As Java developers, we do a lot of data processing. If you have terabytes pumped through your system daily, maybe you would reach for Spark, Flink or some other “big data” solution. But there are also many everyday tasks that do not warrant the complexity of traditional data pipelines. Some examples are analysis of app logs, cleaning up and persisting Excel files, simple ETL copying tables between different databases, etc. So, how can you use “big data” techniques without big data infrastructure?
This talk focuses on “DataFrame” - an in-memory table-like data structure with operations including column / row filtering and transformations, joins, aggregations, etc. I am using an open source DFLib library (https://dflib.org) and Jupyter notebook to demonstrate how to do data processing in any Java app without much fuss.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
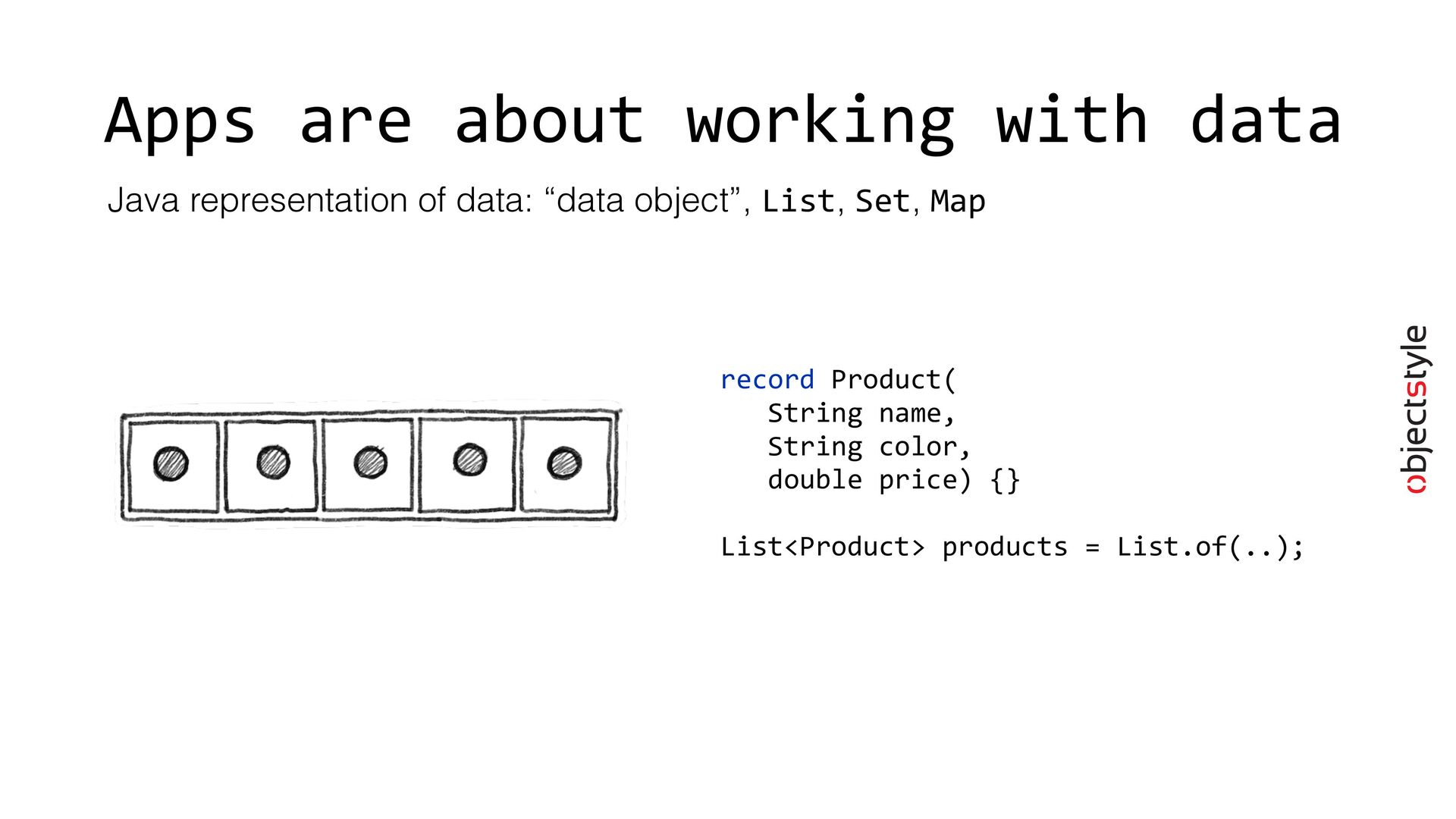{kind=link}
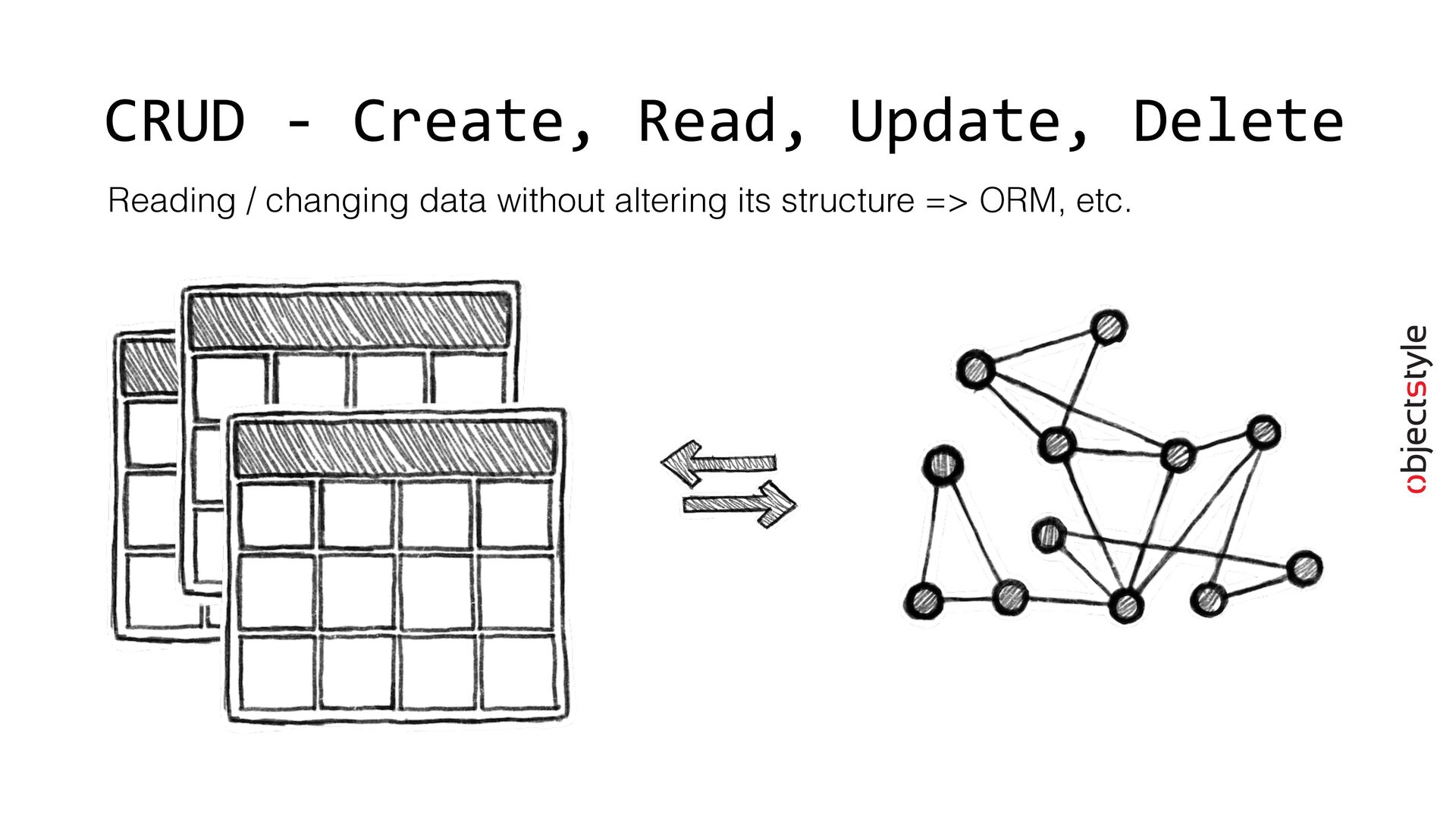{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
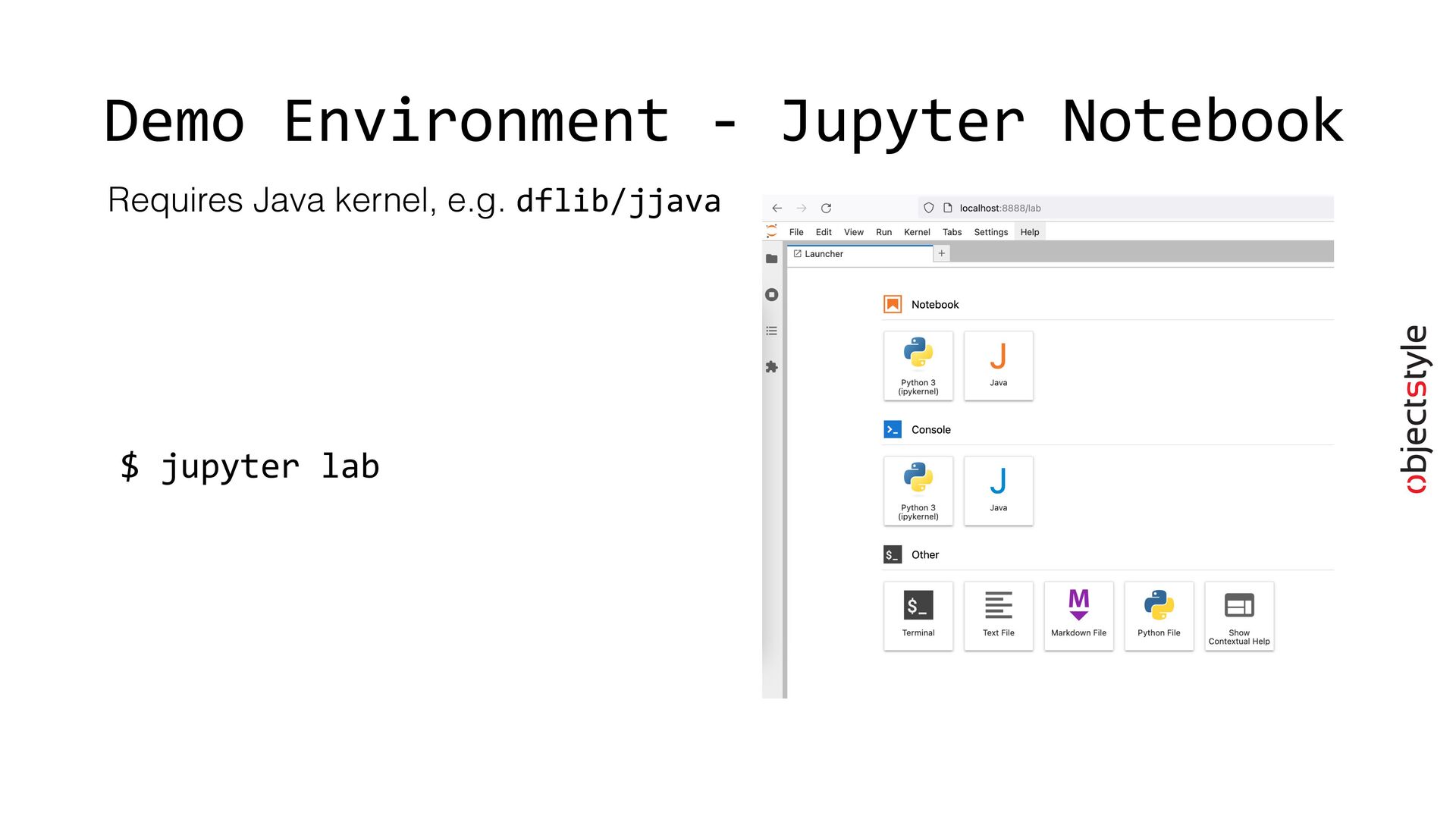{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}