Today's AI narrative is anchored in scale, and models are far from textbook statistical modeling. And yet, the plague that are hallucination shows us that statistical concepts such as uncertainty, still matter. I will discuss uncertainty quantification on a black-box classifier, in particular how errors can be decomposed, connecting epistemic and calibration error, and corresponding estimators. I will show how roping in a bit of decision theory, these, fairly theoretical, tools can be used to build better AI systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The narrative of progress [Varoquaux... 2025] More compute drive smarter](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_7.jpg){kind=link}
![The narrative of progress [Varoquaux... 2025] More compute drive smarter](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_8.jpg){kind=link}
![Biiiiiig AI [Varoquaux... 2025] G Varoquaux 8 “our results can](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_9.jpg){kind=link}
![The bitter lesson [Varoquaux... 2025] “leveraging computation is ultimately the](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_10.jpg){kind=link}
![Checking this narrative [Varoquaux... 2025] 1GB 500MB 5GB GPU Memory](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
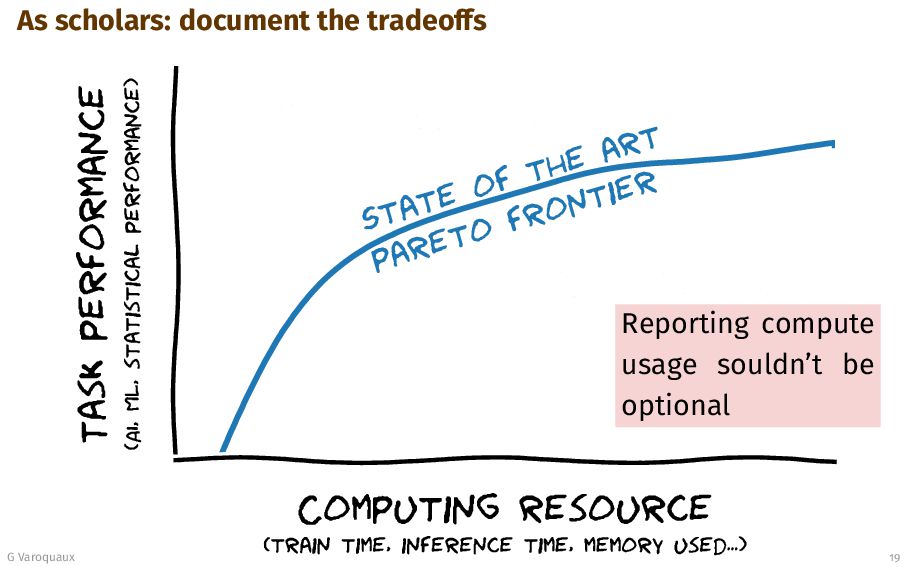{kind=link}
{kind=link}
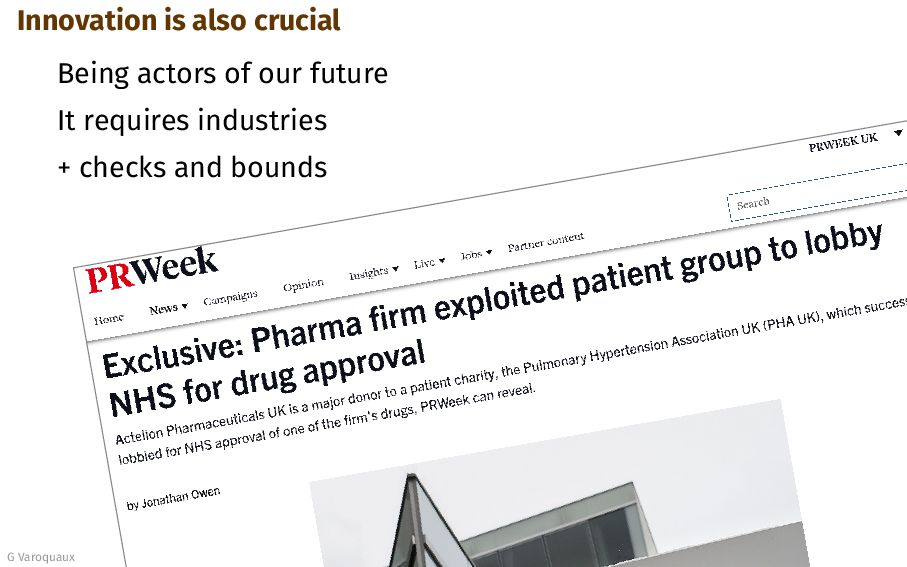{kind=link}
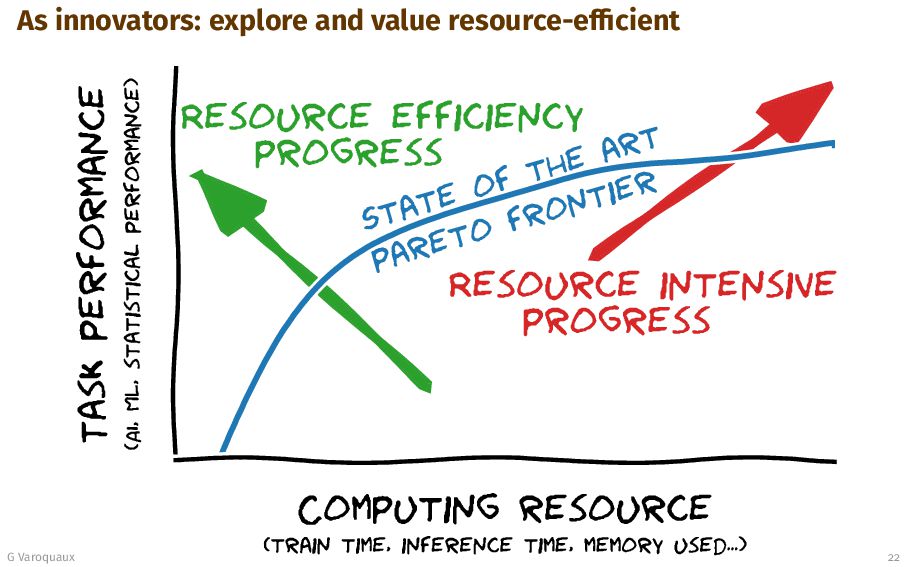{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
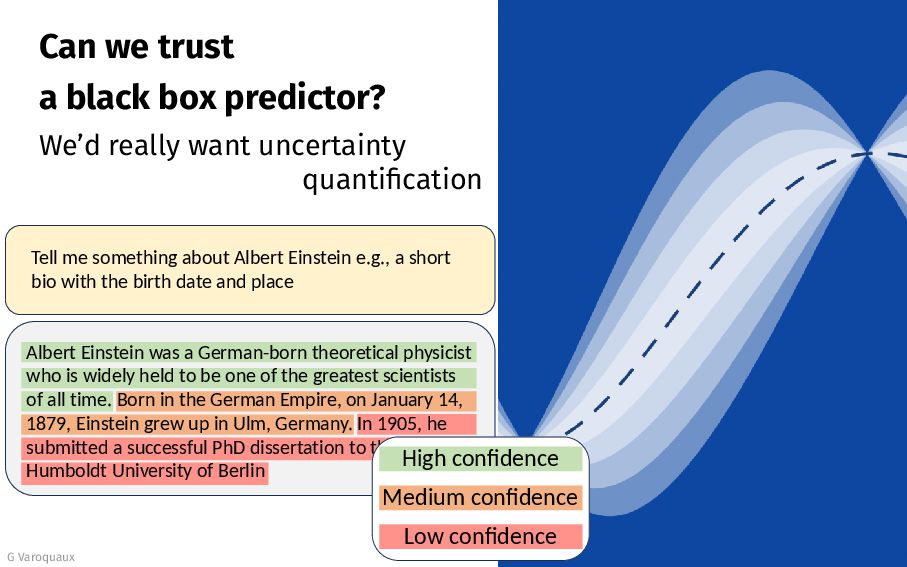{kind=link}
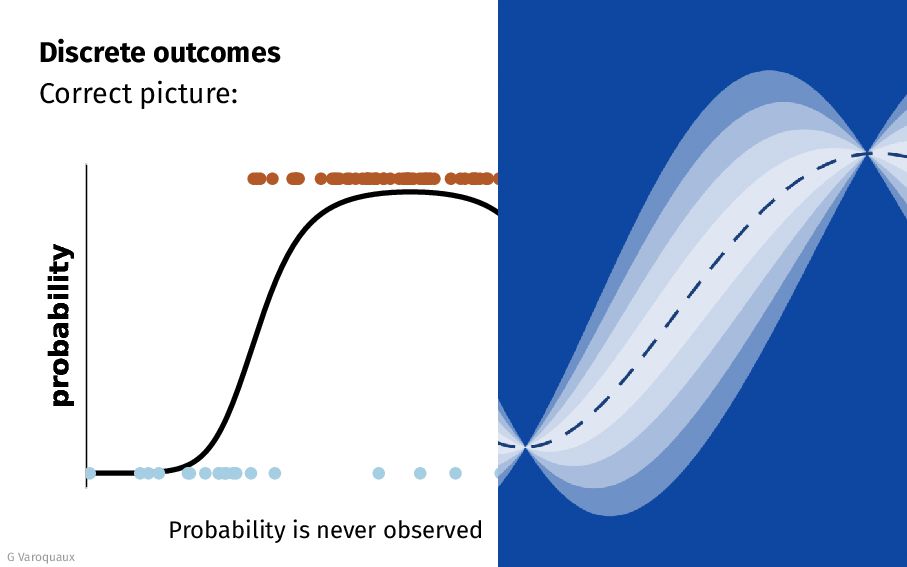{kind=link}
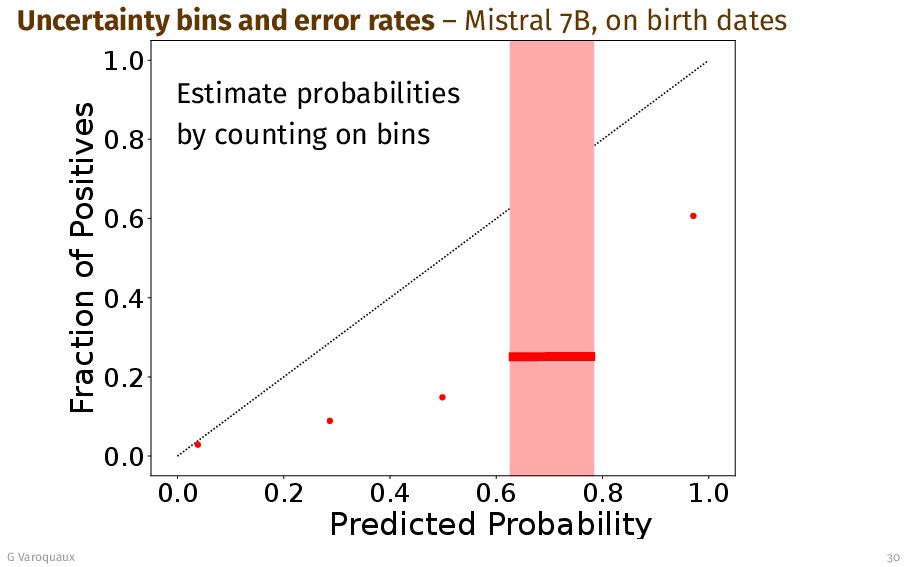{kind=link}
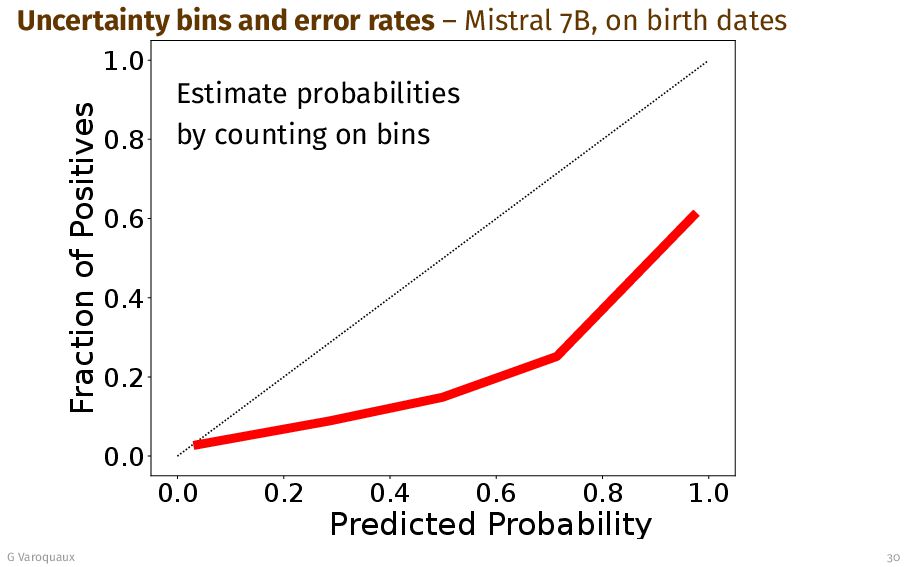{kind=link}
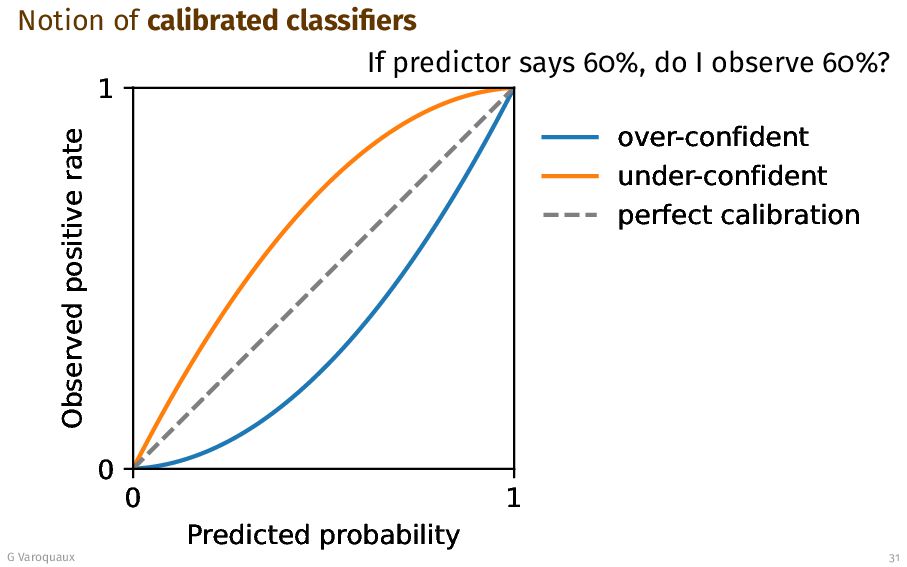{kind=link}
![Varying the queried nationality [Chen... 2024] 0.0 0.2 0.4 0.6](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
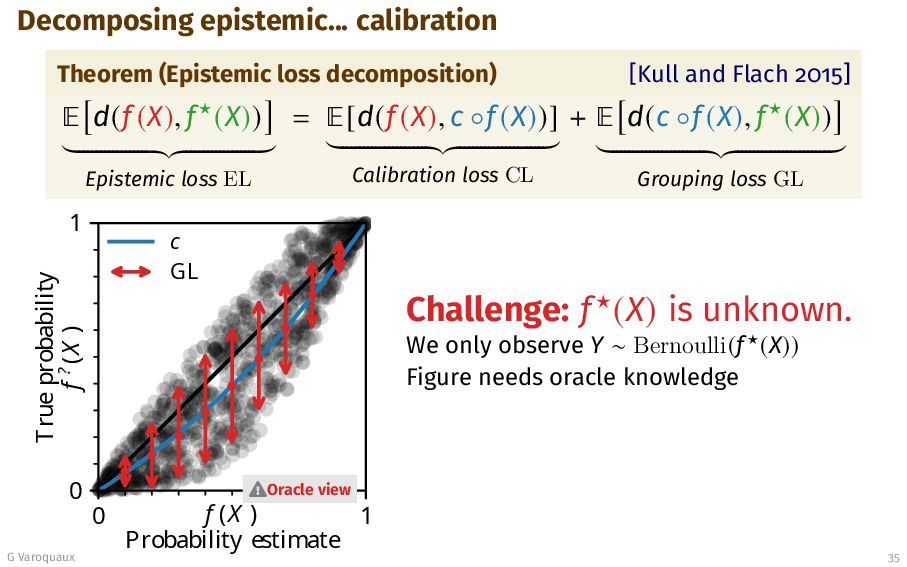{kind=link}
![Estimation principle: Law of total variance [g(X)] X P g(X)](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_45.jpg){kind=link}
![Estimation principle: Law of total variance [g(X)] X P g(X)](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_46.jpg){kind=link}
![Estimation principle: Law of total variance [g(X)] X P g(X)](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_47.jpg){kind=link}
![Estimation principle: Law of total variance [g(X)] = [¾[g(X) |](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_48.jpg){kind=link}
![Estimation principle: Law of total variance [g(X)] = [¾[g(X) |](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_49.jpg){kind=link}
![Estimation principle: Law of total variance [g(X)] = [¾[g(X) |](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_50.jpg){kind=link}
![Estimation principle: Law of total variance [g(X)] = [¾[g(X) |](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_51.jpg){kind=link}
{kind=link}
![Creating the partition of the input space [Perez-Lebel... 2023] Goal:](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_53.jpg){kind=link}
![From epistemic error to decisions [Perez-Lebel... 2025] 0 1 f](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_54.jpg){kind=link}
![Knowing oracle probabilities [Elkan 2001] Utility Event ¯ E Event](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_55.jpg){kind=link}
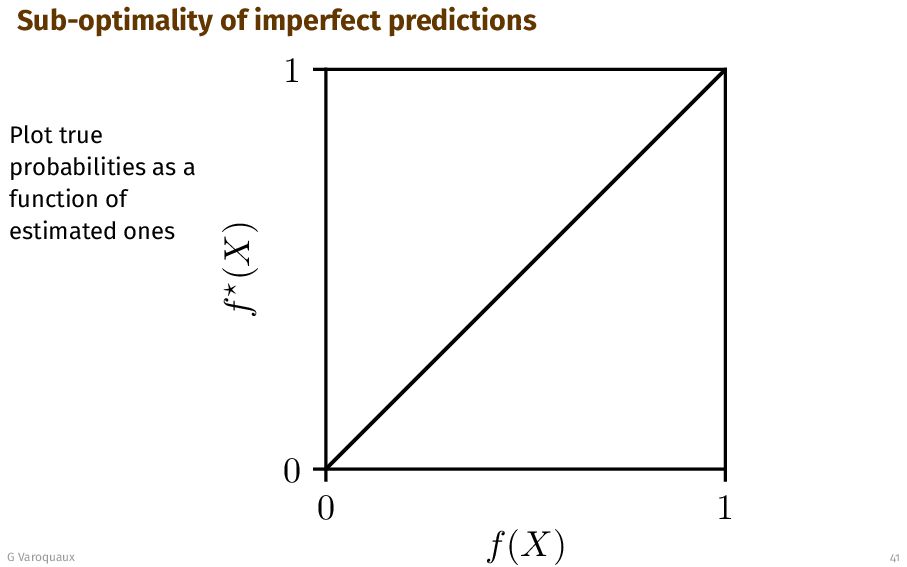{kind=link}
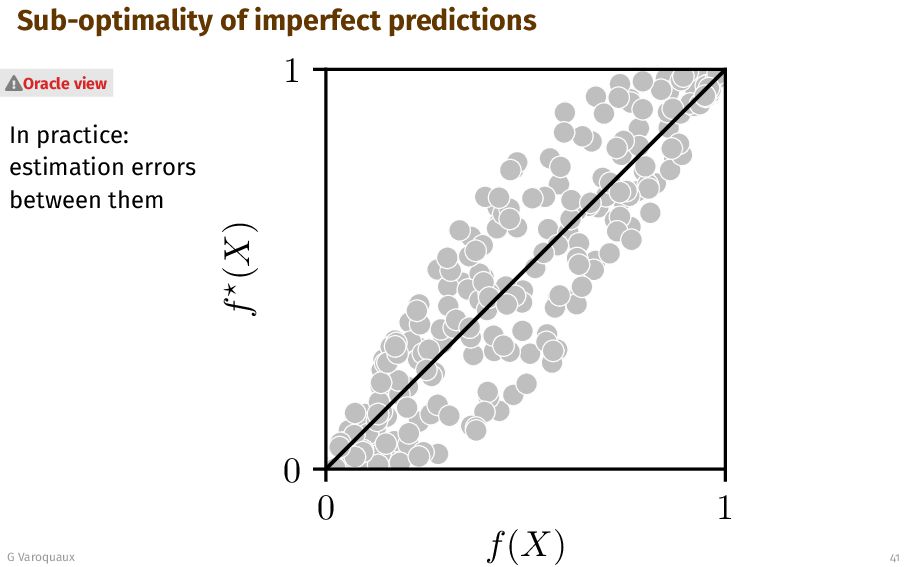{kind=link}
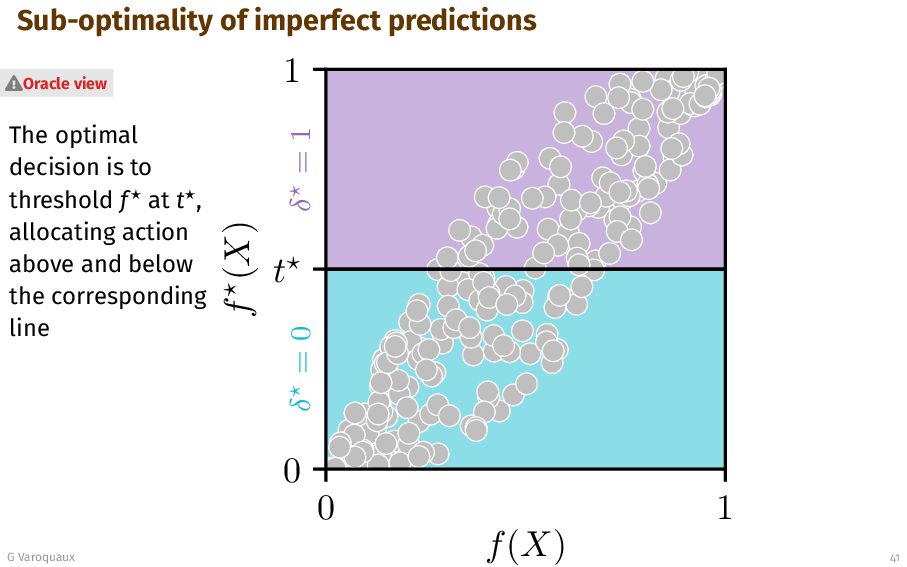{kind=link}
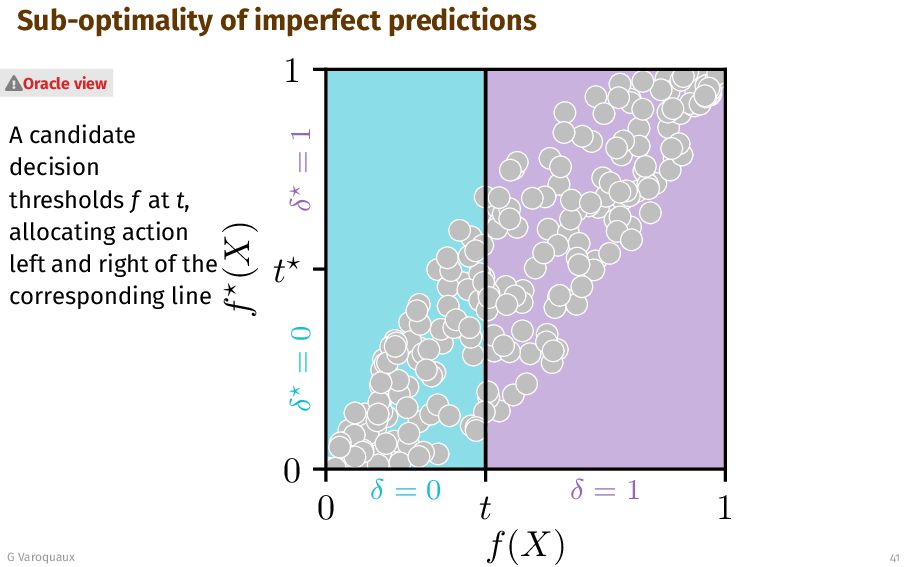{kind=link}
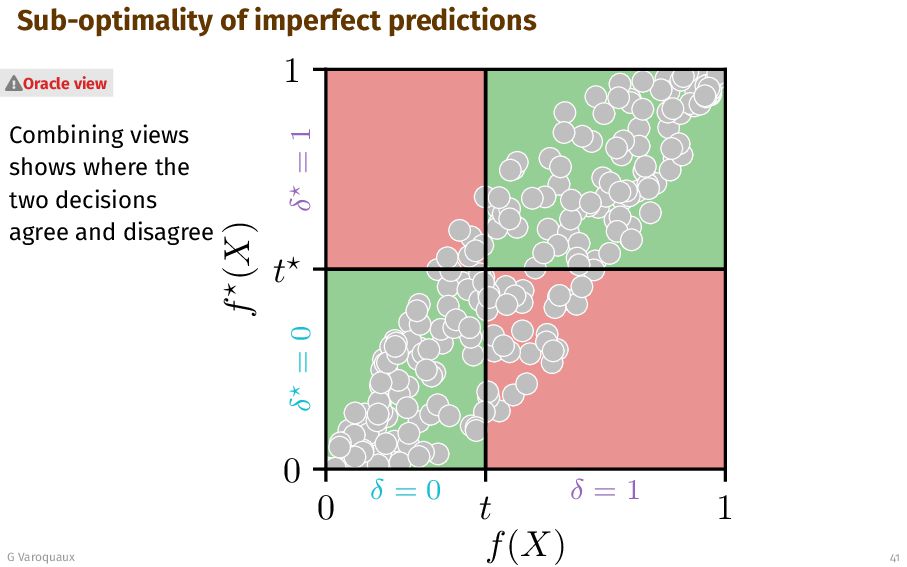{kind=link}
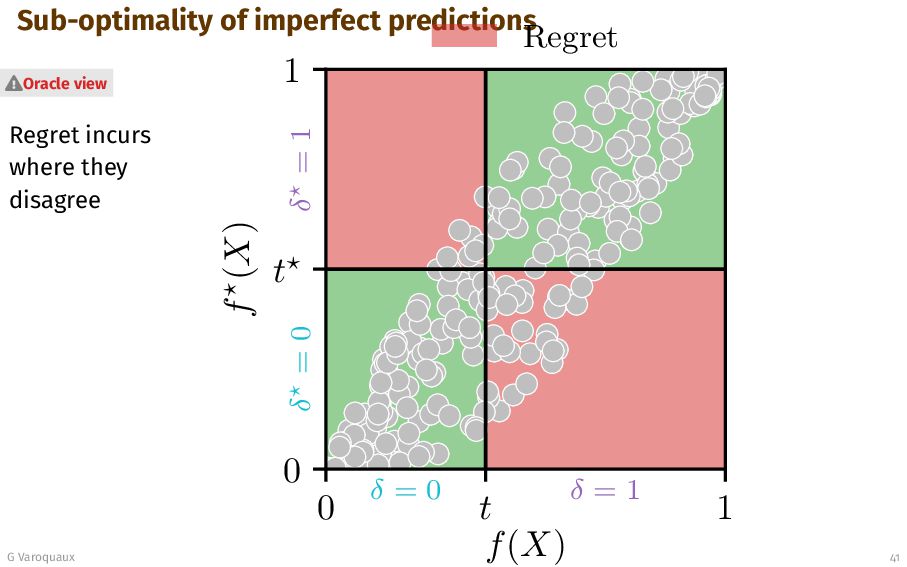{kind=link}
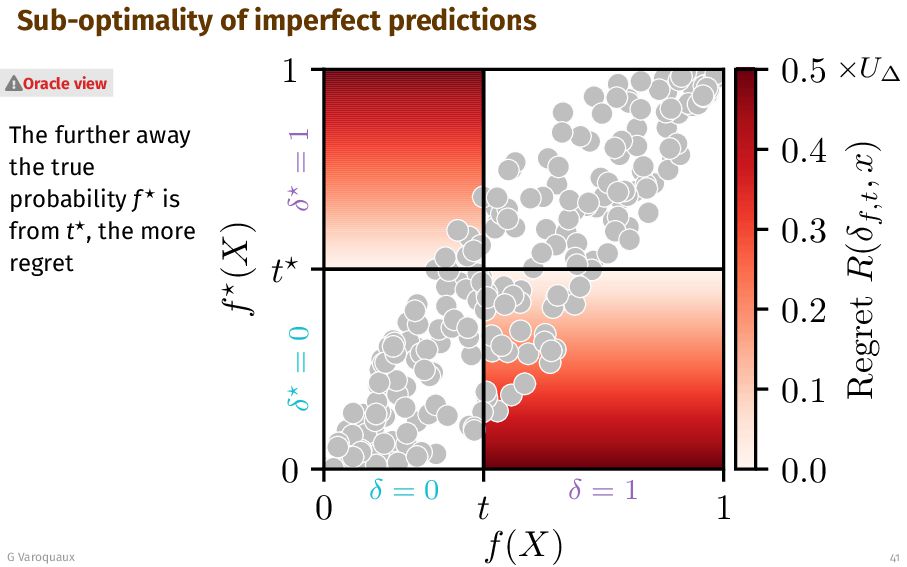{kind=link}
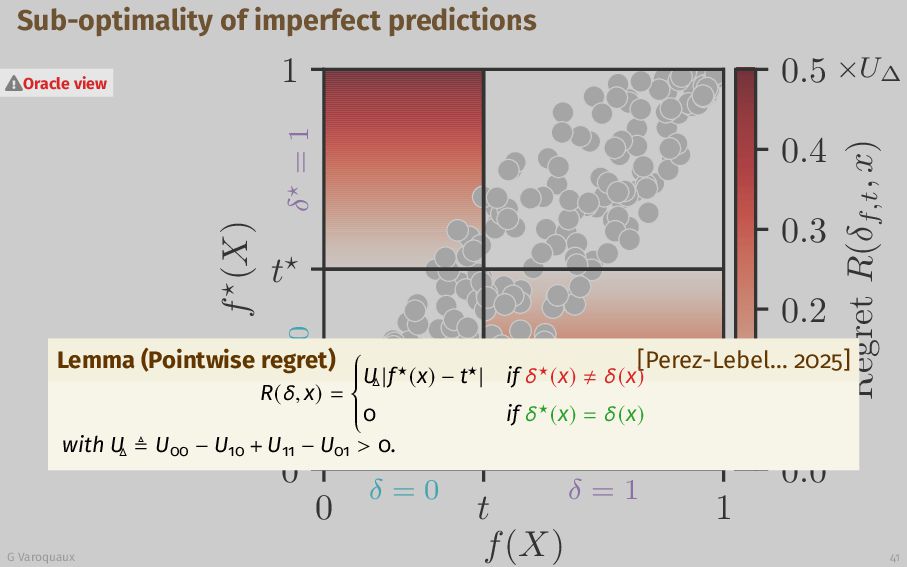{kind=link}
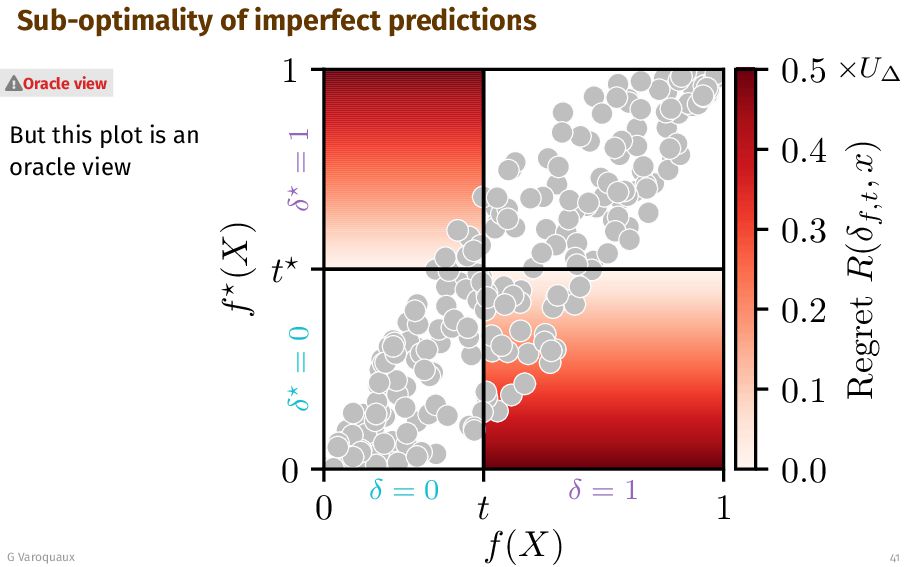{kind=link}
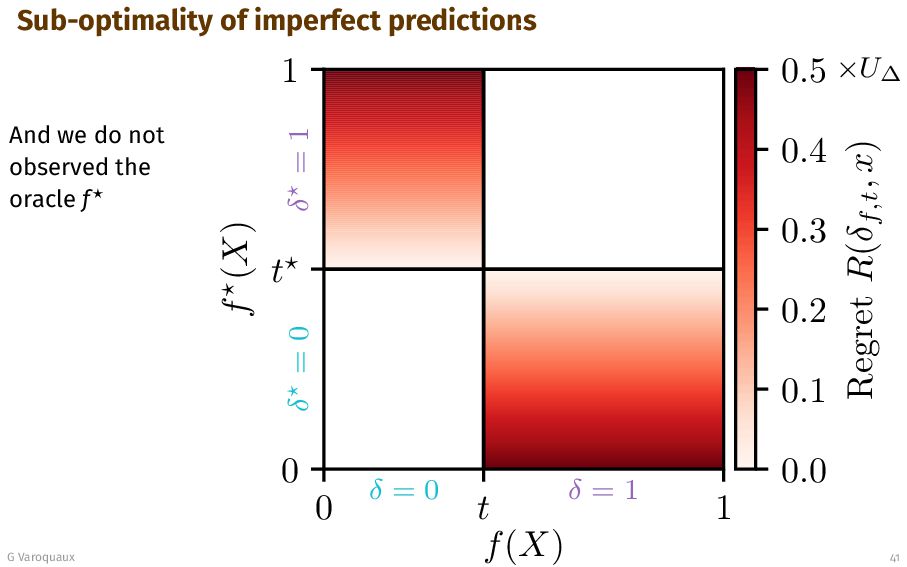{kind=link}
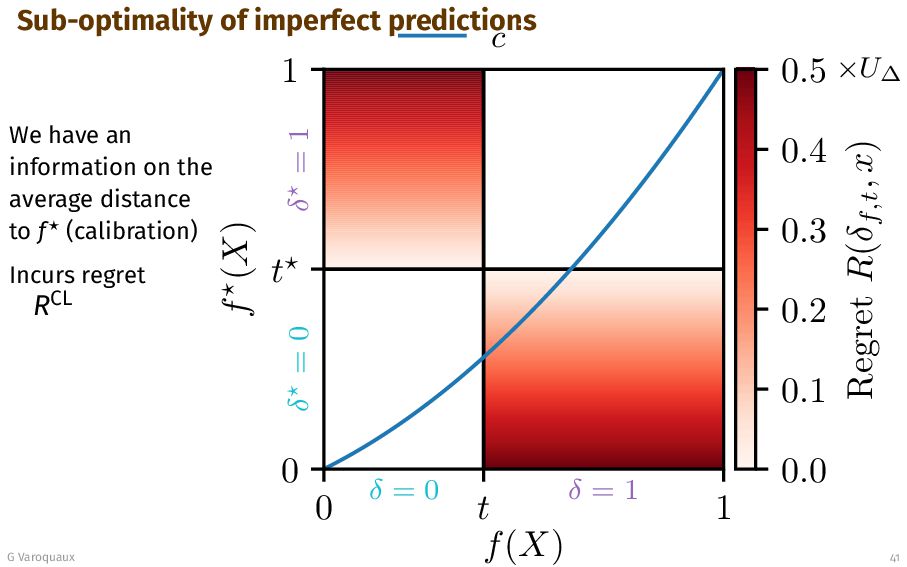{kind=link}
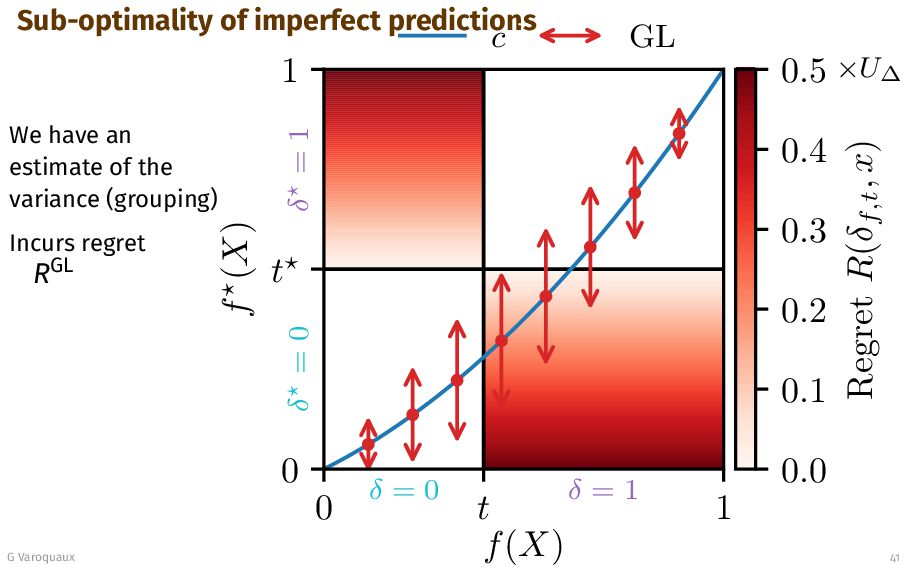{kind=link}
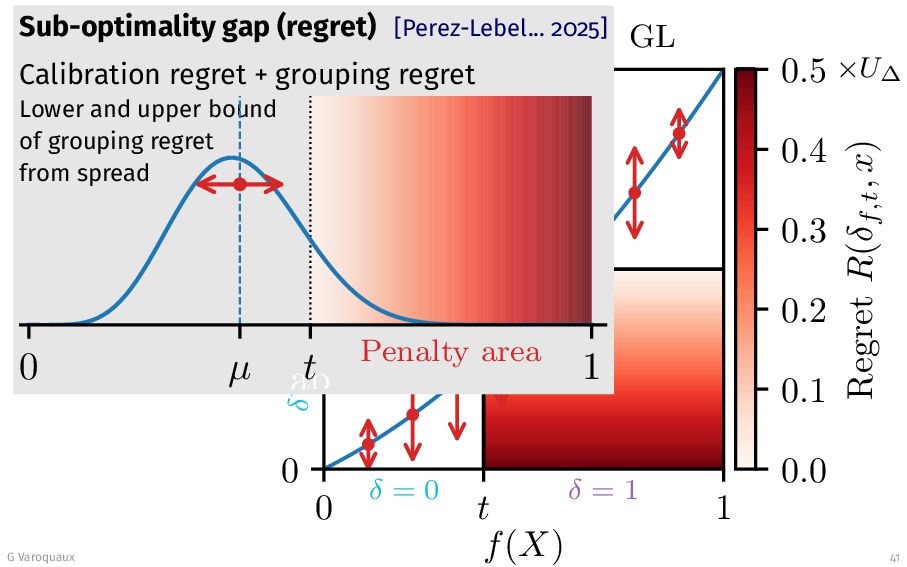{kind=link}
![Estimating local suboptimality [Melo... 2025] Estimates on the parcellation ⇒](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_69.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The role of small models [Chen and Varoquaux 2024] 0](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_74.jpg){kind=link}
![The role of small models [Chen and Varoquaux 2024] G](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_75.jpg){kind=link}
{kind=link}
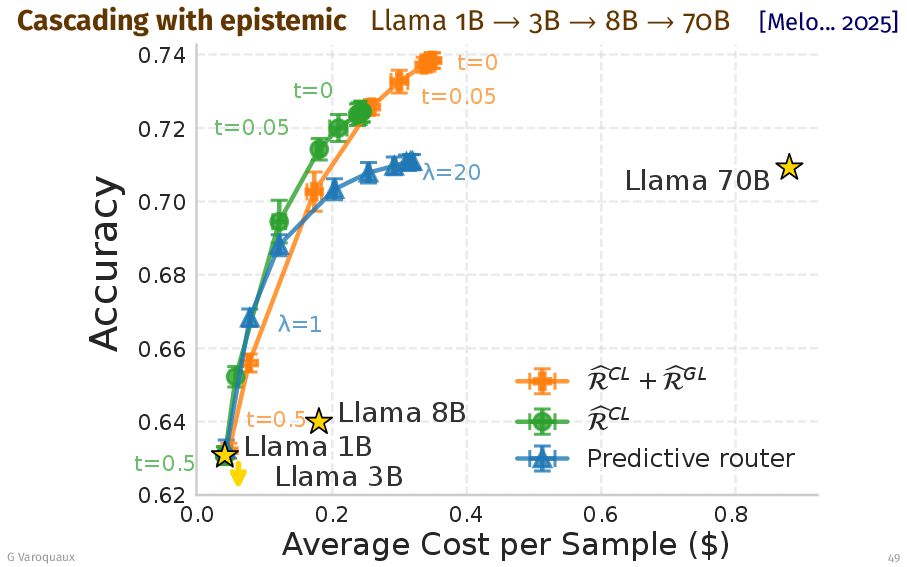
![Cascading with epistemic [Melo... 2025] Epistemic / aleatoric error!? “What](https://files.speakerdeck.com/presentations/234a3a76adbf436981c9853b6a8c66aa/slide_77.jpg){kind=link}
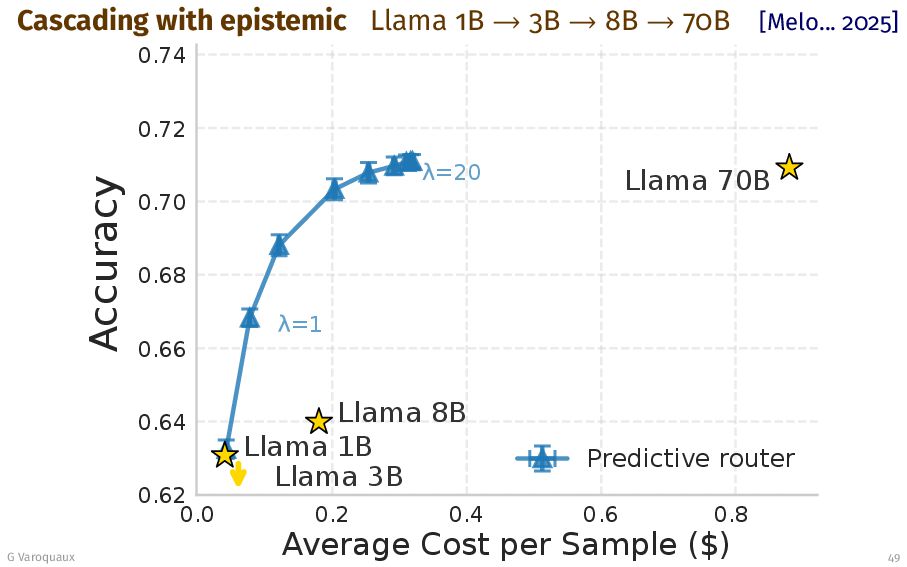{kind=link}
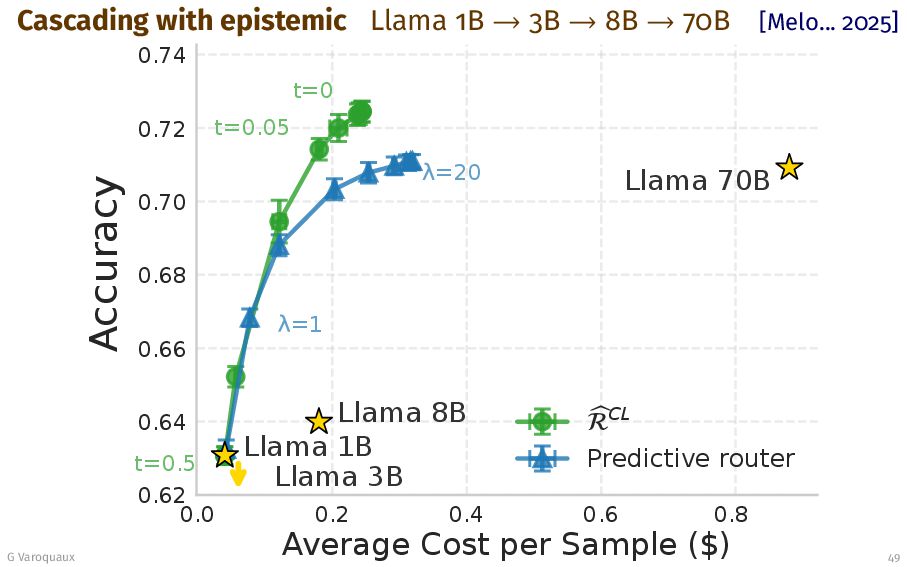{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}