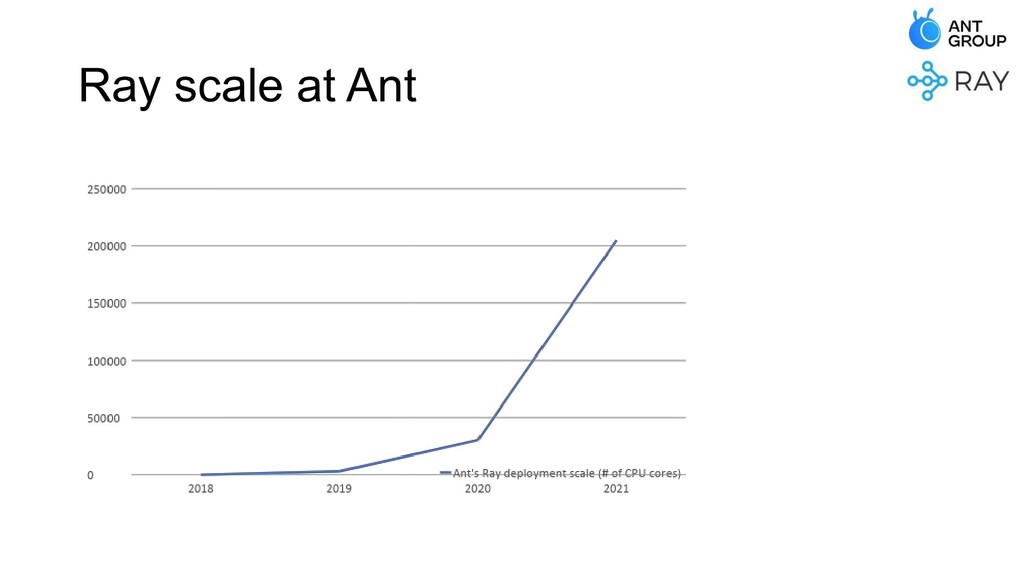
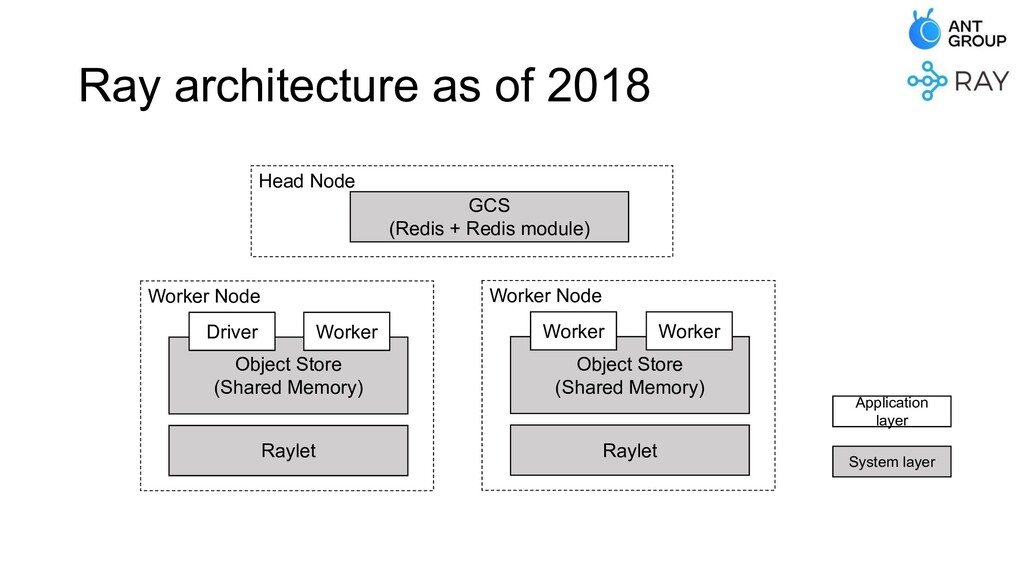
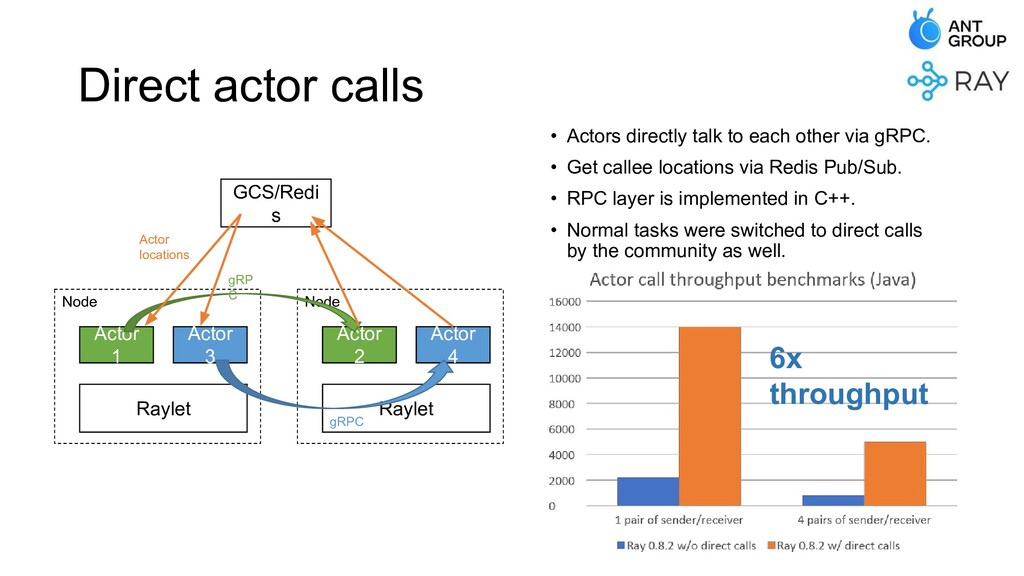
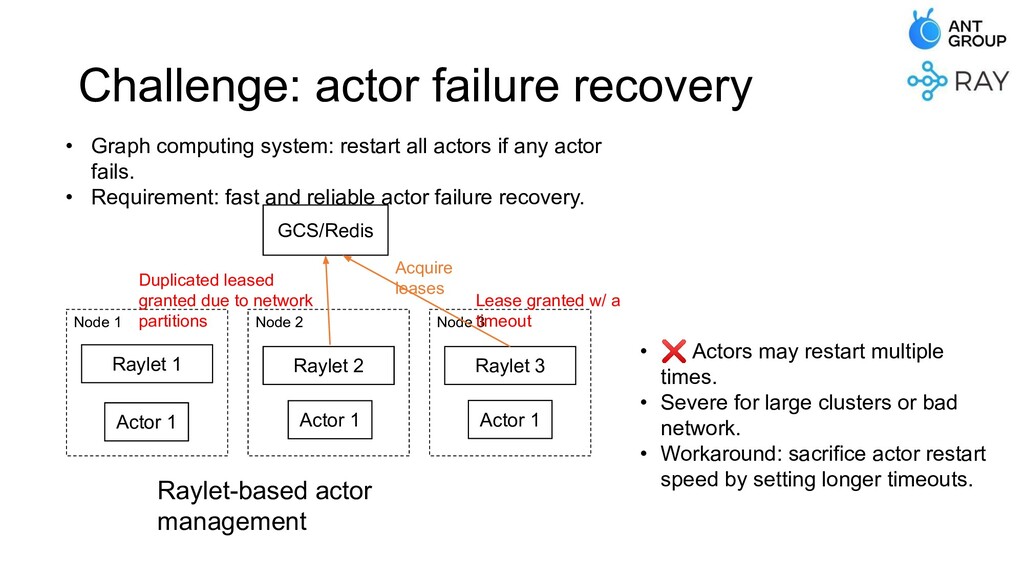
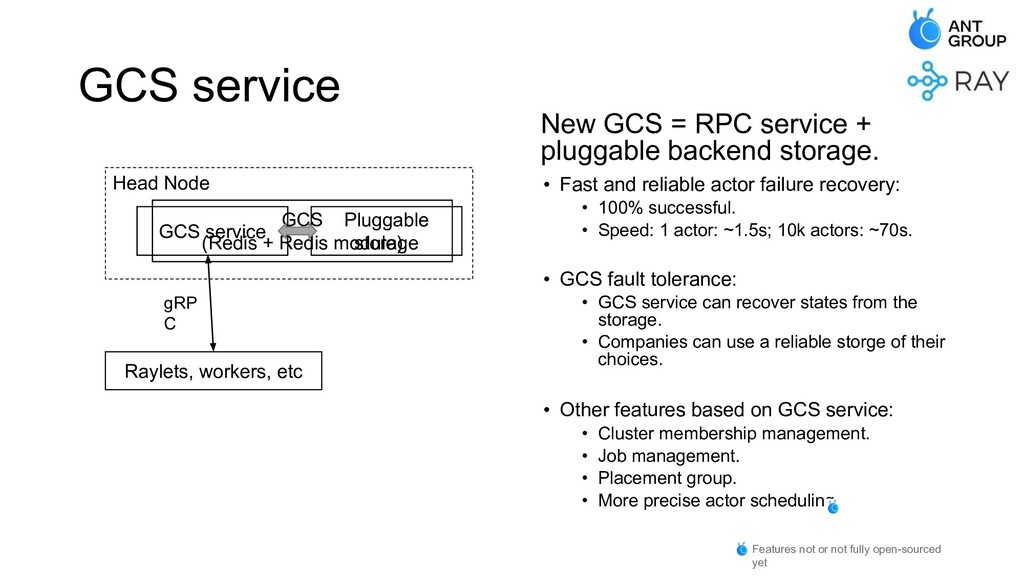
At Ant Group, we have built various kinds of distributed systems on top of Ray, and deployed them in production with large scales. In this talk, we'll be covering the problems we've met, and the improvements we've made that make Ray an industry-level system with high scalability and stability.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks We are hiring! [email protected]](https://files.speakerdeck.com/presentations/7daa4ed9b4534d4e90b821bc3974e623/slide_20.jpg){kind=link}