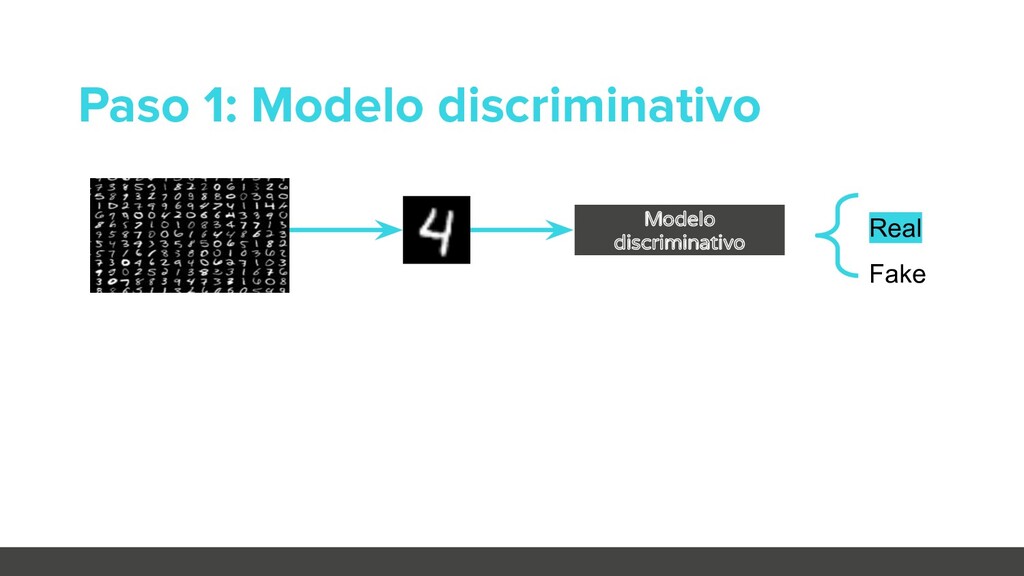
busca que el clasificador ofrezca un resultado incorrecto Orientado Más difícil Busca obtener una clase específica Caja blanca Tenemos acceso al modelo: • Arquitectura • Parametrización • Datos de entrenamiento Caja negra Sólo disponemos de la salida del modelo
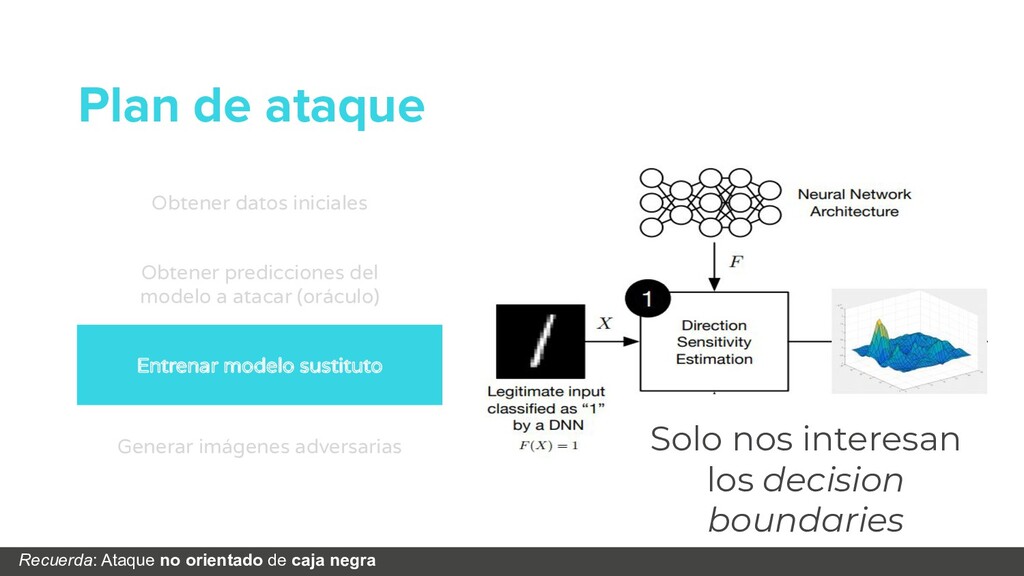
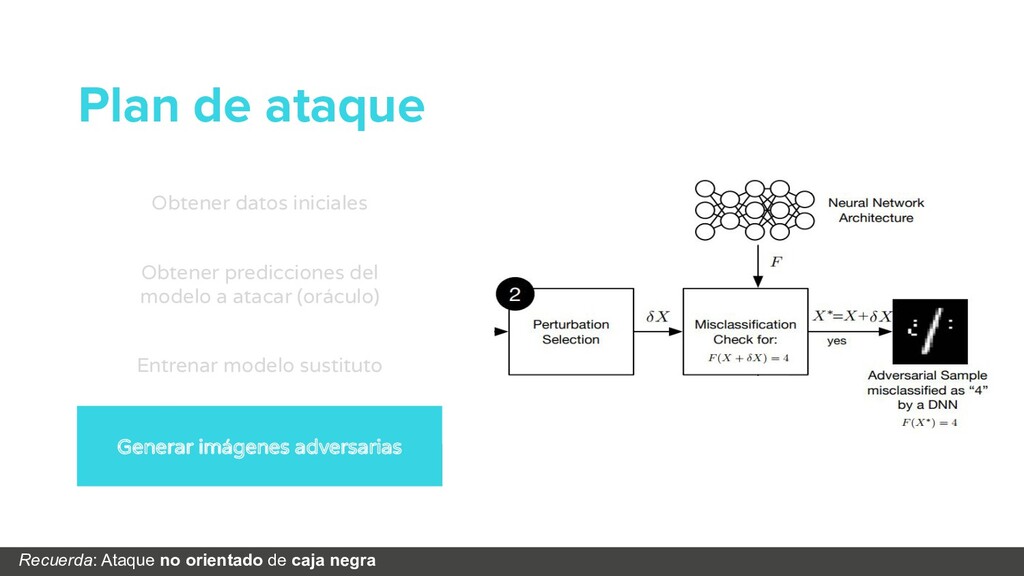
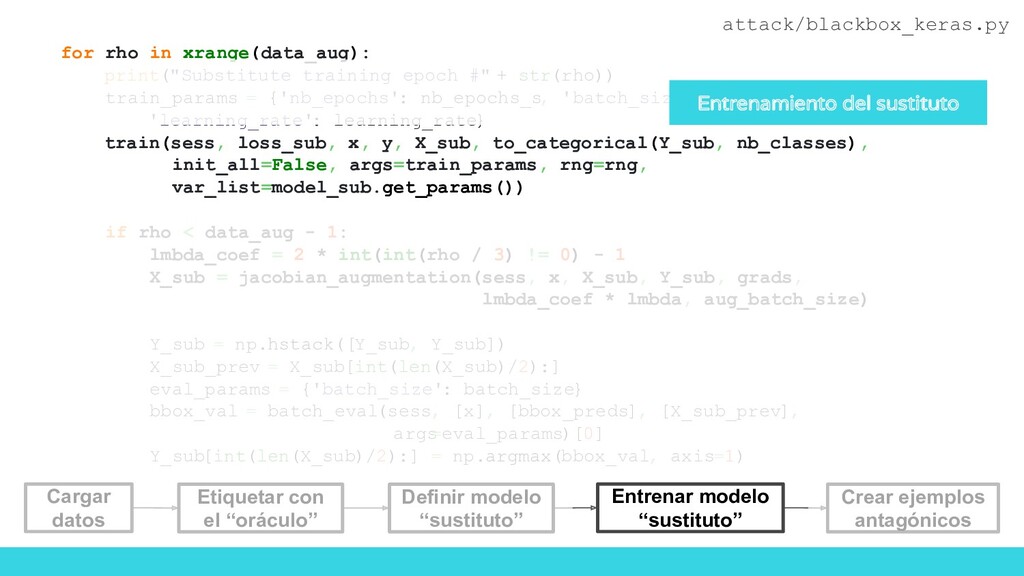
Obtener datos iniciales Obtener predicciones del modelo a atacar (oráculo) Entrenar modelo sustituto Generar imágenes adversarias Solo nos interesan los decision boundaries
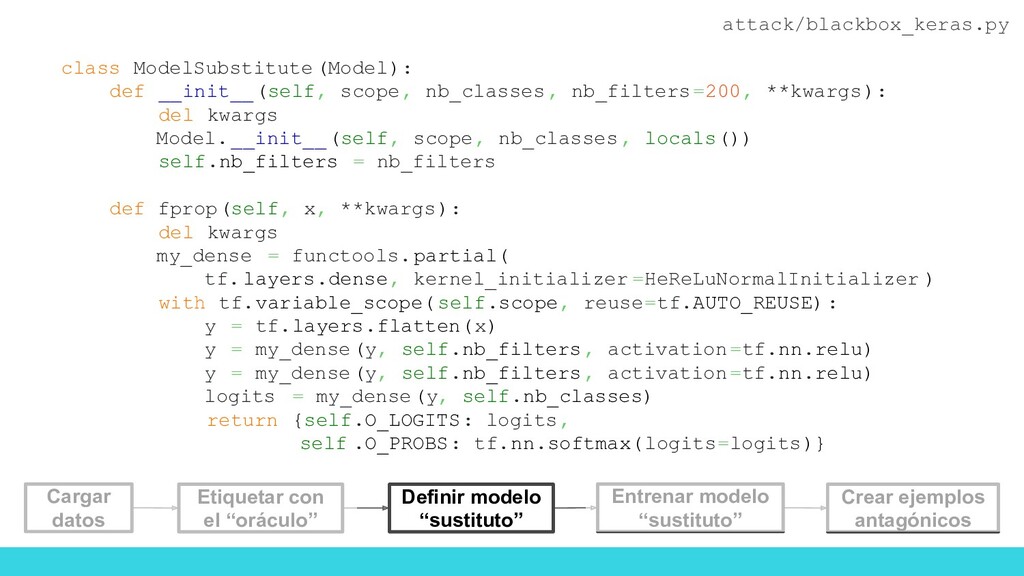
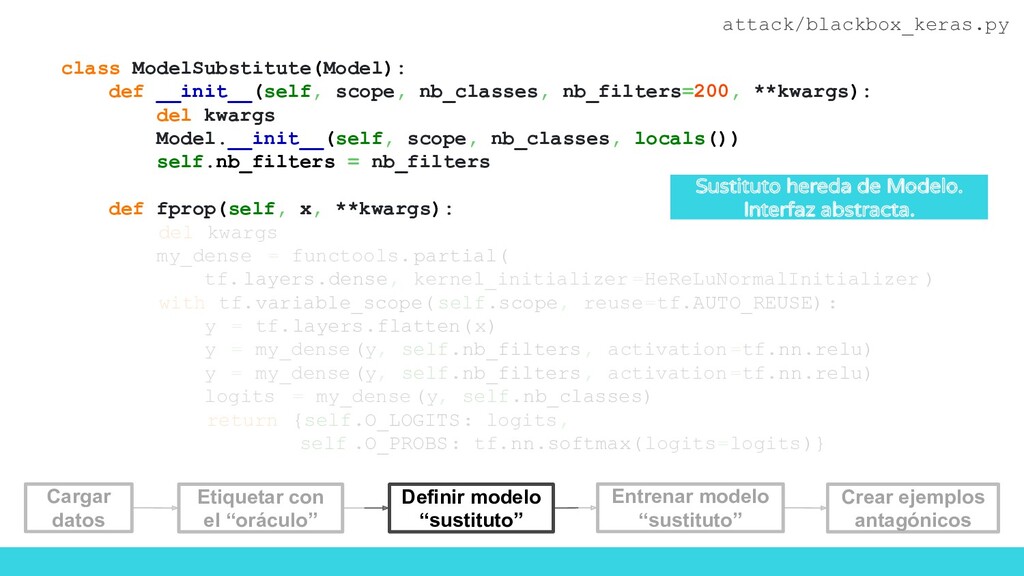
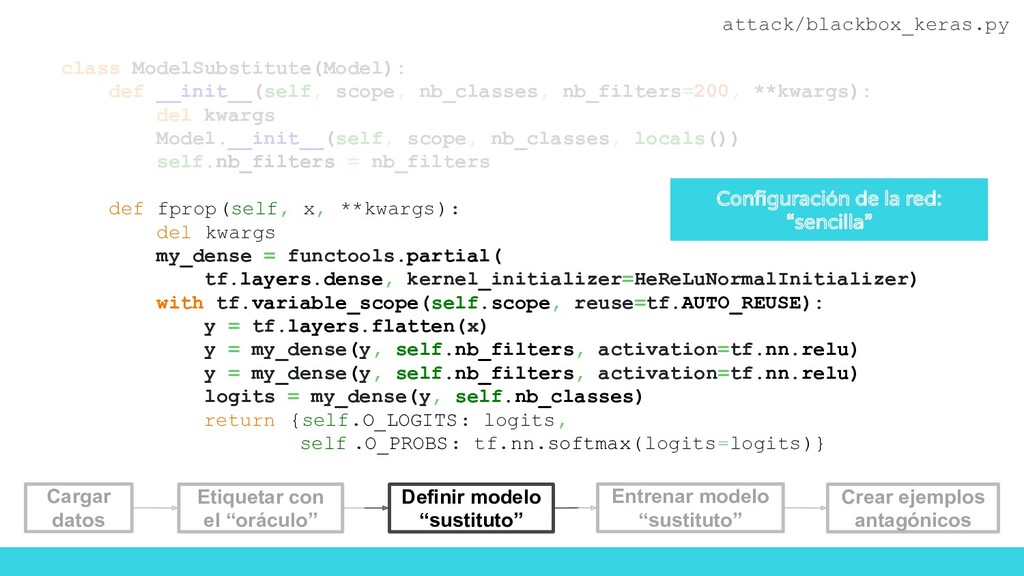
flow_from_directory( '/data/randomfood/training' , target_size =(IM_WIDTH, IM_HEIGHT), batch_size =BATCH_SIZE, ) validation_generator = test_datagen. flow_from_directory( '/data/randomfood/evaluation', target_size =(IM_WIDTH, IM_HEIGHT), batch_size =BATCH_SIZE, ) x_train, y_train = train_generator.next() x_test, y_test = validation_generator.next() # Initialize substitute training set reserved for adversary X_sub = x_test Y_sub = np.argmax(y_test, axis=1) Carga de imágenes Reservamos una parte de los datos para que nos sirvan de test en el modelo sustituto attack/blackbox_keras.py Definir modelo “sustituto” Cargar datos Etiquetar con el “oráculo” Entrenar modelo “sustituto” Crear ejemplos antagónicos
# You could replace this by a remote labeling API for instance Hacemos la llamada para obtener las predicciones Definir modelo “sustituto” Cargar datos Etiquetar con el “oráculo” Entrenar modelo “sustituto” Crear ejemplos antagónicos
en redes de neuronas. No es fácil. ¡Las APIs son vulnerables! Cómo defendernos Estrategia reactiva • Intentar detectar y anular el ataque. • Aumentar el tamaño de las entradas o la complejidad de la red para suponer mayor esfuerzo al sistema atacante. Estrategia proactiva • Crear modelos más robustos a los ataques. • Técnicas relacionadas con el entrenamiento de la red.
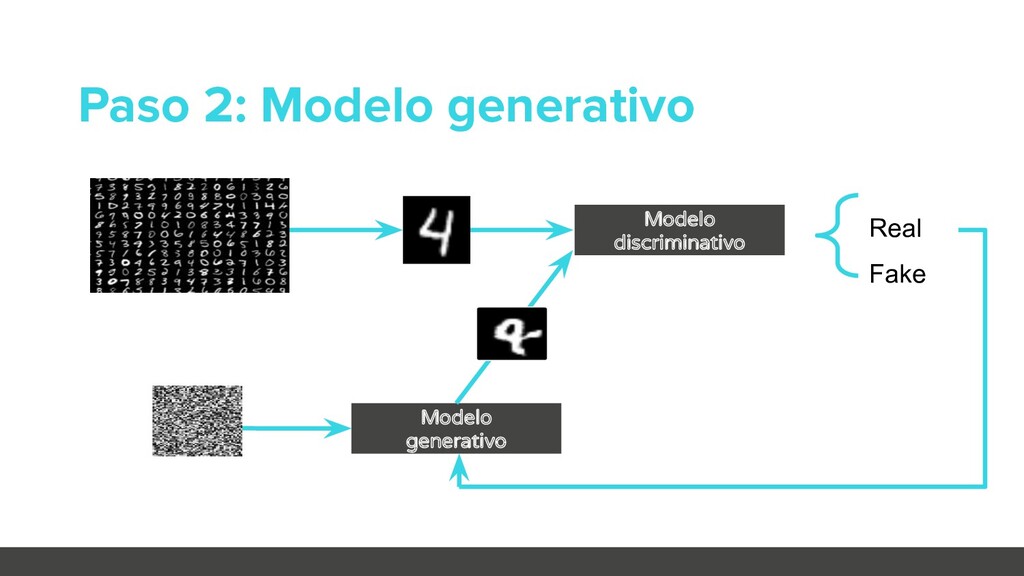
añadiendo ejemplos antagónicos creados por nosotros. Aumenta la robustez del modelo y sirve como factor regularizador. Defensive distillation Aplica el principio de entrar un modelo sustituto para reducir la confianza de las predicciones del sistema. El modelo se entrena sobre distribuciones de probabilidad en vez de etiquetas. Gradient masking Intenta ocultar el gradiente. Se ha demostrado que no es válido. El modelo sustituto lo hace inútil. Estrategias proactivas [source]
la investigación. • Technical AI safety es un campo nuevo, pero con mucho potencial. • Ya presente en empresas como Google DeepMind, con su DeepMind safety team. • Partnerships on AI (+80 socios) también tiene presente la seguridad en AI.
{kind=link}
{kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_2.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_3.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_4.jpg){kind=link}
{kind=link}
![Modelos discriminativos [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_6.jpg){kind=link}
![[source] Extracción de características](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_7.jpg){kind=link}
![[source] Ejemplo con MNIST](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_8.jpg){kind=link}
![[source] Entrada](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_9.jpg){kind=link}
![[source] Conv #1](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_10.jpg){kind=link}
![[source] Conv #3](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_11.jpg){kind=link}
![[source] Salida](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_12.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_13.jpg){kind=link}
![[source] Aprendizaje de características • Inicialización aleatoria de los parámetros](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_14.jpg){kind=link}
![Descenso del gradiente [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_15.jpg){kind=link}
![Descenso del gradiente [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_16.jpg){kind=link}
![Descenso del gradiente [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_17.jpg){kind=link}
![Descenso del gradiente [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_18.jpg){kind=link}
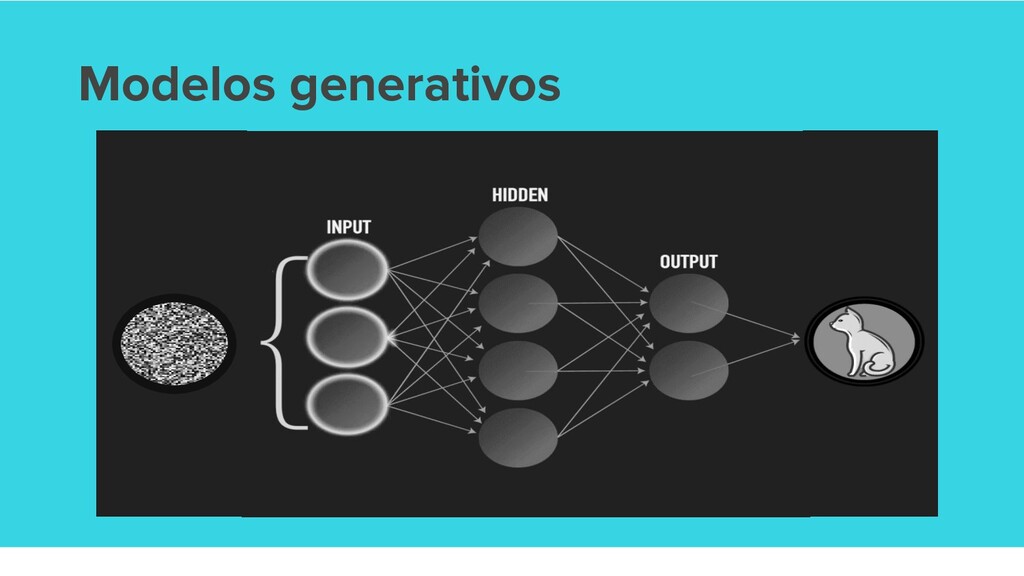
![Modelos discriminativos [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_22.jpg){kind=link}
![Arte - Style Transfer [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fake! Fake! Fake! Fake! Fake! Fake! [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_30.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_31.jpg){kind=link}
![[source] “Everybody Dance Now”](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[source] Modelo discriminativo Categoria Imágenes Bread 1724 Dairy product 721](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
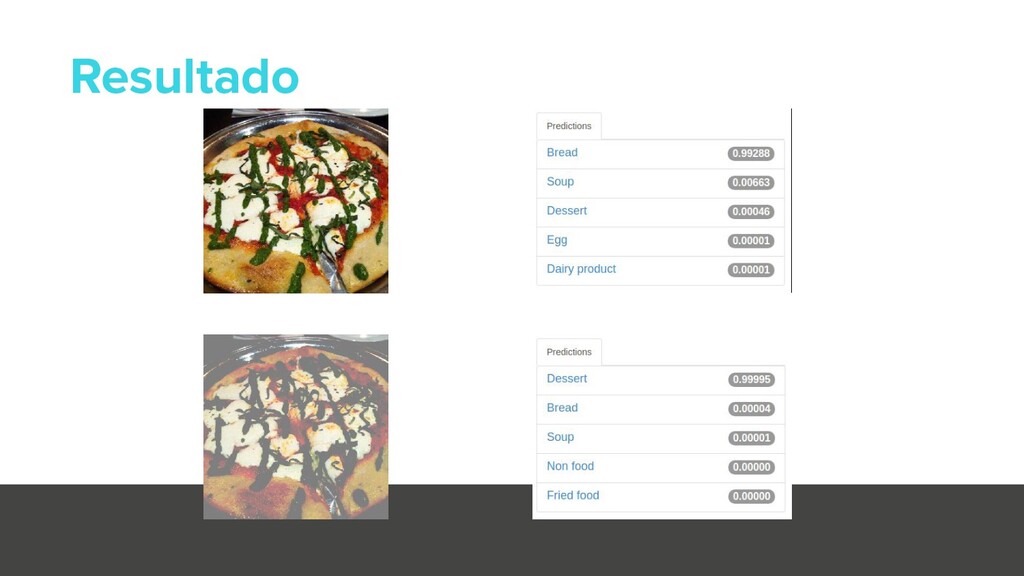{kind=link}
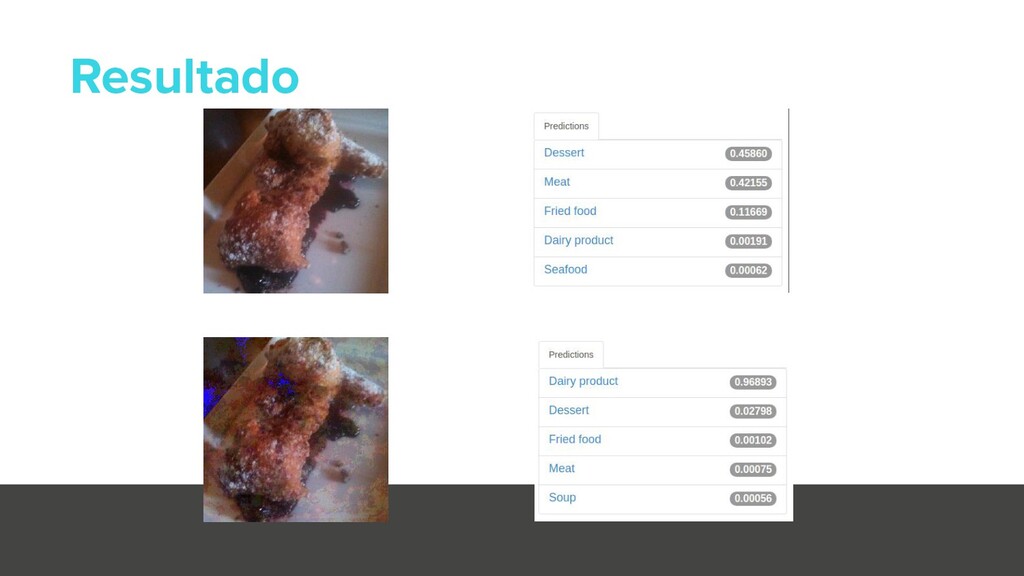{kind=link}
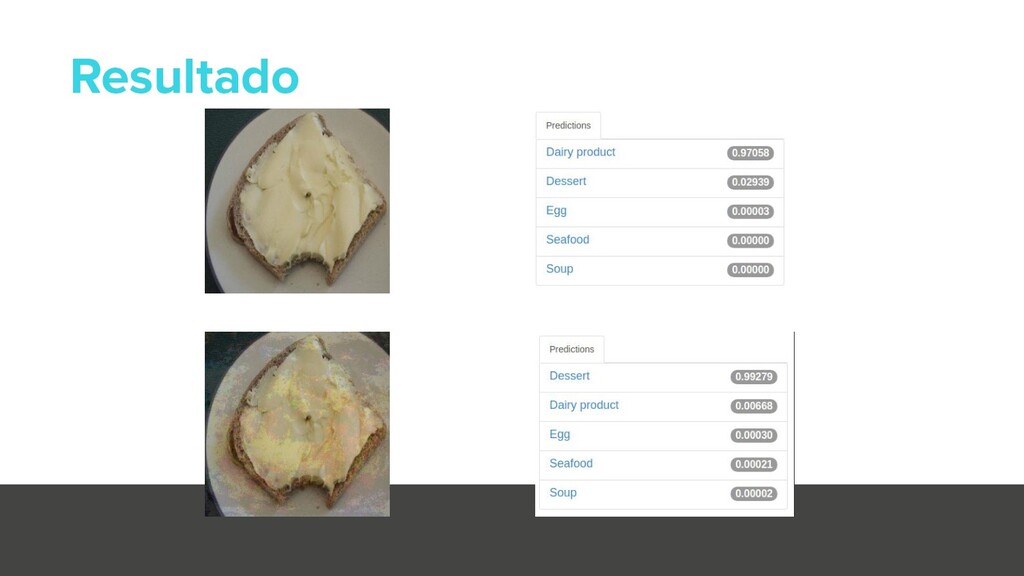{kind=link}
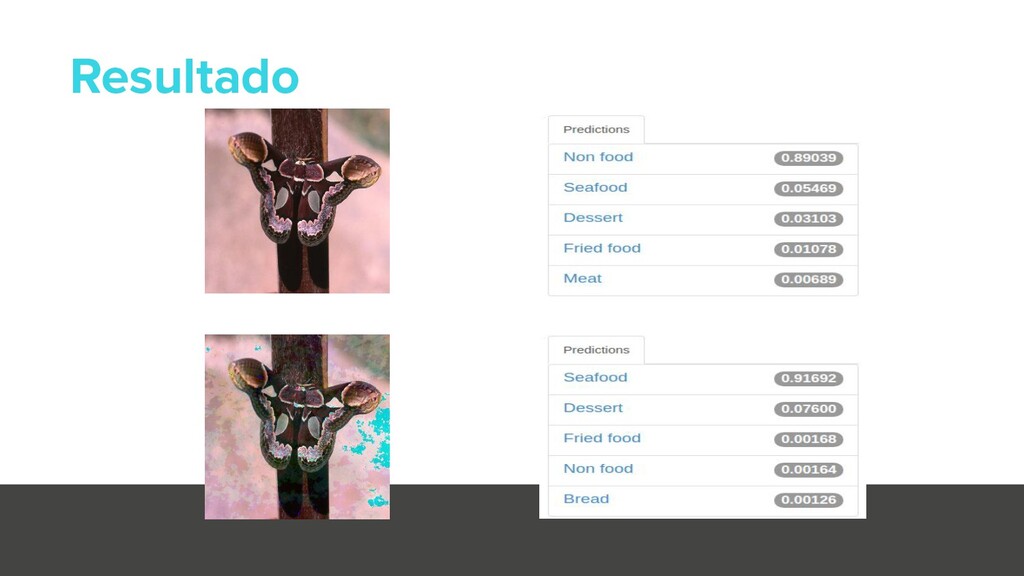{kind=link}
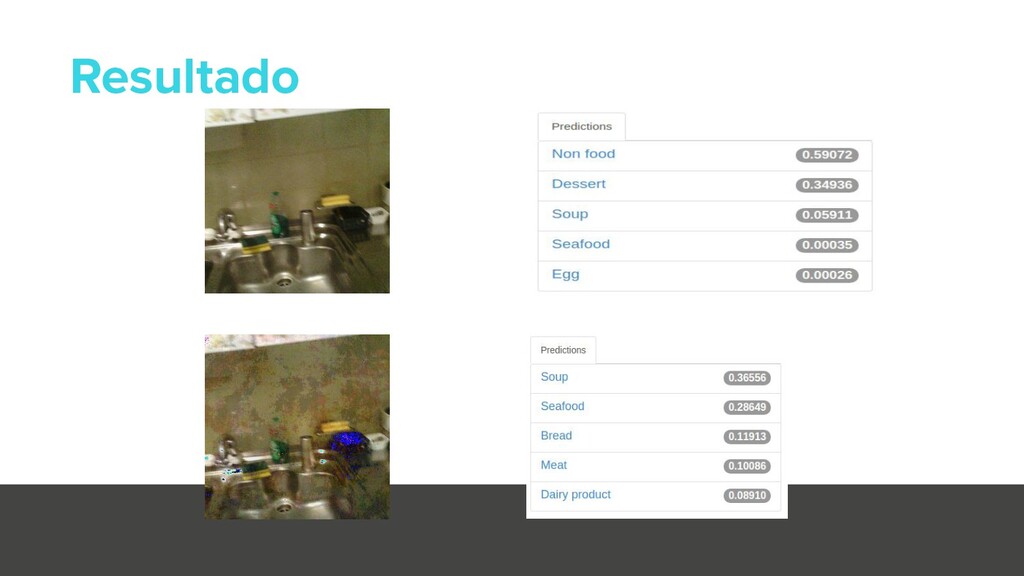{kind=link}
{kind=link}
![Los ataques traspasan lo digital [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_87.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_88.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_89.jpg){kind=link}
![[source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_90.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Estrategias que podemos seguir PROACTIVA REACTIVA [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_95.jpg){kind=link}
![[source] PROACTIVA PROACTIVA](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_96.jpg){kind=link}
![[source] ADVERSARIAL TRAINING DEFENSIVE DISTILLATION PROACTIVA](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_97.jpg){kind=link}
![ADVERSARIAL TRAINING DEFENSIVE DISTILLATION [source]](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_98.jpg){kind=link}
![[source] ADVERSARIAL TRAINING DEFENSIVE DISTILLATION DISCRIMINATIVE 1 P(1) = 1](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_99.jpg){kind=link}
{kind=link}
{kind=link}
![[source] • La IA ya salido del ámbito teórico y](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_102.jpg){kind=link}
![GRACIAS ¿Alguna pregunta? @alipeji | [email protected] @g_Beaa | [email protected] ?](https://files.speakerdeck.com/presentations/e1315eb42a174c0ea454e55183115ca0/slide_103.jpg){kind=link}