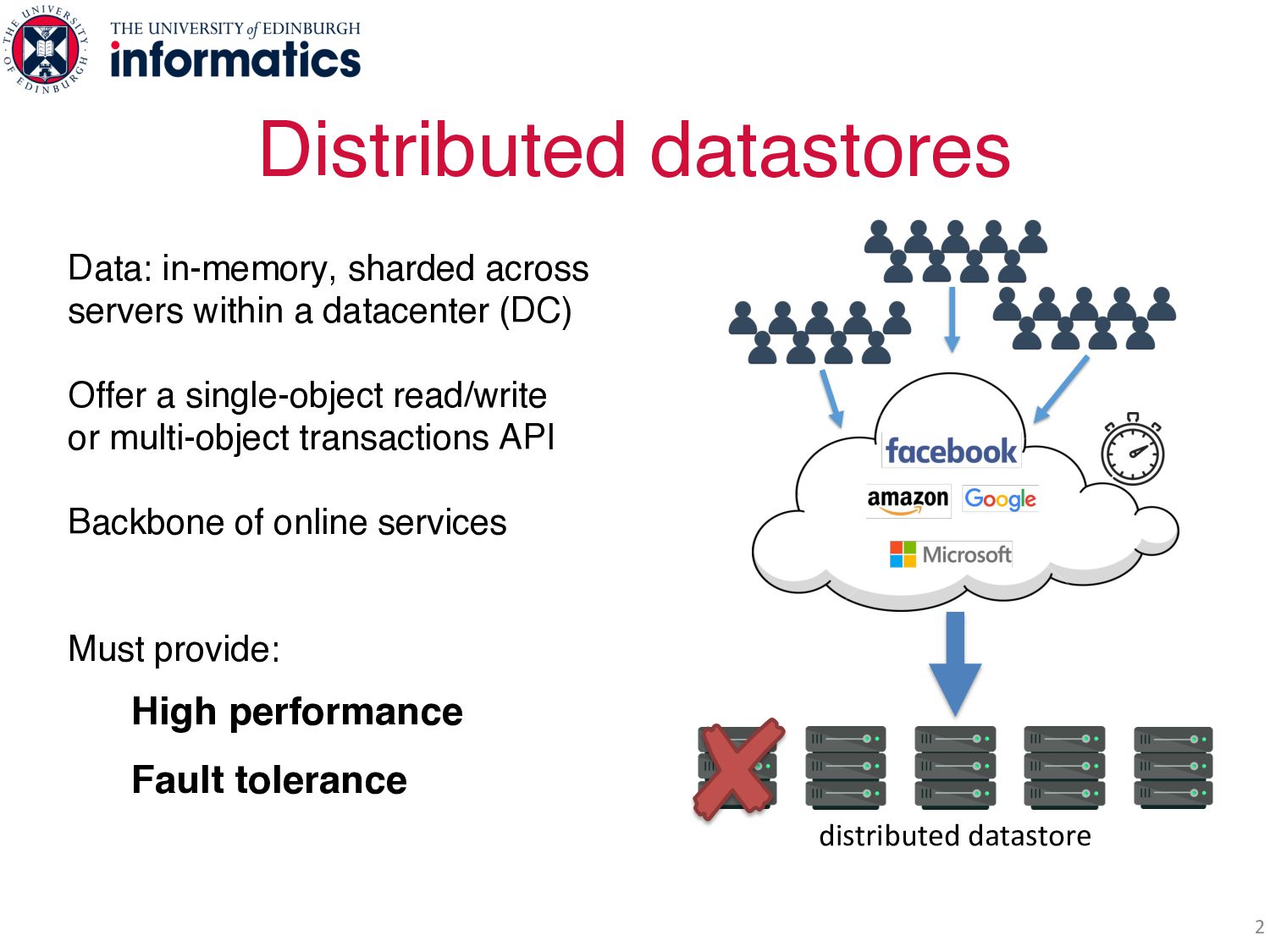
a single-object read/write or multi-object transactions API Backbone of online services and cloud applications Must provide: High performance Fault tolerance Distributed datastores 2 distributed datastore
a single-object read/write or multi-object transactions API Backbone of online services and cloud applications Must provide: High performance Fault tolerance Distributed datastores 2 distributed datastore
a single-object read/write or multi-object transactions API Backbone of online services and cloud applications Must provide: High performance Fault tolerance Distributed datastores 2 distributed datastore Mandate data replication
Fault tolerance data remain available despite failures Typically 3 to 7 replicas Consistency Weak: performance but nasty surprises Strong: intuitive, broadest spectrum of apps Replication protocols - Strong consistency even under faults – if fault tolerant - Define actions to execute reads/writes or transactions (txs) à determine the datastore’s performance Replication 101 3 … … … … replication protocol
Fault tolerance data remain available despite failures Typically 3 to 7 replicas Consistency Weak: performance but nasty surprises Strong: intuitive, broadest spectrum of apps Replication protocols - Strong consistency even under faults – if fault tolerant - Define actions to execute reads/writes or transactions (txs) à determine the datastore’s performance Replication 101 3 … … … … replication protocol
Fault tolerance data remain available despite failures Typically 3 to 7 replicas Consistency Weak: performance but nasty surprises Strong: intuitive, broadest spectrum of apps Replication protocols - Strong consistency even under faults – if fault tolerant - Define actions to execute reads/writes or transactions (txs) à determine the datastore’s performance Replication 101 3 Can strongly consistent protocols offer fault tolerance and high performance? … … … … replication protocol
Performance via Invalidations (low-latency interconnect) - reads/writes: concurrency & speed - txs: fully exploit locality Replication protocols inside a DC - Network: fast, remote direct memory access (RDMA) - Faults are rare within a replica group A server fails at most twice a year fault-free operation >> operation under faults Strongly consistent replication 4 Datastores: replication protocols data replicated across nodes Fault tolerance Performance - reads/writes: sacrifice concurrency or speed - txs: cannot exploit locality Multiprocessor: coherence / HTM data replicated across caches Fault tolerance Performance via Invalidations (low-latency interconnect) - reads/writes: concurrency & speed - txs: fully exploit locality
Performance via Invalidations (low-latency interconnect) - reads/writes: concurrency & speed - txs: fully exploit locality Replication protocols inside a DC - Network: fast, remote direct memory access (RDMA) - Faults are rare within a replica group A server fails at most twice a year fault-free operation >> operation under faults Strongly consistent replication 4 Datastores: replication protocols data replicated across nodes Fault tolerance Performance - reads/writes: sacrifice concurrency or speed - txs: cannot exploit locality Multiprocessor: coherence / HTM data replicated across caches Fault tolerance Performance via Invalidations (low-latency interconnect) - reads/writes: concurrency & speed - txs: fully exploit locality The common operation of replication protocols resembles the multiprocessor!
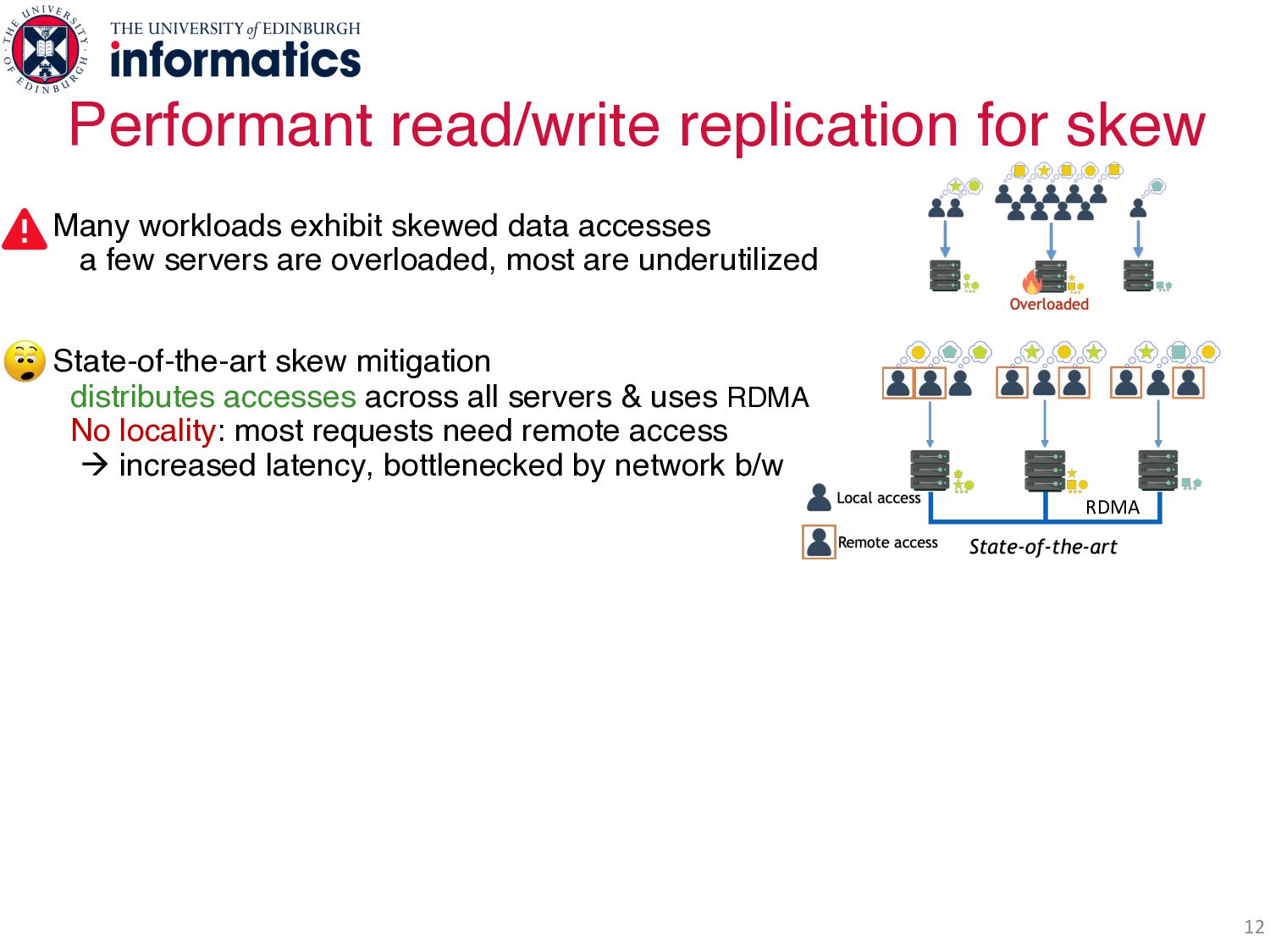
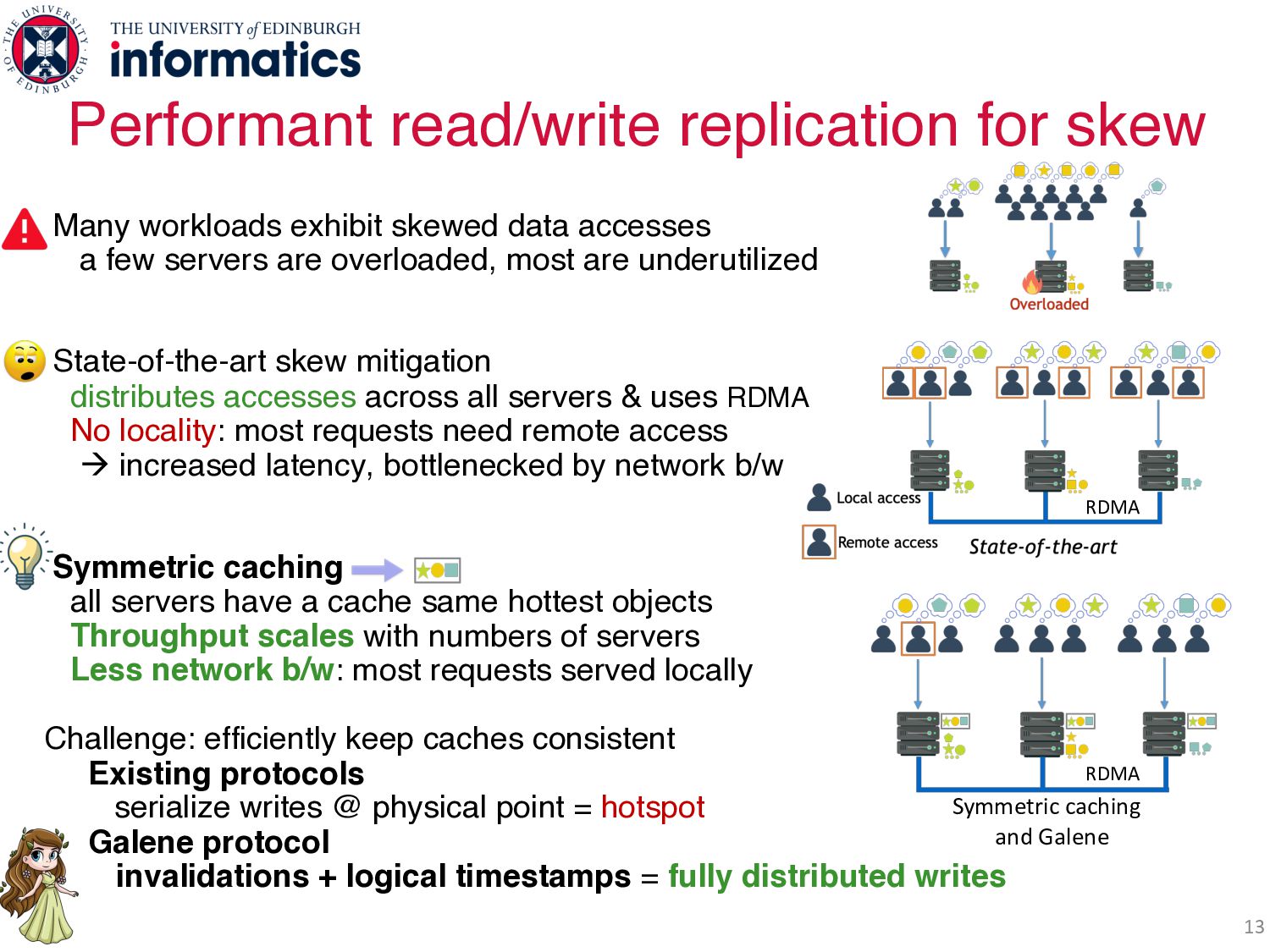
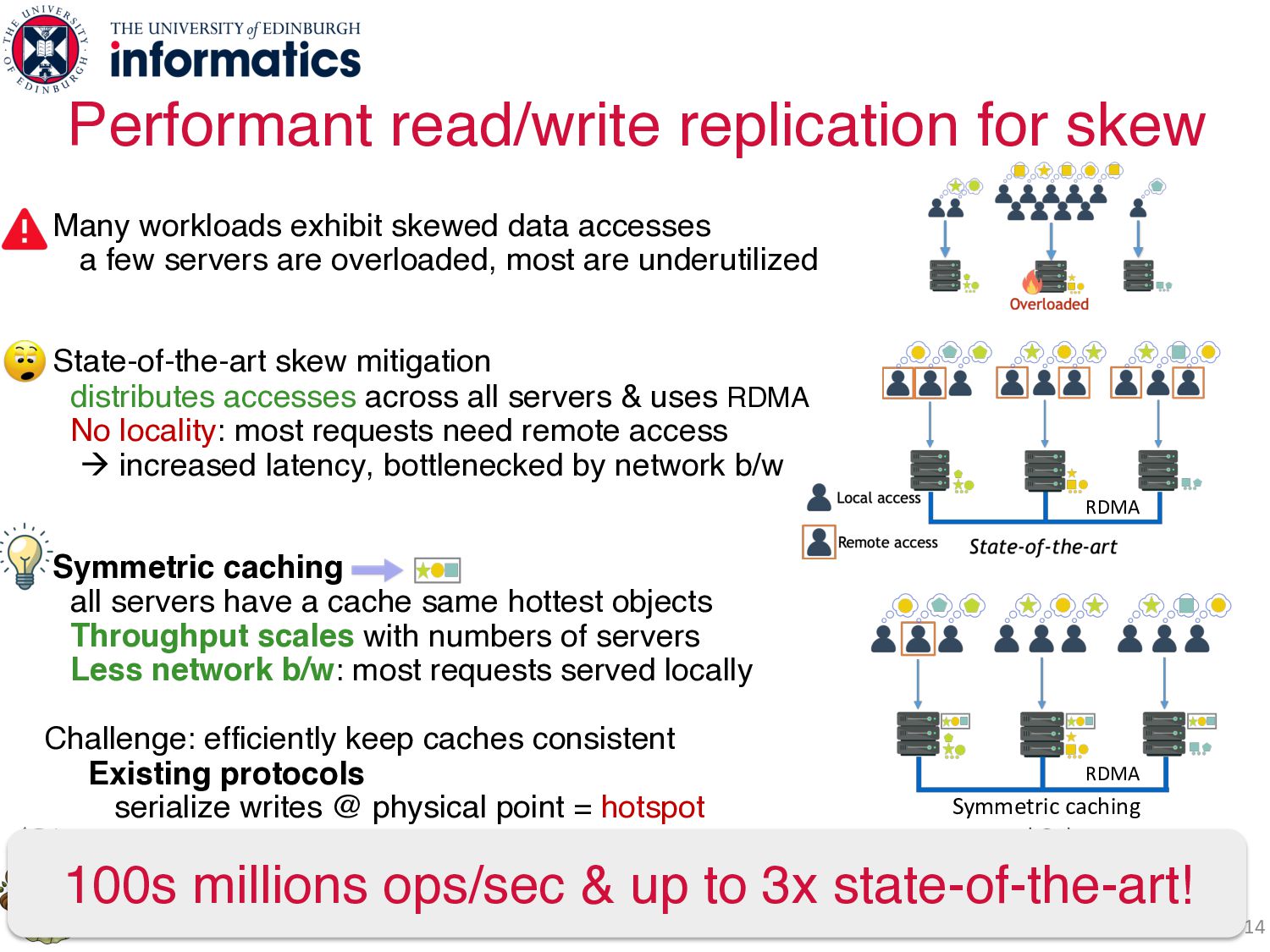
data accesses a few servers are overloaded, most are underutilized State-of-the-art skew mitigation distributes accesses across all servers & uses RDMA No locality: most requests need remote access à increased latency, bottlenecked by network b/w Symmetric caching all servers have a cache same hottest objects Throughput scales with numbers of servers Less network b/w: most requests served locally Challenge: efficiently keep caches consistent Existing protocols serialize writes @ physical point = hotspot Galene protocol invalidations + logical timestamps = fully distributed writes RDMA
data accesses a few servers are overloaded, most are underutilized State-of-the-art skew mitigation distributes accesses across all servers & uses RDMA No locality: most requests need remote access à increased latency, bottlenecked by network b/w Symmetric caching all servers have a cache same hottest objects Throughput scales with numbers of servers Less network b/w: most requests served locally Challenge: efficiently keep caches consistent Existing protocols serialize writes @ physical point = hotspot Galene protocol invalidations + logical timestamps = fully distributed writes RDMA RDMA Symmetric caching and Galene
data accesses a few servers are overloaded, most are underutilized State-of-the-art skew mitigation distributes accesses across all servers & uses RDMA No locality: most requests need remote access à increased latency, bottlenecked by network b/w Symmetric caching all servers have a cache same hottest objects Throughput scales with numbers of servers Less network b/w: most requests served locally Challenge: efficiently keep caches consistent Existing protocols serialize writes @ physical point = hotspot Galene protocol invalidations + logical timestamps = fully distributed writes RDMA RDMA Symmetric caching and Galene 100s millions ops/sec & up to 3x state-of-the-art!
under skew can maintain high read/write performance while providing fault tolerance? reliable = strongly consistent + fault tolerant 2nd primary contribution: Hermes! What is the issue of existing reliable protocols?
à inter-replica communication writes à multiple RTTs over the network Common-case performance (i.e., no faults) as bad as worst-case (under faults) 17 Paxos
à inter-replica communication writes à multiple RTTs over the network Common-case performance (i.e., no faults) as bad as worst-case (under faults) 18 Paxos State-of-the-art replication protocols exploit failure-free operation for performance
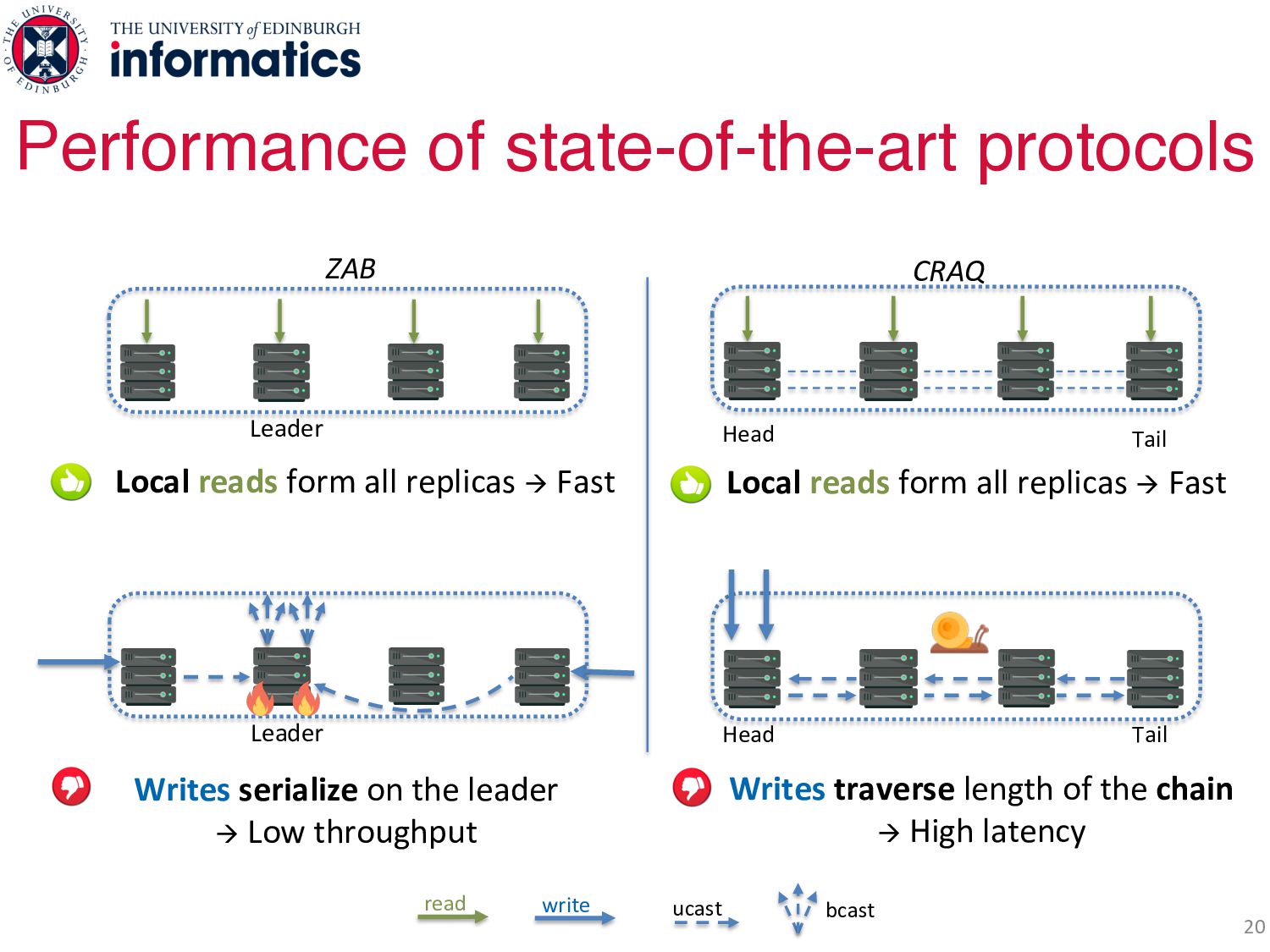
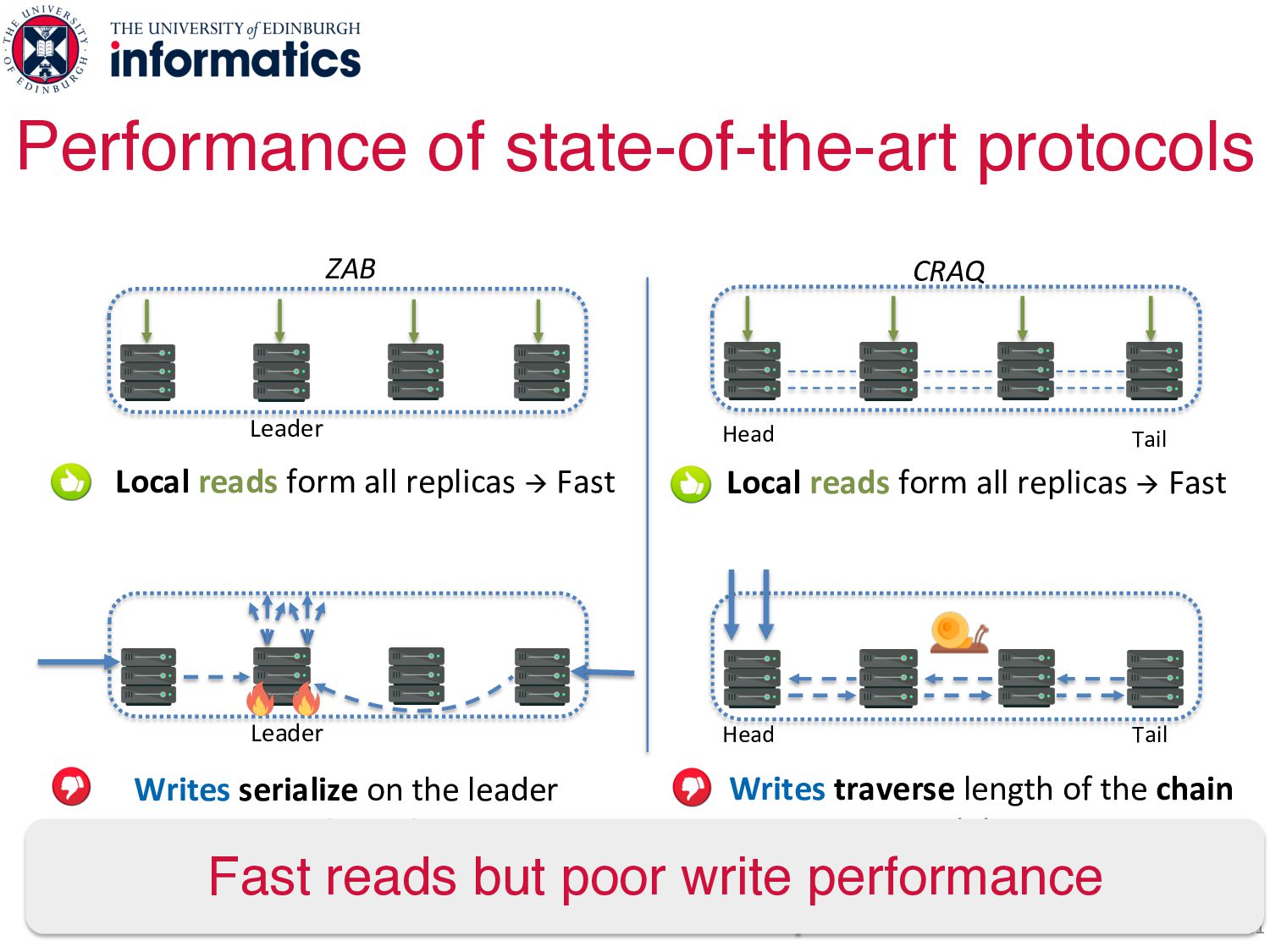
on the leader à Low throughput Head Tail CRAQ Head Tail Writes traverse length of the chain à High latency write read bcast ucast Local reads form all replicas à Fast Local reads form all replicas à Fast
on the leader à Low throughput Head Tail CRAQ Head Tail Writes traverse length of the chain à High latency write read bcast ucast Fast reads but poor write performance Local reads form all replicas à Fast Local reads form all replicas à Fast
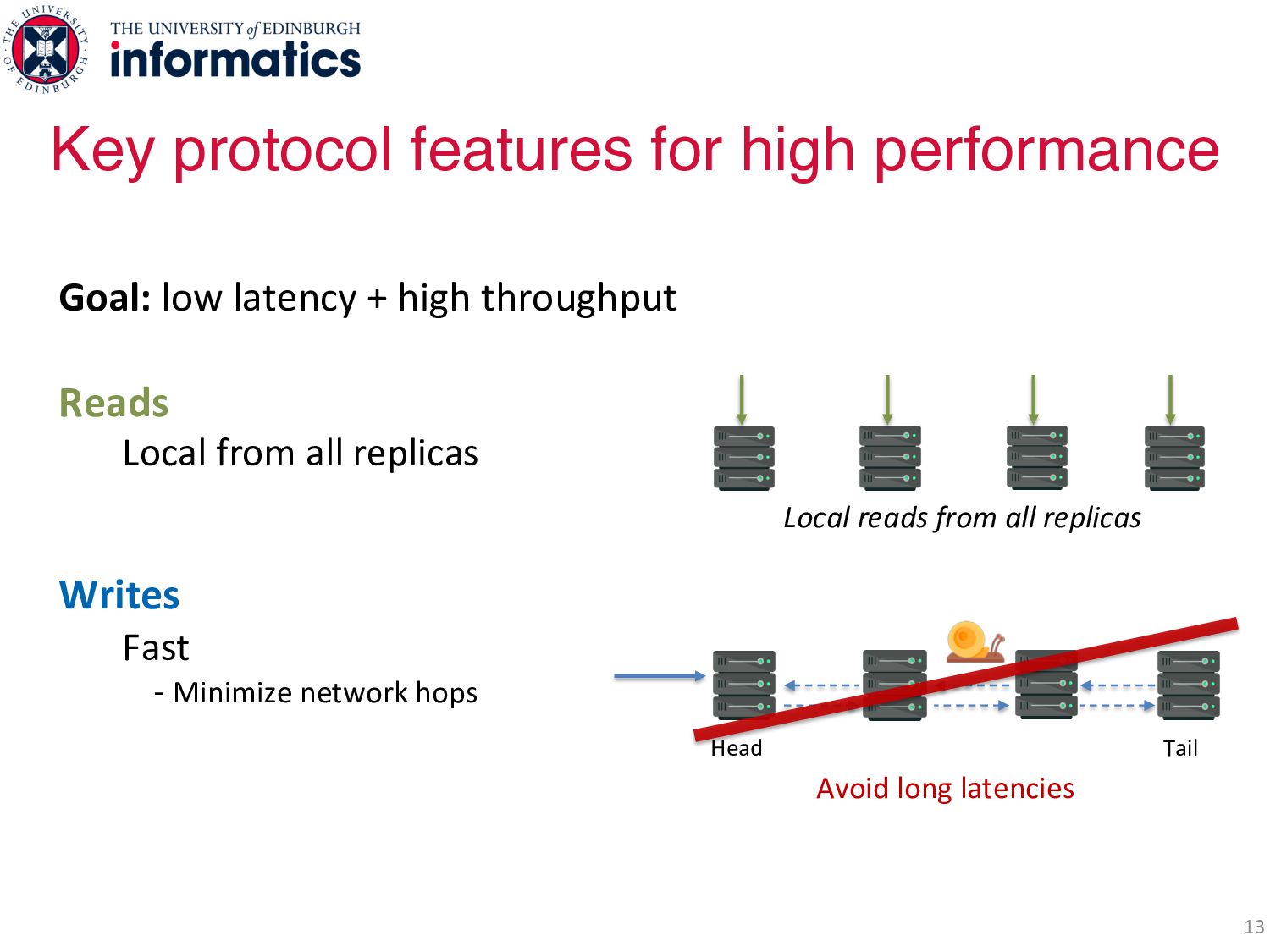
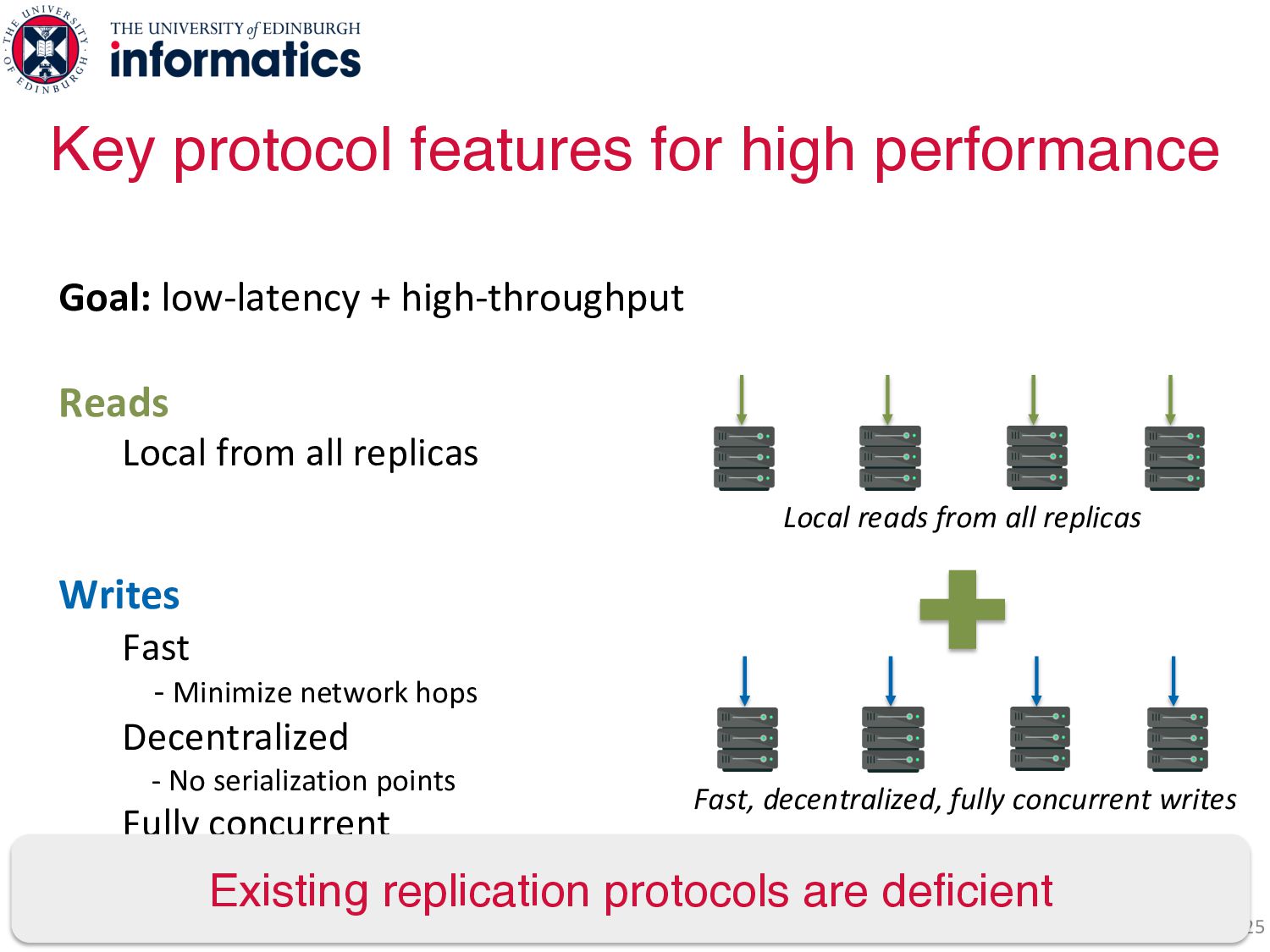
all replicas Writes Fast - Minimize network hops Decentralized - No serialization points Fully concurrent - Any replica can service a write Key protocol features for high performance Local reads from all replicas Head Tail Avoid long latencies
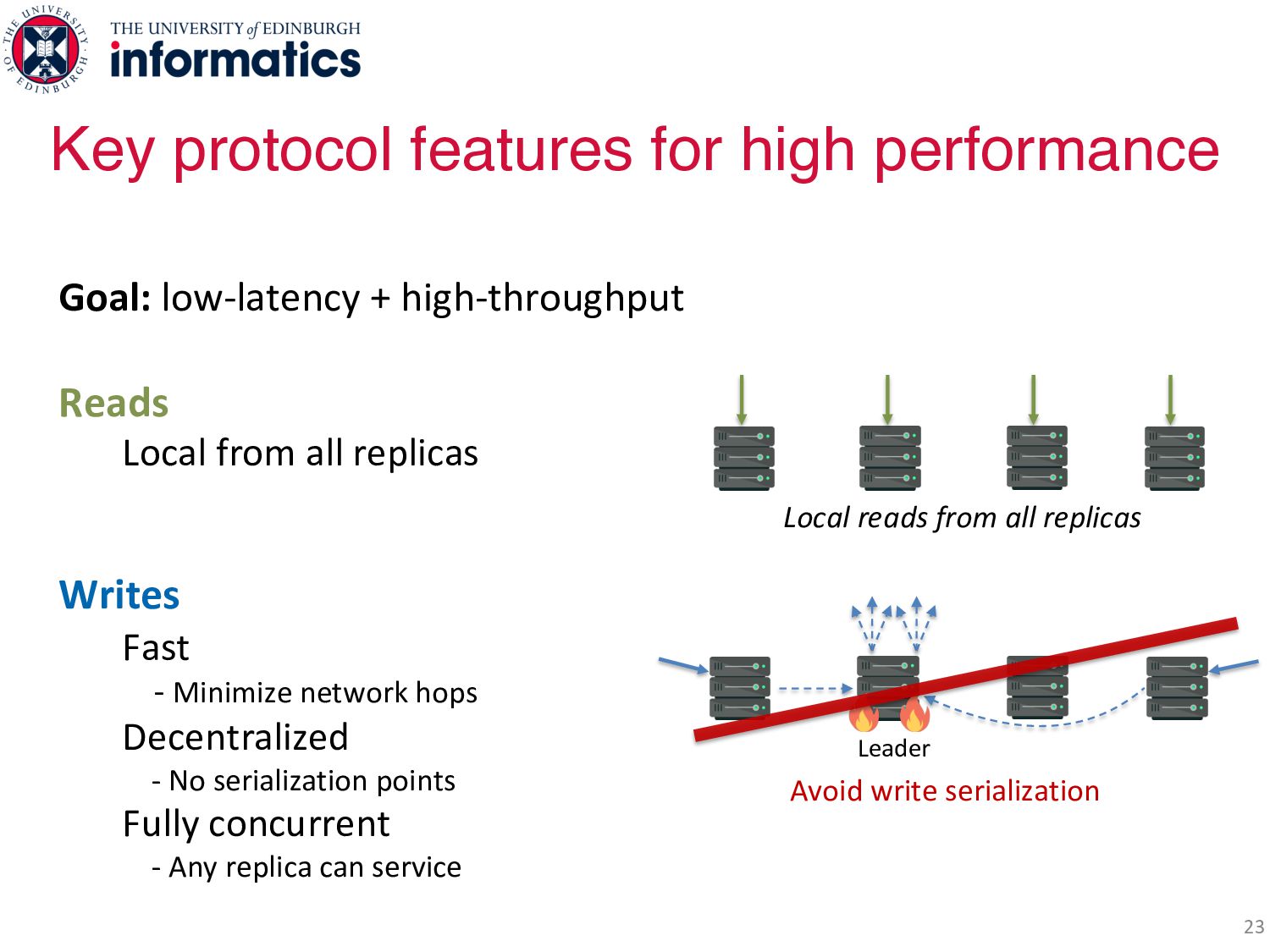
Writes Fast - Minimize network hops Decentralized - No serialization points Fully concurrent - Any replica can service Leader Avoid write serialization Key protocol features for high performance Local reads from all replicas
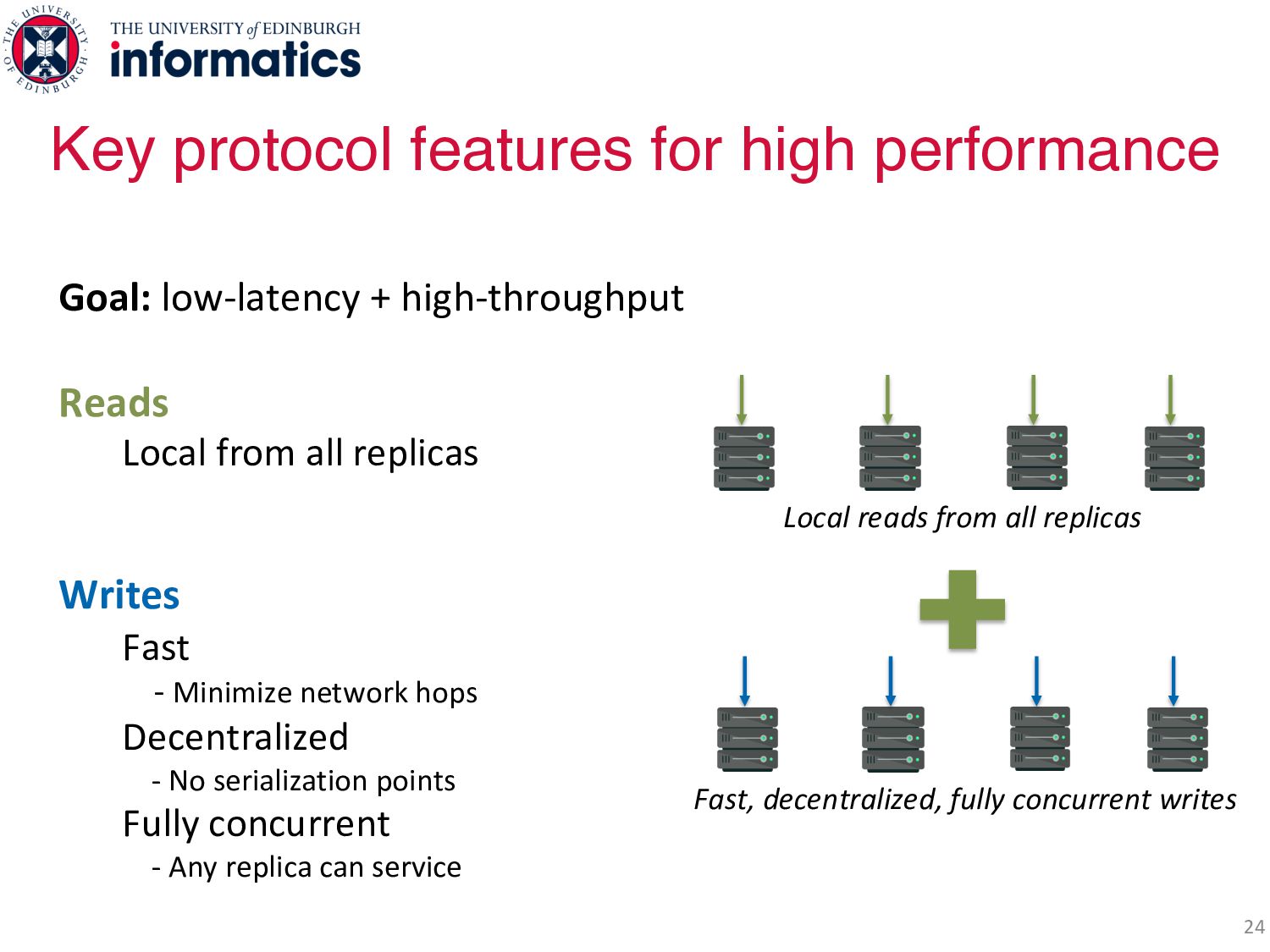
Writes Fast - Minimize network hops Decentralized - No serialization points Fully concurrent - Any replica can service a write Key protocol features for high performance Local reads from all replicas Fast, decentralized, fully concurrent writes
Writes Fast - Minimize network hops Decentralized - No serialization points Fully concurrent - Any replica can service a write Key protocol features for high performance Local reads from all replicas Fast, decentralized, fully concurrent writes Existing replication protocols are deficient
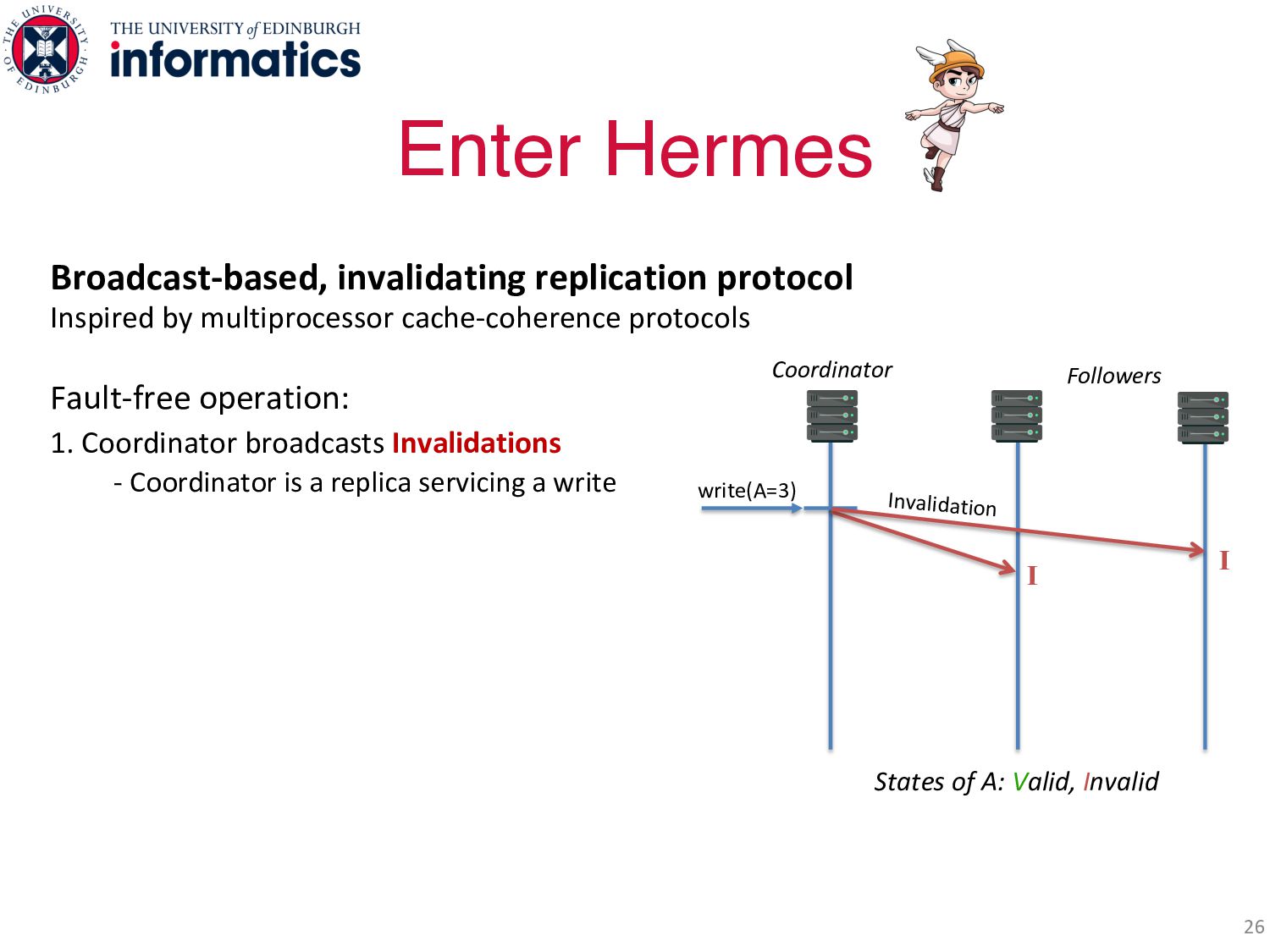
operation: 1. Coordinator broadcasts Invalidations - Coordinator is a replica servicing a write Enter Hermes 26 States of A: Valid, Invalid write(A=3) Coordinator Followers I Invalidation I
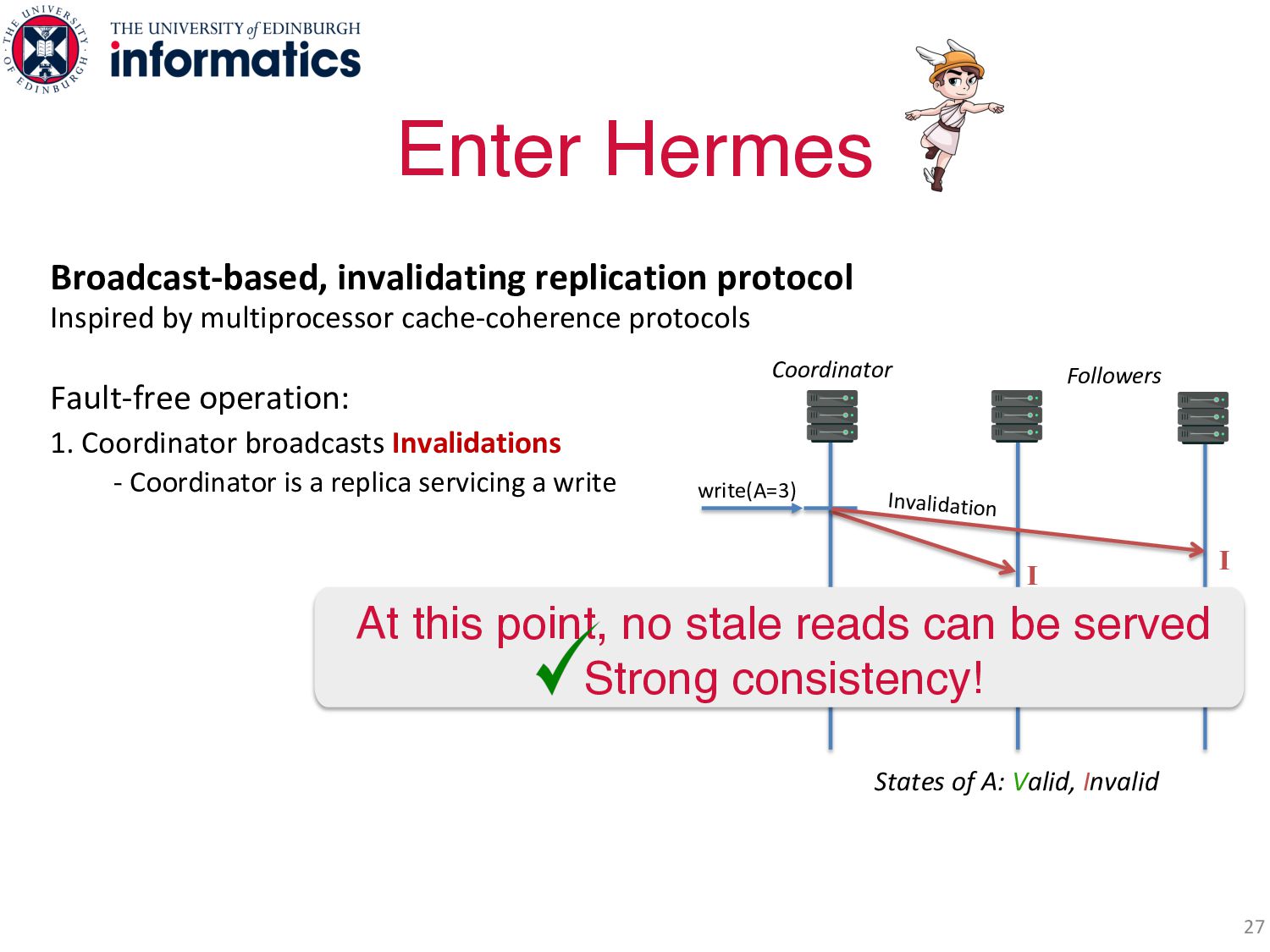
operation: 1. Coordinator broadcasts Invalidations - Coordinator is a replica servicing a write Enter Hermes 27 States of A: Valid, Invalid write(A=3) Coordinator Followers At this point, no stale reads can be served Strong consistency! I Invalidation I
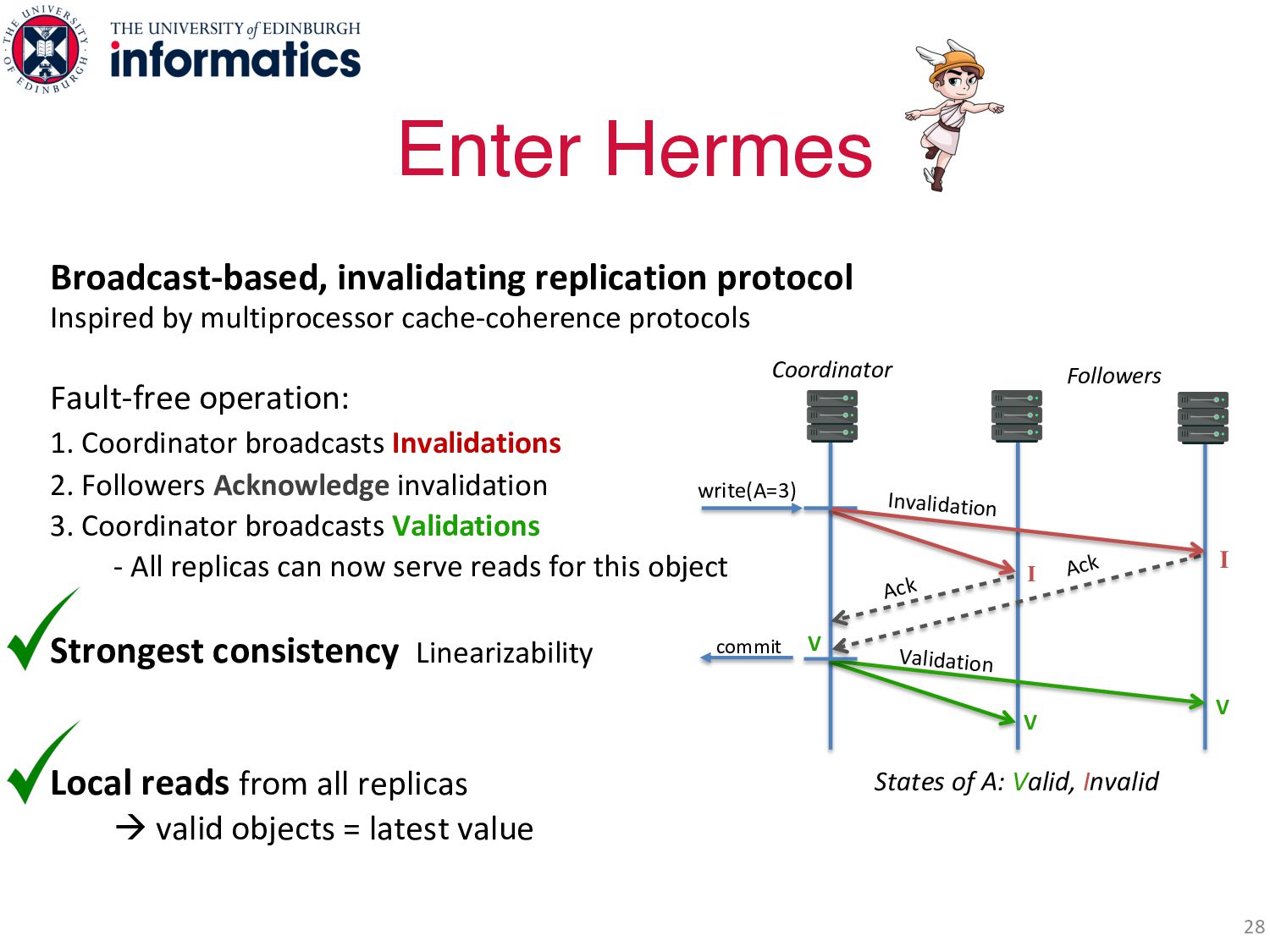
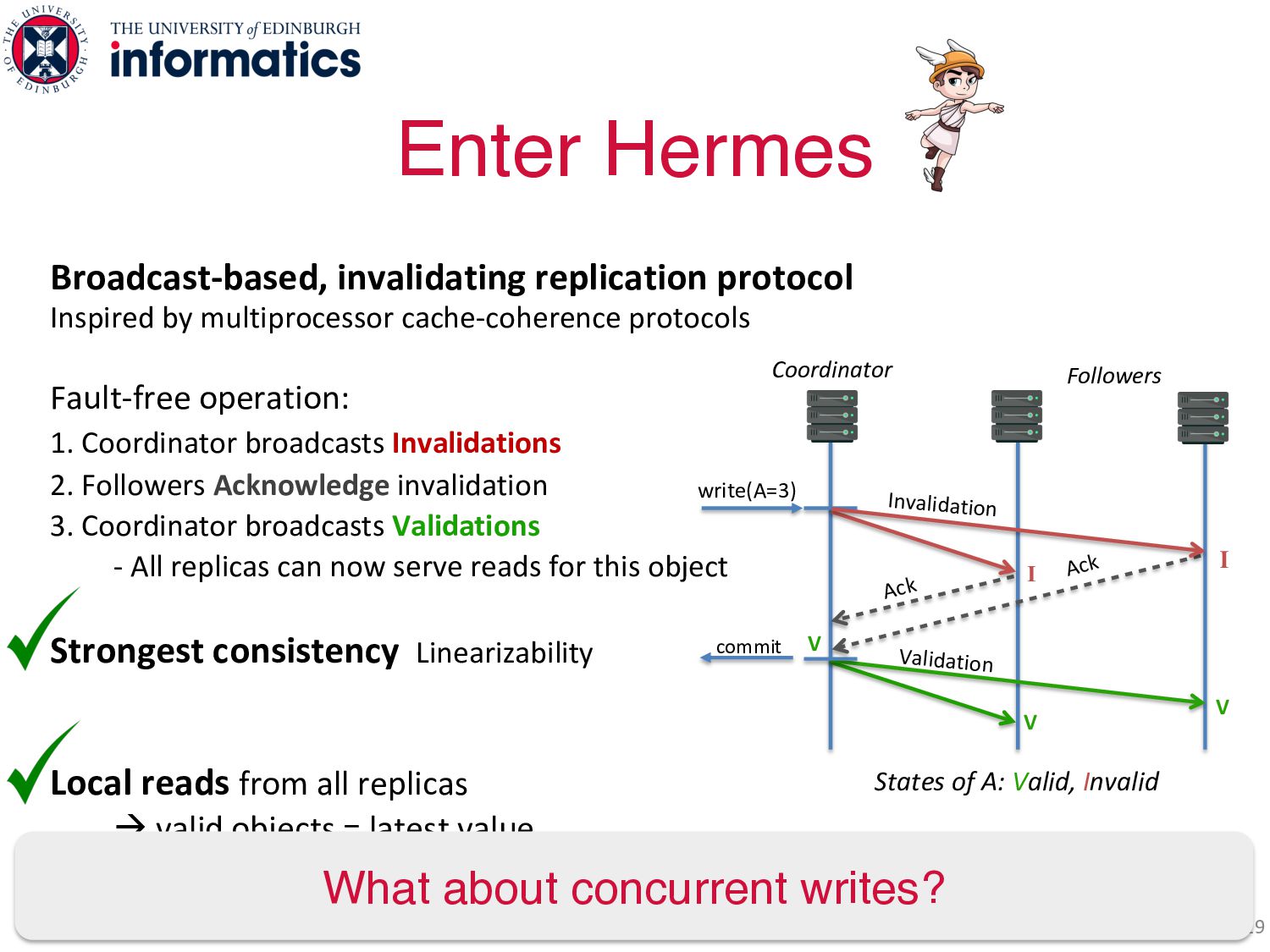
operation: 1. Coordinator broadcasts Invalidations 2. Followers Acknowledge invalidation 3. Coordinator broadcasts Validations - All replicas can now serve reads for this object Strongest consistency Linearizability Local reads from all replicas à valid objects = latest value Enter Hermes 28 States of A: Valid, Invalid write(A=3) Coordinator Followers V Validation V Ack Ack I Invalidation I V commit
operation: 1. Coordinator broadcasts Invalidations 2. Followers Acknowledge invalidation 3. Coordinator broadcasts Validations - All replicas can now serve reads for this object Strongest consistency Linearizability Local reads from all replicas à valid objects = latest value Enter Hermes 29 States of A: Valid, Invalid write(A=3) Coordinator Followers What about concurrent writes? V Validation V Ack Ack I Invalidation I V commit
Solution Store a logical timestamp (TS) along with each object - Upon a write: coordinator increments TS and sends it with Invalidations - Upon receiving Invalidation: a follower updates the object’s TS - When two writes to the same object race: use node ID to order them Concurrent writes = challenge 30 write(A=3) write(A=1) Inv(TS1) Inv(TS4)
Solution Store a logical timestamp (TS) along with each object - Upon a write: coordinator increments TS and sends it with Invalidations - Upon receiving Invalidation: a follower updates the object’s TS - When two writes to the same object race: use node ID to order them Concurrent writes = challenge 31 write(A=3) write(A=1) Inv(TS1) Inv(TS4) Broadcast + Invalidations + TS à high performance writes
concurrent Any replica can coordinate a write Writes to different objects proceed in parallel 3. Fast Commit in 1 RTT Never abort Writes in Hermes 32 Broadcast + Invalidations + TS
concurrent Any replica can coordinate a write Writes to different objects proceed in parallel 3. Fast Commit in 1 RTT Never abort Writes in Hermes 33 Awesome! But what about fault tolerance? Broadcast + Invalidations + TS
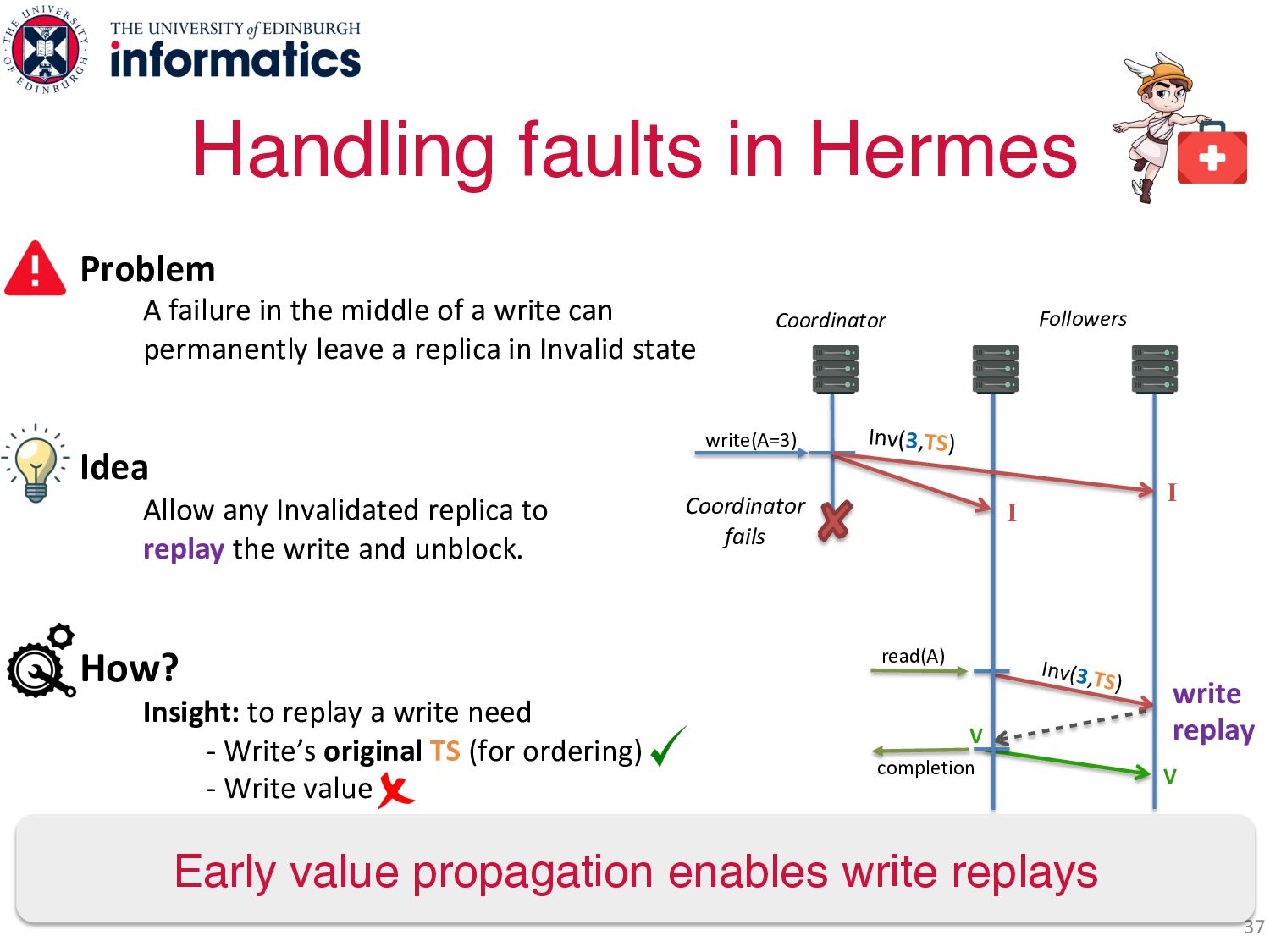
permanently leave a replica in Invalid state Idea Allow any Invalidated replica to replay the write and unblock. How? Insight: to replay a write need - Write’s original TS (for ordering) - Write value TS sent with Invalidation, but write value is not Solution: send write value with Invalidation à Early value propagation write(A=3) Coordinator Followers 34 Handling faults in Hermes read(A) Inv(TS) Coordinator fails I I
permanently leave a replica in Invalid state Idea Allow any Invalidated replica to replay the write and unblock. How? Insight: to replay a write need - Write’s original TS (for ordering) - Write value TS sent with Invalidation, but write value is not Solution: send write value with Invalidation à early value propagation Handling faults in Hermes 35 Inv(3,TS) write(A=3) read(A) Coordinator fails I I Coordinator Followers
permanently leave a replica in Invalid state Idea Allow any Invalidated replica to replay the write and unblock. How? Insight: to replay a write need - Write’s original TS (for ordering) - Write value TS sent with Invalidation, but write value is not Solution: send write value with Invalidation à early value propagation V V Inv(3,TS) completion write replay read(A) Handling faults in Hermes 36 Inv(3,TS) write(A=3) Coordinator fails I I Coordinator Followers
permanently leave a replica in Invalid state Idea Allow any Invalidated replica to replay the write and unblock. How? Insight: to replay a write need - Write’s original TS (for ordering) - Write value TS sent with Invalidation, but write value is not Solution: send write value with Invalidation à early value propagation V V Inv(3,TS) completion write replay read(A) Handling faults in Hermes 37 Inv(3,TS) write(A=3) Early value propagation enables write replays Coordinator fails I I Coordinator Followers
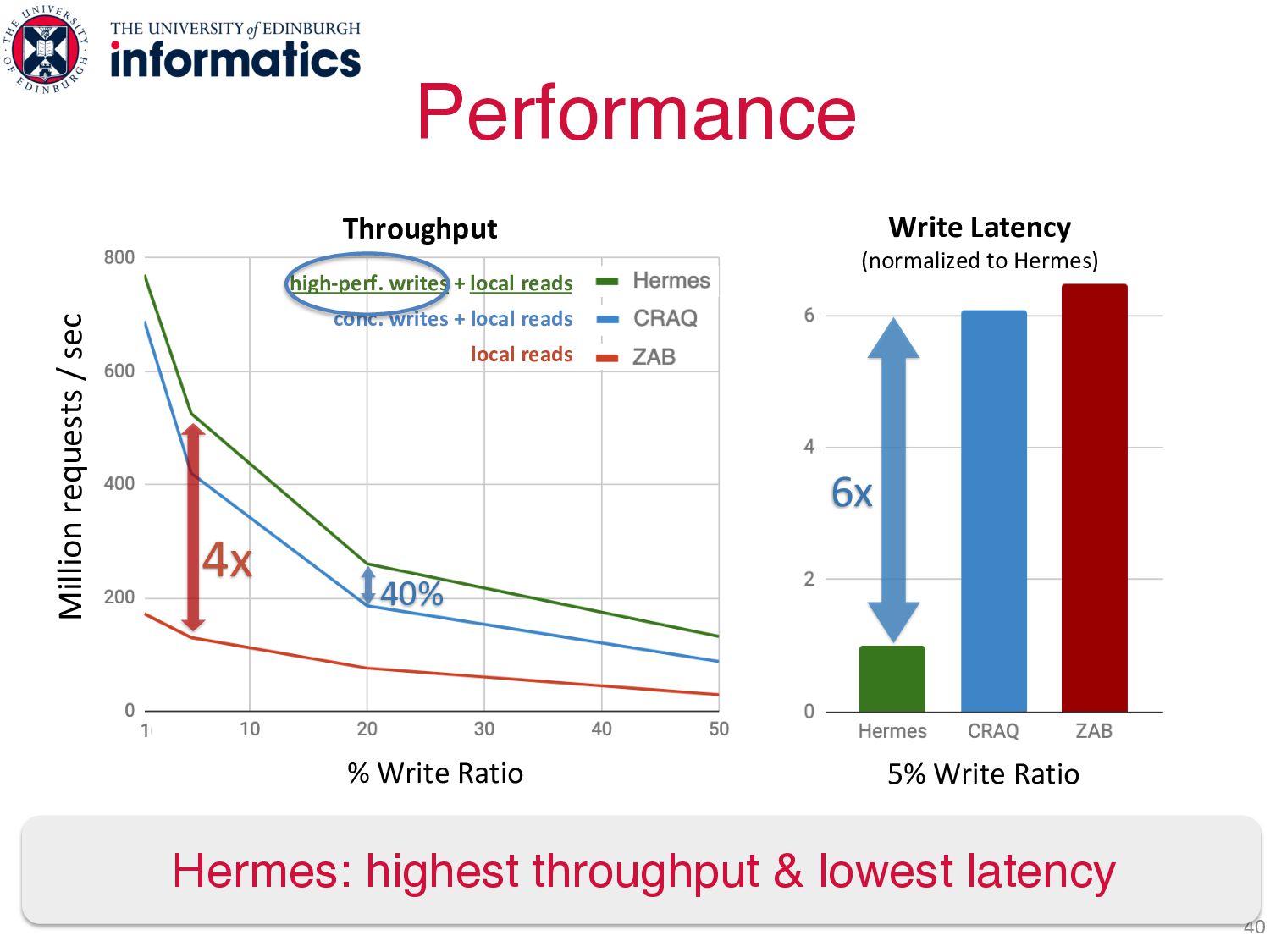
+ local reads local reads 4x 40% 5% Write Ratio Write Latency (normalized to Hermes) Million requests / sec Write performance matters even at low write ratios 6x % Write Ratio
+ local reads local reads 4x 40% 5% Write Ratio Write Latency (normalized to Hermes) Million requests / sec Write performance matters even at low write ratios 6x Hermes: highest throughput & lowest latency % Write Ratio
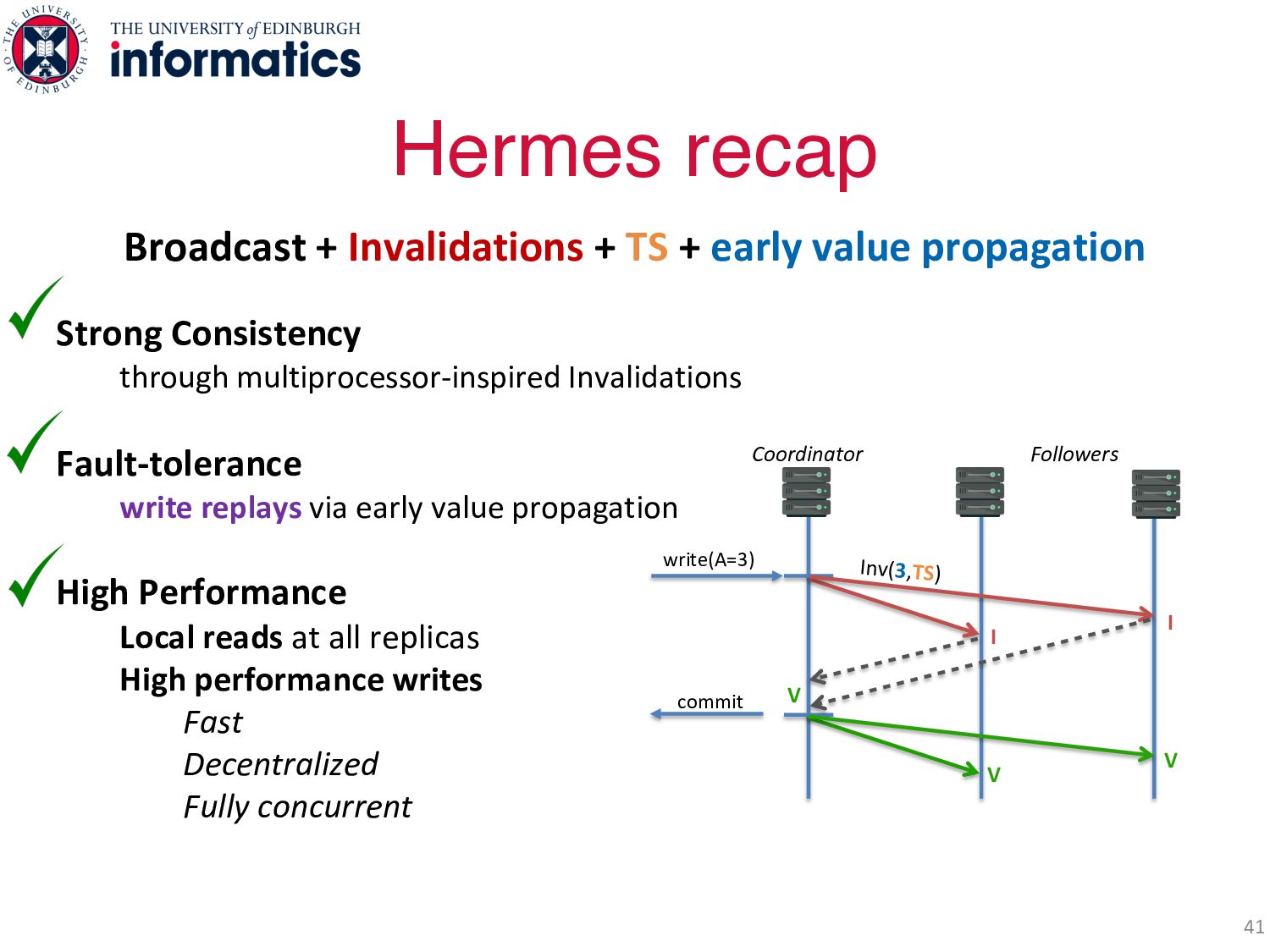
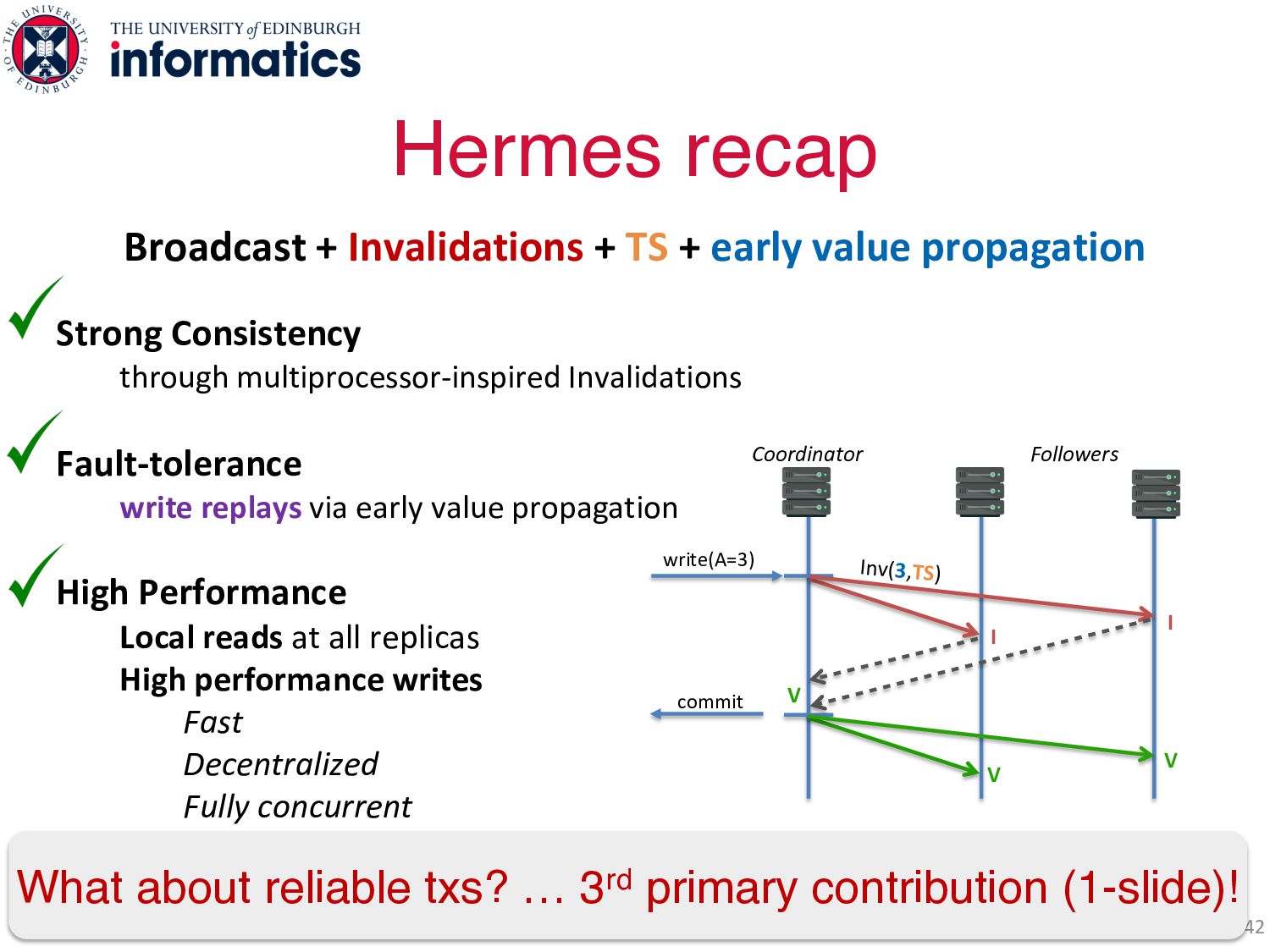
value propagation High Performance Local reads at all replicas High performance writes Fast Decentralized Fully concurrent Hermes recap 41 V I write(A=3) commit Coordinator Followers Inv(3,TS) V I V Broadcast + Invalidations + TS + early value propagation
value propagation High Performance Local reads at all replicas High performance writes Fast Decentralized Fully concurrent Hermes recap 42 V I write(A=3) commit Coordinator Followers Inv(3,TS) V I V Broadcast + Invalidations + TS + early value propagation What about reliable txs? … 3rd primary contribution (1-slide)!
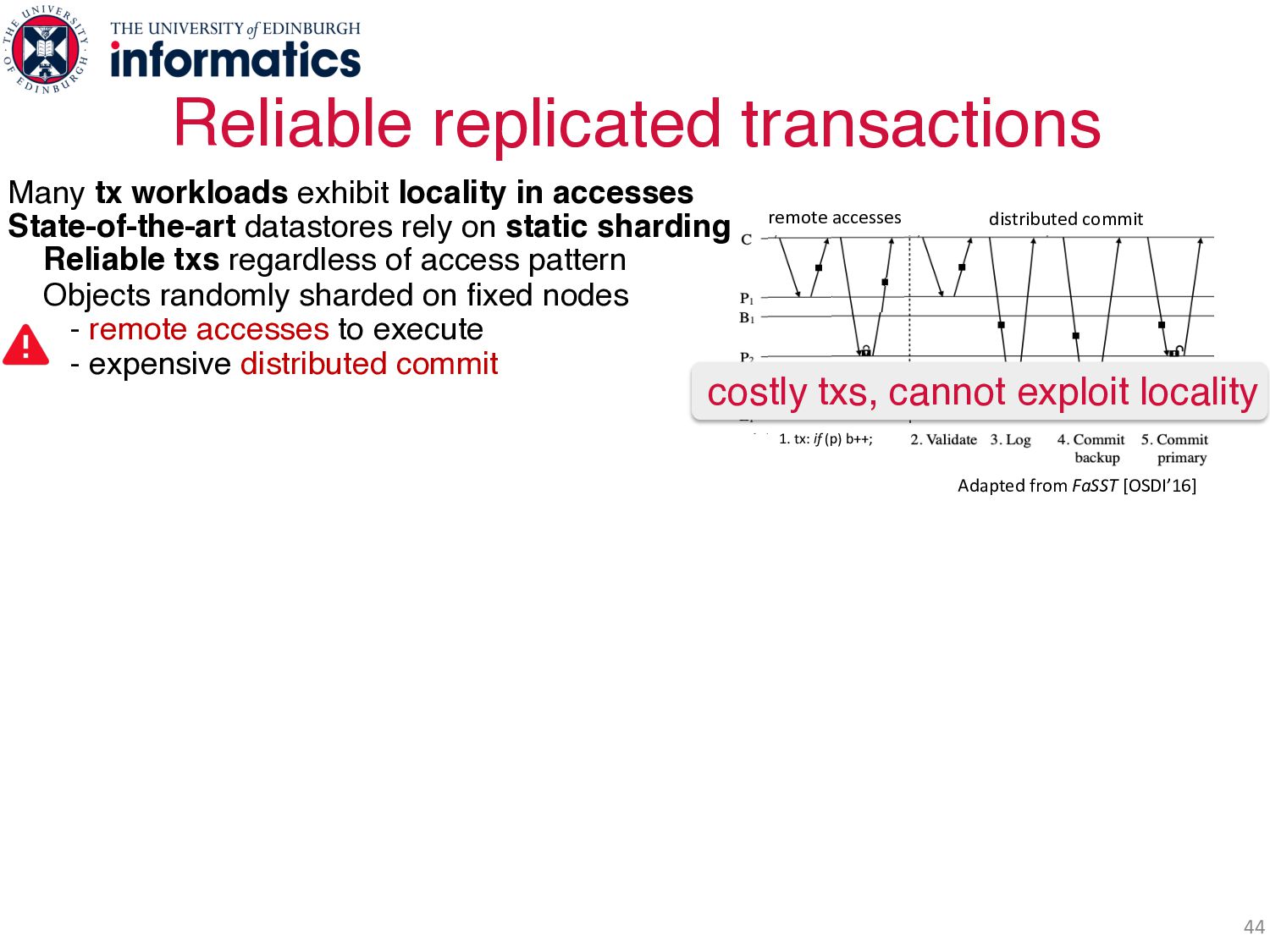
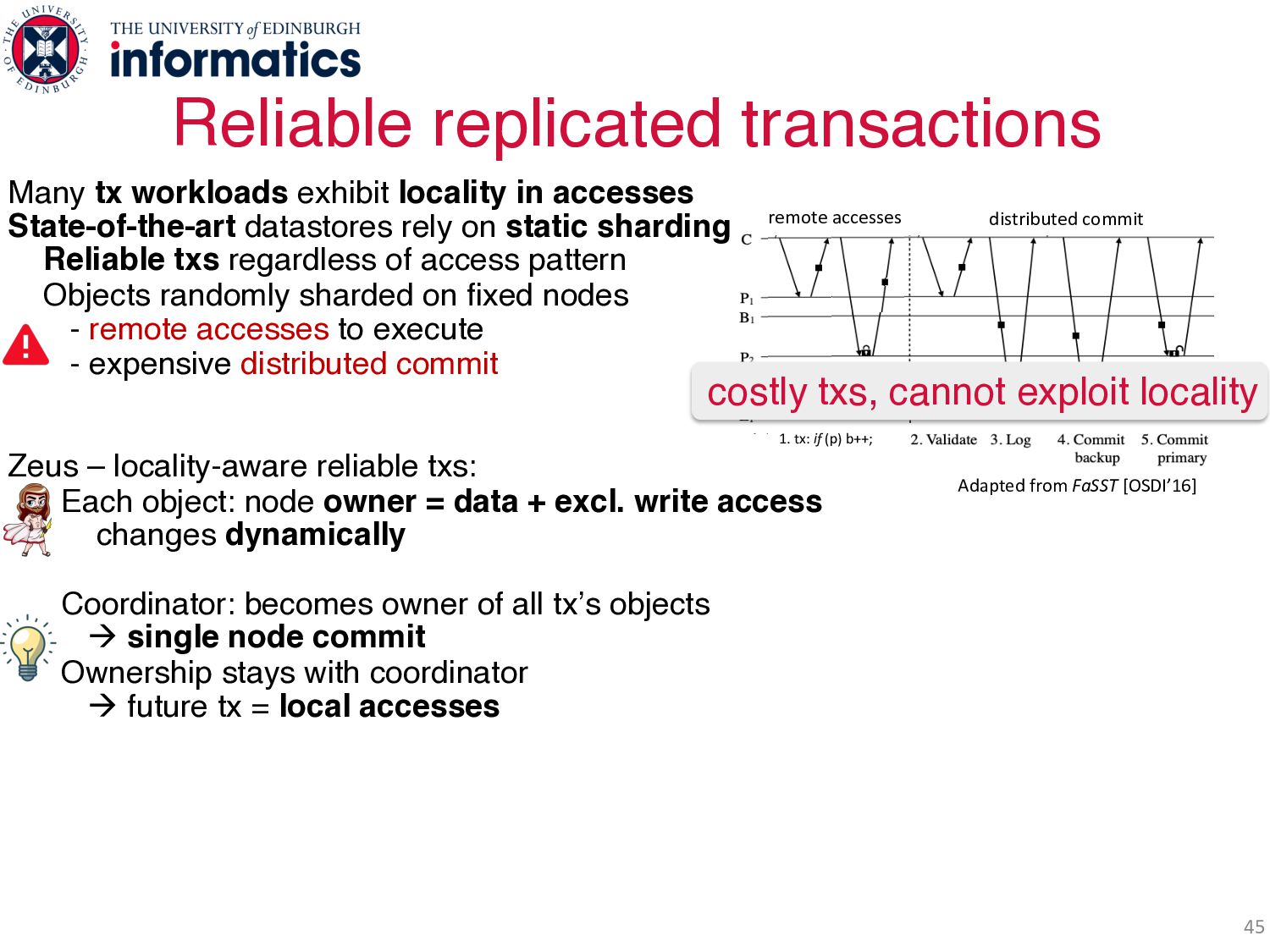
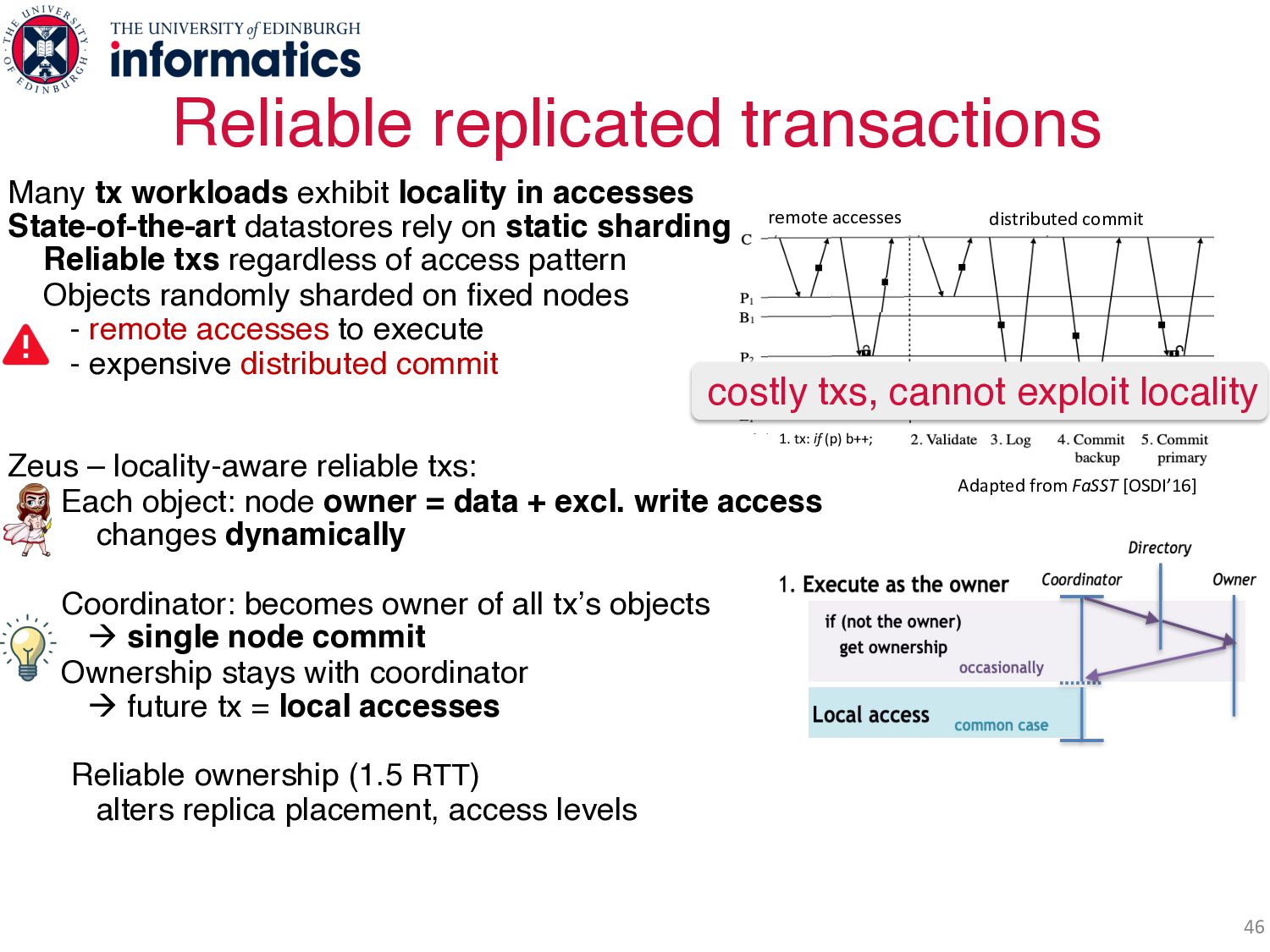
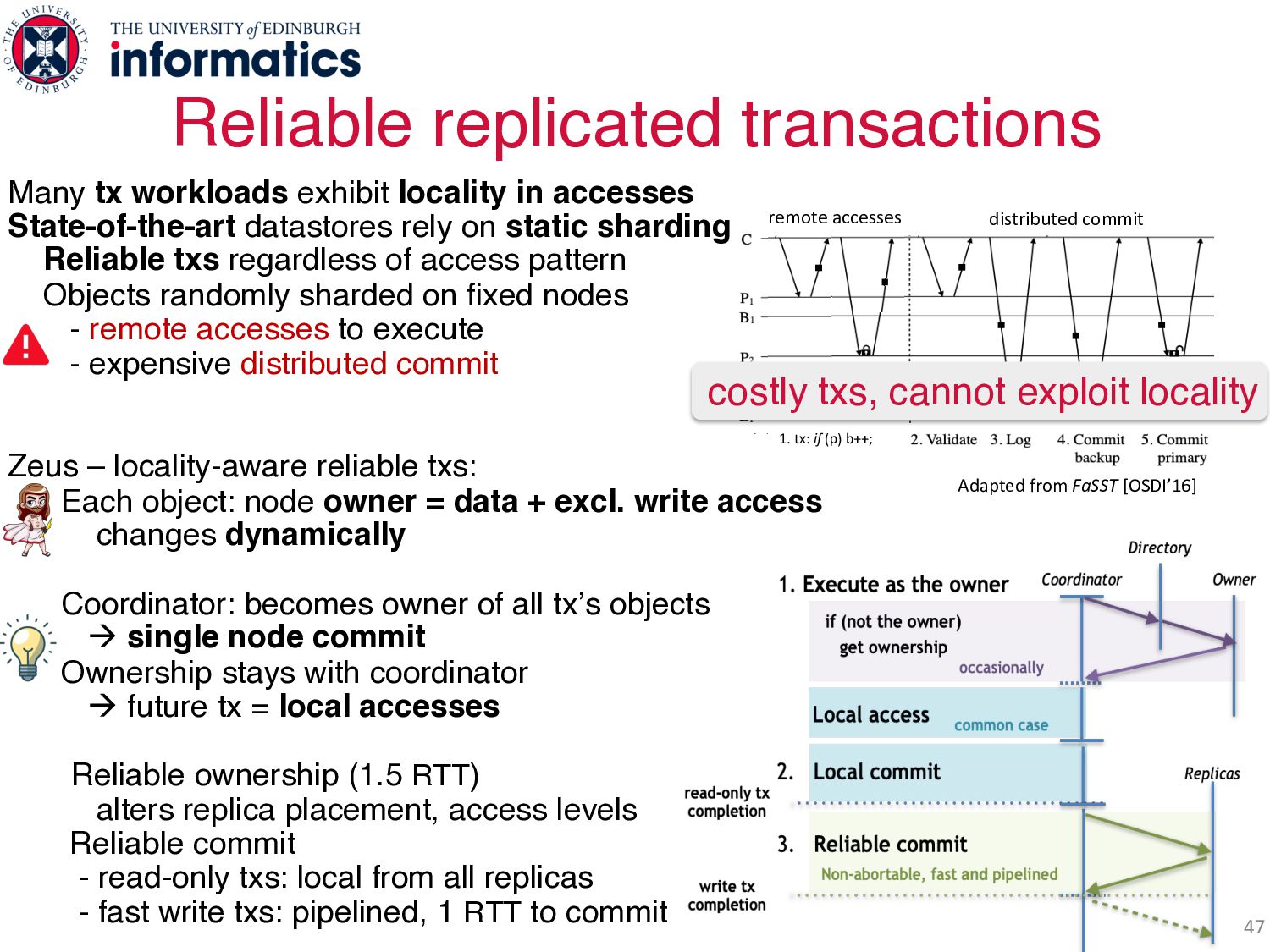
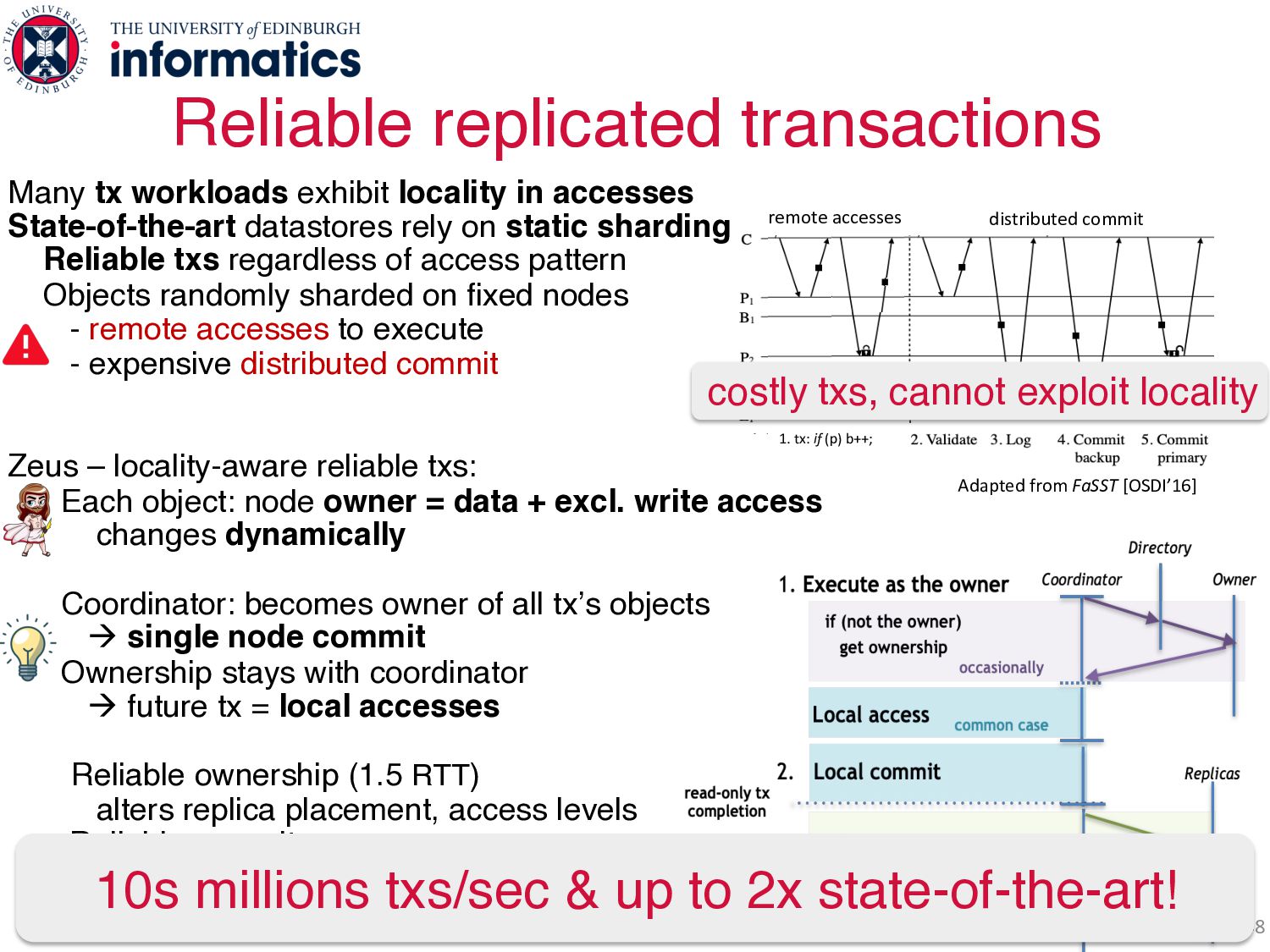
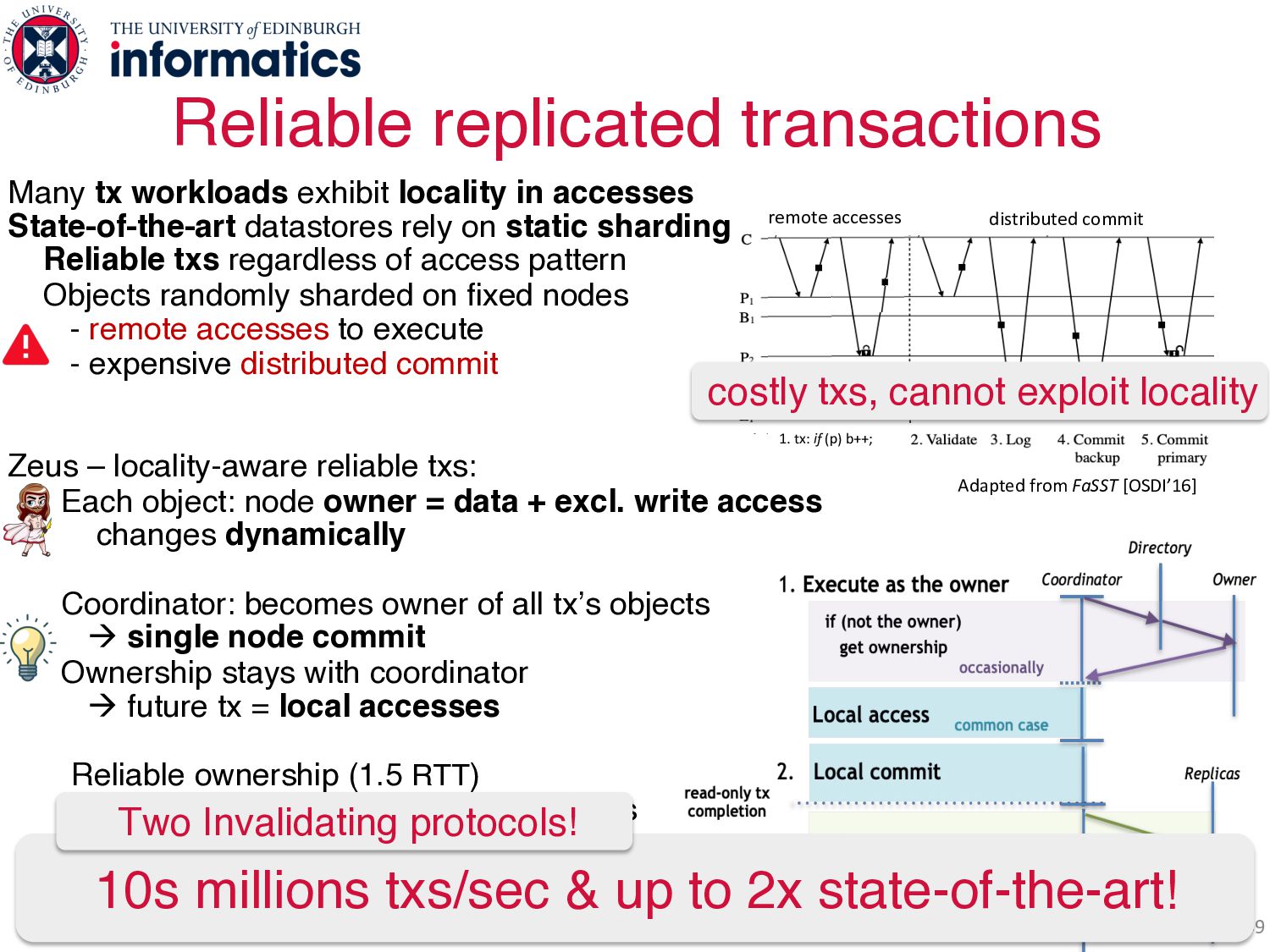
accesses State-of-the-art datastores rely on static sharding Reliable txs regardless of access pattern Objects randomly sharded on fixed nodes - remote accesses to execute - expensive distributed commit Zeus – locality-aware reliable txs: Each object: node owner = data + excl. write access changes dynamically Coordinator: becomes owner of all tx’s objects à single node commit Ownership stays with coordinator à future tx = local accesses Reliable ownership (1.5 RTT) alters replica placement, access levels Reliable commit - read-only txs: local from all replicas - fast write txs: pipelined, 1 RTT to commit 10s millions txs/sec & up to 2x state-of-the-art! distributed commit 1. tx: if (p) b++; remote accesses Adapted from FaSST [OSDI’16] distributed commit 1. tx: if (p) b++; remote accesses Adapted from FaSST [OSDI’16] Adapted from FaSST [OSDI’16] costly txs, cannot exploit locality Two Invalidating protocols!
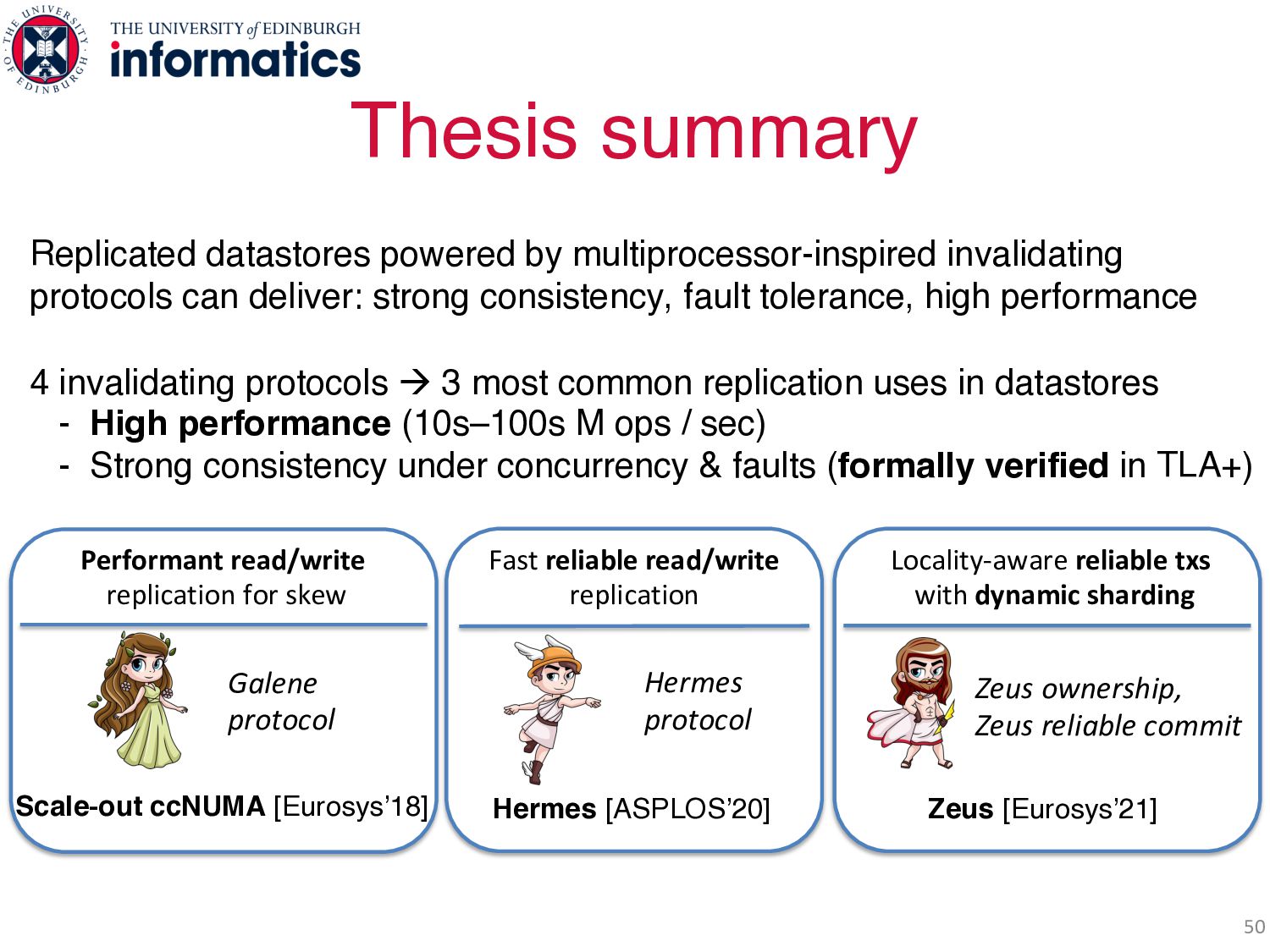
can deliver: strong consistency, fault tolerance, high performance 4 invalidating protocols à 3 most common replication uses in datastores - High performance (10s–100s M ops / sec) - Strong consistency under concurrency & faults (formally verified in TLA+) Scale-out ccNUMA [Eurosys’18] Hermes [ASPLOS’20] Zeus [Eurosys’21] Galene protocol Hermes protocol Zeus ownership, Zeus reliable commit Performant read/write replication for skew Fast reliable read/write replication Locality-aware reliable txs with dynamic sharding
can deliver: strong consistency, fault tolerance, high performance 4 invalidating protocols à 3 most common replication uses in datastores - High performance (10s–100s M ops / sec) - Strong consistency under concurrency & faults (formally verified in TLA+) Scale-out ccNUMA [Eurosys’18] Hermes [ASPLOS’20] Zeus [Eurosys’21] Galene protocol Hermes protocol Zeus ownership, Zeus reliable commit Performant read/write replication for skew Fast reliable read/write replication Locality-aware reliable txs with dynamic sharding Is this the end ??
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}