Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
マルチプロダクト×非構造化データ×機械学習を支えるデータ信頼性
Search
akino
June 28, 2022
Programming
8.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
マルチプロダクト×非構造化データ×機械学習を支えるデータ信頼性
akino
June 28, 2022
Other Decks in Programming
See All in Programming
ローカルLLMを使ってB2Bサービスを作っていての学び
yaotti
0
160
TSKaigi Night Talks 2026_TypeScriptでサプライチェーンの整合性を型に閉じ込める
geekplus_tech
0
330
タクシーアプリ『GO』の バックエンド開発のおける AI利活用と若者のすべて
pyama86
3
2k
Oxlintのカスタムルールの現況
syumai
6
1.1k
[2026年度第1回ORセミナー] 計画最適化ベンチャーと競技プログラミング人材
terryu16
0
260
TypeScript+Orvalで実現する型安全かつ堅牢でスケーラブルなマルチチャネル通知基盤 / TSKaigi Night talks ~after conference~
d0riven
0
320
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
540
Language Server 使ってる? 〜VSCode と Zed の場合〜 / Are you using a Language Server? ~For VS Code and Zed~
handlename
0
780
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
120
メソッドのジェネリクスでGoの夢は広がるか? / Kyoto.go #65
utgwkk
3
670
Vite+ Unified Toolchain for the Web
naokihaba
0
240
キャリア迷子上等 ─ "ない道"は自分で作ればいい
16bitidol
3
1.9k
Featured
See All Featured
sira's awesome portfolio website redesign presentation
elsirapls
0
280
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Navigating Weather and Climate Data
rabernat
0
220
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
160
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
420
How STYLIGHT went responsive
nonsquared
100
6.2k
4 Signs Your Business is Dying
shpigford
187
22k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
420
Transcript
Confidential © 2022 LayerX Inc. 1 マルチプロダクト×非構造化データ ×機械学習を支えるデータ信頼性 2022/06/28 @akino_1027
SaaS.tech #4
Confidential © 2022 LayerX Inc. 2 自己紹介 秋野 統輝 @akino_1027
• 2000年生まれ • 株式会社LayerX バクラク事業部 AI-OCRチーム ソフトウェアエンジニア • AI-OCRにおけるデータパイプラインの整備や基盤開発 • フロントエンド、バックエンド、インフラまで広く携わっています
Confidential © 2022 LayerX Inc. 3 • マルチプロダクトを背景にした、非構造化データMLにおける「信頼できる データ」の定義 •
各プロダクトに散らばったデータを統合・整形して蓄積するアプローチ • ML全般の話というよりは、ML×SaaSプロダクトの文脈でお話していき ます 今回話すこと
Confidential © 2022 LayerX Inc. 4 1. バクラクOCRの紹介 2. バクラクならではの背景と解きたい課題
3. マルチプロダクト×非構造化データ×MLにおける信頼できるデータとは? 4. OCRデータ基盤と設計 a. 書類データ統合 b. 書類と正解データの紐付け 5. まとめ 目次
Confidential © 2022 LayerX Inc. 5 1.バクラクOCRの紹介
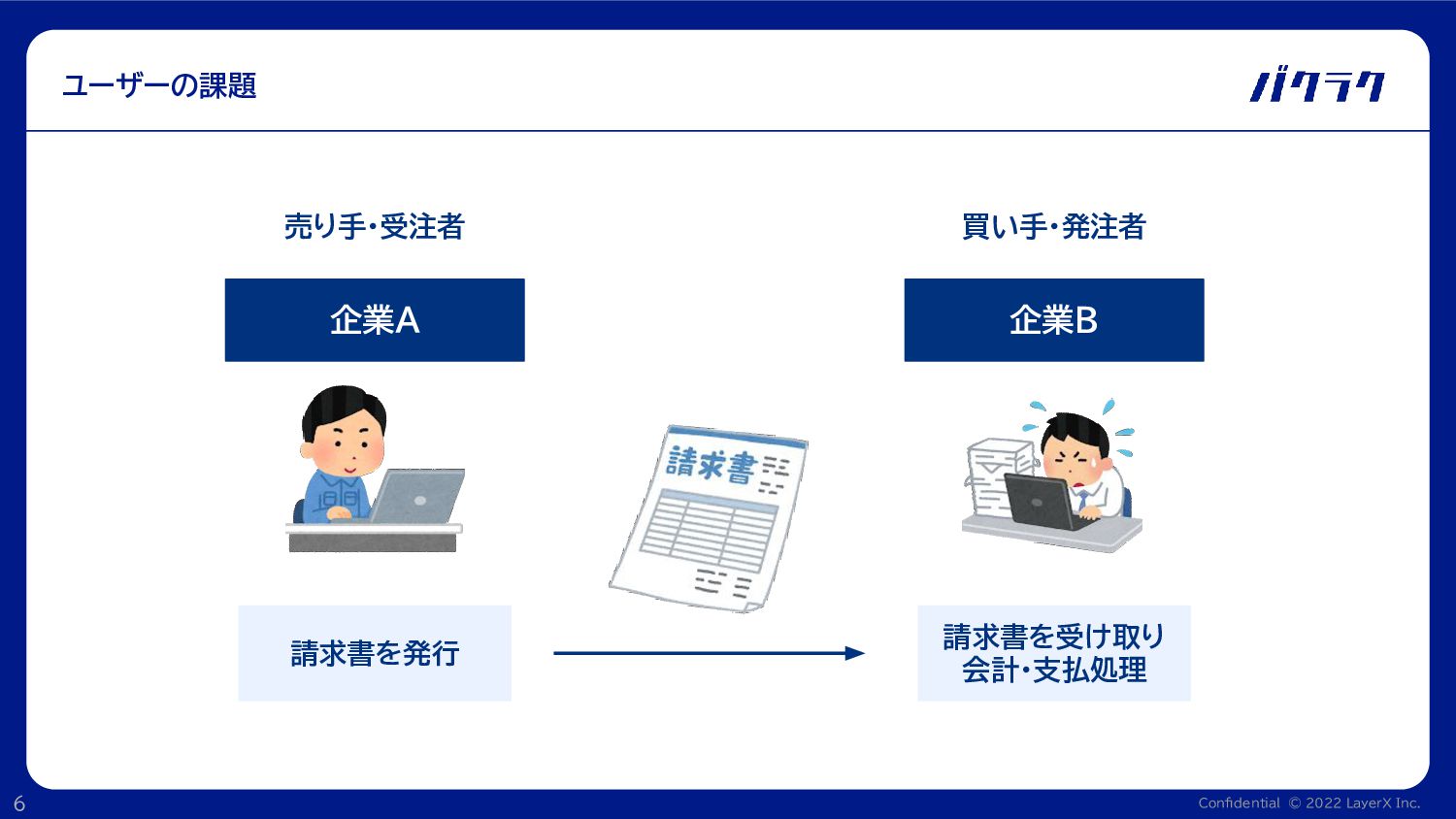
Confidential © 2022 LayerX Inc. 6 ユーザーの課題 企業A 企業B 売り手・受注者
買い手・発注者 請求書を発行 請求書を受け取り 会計・支払処理
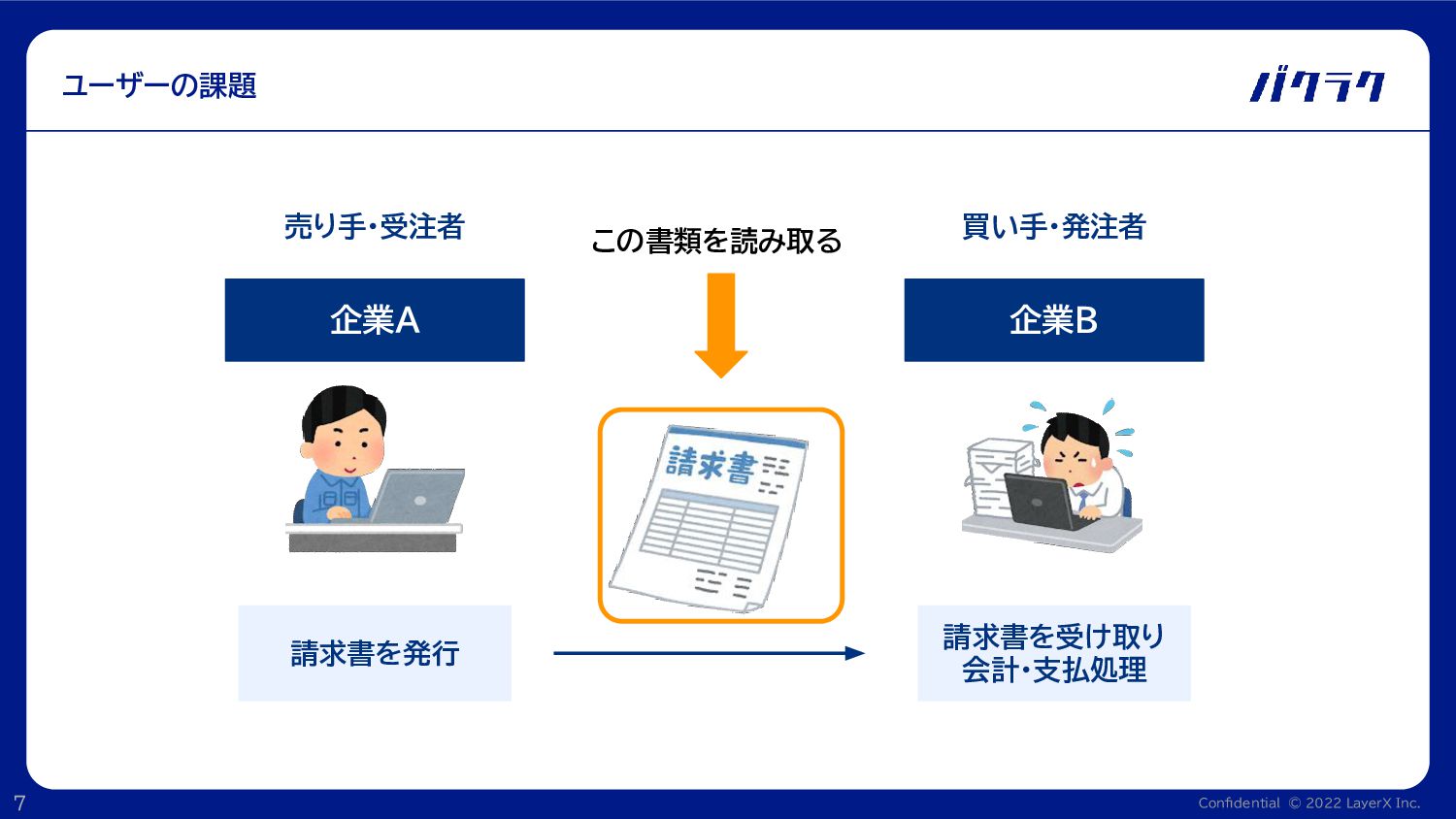
Confidential © 2022 LayerX Inc. 7 ユーザーの課題 企業A 企業B 売り手・受注者
買い手・発注者 請求書を発行 請求書を受け取り 会計・支払処理 この書類を読み取る
Confidential © 2022 LayerX Inc. 8 書類の読み取りはめちゃめちゃ大変 ユーザーの課題 • 1日に何十枚、何百枚も確認するのでミ
スが起こりやすい • 世の中には多様なレイアウトがあるた め、読み取りが困難(疲れる) • ミス=大問題なので、ダブルチェック・ト リプルチェックしなければいけない
Confidential © 2022 LayerX Inc. 9 このような問題を解決するために、バクラクAI-OCRを開発しました 書類自動読取 5秒でデータ化・自動入力 バクラクシリーズの
4つの製品で使用中 特長1 特長3 特長2 100枚までの書類を 同時アップロード可能 3つの特長
Confidential © 2022 LayerX Inc. 10 ここから、技術的な話
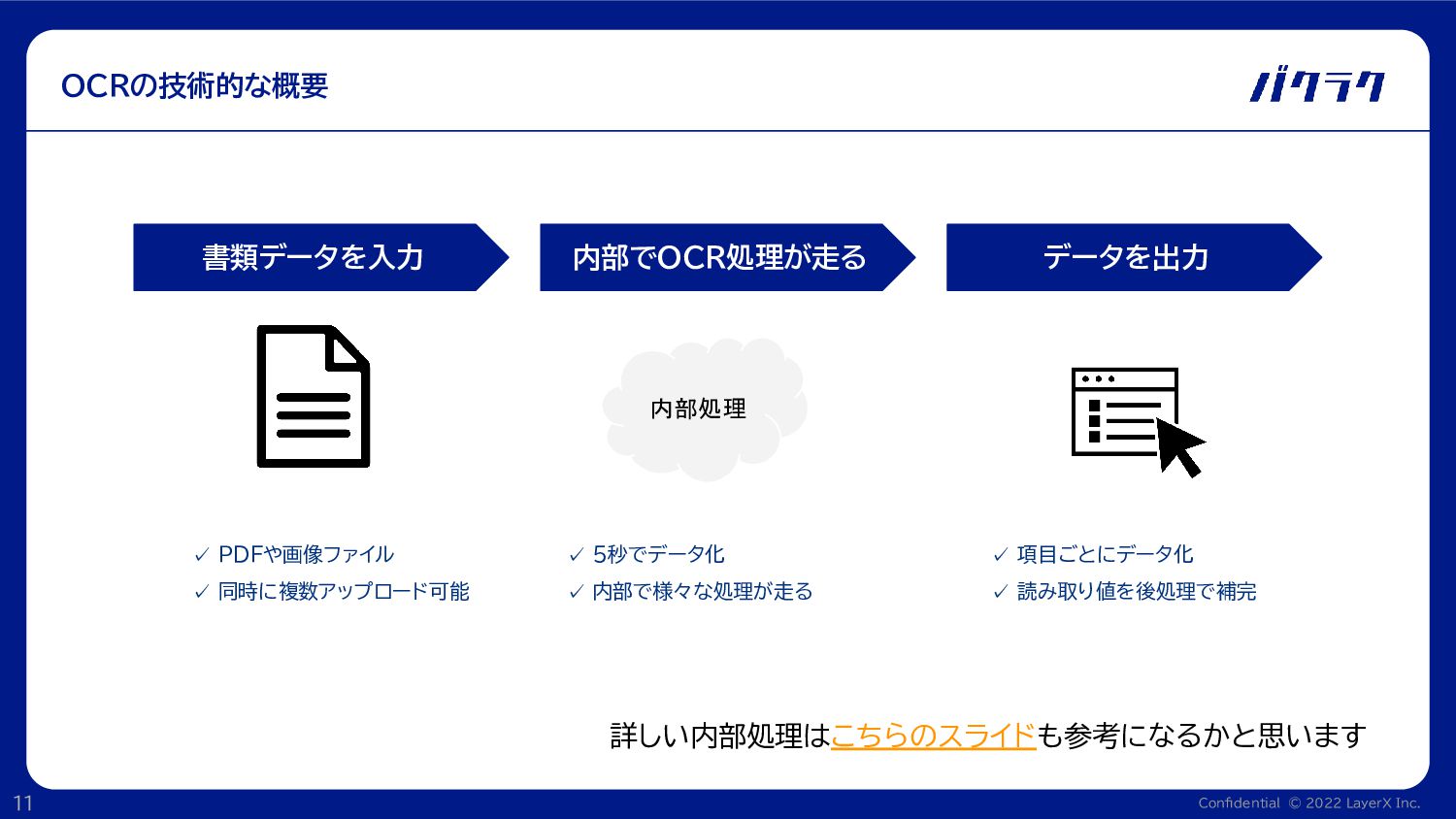
Confidential © 2022 LayerX Inc. 11 OCRの技術的な概要 内部でOCR処理が走る 書類データを入力 データを出力
✓ PDFや画像ファイル ✓ 同時に複数アップロード可能 内部処理 ✓ 項目ごとにデータ化 ✓ 読み取り値を後処理で補完 ✓ 5秒でデータ化 ✓ 内部で様々な処理が走る 詳しい内部処理はこちらのスライドも参考になるかと思います
Confidential © 2022 LayerX Inc. 12 2.バクラクならではの背景と解きたい課題
Confidential © 2022 LayerX Inc. 13 (前置き)そもそも何のためにデータを管理したいのか • 機械学習が目的 •
サブ的な目的として、精度モニタリングやテストに必要なデータも一緒に管理
Confidential © 2022 LayerX Inc. 14 • 書類データ(インプット) ◦ 書類の種類(請求書,領収書,支払通知書...etc)
◦ 文字列とその位置情報 ◦ MIMEタイプ(PDF,JPEG,PNG…etc) • 正解データ(アウトプット) ◦ 複数の読み取り項目 ▪ (例)取引先名は「株式会社LayerX」 ◦ 項目ごとの位置情報(何ページ目のどの部分にあるか) 管理したいデータはこんな感じ 書類データと正解データをペアで管理する
Confidential © 2022 LayerX Inc. 15 さっきの流れで見ると... OCR内部で処理が走る 書類データを入力 データを出力
✓ PDFや画像ファイル ✓ 同時に複数アップロード可能 内部処理 ✓ 項目ごとにデータ化 ✓ 読み取り値を後処理で補完 ✓ 5秒でデータ化 ✓ 内部で様々な処理が走る インプット アウトプット
Confidential © 2022 LayerX Inc. 16 バクラクならではの背景と解きたい課題 • (1)複数プロダクトでAI-OCRが使われていて、DBも別々 •
(2)非構造化データ(画像・書類)を扱う • (3)多様なデータを扱う • (4)正解データ作成が困難
Confidential © 2022 LayerX Inc. 17 (課題1)複数プロダクトでAI-OCRが使われていて、DBも別々
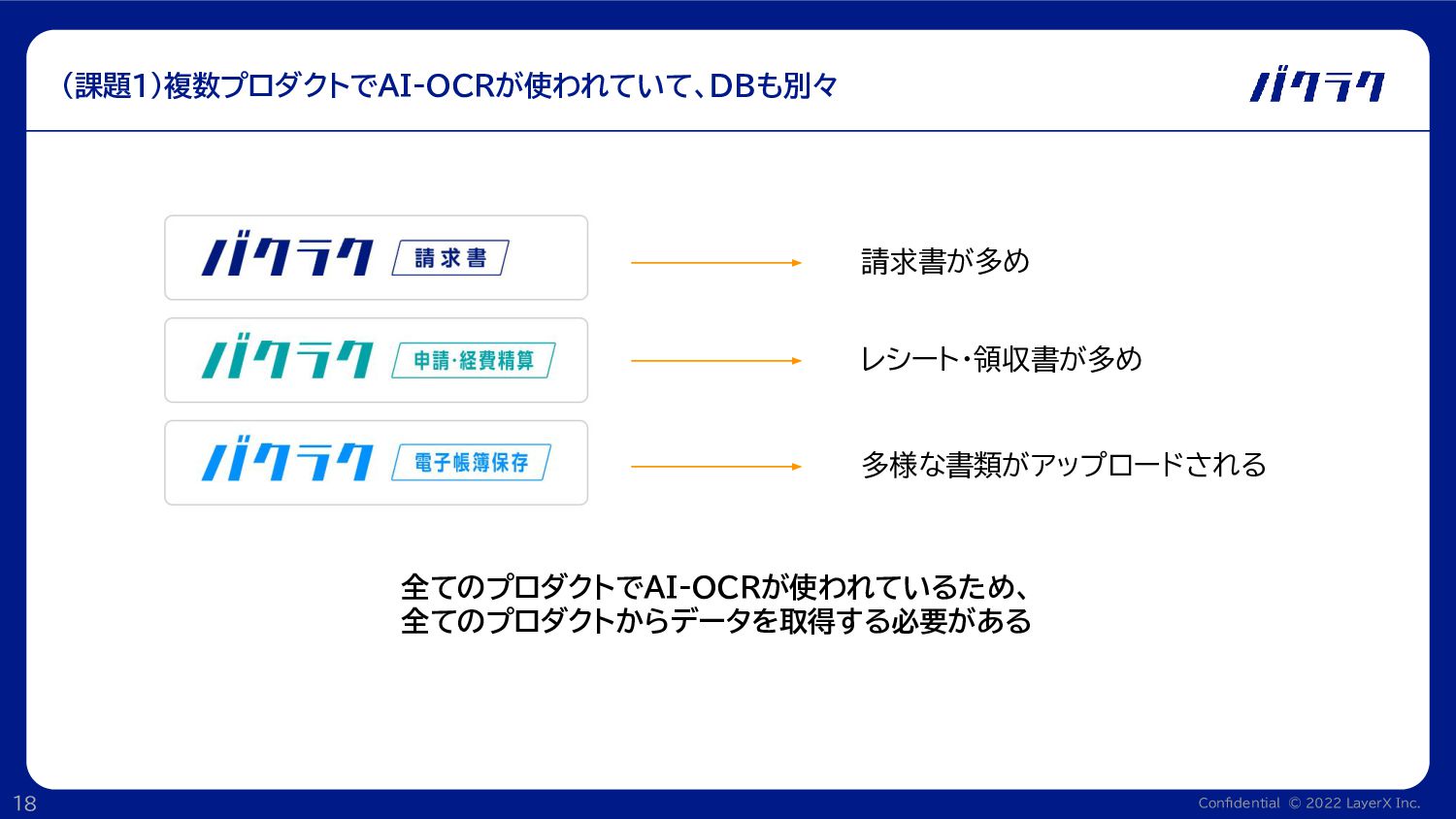
Confidential © 2022 LayerX Inc. 18 (課題1)複数プロダクトでAI-OCRが使われていて、DBも別々 請求書が多め レシート・領収書が多め 全てのプロダクトでAI-OCRが使われているため、
全てのプロダクトからデータを取得する必要がある 多様な書類がアップロードされる
Confidential © 2022 LayerX Inc. 19 (課題1)複数プロダクトでAI-OCRが使われていて、DBも別々 • 複数のプロダクトからデータを取得する必要がある ◦
DBが異なるためSQLだけで完結せず、コードを書く必要がある ◦ スキーマが異なるため、それぞれのクエリを書かなければならない • 各プロダクトの仕様を把握する必要がある ◦ どのような場合にNullになるのか ◦ 入り得る値はどのようなものか • 各DBでデータを同期している箇所がある ◦ 重複を排除する必要がある
Confidential © 2022 LayerX Inc. 20 (課題2)非構造化データ(書類・画像)を扱う • PDF,JPEG,PNGを扱う •
S3にファイルの実態がある ◦ 画像や書類などの非構造化データなため分析がしにくい • メタデータを付与し構造化する必要がある
Confidential © 2022 LayerX Inc. 21 (課題3)多様なデータを扱う • 多様な書類種別 ◦
(例)請求書,領収書,支払通知書...etc • 多様なレイアウトの書類 • 項目ごとの正解データ ◦ (例)取引先名:「株式会社LayerX」 • 項目ごとの位置情報
Confidential © 2022 LayerX Inc. 22 • 今まではスプレッドシートで管理していた • 一つ一つの正解データを作成するのに時間がかかる
• 書類・画像の内容を管理するため、精度を保ったまま機械的に作成するのは難しい ◦ けど、自動化・効率化できるところは、やっていく (課題4)正解データの作成が困難 • 素朴な疑問:ユーザーの入力値はそのまま使えないの? → No. AI-OCRで解きたい問題を簡単にするため ユーザーは書類に記載の値をそのまま使うわけではない
Confidential © 2022 LayerX Inc. 23 ここから本題
Confidential © 2022 LayerX Inc. 24 3.マルチプロダクト×非構造化データ×MLにおける 信頼できるデータとは
Confidential © 2022 LayerX Inc. 25 • (1)複数のプロダクトにデータが存在 • (2)非構造化データを扱う
• (3)多様なデータ マルチプロダクト×非構造化データ×MLを扱う難しさと信頼できるデータ • (1)統合されていて、SQLでアクセス可能 • (2)正確な正解データ 扱う難しさ 信頼できるデータ
Confidential © 2022 LayerX Inc. 26 • (1)複数のプロダクトにデータが存在 • (2)非構造化データを扱う
• (3)多様なデータ マルチプロダクト×非構造化データ×MLを扱う難しさと信頼できるデータ • (1)統合されていて、SQLでアクセス可能 • (2)正確な正解データ 扱う難しさ 信頼できるデータ 先ほどまで話していたこと
Confidential © 2022 LayerX Inc. 27 • (1)複数のプロダクトにデータが存在 • (2)非構造化データを扱う
• (3)多様なデータ マルチプロダクト×非構造化データ×MLを扱う難しさと信頼できるデータ • (1)統合されていて、SQLでアクセス可能 • (2)正確な正解データ 扱う難しさ 信頼できるデータ これから話すこと
Confidential © 2022 LayerX Inc. 28 • CSV等だと読み込み側で工夫が必要 • 複数DBに散らばっていると、データの取得が困難
• 1つのRDBで管理されていれば、取得・加工がしやすい (信頼できるデータ1)統合されていて、SQLでアクセス可能
Confidential © 2022 LayerX Inc. 29 (信頼できるデータ2)正解データの正確性 前提 • 正解データを正確に保存することは難しい
◦ 非構造化データ & 多様なデータゆえ • 上記を理解した上での手厚いアプローチが必要 • ボリュームを言い訳に、正確性を捨てない • ボリュームと正確性はトレードオフではない ◦ ソフトウェア設計と運用次第でどちらも担保できるはず 詳細
Confidential © 2022 LayerX Inc. 30 バクラクAI-OCRにおける、正解データの「正解」とは 書類に記載されている値を「正解」とする (例) (理由)
Confidential © 2022 LayerX Inc. 31 バクラクAI-OCRにおける、正解データの「正解」とは 書類に記載されている値を「正解」とする (例) •
「レイヤー・エックス」のように正式な名称と異なっていても、修正しない。 • 「LayerX」と記載されている場合、「株式会社LayerX」のように補完はしない。 (理由)
Confidential © 2022 LayerX Inc. 32 バクラクAI-OCRにおける、正解データの「正解」とは 書類に記載されている値を「正解」とする (例) •
「レイヤー・エックス」のように正式な名称と異なっていても、修正しない。 • 「LayerX」と記載されている場合、「株式会社LayerX」のように補完はしない。 (理由) • 書類に記載している値を「正解」とすることで、OCR自体の問題が単純になる • 一方で、ユーザーが入力して欲しい値は後処理で補完
Confidential © 2022 LayerX Inc. 33 • (1)複数のプロダクトにデータが存在 • (2)非構造化データを扱う
• (3)多様なデータ マルチプロダクト×非構造化データ×MLを扱う難しさと信頼できるデータ • (1)統合されていて、SQLでアクセス可能 • (2)正確な正解データ 扱う難しさ 信頼できるデータ 困難さに対して、信頼できるデータを蓄積していく アプローチについて話していきます
Confidential © 2022 LayerX Inc. 34 3.OCRデータ基盤と設計
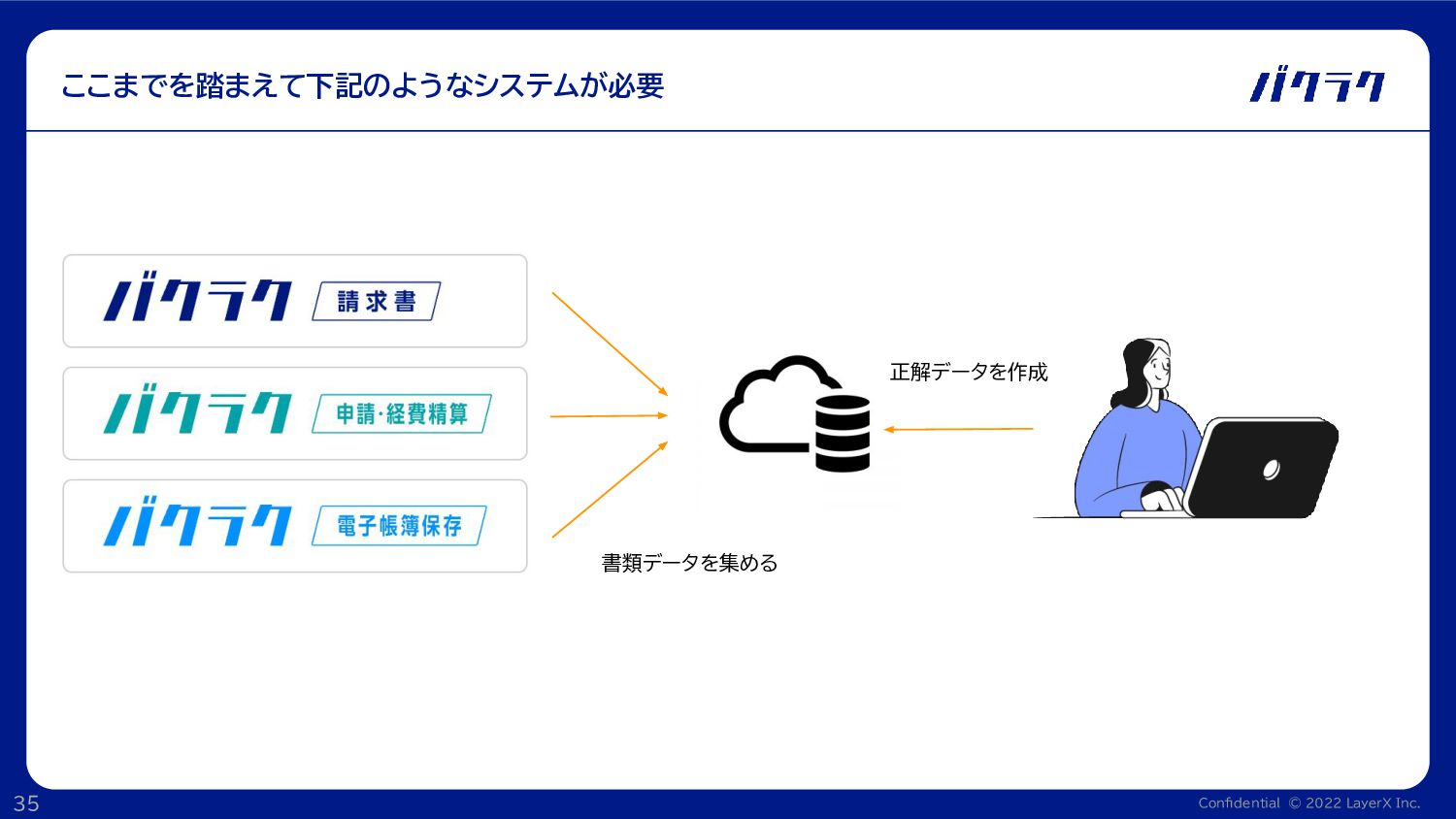
Confidential © 2022 LayerX Inc. 35 ここまでを踏まえて下記のようなシステムが必要 書類データを集める 正解データを作成
Confidential © 2022 LayerX Inc. 36 ここまでを踏まえて下記のようなシステムが必要 書類データを集める 正解データを作成 OCRデータ基盤の開発をしました
Confidential © 2022 LayerX Inc. 37 OCRデータ基盤の概要と要件 概要 要件 •
Webアプリ(API+MySQL) • Go×Vue.js×GraphQLで開発 • MLや精度検証時にデータを容易に取得できる • 各プロダクトからデータをImportできる • 書類データと正解データを紐付けることができる ◦ Webアプリ上で書類を見ながら正解データを入力することで、データ作成可能
Confidential © 2022 LayerX Inc. 38 OCRデータ基盤の概要と要件 概要 要件 •
Webアプリ(API+MySQL) • Go×Vue.js×GraphQLで開発 • MLや精度検証時にデータを容易に取得できる • 各プロダクトからデータをImportできる • 書類データと正解データを紐付けることができる ◦ Webアプリ上で書類を見ながら正解データを入力することで、データ作成可能 今回は、ここに注目
Confidential © 2022 LayerX Inc. 39 4-a.書類データ統合
Confidential © 2022 LayerX Inc. 40 バッチを定期実行させてデータをImport バクラク請求書 (DB) バクラク申請・経費精算
(DB) バクラク電子帳簿保存 (DB) バッチ基盤 (定期実行) OCRデータ基盤 (DB) Import 整形 この形に落ち着くまで結構、試行錯誤しましたが、今回は割愛...
Confidential © 2022 LayerX Inc. 41 DB設計で特に意識したこと • 正解データを紐付ける書類単位では同一のテーブルで管理する ◦
どのプロダクトから来たとしても同一テーブルで管理する ◦ プロダクトごとに書類情報を管理するテーブルを分けたりしない • 今後、プロダクトが増えたとしても拡張しやすくする • 書類と正解データをセットで取得しやすいようなスキーマにする • 精度検証やテスト時にもDBを参照するため、その考慮も必要
Confidential © 2022 LayerX Inc. 42 4-b.書類と正解データの紐付け
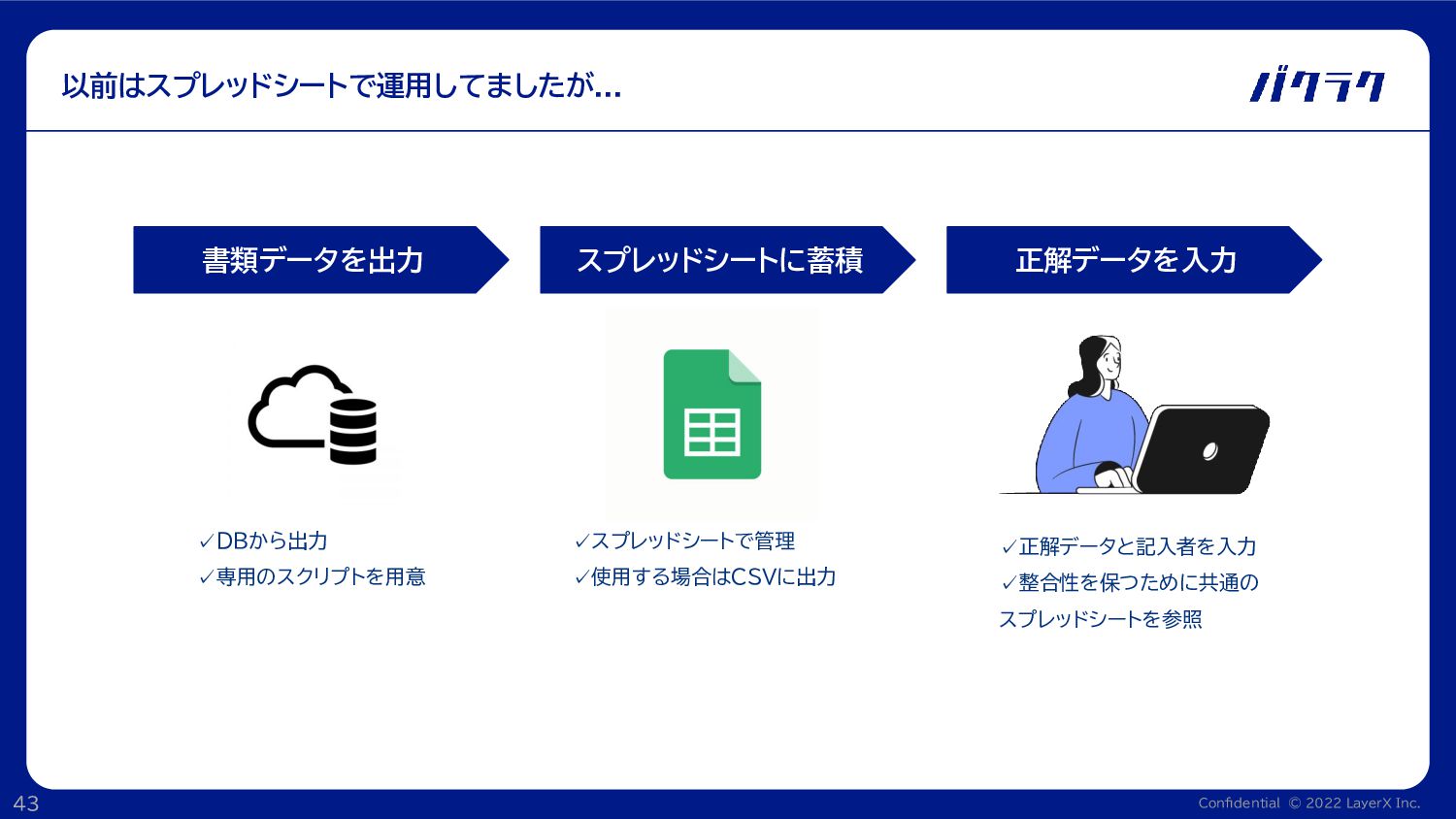
Confidential © 2022 LayerX Inc. 43 以前はスプレッドシートで運用してましたが... 書類データを出力 スプレッドシートに蓄積 正解データを入力
✓正解データと記入者を入力 ✓整合性を保つために共通の スプレッドシートを参照 ✓スプレッドシートで管理 ✓使用する場合はCSVに出力 ✓DBから出力 ✓専用のスクリプトを用意
Confidential © 2022 LayerX Inc. 44 • データを使用したい場合、CSVを読み込む必要がある ◦ (例1)精度測定
◦ (例2)テスト実行 • 書類データ→正解データ入力のプロセスに特化していないため、効率が悪い • 検索等の機能はスプレッドシートの枠を出ないため、拡張性が低い...etc スプレッドシート運用はここが辛い
Confidential © 2022 LayerX Inc. 45 管理画面のWebアプリを開発しました
Confidential © 2022 LayerX Inc. 46 • フルスクラッチで開発 • Webフロント×API構成
• Go×Vue.js×GraphQLで開発 ◦ LayerXでの技術的な知見を活かす • 書類データの検索・正解データ作成に特化 OCRデータ基盤Webアプリを開発
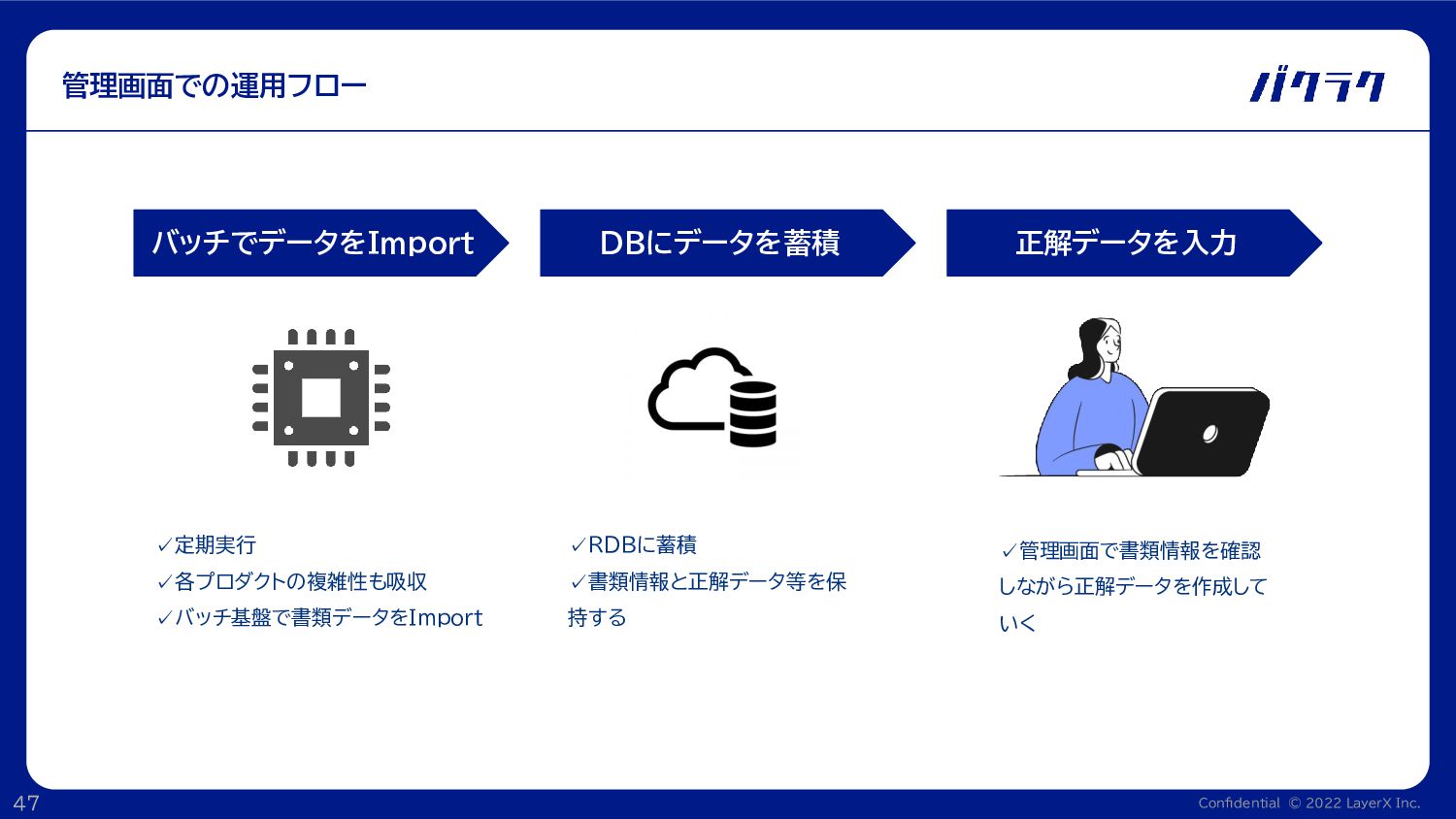
Confidential © 2022 LayerX Inc. 47 管理画面での運用フロー バッチでデータをImport DBにデータを蓄積 正解データを入力
✓管理画面で書類情報を確認 しながら正解データを作成して いく ✓RDBに蓄積 ✓書類情報と正解データ等を保 持する ✓定期実行 ✓各プロダクトの複雑性も吸収 ✓バッチ基盤で書類データをImport
Confidential © 2022 LayerX Inc. 48 • CSVを読み込む必要がある • 効率が悪い
• UI・機能の拡張性が低い スプレッドシートとWebアプリ比較 • SQLで取得可能 • 正解データ作成に特化 • 自由度が高い ◦ 独自の検索機能が開発可能
Confidential © 2022 LayerX Inc. 49 5.まとめ
Confidential © 2022 LayerX Inc. 50 • 複数プロダクトの複雑性を吸収した上で、正確性を担保しながらデータを蓄積する仕組みを構築 する ◦
取得しやすい形でデータを保持する必要がある ◦ ボリュームと正確性はトレードオフではない ▪ ソフトウェア設計と運用次第でどちらも担保できるはず • データ管理において、既存システムを活用するのかフルスクラッチで開発するのかは、全体の効 率を考えて意思決定する必要がある ◦ 考慮事項:正解データの作成効率、データセット作成効率...etc まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}