◦ 3d Radio BN (2008-2012) • BS - University of Missouri (2016) • MS - UC Berkeley (2018) • 6th year PhD student at UC Berkeley (2021) ◦ Anthony Joseph ◦ Started with work in Genomics ◦ Learned how to communicate with Scientists ◦ Started the dataframe effort in RISELab
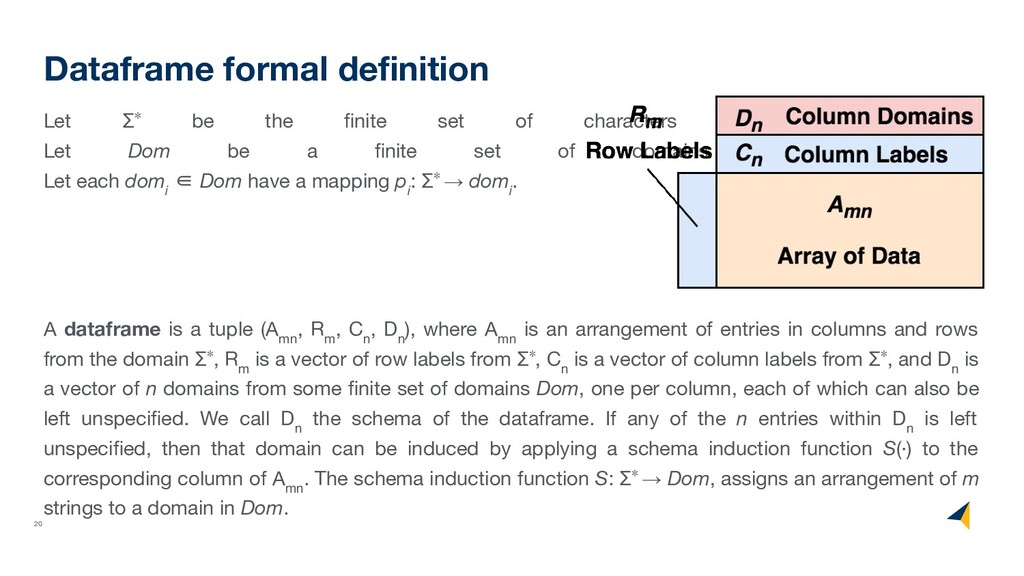
alphabet Σ. Let Dom be a finite set of domains {dom 1 ,dom 2 , ...}. Let each dom i ∈ Dom have a mapping p i : Σ∗ → dom i . A dataframe is a tuple (A mn , R m , C n , D n ), where A mn is an arrangement of entries in columns and rows from the domain Σ∗, R m is a vector of row labels from Σ∗, C n is a vector of column labels from Σ∗, and D n is a vector of n domains from some finite set of domains Dom, one per column, each of which can also be left unspecified. We call D n the schema of the dataframe. If any of the n entries within D n is left unspecified, then that domain can be induced by applying a schema induction function S(·) to the corresponding column of A mn . The schema induction function S: Σ∗ → Dom, assigns an arrangement of m strings to a domain in Dom. Dataframe formal definition
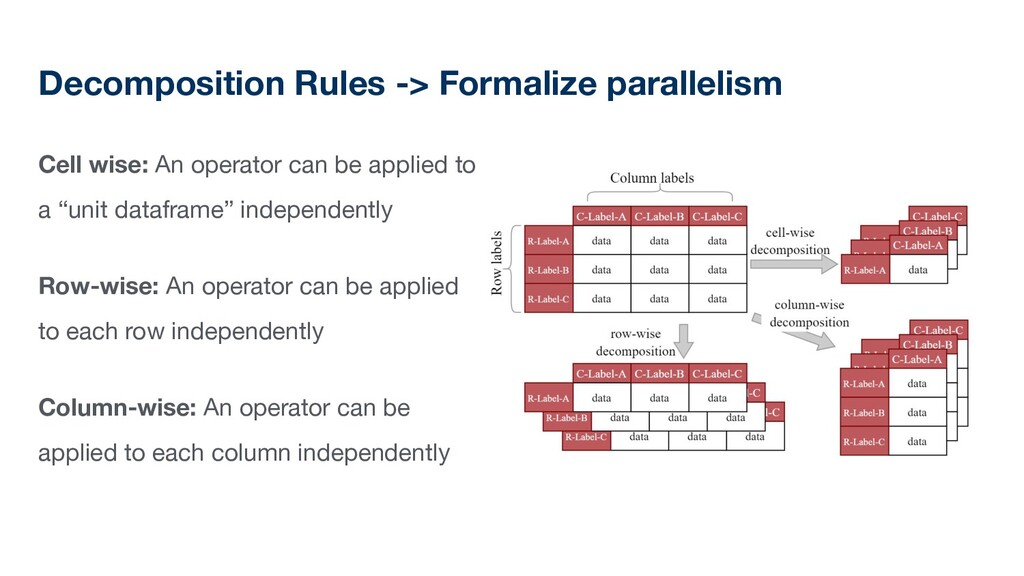
be applied to a “unit dataframe” independently Row-wise: An operator can be applied to each row independently Column-wise: An operator can be applied to each column independently
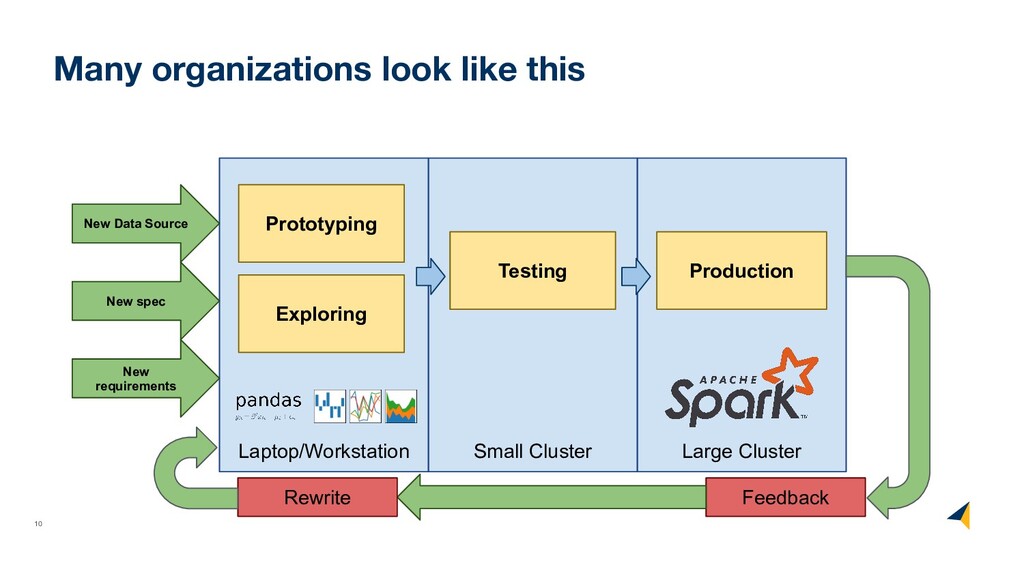
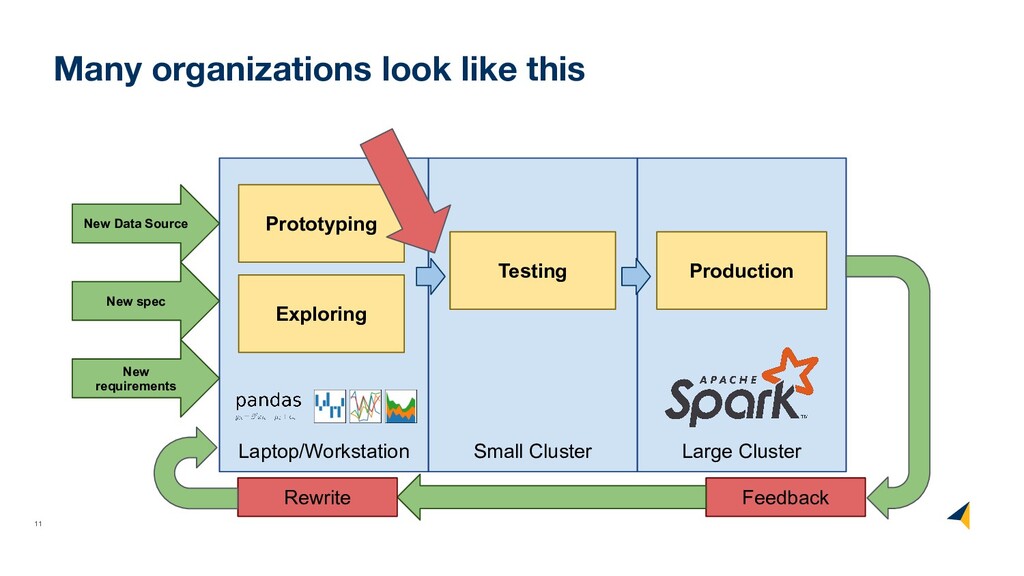
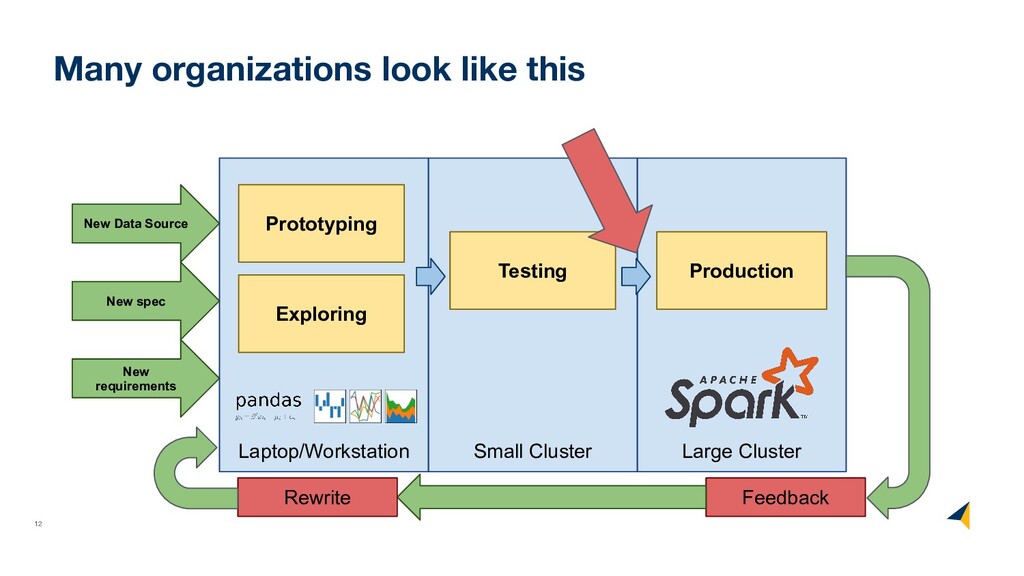
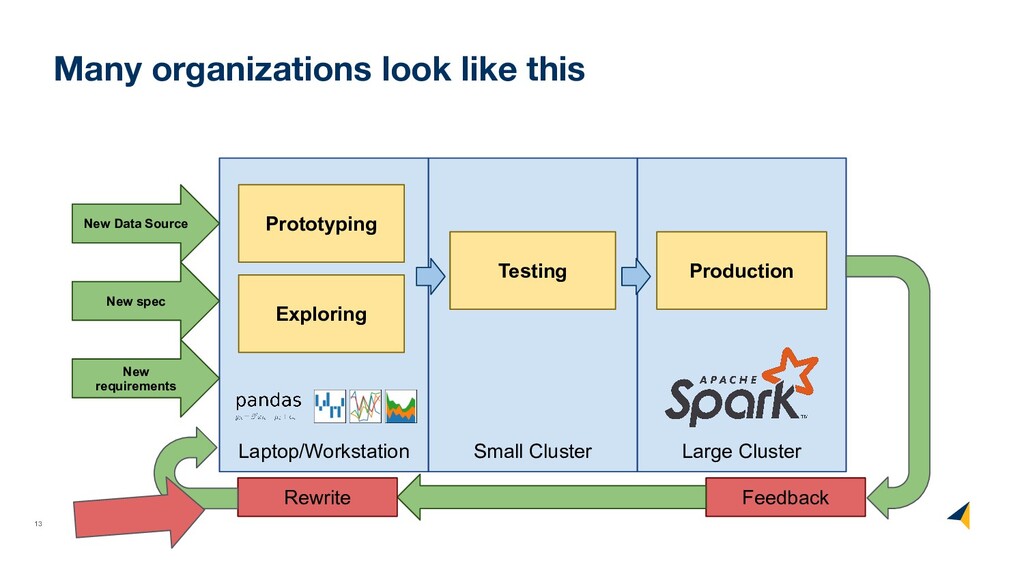
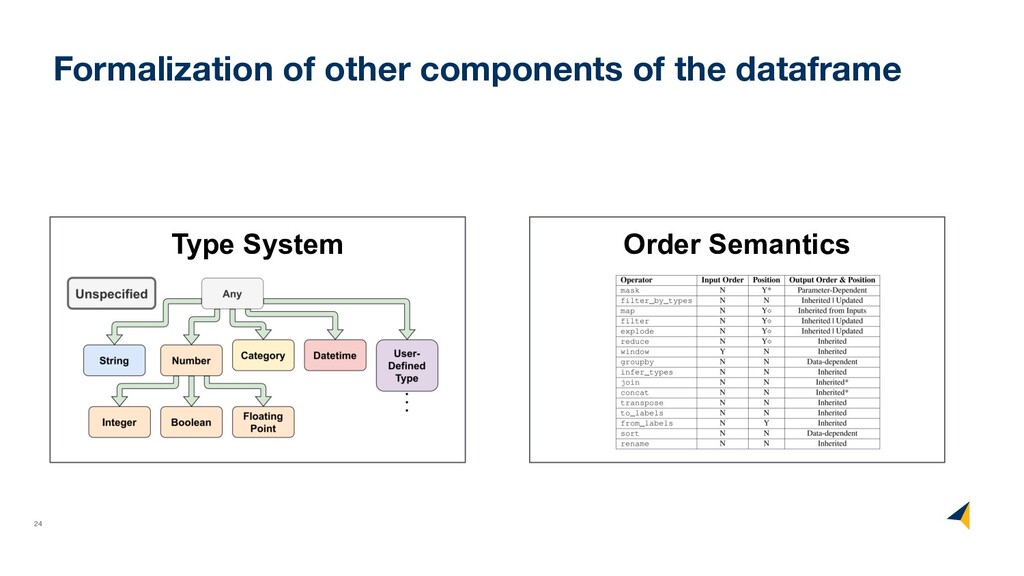
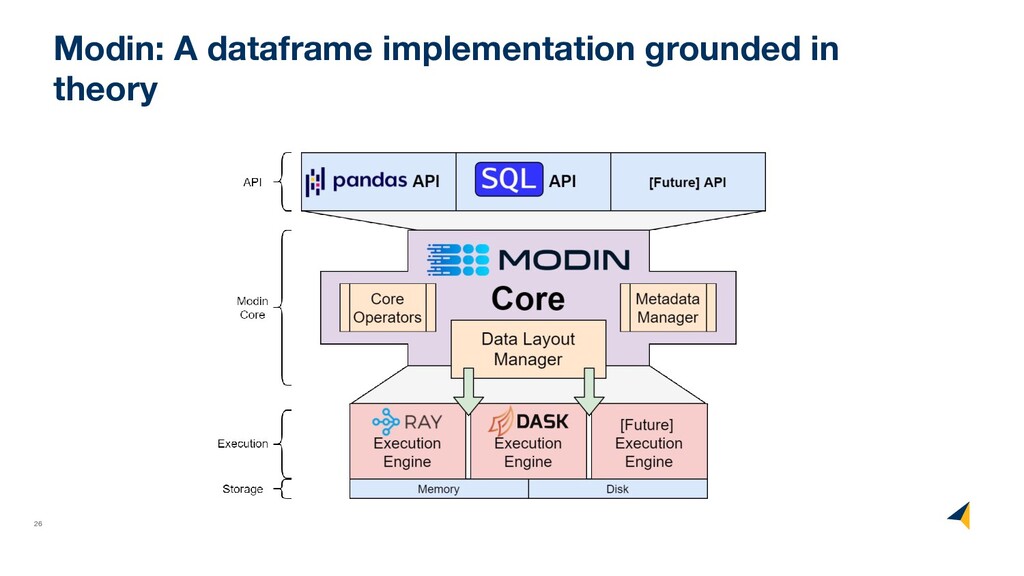
(formally) • What operators a dataframe supports • How these operators map back to pandas • How to handle dataframe types • How to decouple logical and physical order
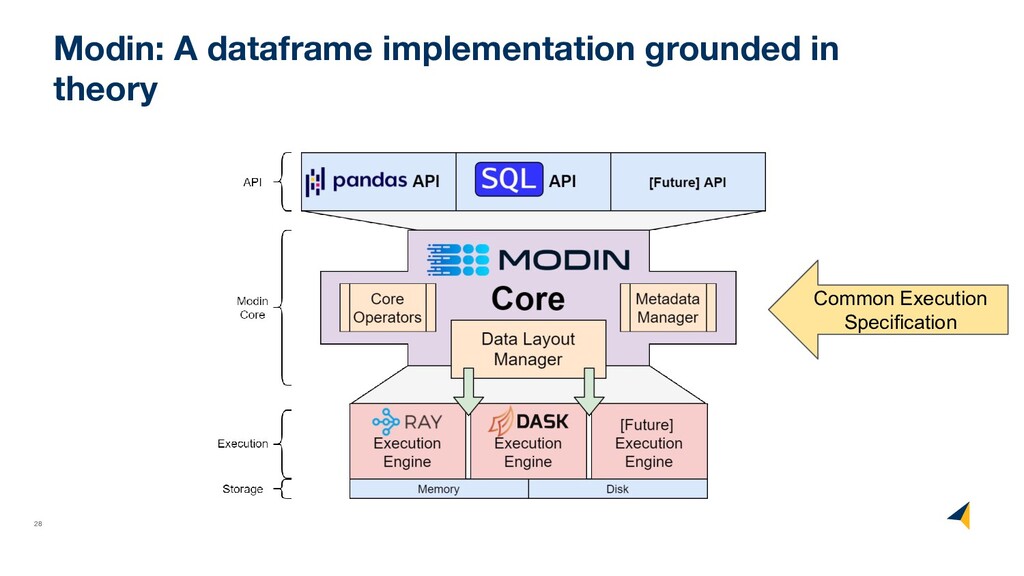
columnar operations) • Sorts the dataframe implicitly based on row labels (index) • No support for MultiIndex • Supports most relational database-style queries (join, groupby) • Fairly rigid partitioning, more flexible than Spark
columnar operations) • Only supports dataframe operators that directly translate to ANSI SQL • Supports only relational database-style queries (join, groupby) • Missing support for categorical data • Fairly rigid partitioning
axes (columns and rows) • Not all translations to low-level algebra finished • Not all low-level algebraic operators fully optimized (uncounted) • Fall back to pandas in case something is not yet supported
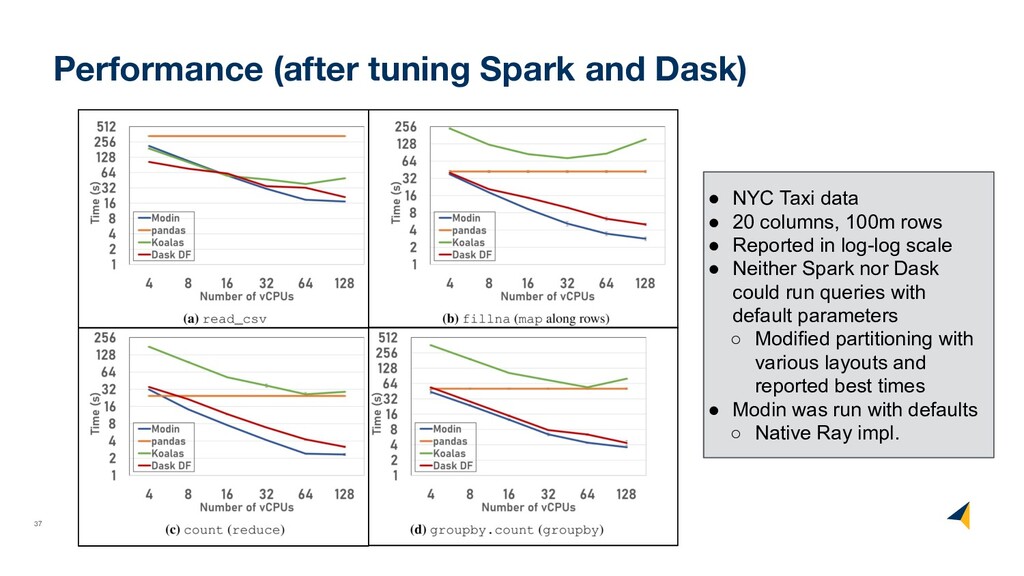
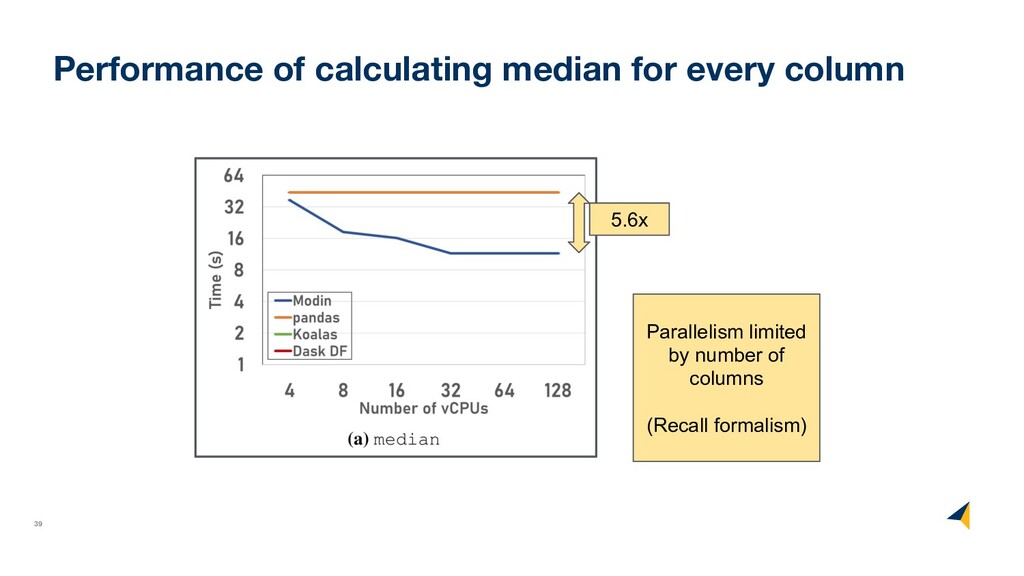
data • 20 columns, 100m rows • Reported in log-log scale • Neither Spark nor Dask could run queries with default parameters ◦ Modified partitioning with various layouts and reported best times • Modin was run with defaults ◦ Native Ray impl.
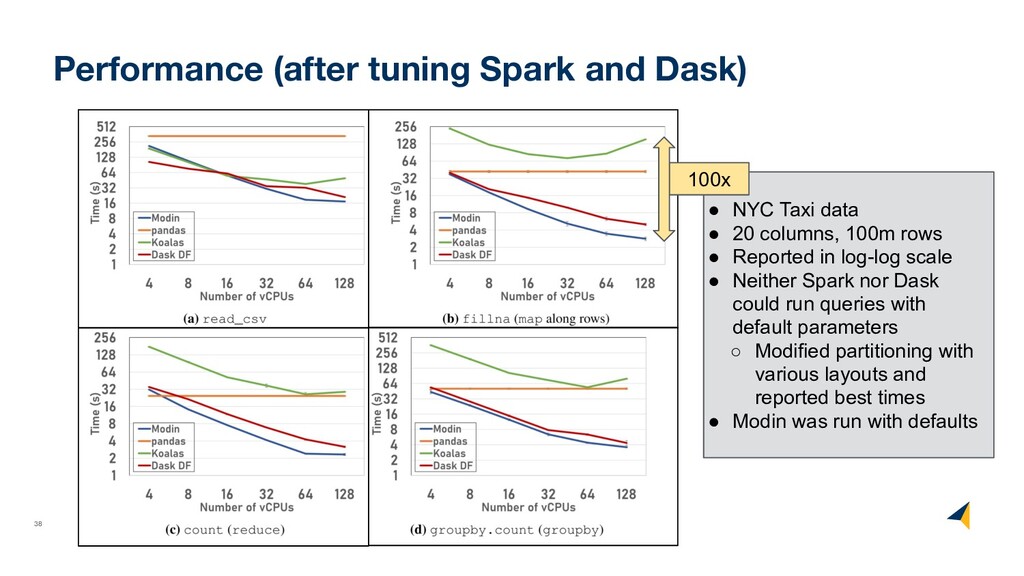
data • 20 columns, 100m rows • Reported in log-log scale • Neither Spark nor Dask could run queries with default parameters ◦ Modified partitioning with various layouts and reported best times • Modin was run with defaults 100x
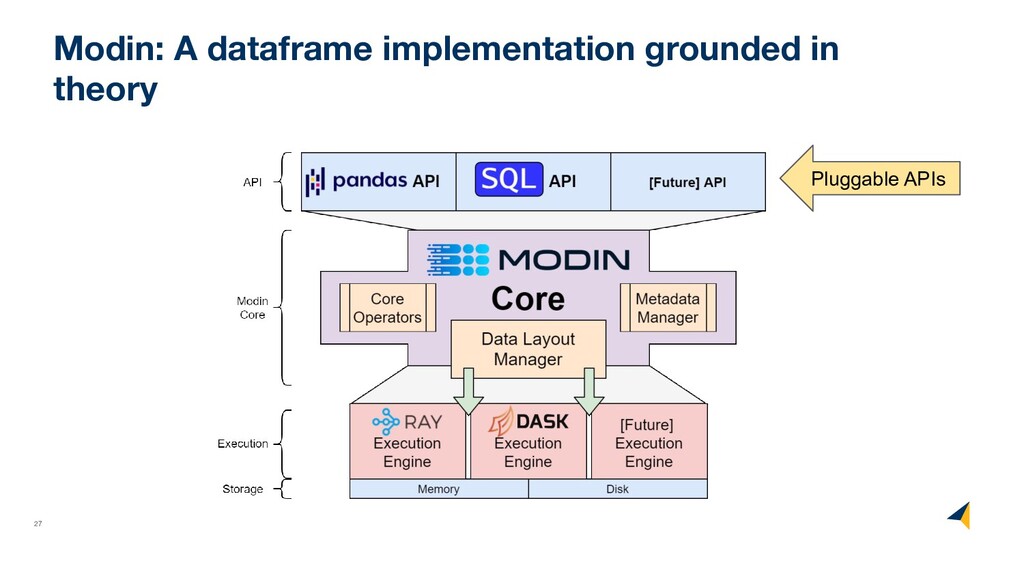
concept implemented with OmnisciDB ◦ Compiles the Modin’s Dataframe DSL to Apache Calcite ◦ Execution is handed off to OmnisciDB ◦ Supports the parts of the pandas API that the Omnisci implementation supports Do you have a data processing system you wish would expose the pandas API? Let us know!
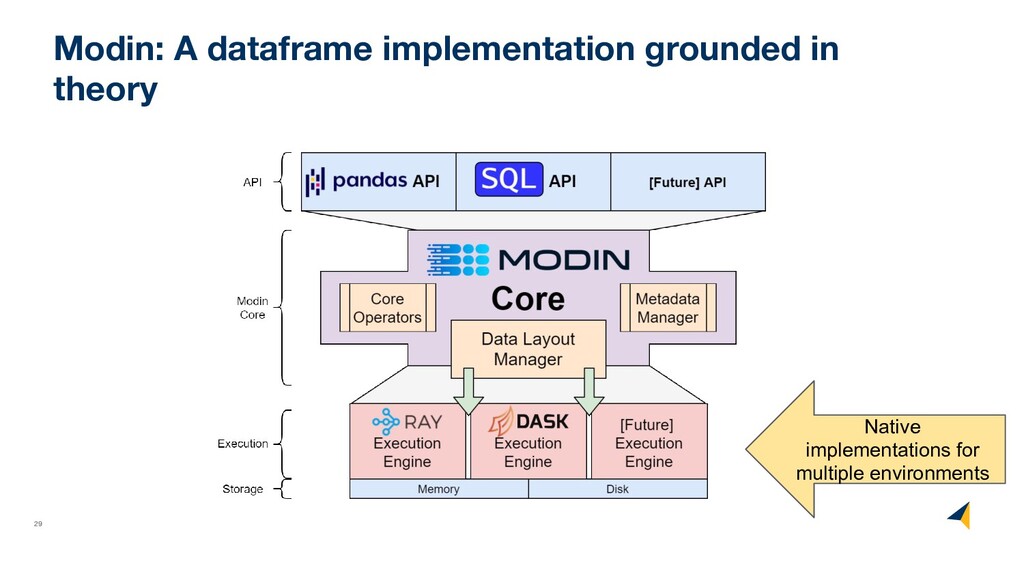
users • Used in many companies, government organizations, and research labs • Major contributions from outside of Berkeley ◦ Intel - 10+ full time engineers actively contributing (daily) ◦ Georgia Tech - 4 students added NVIDIA GPU support (RAPIDS) ◦ MindsDB - added SQL language support ◦ GitHub contributions - XGBoost support, Functionality, enhancements • Most users are replacing pandas + Spark in their DS workloads with Modin
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}