these issues. Key Elements: — Model versioning — Firefly - A tool to run python functions as RESTful API (open source) — Compute environment to deploy models, run 12
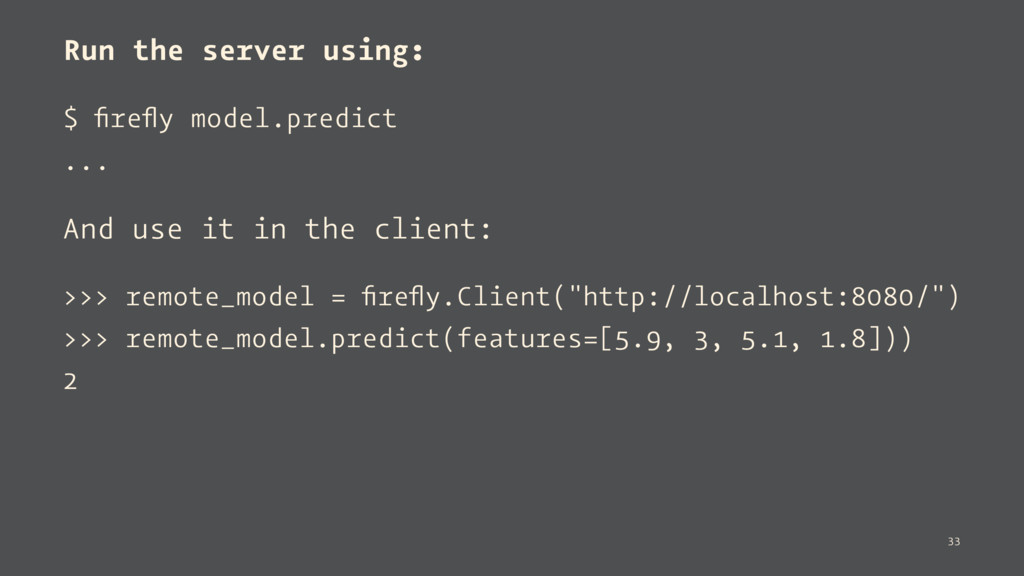
the current project project = roro.get_current_project() # Get repo for the model you are looking for repo = project.get_model_repository("credit-risk") # get the model image model_image = repo.get_model_image(tag="latest") print(model_image["Model-Version"], model_image["Accuracy"]) 19
project.get_model_repository("credit-risk") model_image = repo.new_image(model) model_image["Dataset-Features"] = "A,B,C,D" model_image["Training-Parameters"] = parameters model_image["Training-Accuracy"] = 0.35 model_image.save( comment="Built a new model using the data till August 2017") 20
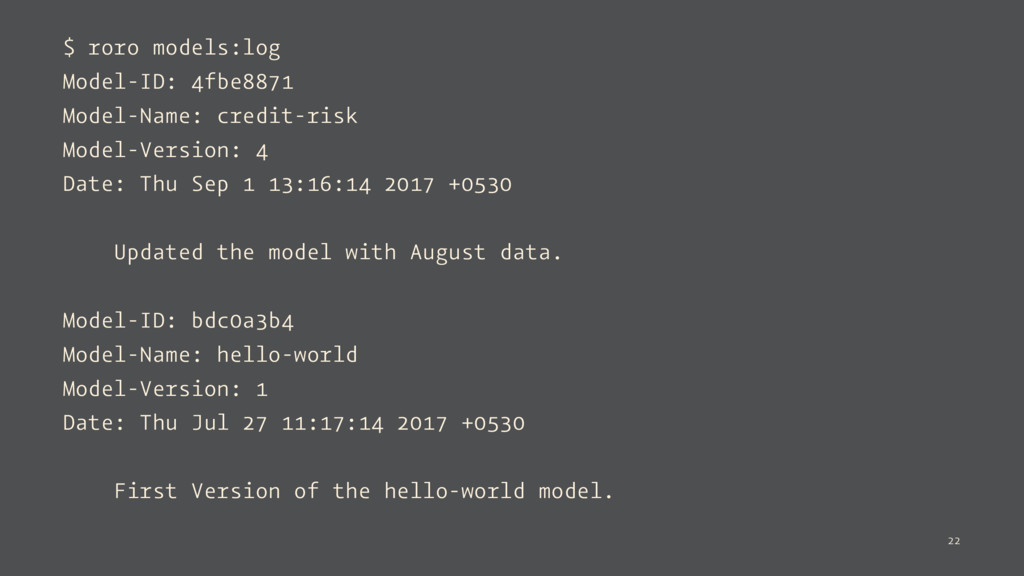
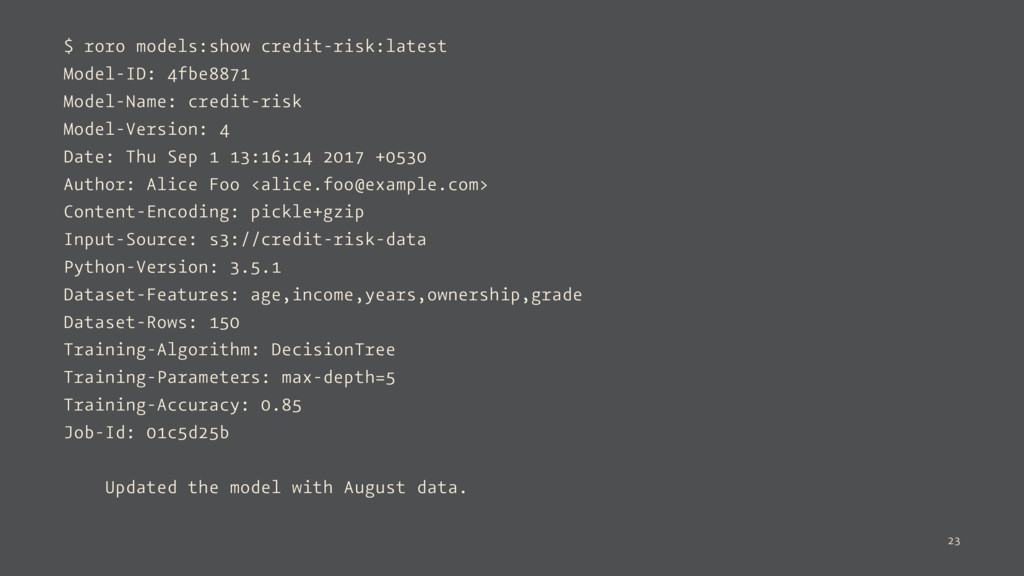
Thu Sep 1 13:16:14 2017 +0530 Updated the model with August data. Model-ID: bdc0a3b4 Model-Name: hello-world Model-Version: 1 Date: Thu Jul 27 11:17:14 2017 +0530 First Version of the hello-world model. 22
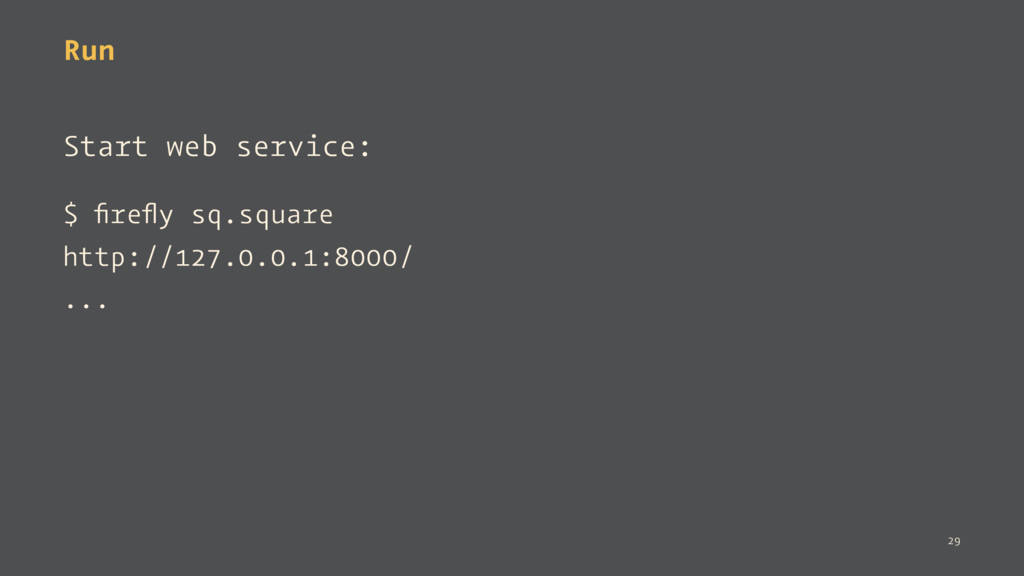
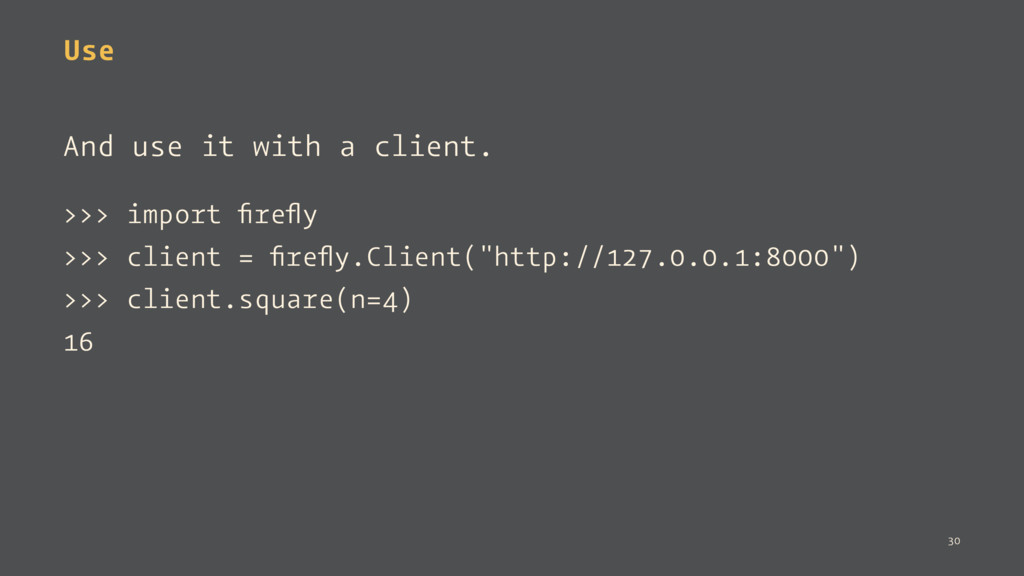
abcd1234 sq.square ... The client must pass the same token to autenticate it. >>> client = firefly.Client( "http://127.0.0.1:8000", auth_token="abcd1234") >>> client.square(n=4) 16 34
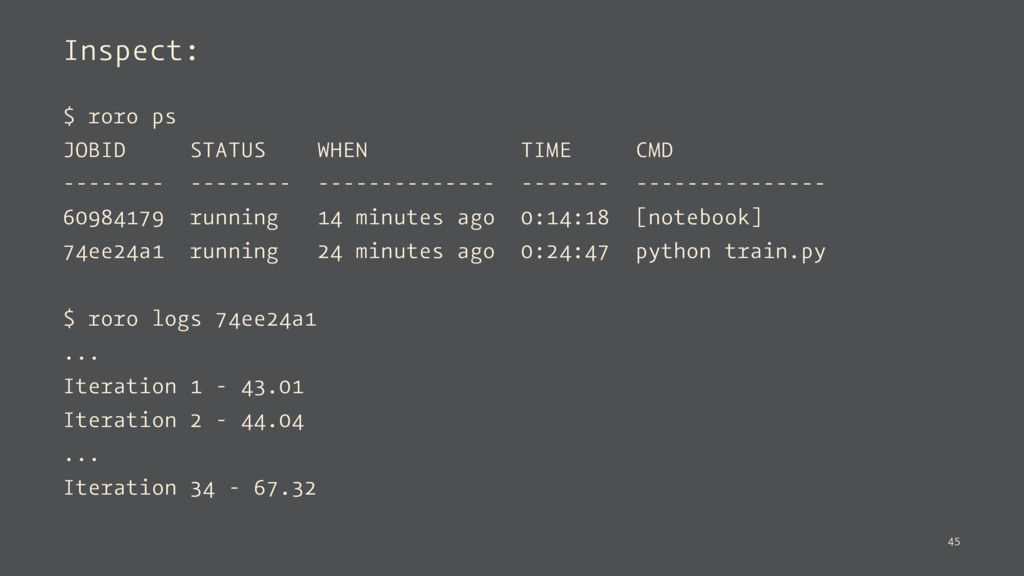
Created new job b42c12a0 $ roro run --gpu train.py Created new job b42c12a0 $ roro run:notebook Created new job 60984179 Jupyter notebook is available at: https://60984179-nb.rorocloud.io/?token=LNRZDpHdPhGLzf00 The jupyter notebook server can be stopped using: roro stop 60984179 44
The pace of innovation of a data-driven business is limited by the bottlenecks in their data science workflows — Data Science Platforms are essential to fill that gap 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}