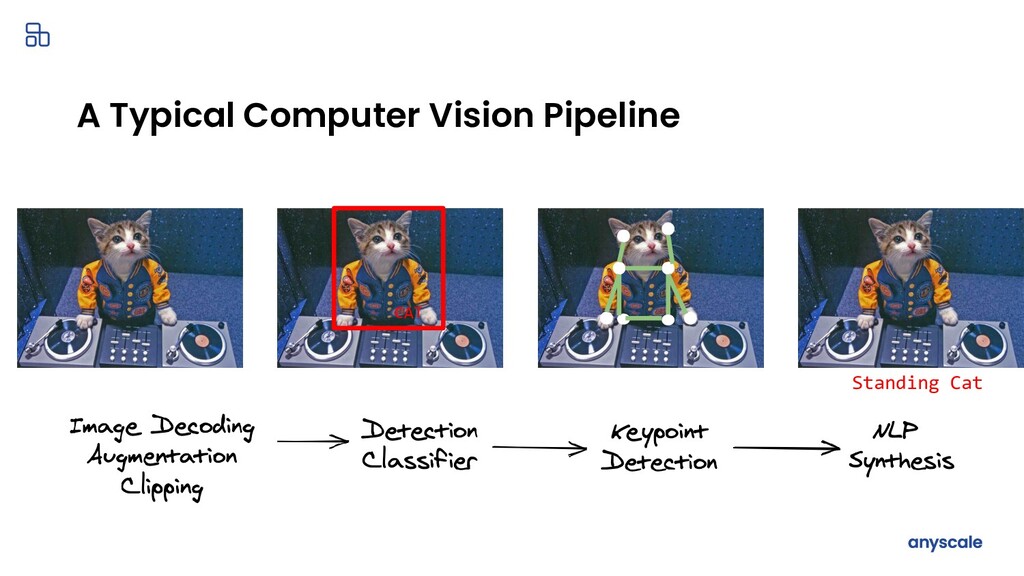
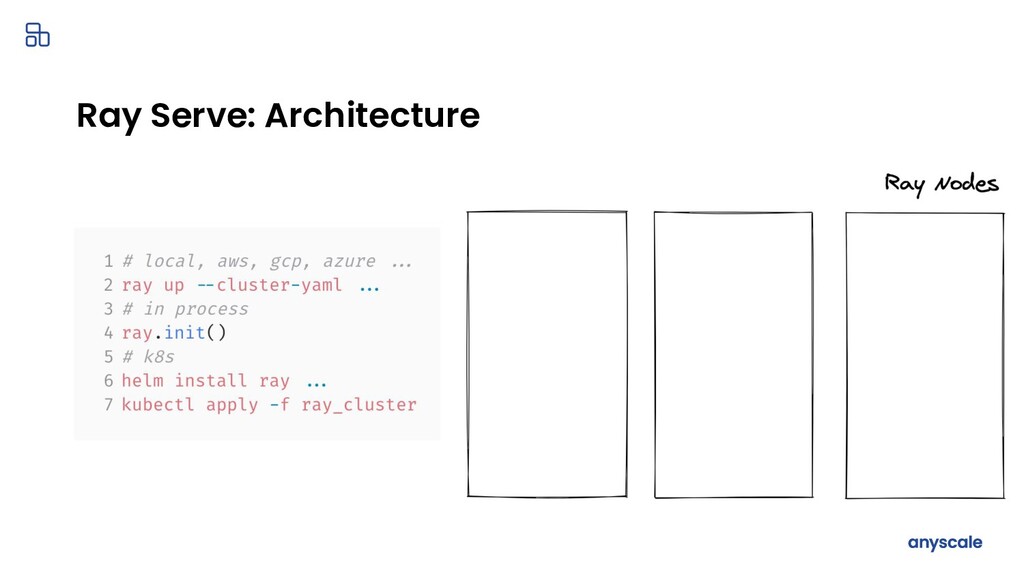
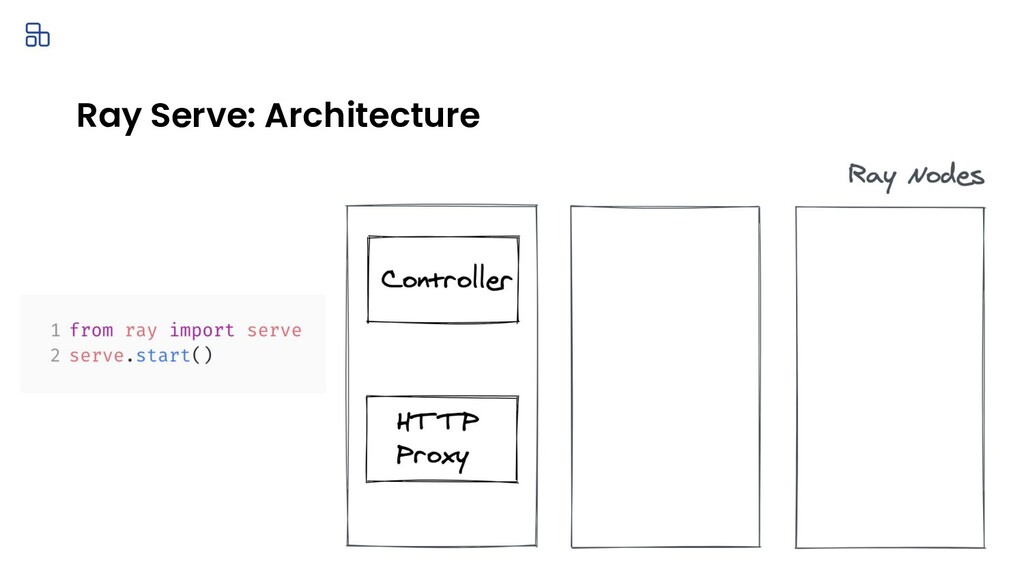
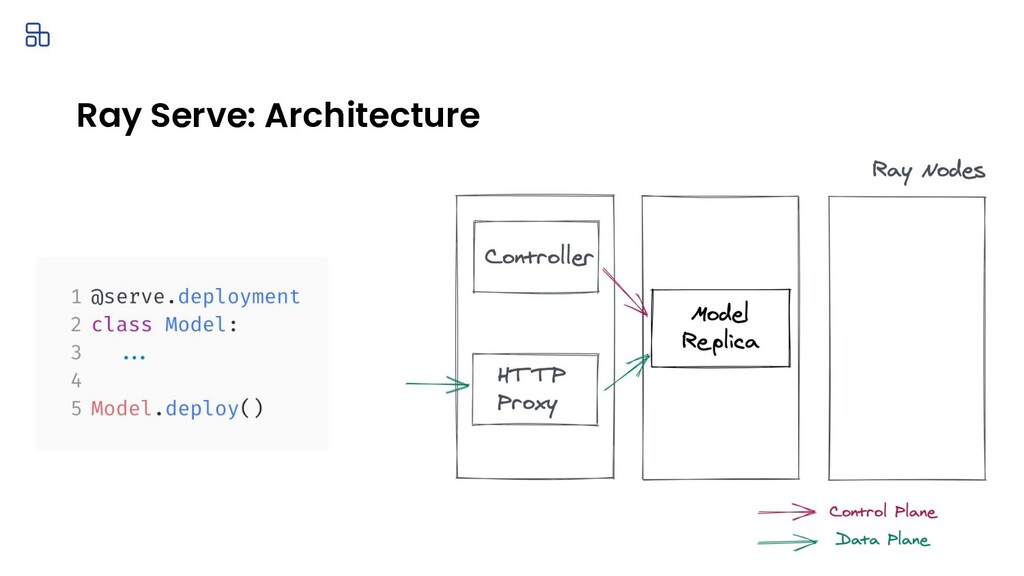
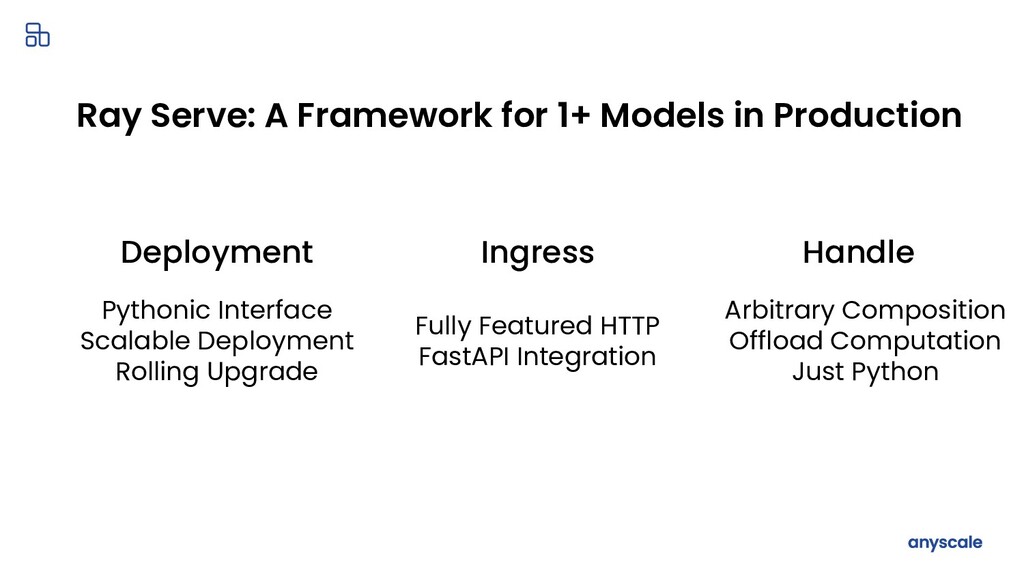
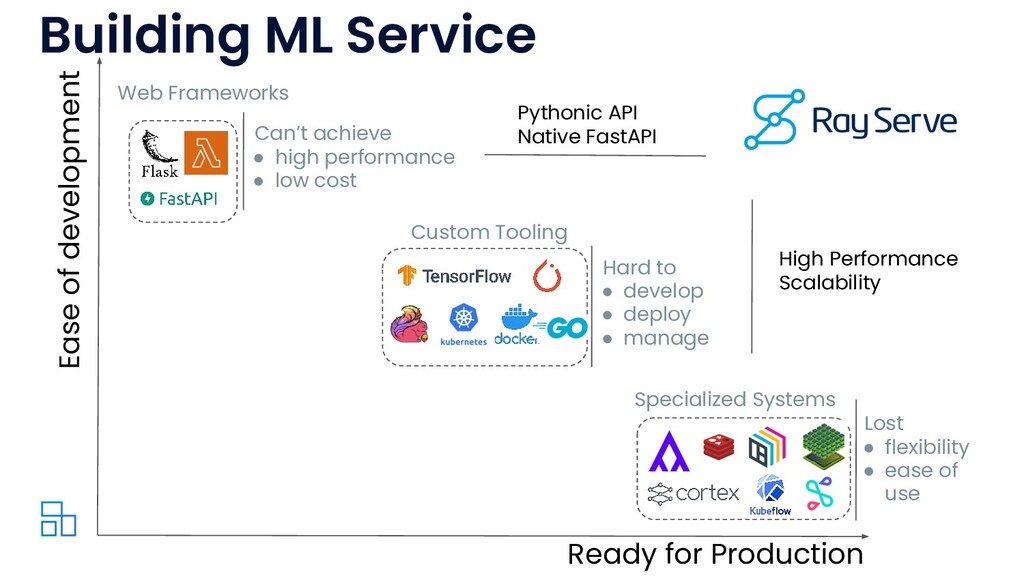
You trained a ML model, now what? The model needs to be deployed for online serving and offline processing. This talk walks through the journey of deploying your ML models in production. I will cover common deployment patterns backed by concrete use cases which are drawn from 100+ user interviews for Ray and Ray Serve. Lastly, I will cover how we built Ray Serve, a scalable model serving framework, from these learnings.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
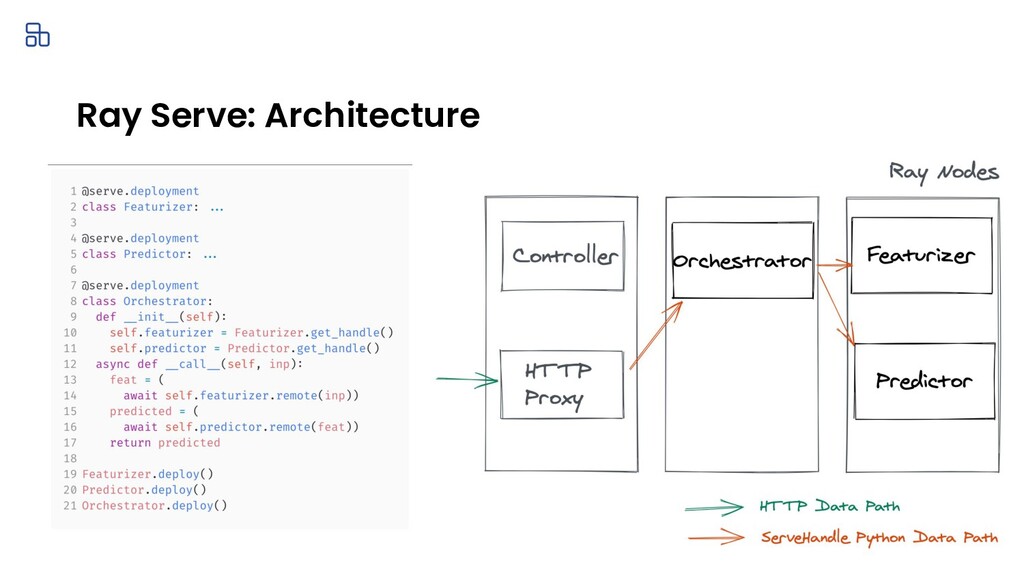{kind=link}
{kind=link}
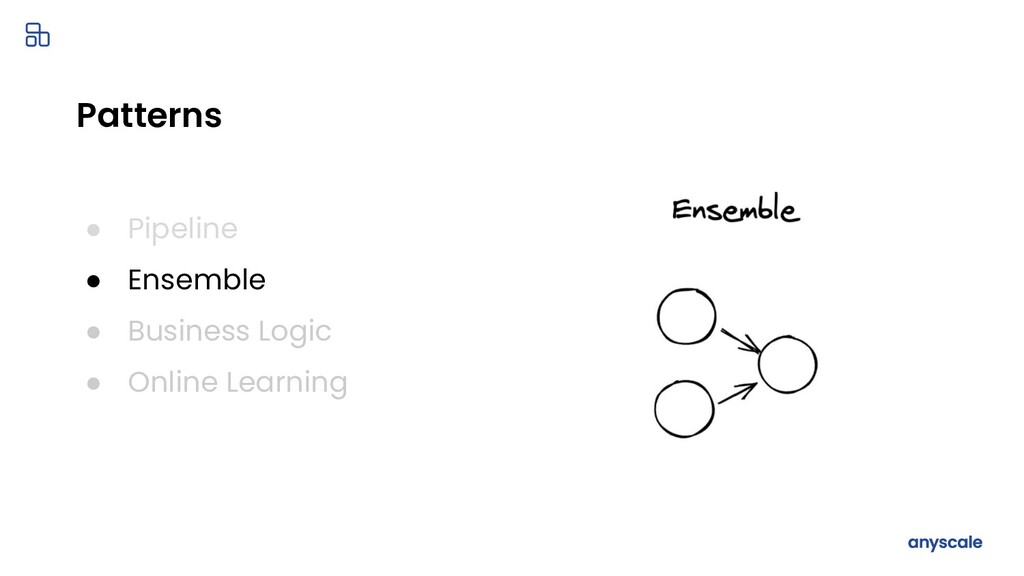{kind=link}
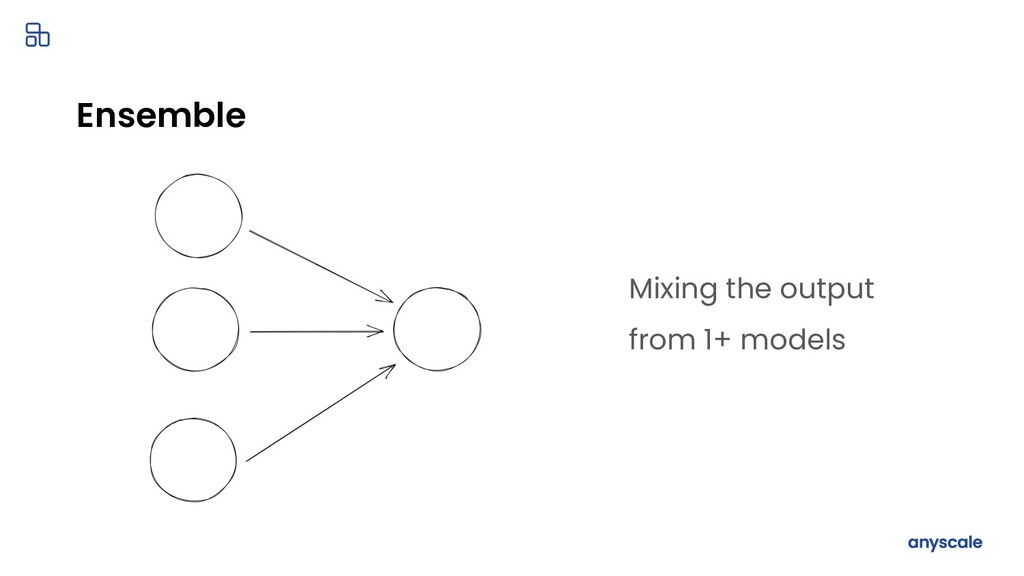{kind=link}
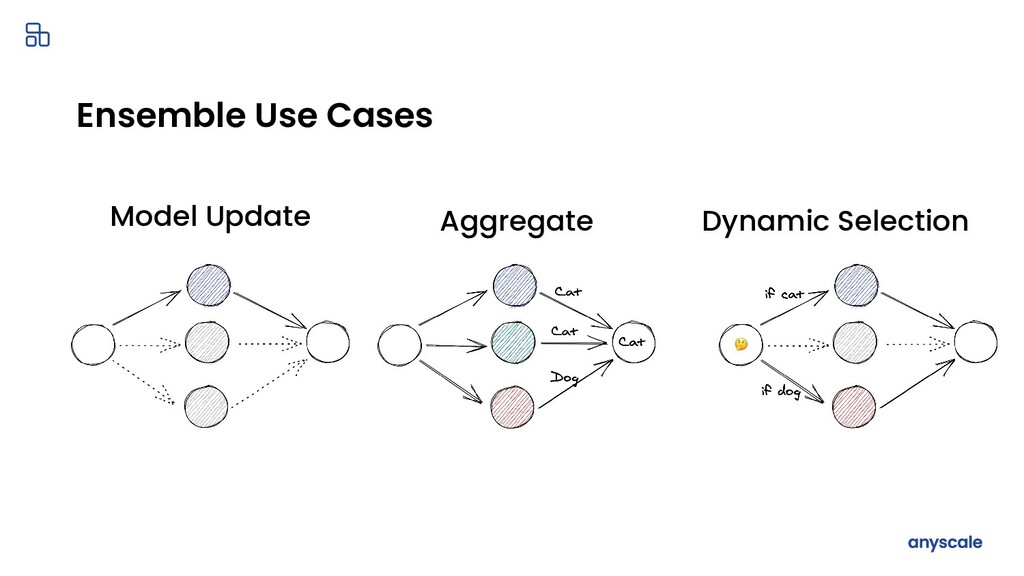{kind=link}
{kind=link}
{kind=link}
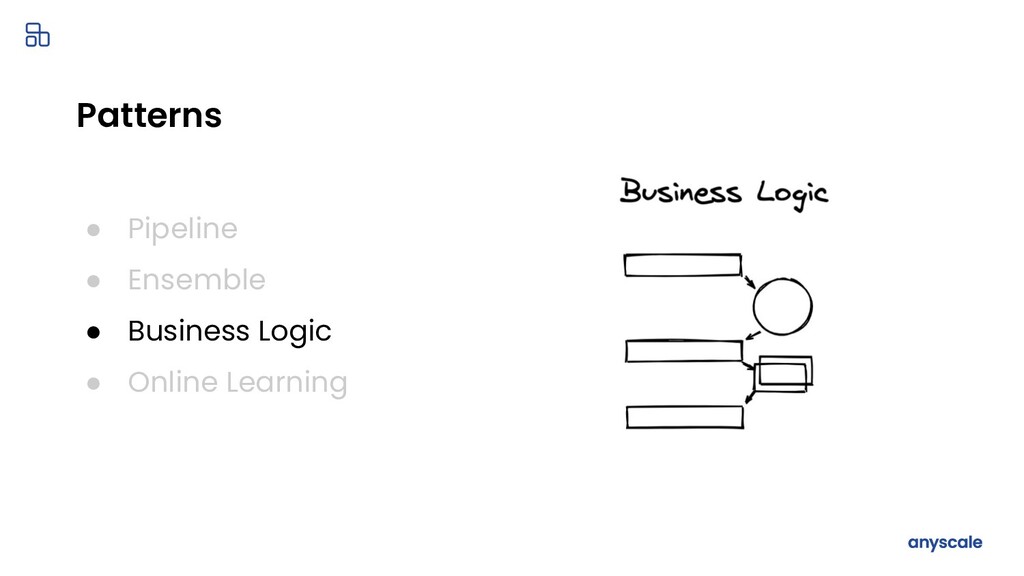{kind=link}
{kind=link}
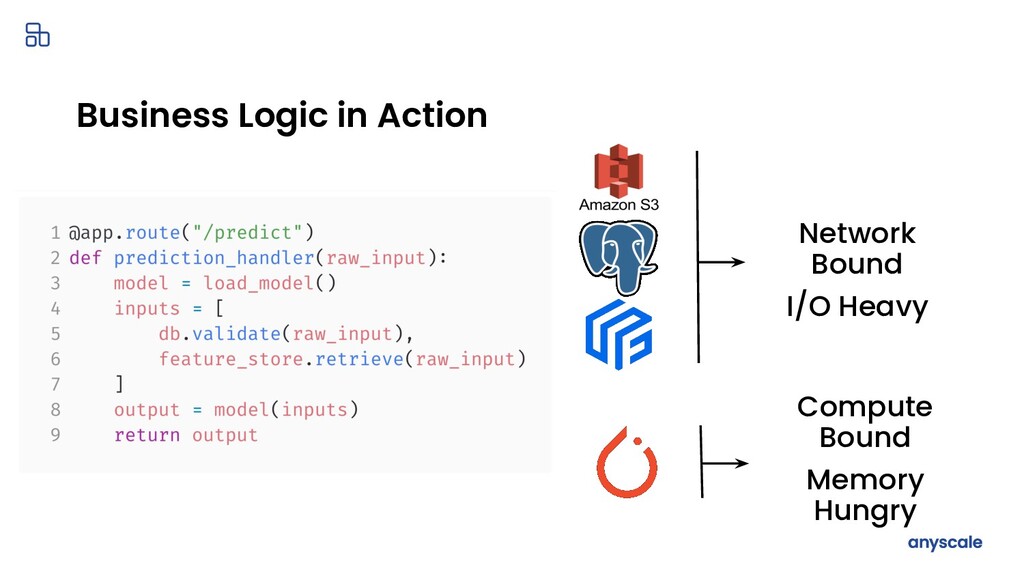{kind=link}
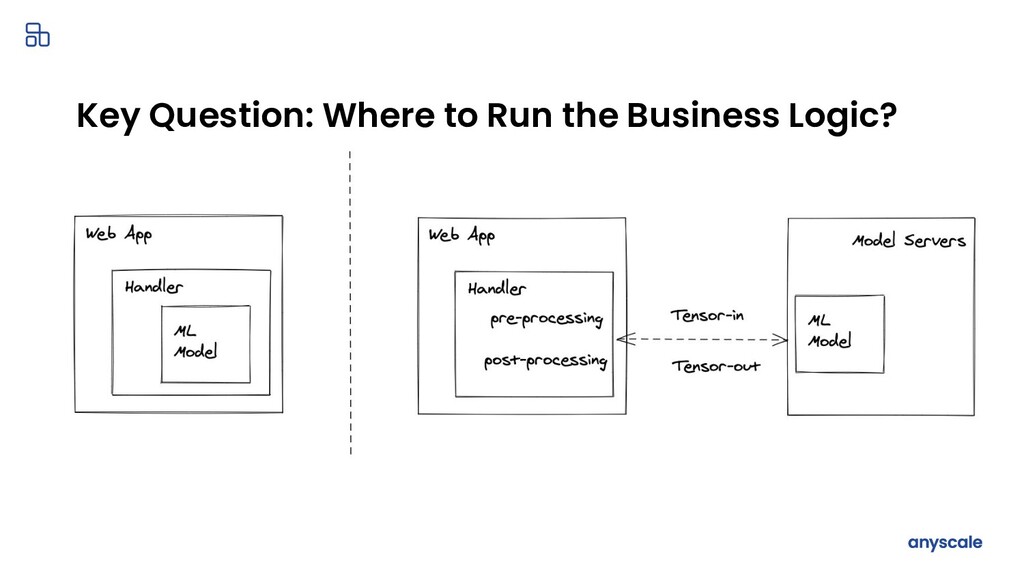{kind=link}
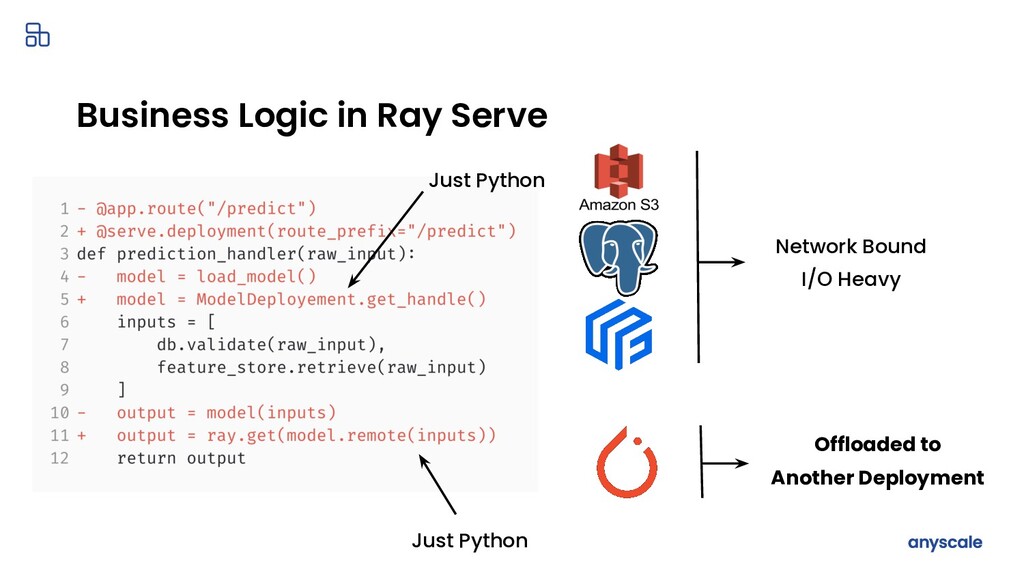{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}