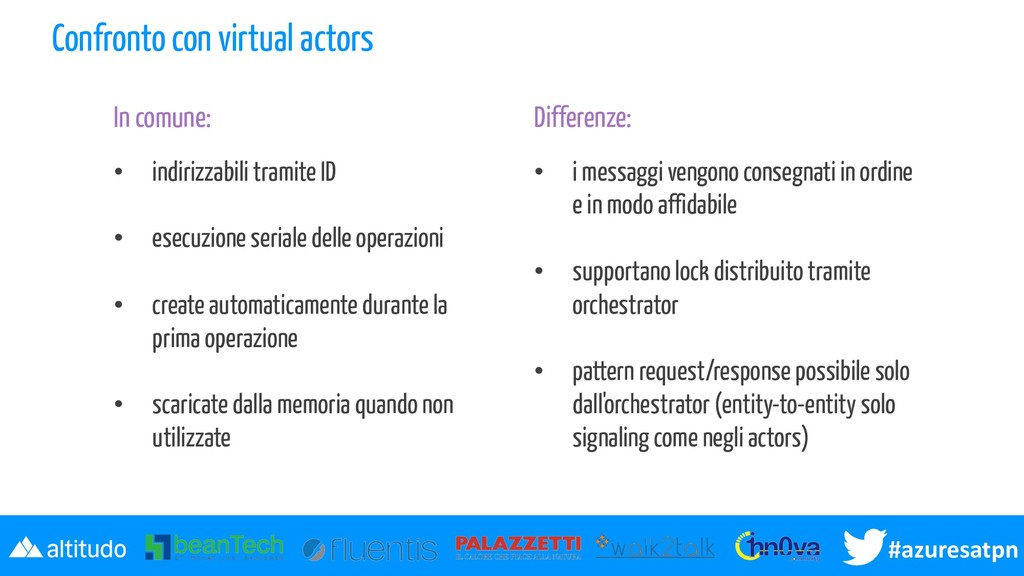
actors (Akka.Net, Orleans) ma con alcune sostanziali differenze Explicit state esprimono lo stato in modo "esplicito" e non sotto forma di workflow come accade con gli orchestrator, ma posso essere utilizzate insieme agli orchestrator Reliability per i messaggi (call - signal) viene garantita la consegna "exactly-once" la comunicazione avviene attraverso code persistenti (Azure Storage Queue) che garantiscono ordinamento e de-duplicazione I messaggi vengono processati uno alla volta
al suo id nella forma @EntityType@EntityKey, ad esempio @Light@Hue1 SingnalEntityAsync vs CallEntitiyAsync "signaling" significa fare l'enqueue di un'operazione (comando asincrono ane-way) "call" è invece utilizzabile solo all'interno di un orchestrator e ritorna direttamente una risposta Proxy definendo un'interfaccia, che l'entity dovrà implementare, possiamo svolgere operazioni sulla entity in modo type-safe evitando le magic string nel codice
ID • esecuzione seriale delle operazioni • create automaticamente durante la prima operazione • scaricate dalla memoria quando non utilizzate • i messaggi vengono consegnati in ordine e in modo affidabile • supportano lock distribuito tramite orchestrator • pattern request/response possibile solo dall'orchestrator (entity-to-entity solo signaling come negli actors) Differenze:
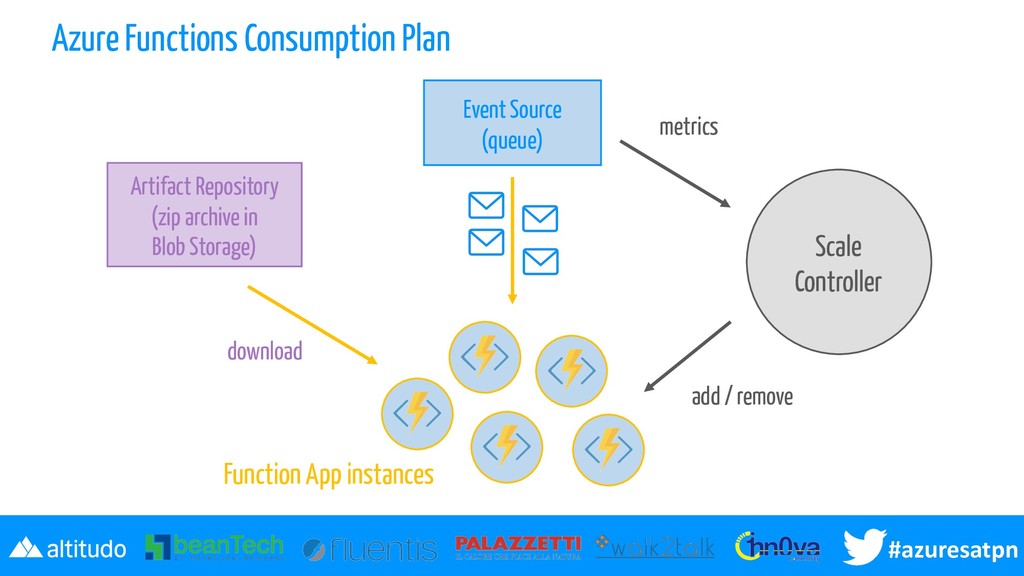
è un processo host che sa come "pullare" eventi da una fonte e passarli alla funzione Event Source è definito tramite il trigger associato alla funzione Horizontal Scaling tipicamente un runtime solo non basta ma non ha nemmeno senso averne uno attivo sempre quando non ci sono eventi
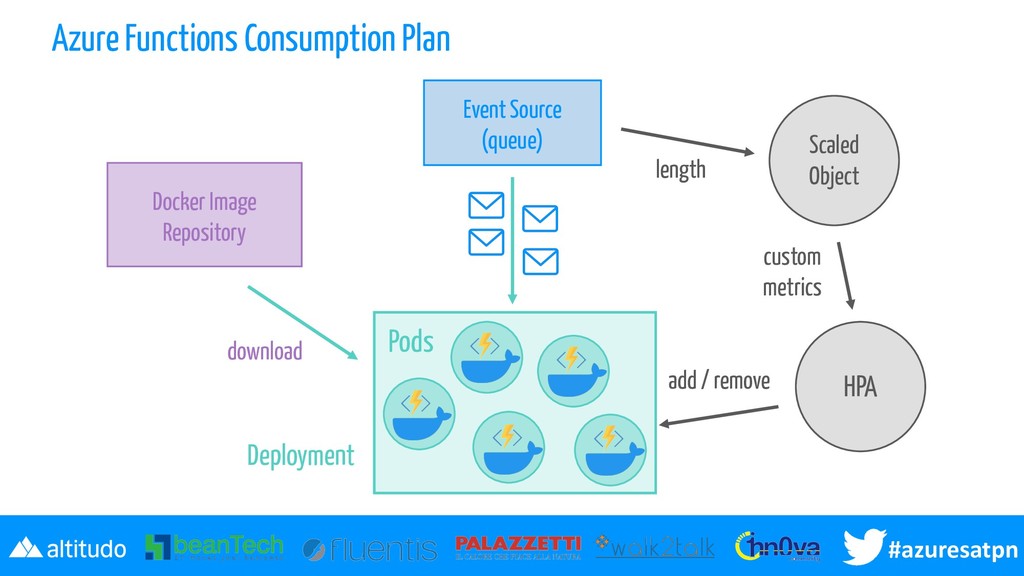
nel "linguaggio di Kubernetes" Docker + KEDA il runtime è fornito in un container docker, KEDA supporta lo scale controller 0...N scaling fornendo metriche custom per Kubernetes Horizontal Pod Autoscaler il numero di pod è zero se non ci sono eventi che triggerano la funzione cresce dinamicamente in base agli eventi per poi tornare di nuovo a zero Si replica il modello serverless event-driven su un cluster K8s
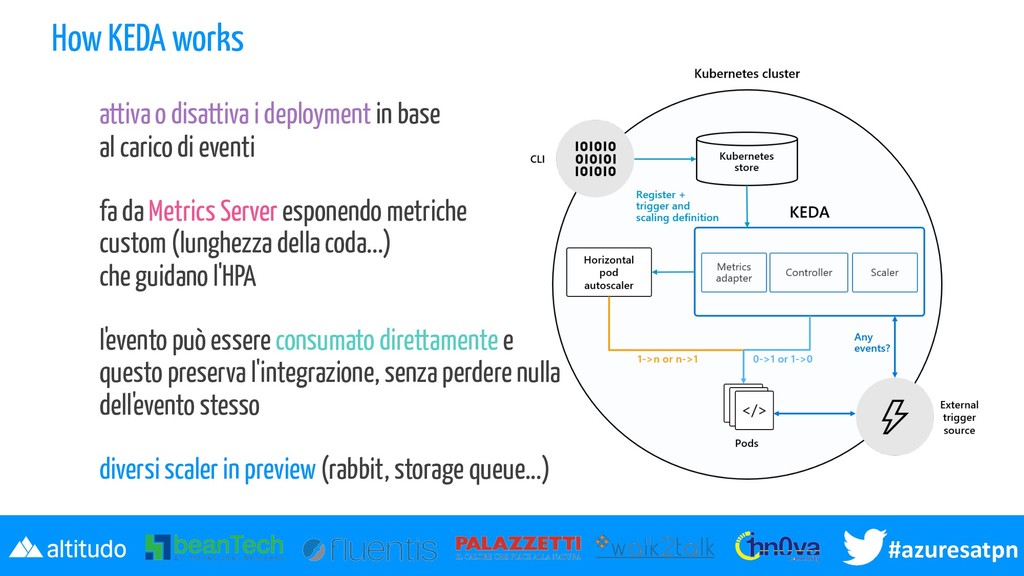
base al carico di eventi fa da Metrics Server esponendo metriche custom (lunghezza della coda...) che guidano l'HPA l'evento può essere consumato direttamente e questo preserva l'integrazione, senza perdere nulla dell'evento stesso diversi scaler in preview (rabbit, storage queue...)
{kind=link}
![#azuresatpn klabcommunity.org elfo.net @andrekiba https://github.com/andrekiba https://www.linkedin.com/in/andreaceroni Andrea Ceroni [email protected]](https://files.speakerdeck.com/presentations/f2451b0233e743b2aeedf6ec99639d63/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![#azuresatpn Durable Functions Actions [DurableClient] IDurableOrchestrationClient Client output Binding •](https://files.speakerdeck.com/presentations/f2451b0233e743b2aeedf6ec99639d63/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#azuresatpn Thanks! [email protected] [email protected] @andrekiba http://github.com/andrekiba http://www.linkedin.com/in/andreaceroni https://creativecommons.org/licenses/by-nc-sa/3.0/](https://files.speakerdeck.com/presentations/f2451b0233e743b2aeedf6ec99639d63/slide_21.jpg){kind=link}