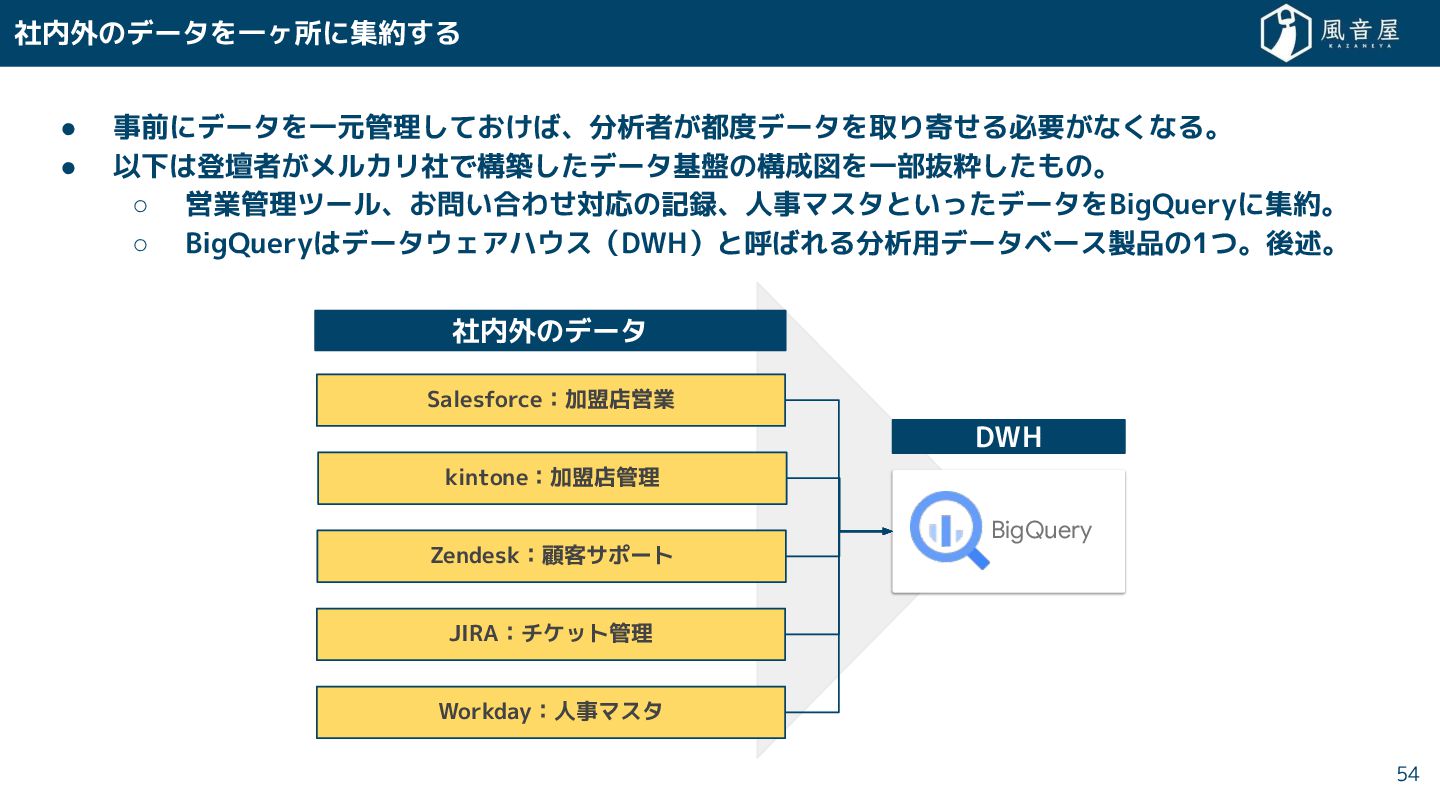
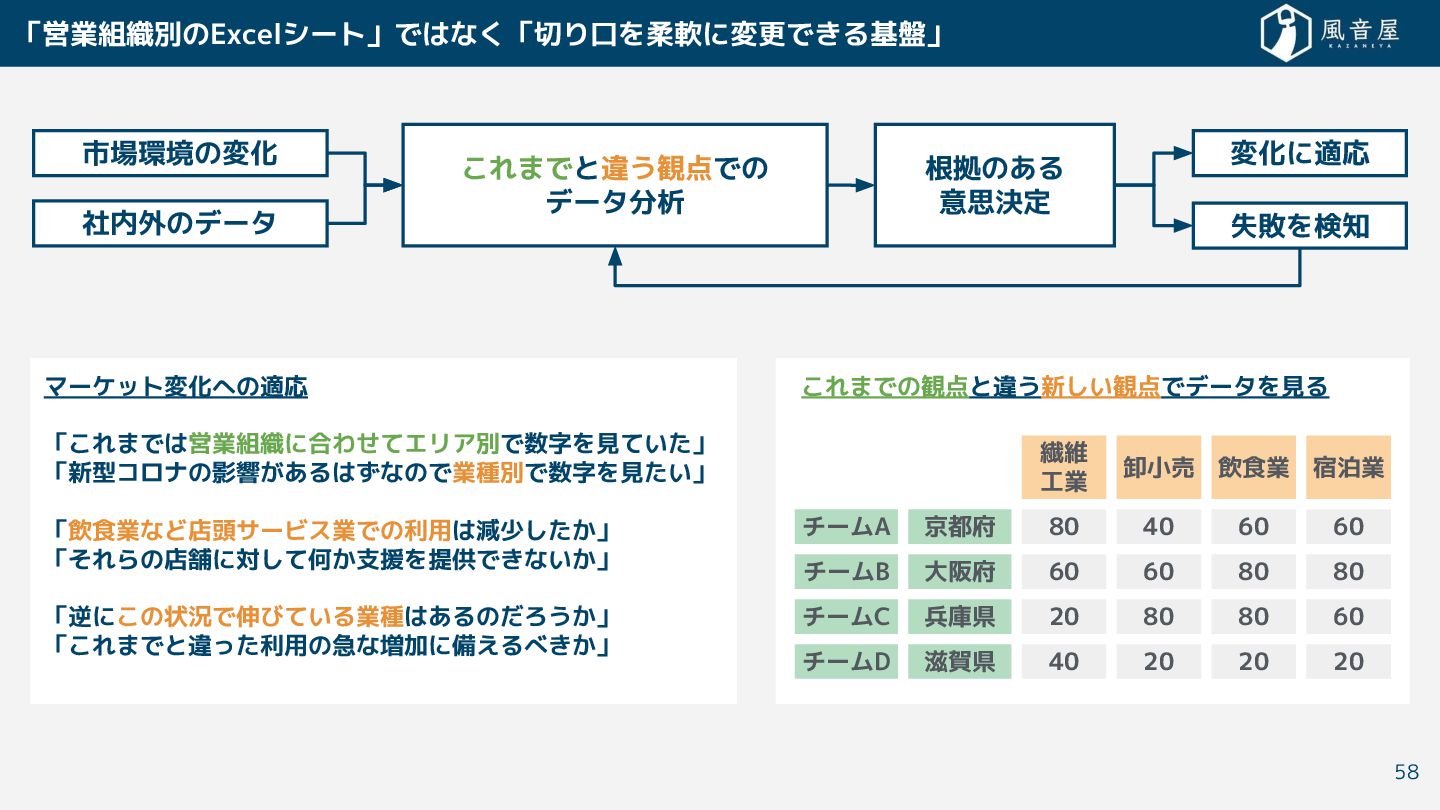
• データ分析者 「 を見れば必要なデータ 揃う」と信頼で る「寄る辺」 必要と れている。 https://techcrunch.com/2017/06/23/five-building-blocks-of-a-data-driven-culture/ ならびに https://jp.techcrunch.com/2017/06/25/20170623five-building-blocks-of-a-data-driven-culture/ ※閉鎖済 事実の単一情報源を持っている場合には、 アナリストや他の意思決定者といっ エンドユーザー に、 優れ 価値を提供 る と で る。 彼らは組織内でデータを探 時間 少な て済むようになり、 データの利用により多 の時間を割 と で るようになる ら 。 When you have a single source of truth,you provide superior value to the end user: the analysts and other decision makers. They’ll spend less time hunting for data across the organization and more time using it. Additionally, the data sources are more likely to be organized, documented and joined. Thus, by providing a richer context about the entities of interest, the users are better positioned to leverage the data and find actionable insights. 53
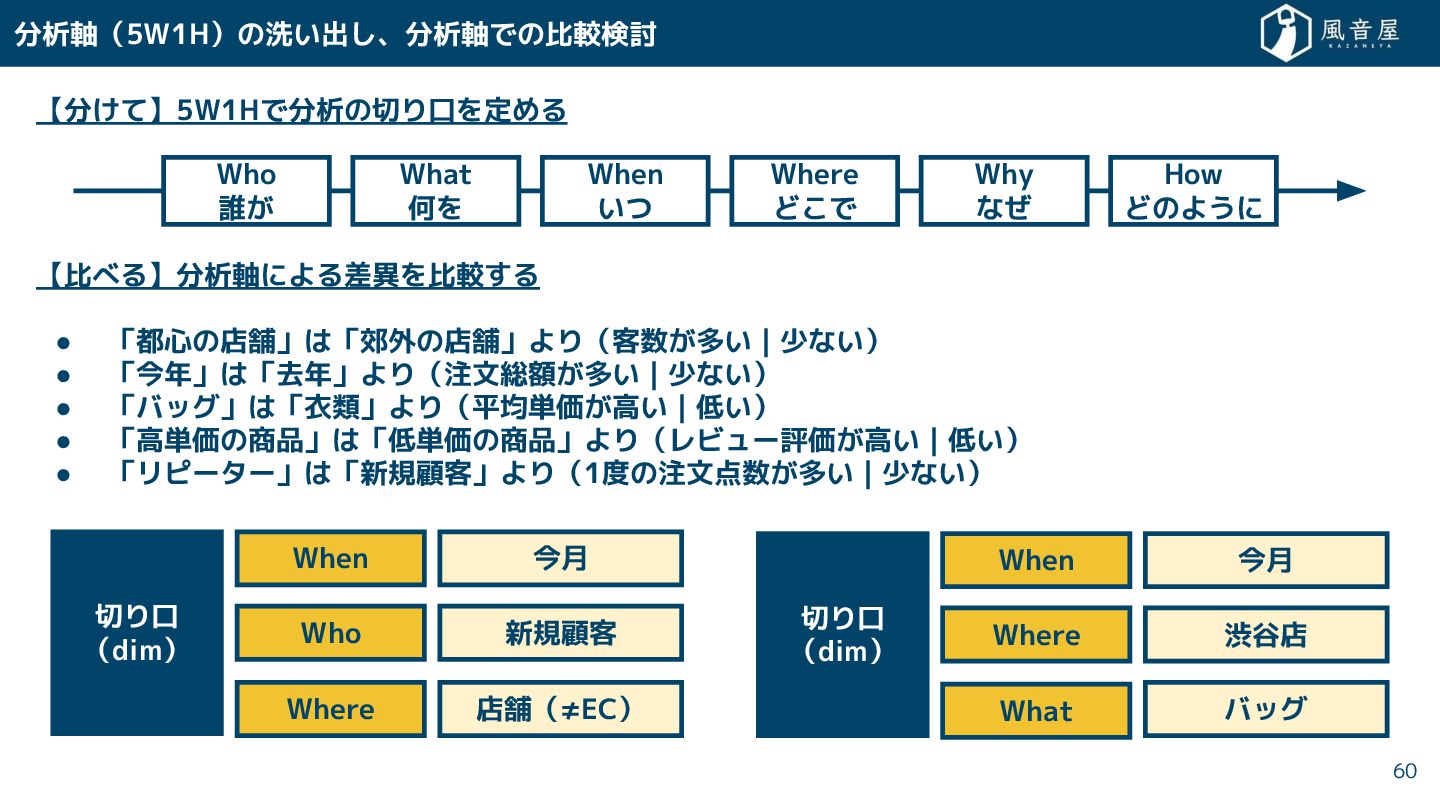
• 「バッグ」は「衣類」より(平均単価 高い|低い) • 「高単価の商品」は「低単価の商品」より(レビュー評価 高い|低い) • 「リピーター」は「新規顧客」より(1度の注文点数 多い|少ない) 分析軸(5W1H)の洗い出 、分析軸での比較検討 60 今月 When 切り口 (dim) Who 新規顧客 今月 When 切り口 (dim) Where 渋谷店 What バッグ Where 店舗(≠EC) Who 誰 What 何を When いつ Where ど で Why な How どのように
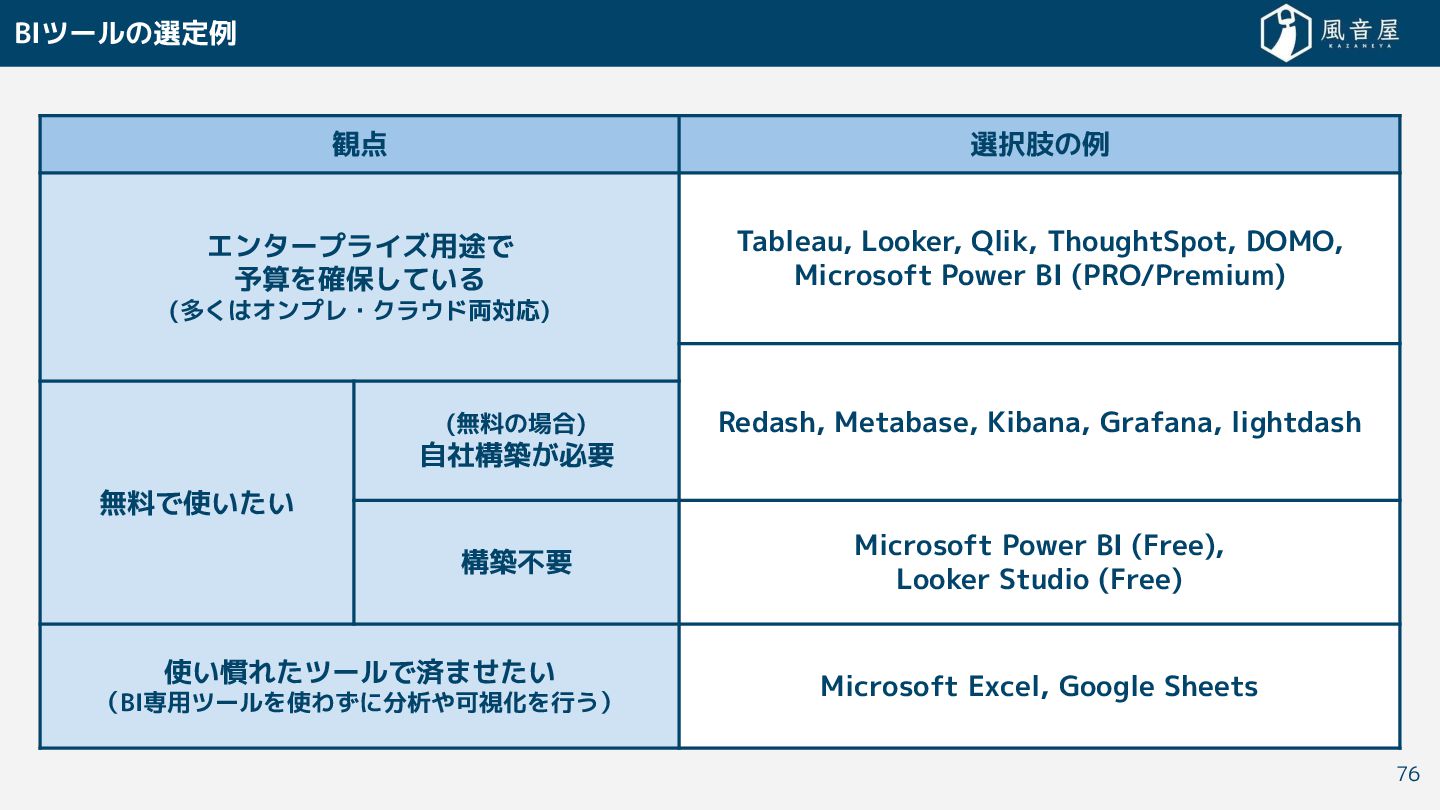
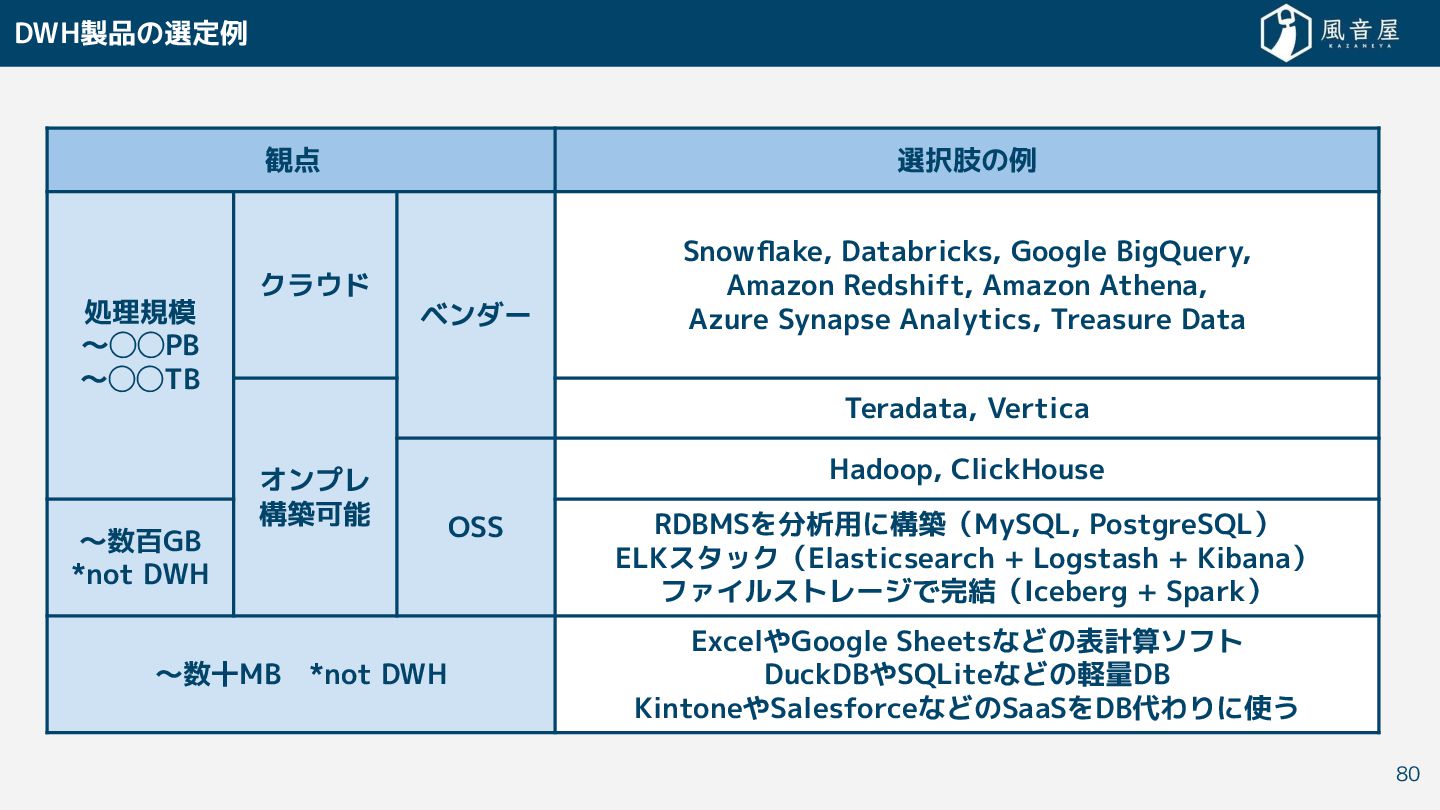
Looker, Qlik, ThoughtSpot, DOMO, Microsoft Power BI (PRO/Premium) Redash, Metabase, Kibana, Grafana, lightdash 無料で使い い (無料の場合) 自社構築 必要 構築不要 Microsoft Power BI (Free), Looker Studio (Free) 使い慣れ ツールで済ま い (BI専用ツールを使わ に分析や可視化を行う) Microsoft Excel, Google Sheets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
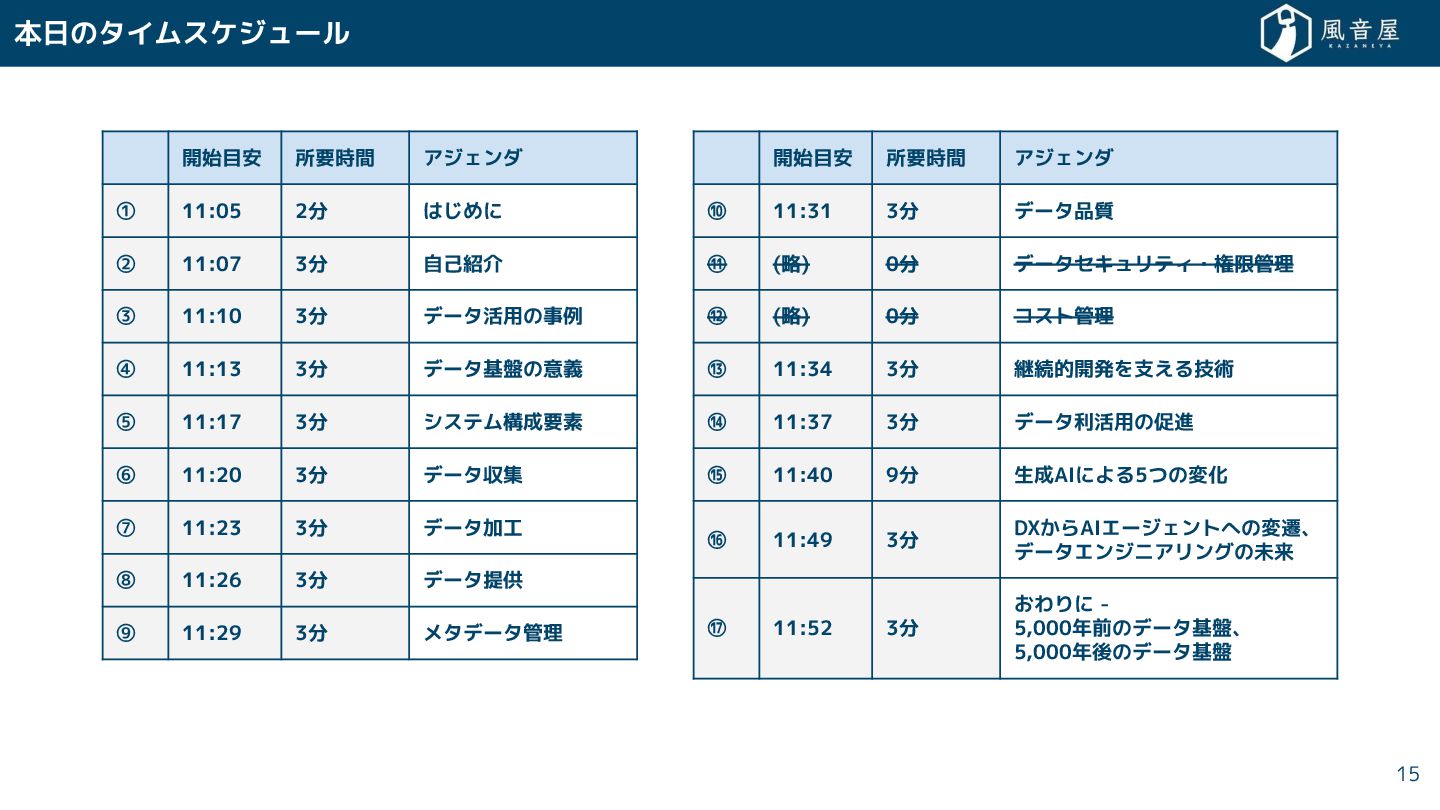{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
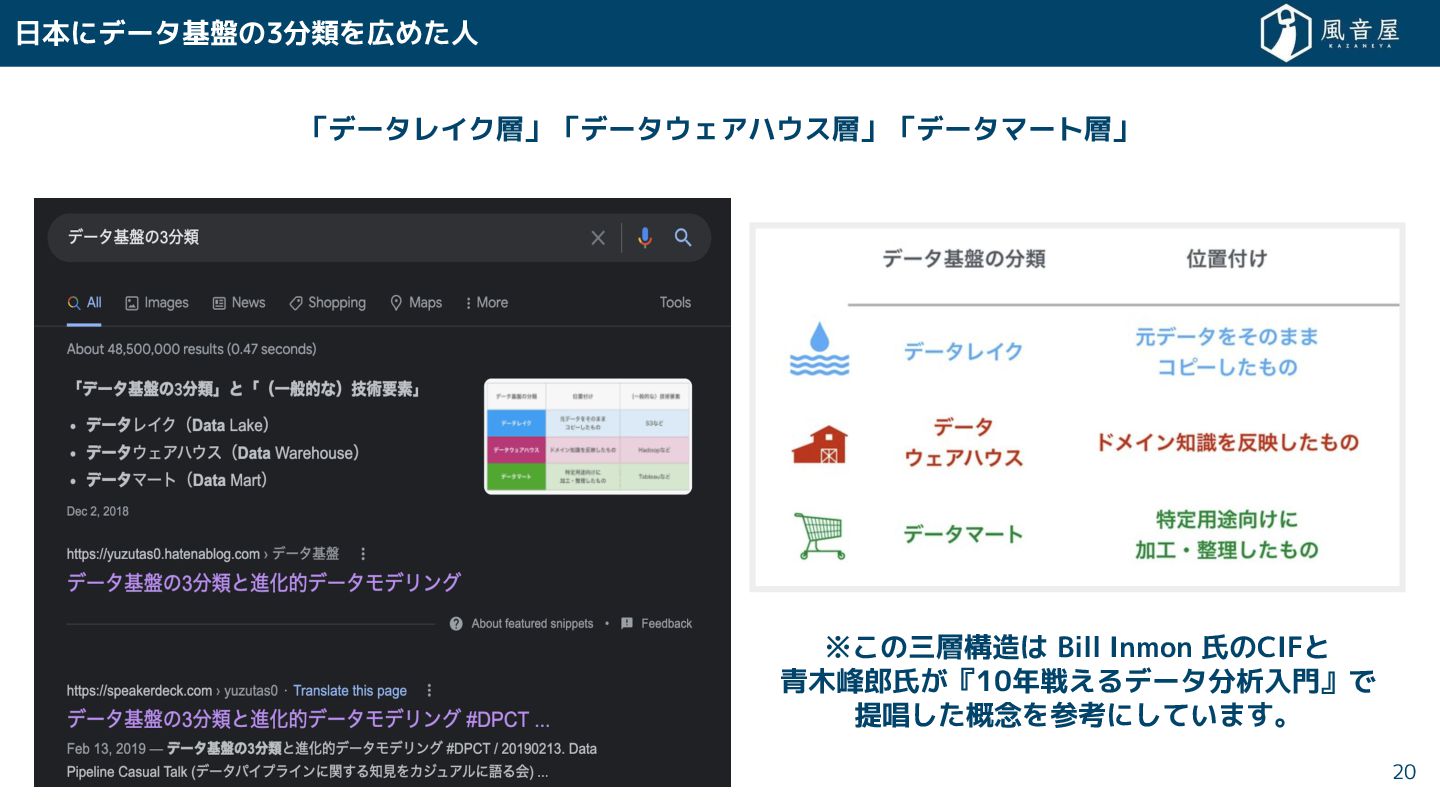{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
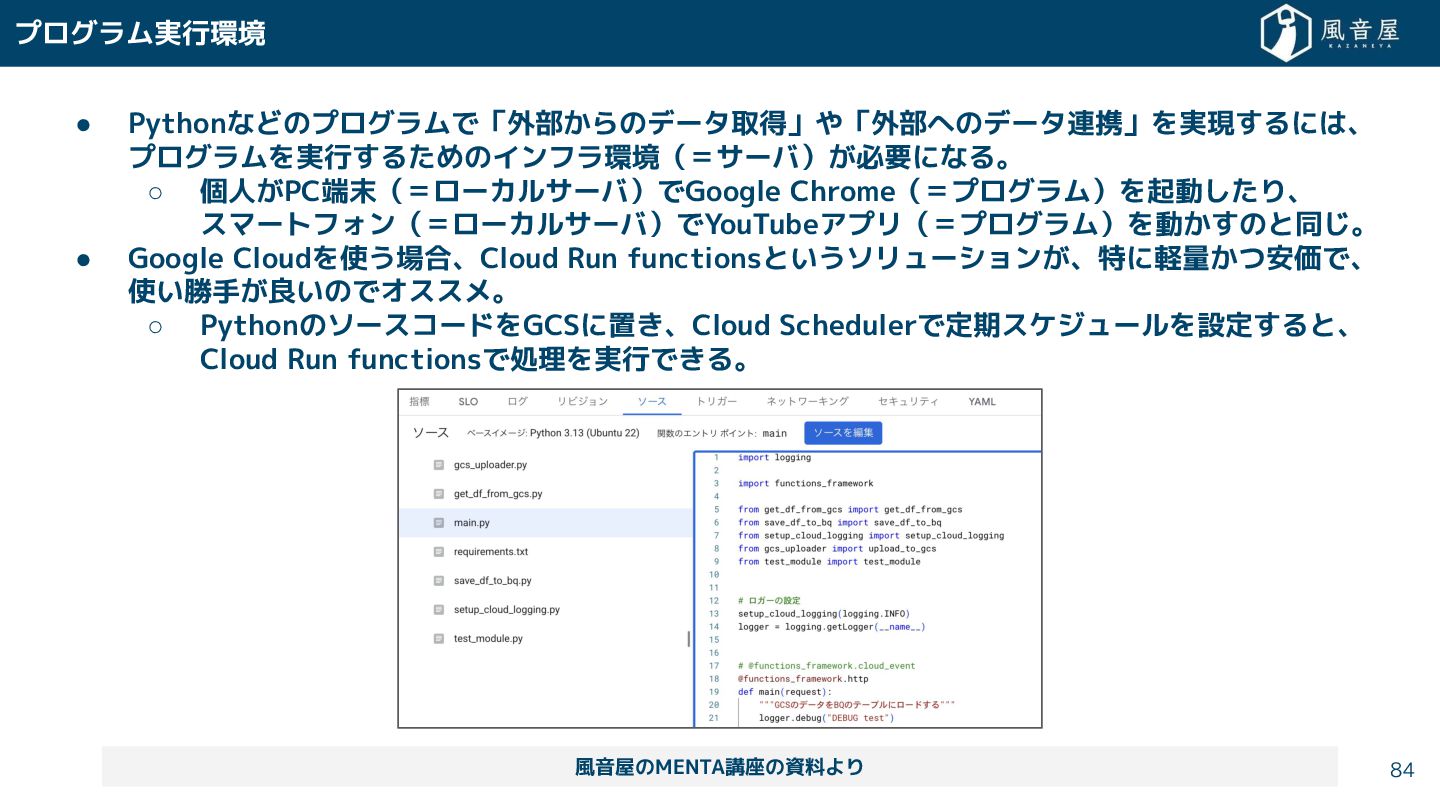{kind=link}
{kind=link}
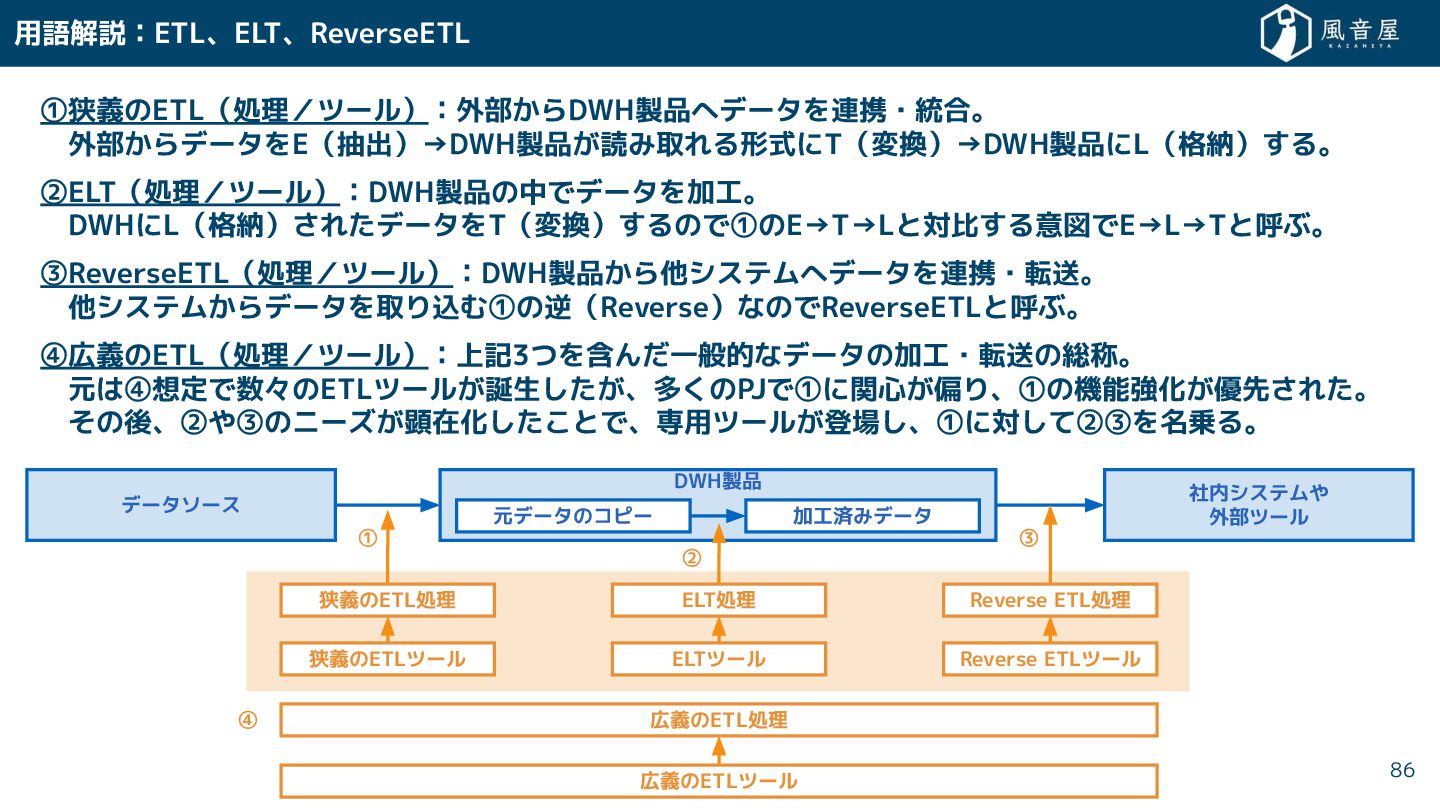{kind=link}
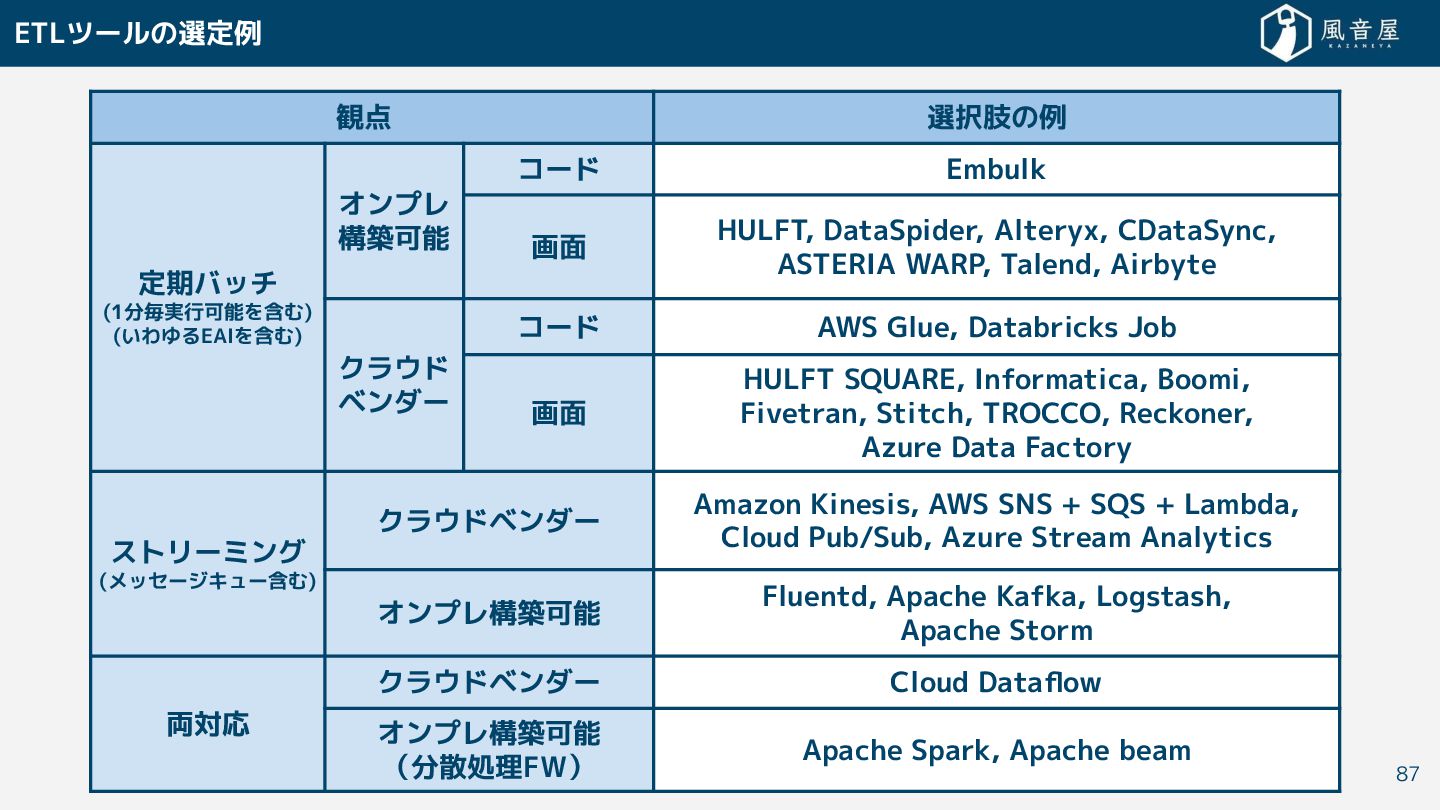{kind=link}
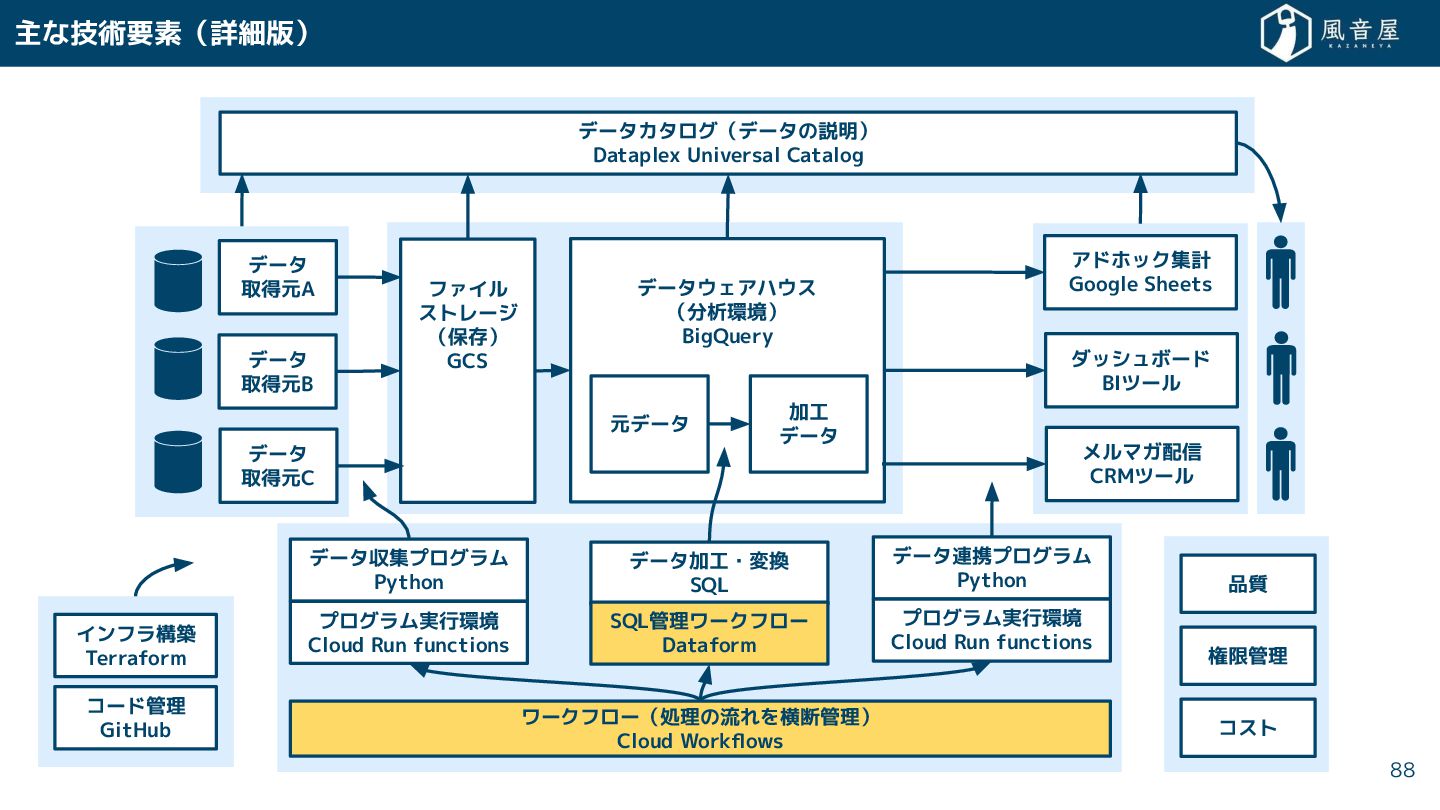{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
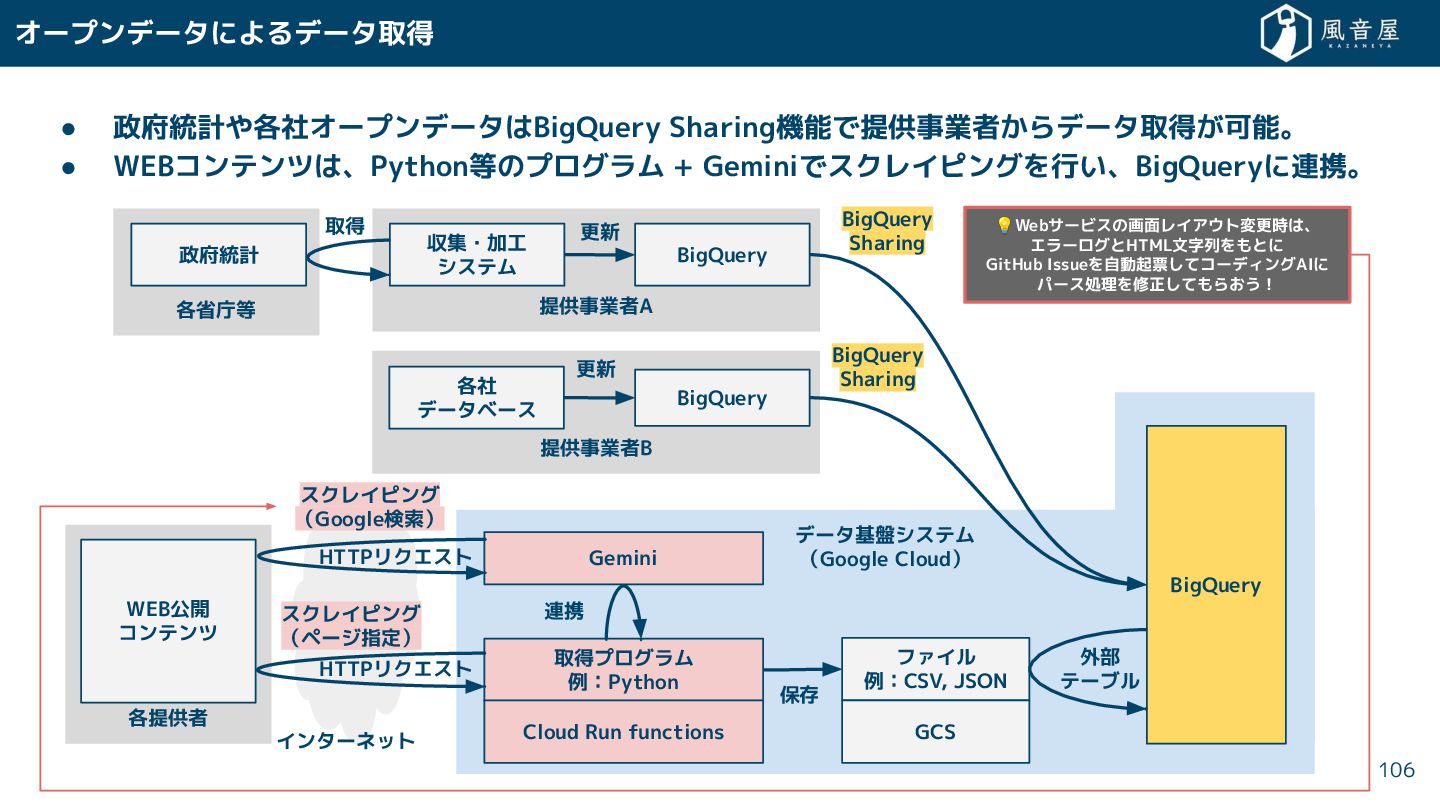{kind=link}
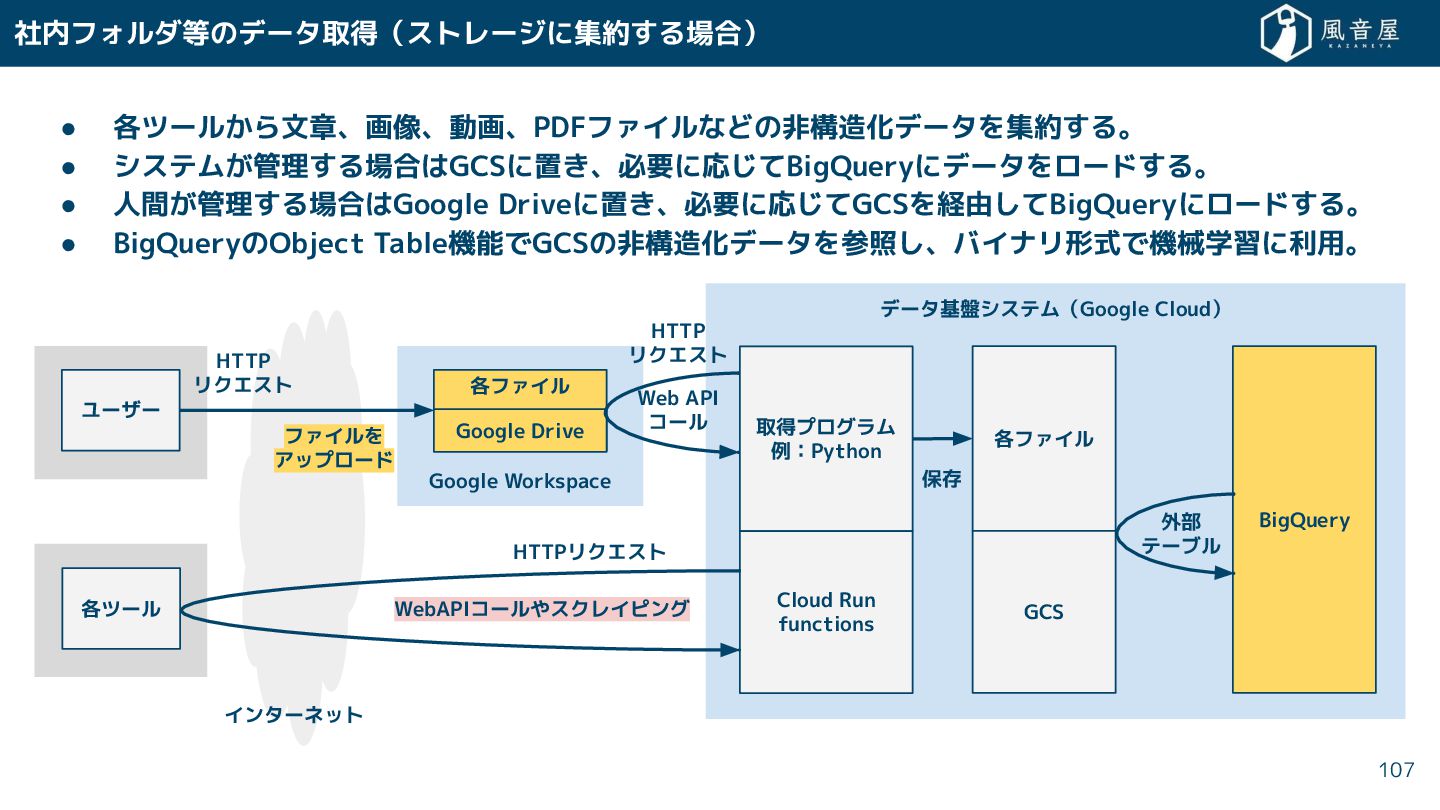{kind=link}
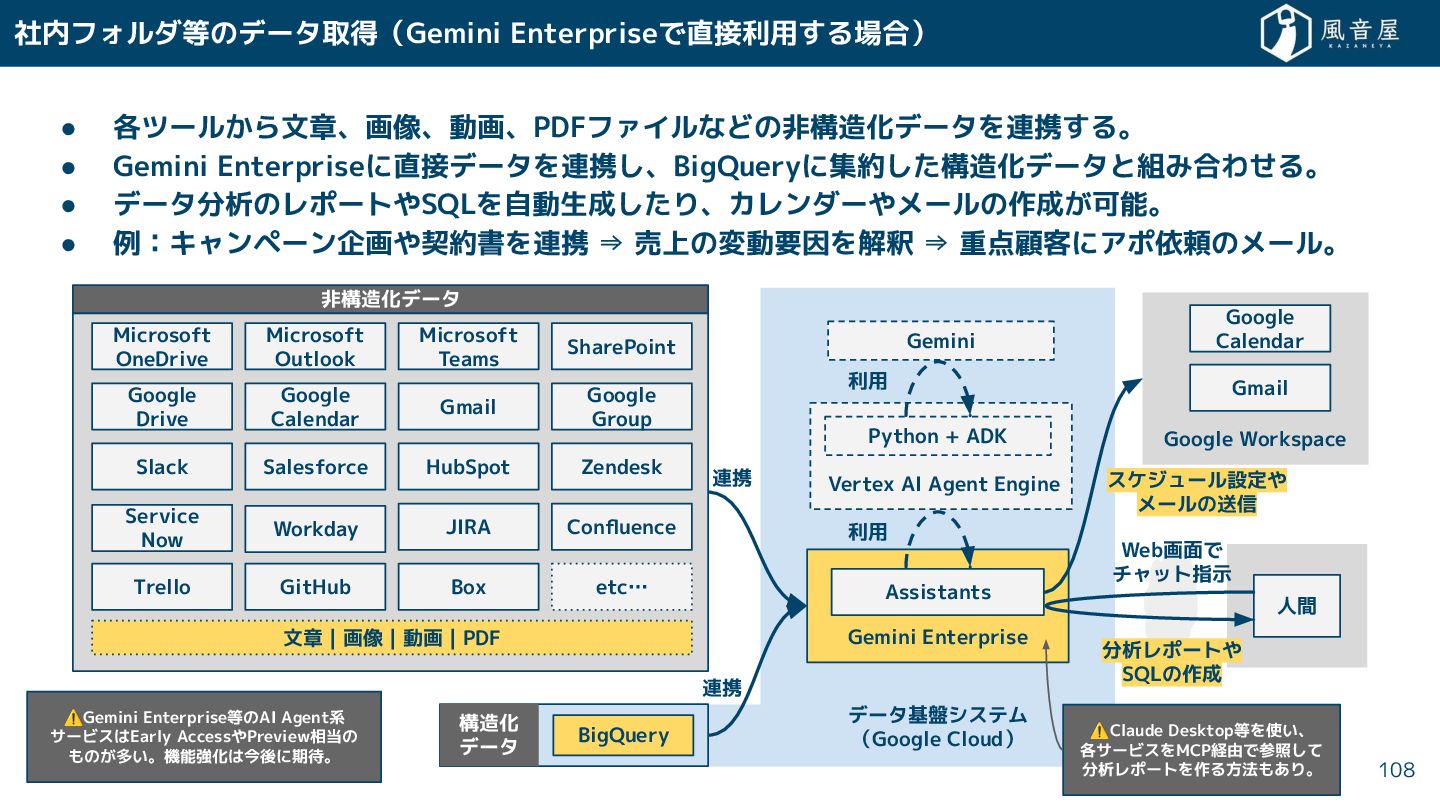{kind=link}
{kind=link}
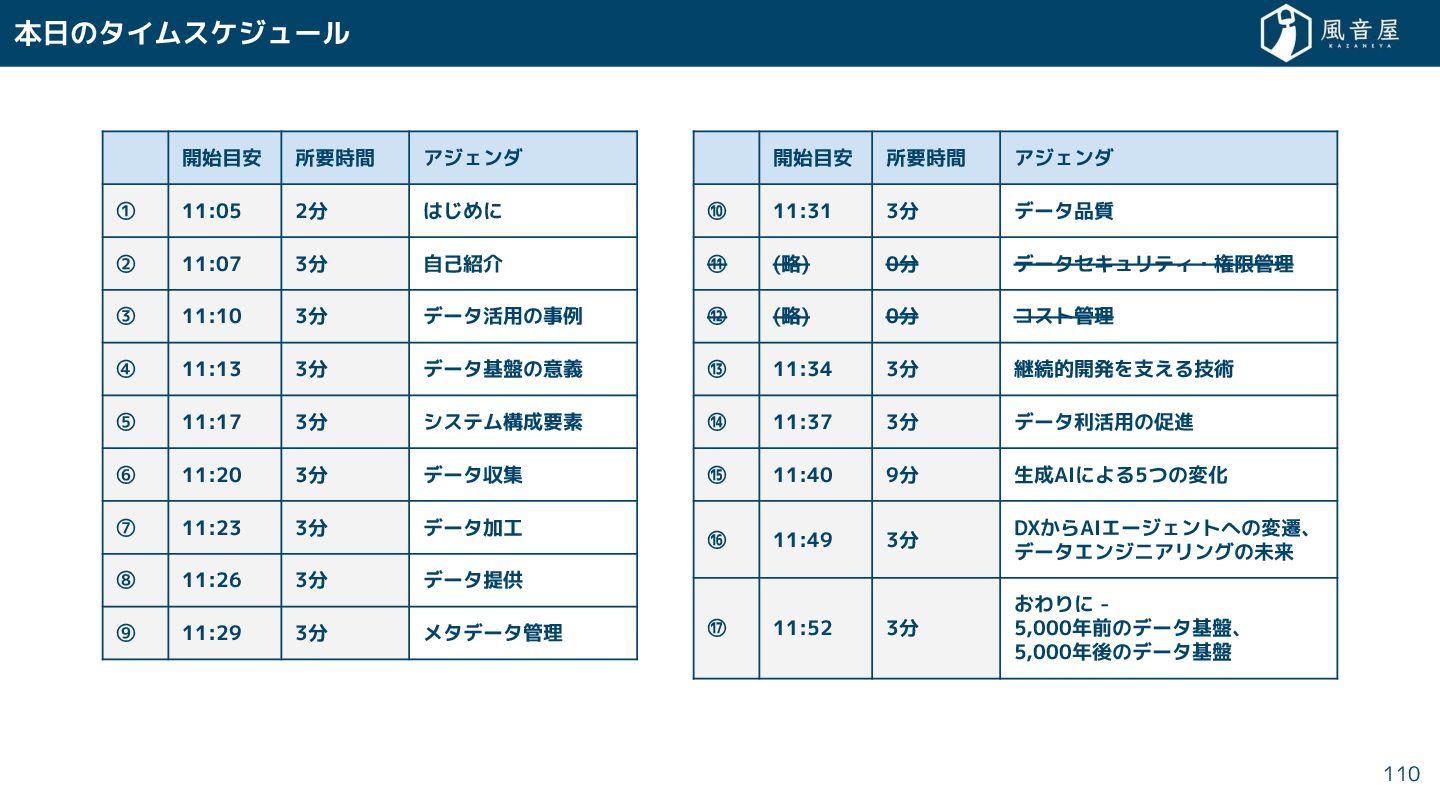{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
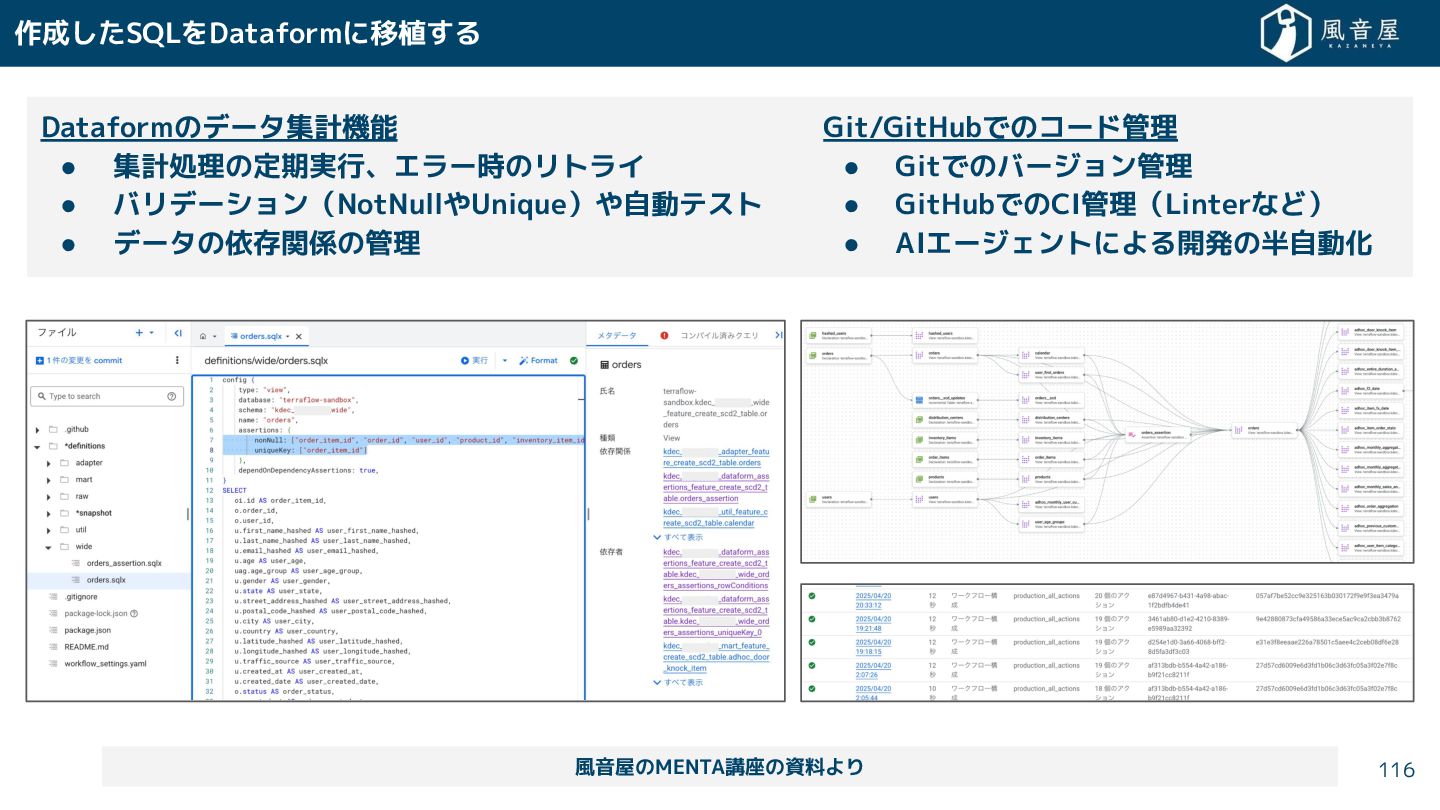{kind=link}
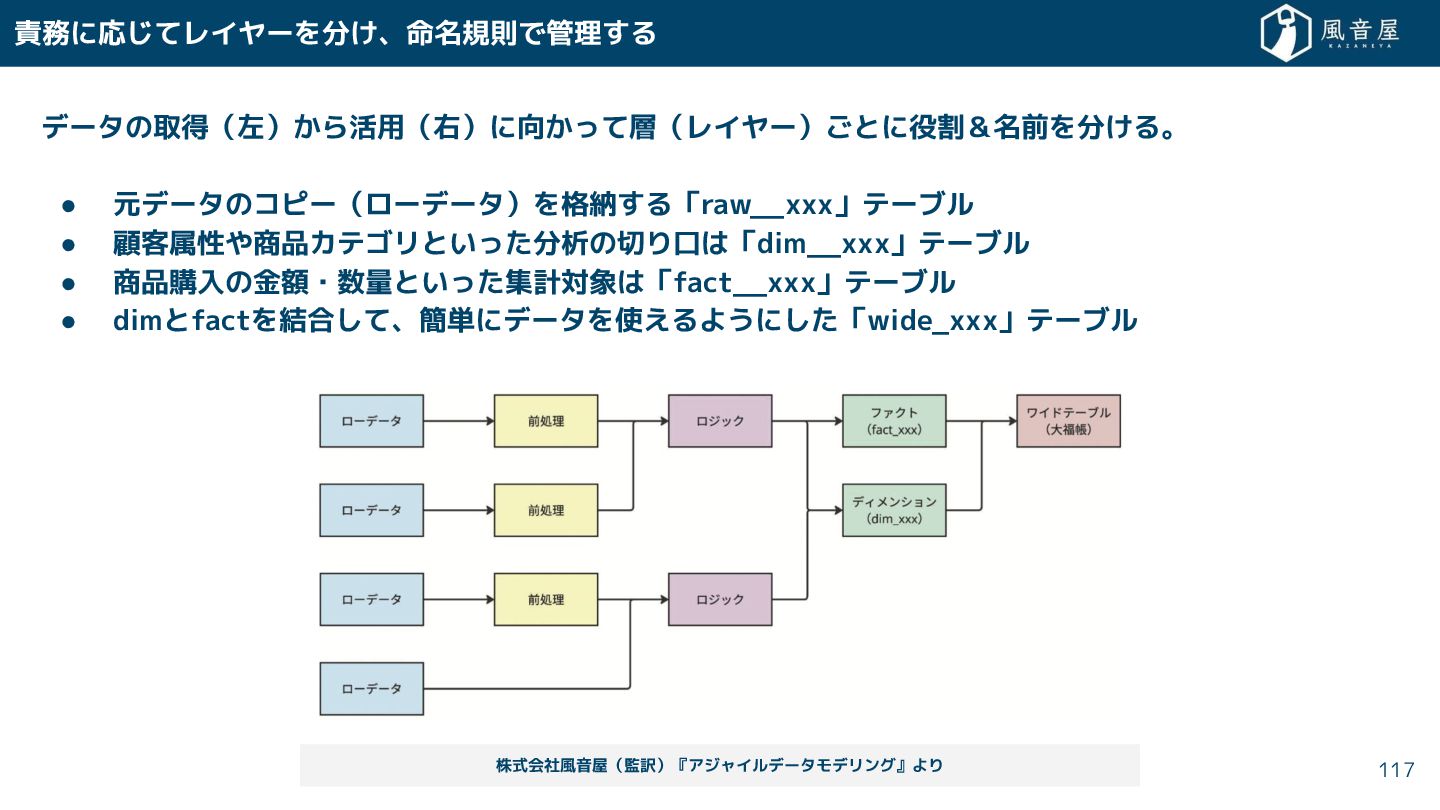{kind=link}
{kind=link}
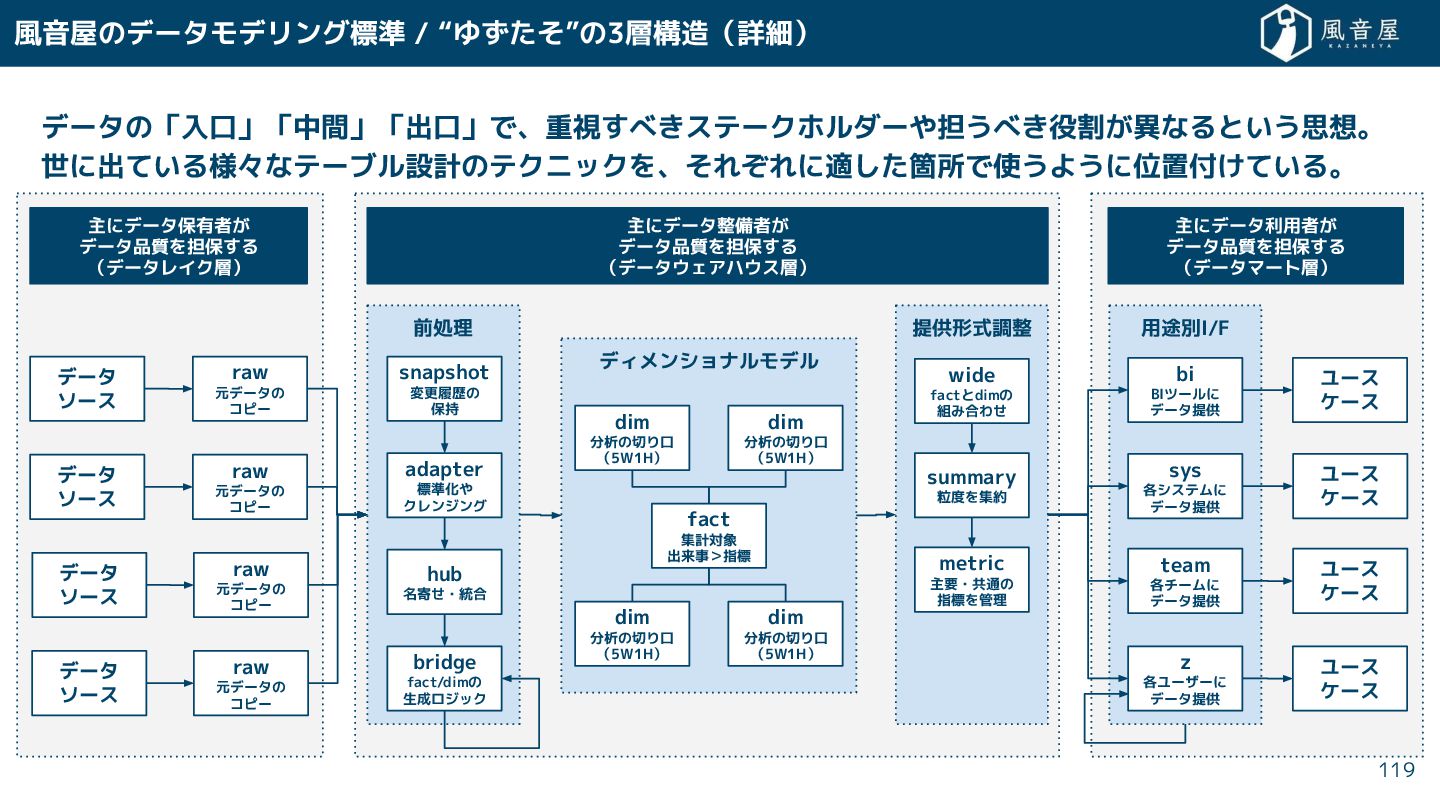{kind=link}
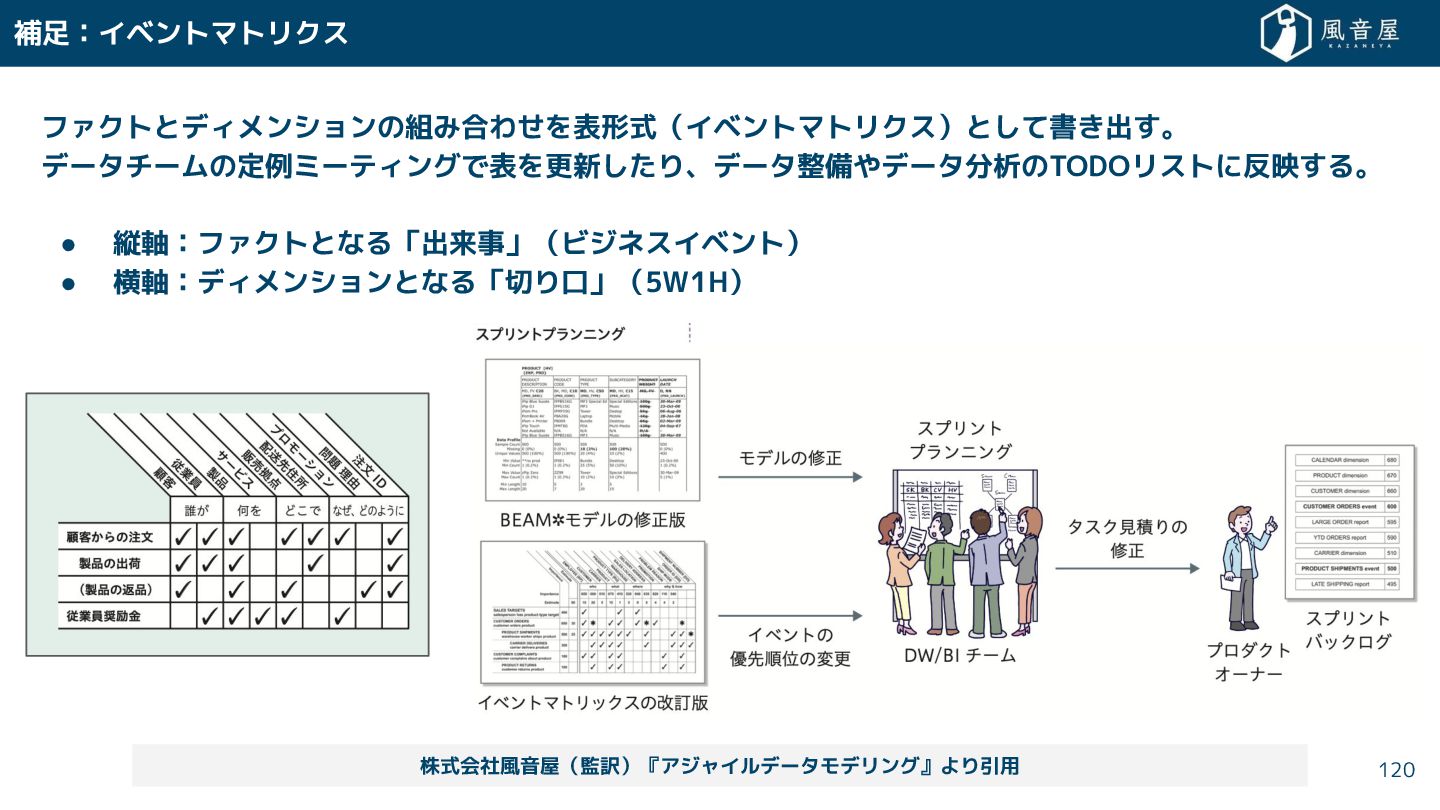{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
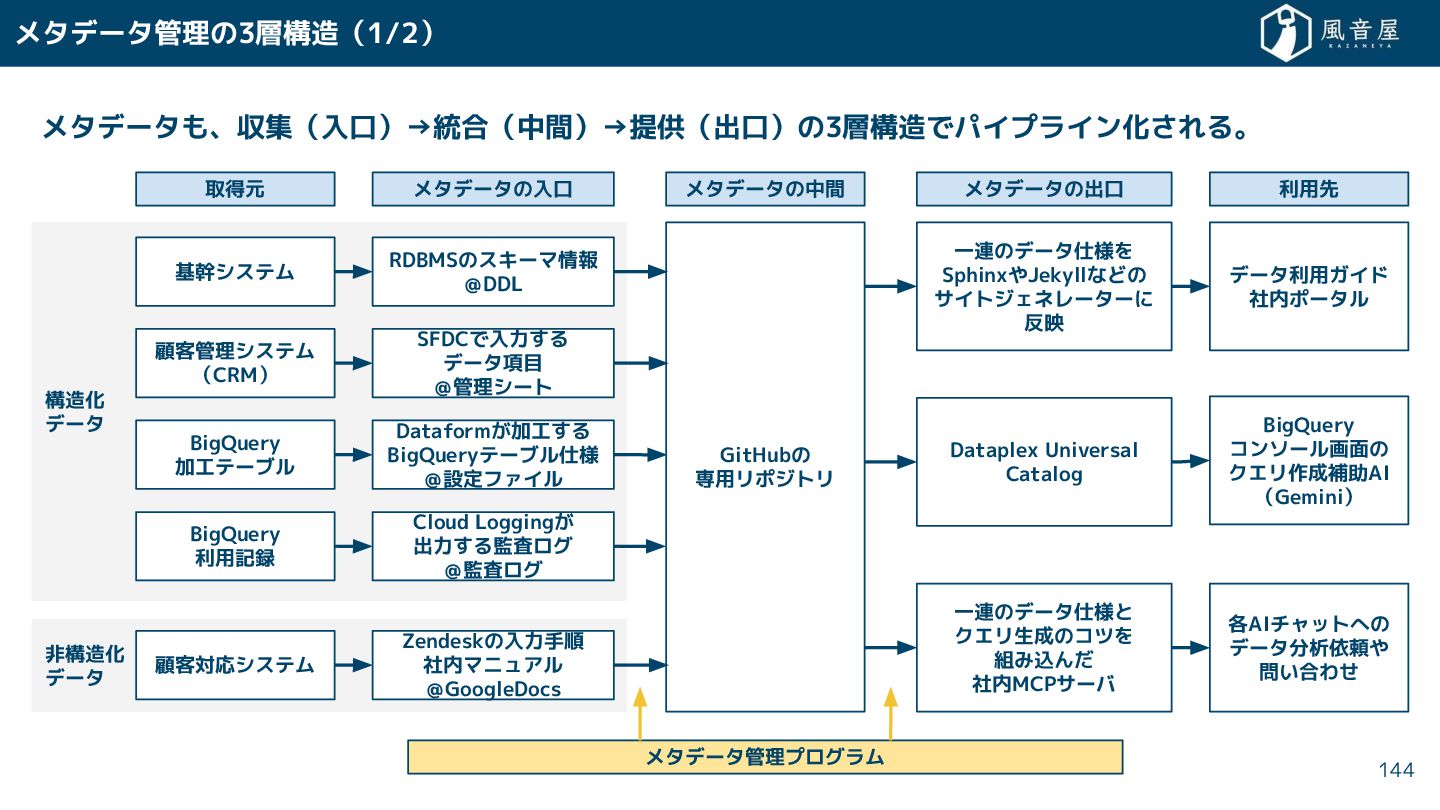{kind=link}
{kind=link}
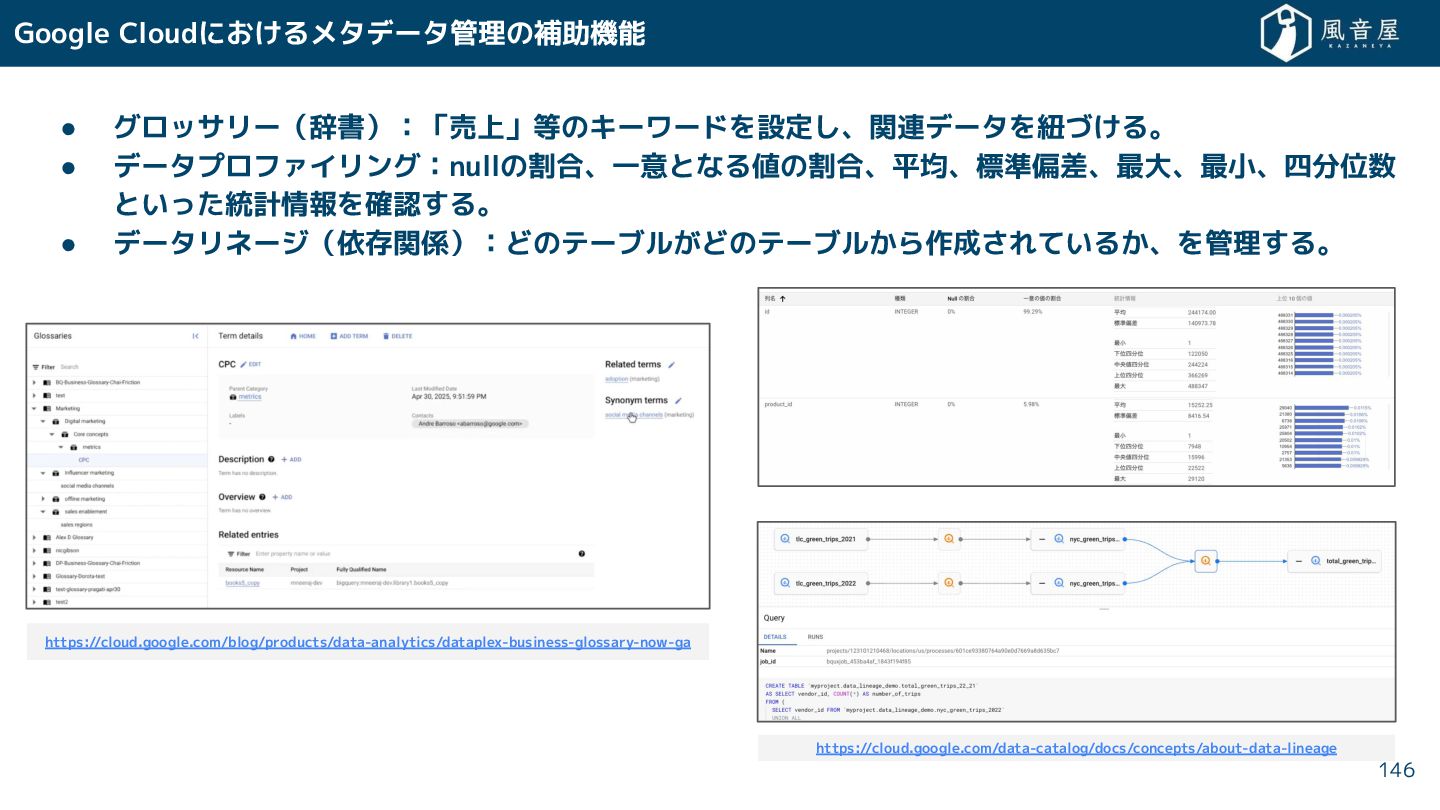{kind=link}
{kind=link}
{kind=link}
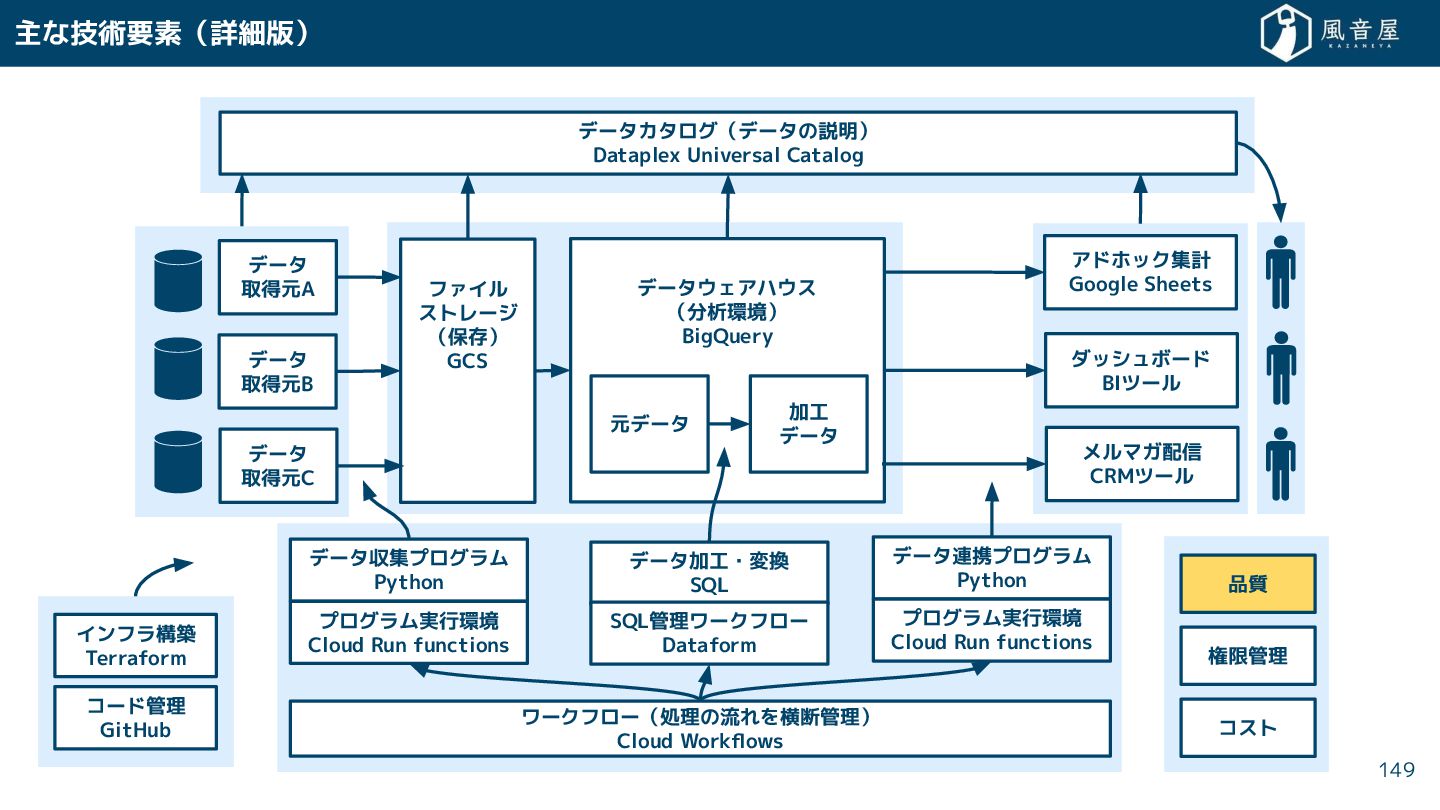{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
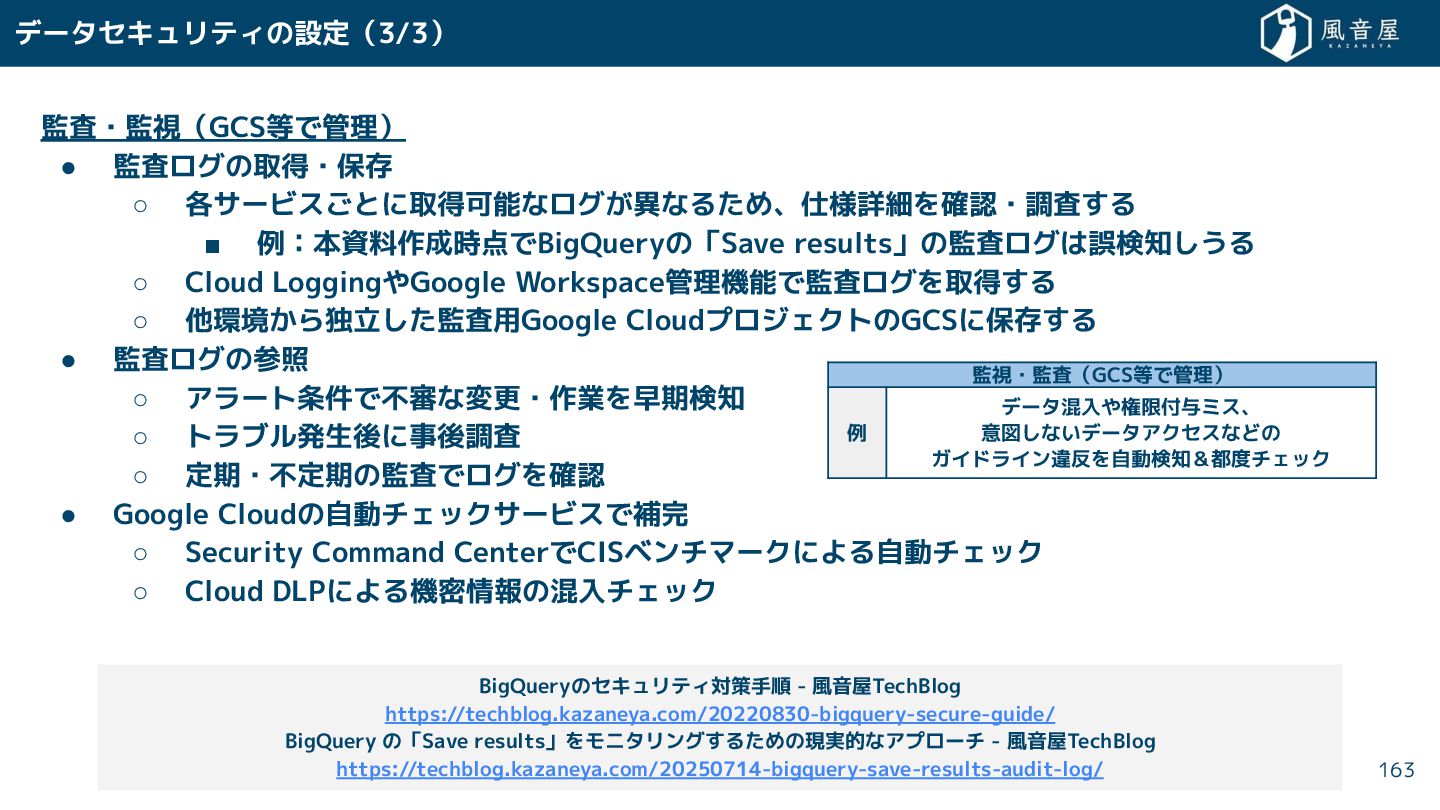{kind=link}
{kind=link}
{kind=link}
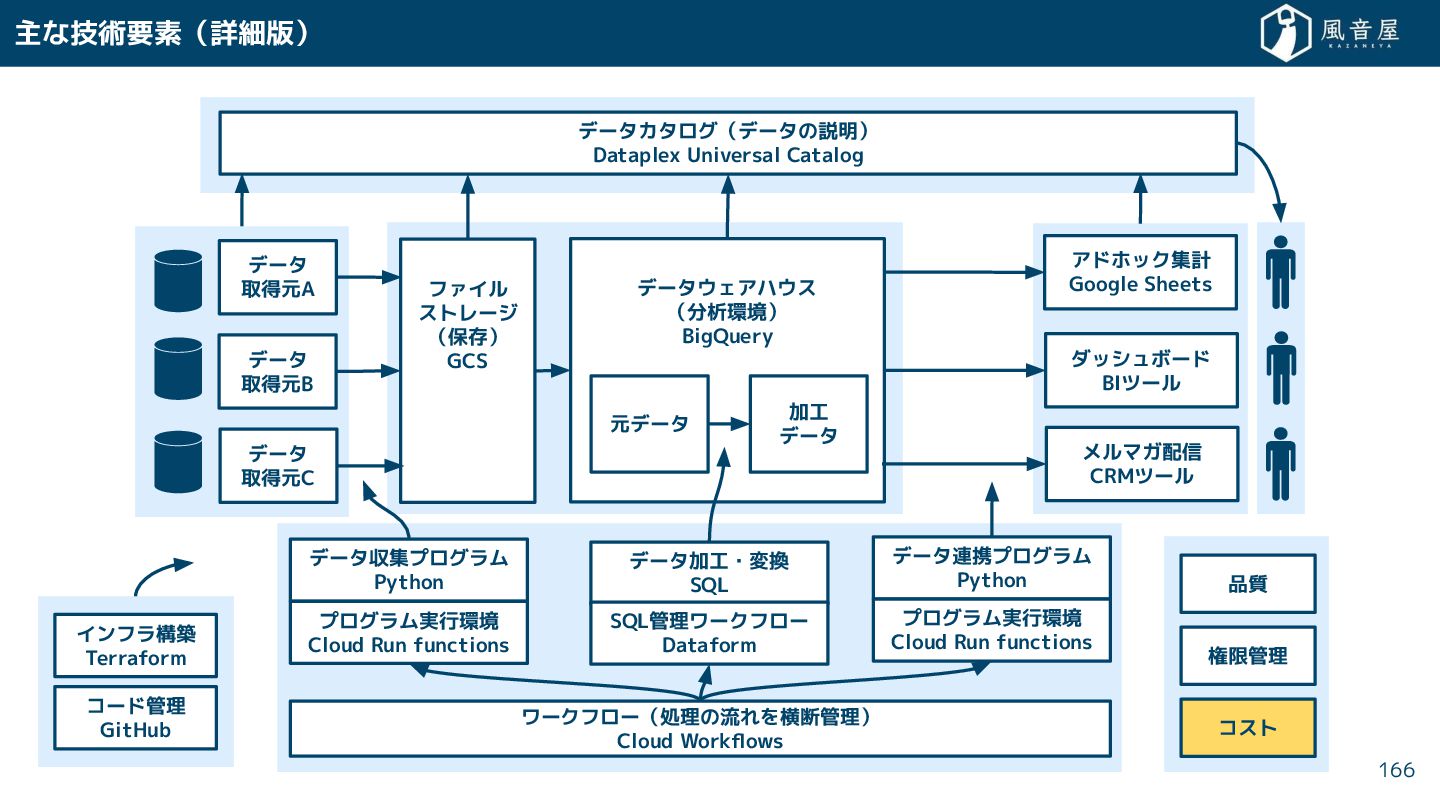{kind=link}
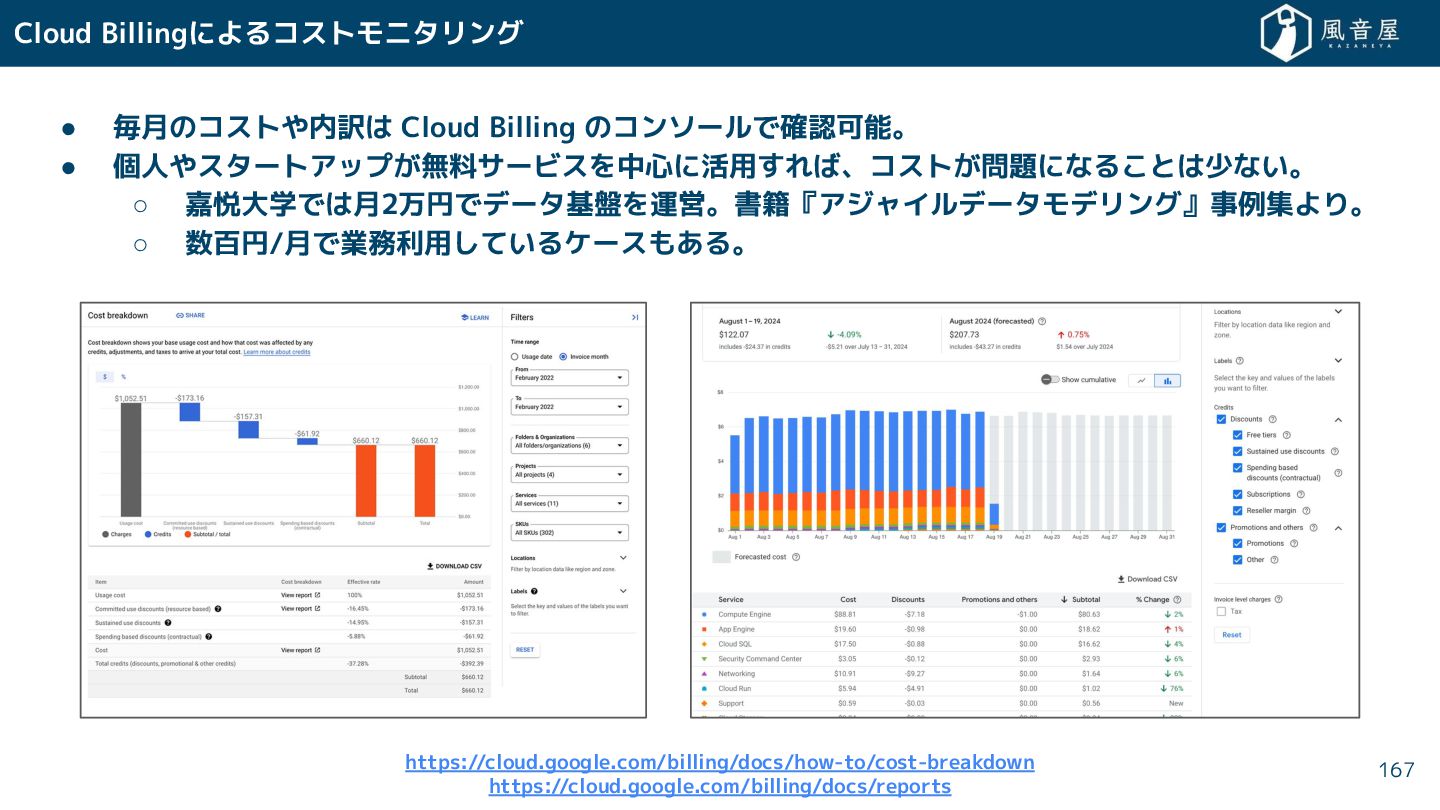{kind=link}
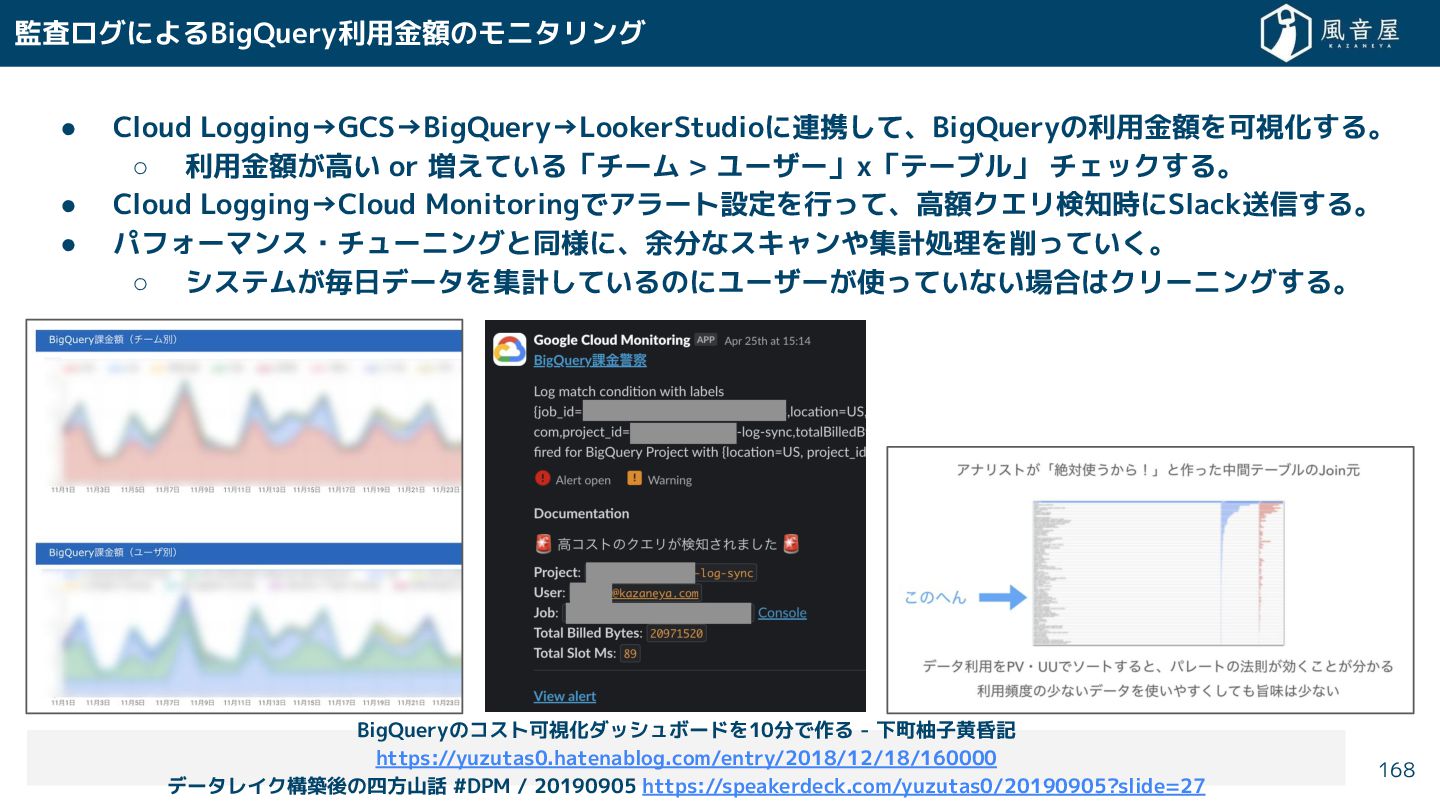{kind=link}
{kind=link}
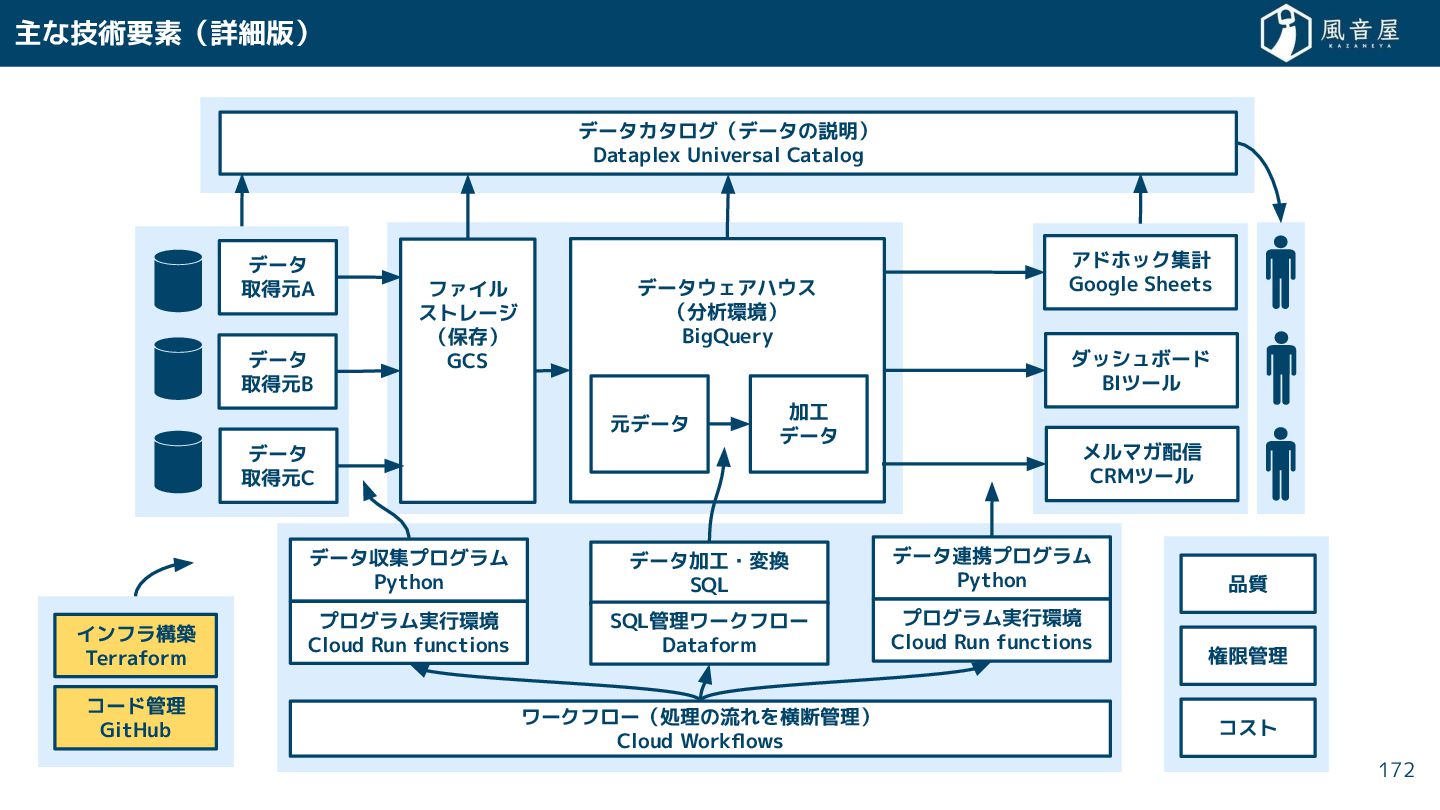
{kind=link}
{kind=link}
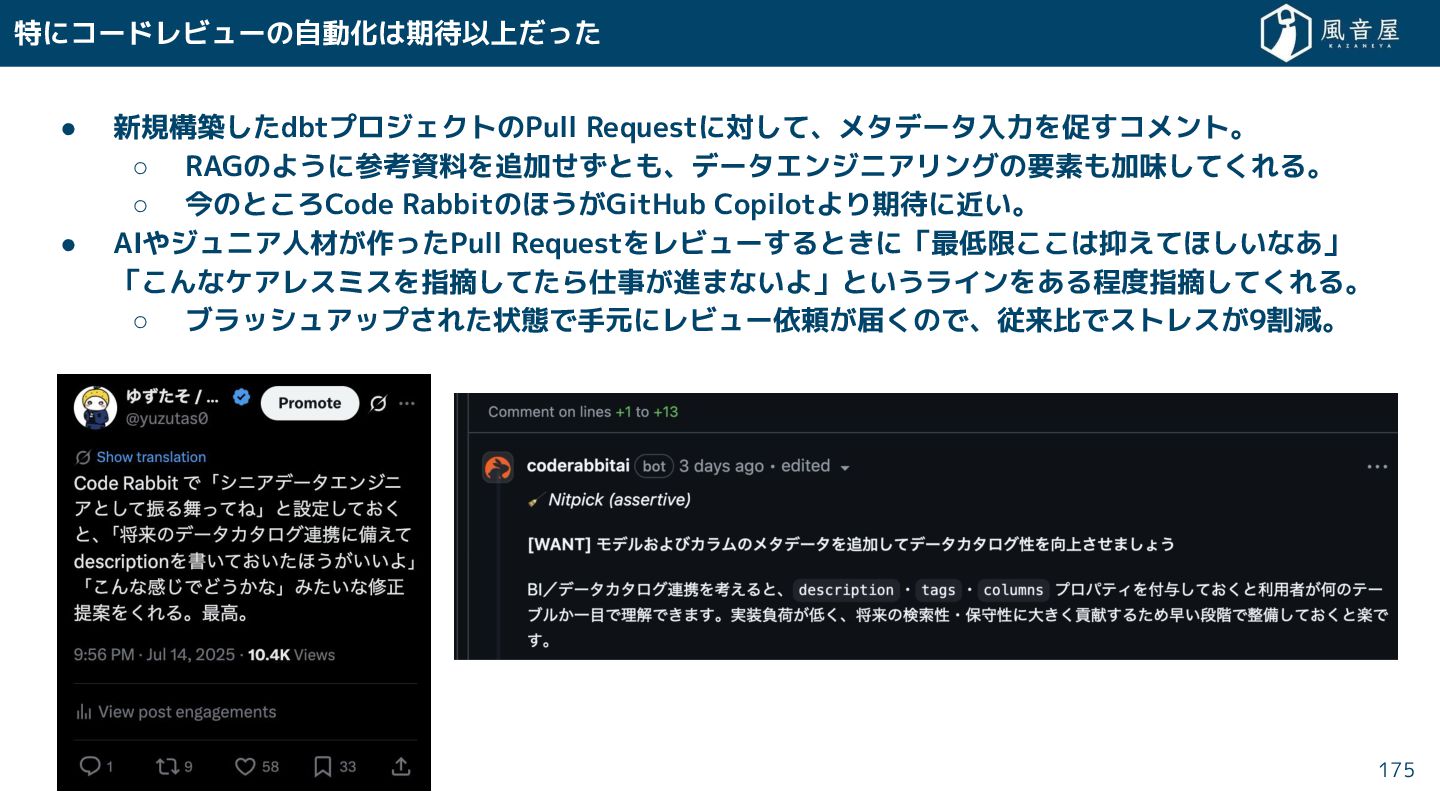
{kind=link}
{kind=link}
{kind=link}
{kind=link}
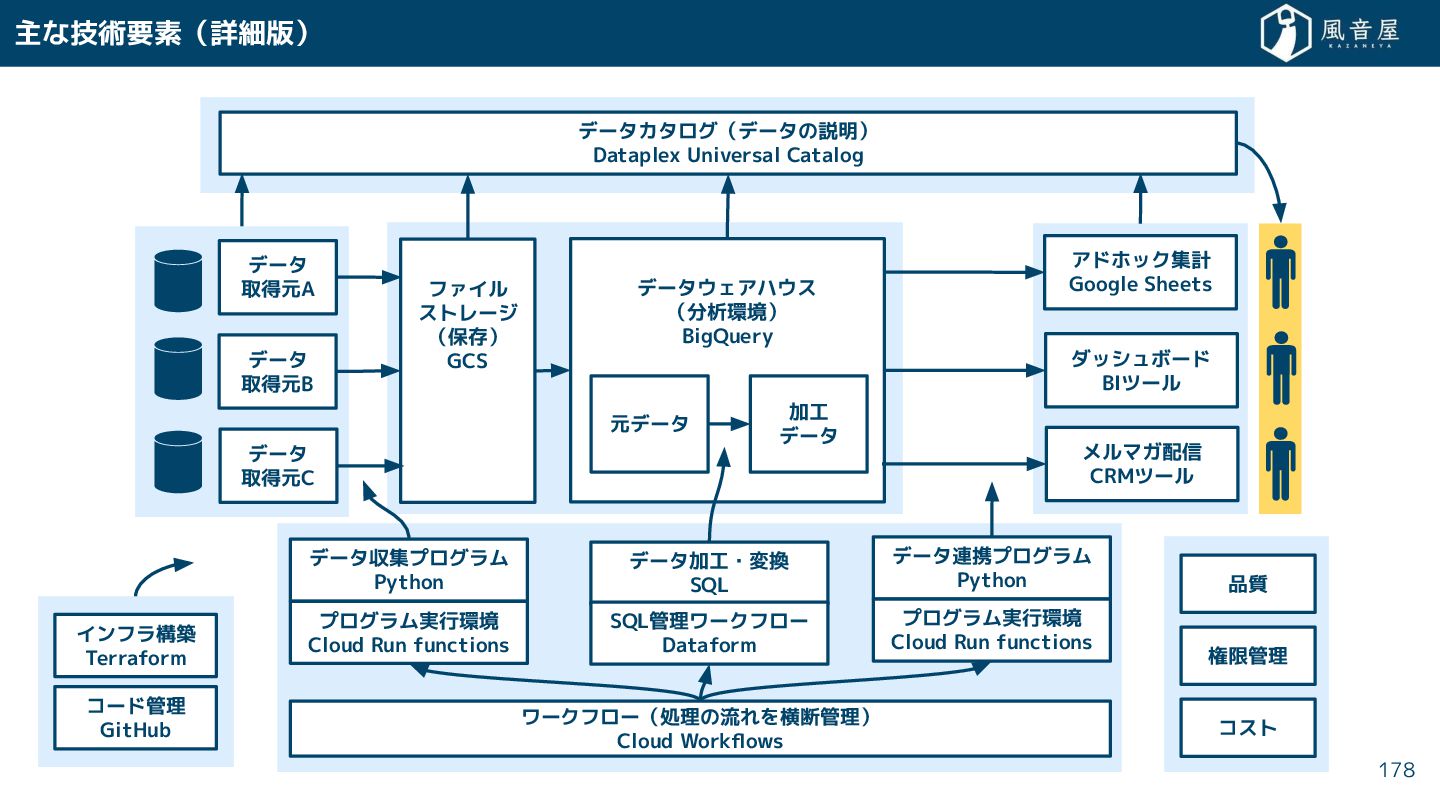
{kind=link}
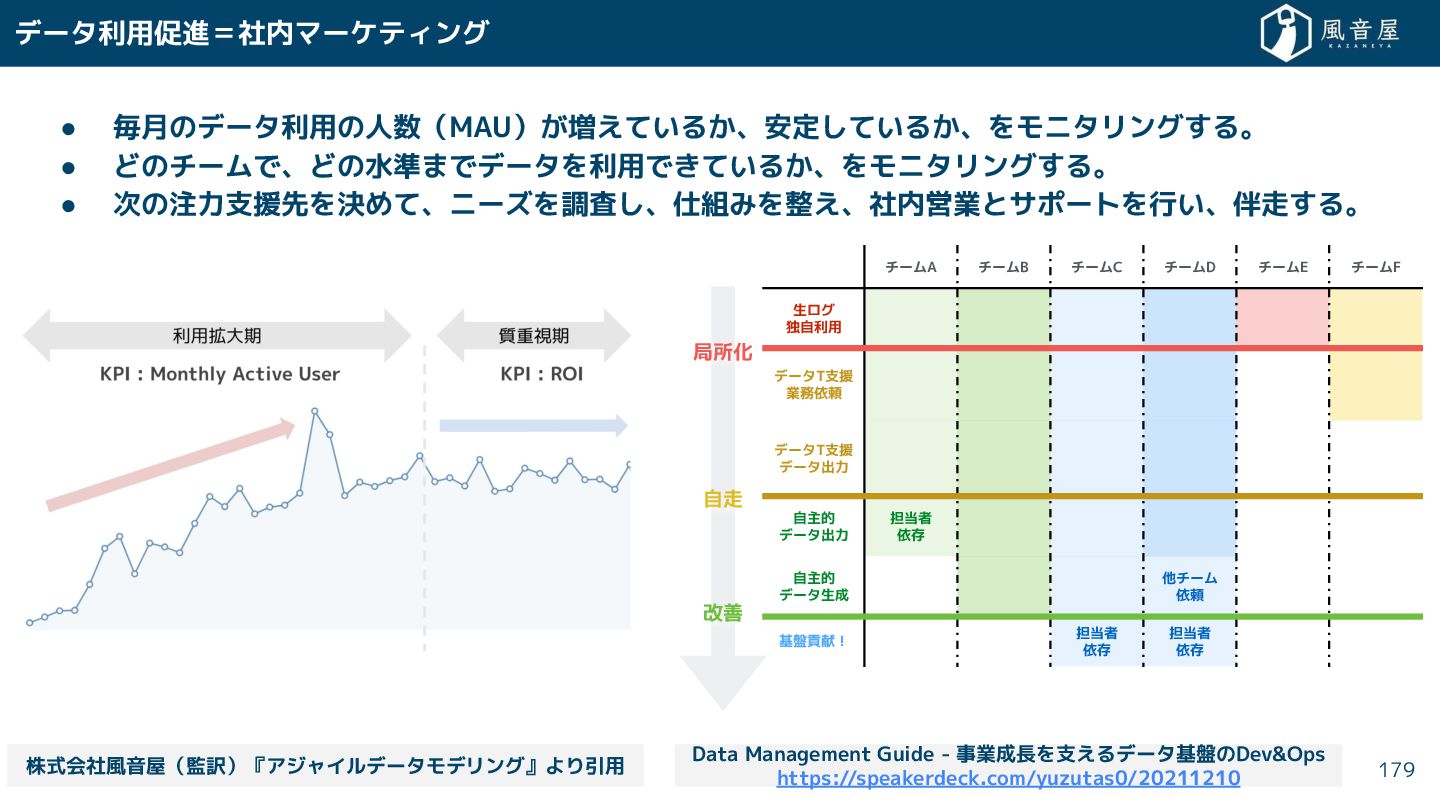
{kind=link}
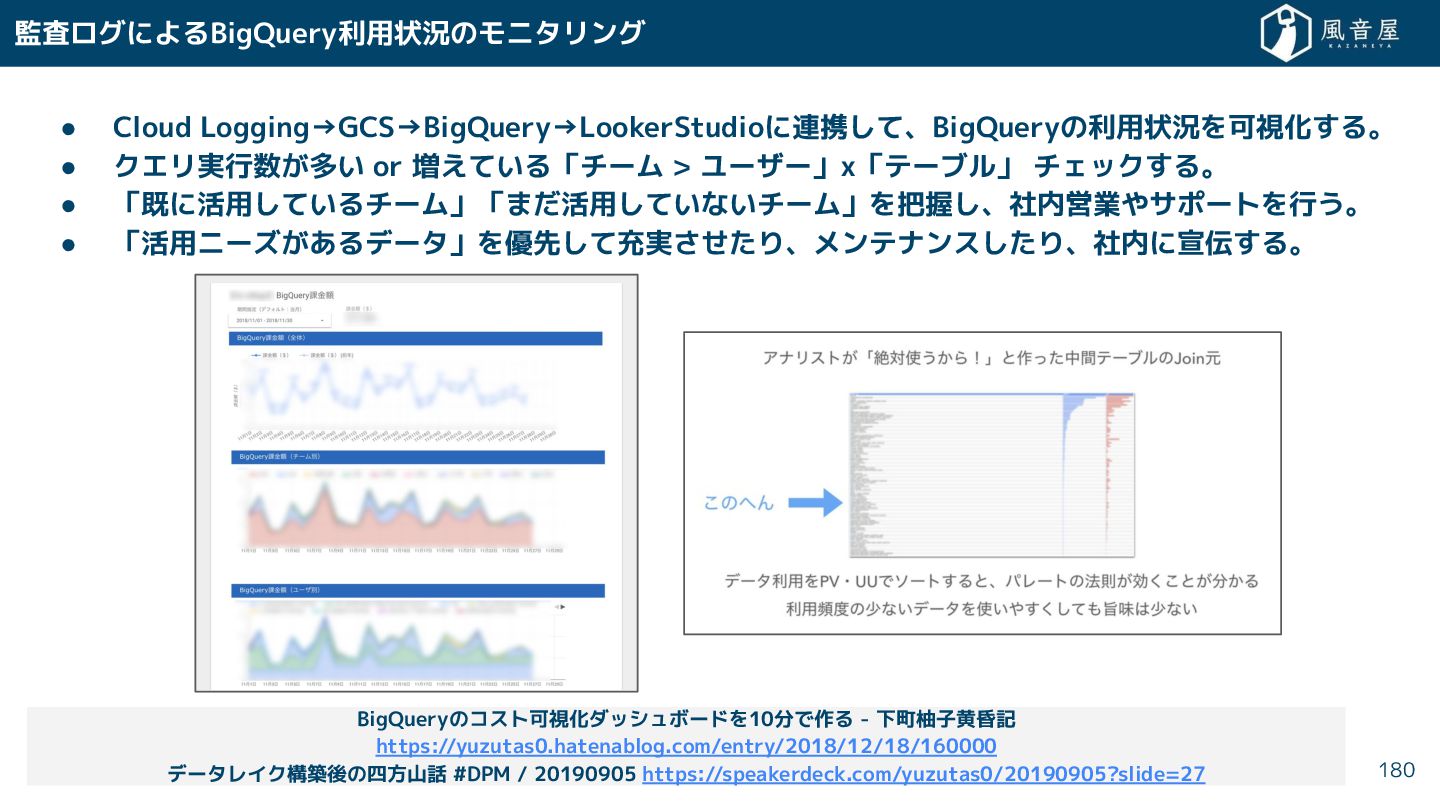
{kind=link}
{kind=link}
{kind=link}
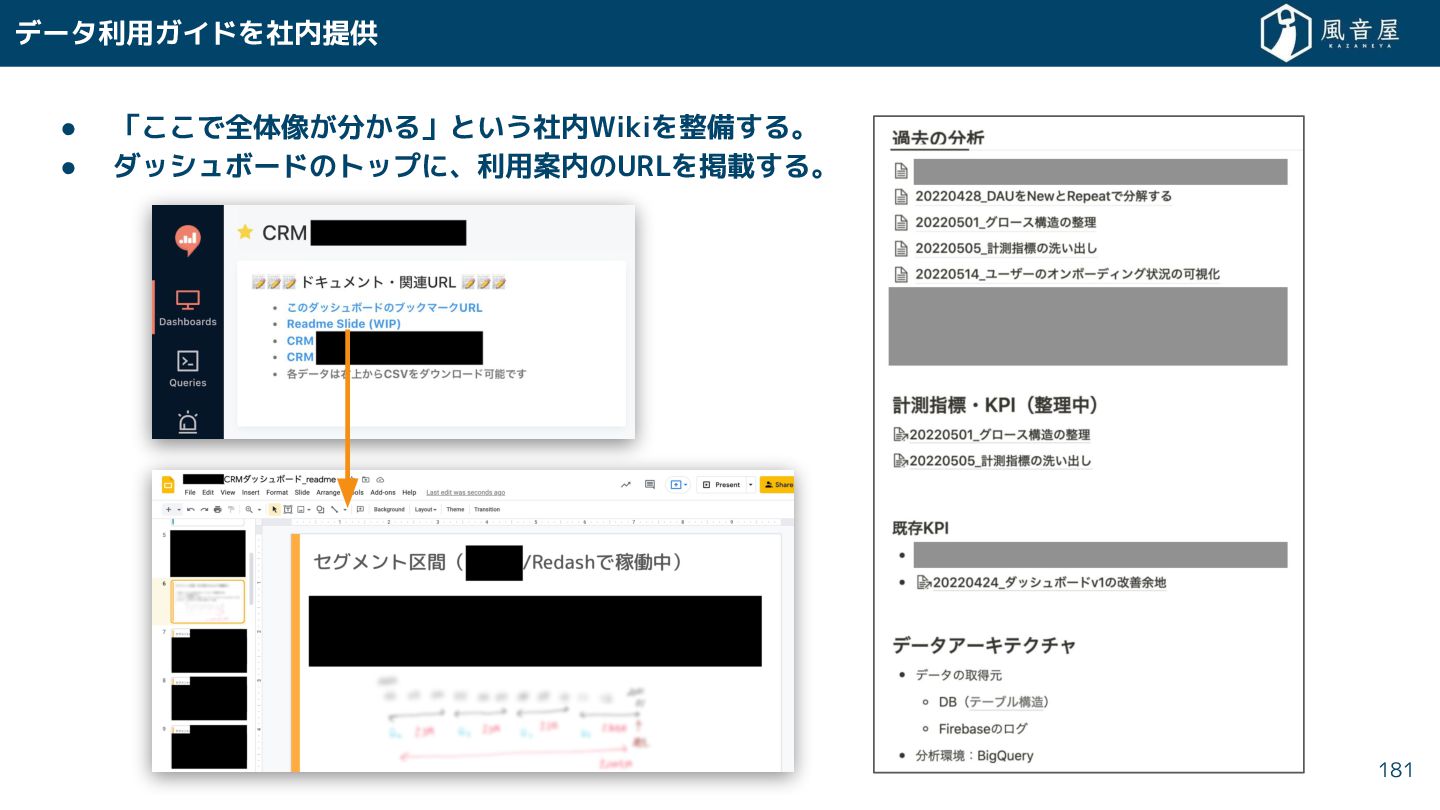{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
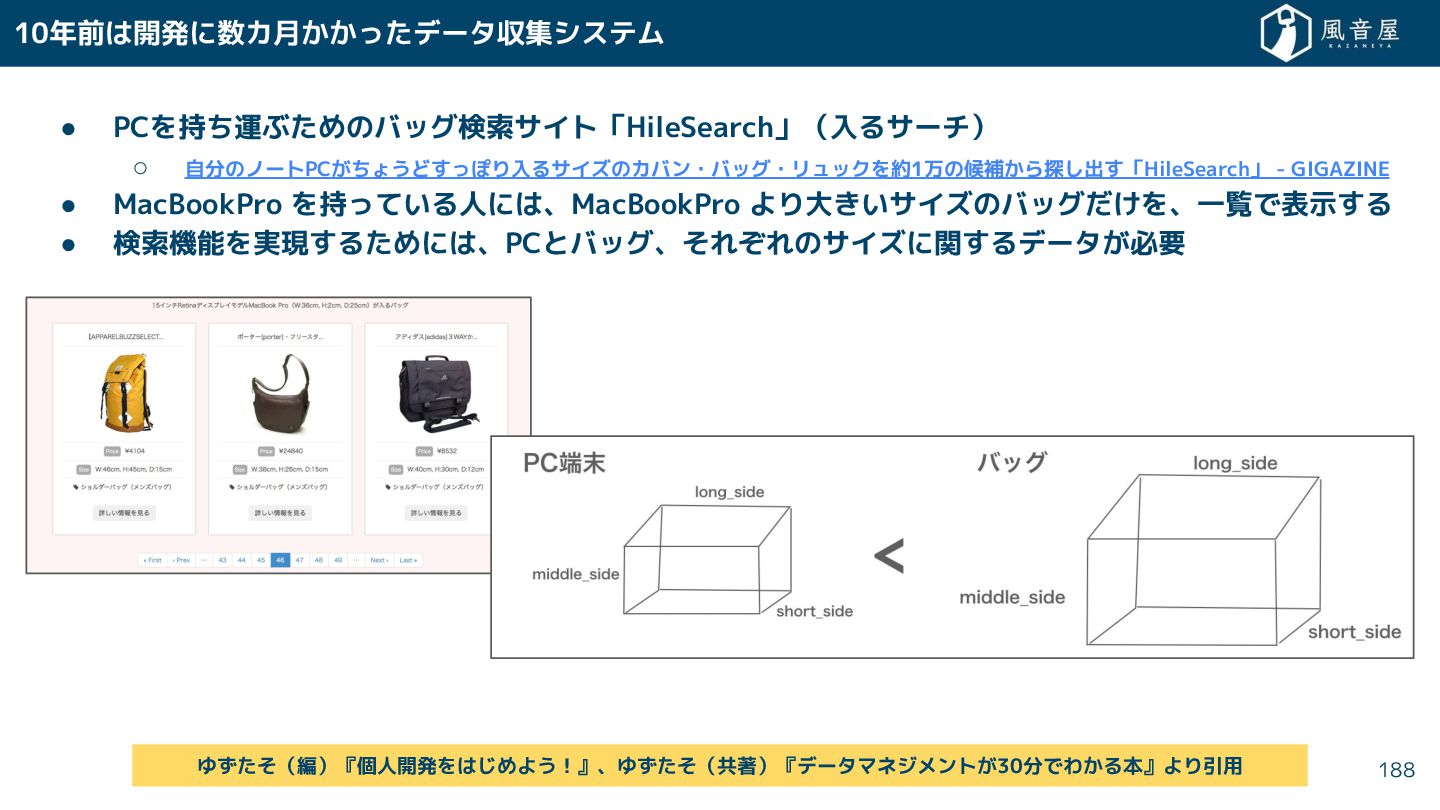{kind=link}
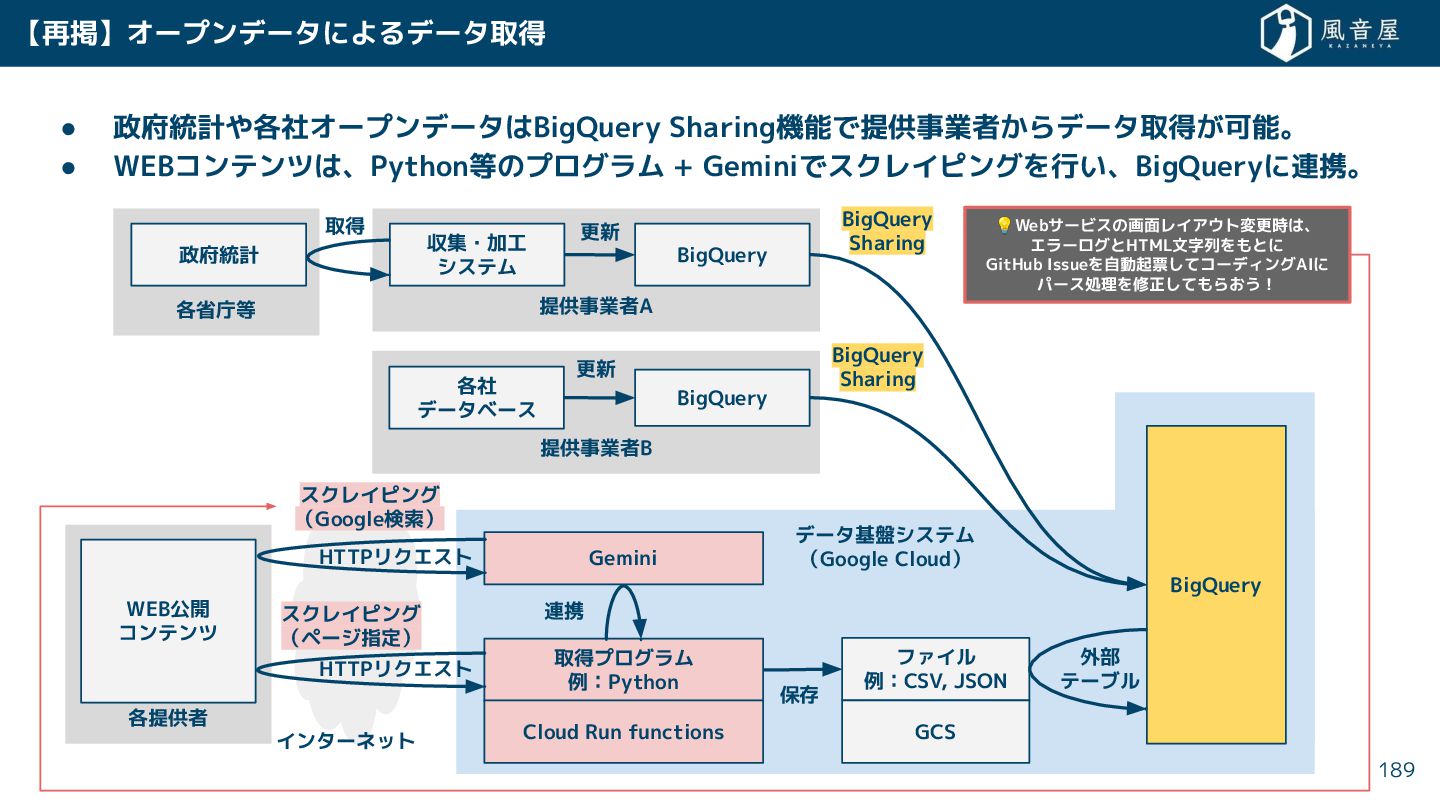{kind=link}
{kind=link}
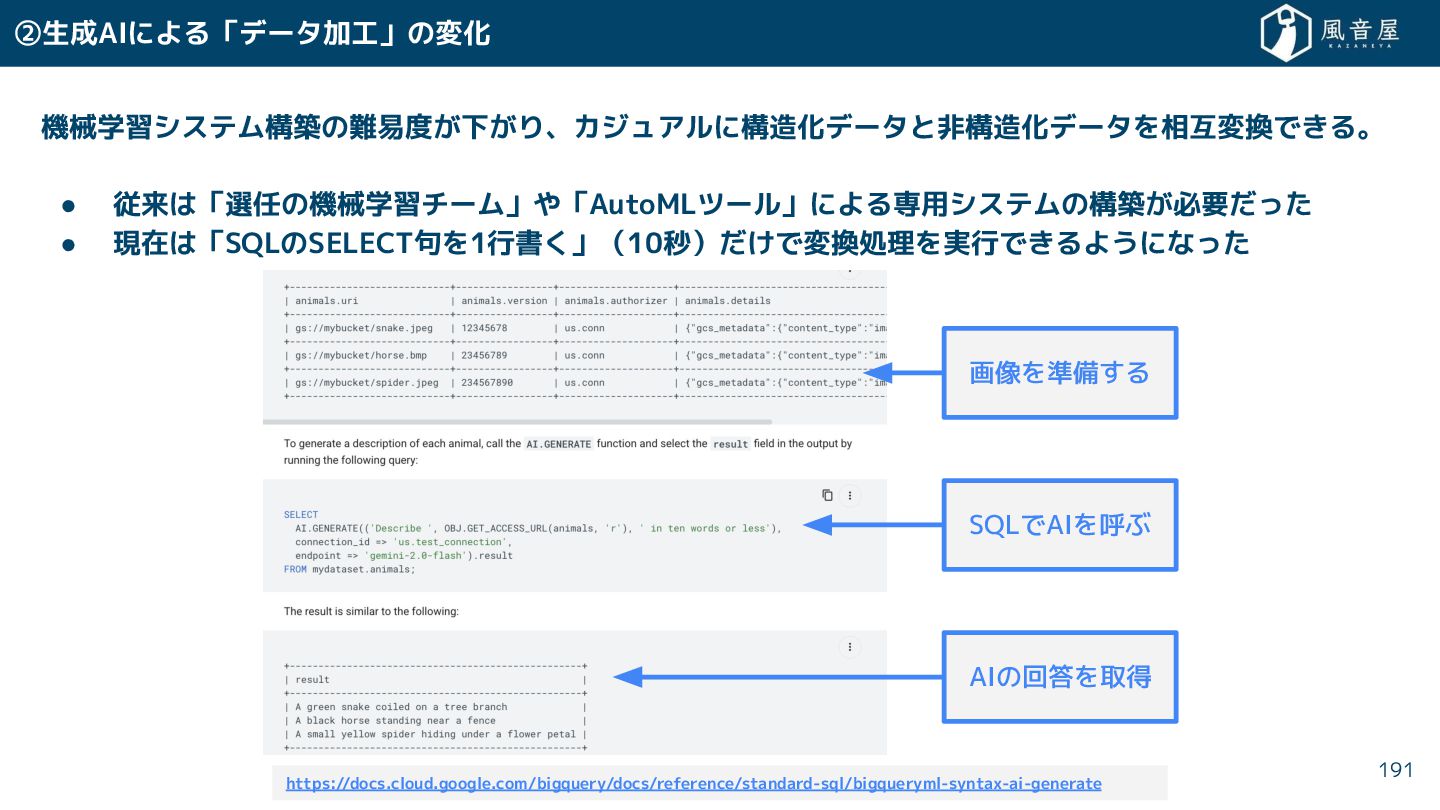{kind=link}
{kind=link}
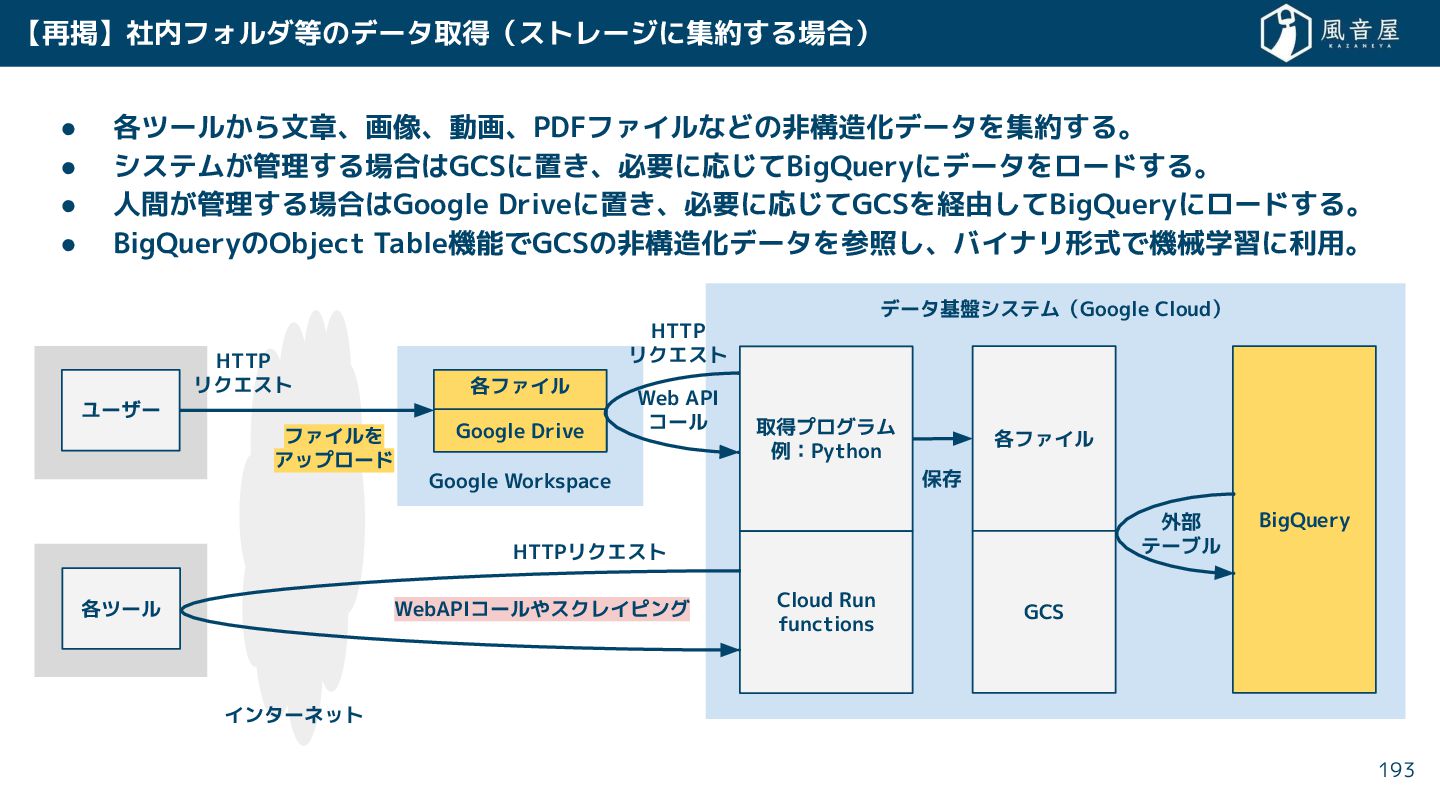{kind=link}
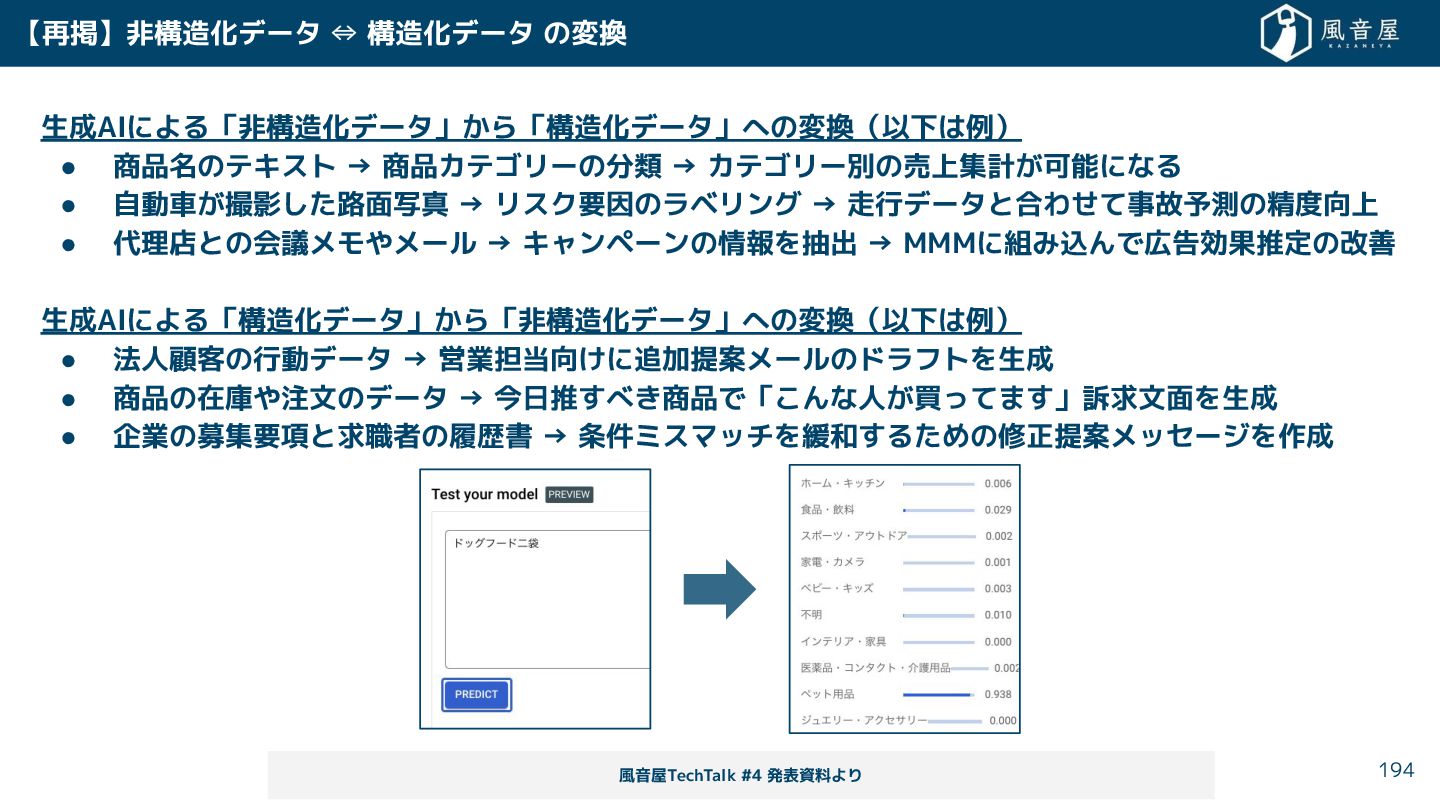{kind=link}
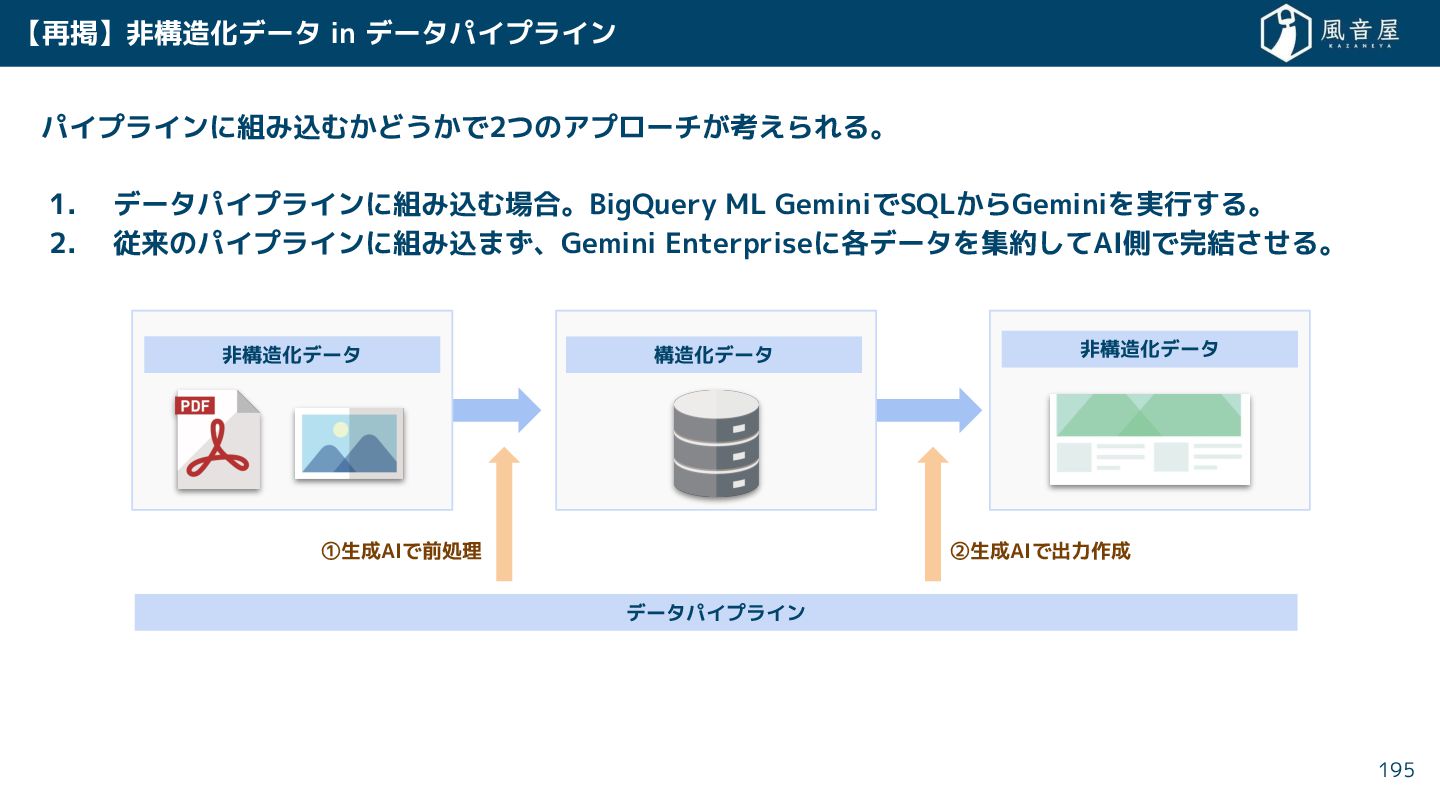{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
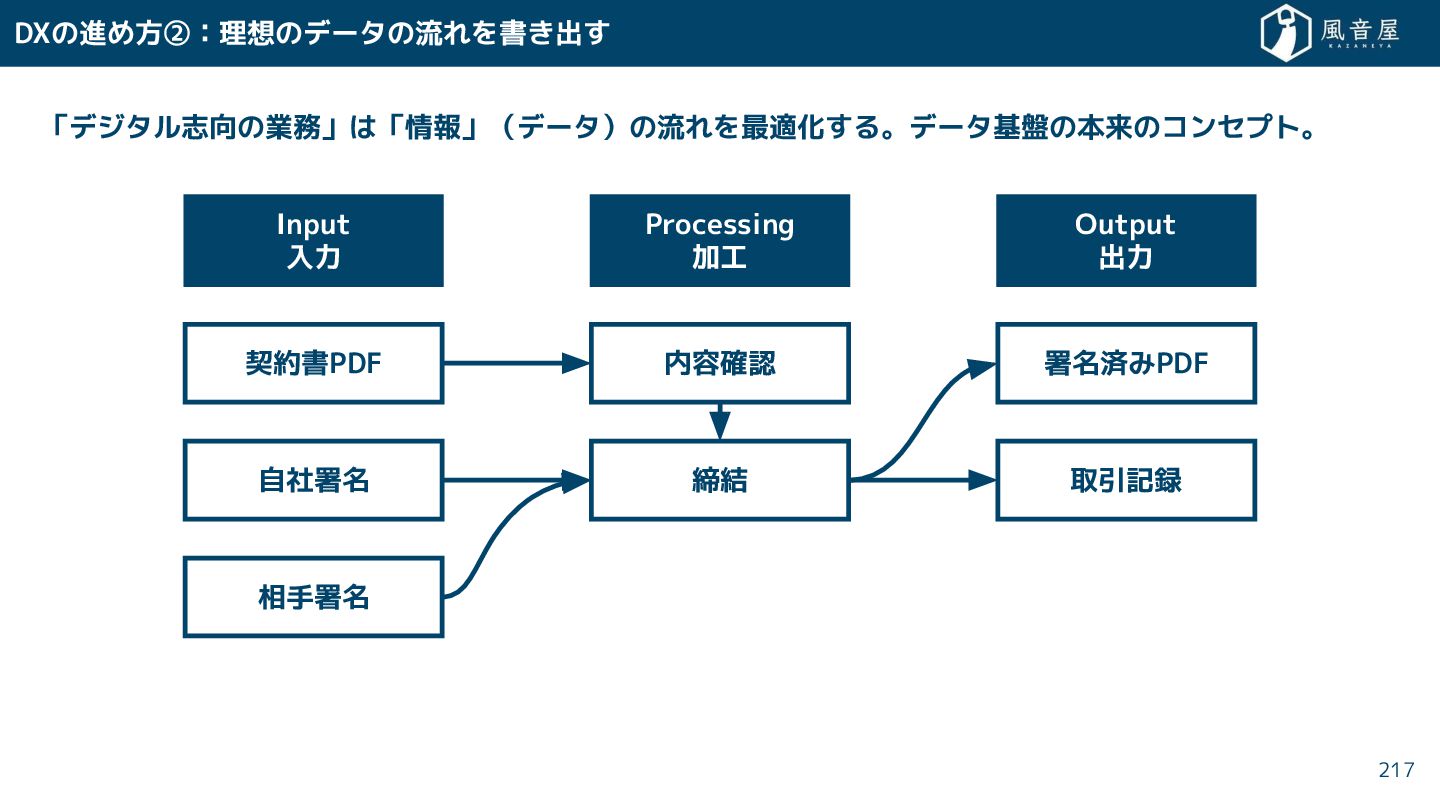{kind=link}
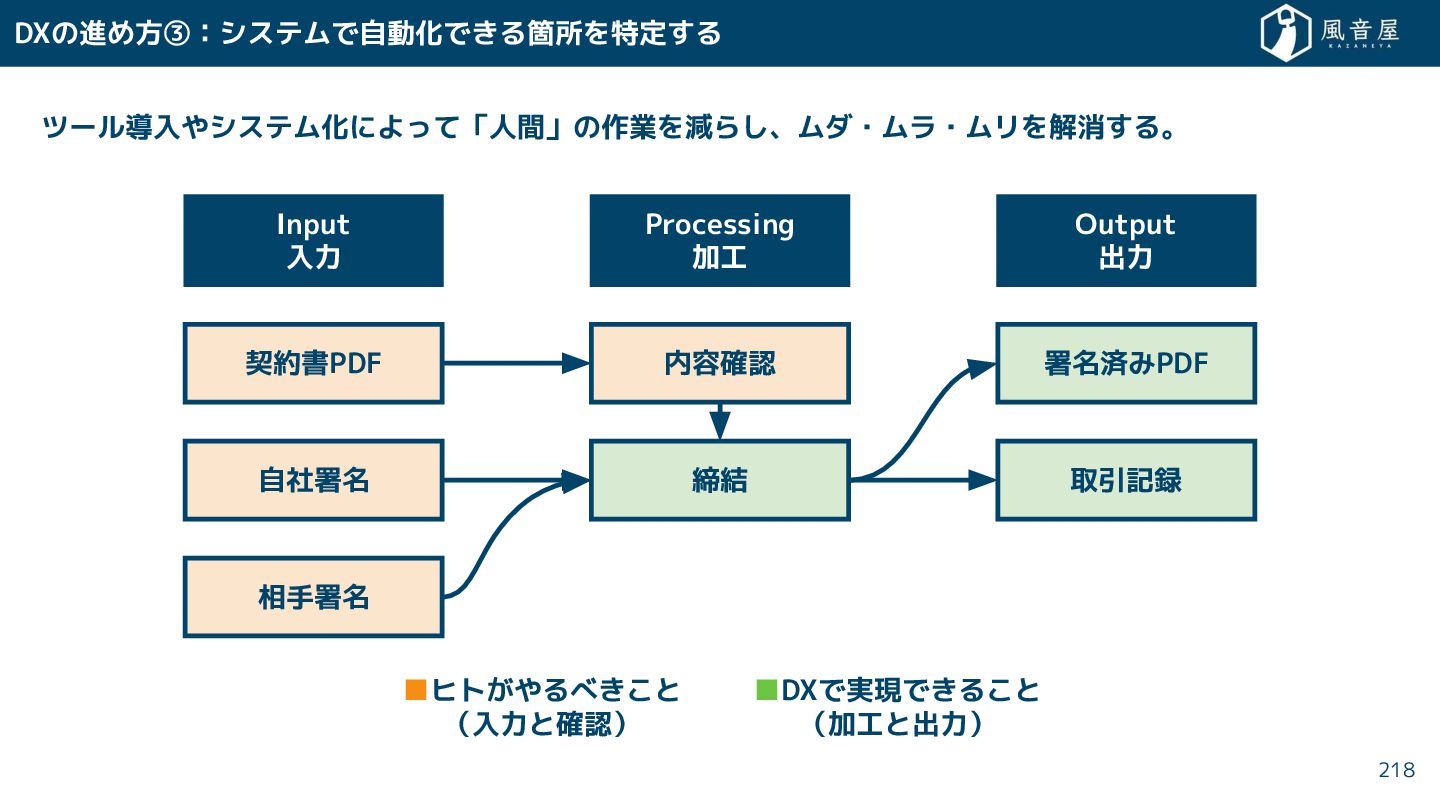{kind=link}
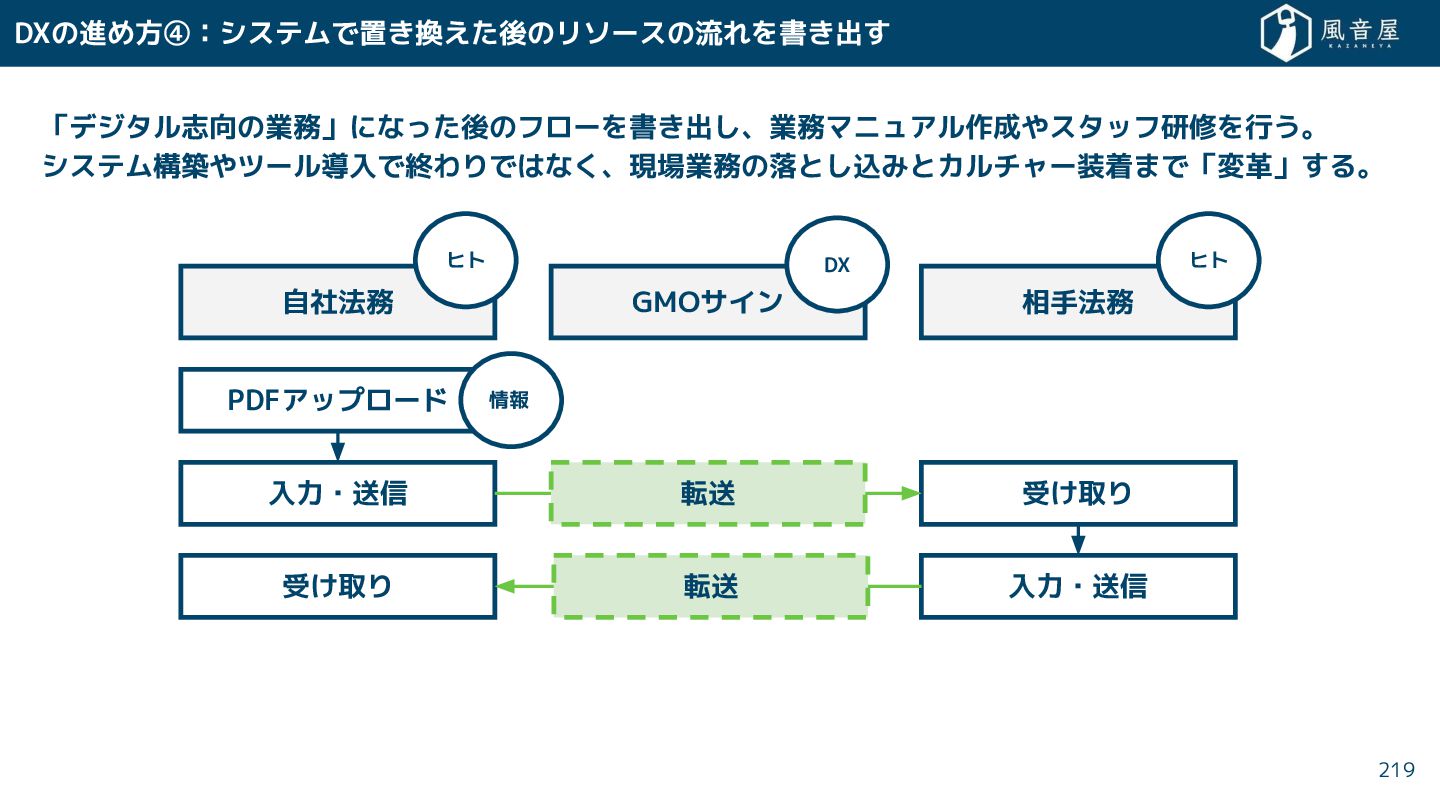{kind=link}
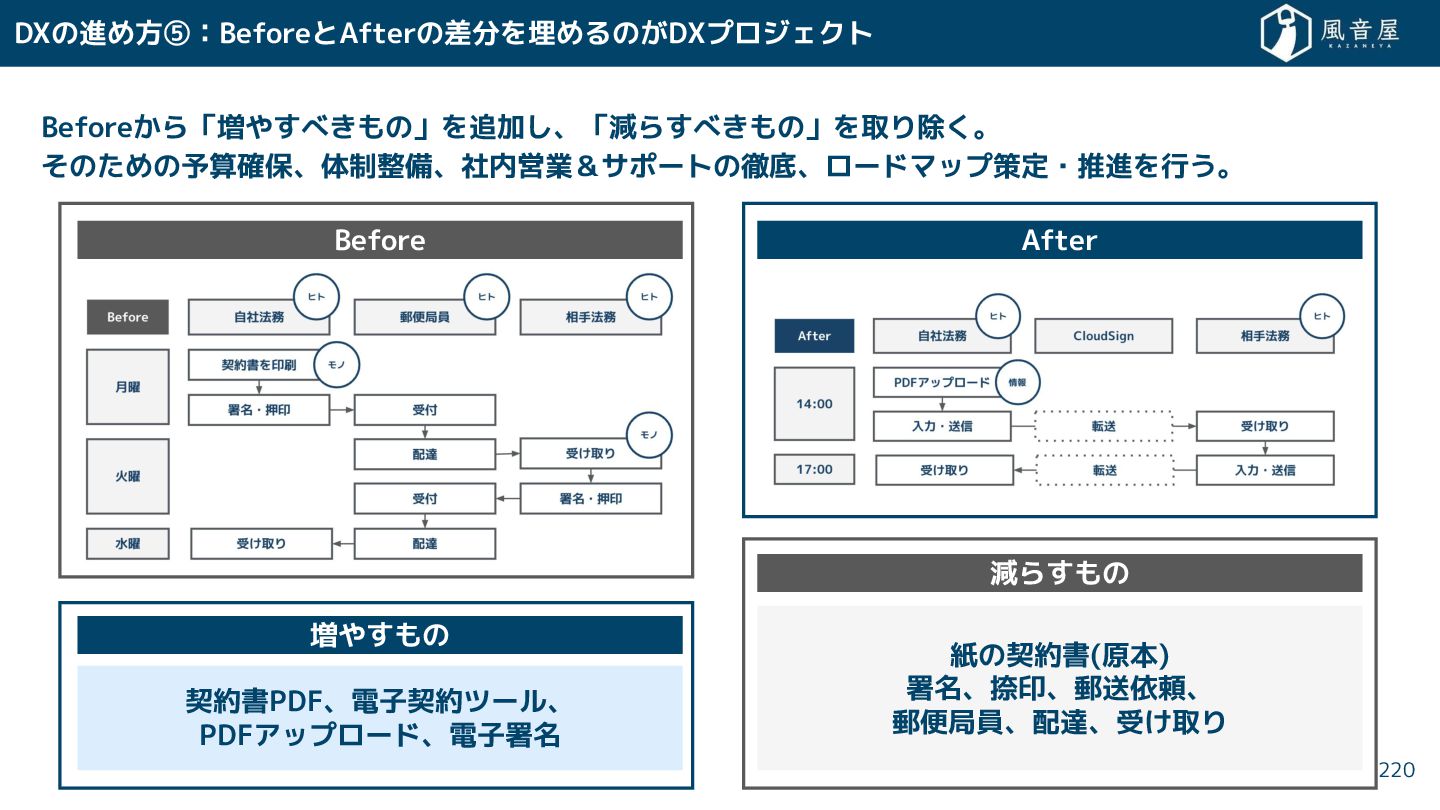{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
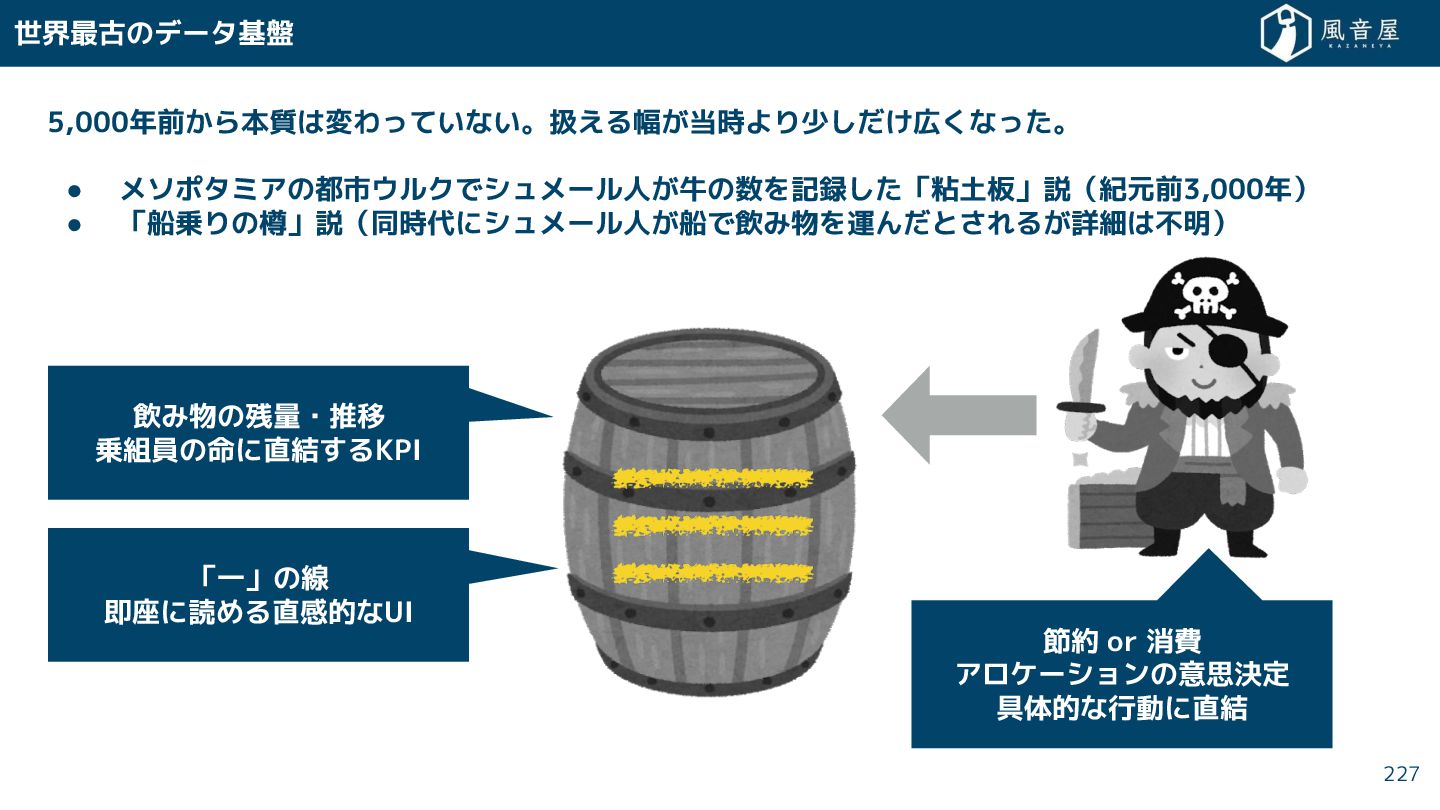{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}