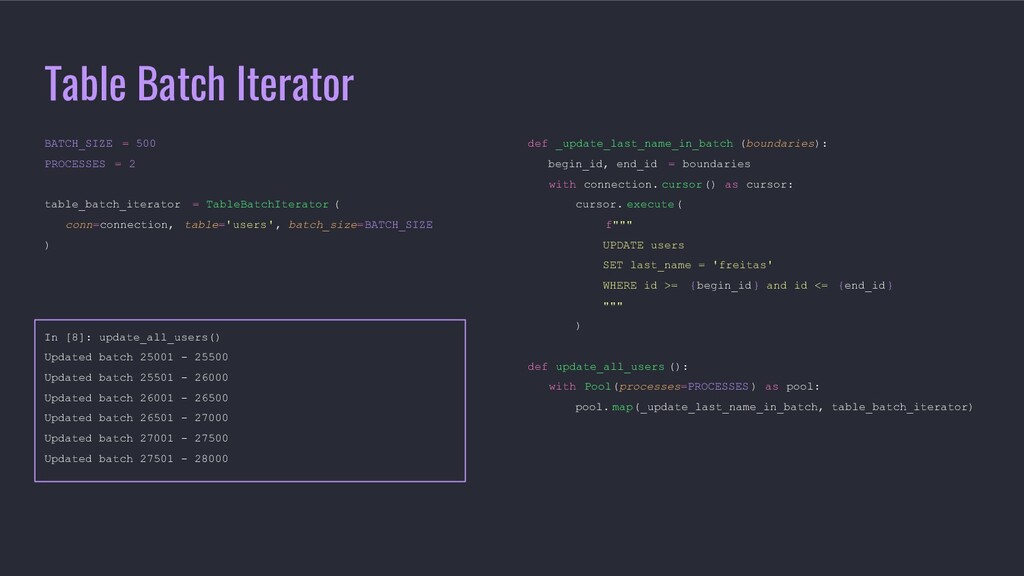
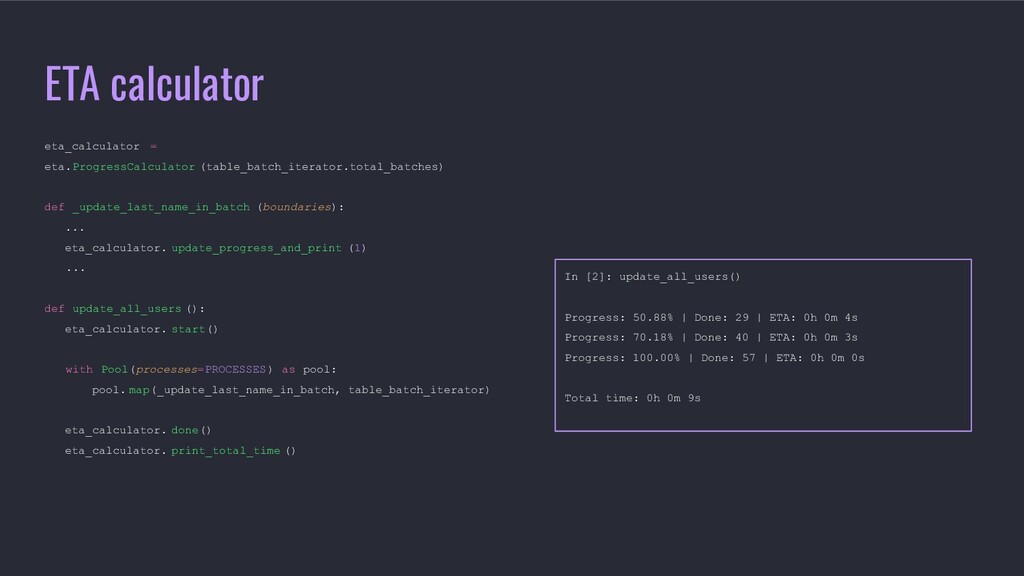
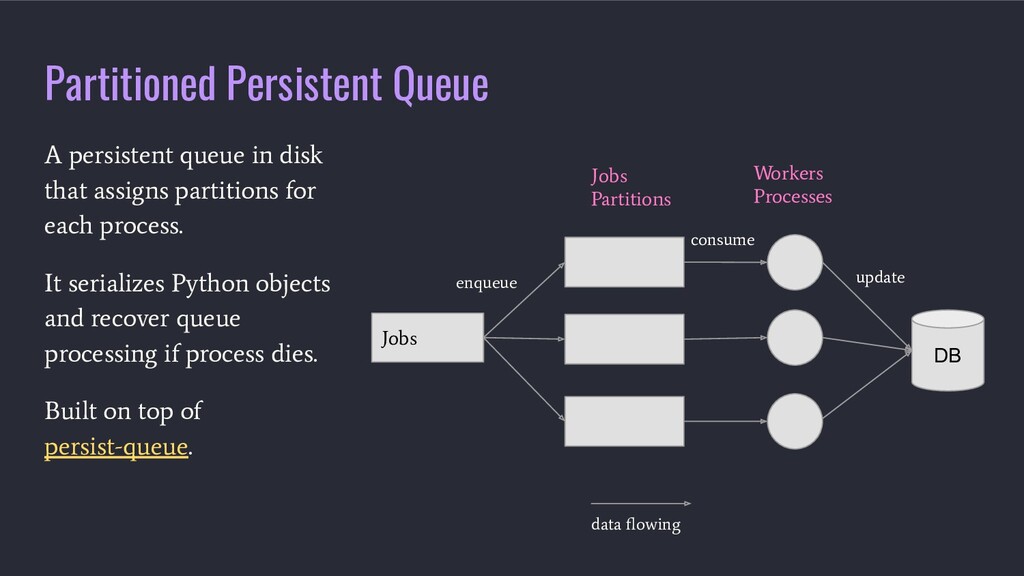
In this talk André will present tooling that will help you update large tables in Postgres with observability on the progress, pause/resume work, optimization of databases updates throughput and having atomic operations while not locking all the table but just the rows you want to update.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}