high-performance, RESTful web services. A modern standalone stack like play and twitter libraries (commons, ostrich, server) with a cloud/devops orientation Named after a comic strip http://gunshowcomic.com/316 A new tool to solve a recurring problem today. Tools, problems, environments, techniques and assumptions never stay constant but evolve.
API endpoints • templates and their rendering engines • database access libraries • additional servlets and filters • special admin servlets like /abort, /reload • lifecycle bound objects (executors or connection pools) • health checks (periodically running application tests) • metrics monitors (check behavior in production) For all the above, there are well known implementations that provide APIs for using, integrating and extending them.
code for • Jetty - embedded, tunable web server • Jersey - JAX-RS, higher level abstraction over servlets • Jackson - JSON processor • Logback - successor of log4j for logging • Metrics - a library for application runtime metrics • Liquibase - a tool for database refactoring/migration • Hibernate - the well known ORM • JDBI - an alternative database access API • Mustache, Freemarker - template engines
you can’t optimize it. Compare A. Our code uses HAL and runs on death star B. At ~2,000 req/sec, latency jumps from 13ms to 453ms. Provides Gauge, Counter, Meter, Histogram, Timer, Health Check programmatically or instrumented (@Timed, @Metered, @Gauge) Monitoring files, logs, http/json, monitoring systems(Graphite, Ganglia)
write code following dropwizard’s conventions and API • provide the service configuration in a single yaml file • java -jar service.jar server configuration.yaml From my experience people new to dropwizard either love it because of all these features or hate it because of a single one of them (each one gets equal 33.33% disapproval) More on these later.
way to configure. No .properties or .xml files in the classpath or in META-INF/ or in “hidden/non standard” server places logging: level: INFO http: port: 8080 database: driverClass: org.postgresql.Driver httpClient: maxConnections: 10 Dropwizard provides sensible defaults for most uses
pack this in a war and deploy @Path("/") @Produces(MediaType.APPLICATION_JSON) public class TeamsServiceResource { @Context private RedisPool pool; @GET @Path("{name}") @Produces({MediaType.APPLICATION_JSON}) public Team getTeam(@PathParam("name") String name) { // implementation omitted } }
hold your configuration. The configuration.yaml file will be deserialized to this pojo using Jackson and will be validated with hibernate validator(@NotNull, @NotEmpty, @Min, ...) Then extend dropwizard’s default service, to create yours public class TeamsService extend Service<TeamsServiceConfiguration> { // override what is needed }
is called a bundle. Think of them as modules or plugins. A service out of the box uses only the bundles for jetty, jersey and metrics. Additional ones (hibernate, views, liquibase) must be declared for a service public void initialize( Bootstrap<TeamsServiceConfiguration> bootstrap) { bootstrap.setName("dropwizard-example"); bootstrap.addBundle(new AssetsBundle("/assets/", "/")); bootstrap.addBundle(new ViewBundle()); bootstrap.addBundle(new MigrationsBundle()); }
the things bundles provide. These are gathered in an environment. Note: be very explicit. No shortcuts like autowiring public void run( TeamsServiceConfiguration conf, Environment env) { env.addResource(TeamsServiceResource.class); env.addResource(new TeamsServiceResource(“custom”); env.addHealthCheck(new TeamsHealthCheck(“teamshealth”)); env.managedExecutorService(executor); env.addTask(new ShutdownTask(“shutdown”); env.addServlet(new MyViewServlet()); }
Service Endpoints GET http://localhost:8080/teams/ GET http://localhost:8080/teams/{name} POST http://localhost:8080/teams/{name} Admin Console POST http://localhost:8081/tasks/gc (dropwizard) POST http://localhost:8081/tasks/shutdown (user) GET http://localhost:8081/ping GET http://localhost:8081/healthcheck GET http://localhost:8081/threads GET http://localhost:8081/metrics
resources • OAuth2 authentication (no token exchange, only auth) • database migrations with liquibase • instrumented rest client with Apache http or jersey Commands manage applications with custom cli arguments and code java -jar hello-world.jar db status helloworld.yml java -jar hello-world.jar queues persist helloworld.yml
dropwizard. They usually are build on jersey’s SPI // from views bundle env.addProvider(ViewMessageBodyWriter.class); // from hibernate bundle DatabaseConfiguration dbConfig = getDatabaseConfiguration(configuration); sessionFactory = sessionFactoryFactory.build( environment, dbConfig, entities); env.addProvider(new UnitOfWorkResourceMethodDispatchAdapter(sessionFactory));
as small as possible. You must declare everything you are going to use. Sometimes this is simple. Templates for example: public class TeamView extends View { public TeamView(String name, List<String> members) { // the view file goes on resources/same package super("Team.mustache"); } }
hibernate bundle protected HibernateBundle( Class<?> entity, Class<?>... entities) {...} The bundle builds the sessionFactory entirely programmatically. It consults only the yaml configuration not hibernate.cfg.xml. To make it easier dropwizard provides AbstractDao<T> and @UnitOfWork.
<changeSet id="1" author="anastasop"> <createTable tableName="teams"> <column name="id" type="bigint" autoIncrement="true"> <constraints primaryKey="true" /> • No additional configuration like liquibase.properties • src/main/resources/migrations.xml packed with service • Liquibase runner integrated as dropwizard commands ◦ java -jar hello-world.jar db migrate helloworld.yml ◦ no need for separate cli tool or maven plugin ◦ more script control than mvn lifecycle or web listener
monitoring RESTful web applications. It combines the power of jetty, jersey and metrics to provide a simple, coherent and powerful toolbox for developers and devops. Main features • single standalone jar for deployment (embedded jetty) • centralized application configuration using yaml • developer friendly as it’s based on a proven java stack • devops friendly with metrics, health checks and tasks • admin friendly with commands • creates production ready services very fast
used a lot in enterprise computing ◦ bureaucratic, heavy, not friendly • Ruby, Python, Javascript devs view of java ◦ all the above + difficult, rigid, not very expressive Today java is having a renaissance. • Many companies start using more and more java ◦ codebase size and performance scales better • Transition should be easy and smooth ◦ traditional java (JEE, spring) does not help
in say Ruby/Sinatra start with: get '/hello/:name' do # matches "GET /hello/foo" and "GET /hello/bar" # params[:name] is 'foo' or 'bar' "Hello #{params[:name]}!" end To write a web application in java that uses HTTP, MySQL and JSON first write code for a PublishedNetworkService that uses a RequestResponseProtocol over a ReliableStreamTransport, persists data to a StructuredDataStore and returns a RenderableMessage. Then configure the framework to wire HTTP, JDBC, JSON.
things @Path("/") @Produces(MediaType.APPLICATION_JSON) public class TeamsServiceResource { @GET @Path("{name}") @Produces({MediaType.APPLICATION_JSON}) public Team getMembers(@PathParam("name") String name) {} } It does not try to do magic behind the scenes env.addResource(TeamsServiceResource.class); Spring and JEE, try to simplify things but...
it ◦ search repos, use best solutions, contribute back • Libraries are a better paradigm than frameworks ◦ work the same in different stacks and languages • Some java techniques are abused by large frameworks ◦ class scanning, runtime code generation, autowiring • Developers prefer to assemble their own stacks ◦ simpler, easier to use, understand and explain ◦ see and handle the SQL generated by the ORM ◦ know how the object graph is constructed ◦ track HTTP request, response handling ◦ debug and profile applications better
the proper runtime environment. Essentially, it is a set of conventions that must be manually satisfied. Examples JEE: web.xml, application-server.xml, JNDI Spring: applicationContext.xml, runtime.properties GNU: ./configure; make; make install Microsoft: .MSI, Windows registry Note the last 2 are automated but not 100% bullet proof
the application - Who satisfies the configuration? - The owner of the runtime environment There must be some common conventions so that these two can come to agreement. The most successful so far is JEE “The application is written according to JEE, packaged as a standard EAR and runs after deployment in a JEE server”
from prototype to production and beyond? • mvn jetty:run - properties in pom.xml • docker run - DockerFile • vagrant up - VagrantFile • JEE server - vendor specific xml files • hosted datacenter - all the above • cloud - git, cli + all the above An example using vagrant is Mozilla/Kuma the python/django framework that powers MDN
• Developers • QA • Management • Monitoring and Continuous Integration Tools • An application who depends on one of your services • A service that depends on one of your services • The datacenter/cloud provisioner Clearly each one of these has different requirements and expectations regarding acquiring, configuring and running the application.
and complex, dropwizard adopts a simple solution, a single yaml file, which is not the best for each different case but it suits all cases in the most uniform and straightforward way. The hope of the IT world is that progress in virtualization technology will make explicit configuration obsolete but we are not there yet.
an isolated single unix process • can use existing unix process management tools • no PermGen issues with hot deployment of WARs • no application server configuration and maintenance • no arcane deployment tools • easy dependencies resolution, no classloader troubles • no hidden application logs • no GC tuning to work with multiple applications
were big and expensive • more applications than machines • application servers ◦ total provisioning of the machines cluster ◦ multiplexing many applications on few machines Now • smaller, cheaper, more capable machines ◦ an application may run on a dedicated machine • big datacenters, on site or on the cloud • web scaling ◦ more machines for traffic, replication, fault tolerance
monolithic applications ◦ all parts written using the same stack, JEE Now • Write reusable services ◦ use best available stack for each service ◦ provision, deploy, monitor each one independently • Assemble applications from services ◦ loose coupling, reusability, distribution • Applications are big but individual services need not ◦ reusability at service level not only at code level
to a single vendor or standard seemed good ◦ everybody uses the standard after all • servers and standards are big and hard to master ◦ but so are our applications Now • Open source movement. Developers love it ◦ search repos, use best solutions, contribute back • Developers prefer to assemble their own stacks ◦ simpler to use and understand • Libraries are a better paradigm than frameworks ◦ work the same in different stacks and languages
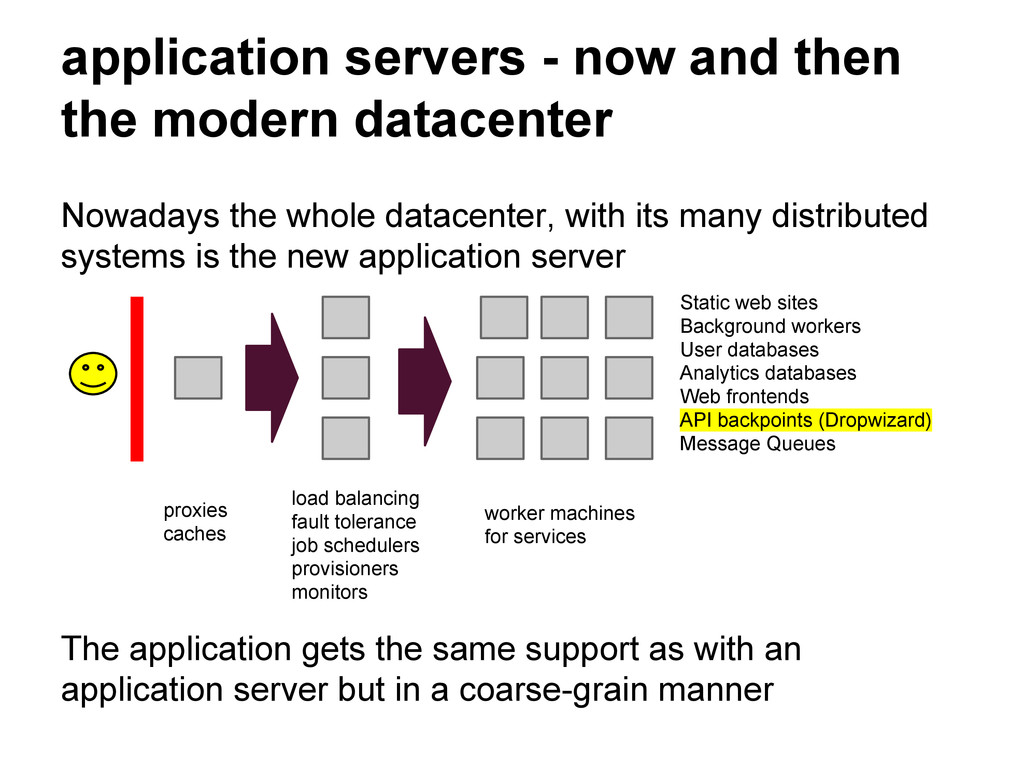
the whole datacenter, with its many distributed systems is the new application server The application gets the same support as with an application server but in a coarse-grain manner Static web sites Background workers User databases Analytics databases Web frontends API backpoints (Dropwizard) Message Queues load balancing fault tolerance job schedulers provisioners monitors worker machines for services proxies caches
Dropwizard-Jedis - An example application with Redis Articles for modern java stacks The Square stack - the java stack used at Square Heroku and Java - introduction for java developers The Twitter stack - the stack used at Twitter Talks Make features, not WAR - a presentation on InfoQ Autoscaling java Google I/O 2013 - dropwizard is compliant Twitter commons at Airbnb - a stack similar to dropwizard
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}