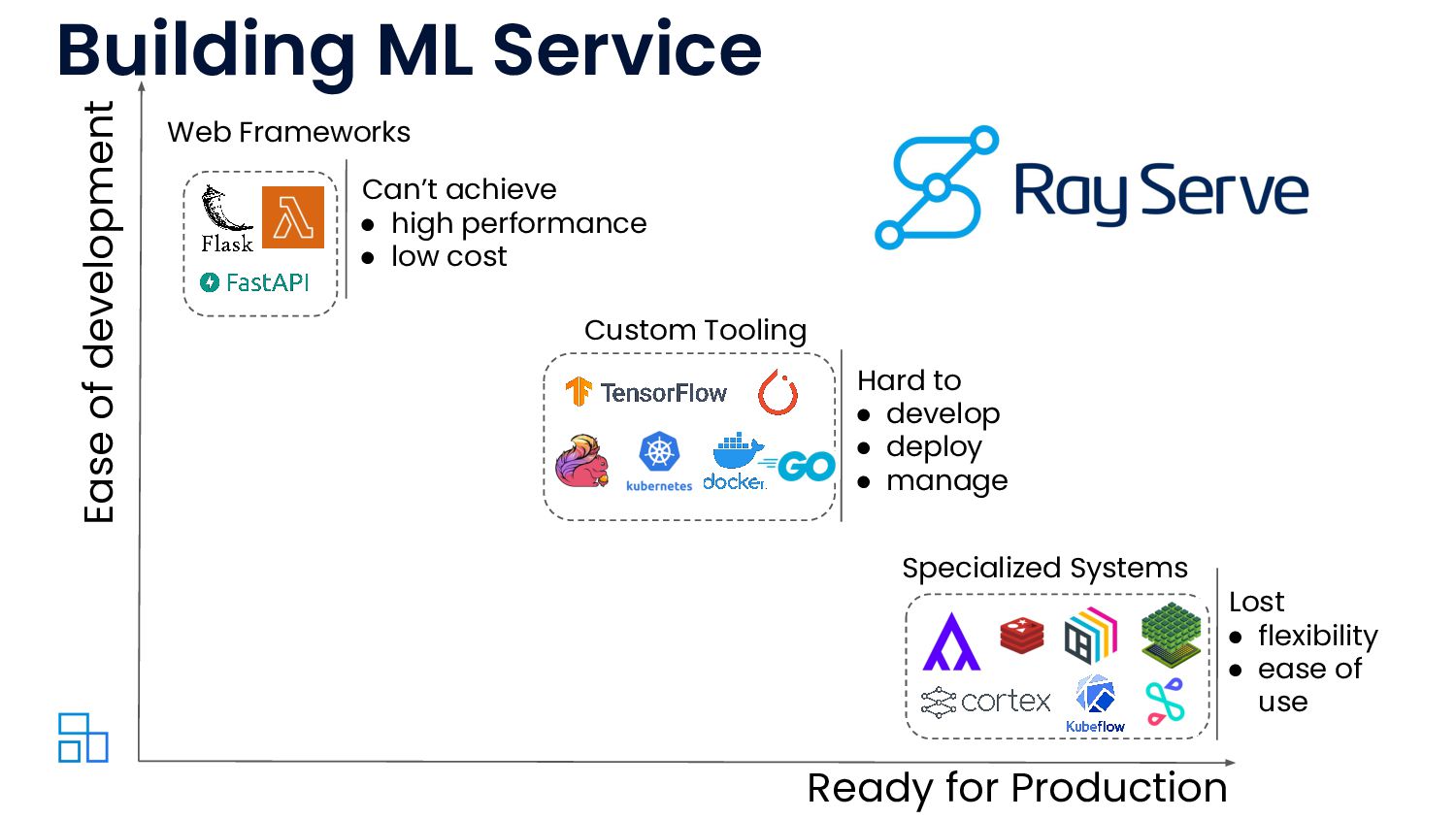
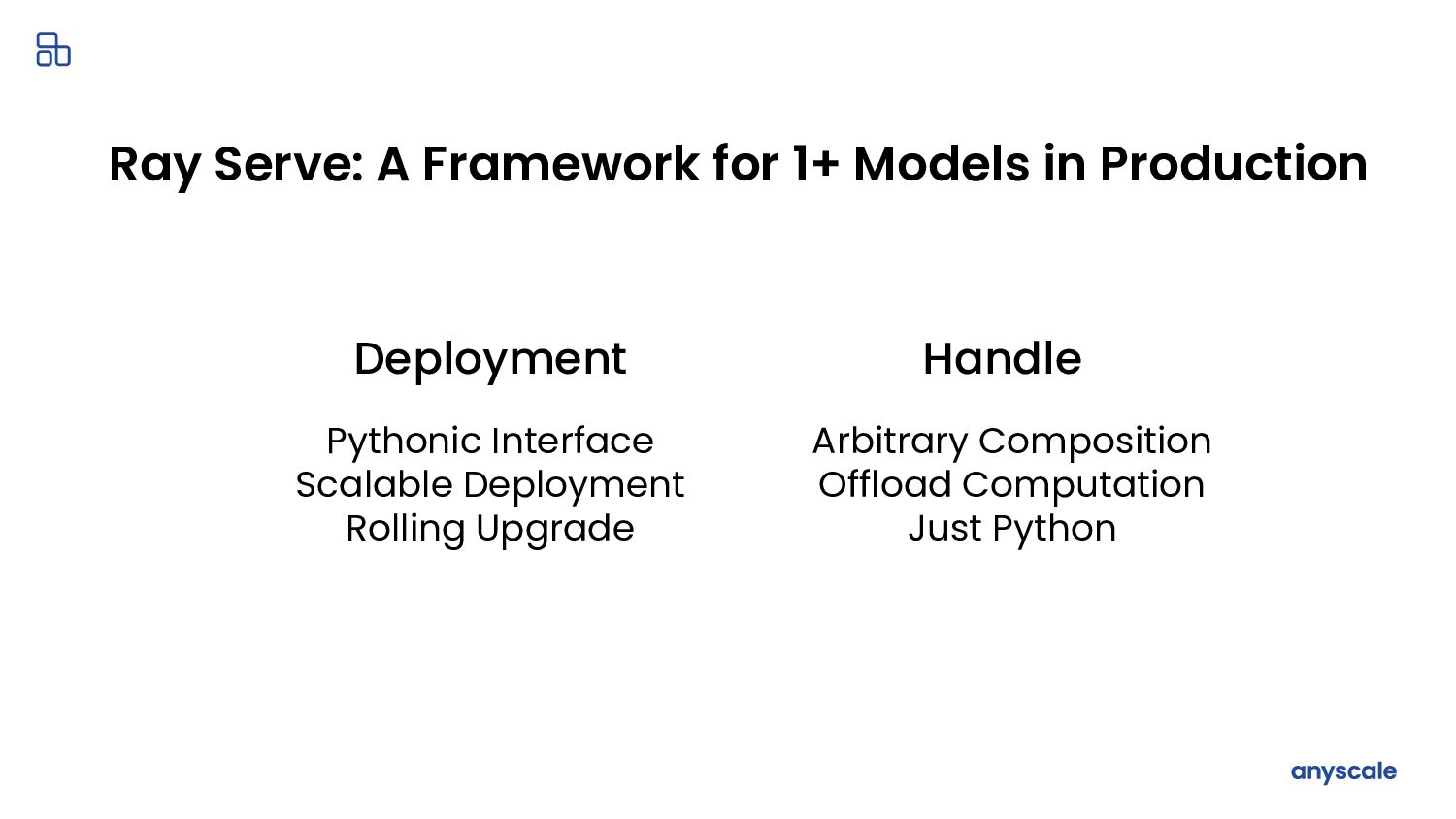
Ray Serve is Ray’s model serving library. Traditionally, model serving requires configuring a web server or a cloud-hosted solution. These approaches either lack scalability or hinder development through framework-specific tooling, vendor lock-in, and general inflexibility. Ray Serve overcomes these limitations. It offers a developer-friendly and framework-agnostic interface that provides scalable, production-ready model serving.
Ray Serve is
- Scalable: It provides fine-grained resource management and scaling using Ray.
- Framework-agnostic: It works with any Python code, regardless of framework.
- Production-ready: It comes with a web server out of the box and handles routing, testing, and scaling logic for deployments.
- Developer-friendly: It offers a decorator-based API that converts existing applications into Ray Serve deployments with minimal refactoring.
This presentation introduces Ray Serve, including its use cases and its features. It walks through Ray Serve setup and integration with existing machine learning models.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
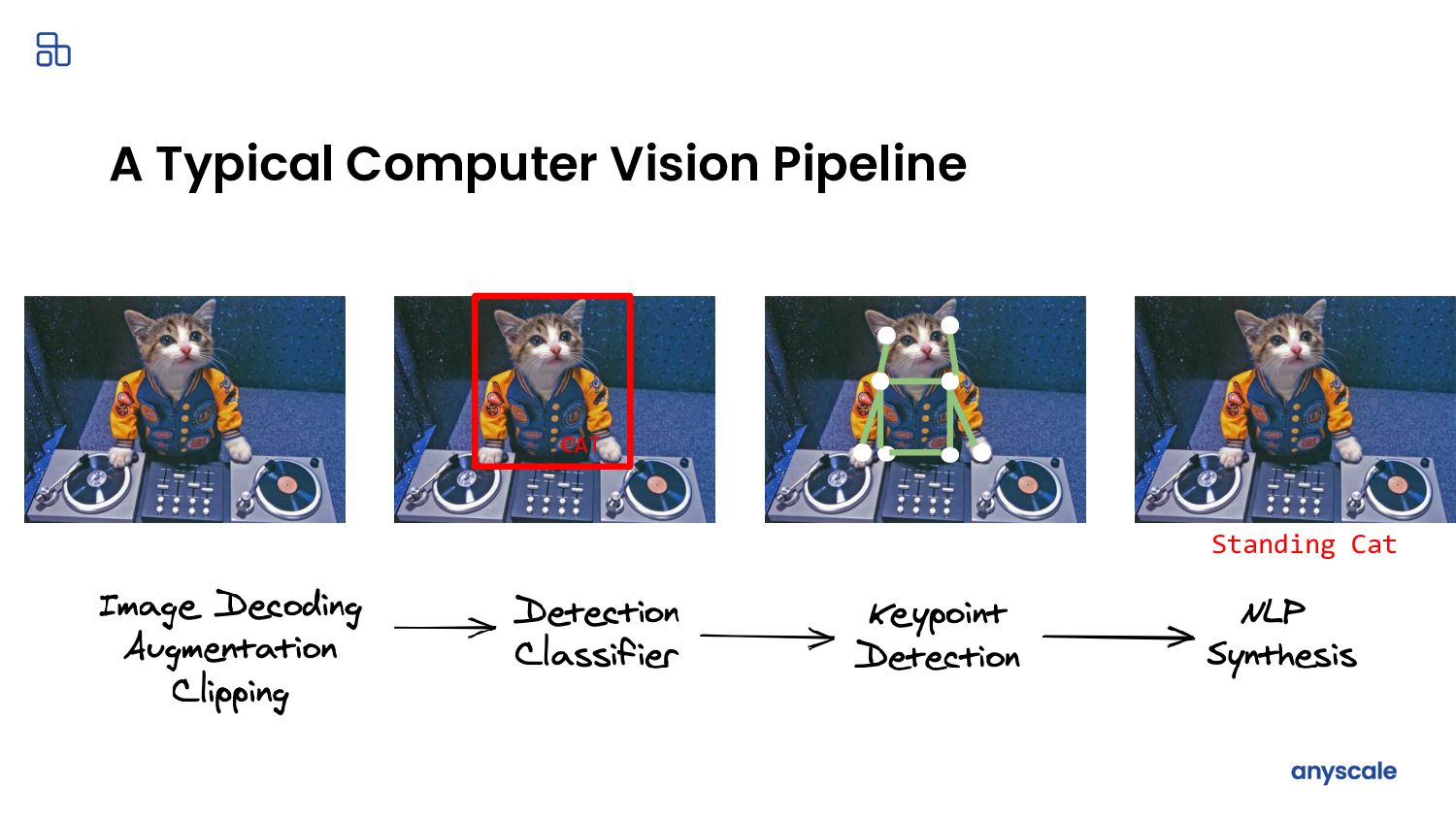{kind=link}
{kind=link}
{kind=link}
{kind=link}
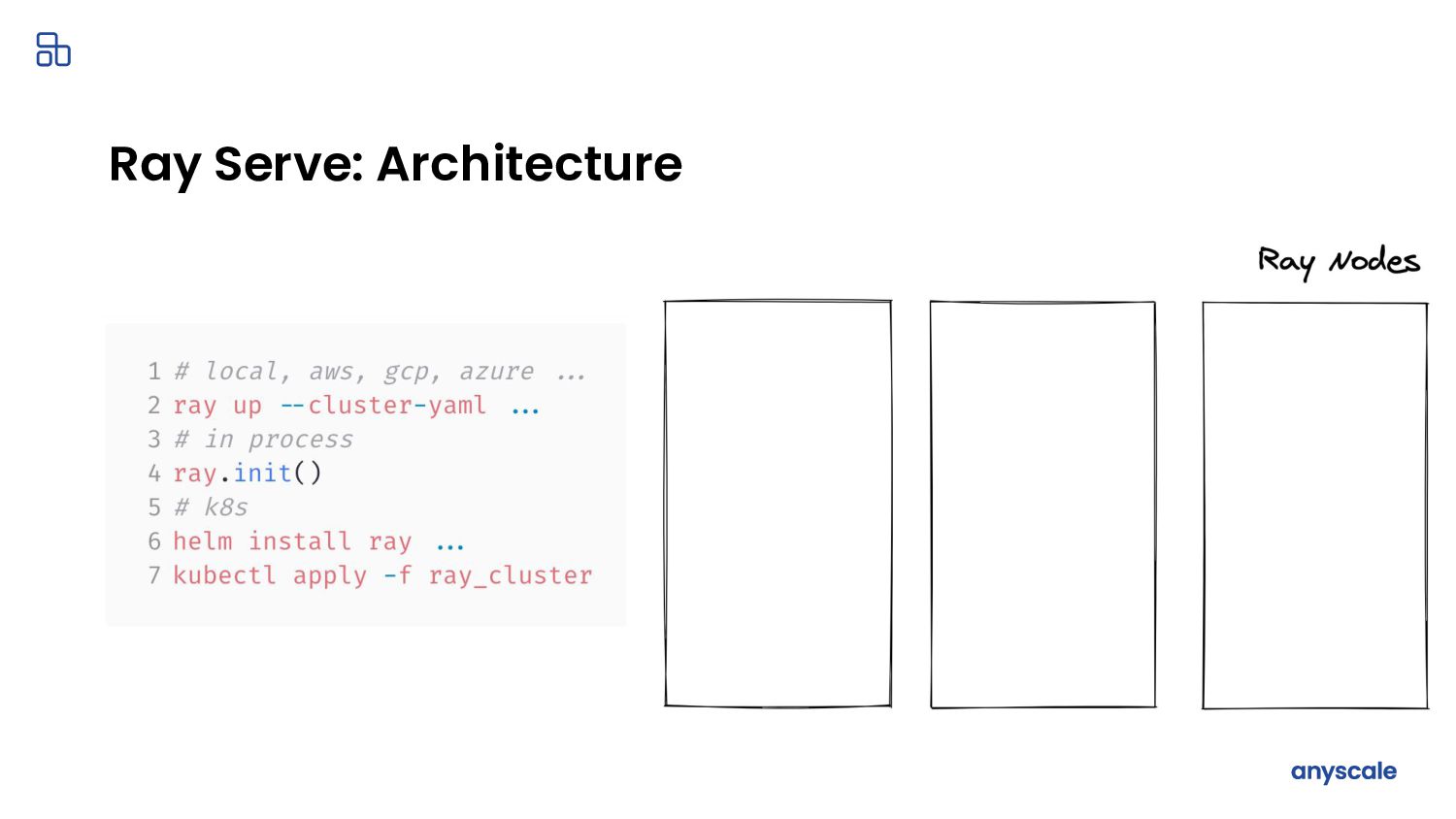{kind=link}
{kind=link}
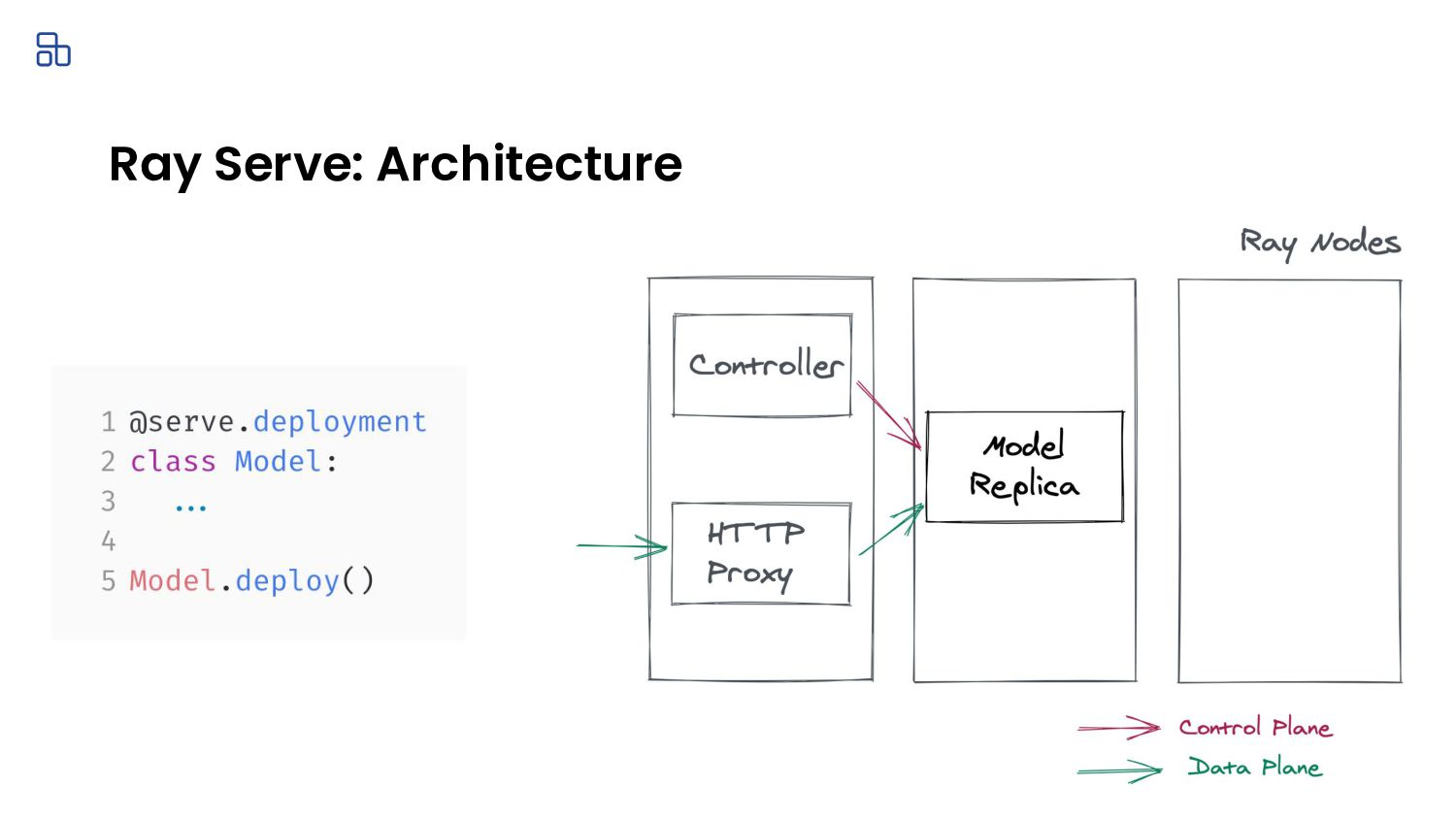{kind=link}
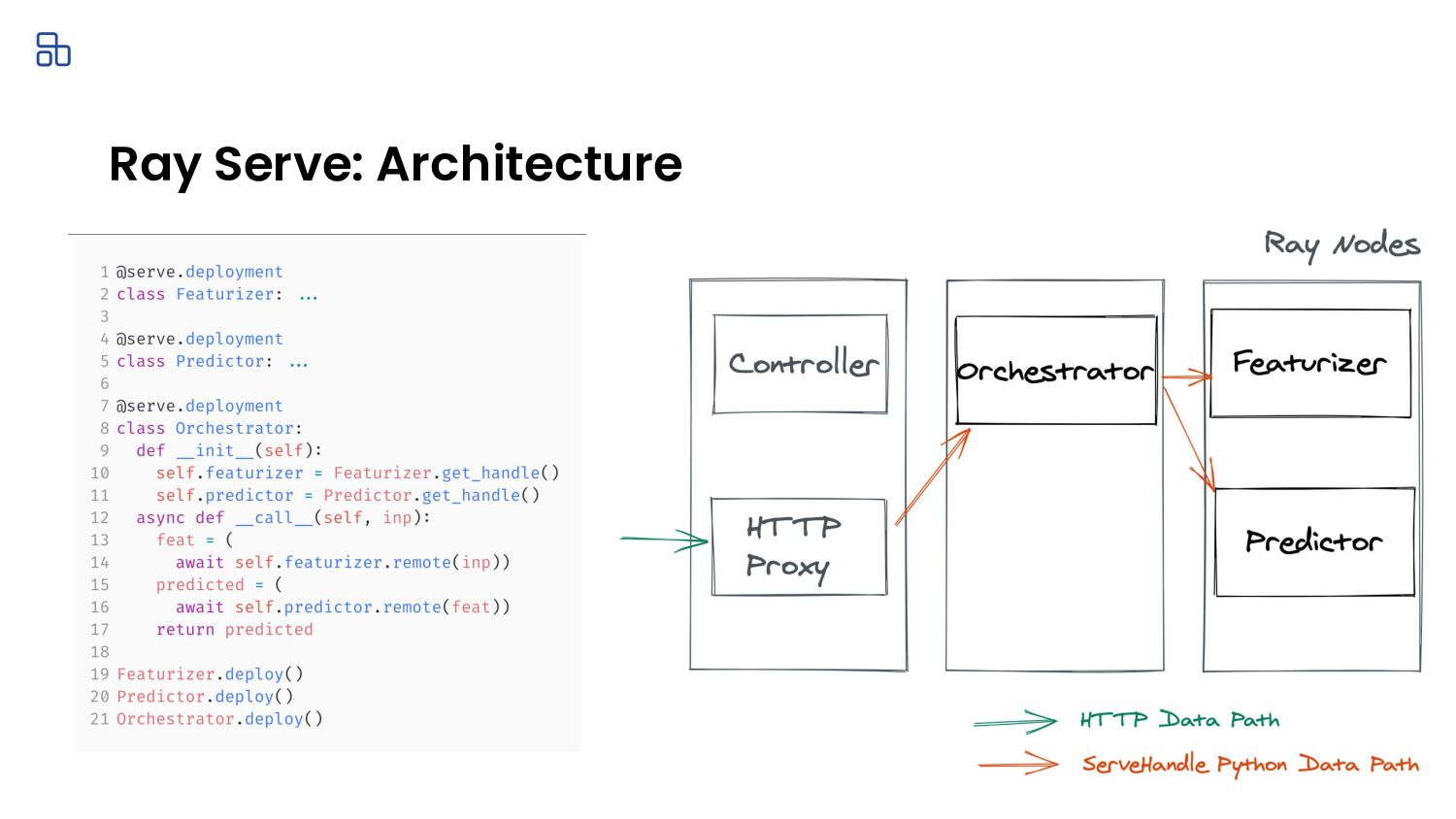{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}