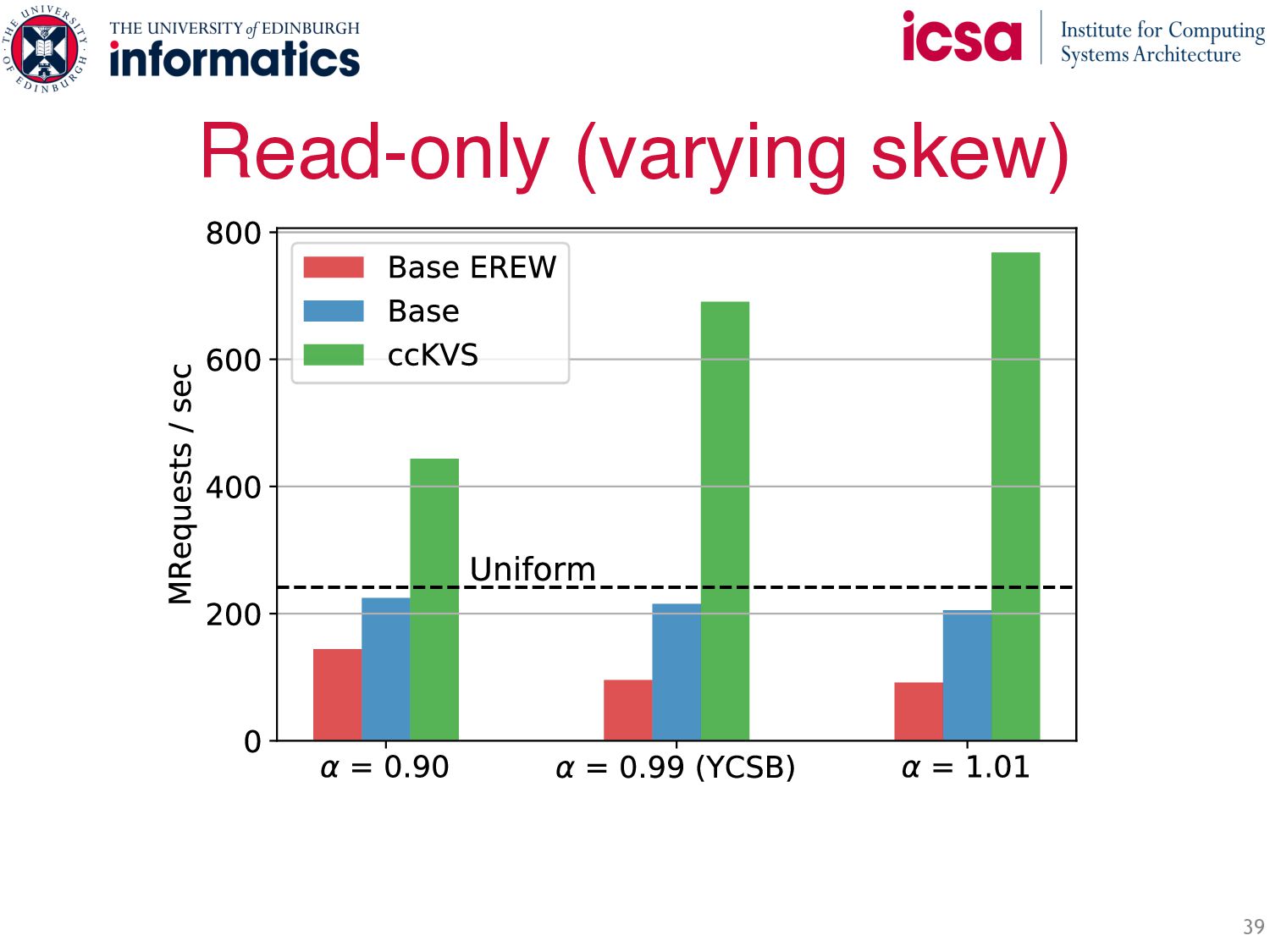
objects see most hits • Idea: all nodes cache hottest objects → Implication: all caches have same content • Symmetric caching: small cache with hottest objects at each node How to steer traffic for maximum load balance and hit rate? • Insight: symmetric caching → all caches equal (highest) hit rate • Idea: uniformly spread requests • Requests for hottest objects → served locally on any node • Cache misses served as in NUMA Abstraction Benefits: • Load balances and filters the skew • Throughput scales with number of servers • Less network b/w: most requests are served locally Symmetric Caching … … …
objects see most hits • Idea: all nodes cache hottest objects → Implication: all caches have same content • Symmetric caching: small cache with hottest objects at each node How to steer traffic for maximum load balance and hit rate? • Insight: symmetric caching → all caches equal (highest) hit rate • Idea: uniformly spread requests • Requests for hottest objects → served locally on any node • Cache misses served as in NUMA abstraction Benefits: • Load balances and filters the skew • Throughput scales with number of servers • Less network b/w: most requests are served locally Symmetric Caching … … …
objects see most hits • Idea: all nodes cache hottest objects → Implication: all caches have same content • Symmetric caching: small cache with hottest objects at each node How to steer traffic for maximum load balance and hit rate? • Insight: symmetric caching → all caches equal (highest) hit rate • Idea: uniformly spread requests • Requests for hottest objects → served locally on any node • Cache misses served as in NUMA abstraction Benefits: • Load balances and filters the skew • Throughput scales with number of servers • Less network b/w: most requests are served locally Symmetric Caching … … …
objects see most hits • Idea: all nodes cache hottest objects → Implication: all caches have same content • Symmetric caching: small cache with hottest objects at each node How to steer traffic for maximum load balance and hit rate? • Insight: symmetric caching → all caches equal (highest) hit rate • Idea: uniformly spread requests • Requests for hottest objects → served locally on any node • Cache misses served as in NUMA abstraction Benefits: • Load balances and filters the skew • Throughput scales with number of servers • Less network b/w: most requests are served locally Symmetric Caching … … … Challenge 2: How to keep the caches consistent?
all replicas of the new value How to locate replicas? - Easy with Symmetric Caching! If object in local cache → all nodes cache it How to execute writes efficiently? • Typical protocols: ◦ Ensure global write ordering via a primary ◦ Primary executes all writes → hot-spot Primary executes all writes Write( ) Write( ) Primary
all replicas of the new value How to locate replicas? - Easy with Symmetric Caching! If object in local cache → all nodes cache it How to execute writes efficiently? • Typical protocols: ◦ Ensure global write ordering via a primary ◦ Primary executes all writes → hot-spot • Fully distributed writes Can guarantee ordering via logical clocks Avoid hot-spots Evenly spread write propagation costs Primary executes all writes Write( ) Write( ) Primary Fully distributed writes Write( ) Write( )
writes via logical clocks Two (per-key) strongly consistent flavours: ◦ Linearizability (Lin): 2 RTTs Broadcast Invalidations* * along with logical (Lamport) clocks Lin Invalidate all caches Write( )
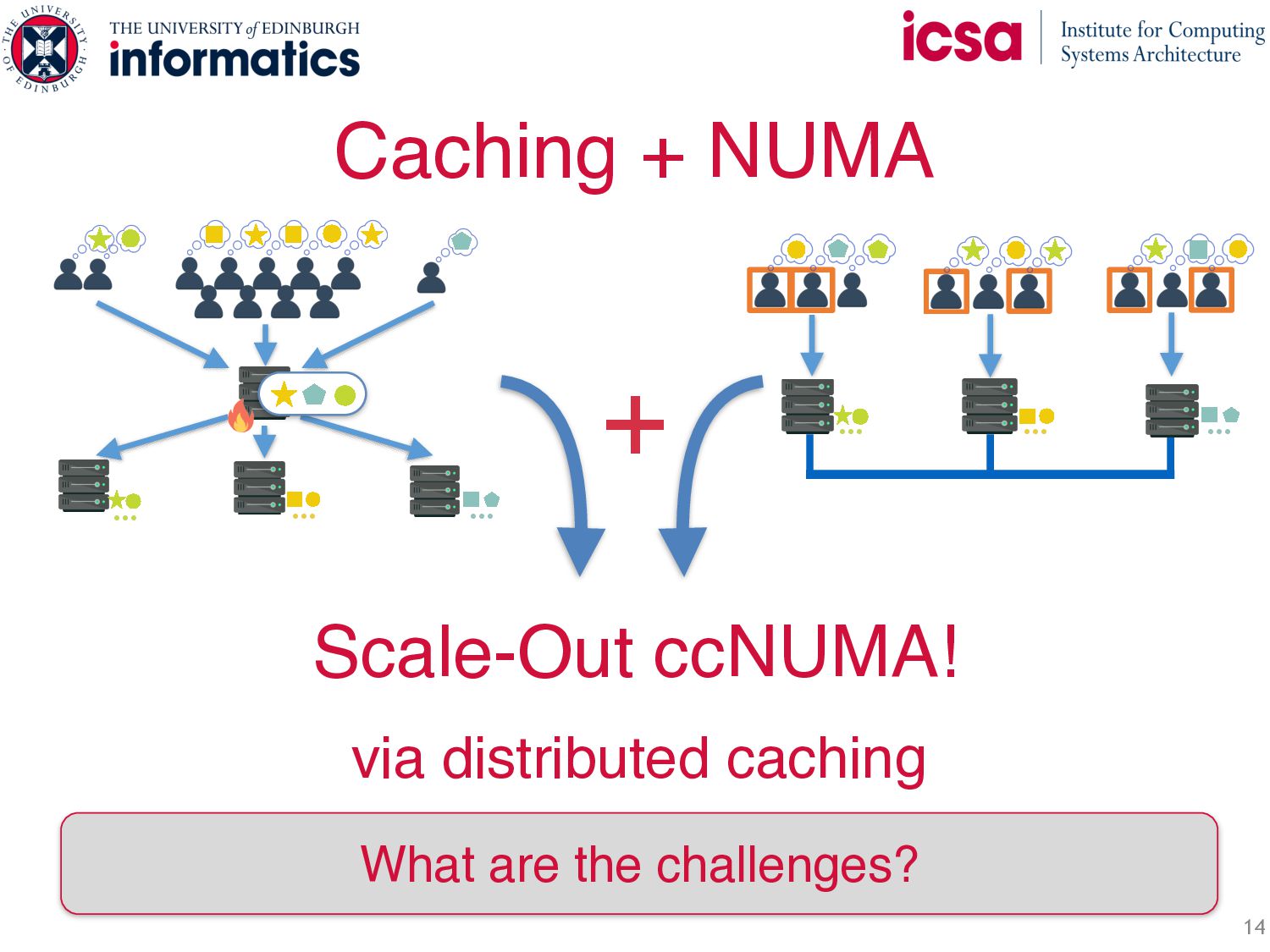
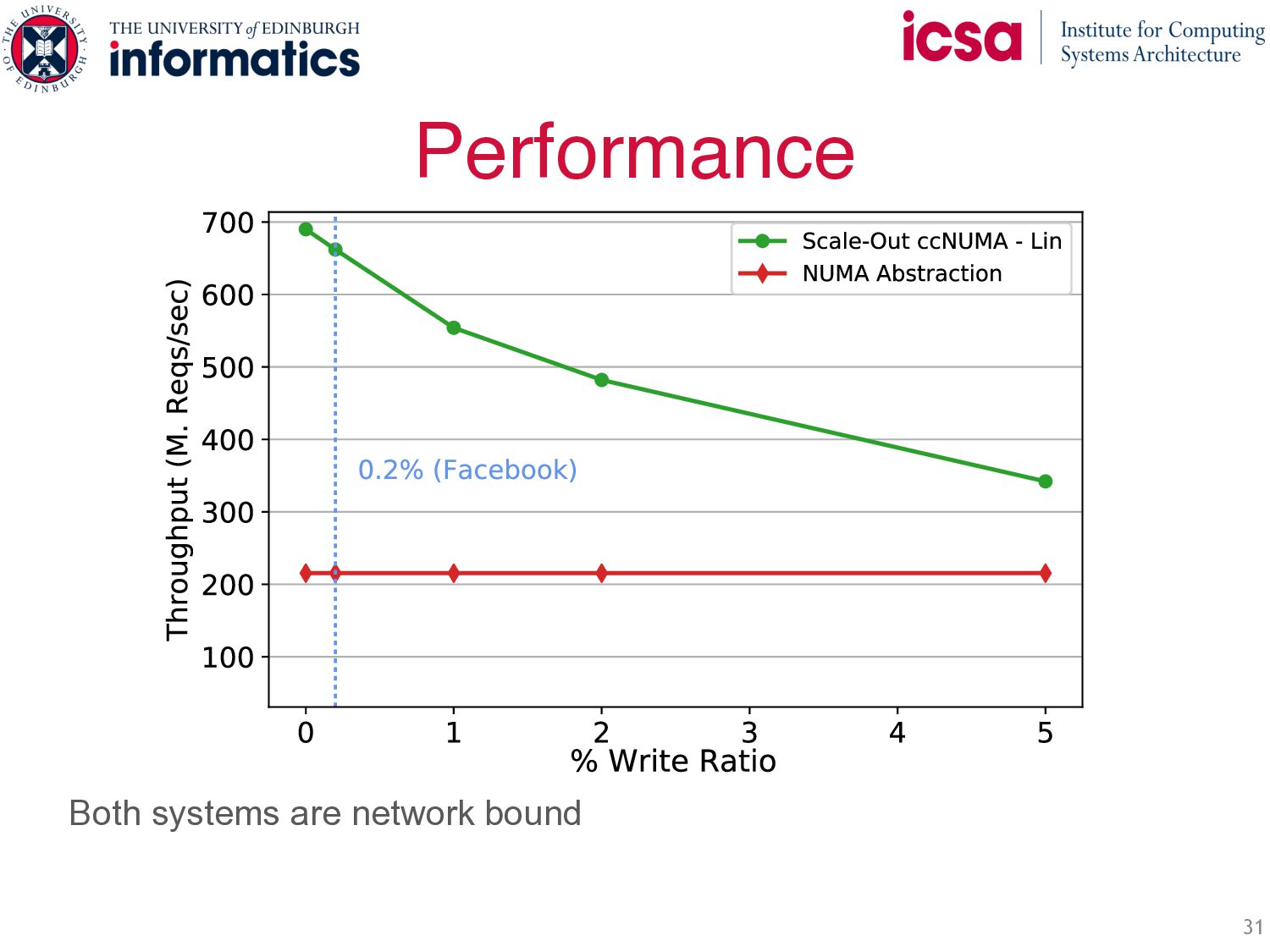
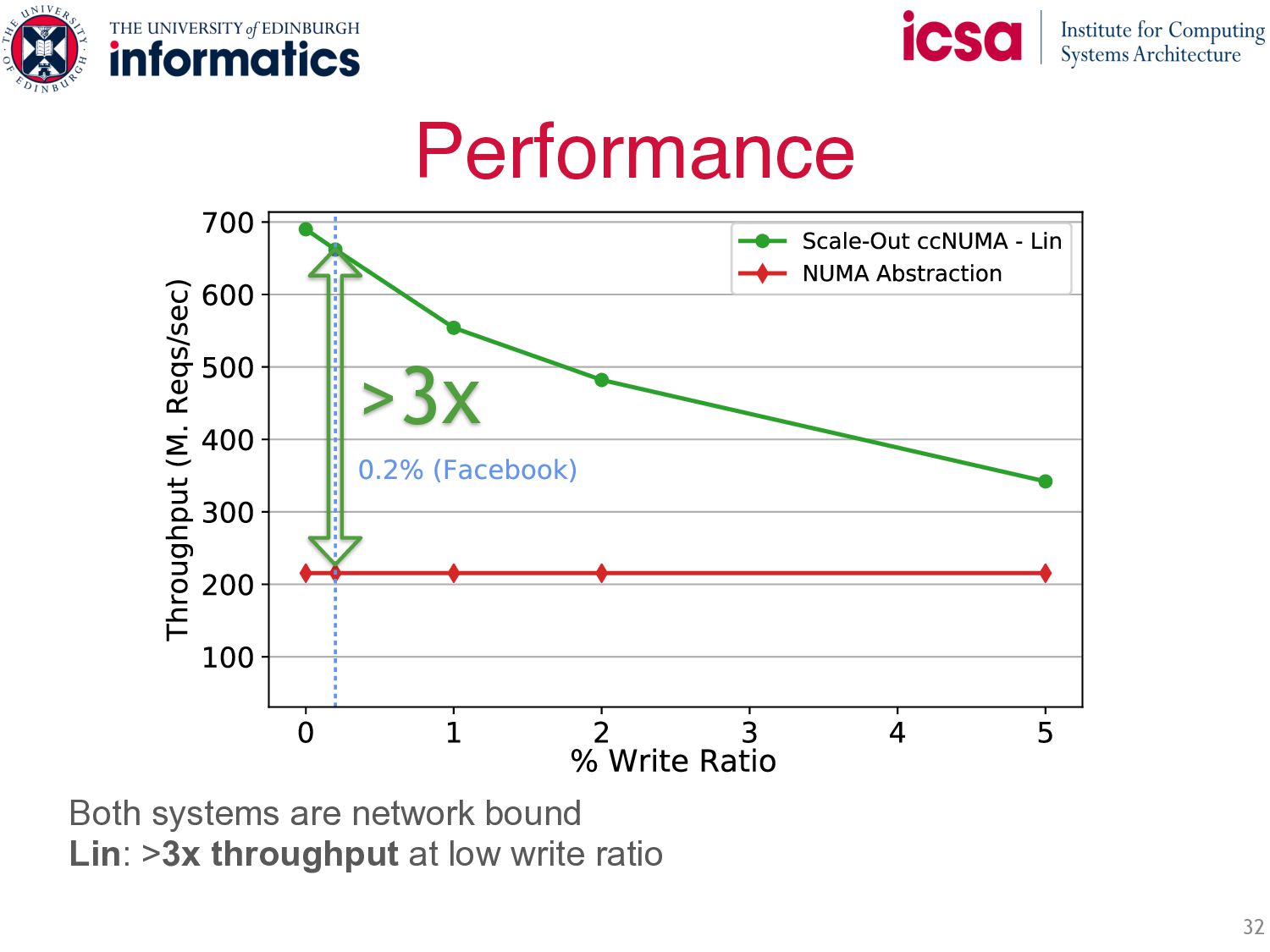
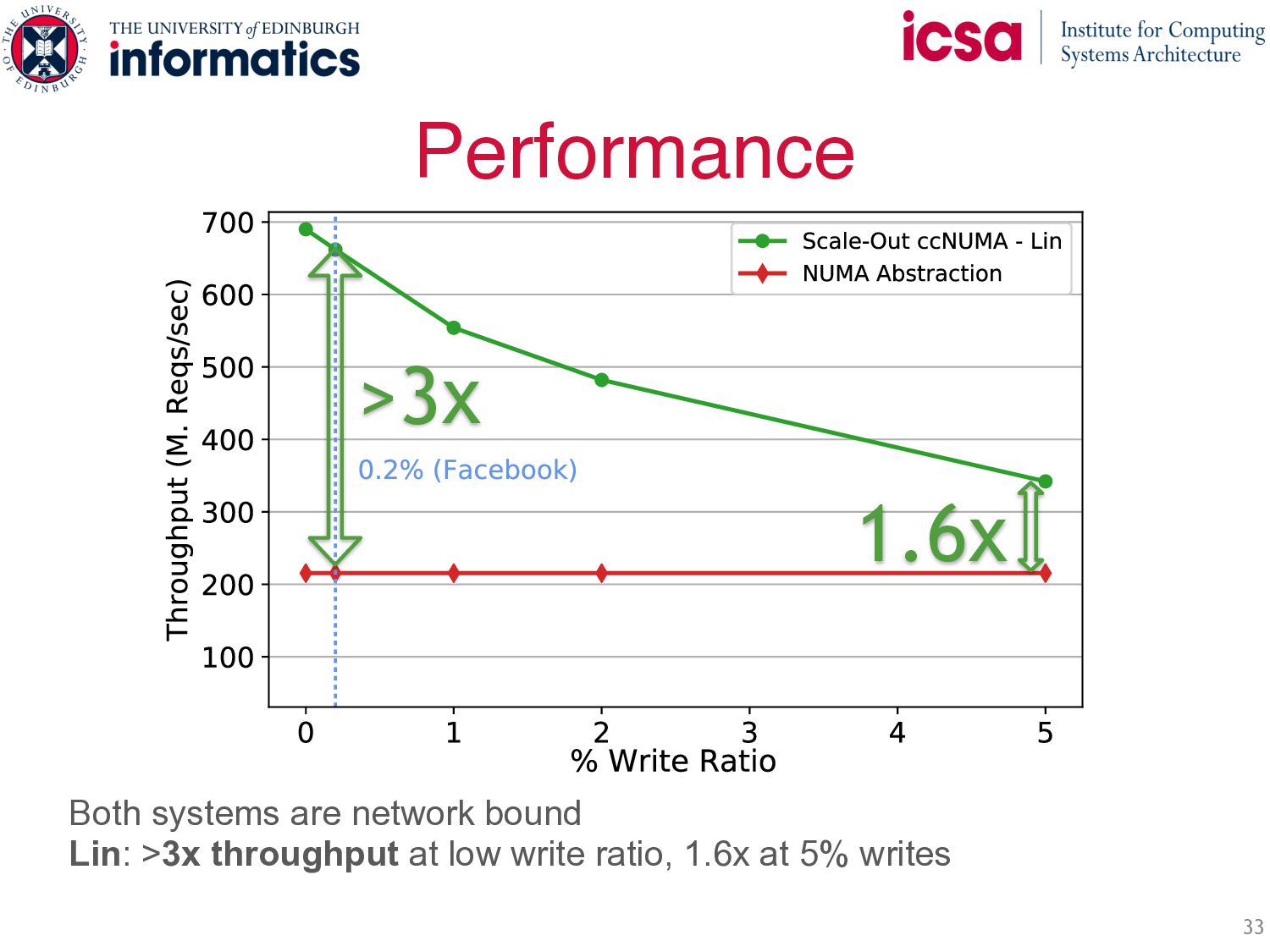
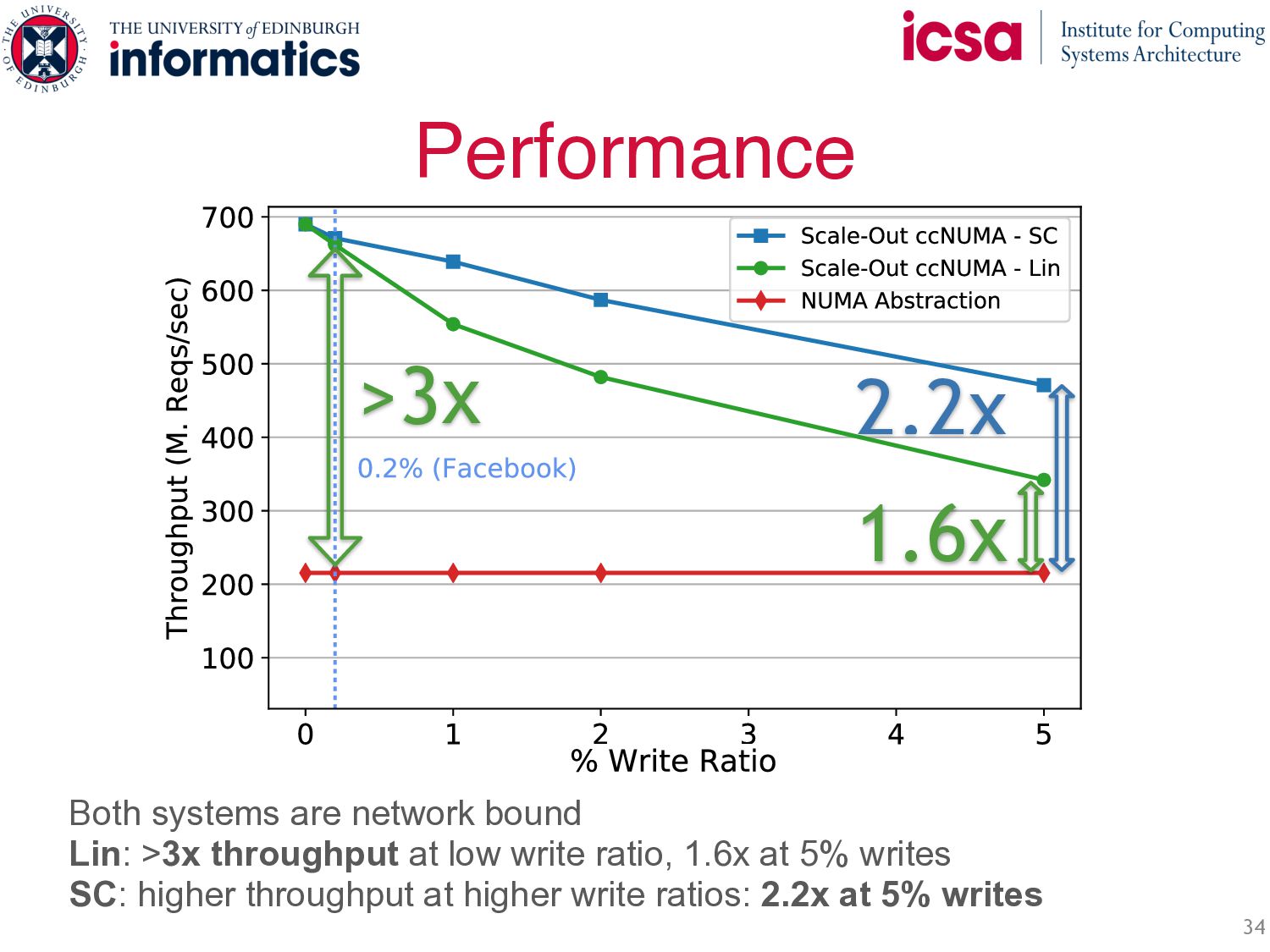
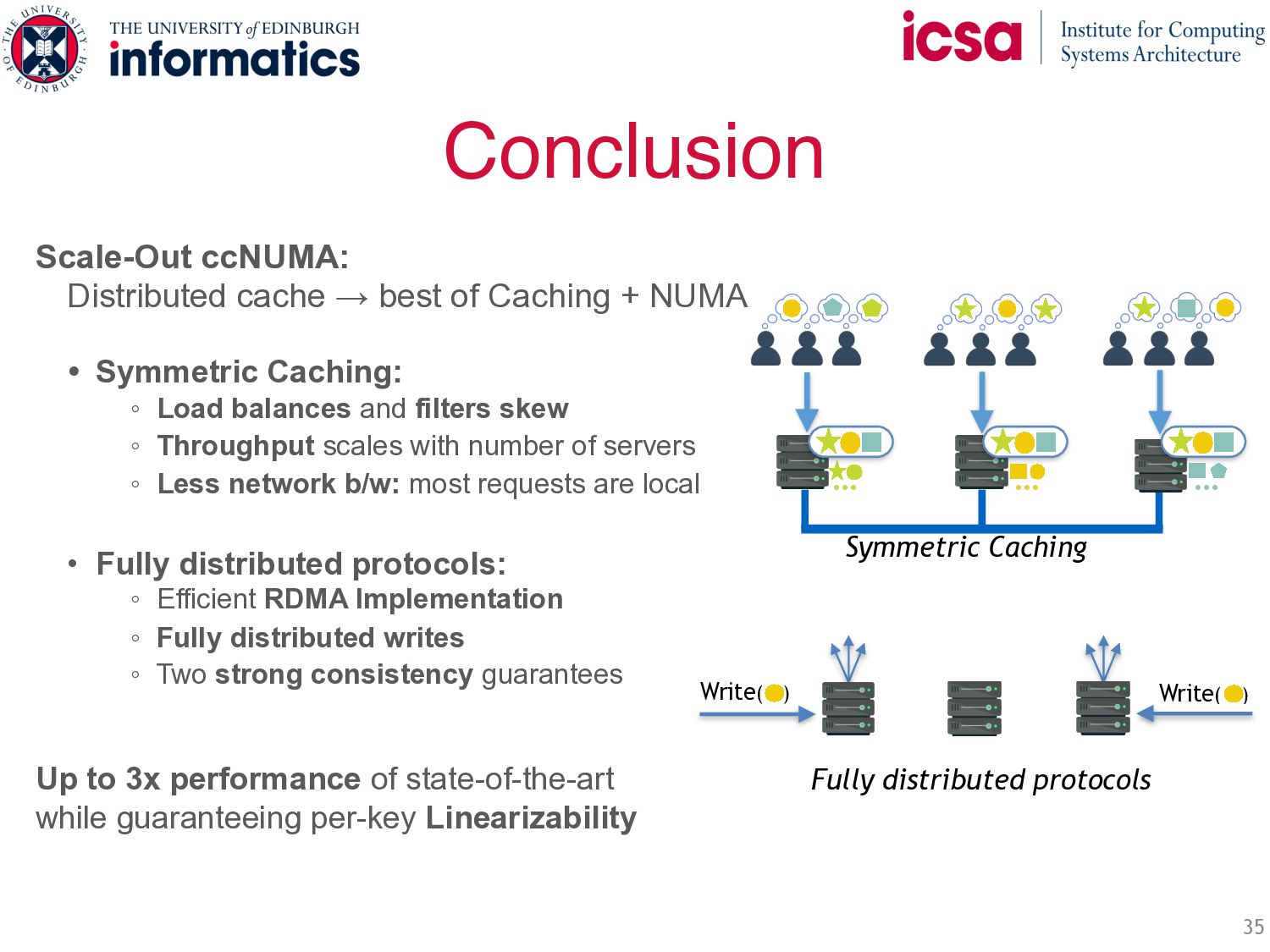
+ NUMA • Symmetric Caching: ◦ Load balances and filters skew ◦ Throughput scales with number of servers ◦ Less network b/w: most requests are local • Fully distributed protocols: ◦ Efficient RDMA Implementation ◦ Fully distributed writes ◦ Two strong consistency guarantees Up to 3x performance of state-of-the-art while guaranteeing per-key Linearizability Symmetric Caching Fully distributed protocols Write( ) Write( ) … … …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Centralized cache [SOCC’11, SOSP’17] • Dedicated node resides in front](https://files.speakerdeck.com/presentations/86a879d73d5646d5a328049f5604fe80/slide_9.jpg){kind=link}
![Centralized cache [SOCC’11, SOSP’17] • Dedicated node resides in front](https://files.speakerdeck.com/presentations/86a879d73d5646d5a328049f5604fe80/slide_10.jpg){kind=link}
![Centralized cache [SOCC’11, SOSP’17] • Dedicated node resides in front](https://files.speakerdeck.com/presentations/86a879d73d5646d5a328049f5604fe80/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}