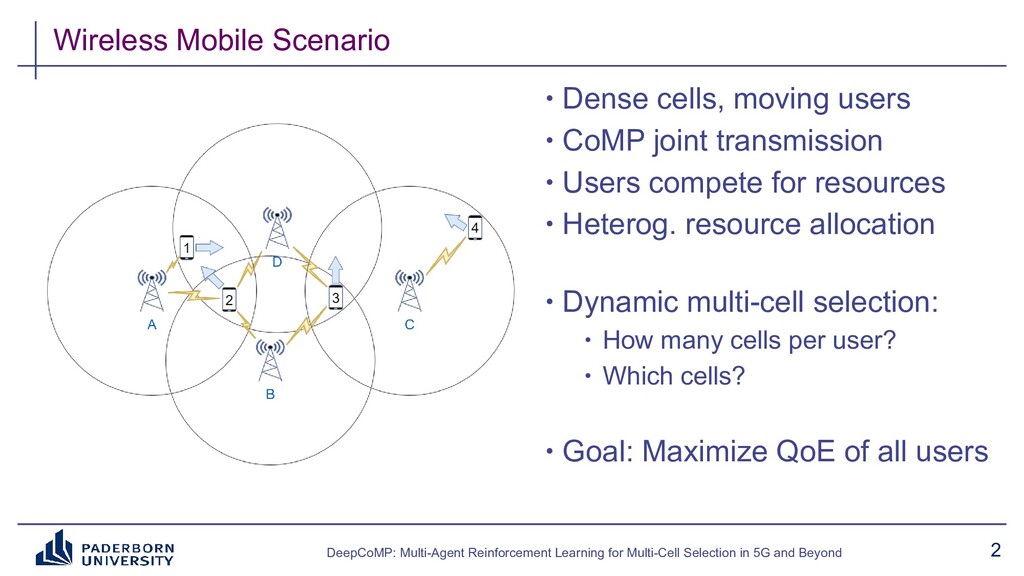
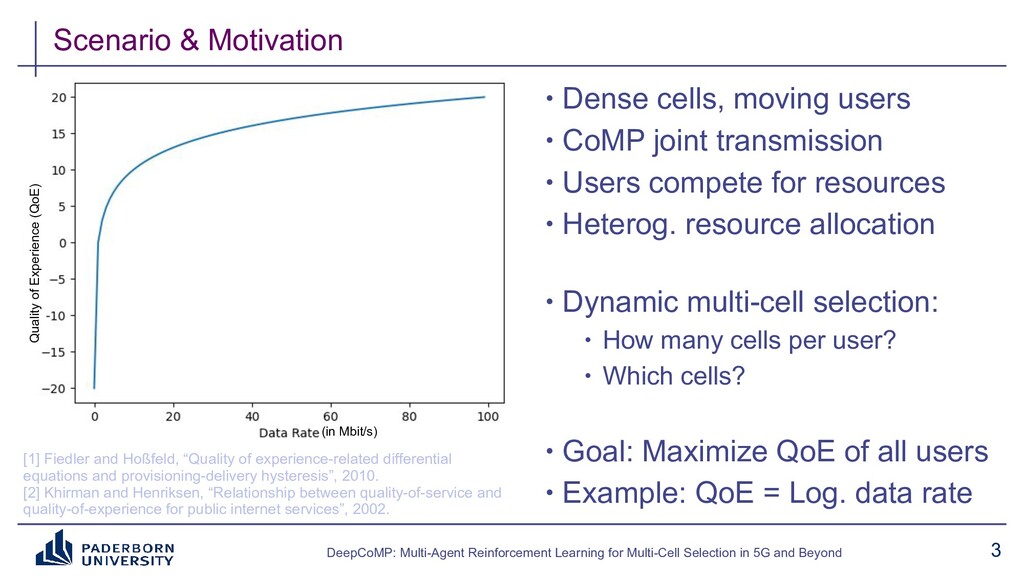
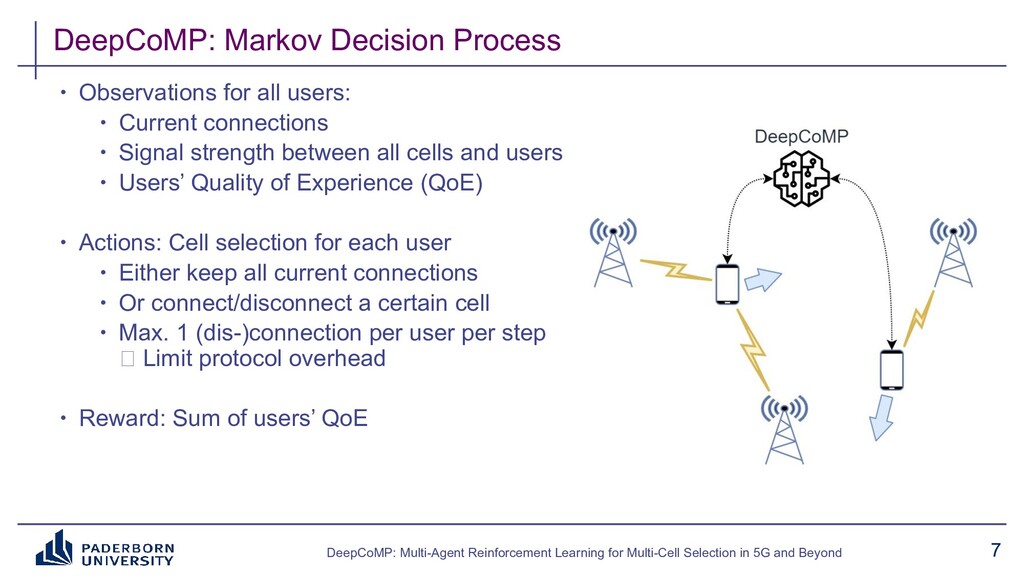
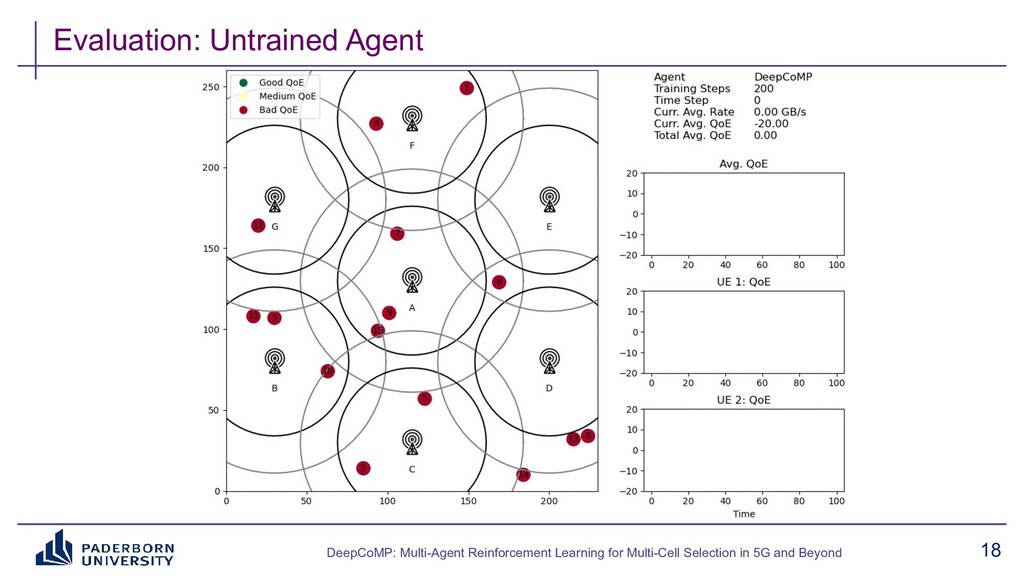
We present DeepCoMP as outcome of a research project on dynamic multi-cell selection in future mobile networks. DeepCoMP is a (multi-agent) deep reinforcement learning approach using Ray RLlib that continuously coordinates user-cell connections in mobile networks. Connecting to and receiving data from multiple cells simultaneously using coordinated multipoint (CoMP) can greatly increase the received data rate and is crucial for AR/VR, smart manufacturing, cloud gaming, and vehicular networking scenarios in 5G and beyond. Selecting how many and which cells to serve which users is challenging as users compete for limited radio resources and channel state continuously changes with users moving around.
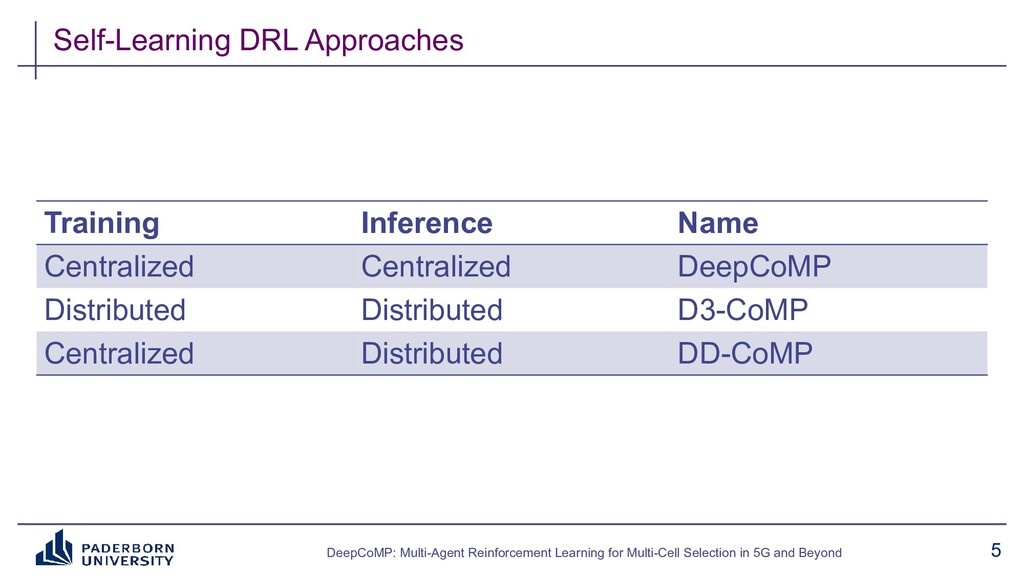
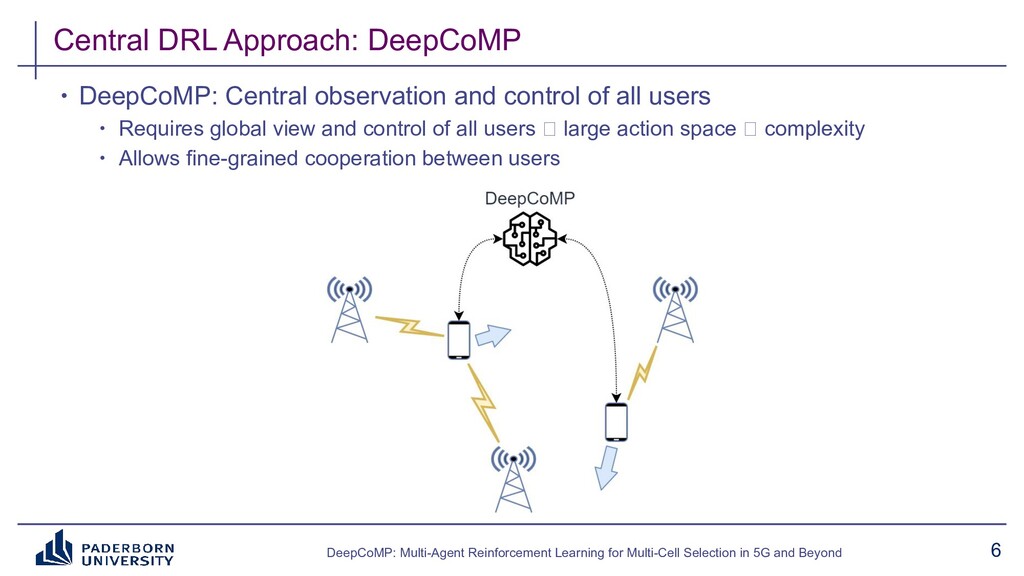
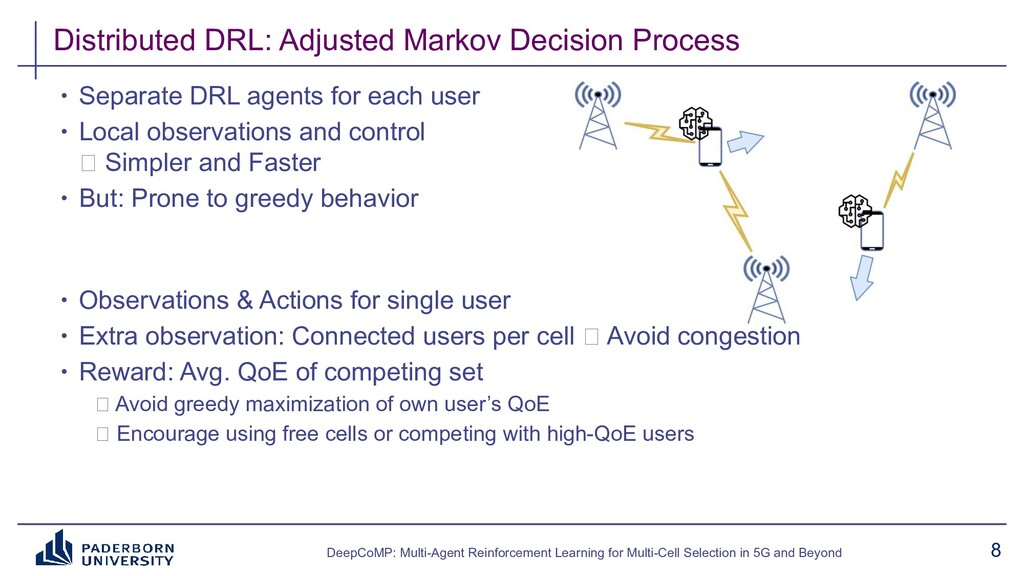
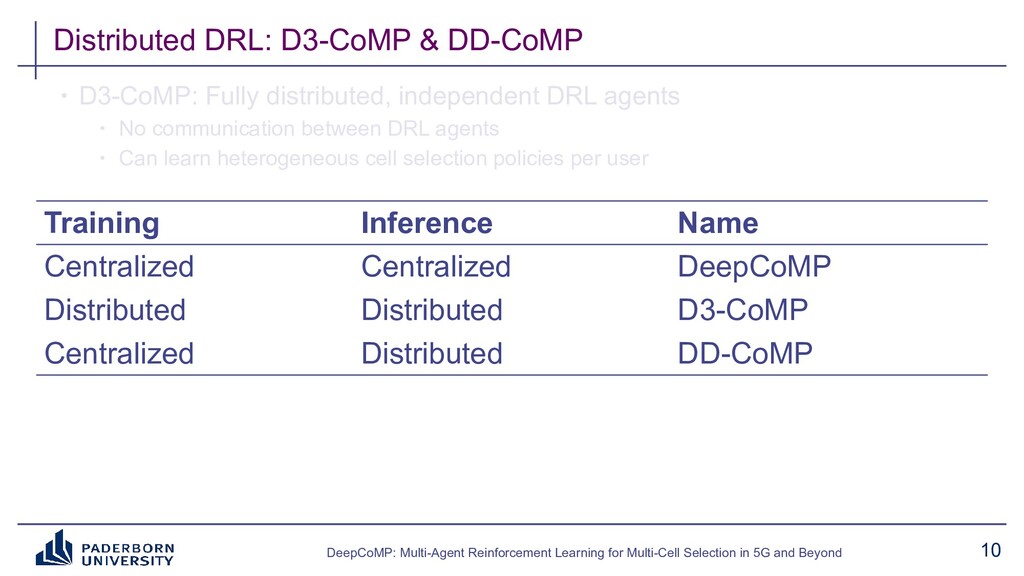
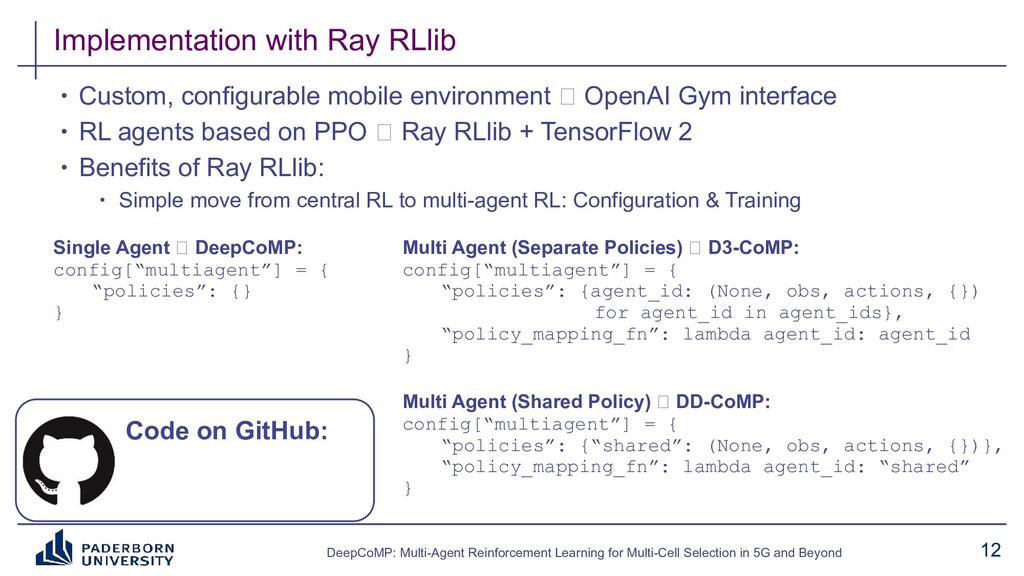
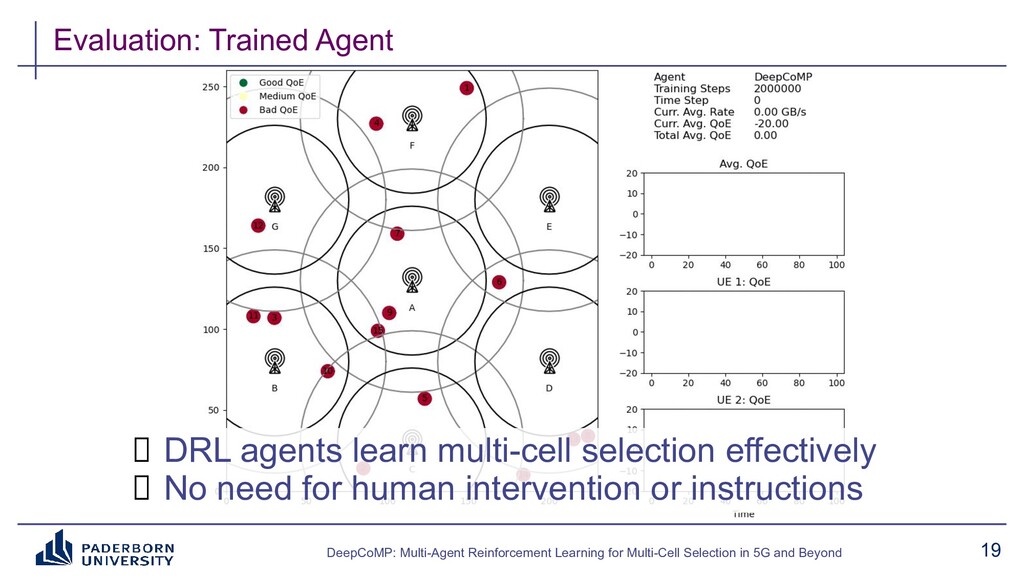
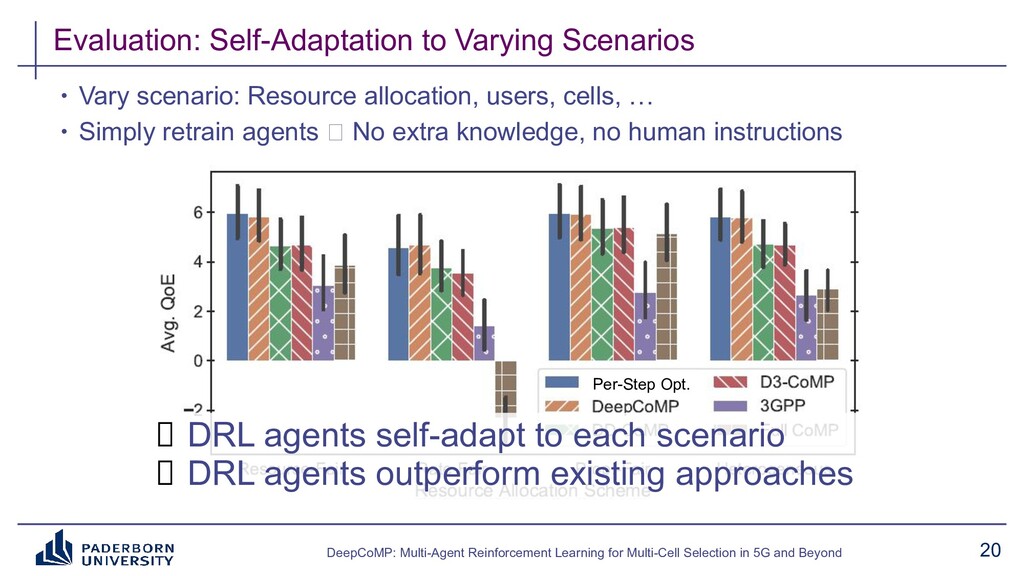
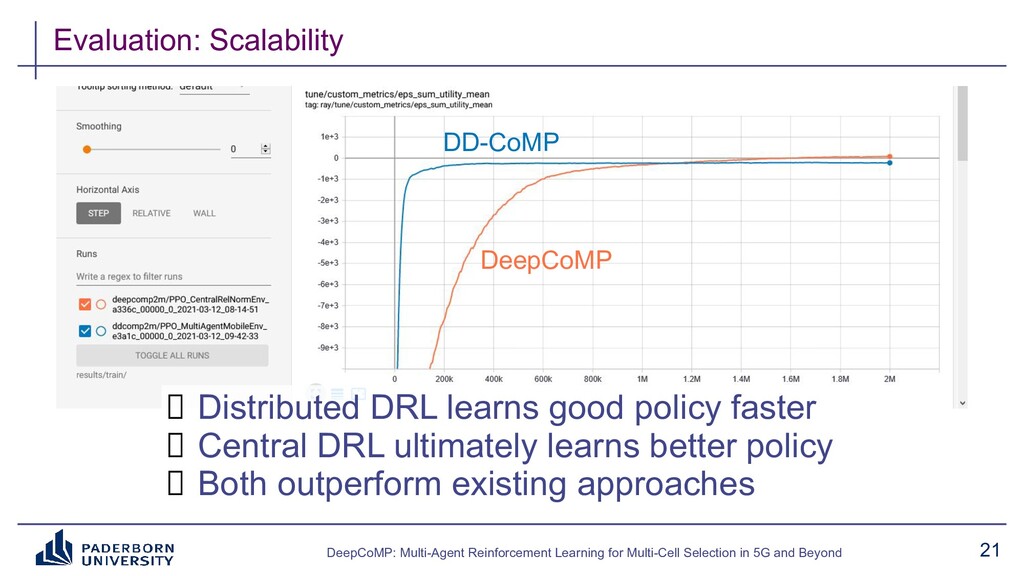
Existing approaches typically build on expert-tailored models and require strict assumptions or perfect knowledge of the underlying radio system and environment dynamics, which are often unavailable in practice. Instead, DeepCoMP has very limited built-in assumptions and learns to control multi-cell selection just from partial, realistically available observations and its own experience. We present three different variants of DeepCoMP using either centralized or distributed multi-agent deep reinforcement learning, discuss their strengths and weaknesses, and show that DeepCoMP outperforms other approaches by up to 231%. We also show how we used Ray RLlib to implement DeepCoMP and how RLlib simplified switching between centralized and multi-agent RL as well as local development and deployment of experiments on a private cluster.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}