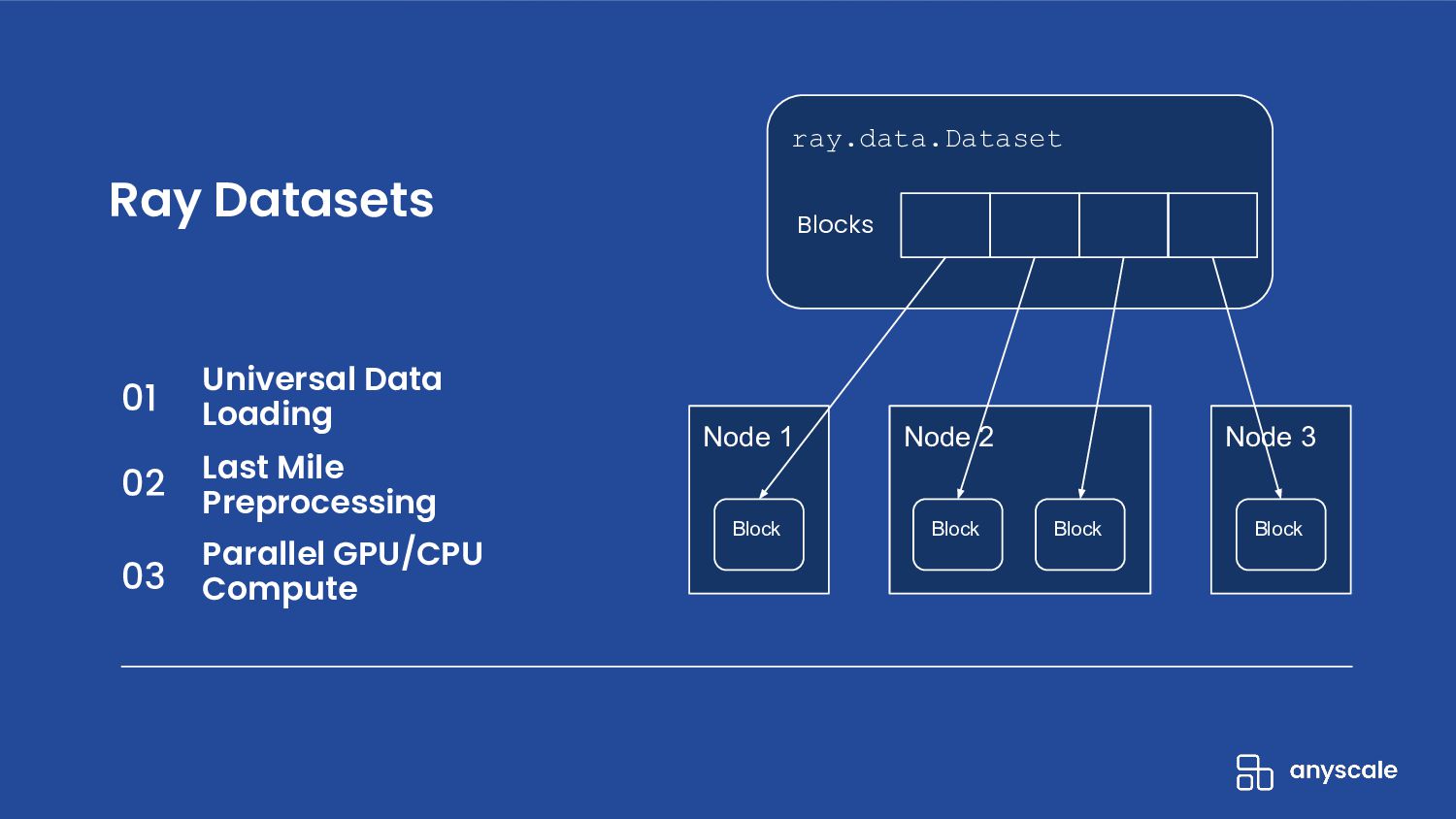
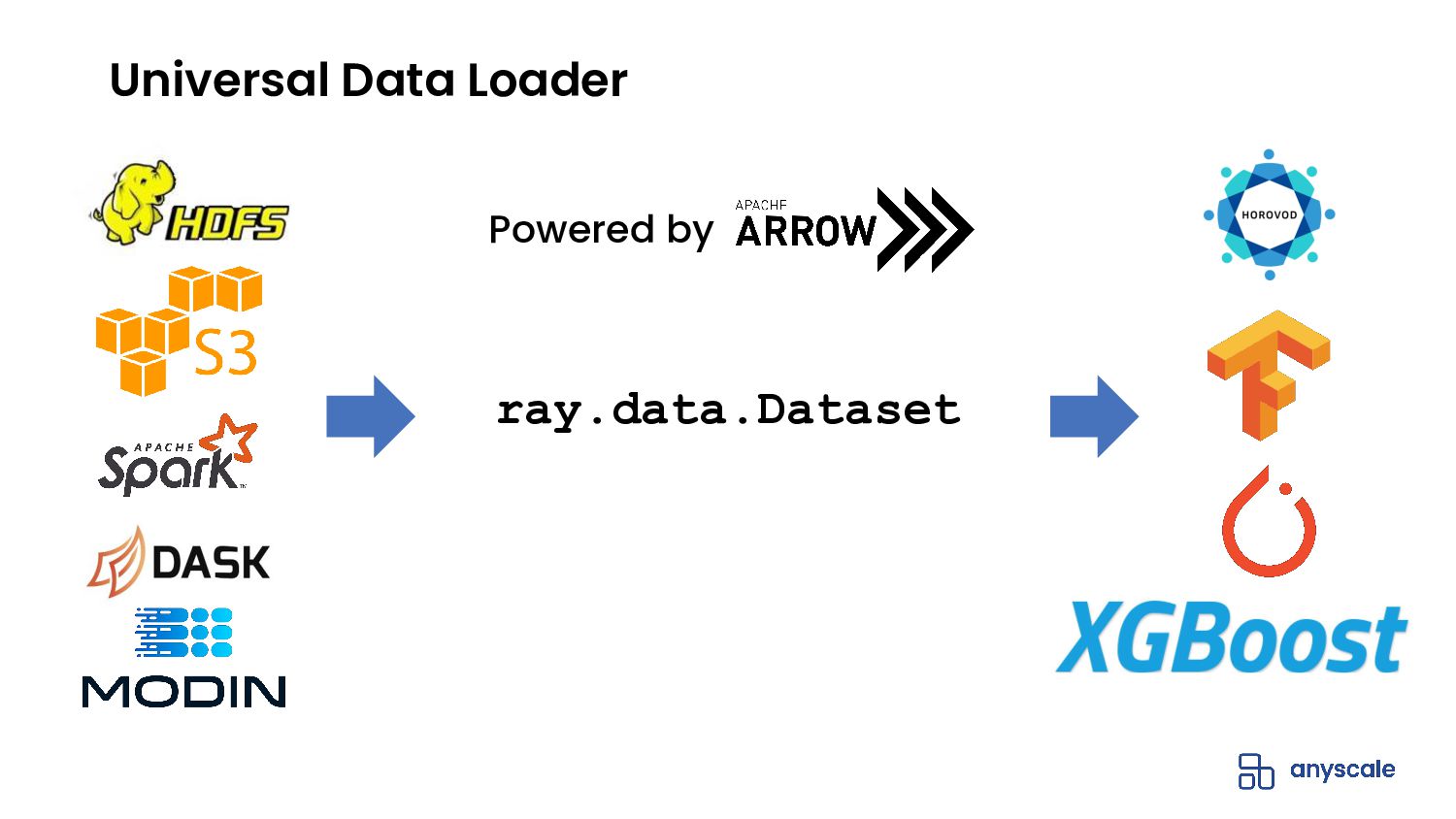
Ray Datasets is a Ray-native distributed dataset library that serves as the standard way to load, process, and exchange data in Ray libraries and applications. It features performant distributed data loading, flexible parallel compute operations, and comprehensive datasource compatibility and distributed framework integrations, all behind an incredibly simple API.
Get a first-hand look at how Ray Datasets:
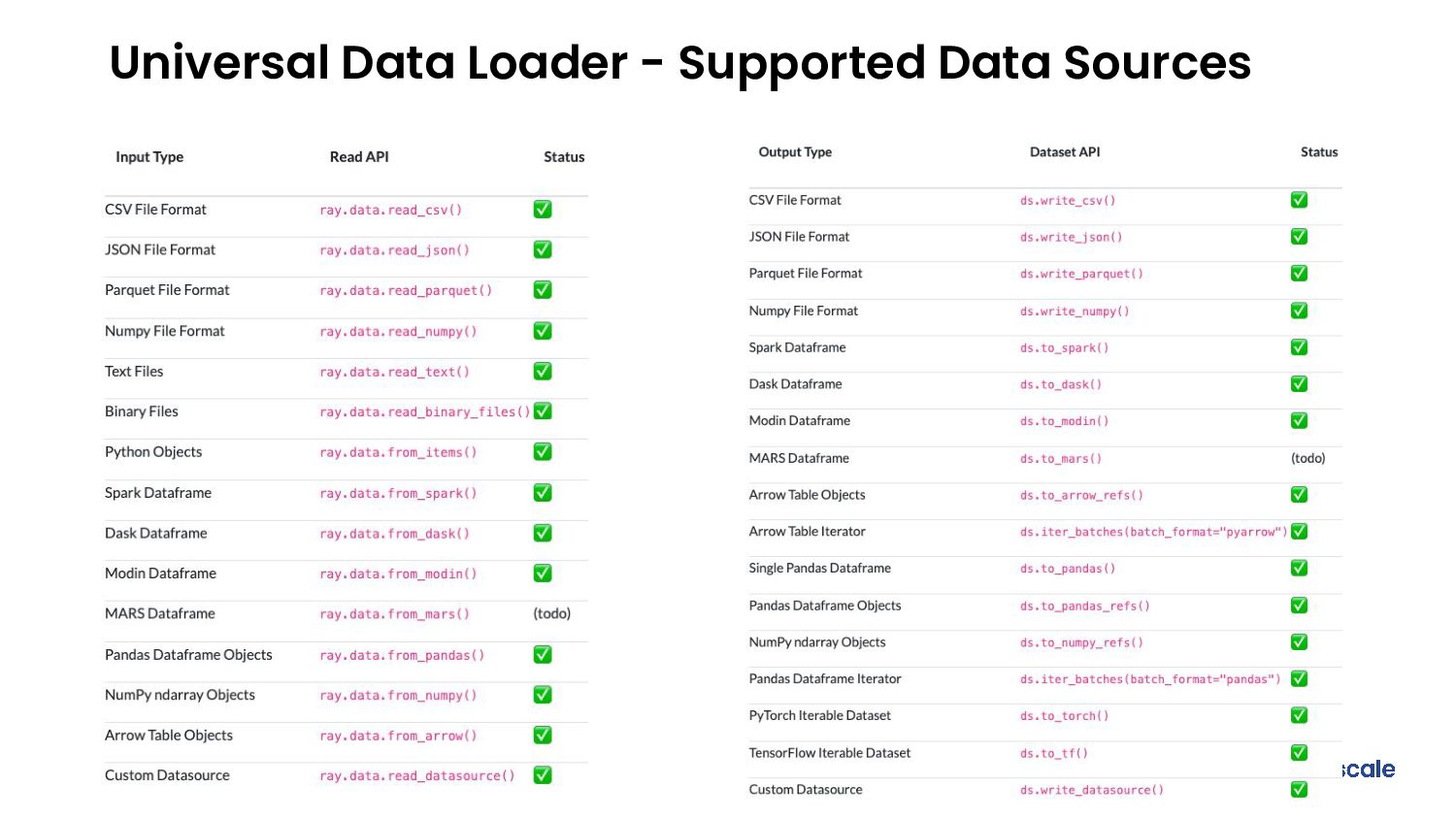
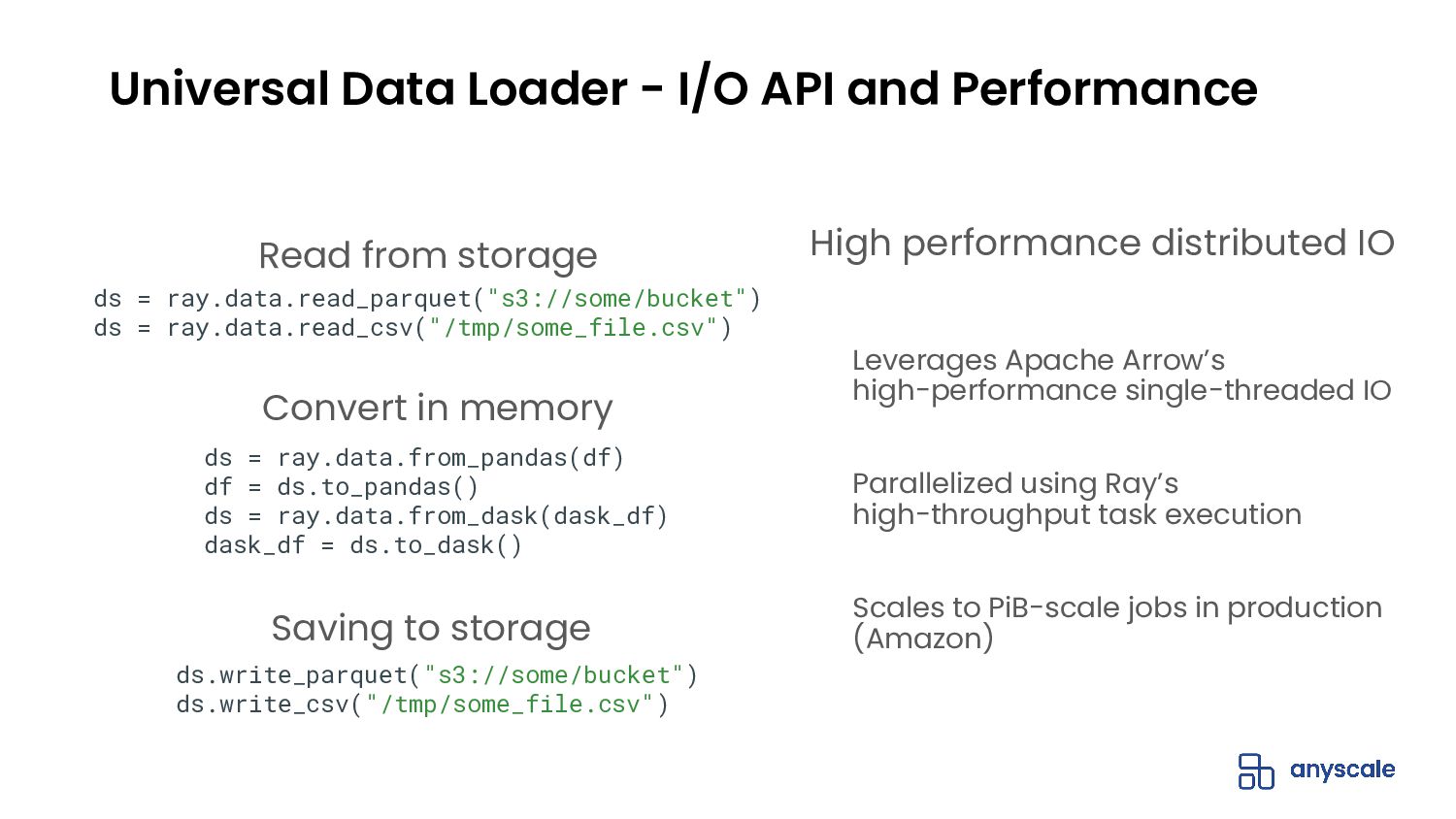
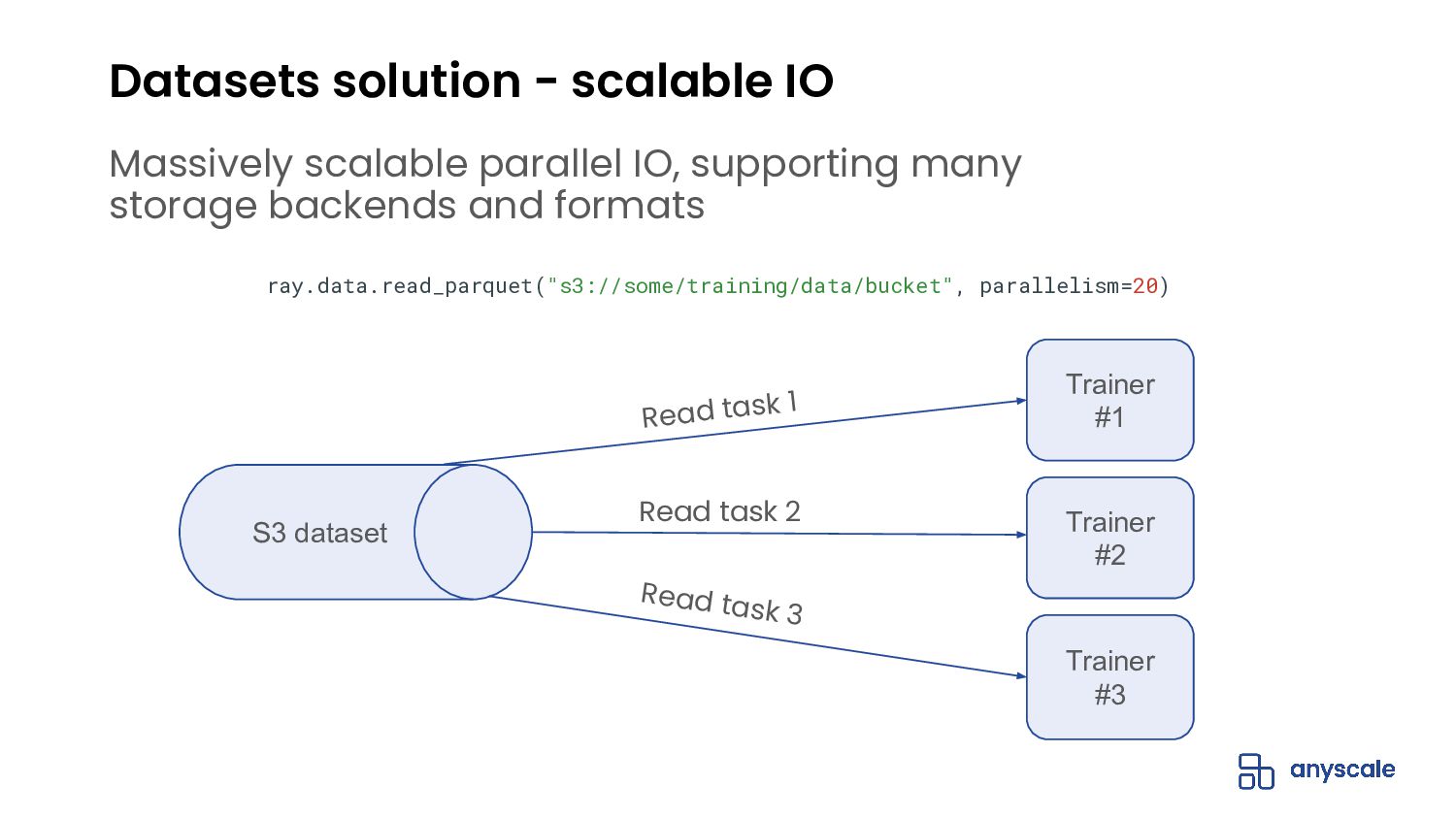
- Provides hyper-scalable parallel I/O to most popular storage backends and file formats
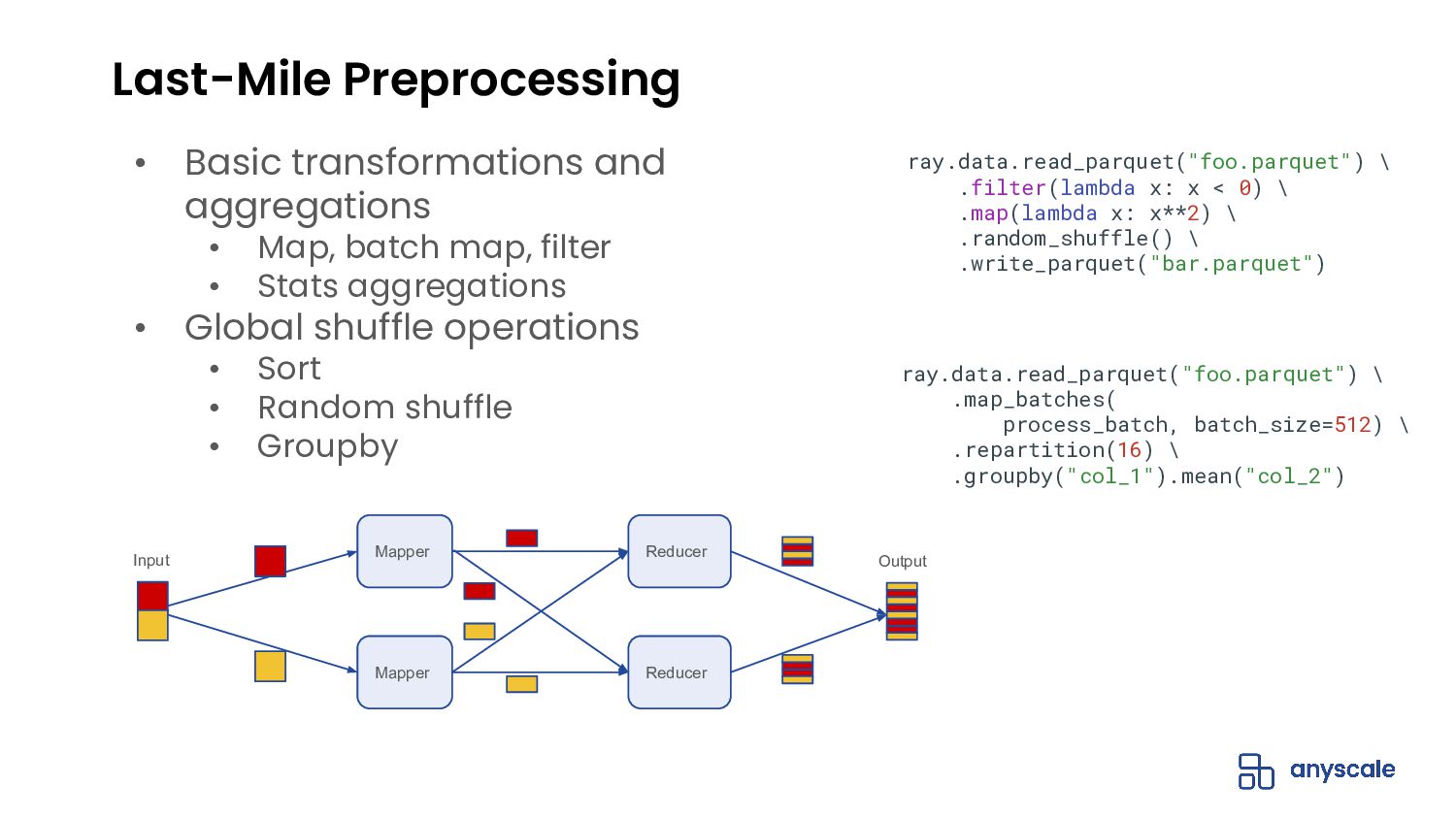
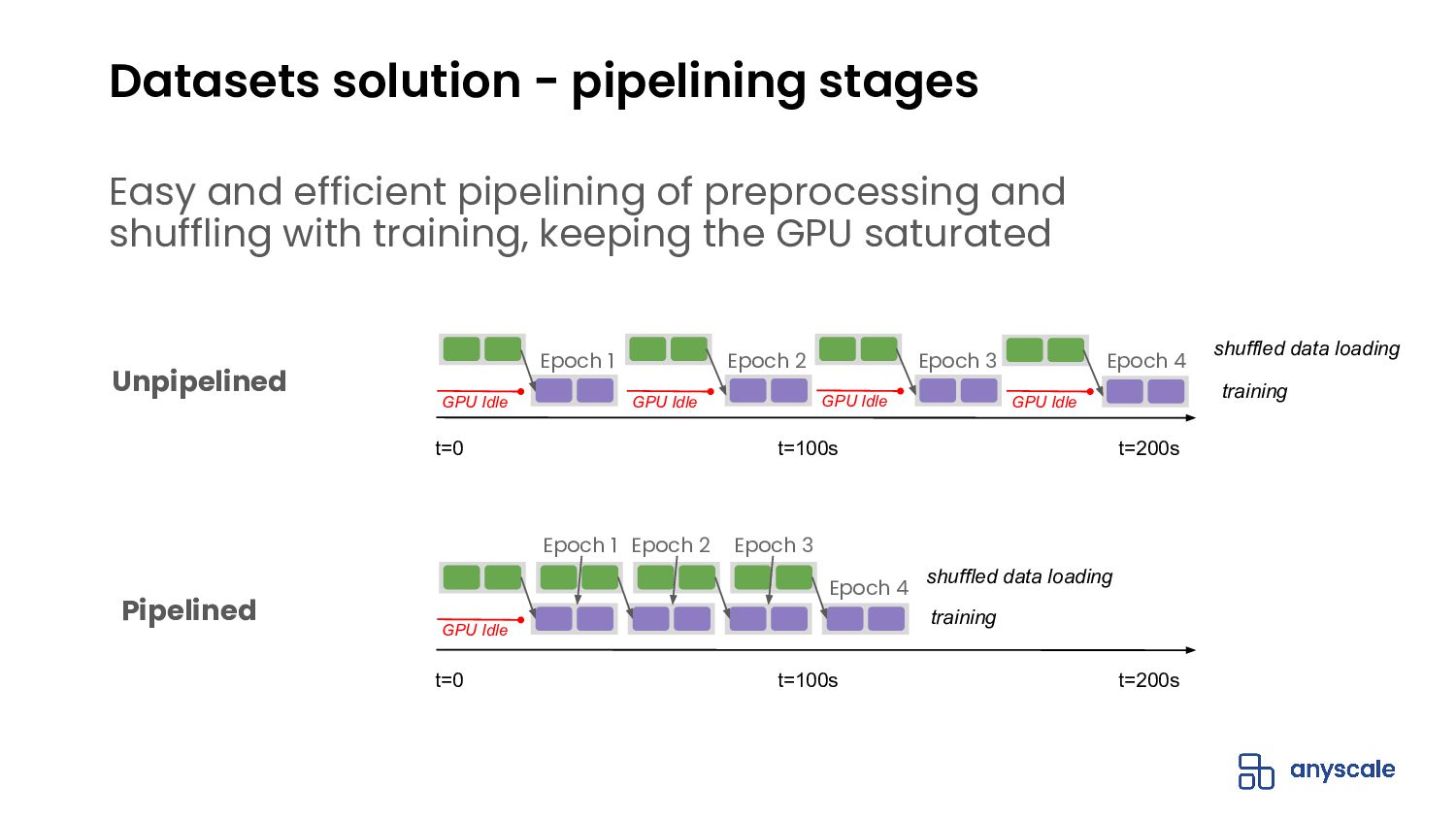
- Supports common last-mile preprocessing operations, including basic parallel data transformations such as map, batched map, and filter, and global operations such as sort, shuffle, groupby, and stats aggregations
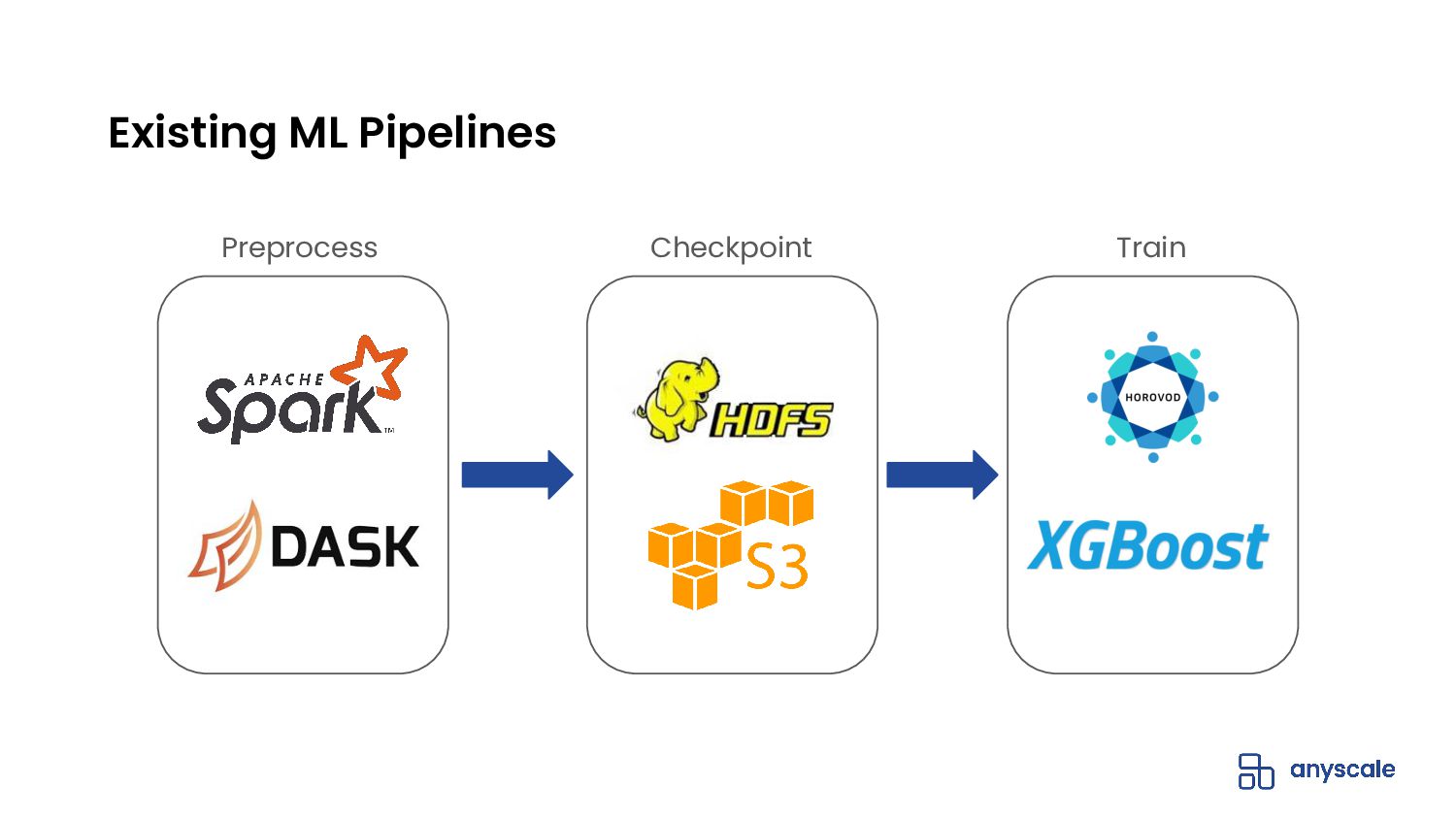
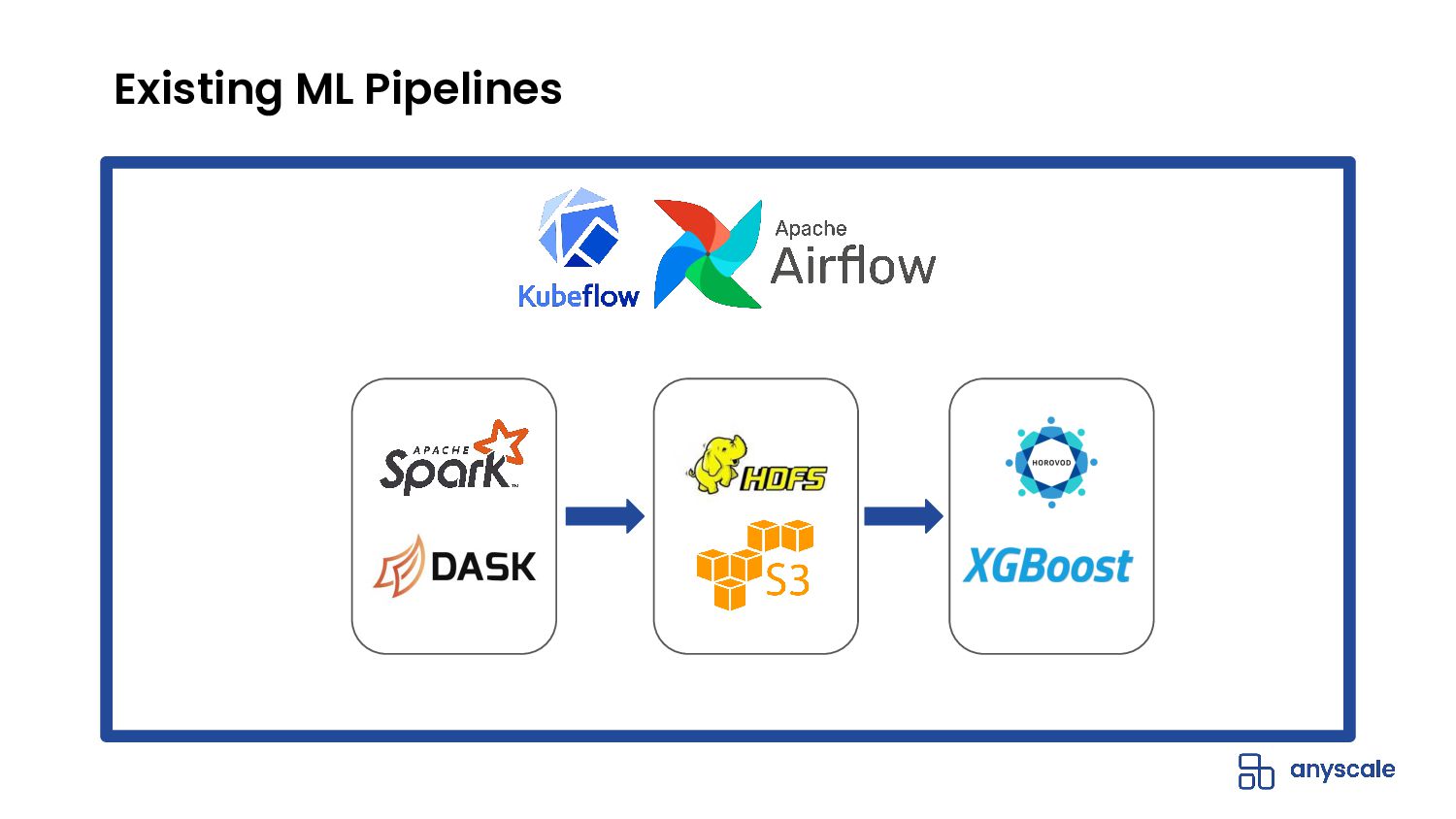
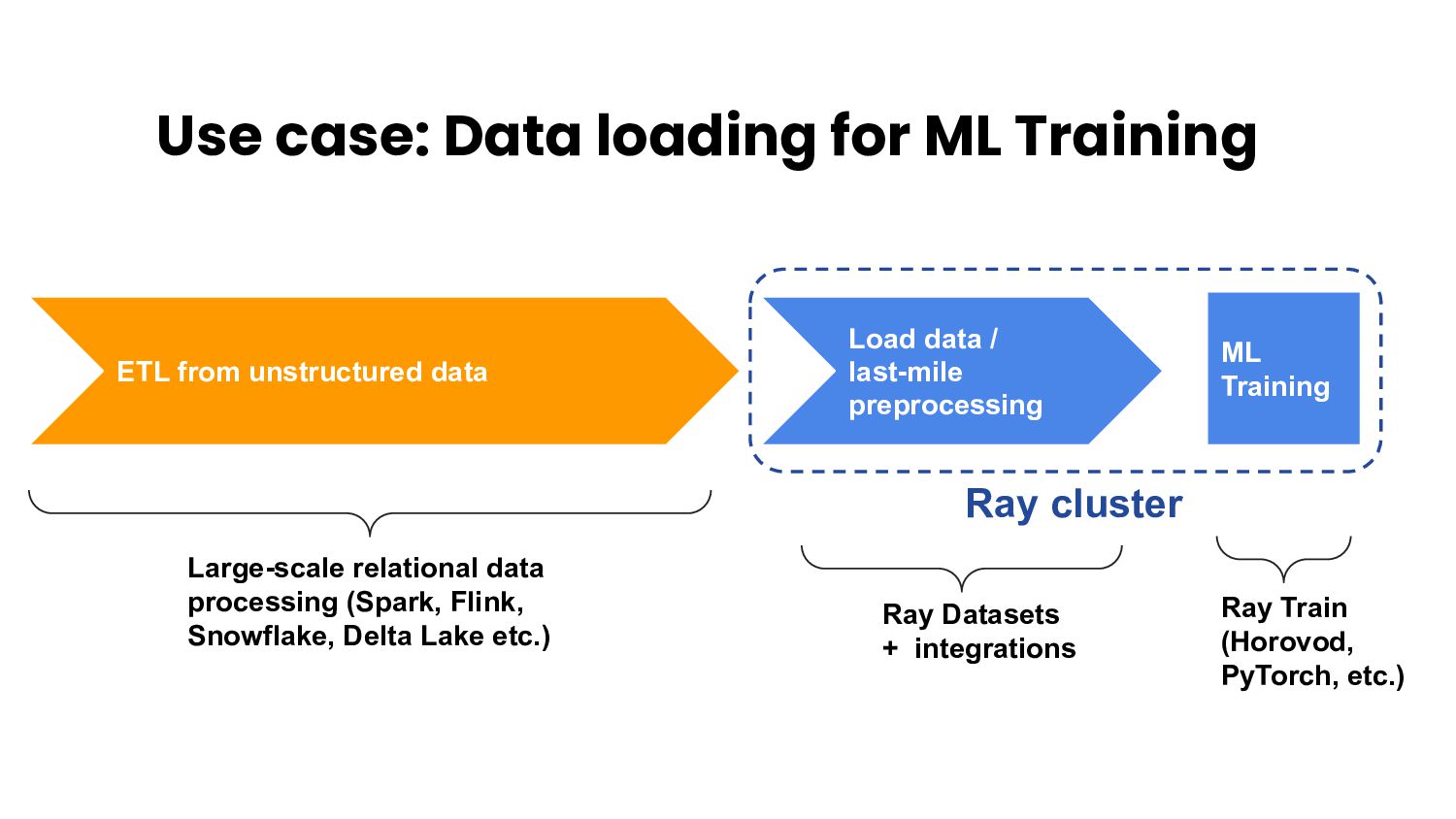
- Efficiently integrates with data processing libraries (e.g., Spark, Pandas, NumPy, Dask, Mars) and machine learning frameworks (e.g., TensorFlow, Torch, Horovod)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
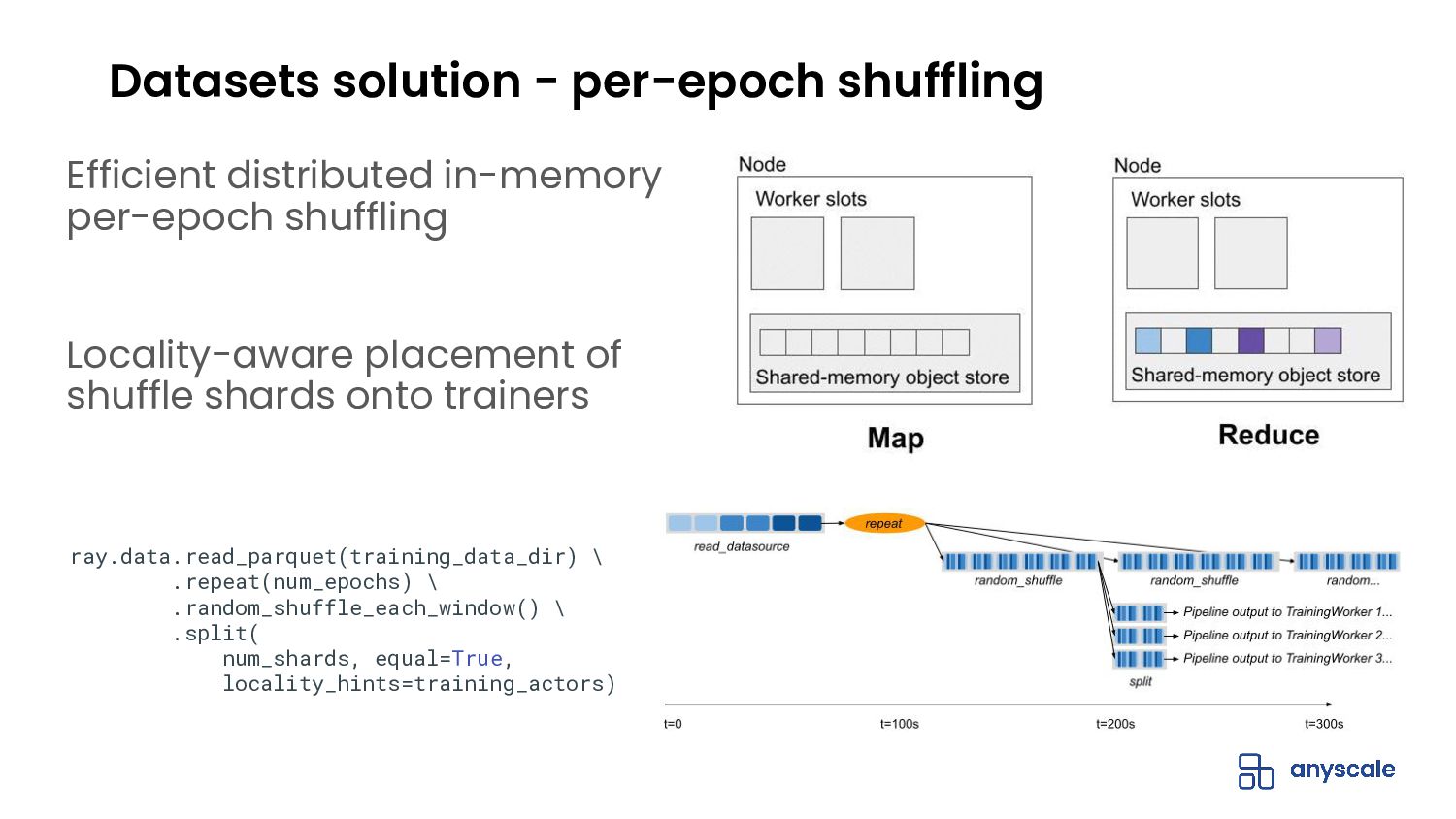{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
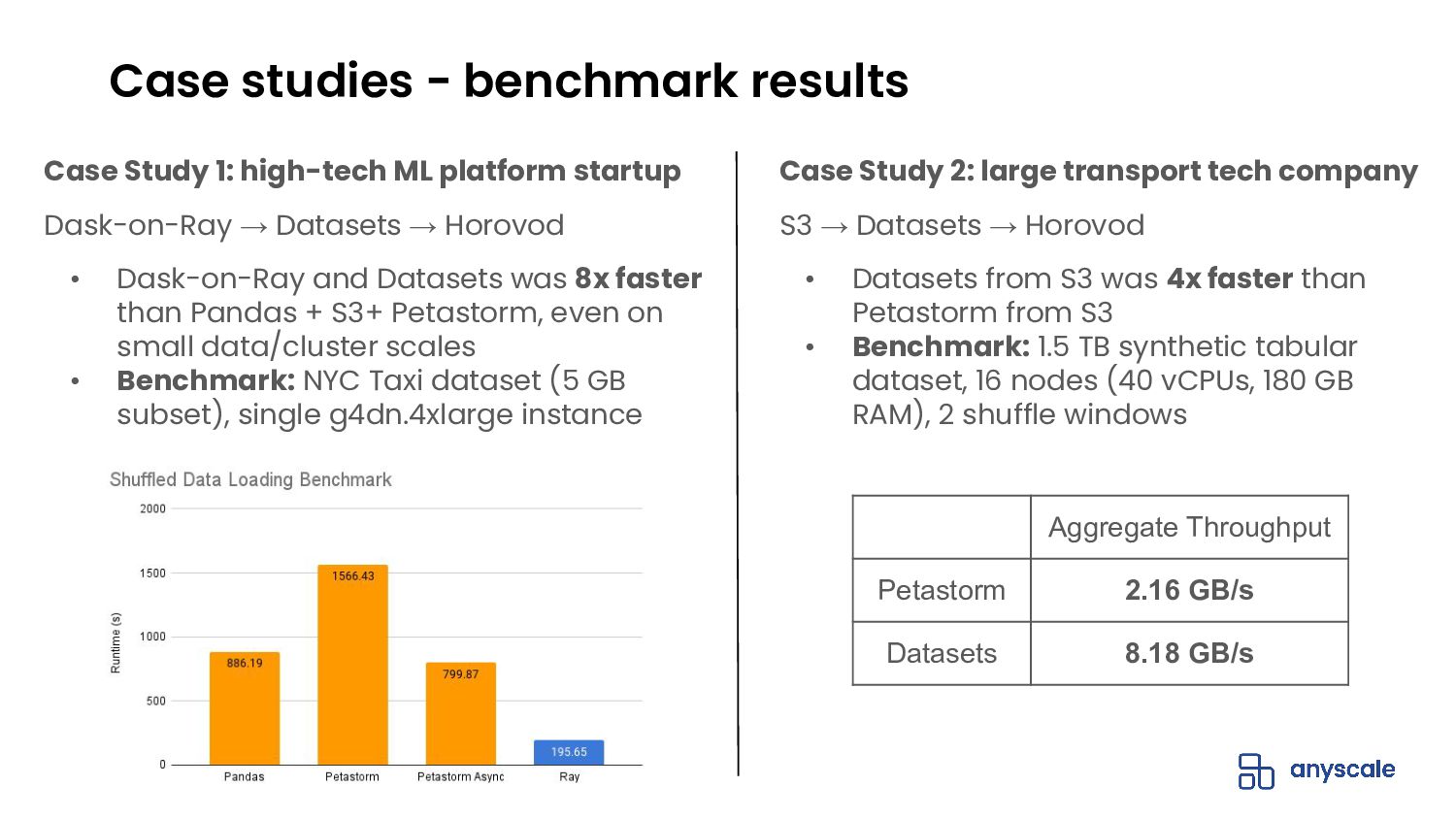{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
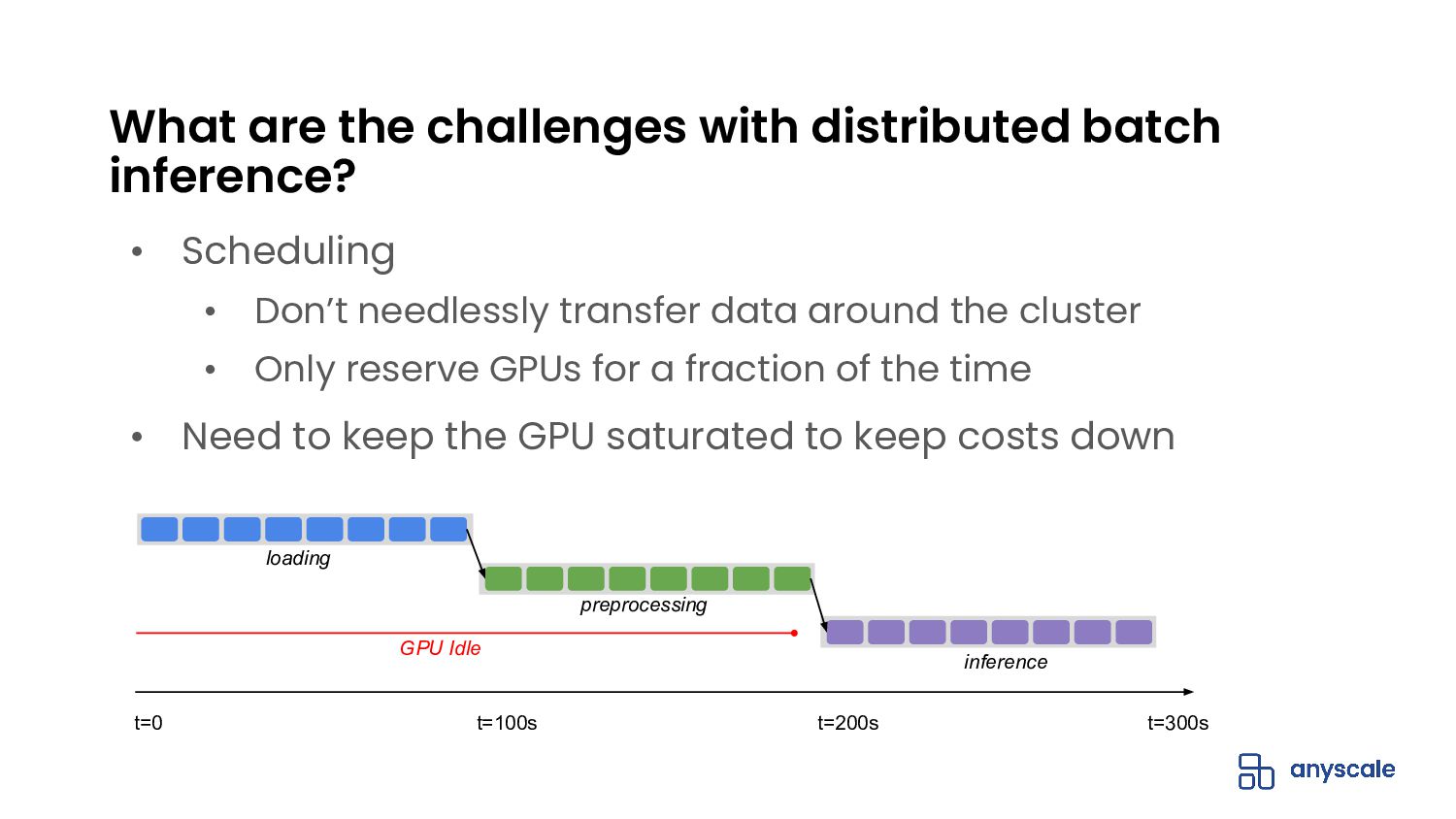{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
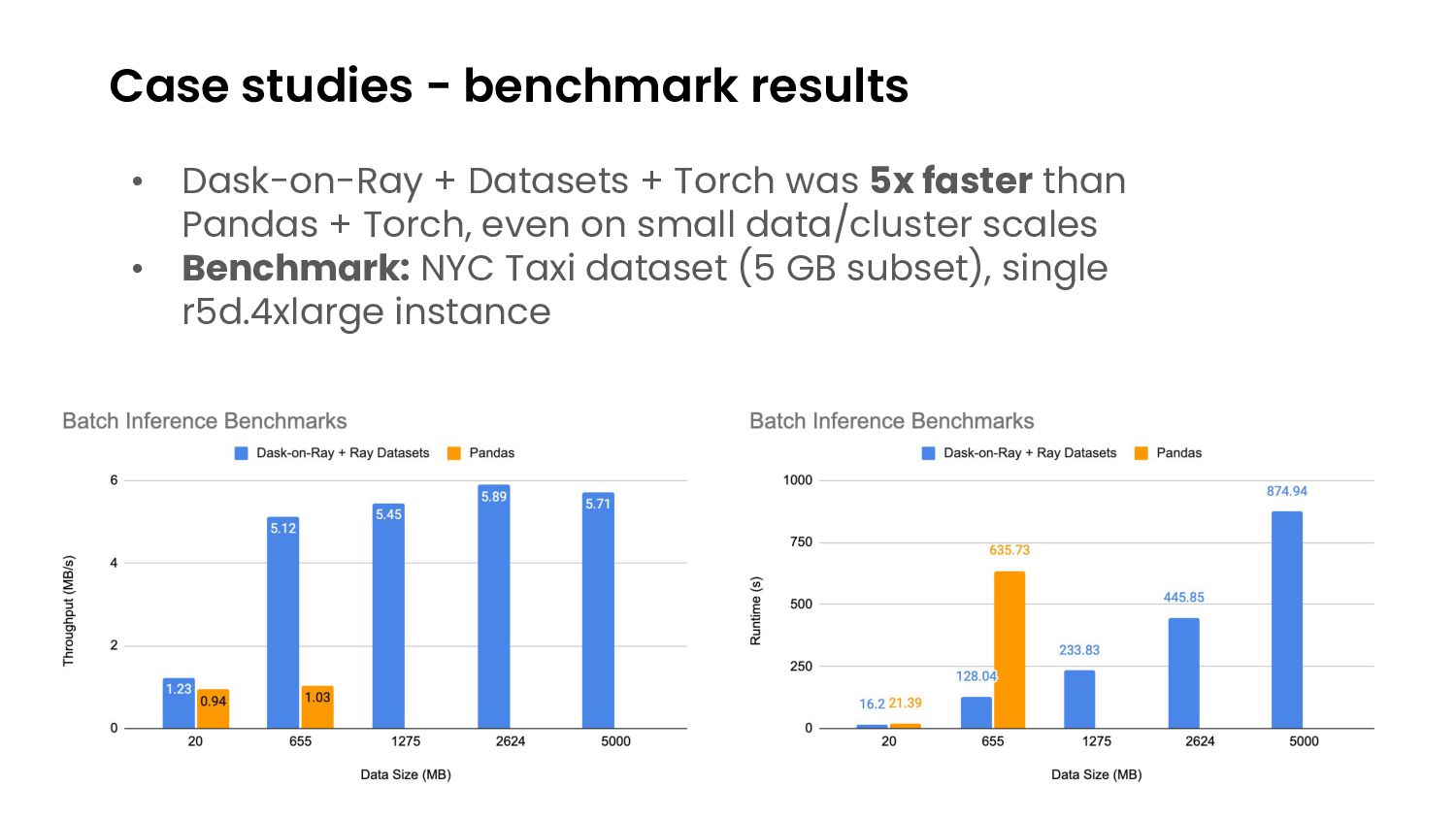{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}