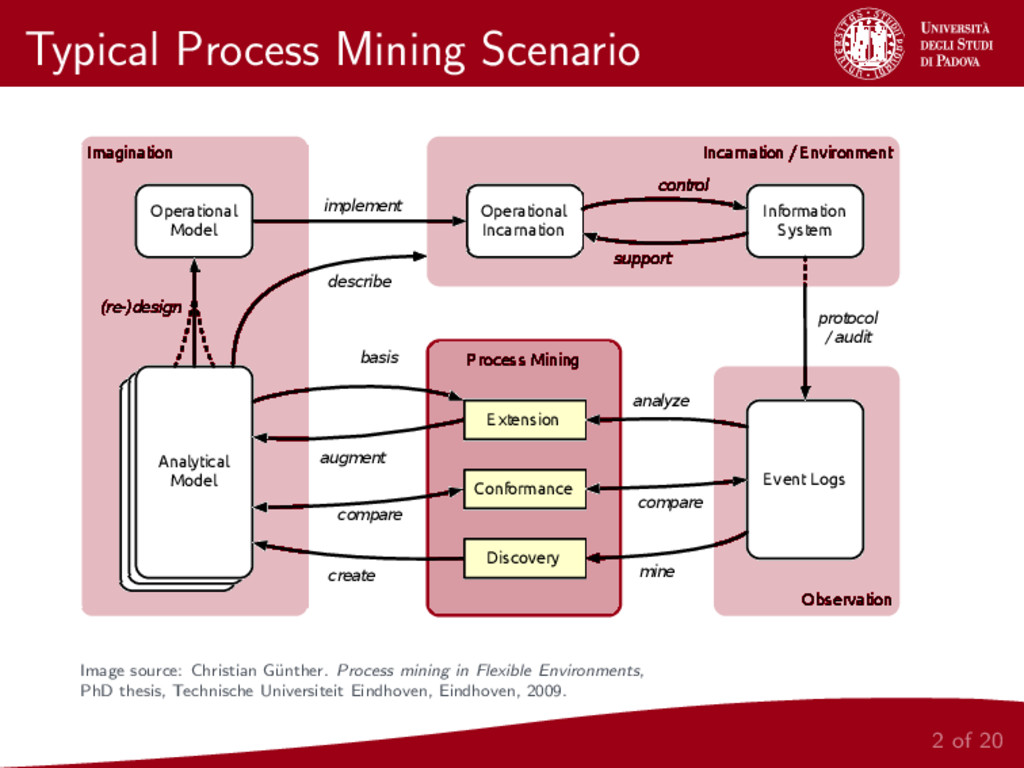
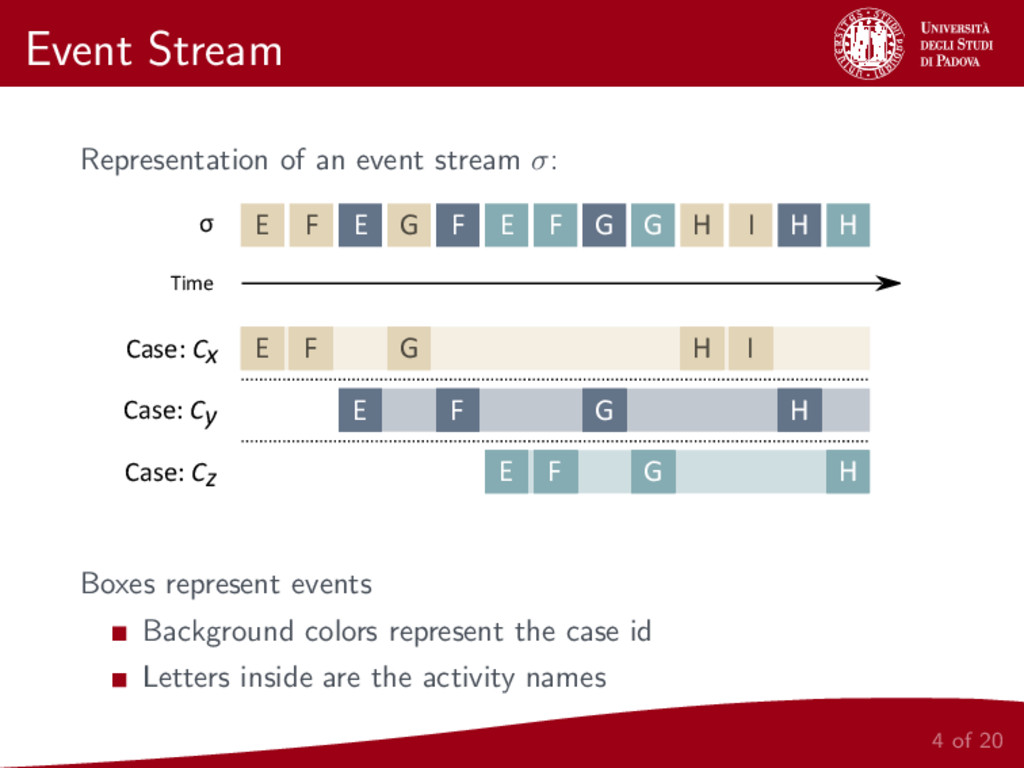
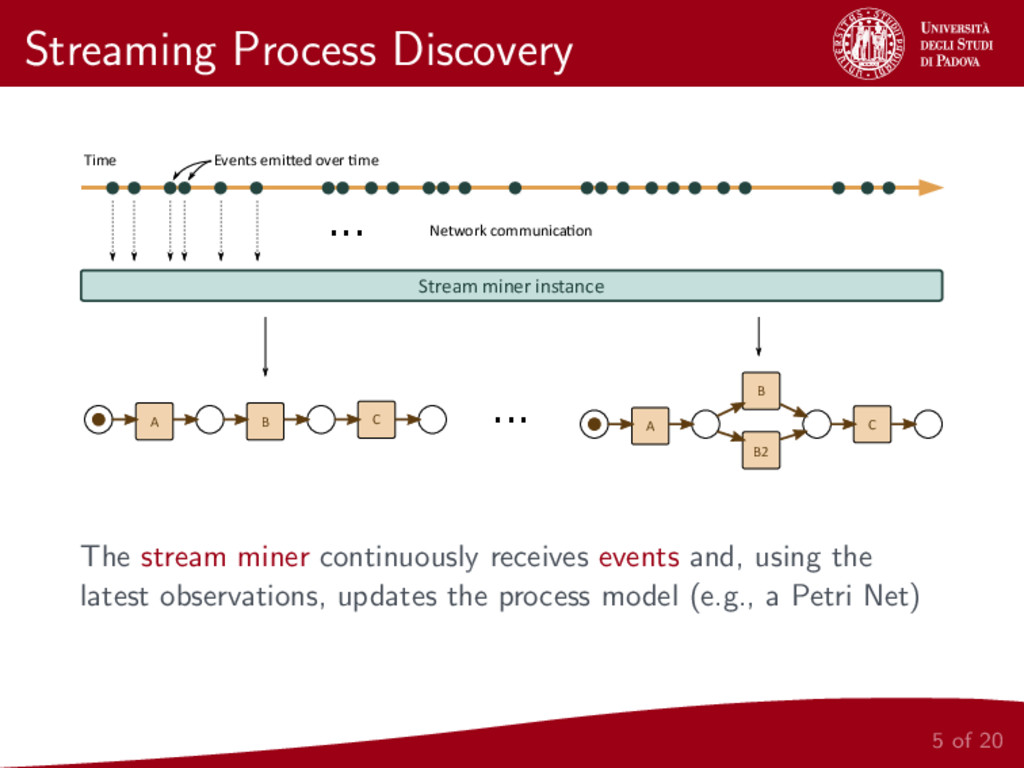
Process Mining represents an important research field that connects Business Process Modeling and Data Mining. One of the most prominent task of Process Mining is the discovery of a control-flow starting from event logs. This paper focuses on the important problem of control-flow discovery starting from a stream of event data. We propose to adapt Heuristics Miner, one of the most effective control-flow discovery algorithms, to the treatment of streams of event data.
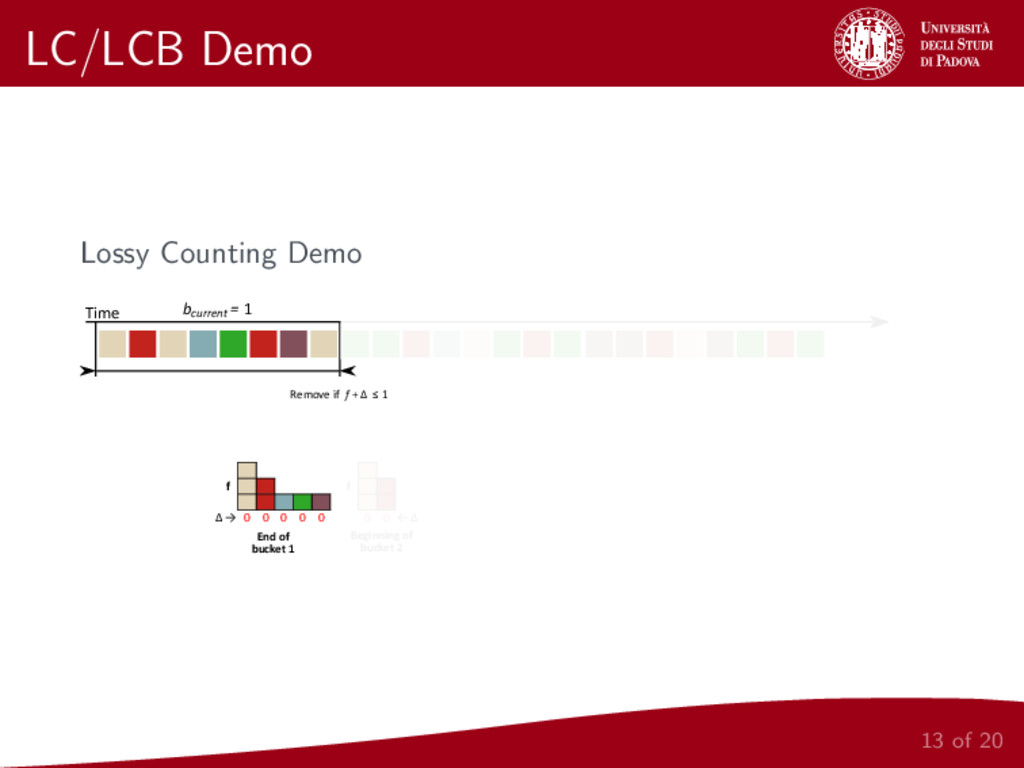
Two adaptations, based on Lossy Counting and Lossy Counting with Budget, as well as a sliding window based version of Heuristics Miner, are proposed and experimentally compared against both artificial and real streams. Experimental results show the effectiveness of control-flow discovery algorithms for streams on artificial and real datasets.
More info: http://andrea.burattin.net/publications/2014-cec
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
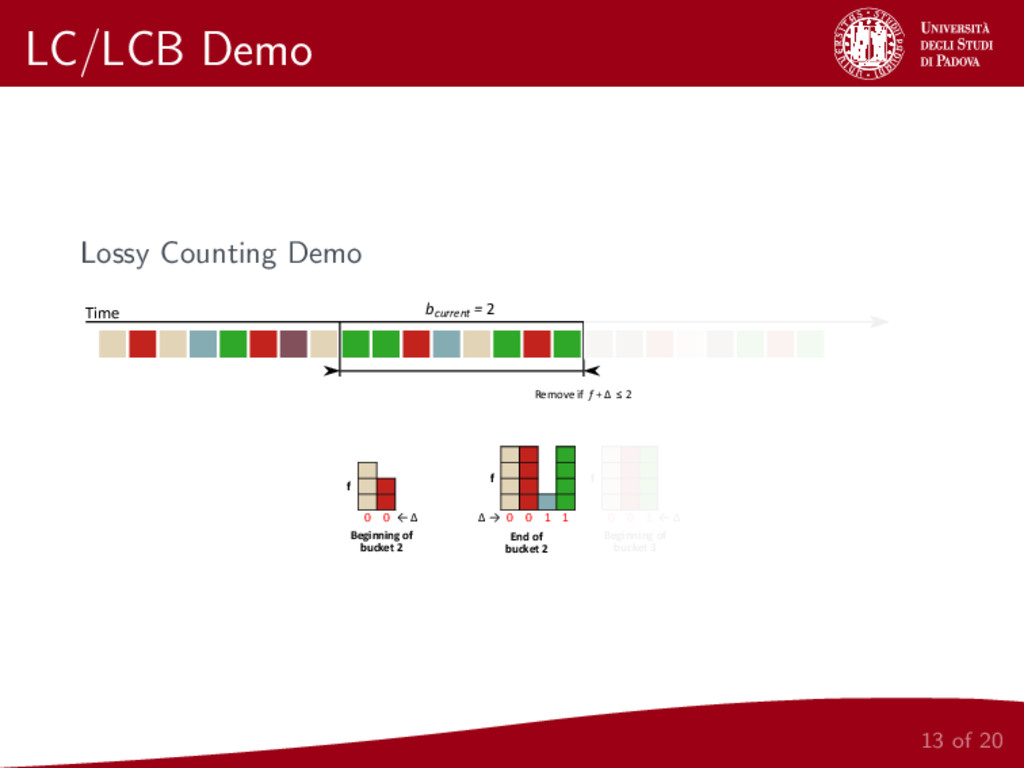{kind=link}
{kind=link}
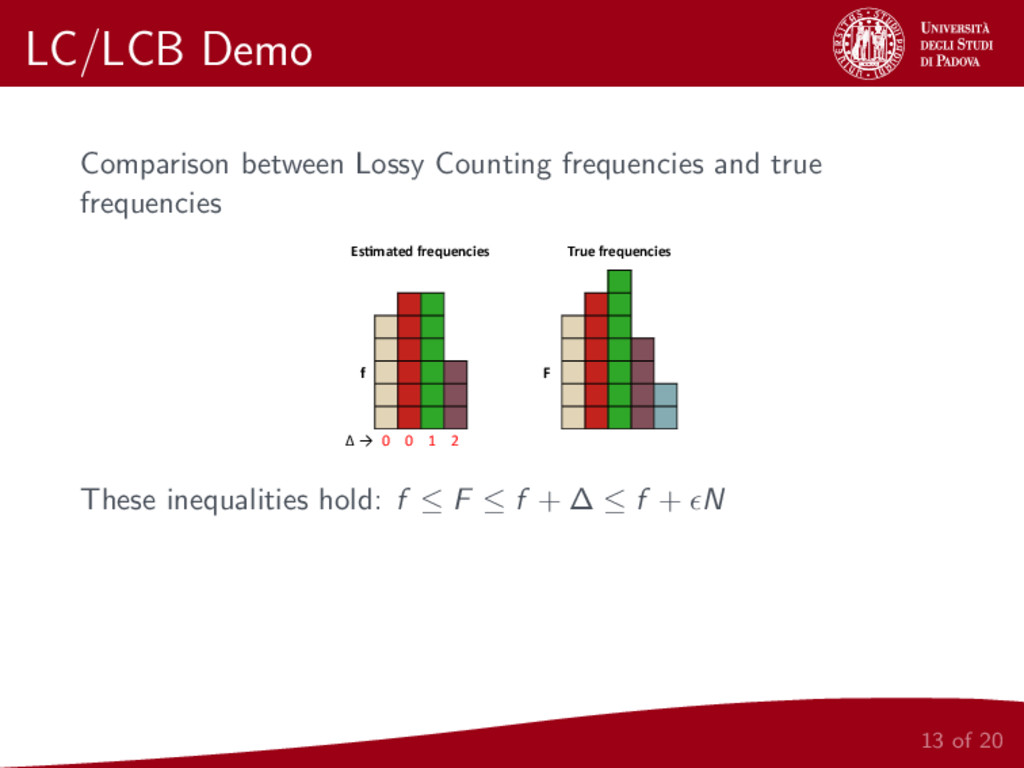{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
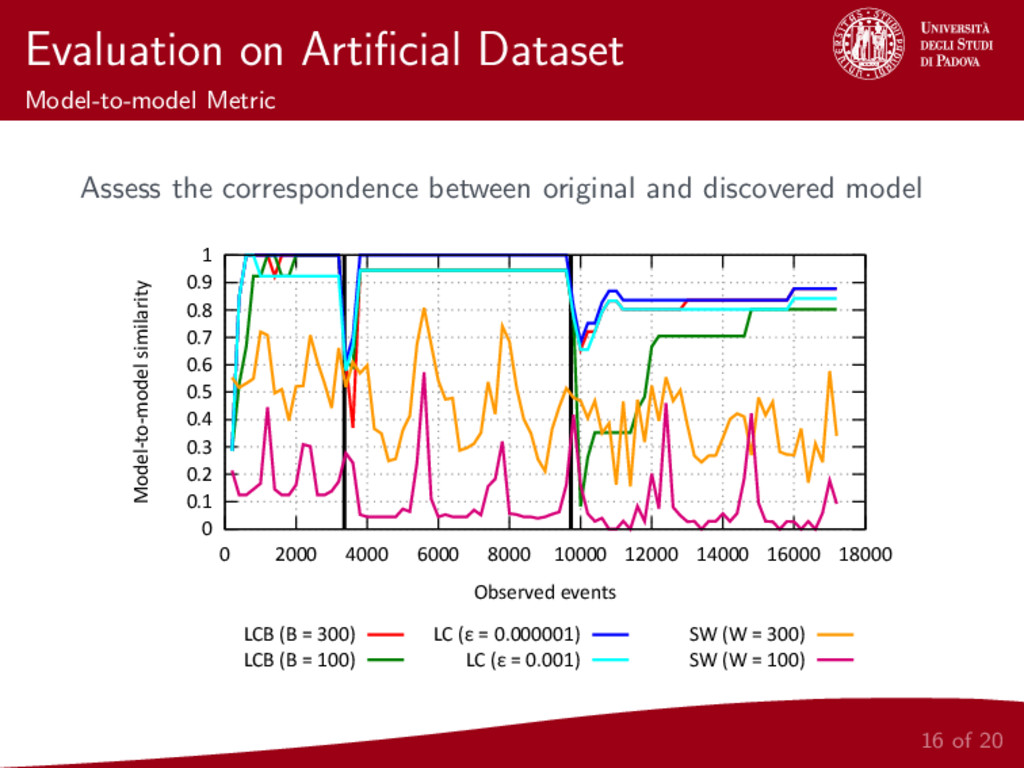{kind=link}
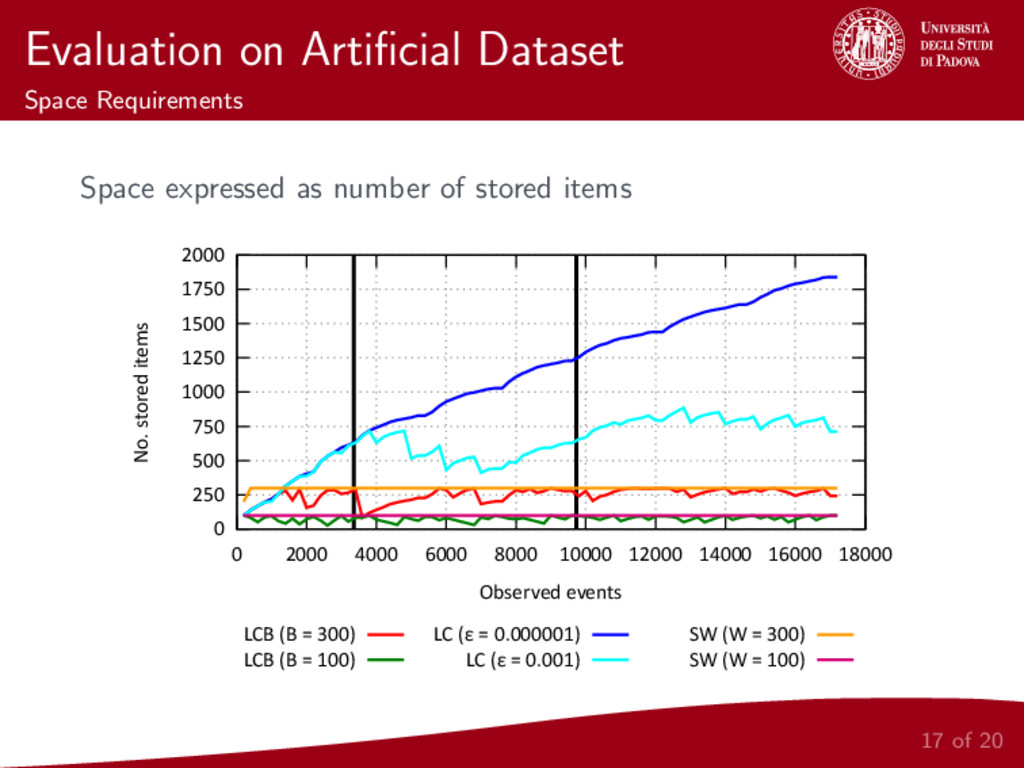{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}