open-data research infrastructure funded by the world’s governments and aimed at providing anyone, anywhere access to data about all types of life on Earth. • 875 millions occurrences records from 1,124 Institutions • 60 billions records downloaded and 125,000 users sessions per month • 5,286 peer reviewed articles using GBIF mediated data Source: GBIF.org on 7 November 2017
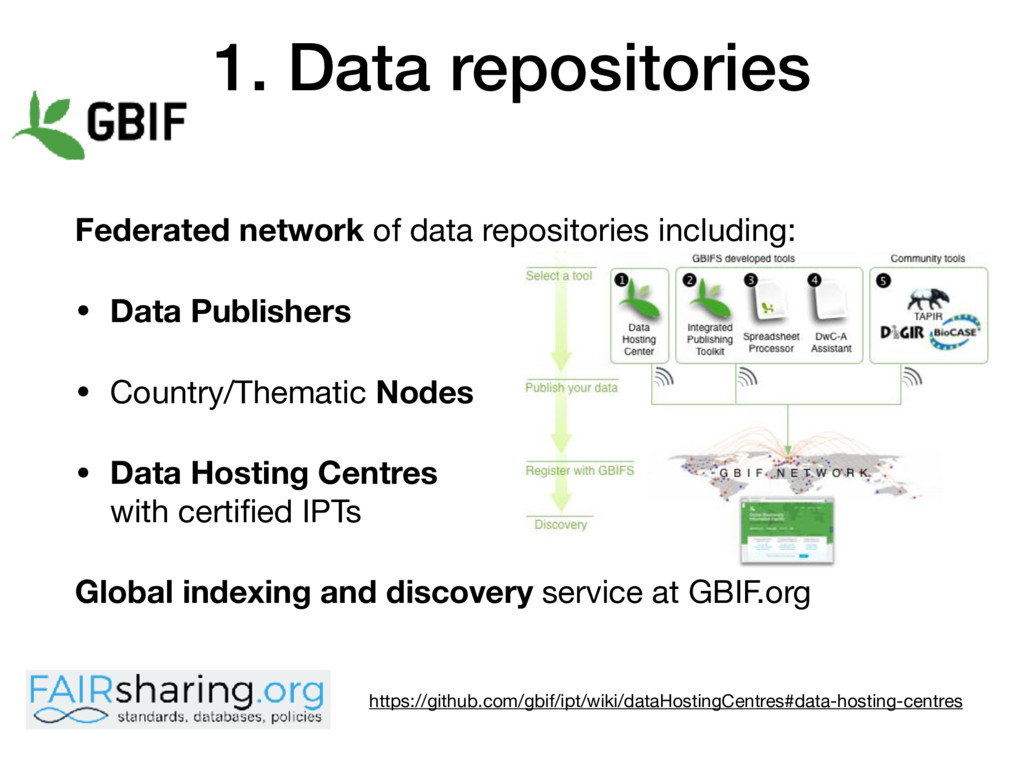
Data Publishers • Country/Thematic Nodes • Data Hosting Centres with certified IPTs Global indexing and discovery service at GBIF.org https://github.com/gbif/ipt/wiki/dataHostingCentres#data-hosting-centres
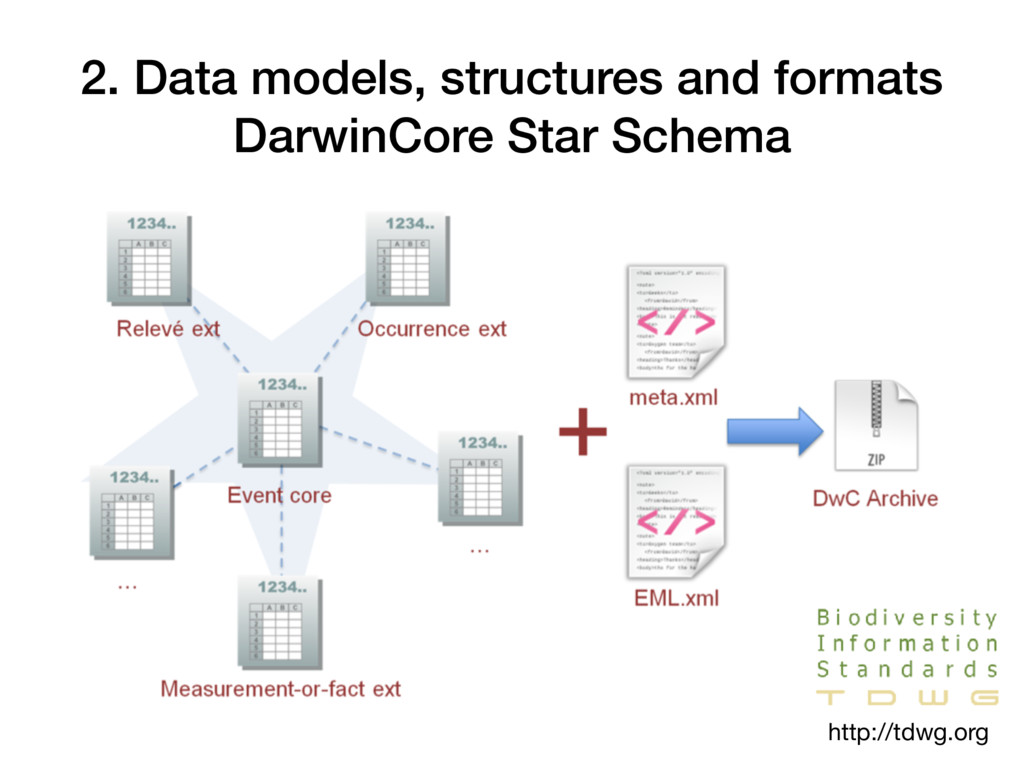
A DublinCore extension for biodiversity information • BioCASe/ABCD: Access to Biological Collections Data Standard • Legacy protocols/standards: Digir and Tapir Metadata • EML (Ecological Metadata Language) • Supporting three core data types: Occurrence, Checklist and Sampling-event • Community driven extensions to DarwinCore • Format: DwC Archive, XLS templates and CSV http://tdwg.org
Term Status occurrenceID Required basisOfRecord Required scientificName Required eventDate Required countryCode Required taxonRank Strongly recommended kingdom Strongly recommended decimalLatitude & decimalLongitude Strongly recommended geodeticDatum Strongly recommended coordinateUncertaintyInMeters Strongly recommended individualCount, organismQuantity & organismQuantityType Strongly recommended informationWithheld Share if available dataGeneralizations Share if available eventTime Share if available country Share if available
select a Creative Commons Licence for each dataset • CC0, under which data are made available for any use without restriction or particular requirements on the part of users • CC BY, under which data are made available for any use provided that attribution is appropriately given for the sources of data used • CC BY-NC, under which data are made available for any use provided that attribution is appropriately given and provided the use is not for commercial purposes
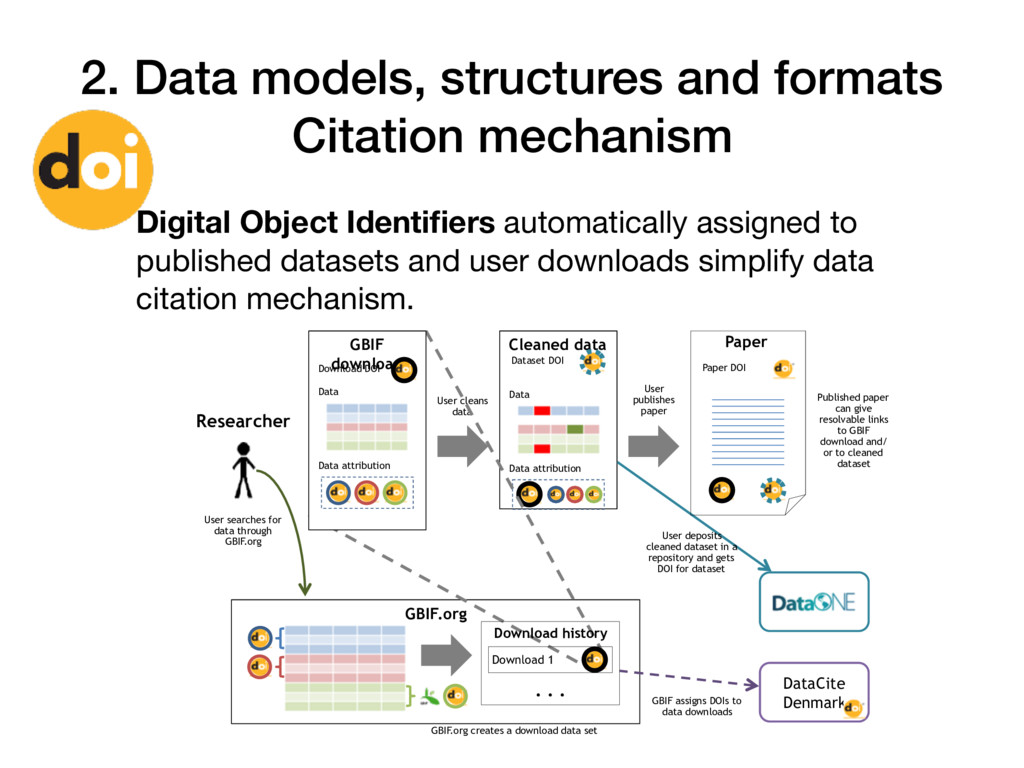
for data through GBIF.org DataCite Denmark GBIF.org GBIF assigns DOIs to data downloads Cleaned data Data Data attribution Dataset DOI Researcher Paper Paper DOI User deposits cleaned dataset in a repository and gets DOI for dataset Published paper can give resolvable links to GBIF download and/ or to cleaned dataset User cleans data User publishes paper GBIF download Data Data attribution Download DOI Download history Download 1 . . . GBIF.org creates a download data set Digital Object Identifiers automatically assigned to published datasets and user downloads simplify data citation mechanism.
• Who is in charge? • How to enforce? • How to maintain? BasisOfRecord # records Observation 30.284.100 Literature 494.857 Preserved Specimen 128.332.911 Fossil Specimen 7.999.142 Human Observation 664.275.917 Machine Observation 9.844.670 Material Sample 508.439 Unknown 31.281.857 Source: GBIF.org on 7 November 2017
Scoping Document. 2. Development of a common repository for TDWG vocabularies-of-values. 3. Development of a standard format for the building of TDWG vocabularies. 4. Building of at least one exemplary vocabulary. 5. Collection and assessment of already existing vocabularies across the community. 6. Identification of domain-specific groups that may be involved in the preparation of vocabularies. 7. In-depth evaluation of the current state of data shared through aggregators in relation to the use of controlled values. 8. Preparation of a list of vocabularies needed for terms of the Darwin Core standard. https://github.com/tdwg/bdq/tree/master/Vocabularies
• OccurrenceID A unique identifier for the occurrence, allowing the same occurrence to be recognized across dataset versions as well as through data downloads and use (see Darwin Core Terms: A quick reference guide). Ideally, the occurrenceID is a persistent global unique identifier. As a minimum requirement, it has to be unique within the published dataset. • GUID applicability statement Richards Kevin. 2010. TDWG GUID Applicability Statement, Version 2010-09. Biodiversity Information Standards (TDWG) • LSID applicability statement Pereira Ricardo, Richards Kevin, Hobern Donald, Hyam Roger, Belbin Lee, Blum Stan. 2009. TDWG Life Sciences Identifiers (LSID) Applicability Statement, Version 2009-09. Biodiversity Information Standards (TDWG) https://github.com/tdwg/guid-as
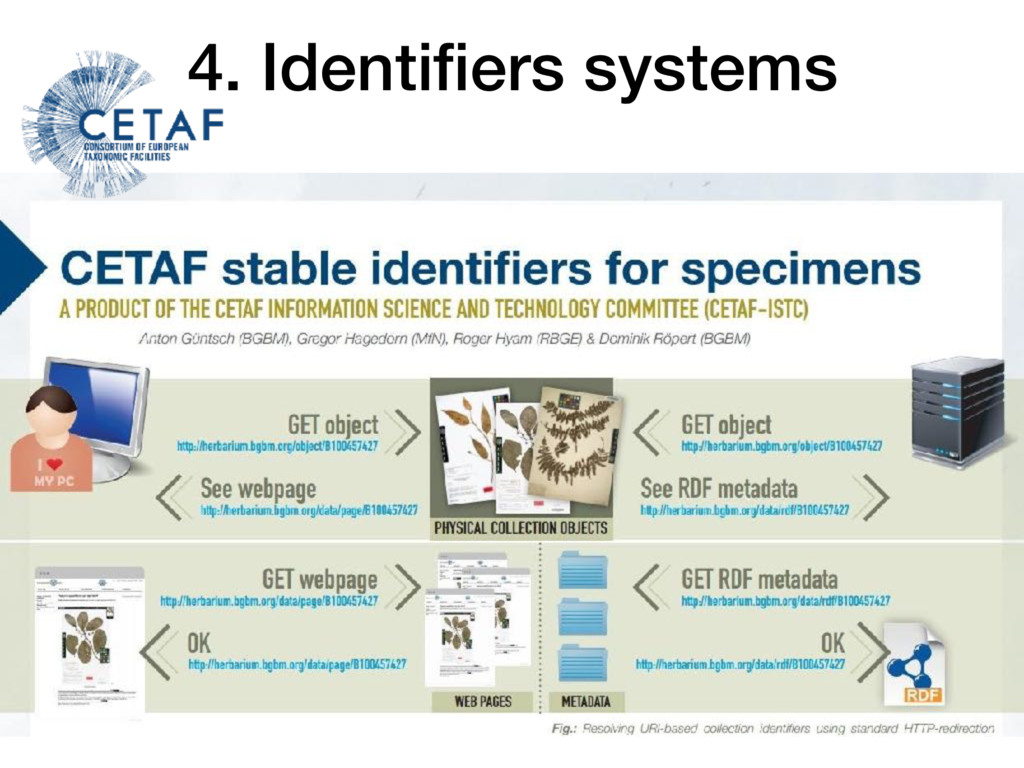
Objects HTTP URI-based specimen identifiers Easy to implement and use No strict syntax Distributed amongst Natural History Institutions Both Human-readable and Machine-readable Compliant with Linked Open Data(LOD) and semantic web Gregor Hagedorn, Terry Catapano, Anton Güntsch, Daniel Mietchen, Dag Endresen, Soraya Sierra, Quentin Groom, Jordan Biserkov, Falko Glöckler & Robert Morris, 2013. Best practices for stable URIs http://wiki.pro-ibiosphere.eu/wiki/Best_practices_for_stable_URIs
can successfully index the file. Each validation report gives: • An overview of any GBIF interpretation issues with the dataset • A detailed rundown of any issues with the metadata, dataset core and extensions • The number of records successfully interpreted • The frequency of terms used in dataset https://www.gbif.org/tools/data-validator/about
(one country one vote) • Executive, Science and Budget Committees • Nodes Committee with Regional sub-committees • Secretariat, including IT team, is located at Copenhagen TDWG is a community with Executive Committee CETAF is a taxonomic research network formed by institutions of reference in Europe Community driven process Relying on people and Open Source Software 6. Governance of technical components https://www.gbif.org/governance
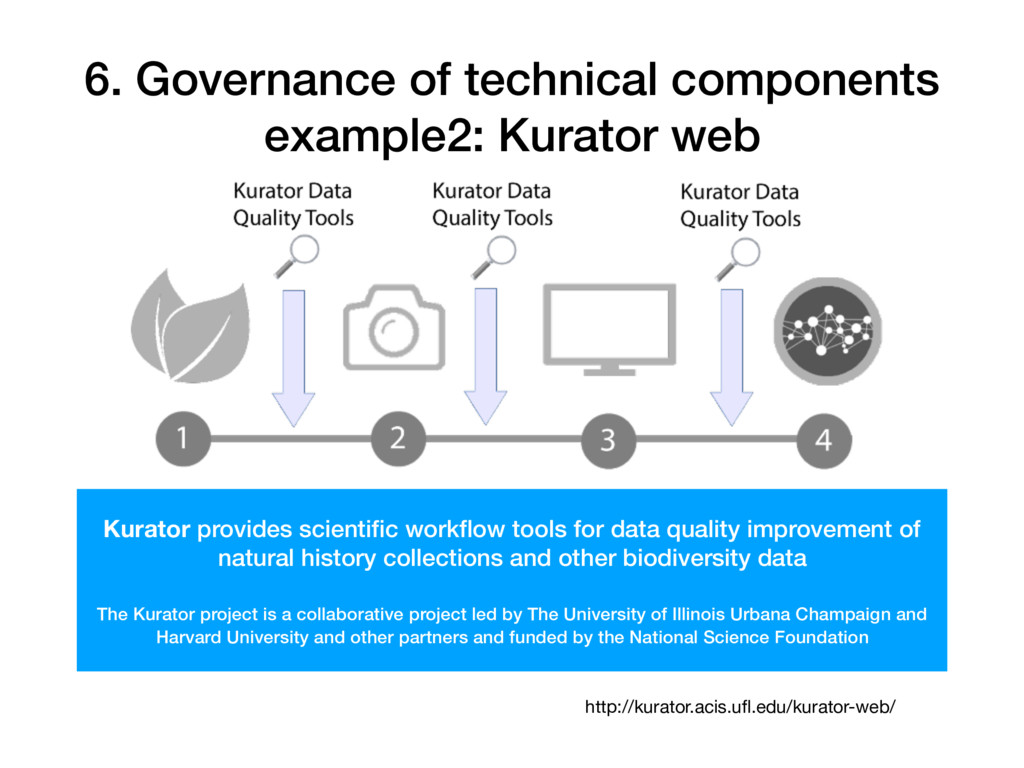
scientific workflow tools for data quality improvement of natural history collections and other biodiversity data The Kurator project is a collaborative project led by The University of Illinois Urbana Champaign and Harvard University and other partners and funded by the National Science Foundation http://kurator.acis.ufl.edu/kurator-web/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you for your attention Any questions? André Heughebaert [email protected]](https://files.speakerdeck.com/presentations/3eb28c3a2abc4bc490ed39468e978dcb/slide_22.jpg){kind=link}