regex Regular Expressions are very useful for validating user input Regular Expressions can replace hundreds of lines of code We will look at Regular Expressions usage on Linux using a terminal app client side with JavaScript server side with PHP
any single character * preceding item matched 0 or more times ? preceding item matched 0 or 1 times + preceding item matched 1 or more times {n} preceding item matched n times {n,} preceding item matched n or more times
matched at most m times {n,m} preceding item matched n thru m times [...] matched with any single char in brackets [abcd] [⼩小中⼤大] [^...] matched with any single character not in brackets [^༂༆༊] [.-.] matched with any single character in range [0-9] ^ matched with start of string/line
in text data grep provides basic regexp/regex meta characters egrep extends the set of regexp/regex meta characters I will use egrep interactively to demonstrate the use of regex on sci-project
Counting in Unicode codepoints grep -P '^.{2}$' will match with flags *+,-./0123456 grep -P '^.{3}$' will match with keycap digits 789:;<=>? grep -P '^.{7}$' will match with full family emoji @ A B C D E F G
letter function Letʼs rewrite the function using regex function letter(c){ //returns true if c is ascii letter, else false return ((c>='a'&&c<='z')||(c>='A'&&c<='Z')); } function letter(c){ //returns true if c is ascii letter, else false return (/[a-zA-Z]/.test(c)); //or /[A-Z]/i.test(c) }
a Thai private car registration number entered into a form by a user. function car(reg){ //true if valid reg number, else false return (/^[1-9]?[กขงจฉธฐพภวษศสชฌฎญฆ]{2}[ ]*[1-9][0-9] {0,3}$/.test(reg)); }
address Evaluation of Websites for Acceptance of Email Addresses ⾒見見 usag.tech/wp-content/uploads/2017/09/UASG-Report- UASG017.pdf function email(e){ //true if valid email address, else false return (/^[о-䛪0-9]+\.[о-䛪0-9]+@([о-䛪0-9]+\.)+ೠҴ$/.test(e)); }
tweet text parsing code eg validation TLDs (Top Level Domains) ⾒見見 github.com/twitter/twitter-text/blob/master/js/ twitter-text.js Note use of RegExp object constructor regex can be built as quoted strings consequently regex can be split over multiple lines, making for a more easily readable regex
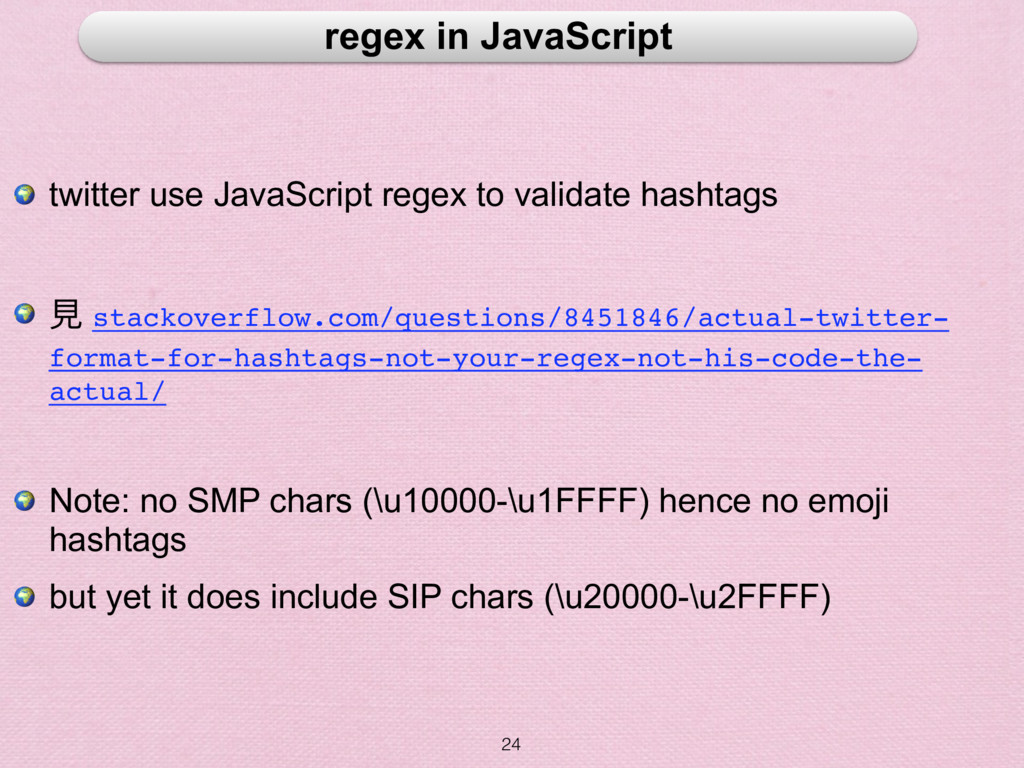
hashtags ⾒見見 stackoverflow.com/questions/8451846/actual-twitter- format-for-hashtags-not-your-regex-not-his-code-the- actual/ Note: no SMP chars (\u10000-\u1FFFF) hence no emoji hashtags but yet it does include SIP chars (\u20000-\u2FFFF)
test for match in string, returns matched text ⾒見見 w3schools.com/jsref/jsref_regexp_exec.asp function cnum(s){ //returns first chinese number in string return (/[⼀一⼆二三四五六七⼋八九][零⼀一⼆二三四五六七⼋八九]*/.exec(s)); }
all matches (as array) if g flag is used ⾒見見 w3schools.com/jsref/jsref_match.asp function cnum(s){ return (s.match(/[⼀一⼆二三四五六七⼋八九][零⼀一⼆二三四五六七⼋八九]*/g)); } cnum('⼩小⼭山⼀一⼆二三北北京四五南京') returns ["⼀一⼆二三","四五"]
a string with all (if g flag is used) matches replaced with replacement a programming challenge ➜ jsfiddle.net/coas/wda45gLp w3schools.com/jsref/jsref_replace.asp
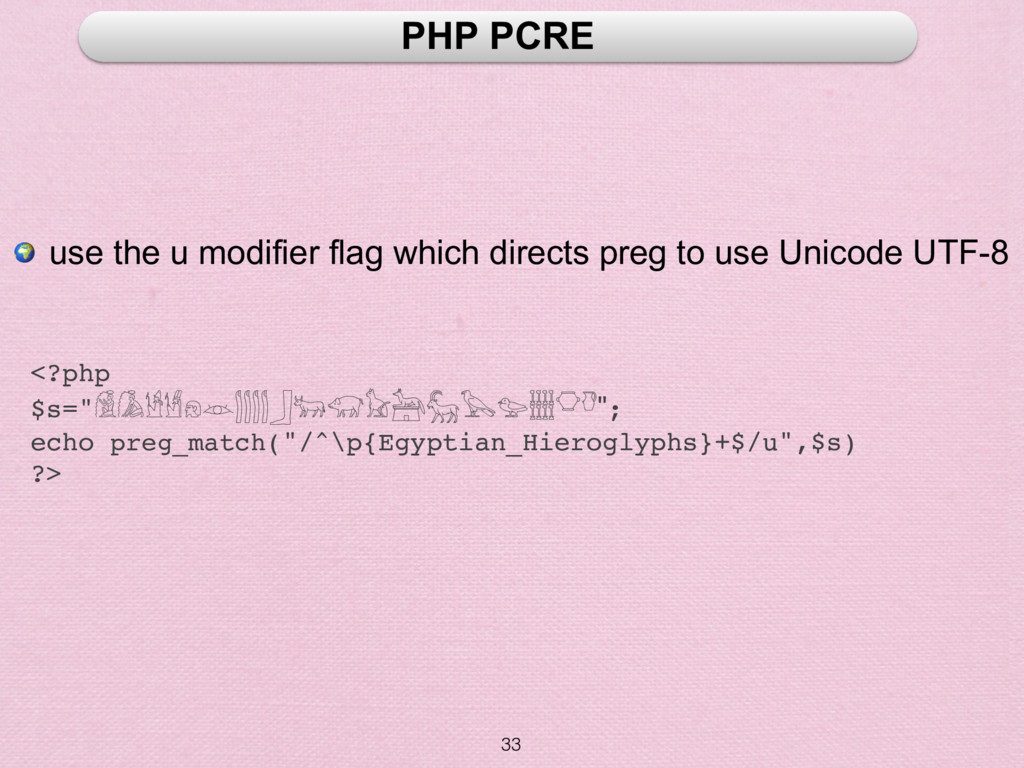
aforementioned JavaScript RegExp constructs + additional RegExp constructs to process Unicode character properties We will look at the use of PCRE in PHP ⾒見見 pcre.org
Every Unicode character is assigned to a single General Category Lu — Letter uppercase Ll — Letter lowercase Lo — Letter other Nd — Number decimal Sm — Symbol mathematical Sc — Symbol currency ... ⾒見見 codepoints.net/search?gc=Sm
match with char having property \P{property} — do not match with char having property \p{Lu}{3} — match with 3 uppercase letters \p{Sm}+ — match with 1 or more maths symbols \p{Devanagari} — match with a single devanagari char (devanagari is used for writing Hindi) php.net/manual/en/regexp.reference.unicode.php
add Latin, which includes the English alphabet add Common, which includes punctuation ⾒見見 en.wikipedia.org/wiki/Latin_script_in_Unicode $s="⼩小⼭山"; preg_match("/^\p{Han}+$/u",$s); $s="André is ⼩小⼭山"; preg_match("/^(\p{Han}|\p{Latin}|\s)+$/u",$s); $s="Andréʼs adopted Chinese name is ⼩小⼭山!"; preg_match("/^(\p{Han}|\p{Latin}|\p{Common})+$/u",$s);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![9 egrep - regex examples match using regex '^[a-zA-Z]$' string:](https://files.speakerdeck.com/presentations/f42810df9dea4efcbc4dd1fd15430a5f/slide_8.jpg){kind=link}
![10 egrep - regex examples match using regex '^0[0-9]{10}$' string:](https://files.speakerdeck.com/presentations/f42810df9dea4efcbc4dd1fd15430a5f/slide_9.jpg){kind=link}
![11 egrep - regex examples match using regex '^[⼀一⼆二三四五六七⼋八九]+$' string:](https://files.speakerdeck.com/presentations/f42810df9dea4efcbc4dd1fd15430a5f/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}