Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
製薬会社における安全性監視活動の負担最小化の検討
Search
akinorisaito
March 08, 2020
Business
0
150
製薬会社における安全性監視活動の負担最小化の検討
akinorisaito
March 08, 2020
Tweet
Share
More Decks by akinorisaito
See All by akinorisaito
中学数学で新型コロナ罹患者数を予測(2020/05/22更新)
akinorisaito
0
99
COVID19の症状を視覚化
akinorisaito
1
140
中学数学で新型コロナ罹患者数を予測
akinorisaito
1
160
Other Decks in Business
See All in Business
ログラス会社紹介資料 / Loglass Company Deck
loglass2019
13
510k
Rakus Career Introduction
rakus_career
0
490k
AI推進における「勝手に広がる仕組み」の」作り方
notty
2
200
イグニション・ポイント株式会社/採用エントランスBook_2026
ignitionpointhr
2
180k
気がついたら自分がボトルネックになってた -1人でプロダクトをみることになった編-
koinunopochi
0
200
Corporate Story (GA technologies Co., Ltd.)
gatechnologies
0
670
GMO Flatt Security 会社紹介資料
flatt_security
0
29k
BizDocVQA: 実世界ビジネス帳票に対する根拠付きVQAデータセットの提案
icoxfog417
PRO
0
170
今いい感じのチーム構成と営み2025冬 〜Scrumっぽいけどチョット違う形〜
sasakendayo
0
340
株式会社アシスト_会社紹介資料
ashisuto_career
3
160k
㈱サンエー 会社 採用資料
uemura2024
0
1.7k
2025年度ICT職専門研修(海外派遣研修)報告書 No.4
tokyo_metropolitan_gov_digital_hr
0
150
Featured
See All Featured
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
480
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
290
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
1
1.3k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
62
52k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
2.5k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
220
Raft: Consensus for Rubyists
vanstee
141
7.4k
SEO for Brand Visibility & Recognition
aleyda
0
4.4k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
1.9k
30 Presentation Tips
portentint
PRO
1
250
Paper Plane
katiecoart
PRO
0
48k
Transcript
製薬会社における 安全性監視活動の 負担最小化の検討 DataMix データサイエンティスト育成コース 【2019年10月期】 齋藤 昭典
目次 • 背景 • 課題と仮説 • インテグレーションステップで行うこと • 方法 •
使用したツール、アルゴリズム等 • データ • 機械学習アルゴリズムの適用 • 結果 • まとめ • ビジネス活用 • 今後の課題 2
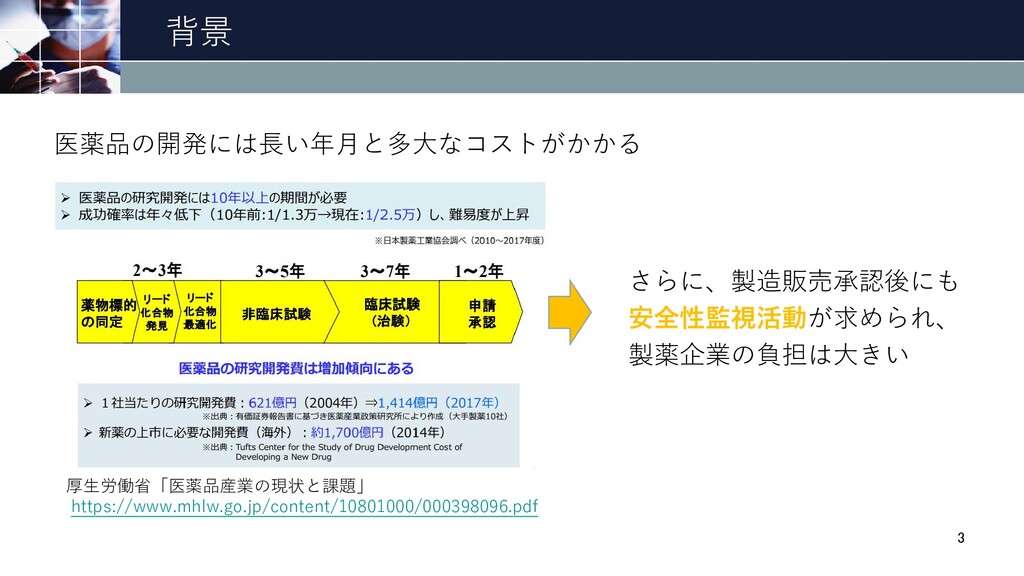
背景 さらに、製造販売承認後にも 安全性監視活動が求められ、 製薬企業の負担は大きい 3 厚生労働省「医薬品産業の現状と課題」 https://www.mhlw.go.jp/content/10801000/000398096.pdf 医薬品の開発には長い年月と多大なコストがかかる
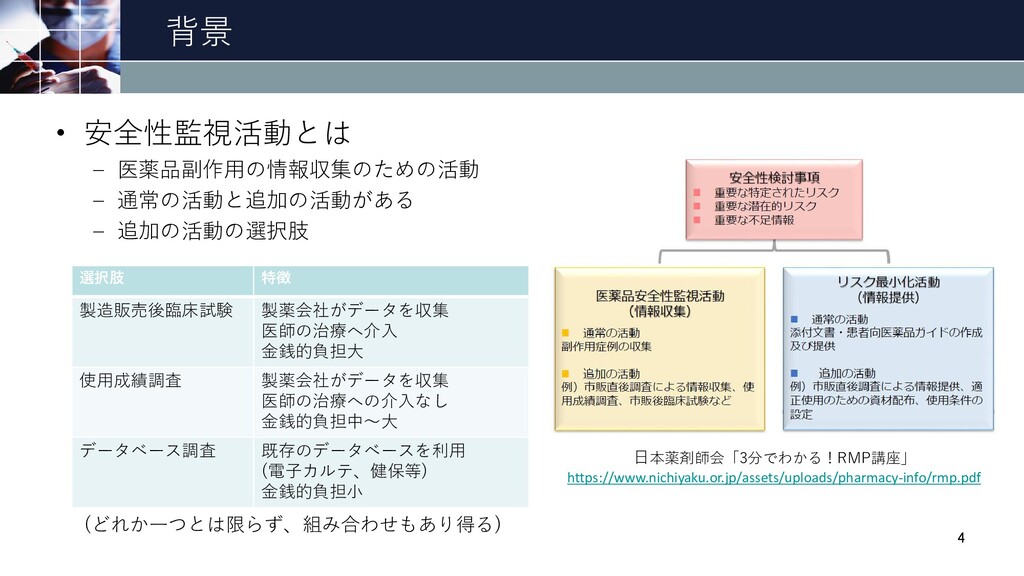
背景 • 安全性監視活動とは – 医薬品副作用の情報収集のための活動 – 通常の活動と追加の活動がある – 追加の活動の選択肢 4
日本薬剤師会「3分でわかる!RMP講座」 https://www.nichiyaku.or.jp/assets/uploads/pharmacy-info/rmp.pdf 選択肢 特徴 製造販売後臨床試験 製薬会社がデータを収集 医師の治療へ介入 金銭的負担大 使用成績調査 製薬会社がデータを収集 医師の治療への介入なし 金銭的負担中~大 データベース調査 既存のデータベースを利用 (電子カルテ、健保等) 金銭的負担小 (どれか一つとは限らず、組み合わせもあり得る)
背景 • RMPとRQ – 安全性監視活動は医薬品リスク管理計画書(RMP)として独立行政法人 医薬品医療機器総 合機構(PMDA/厚生労働省の外郭団体)へ提出し、認められなければならない – 何を重点項目とするか、リサーチクエスチョン(RQ)の設定により、追加の安全性監視活 動をどうするかが決まる
日本薬剤師会「3分でわかる!RMP講座」 https://www.nichiyaku.or.jp/assets/uploads/pharmacy-info/rmp.pdf 5
課題と仮説 • 課題 • 製薬会社は医薬品製造販売後の追加の安全性監視活動に医療情報データ ベースを利用したい • データベース調査を申請してもなかなか承認されない • 医療情報データベースの活用は進んでいるとは言い難いのが現状
• 仮説 • 機械学習アプローチにより、データベース調査が採用されやすい医薬品 の特徴(リスク等)を導き出すことができるのではないか 6
インテグレーションステップで行うこと • 製薬企業における製造販売後の安全性監視活動への負担を最小化す る方策を検討する • データベース調査が採用されやすい医薬品の予測モデルを作成する – RMPから、データベース調査が採用された医薬品の特徴(リスク等)を明ら かにする 7
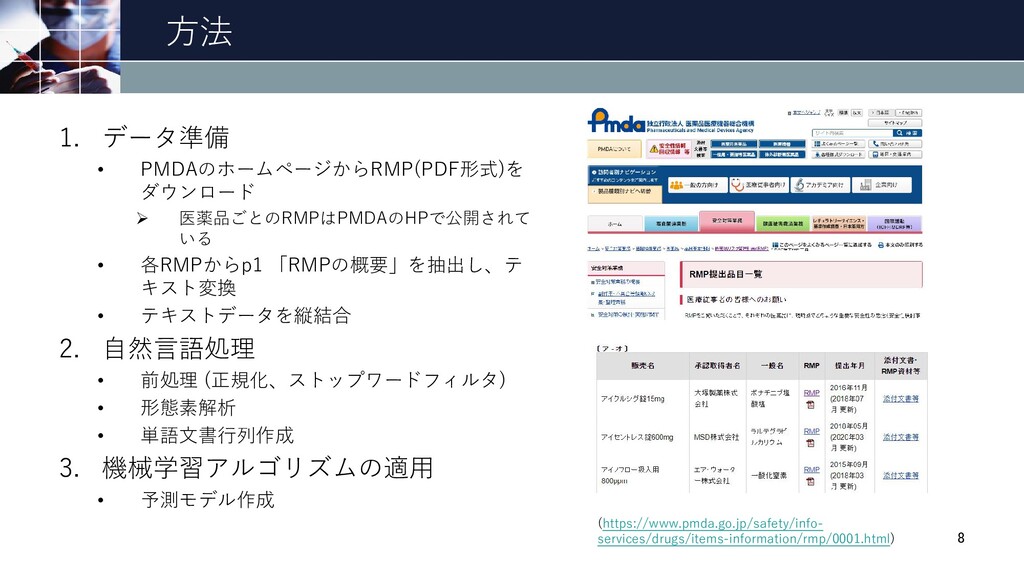
方法 1. データ準備 • PMDAのホームページからRMP(PDF形式)を ダウンロード Ø 医薬品ごとのRMPはPMDAのHPで公開されて いる •
各RMPからp1 「RMPの概要」を抽出し、テ キスト変換 • テキストデータを縦結合 2. 自然言語処理 • 前処理 (正規化、ストップワードフィルタ) • 形態素解析 • 単語文書行列作成 3. 機械学習アルゴリズムの適用 • 予測モデル作成 8 (https://www.pmda.go.jp/safety/info- services/drugs/items-information/rmp/0001.html)
使用したツール、アルゴリズム等 プロセス ツール、アルゴリズム等 PDFダウンロード Firefoxアドオン・DownThemAll PDFページ抽出 PyPDF2 PDFからのテキスト抽出 PDF miner
自然言語処理 形態素解析辞書 MeCab + NEologd Comejisyo (医療用語辞書: https://ja.osdn.net/projects/comedic/) Vectrizer TF-IDF Count Vectrizer 機械学習アルゴリズム ロジスティック回帰 (LR) サポートベクターマシーン (SVM) ランダムフォレスト (RF) xgboost (XGB) 決定木 (DT) 9
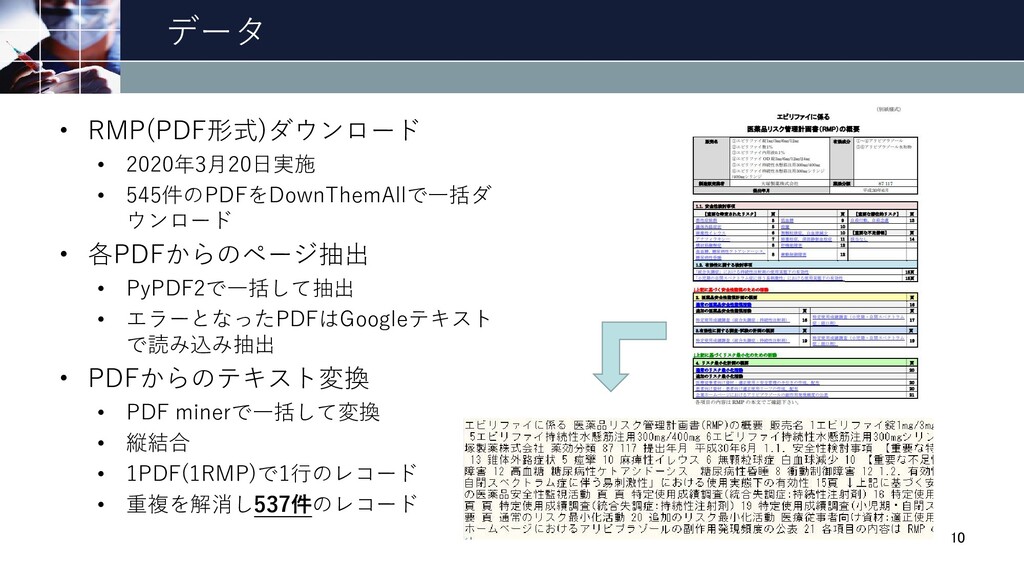
データ • RMP(PDF形式)ダウンロード • 2020年3月20日実施 • 545件のPDFをDownThemAllで一括ダ ウンロード • 各PDFからのページ抽出
• PyPDF2で一括して抽出 • エラーとなったPDFはGoogleテキスト で読み込み抽出 • PDFからのテキスト変換 • PDF minerで一括して変換 • 縦結合 • 1PDF(1RMP)で1行のレコード • 重複を解消し537件のレコード 10
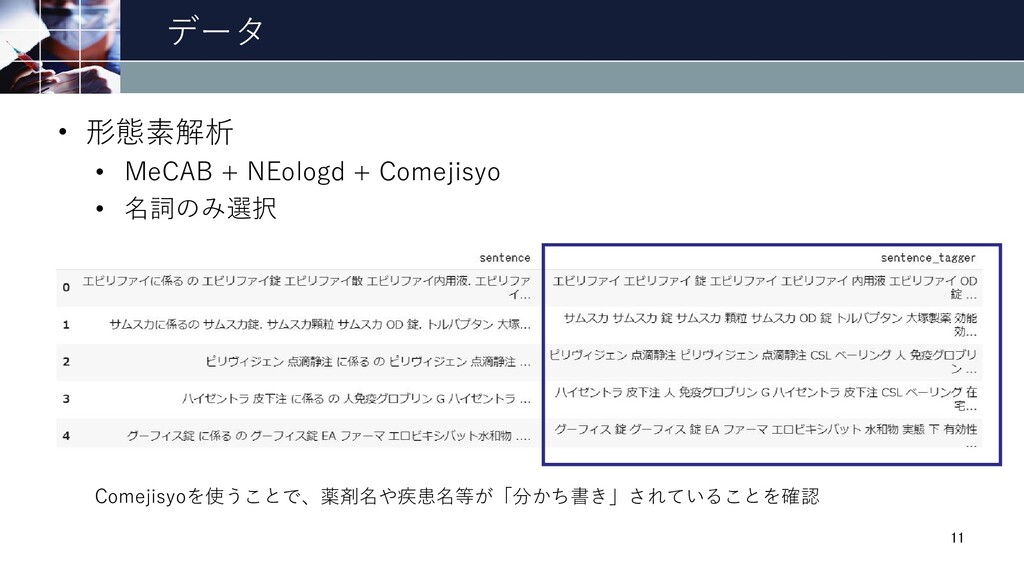
データ • 形態素解析 • MeCAB + NEologd + Comejisyo •
名詞のみ選択 11 Comejisyoを使うことで、薬剤名や疾患名等が「分かち書き」されていることを確認
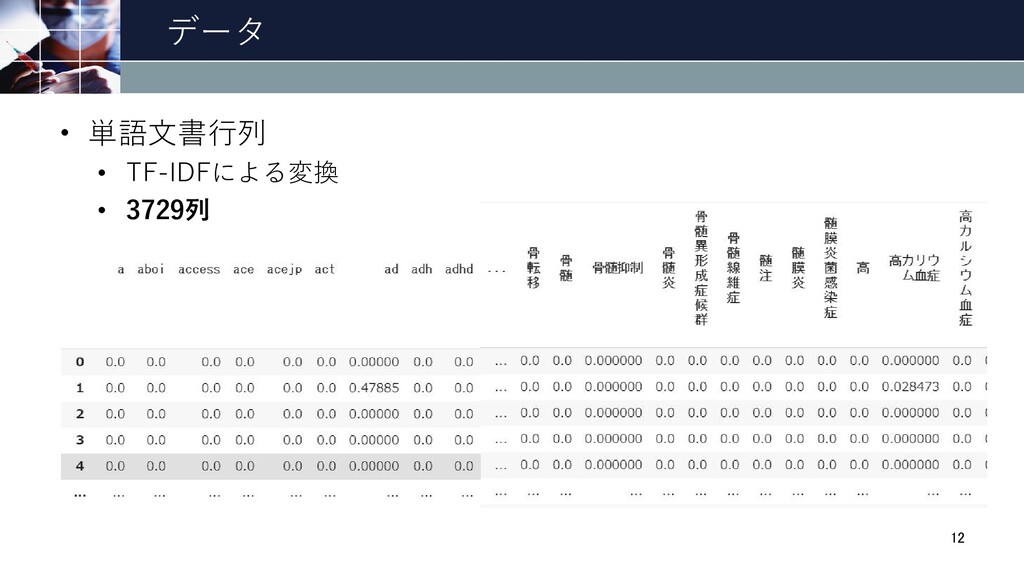
データ • 単語文書行列 • TF-IDFによる変換 • 3729列 12
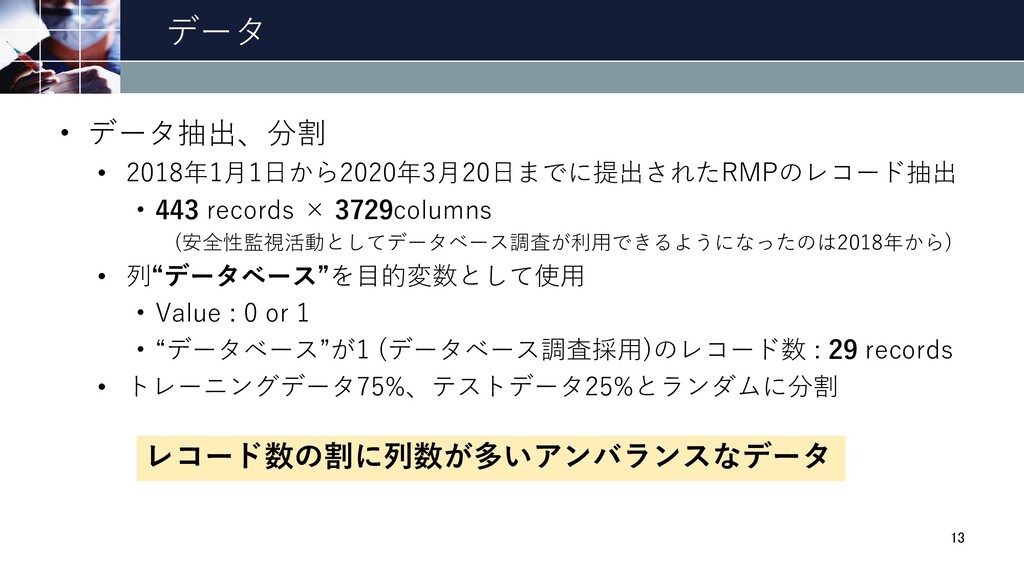
データ • データ抽出、分割 • 2018年1月1日から2020年3月20日までに提出されたRMPのレコード抽出 • 443 records × 3729columns
(安全性監視活動としてデータベース調査が利用できるようになったのは2018年から) • 列“データベース”を目的変数として使用 • Value : 0 or 1 • “データベース”が1 (データベース調査採用)のレコード数 : 29 records • トレーニングデータ75%、テストデータ25%とランダムに分割 13 レコード数の割に列数が多いアンバランスなデータ
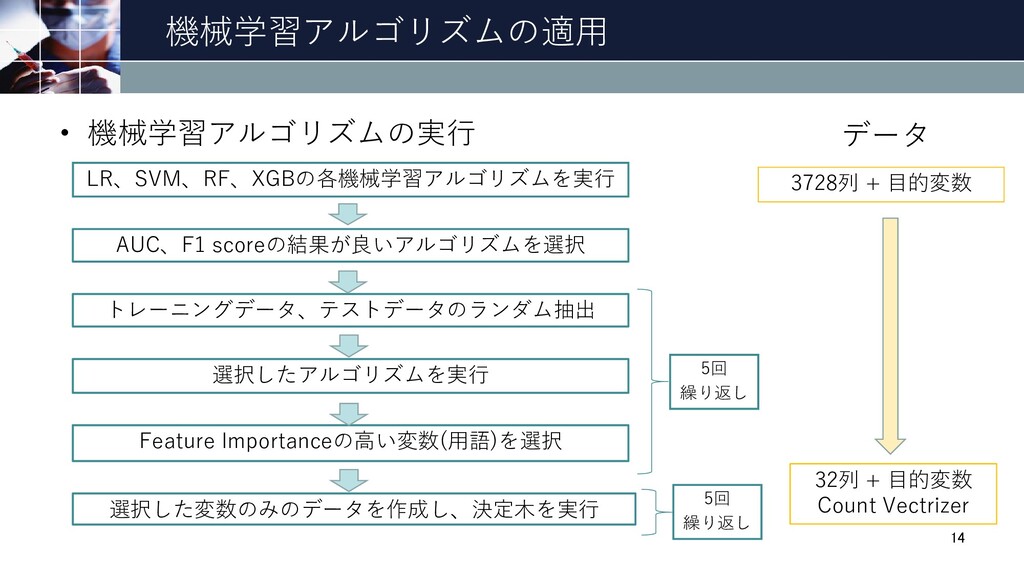
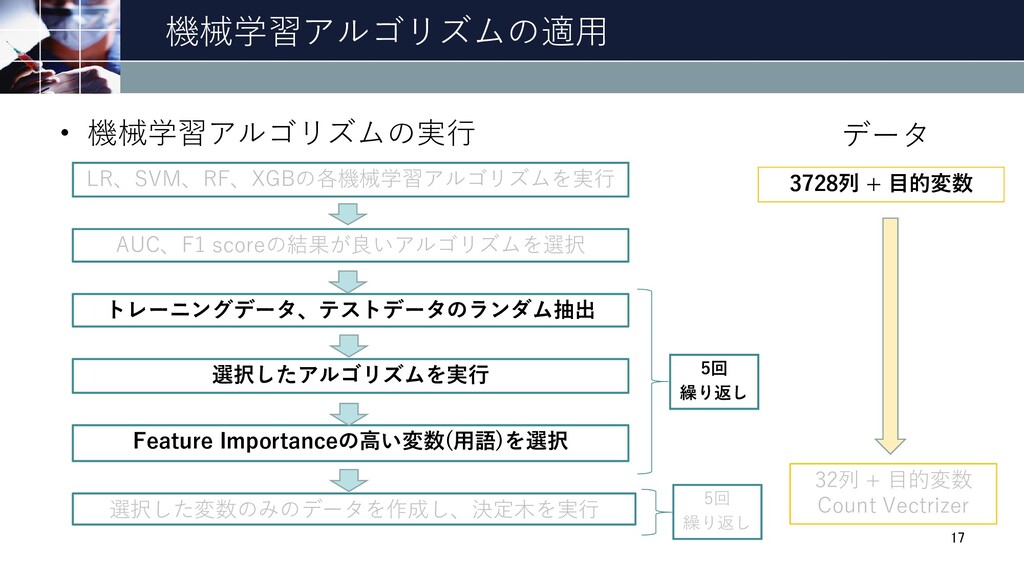
機械学習アルゴリズムの適用 LR、SVM、RF、XGBの各機械学習アルゴリズムを実行 • 機械学習アルゴリズムの実行 AUC、F1 scoreの結果が良いアルゴリズムを選択 トレーニングデータ、テストデータのランダム抽出 選択したアルゴリズムを実行 Feature Importanceの高い変数(用語)を選択
選択した変数のみのデータを作成し、決定木を実行 14 5回 繰り返し 5回 繰り返し データ 3728列 + 目的変数 32列 + 目的変数 Count Vectrizer
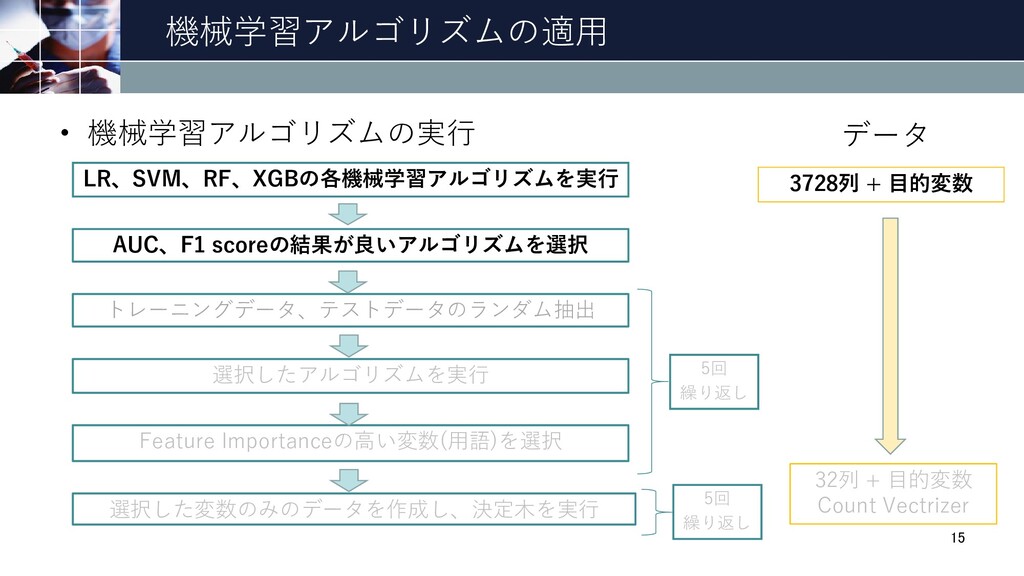
機械学習アルゴリズムの適用 LR、SVM、RF、XGBの各機械学習アルゴリズムを実行 • 機械学習アルゴリズムの実行 AUC、F1 scoreの結果が良いアルゴリズムを選択 トレーニングデータ、テストデータのランダム抽出 選択したアルゴリズムを実行 Feature Importanceの高い変数(用語)を選択
選択した変数のみのデータを作成し、決定木を実行 15 5回 繰り返し 5回 繰り返し データ 3728列 + 目的変数 32列 + 目的変数 Count Vectrizer
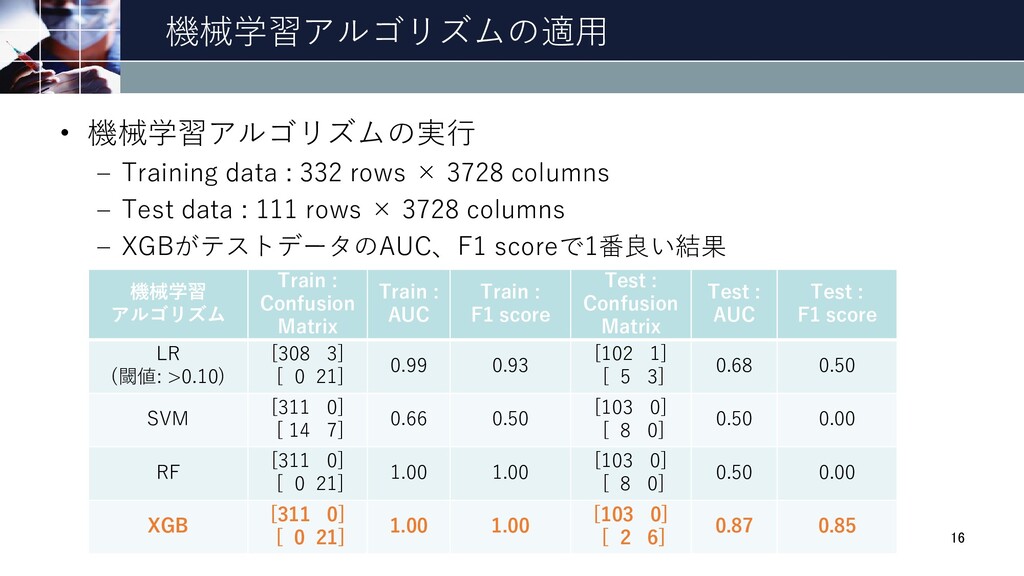
機械学習アルゴリズムの適用 機械学習 アルゴリズム Train : Confusion Matrix Train : AUC
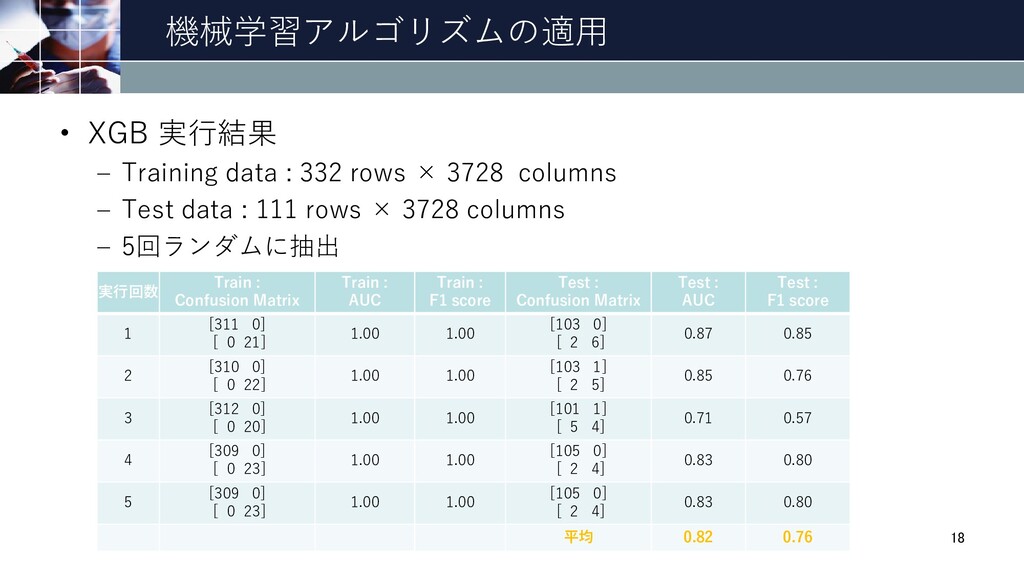
Train : F1 score Test : Confusion Matrix Test : AUC Test : F1 score LR (閾値: >0.10) [308 3] [ 0 21] 0.99 0.93 [102 1] [ 5 3] 0.68 0.50 SVM [311 0] [ 14 7] 0.66 0.50 [103 0] [ 8 0] 0.50 0.00 RF [311 0] [ 0 21] 1.00 1.00 [103 0] [ 8 0] 0.50 0.00 XGB [311 0] [ 0 21] 1.00 1.00 [103 0] [ 2 6] 0.87 0.85 • 機械学習アルゴリズムの実行 – Training data : 332 rows × 3728 columns – Test data : 111 rows × 3728 columns – XGBがテストデータのAUC、F1 scoreで1番良い結果 16
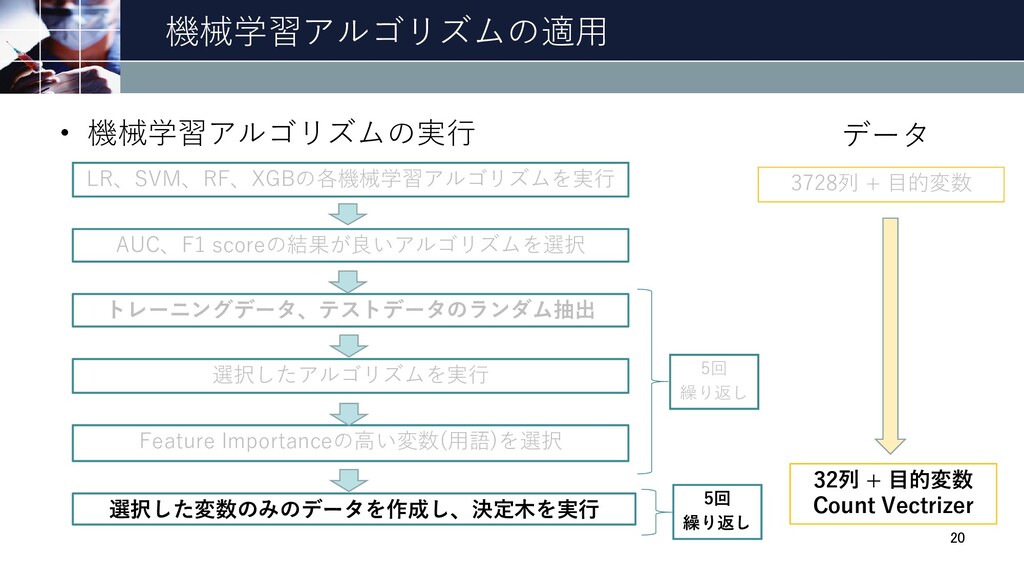
機械学習アルゴリズムの適用 LR、SVM、RF、XGBの各機械学習アルゴリズムを実行 • 機械学習アルゴリズムの実行 AUC、F1 scoreの結果が良いアルゴリズムを選択 トレーニングデータ、テストデータのランダム抽出 選択したアルゴリズムを実行 Feature Importanceの高い変数(用語)を選択
選択した変数のみのデータを作成し、決定木を実行 17 5回 繰り返し 5回 繰り返し データ 3728列 + 目的変数 32列 + 目的変数 Count Vectrizer
機械学習アルゴリズムの適用 実行回数 Train : Confusion Matrix Train : AUC Train
: F1 score Test : Confusion Matrix Test : AUC Test : F1 score 1 [311 0] [ 0 21] 1.00 1.00 [103 0] [ 2 6] 0.87 0.85 2 [310 0] [ 0 22] 1.00 1.00 [103 1] [ 2 5] 0.85 0.76 3 [312 0] [ 0 20] 1.00 1.00 [101 1] [ 5 4] 0.71 0.57 4 [309 0] [ 0 23] 1.00 1.00 [105 0] [ 2 4] 0.83 0.80 5 [309 0] [ 0 23] 1.00 1.00 [105 0] [ 2 4] 0.83 0.80 平均 0.82 0.76 • XGB 実行結果 – Training data : 332 rows × 3728 columns – Test data : 111 rows × 3728 columns – 5回ランダムに抽出 18
機械学習アルゴリズムの適用 • XGBを5回繰り返し実行 • それぞれの回でFeature Importance (Gain)が1.0以上、かつ解釈可能な用語 を選択 • 32語選択
• Gain >= 1.0以上 : 43語 • 解釈が難しい用語11語を削除 (b, l, 以外, 検討, 後, 国内, 情報, 成績, 等, 副作用, 臨床) ×5回分の結果分 実行毎に異なる結果分 19
機械学習アルゴリズムの適用 LR、SVM、RF、XGBの各機械学習アルゴリズムを実行 • 機械学習アルゴリズムの実行 AUC、F1 scoreの結果が良いアルゴリズムを選択 トレーニングデータ、テストデータのランダム抽出 選択したアルゴリズムを実行 Feature Importanceの高い変数(用語)を選択
選択した変数のみのデータを作成し、決定木を実行 20 5回 繰り返し 5回 繰り返し データ 3728列 + 目的変数 32列 + 目的変数 Count Vectrizer
機械学習アルゴリズムの適用 21 • 単語文書行列 • Count vectrizerによる変換 • 32列+目的変数
機械学習アルゴリズムの適用 実行回数 Train : Confusion Matrix Train : AUC Train
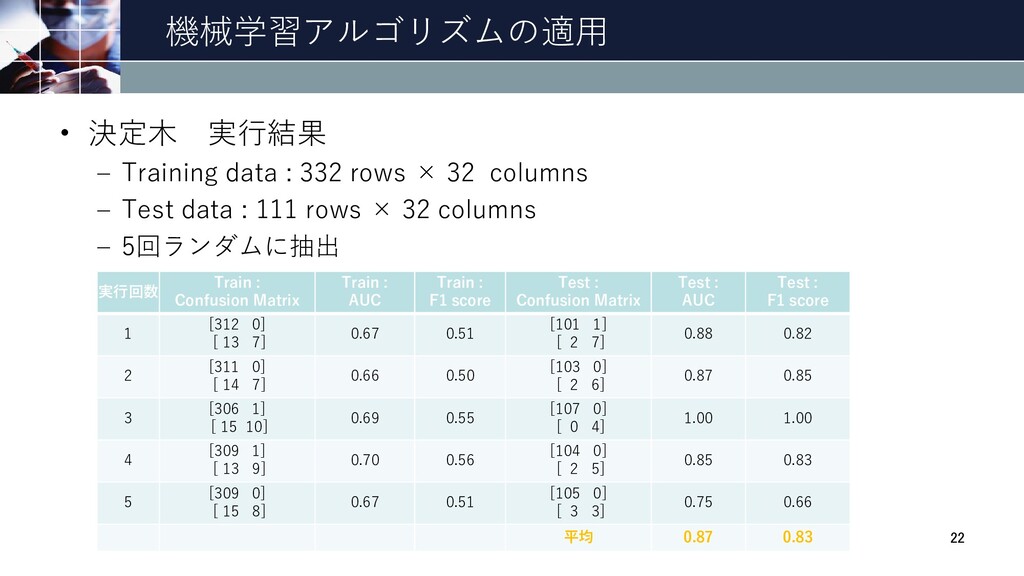
: F1 score Test : Confusion Matrix Test : AUC Test : F1 score 1 [312 0] [ 13 7] 0.67 0.51 [101 1] [ 2 7] 0.88 0.82 2 [311 0] [ 14 7] 0.66 0.50 [103 0] [ 2 6] 0.87 0.85 3 [306 1] [ 15 10] 0.69 0.55 [107 0] [ 0 4] 1.00 1.00 4 [309 1] [ 13 9] 0.70 0.56 [104 0] [ 2 5] 0.85 0.83 5 [309 0] [ 15 8] 0.67 0.51 [105 0] [ 3 3] 0.75 0.66 平均 0.87 0.83 • 決定木 実行結果 – Training data : 332 rows × 32 columns – Test data : 111 rows × 32 columns – 5回ランダムに抽出 22
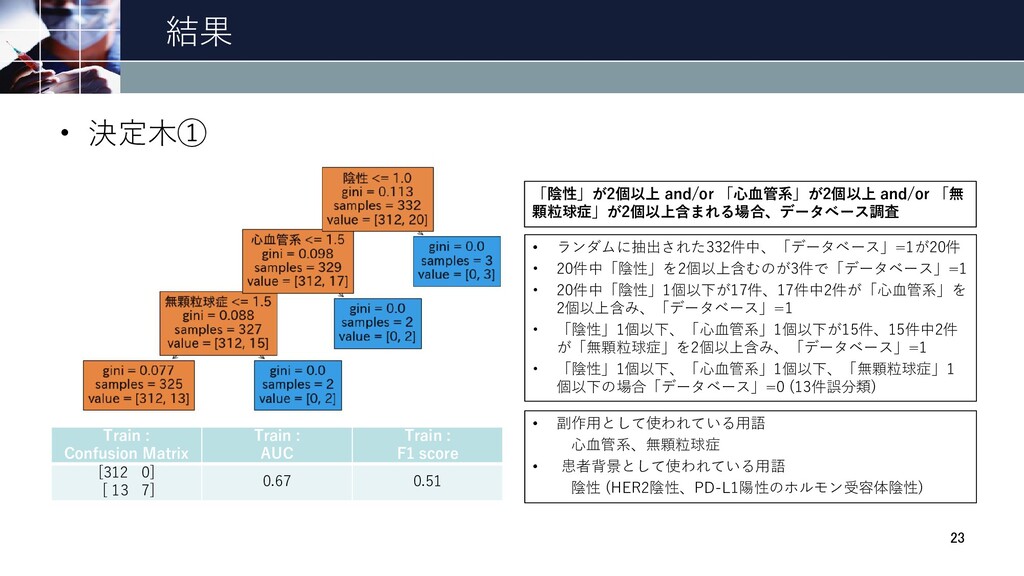
結果 • 決定木① 23 • ランダムに抽出された332件中、「データベース」=1が20件 • 20件中「陰性」を2個以上含むのが3件で「データベース」=1 • 20件中「陰性」1個以下が17件、17件中2件が「心血管系」を
2個以上含み、「データベース」=1 • 「陰性」1個以下、「心血管系」1個以下が15件、15件中2件 が「無顆粒球症」を2個以上含み、「データベース」=1 • 「陰性」1個以下、「心血管系」1個以下、「無顆粒球症」1 個以下の場合「データベース」=0 (13件誤分類) • 副作用として使われている用語 心血管系、無顆粒球症 • 患者背景として使われている用語 陰性 (HER2陰性、PD-L1陽性のホルモン受容体陰性) Train : Confusion Matrix Train : AUC Train : F1 score [312 0] [ 13 7] 0.67 0.51 「陰性」が2個以上 and/or 「心血管系」が2個以上 and/or 「無 顆粒球症」が2個以上含まれる場合、データベース調査
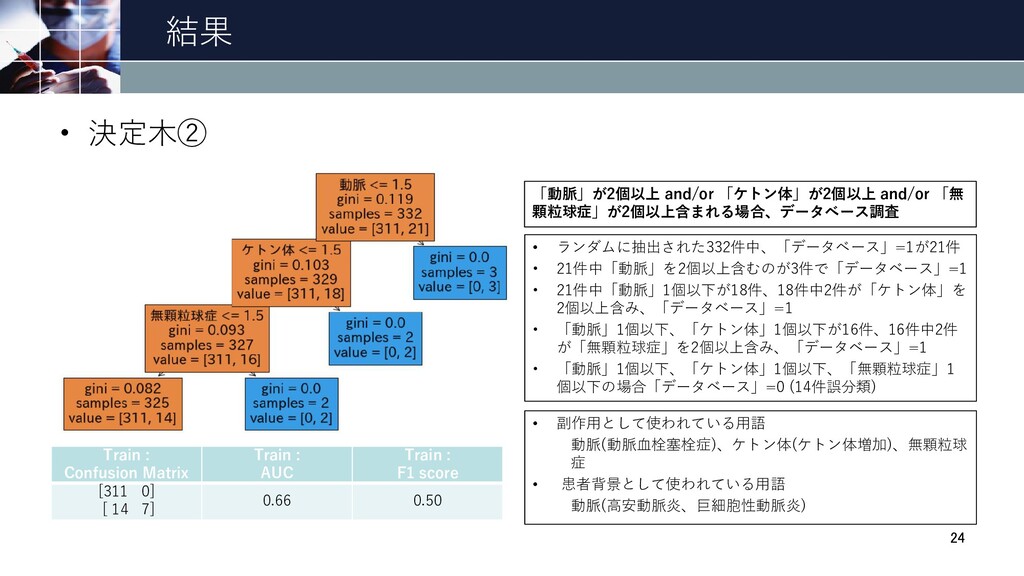
結果 • 決定木② 24 Train : Confusion Matrix Train :
AUC Train : F1 score [311 0] [ 14 7] 0.66 0.50 • ランダムに抽出された332件中、「データベース」=1が21件 • 21件中「動脈」を2個以上含むのが3件で「データベース」=1 • 21件中「動脈」1個以下が18件、18件中2件が「ケトン体」を 2個以上含み、「データベース」=1 • 「動脈」1個以下、「ケトン体」1個以下が16件、16件中2件 が「無顆粒球症」を2個以上含み、「データベース」=1 • 「動脈」1個以下、「ケトン体」1個以下、「無顆粒球症」1 個以下の場合「データベース」=0 (14件誤分類) • 副作用として使われている用語 動脈(動脈血栓塞栓症)、ケトン体(ケトン体増加)、無顆粒球 症 • 患者背景として使われている用語 動脈(高安動脈炎、巨細胞性動脈炎) 「動脈」が2個以上 and/or 「ケトン体」が2個以上 and/or 「無 顆粒球症」が2個以上含まれる場合、データベース調査
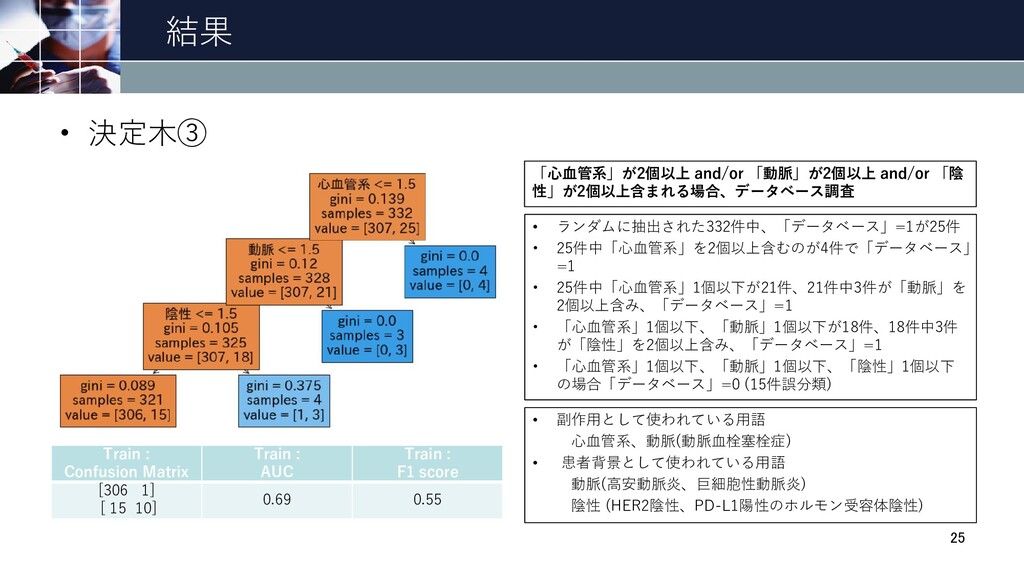
結果 • 決定木③ 25 Train : Confusion Matrix Train :
AUC Train : F1 score [306 1] [ 15 10] 0.69 0.55 • ランダムに抽出された332件中、「データベース」=1が25件 • 25件中「心血管系」を2個以上含むのが4件で「データベース」 =1 • 25件中「心血管系」1個以下が21件、21件中3件が「動脈」を 2個以上含み、「データベース」=1 • 「心血管系」1個以下、「動脈」1個以下が18件、18件中3件 が「陰性」を2個以上含み、「データベース」=1 • 「心血管系」1個以下、「動脈」1個以下、「陰性」1個以下 の場合「データベース」=0 (15件誤分類) • 副作用として使われている用語 心血管系、動脈(動脈血栓塞栓症) • 患者背景として使われている用語 動脈(高安動脈炎、巨細胞性動脈炎) 陰性 (HER2陰性、PD-L1陽性のホルモン受容体陰性) 「心血管系」が2個以上 and/or 「動脈」が2個以上 and/or 「陰 性」が2個以上含まれる場合、データベース調査
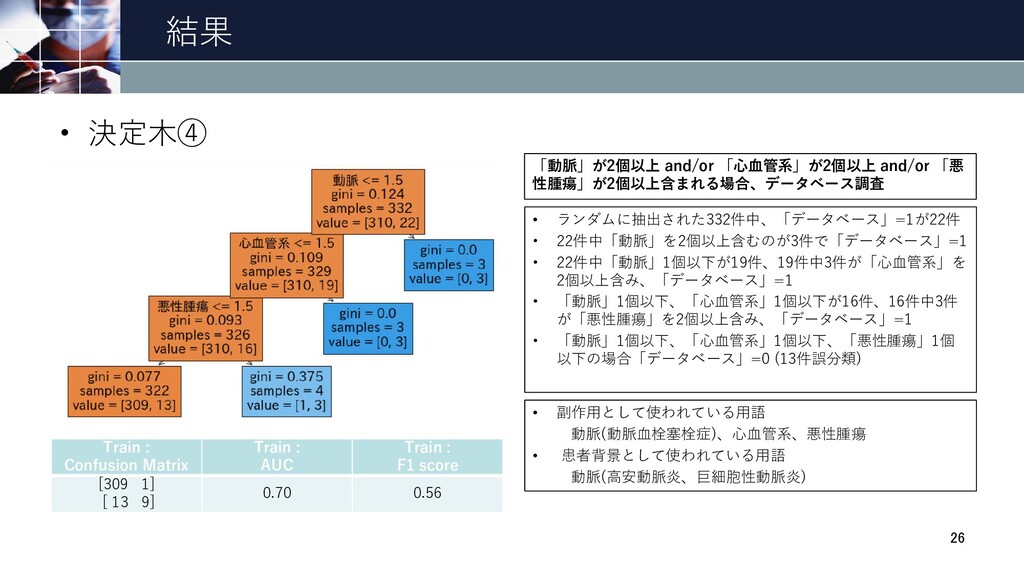
結果 • 決定木④ 26 Train : Confusion Matrix Train :
AUC Train : F1 score [309 1] [ 13 9] 0.70 0.56 • ランダムに抽出された332件中、「データベース」=1が22件 • 22件中「動脈」を2個以上含むのが3件で「データベース」=1 • 22件中「動脈」1個以下が19件、19件中3件が「心血管系」を 2個以上含み、「データベース」=1 • 「動脈」1個以下、「心血管系」1個以下が16件、16件中3件 が「悪性腫瘍」を2個以上含み、「データベース」=1 • 「動脈」1個以下、「心血管系」1個以下、「悪性腫瘍」1個 以下の場合「データベース」=0 (13件誤分類) • 副作用として使われている用語 動脈(動脈血栓塞栓症)、心血管系、悪性腫瘍 • 患者背景として使われている用語 動脈(高安動脈炎、巨細胞性動脈炎) 「動脈」が2個以上 and/or 「心血管系」が2個以上 and/or 「悪 性腫瘍」が2個以上含まれる場合、データベース調査
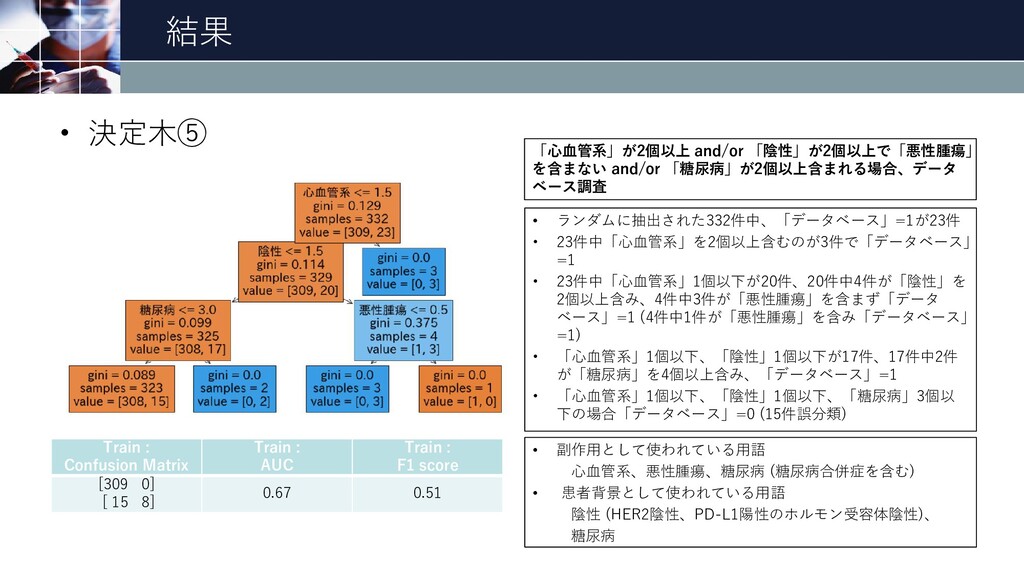
結果 • 決定木⑤ 27 Train : Confusion Matrix Train :
AUC Train : F1 score [309 0] [ 15 8] 0.67 0.51 • ランダムに抽出された332件中、「データベース」=1が23件 • 23件中「心血管系」を2個以上含むのが3件で「データベース」 =1 • 23件中「心血管系」1個以下が20件、20件中4件が「陰性」を 2個以上含み、4件中3件が「悪性腫瘍」を含まず「データ ベース」=1 (4件中1件が「悪性腫瘍」を含み「データベース」 =1) • 「心血管系」1個以下、「陰性」1個以下が17件、17件中2件 が「糖尿病」を4個以上含み、「データベース」=1 • 「心血管系」1個以下、「陰性」1個以下、「糖尿病」3個以 下の場合「データベース」=0 (15件誤分類) • 副作用として使われている用語 心血管系、悪性腫瘍、糖尿病 (糖尿病合併症を含む) • 患者背景として使われている用語 陰性 (HER2陰性、PD-L1陽性のホルモン受容体陰性)、 糖尿病 「心血管系」が2個以上 and/or 「陰性」が2個以上で「悪性腫瘍」 を含まない and/or 「糖尿病」が2個以上含まれる場合、データ ベース調査
まとめ • RMPの概要ページ(P1)を抽出し、テキストデータの作成ができた • テキストデータを自然言語処理することにより、予測モデルの作成ができた (決定木) – 「陰性」「心血管系」「無顆粒球症」 – 「動脈」「ケトン体」「無顆粒球症」
– 「心血管系」「動脈」「陰性」 – 「動脈」「心血管系」「悪性腫瘍」 – 「心血管系」「陰性」「糖尿病」 • テストデータの平均でAUC : 0.87、F1 score : 0.83の予測精度が得られた 28
ビジネス活用 • RMPの概要ページ(P1)のドラフトができれば、自然言語処理を行 い、データベース調査が採用される見込みがあるかどうかの予測 ができるようになった • 追加の安全性監視活動をどのようにするか、判断のサポートとし て期待 29
今後の課題 • 運用上の課題 – 予測モデルの共有化 • ダッシュボード (本資料巻末に掲載) • 半期、4半期等、定期的な更新
– 評価 • 社内担当者や業界内勉強会で意見聴取 • データベース調査採用への貢献 30
今後の課題 • 技術的な課題 – 特徴量選択 (変数として使用する用語の選択) • Feature Importanceは本来変数を削減してから算出すべき •
多重共線性がある用語の一方が落とされ、大事な用語を失っている可能性があるこ とを踏まえた特徴量選択方法を検討する必要がある – 形態素解析 • 専門用語が細かく「分かち書き」されてしまうことを踏まえた対策の検討 – データ作成 • 患者背景、薬効、リスク(副作用)といった情報で整形されたデータの作成 31
32
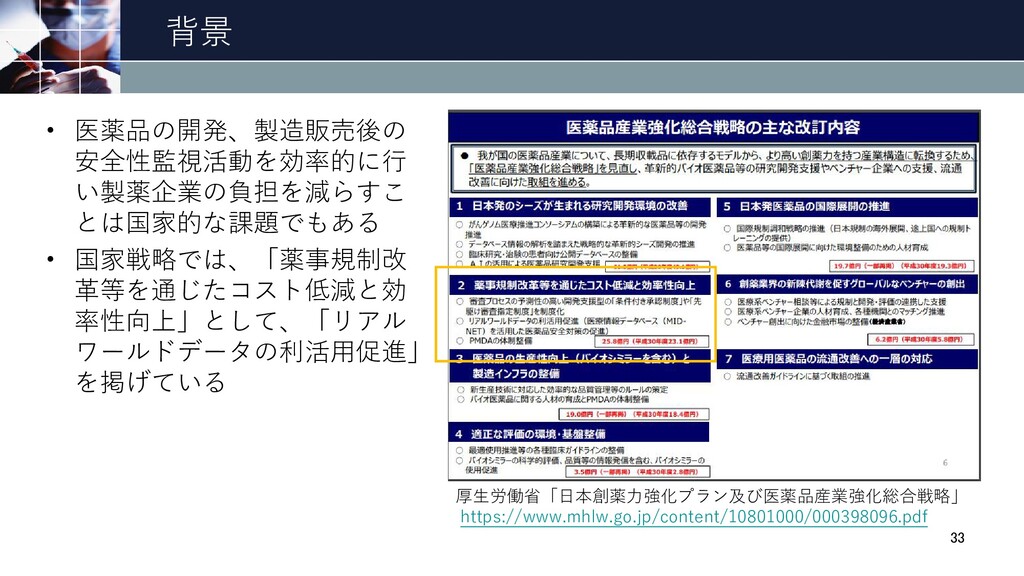
背景 • 医薬品の開発、製造販売後の 安全性監視活動を効率的に行 い製薬企業の負担を減らすこ とは国家的な課題でもある • 国家戦略では、「薬事規制改 革等を通じたコスト低減と効 率性向上」として、「リアル
ワールドデータの利活用促進」 を掲げている 厚生労働省「日本創薬力強化プラン及び医薬品産業強化総合戦略」 https://www.mhlw.go.jp/content/10801000/000398096.pdf 33
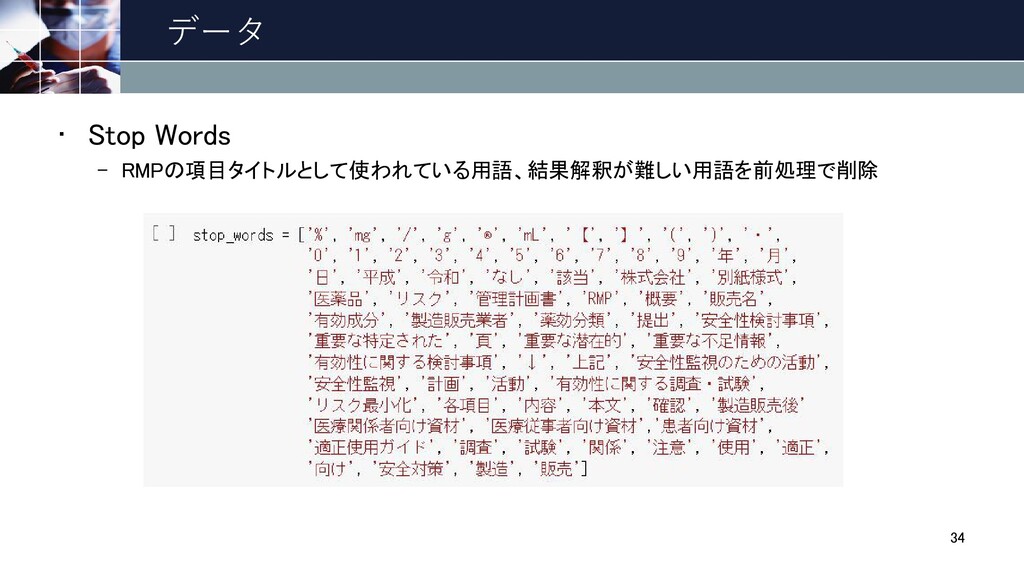
データ • Stop Words – RMPの項目タイトルとして使われている用語、結果解釈が難しい用語を前処理で削除 34
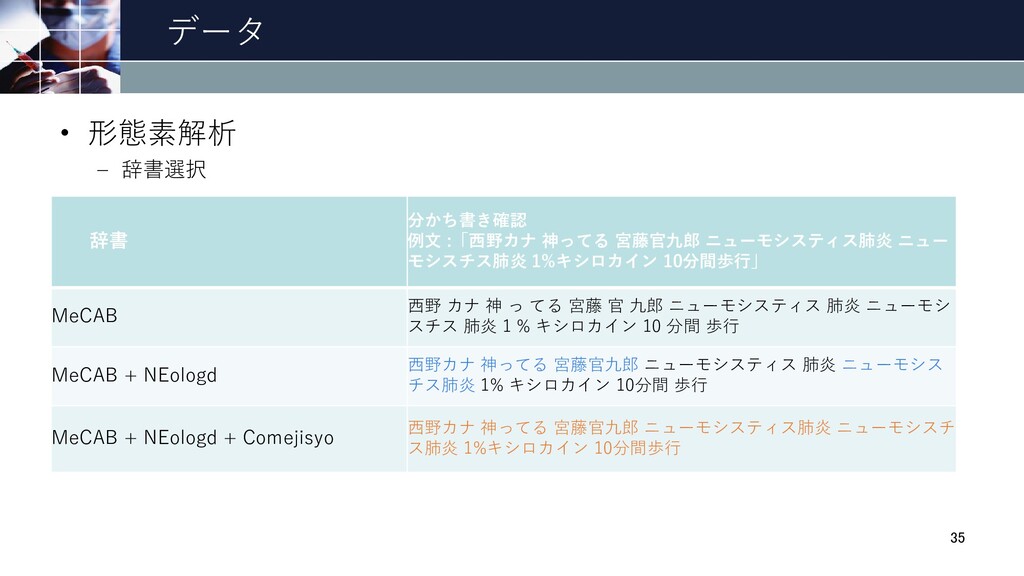
データ • 形態素解析 – 辞書選択 辞書 分かち書き確認 例文 :「西野カナ 神ってる
宮藤官九郎 ニューモシスティス肺炎 ニュー モシスチス肺炎 1%キシロカイン 10分間歩行」 MeCAB 西野 カナ 神 っ てる 宮藤 官 九郎 ニューモシスティス 肺炎 ニューモシ スチス 肺炎 1 % キシロカイン 10 分間 歩行 MeCAB + NEologd 西野カナ 神ってる 宮藤官九郎 ニューモシスティス 肺炎 ニューモシス チス肺炎 1% キシロカイン 10分間 歩行 MeCAB + NEologd + Comejisyo 西野カナ 神ってる 宮藤官九郎 ニューモシスティス肺炎 ニューモシスチ ス肺炎 1%キシロカイン 10分間歩行 35
工夫したところ • 443レコード、3729列のアンバランスなデータの取り扱い • 機械学習アルゴリズムの実行を3段階に分けた Ø 1段階目で機械学習アルゴリズムの選択 Ø 2段階目でXGBによる用語選択 Ø
3段階目で決定木による予測モデル作成 • トレーニング、テストの抽出ごとに、機械学習アルゴリズムの実 行結果が異なった • 2段階目、3段階目の実行を5回繰り返し行い、結果をまとめた 36
苦労したところ • PDFの取り扱い • PyPDF2で読めないPDFがあり、errorが続いた Ø 一つひとつ読めないPDFを特定し、Googleドキュメントでテキスト化した • 形態素解析辞書のインストール •
ComejisyoがWindows版Anacondaで使用できなかった • 最終的にはGoogle Coraboratery上でユーザー辞書として読み込んだ • 日本語の取り扱い • そもそもPDFや形態素解析辞書の問題も日本語コード体系の違いに原因があるのでは • Feature importanceや決定木の日本語表示 Ø japanize-matplotlibをインストールして対応 37
参考資料 DataMix 「データサイエンティスト育成コース」の講義資料、プログラム以外で参考にした資料 • 厚生労働省「医薬品産業の現状と課題」 「日本創薬力強化プラン及び医薬品産業強化総合戦略」 https://www.mhlw.go.jp/content/10801000/000398096.pdf • 日本薬剤師会「3分でわかる!RMP講座」 https://www.nichiyaku.or.jp/assets/uploads/pharmacy-info/rmp.pdf
• 独立行政法人 医薬品医療機器総合機構 (PMDA) https://www.pmda.go.jp/safety/info-services/drugs/items-information/rmp/0001.html • "Automate boring stuff with Python" p.304 - p.305 • 「日経ソフトウェア 2020年3月号」p.58 - p.69 「特集4 Python X PDF活用術」 • 「日経ソフトウェア 2019年1月号」p.6 - p.27 「特集1 機械学習のプロセス徹底解説」 • 「電子医療記録の分ち書き用ユーザ辞書 ComeJisyo の紹介と単語生起コスト」 https://www.anlp.jp/proceedings/annual_meeting/2012/pdf_dir/C3-7.pdf • Comejisyo プロジェクト日本語トップ https://ja.osdn.net/projects/comedic/ • TECH BLOG by GMO 「MeCabへユーザー辞書を追加する方法」https://techblog.gmo-ap.jp/2019/09/18/mecab/ • Qiita「PythonとMecabで特定の品詞の単語だけ取り出す」https://qiita.com/ganariya/items/68fdcfed953f066ad4b7 • CUBE SUGARCONTAINER 「Python: XGBoost を使ってみる」 https://blog.amedama.jp/entry/2019/01/29/235642#%E7%89%B9%E5%BE%B4%E9%87%8F%E3%81%AE%E9%87%8D%E8%A6%81%E5%BA%A6%E3%82%92%E5%8F%AF%E8%A6 %96%E5%8C%96%E3%81%99%E3%82%8B • StatsFragments 「Python XGBoost の変数重要度プロット / 可視化の実装」 http://sinhrks.hatenablog.com/entry/2015/08/27/000235 • Qiita「xgboost で Feature Importance を算出する。」https://qiita.com/daichildren98/items/ebabef57bc19d5624682 • Qiita「[Python]Graphviz不要の決定木可視化ライブラリdtreepltをつくった」https://qiita.com/nekoumei/items/7f2209295515c3aa1053 • 「Kaggleで勝つ データ分析の技術」(技術評論社) p.232 - p.246 「4.3 GBDT(勾配ブースティング木)」 38
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}