Collective communication is the cornerstone of many distributed machine learning systems. While existing ML systems such as distributed TensorFlow have built-in collective communication infrastructure, these functionalities are often bundled with the framework, invisible to users, and cannot extrapolate to ML programs that are not written following the framework-specific languages.
In this talk, we introduce a set of Ray-native Python-based collective communication primitives for Ray clusters with distributed CPUs or GPUs. They can be used in Ray task or actor code to speed up distributed communications, such as those introduced in distributed ML training.
Built on top of these communication primitives, we bring in a Ray-native distributed ML training library, offering Python-based implementations and interfaces to a variety of data- and model-parallel training strategies, such as parameter server, pipeline parallelism, to enable training various DL or non-DL models, on a Ray cluster.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
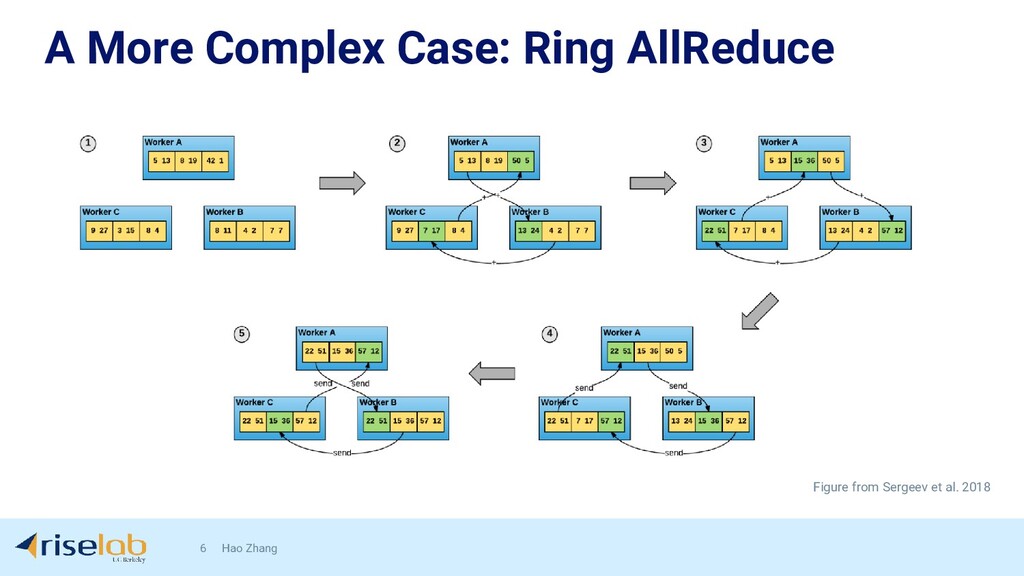{kind=link}
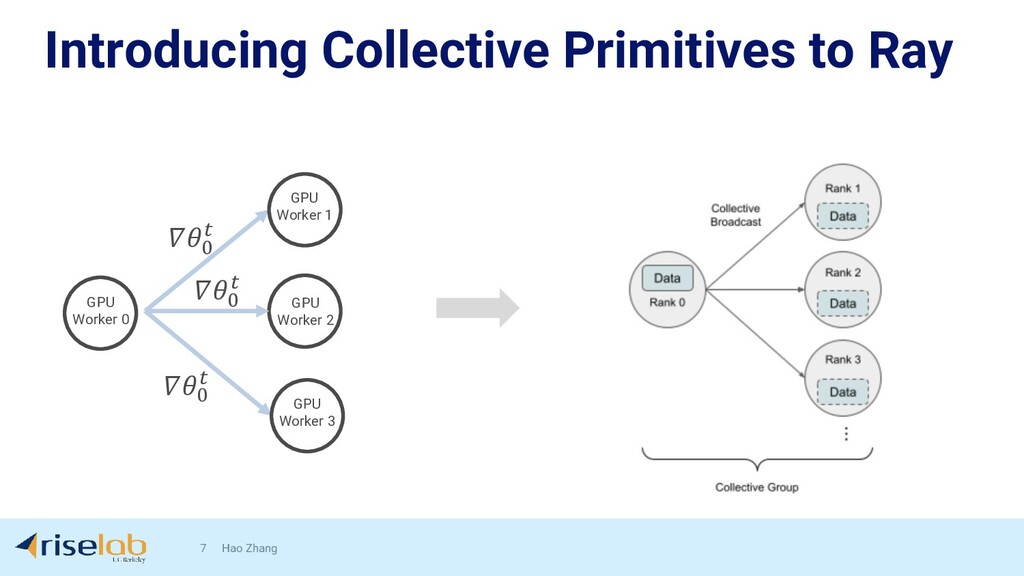{kind=link}
{kind=link}
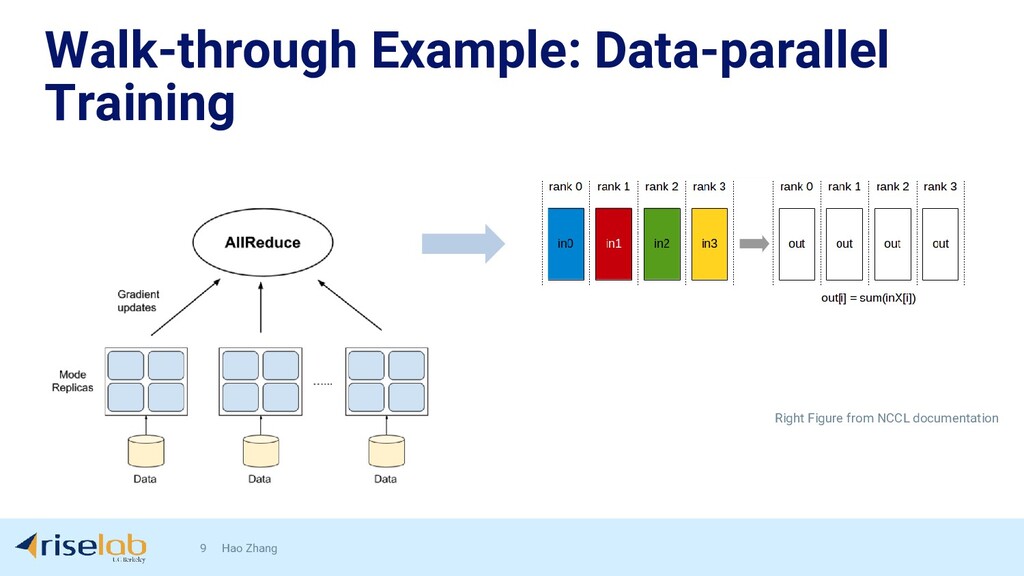{kind=link}
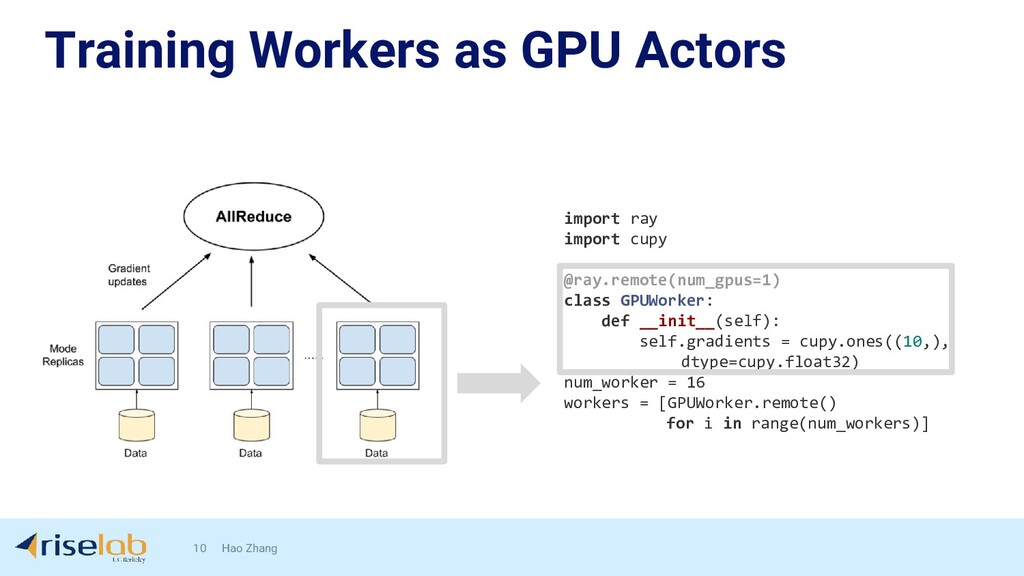{kind=link}
{kind=link}
{kind=link}
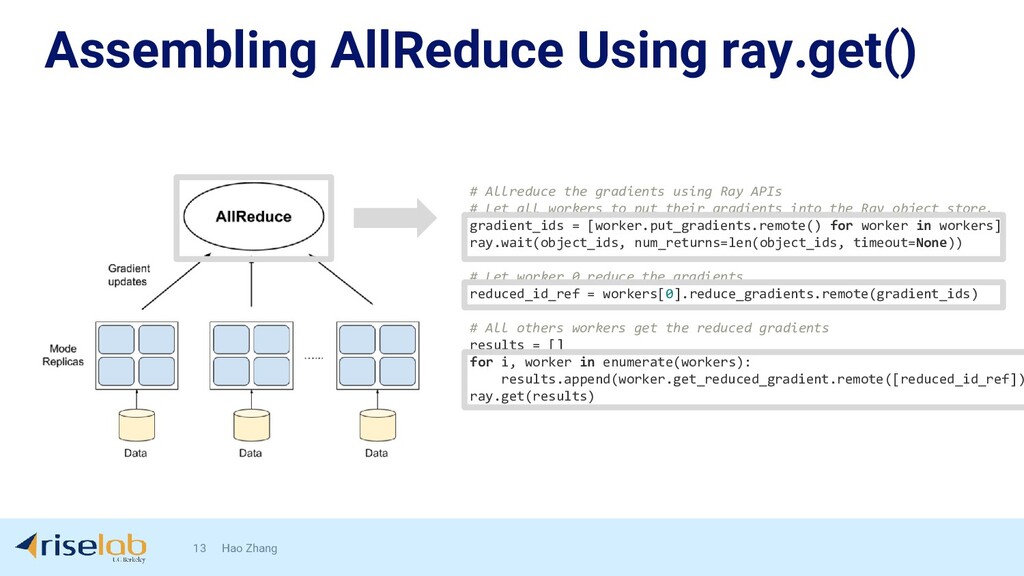{kind=link}
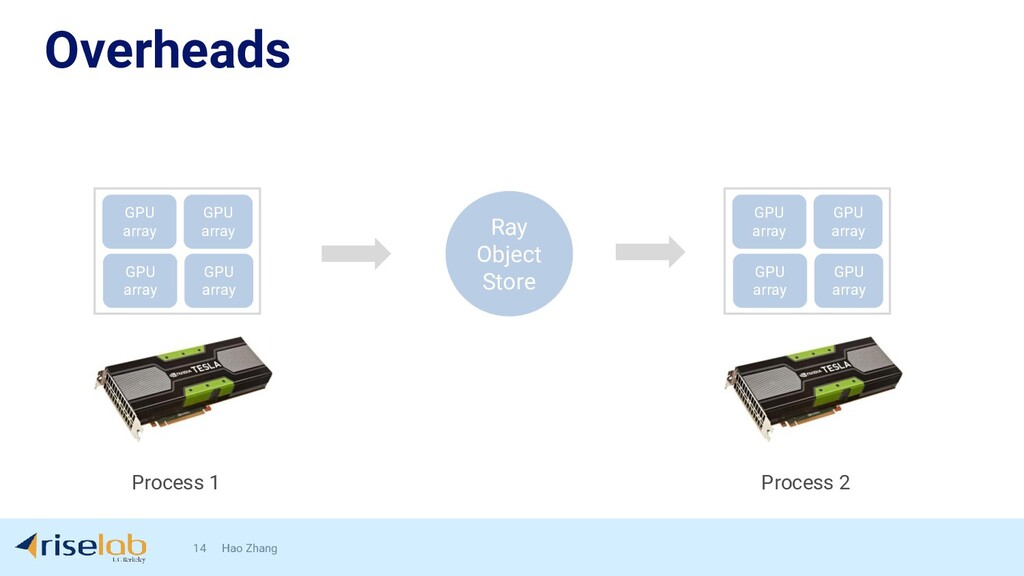{kind=link}
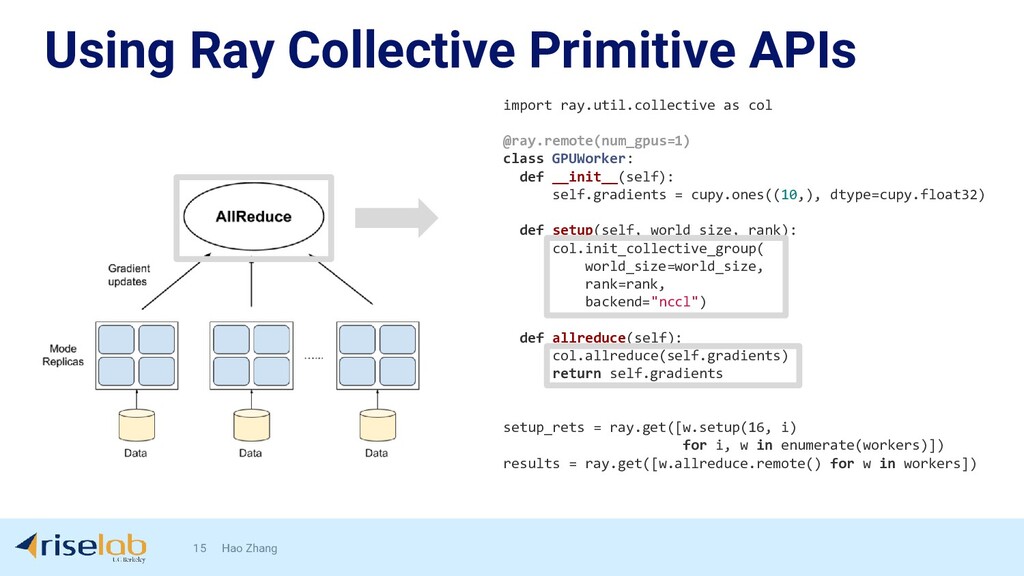{kind=link}
{kind=link}
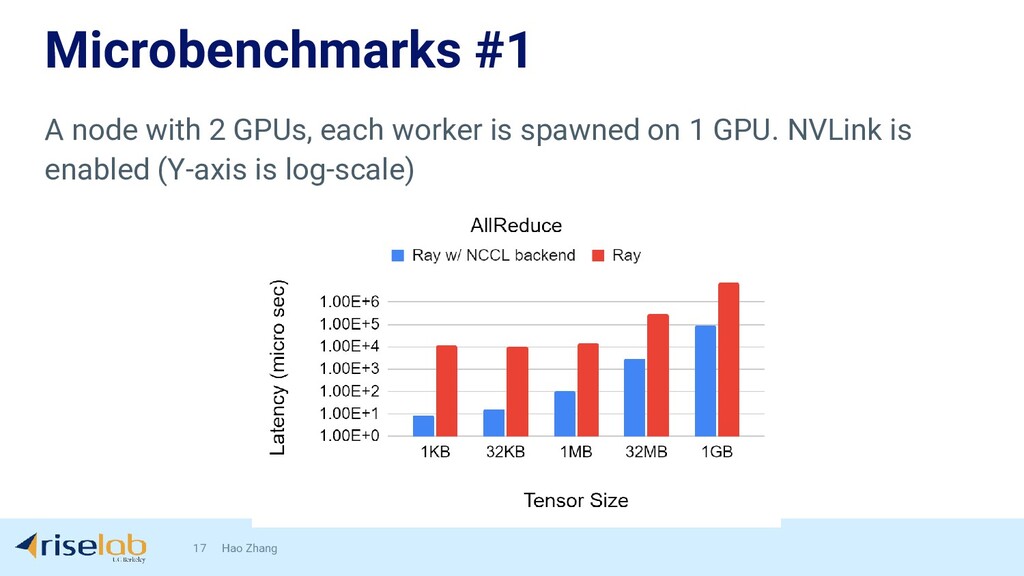{kind=link}
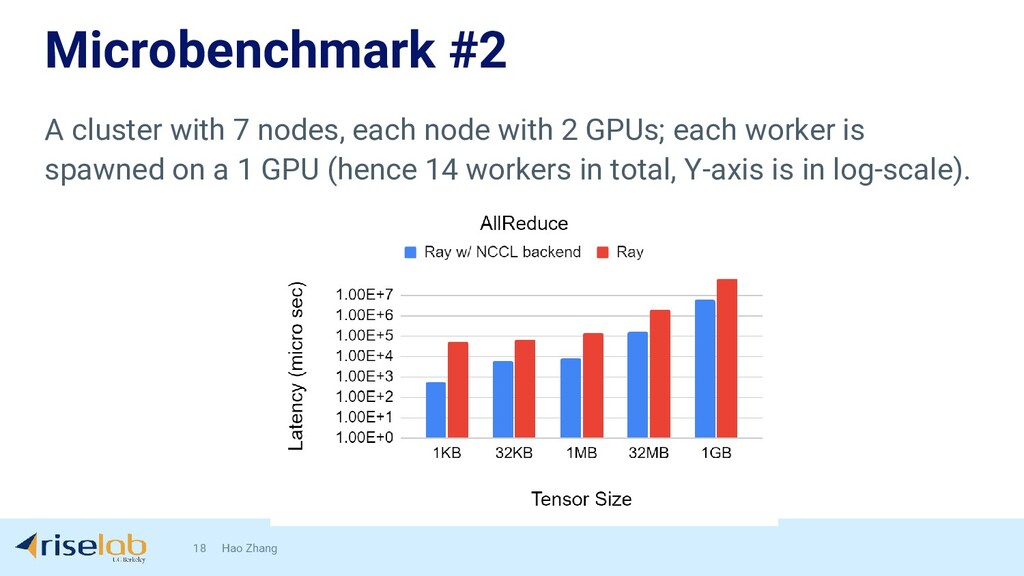{kind=link}
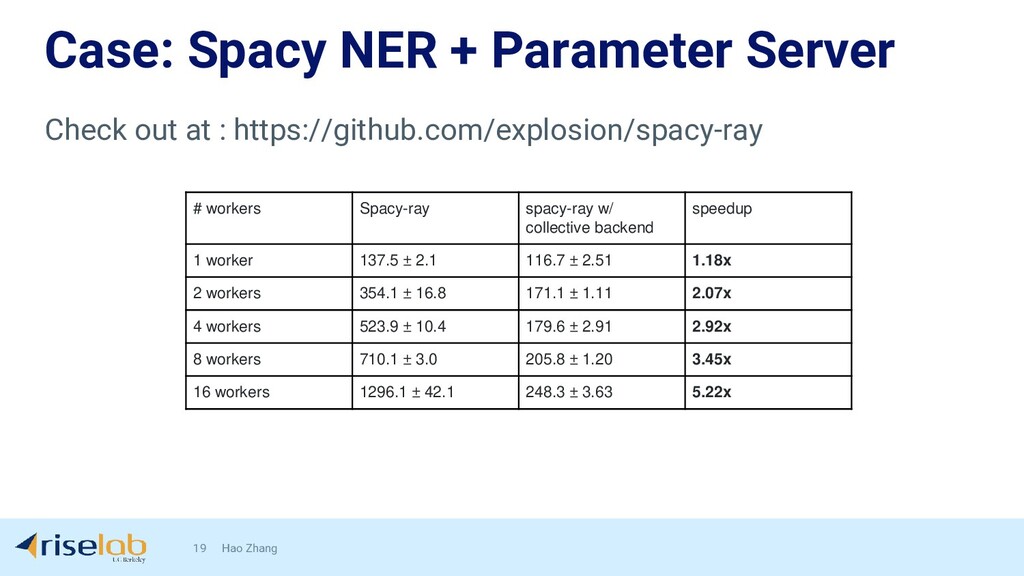{kind=link}
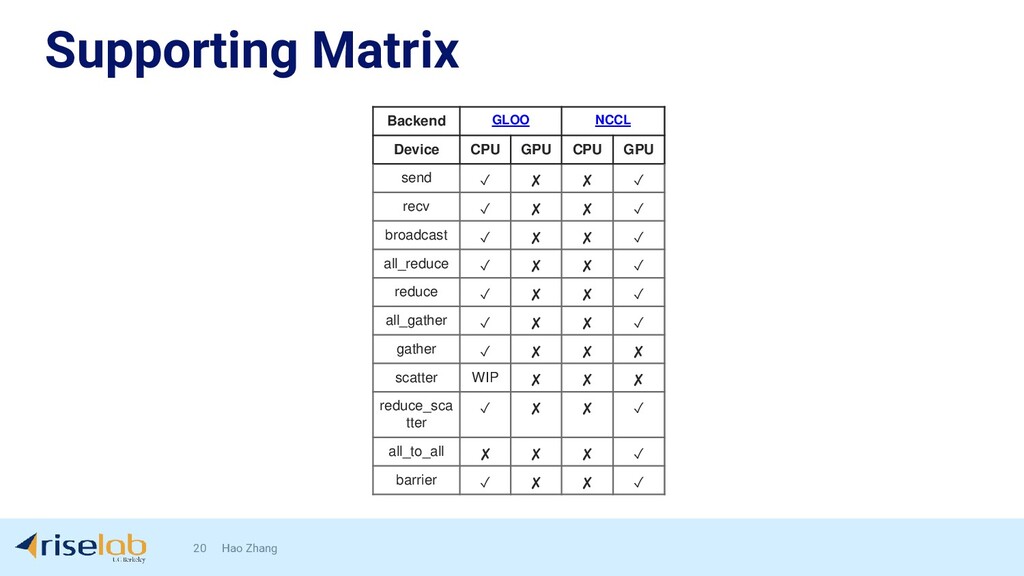{kind=link}
{kind=link}
{kind=link}
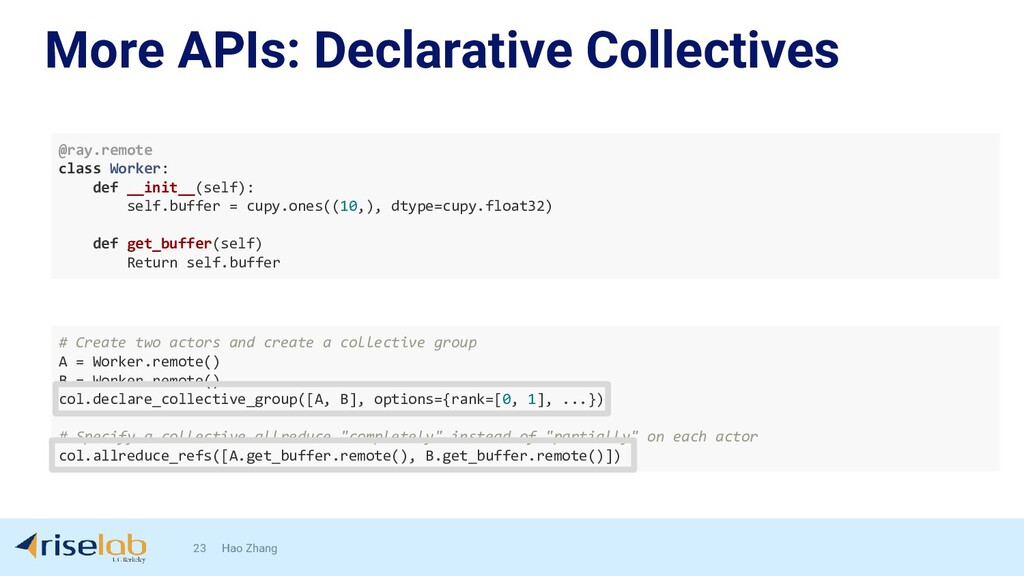{kind=link}
{kind=link}
{kind=link}
{kind=link}